

چکیده
یخبندان آلپ اروپا دارای سنت طولانی مطالعات و فعالیت هایی است که در آن محققان اغلب بر کار میدانی برخی از اپراتورهای داوطلب متخصص تکیه کرده اند. علیرغم نتایج قابل توجه این همکاری، برخی مشکلات در هماهنگ سازی داده های میدانی و در پوشش طیف وسیعی از یخچال های طبیعی نظارت شده همچنان وجود دارد. علاوه بر این، پویایی کاهش، تکه تکه شدن و کاهش، که در دهههای اخیر مشخصه یخچالهای آلپ است، نیاز به بهبود نظارت مکانی و زمانی را با حفظ استانداردهای کیفی کافی ضروریتر میکند. فعالیتهای نظارت میدانی علمی بر روی یخچالهای آلپ به موازات تعدادی از ابتکارات افراد و انجمنهای آماتور، حافظان دانش جایگزین، تجربی و فراعلمی محیط یخچالی انجام میشود. مشکلات هماهنگی، هماهنگی، استخدام و بهروزرسانی را میتوان با کمک یک رویکرد مشارکتی-مانند علم شهروندی- که در آن هماهنگی علمی کیفیت اطلاعات را تضمین میکند و ابزارهای وب 2.0 بهعنوان واسطهای بین یخچالشناسان خبره و مشارکتکنندگان غیرمتخصص عمل میکنند، مورد بررسی قرار میگیرد. این مقاله مروری بر اطلاعات یخچالشناسی در حال حاضر در منطقه آلپ اروپا تولید میکند، و آن را در یک ساختار سازمانیافته، کاربردی برای بحث نشان میدهد. سپس یک راه حل توانمند، هم روش شناختی و هم فناوری، برای یکپارچه سازی داده های چند منبعی پیشنهاد می شود. ویژگی ها، پتانسیل ها و مشکلات آن مورد بحث قرار می گیرد. 0 ابزار به عنوان میانجی بین یخشناسان متخصص و مشارکتکنندگان غیرمتخصص عمل میکنند. این مقاله مروری بر اطلاعات یخچالشناسی در حال حاضر در منطقه آلپ اروپا تولید میکند، و آن را در یک ساختار سازمانیافته، کاربردی برای بحث نشان میدهد. سپس یک راه حل توانمند، هم روش شناختی و هم فناوری، برای یکپارچه سازی داده های چند منبعی پیشنهاد می شود. ویژگی ها، پتانسیل ها و مشکلات آن مورد بحث قرار می گیرد. 0 ابزار به عنوان میانجی بین یخشناسان متخصص و مشارکتکنندگان غیرمتخصص عمل میکنند. این مقاله مروری بر اطلاعات یخچالشناسی در حال حاضر در منطقه آلپ اروپا تولید میکند، و آن را در یک ساختار سازمانیافته، کاربردی برای بحث نشان میدهد. سپس یک راه حل توانمند، هم روش شناختی و هم فناوری، برای یکپارچه سازی داده های چند منبعی پیشنهاد می شود. ویژگی ها، پتانسیل ها و مشکلات آن مورد بحث قرار می گیرد.
کلید واژه ها:
یخبندان ; کیفیت داده ها ؛ دانش شهروندی ; اطلاعات جغرافیایی داوطلبانه اطلاعات اتفاقی ؛ هماهنگ سازی داده ها ; کیفیت داده
1. مقدمه
یخچالها و کلاهکهای یخی (به استثنای صفحات یخی گرینلند و قطب جنوب و یخچالهای اطراف) روی زمین مساحتی بین 510000 تا 514000 کیلومتر مربع را پوشش میدهند ( تخمین کوچکتر و بزرگتر) [ 1 ]. یخچال های آلپ اروپا حدود 0.5 درصد از سطح زمین های یخ زده را تشکیل می دهند [ 2 ]. حتی اگر از نظر گسترش محدود باشند، آنها همیشه مرجع مهمی برای یخبندان شناسی جهان بوده اند، که هم اولین مورد مطالعه و پایش مداوم بوده و هم شاخص های غیرمستقیم خوبی (نمایشگر) تغییرات آب و هوا هستند. یخچال های طبیعی آلپ در حال حاضر موضوع طولانی ترین و قابل اطمینان ترین سری اندازه گیری در جهان هستند و آنها کانون آزمایشات و پروژه های متعدد بین المللی هستند [ 3 ، 4 ]]. همانطور که به خوبی اذعان شده است، قرن گذشته، و به ویژه 30 سال گذشته، شاهد روند کلی کاهش سطوح و حجم یخچال های طبیعی بوده است که عمدتاً ناشی از افزایش میانگین دمای جهانی و کاهش بارش برف زمستانی است [ 5 ]. این منجر به پسرفت چشمگیر یخچال های آلپ شده است که در برخی موارد منجر به تکه تکه شدن، جهش مورفولوژیکی و انقراض کامل چندین بدن یخچالی می شود [ 6 ، 7 ، 8 ].
برخی از سازمانها و ابتکارات علمی بینالمللی – مانند سرویس جهانی نظارت بر یخچالهای طبیعی (WGMS) و اندازهگیریهای جهانی یخ زمین از فضا (GLIMS) – نقشهای رهبری در بخش یخچالشناسی را بر عهده میگیرند و جوامع را تشویق میکنند تا اطلاعات را مطابق با استانداردها و چارچوبهای مشترک تولید کنند. با این وجود، مقامات ملی و منطقه ای به طور سنتی سیاست های خود را در این زمینه مستقل از ابتکارات بین المللی، با ابزار و منابع خود انجام می دهند [ 9 ]]. در بسیاری از موارد، ابتکار عمل توسط مقامات سیاسی و اداری به انجمنها و گروههای تحقیقاتی، موسسات و دانشگاههای داوطلبانه متعهد میشود که از تخصص خود در سطح ملی یا محلی، چه به صورت مشترک یا مستقل استفاده میکنند. به طور کلی، این سازمان ها مسئولیت ارائه دوره ای اندازه گیری پارامترهای فیزیکی و ریخت سنجی را بر عهده می گیرند که گاهی اوقات با تصاویر سنجش از دور و تفاسیر مرتبط تکمیل می شود. در نتیجه، ناهمگونی زیادی در انواع دادههای مشاهده شده، در روشهای جمعآوری، پردازش، ذخیره و انتشار آنها، نه تنها از کشوری به کشور دیگر، بلکه اغلب از منطقهای به منطقه دیگر در همان کشور وجود دارد.
علیرغم اهمیت کار انجام شده در رشته کوه های آلپ اروپا در زمینه یخبندان، عوامل متعددی ایجاد دانش جامع را دشوار می کند. از جمله می توان به موقعیت یخچال ها در مناطق دورافتاده، ماهیت دینامیکی سازندها، دوره محدود برای مشاهدات (معمولاً اواخر تابستان)، کمبود و عدم تداوم بودجه اختصاص داده شده به تحقیق و پایش، و انواع روش ها اشاره کرد. جمع آوری و پردازش داده ها. همه این عوامل به عدم کفایت در نظارت بر پویایی پیچیده موثر بر یخچال های طبیعی آلپ اروپا کمک می کند.
علاوه بر این فعالیتهای نظارتی که توسط متخصصان یخبندان، سنجش از دور و ژئومورفولوژی انجام میشود، تعدادی از فعالیتهای رصد آماتوری نیز وجود دارد که توسط افراد یا گروههایی از علاقهمندان سازماندهی شده در انجمنها انجام میشود، و سابقه و تخصص آنها بسیار متنوع است. آنها حجم قابل توجهی از اطلاعات را تولید می کنند که اغلب از طریق کانال های وب منتشر و به اشتراک گذاشته می شود. از آنجایی که این اطلاعات معمولاً از نظر نوع، ویژگی ها و منابع متفاوت است، به دلیل تنوع در قالب و محتوا، قابلیت ردیابی دشوار، کمبود اطلاعات در مورد دقت، ارزیابی قابلیت اطمینان پیچیده و پیچیدگی حریم خصوصی و حق چاپ، معمولاً توسط دنیای علمی مورد غفلت قرار می گیرد. سیاست های. از سوی دیگر، چنین مجموعه گسترده ای از اسناد به طور بالقوه منبع ارزشمندی از دانش است.
در این مقاله، ما رویکردی را با هدف سازماندهی و جمعآوری دادههای سنتی یخچالشناسی و مشاهدات ارائهشده توسط منابع جایگزین ارائه و توصیف میکنیم که معمولاً از پارادایمهای علمی حذف میشوند و در نتیجه پراکنده و بدون استفاده هستند. ترکیب سیستماتیک اطلاعات یخبندان متخصص و غیرمتخصص فرصتی را برای افزایش دانش یخچال های آلپ از نظر وضعیت فعلی و پویایی آنها – هم از نظر زمانی و هم از نظر مکان – فراهم می کند. روشی که از طریق آن به این هدف دست می یابد چالش برانگیز است و شامل جمع آوری سیستماتیک و تا حدی خودکار داده ها از منابع متخصص، غیر متخصص و حتی ناخواسته است.
برای این منظور، فصل بعدی به شناسایی و تجزیه و تحلیل اشکال موجود داده های یخچالی مربوط به کوه های آلپ اروپایی می پردازد. آنها بر اساس ویژگی های کمی و کیفی مشخص و نشان داده می شوند. در فصل سوم، مراحل روششناختی و فنی مورد نیاز برای تحقق سیستمی برای ادغام دادههای یخچالشناسی چندمنبعی را شناسایی میکنیم. بحرانی ترین مسائل این رویکرد در فصل چهارم مورد بحث قرار گرفته و راه حل های ممکن را برجسته کرده و توصیه هایی ارائه می کند. سپس نتیجه گیری شده و دیدگاه ها در بخش آخر ارائه می شود.
2. داده های یخبندان: وضعیت هنر
در تحقیقات علمی، تکیه بر دادههای حاصل از فعالیتهای متخصصان و از منابعی که معمولاً معتبر هستند، یک روش پذیرفته شده است. بنابراین دادههای یخچالشناسی آلپ برای موضوعات علمی بر اساس معیارهای اعتبار، دقت و پایبندی به روشها انتخاب میشوند. یک استثنا توسط دسته خاصی از مشاهدات میدانی که توسط اپراتورهای “غیر متخصص” اما “با تجربه” تولید شده است، نشان داده می شود. در برخی از مناطق آلپ، در واقع، اندازهگیریهای دورهای برخی از پارامترهای یخچالشناسی معمولاً توسط یک کارمند علمی هماهنگ میشود، اما توسط داوطلبان انجام میشود. اپراتورهای داوطلب کمیته یخبندان ایتالیا نمونه ای از این عمل هستند. بخشی از کمپین اندازه گیری سالانه تغییرات طول یخچال های طبیعی توسط آنها متعهد است. این اپراتورها، اغلب بدون پیشینه علمی یخبندان شناسی، تحت آموزش های مقدماتی قرار می گیرند و در نهایت برخی صلاحیت ها را کسب می کنند. این آنها را قادر میسازد تا مشاهداتی را با قابلیت اطمینان و ثبات خاصی تولید کنند و اطلاعاتی را که ارائه میکنند مواد مفیدی برای یخبندانشناسی علمی میسازد.
علاوه بر این، تعدادی داده و اطلاعات وجود دارد که اغلب از خارج از حوزه علمی به دست میآیند که دارای محتوا و قالبهای بسیار ناهمگون است. یخبندان سنتی معمولاً اطلاعات تولید شده توسط آماتورهای کوهستانی، کوهنوردان، راهنماها و یا متخصصان در زمینه های دیگر غیر از یخبندان (عکاسی، زیست شناسی، هواشناسی و غیره ) را بررسی نمی کند.
در این زمینه، چند عنصر یک ارتباط کلیدی پیدا میکنند: (1) تغییر اخیر در نزدیک شدن به اطلاعات جغرافیایی، که برای کاربران غیرمتخصص بیشتر آشنا شده است و آنها را از نقش دوگانه کاربر و تولیدکننده آگاه میکند ( تولیدکنندگان برای [ 10 ])؛ و (ب) توسعه همزمان فنآوریهای اجتماعی و مشارکتی، که ثابت میکند در جمعآوری و مدیریت محتوای جغرافیایی غیررسمی از منابع مختلف [ 11 ، 12 ]، همچنین در چارچوب علمی مفید است.
در سالهای اخیر، برخی آزمایشها با استفاده از شبکههای فضایی و مشارکتهای غیرمتخصص برای جمعآوری اطلاعات در مورد کرایوسفر پدید آمدهاند. نمونههای فراآلپی عبارتند از شبکه اشتراکی باران، تگرگ و برف [ 13 ]، که در دانشگاه ایالتی کلرادو برای انجام نقشهبرداری مشترک بارشها در ایالات متحده و کانادا، و پروژه آلپاین آمریکا [ 14 ] ایجاد شد.]، یک فراخوان عمومی برای تکرار عکس های تاریخی از یخچال های طبیعی در آمریکا. ابتکارات دیگر سپس به منطقه آلپ اروپا ارجاع داده می شود، مانند مواردی که از برخی آژانس های منطقه ای ایتالیا برای حفاظت از محیط زیست، که پورتال های جغرافیایی و برنامه های تلفن همراه را برای جمع آوری مشارکتی اطلاعات محلی برف [ 15 ، 16 ] و پروژه «Ghiacciai di una volta» که توسط موزه علوم ترنتو برای تکرار عکسهای تاریخی در یخچالهای ایتالیا ترویج شده است [ 17 ].
با این حال، در همه این ابتکارات، جنبه مشارکتی مجموعه به شکلهای خاصی از مشارکت ارائه میشود – برای مثال، برخی از آنها فقط اقدامات کارشناسی معتبر را در نظر میگیرند، برخی دیگر فقط مشاهدات داوطلبانه را در نظر میگیرند، و برخی دیگر عمدتاً مشارکتهای غیررسمی در قالب هستند. ، از فیدهای RSS. هیچ موردی یافت نشد که در آن یک ادغام واقعی بین منابع و اشکال مختلف داده های یخبندان، برف و یخ انجام شده باشد.
همانطور که قبلاً معرفی شد، داده های مربوط به یخچال های طبیعی آلپ، که به طور بالقوه برای تحقیقات یخچال شناسی مفید هستند، متعدد و بسیار متنوع هستند. آنها شامل مشاهدات و اندازه گیری ها، توضیحات در متن آزاد، کدها، علائم متعارف، نقشه ها و آثار گرافیکی می باشند. این داده ها به شکل های مختلفی ترکیب می شوند، برای اهداف مختلف و در زمینه های مختلف تولید می شوند و اندازه و خوانایی بسیار متغیری دارند. در این کار، ما سعی میکنیم این قلمروهای متنوع از دادهها را در گروههای بزرگ همگن سازماندهی کنیم، که امکان درمان مؤثرتر را فراهم میکند. برای به دست آوردن اطلاعات مفید برای دسته بندی داده ها، ابتدا مفاهیمی را یادآوری می کنیم و برخی اصطلاحات را که اخیراً از کاربرد معمولی خارج شده اند توضیح می دهیم.
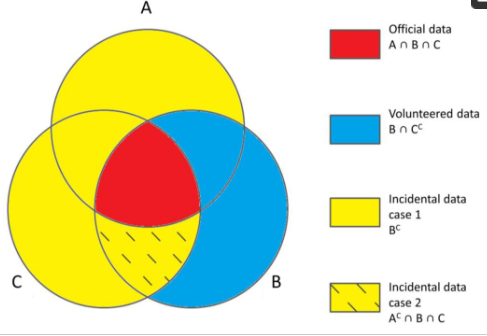
دادههایی که معمولاً «رسمی» در نظر گرفته میشوند مجموعهای از اقدامات، مشاهدات و جزئیات از یک منبع معتبر، علمی یا متخصص هستند که در یک محیط کاری با چارچوب مناسب (یک پروژه تحقیقاتی یا یک کسبوکار) از طریق فرآیندهای کسب و پردازش بهخوبی تعریف شده به دست میآیند. و مستند شده است. از دهه گذشته، حتی مجموعه گستردهای از دادههای «غیر رسمی» که از فعالیتهای مشارکتکنندگان غیرمعتبر به دست میآیند، شروع به برانگیختن برخی علاقهمندیها در جامعه علمی کردند. این مجموعه از فعالیت ها و اطلاعات با اصطلاحات مختلفی مانند Neogeography [ 11 ، 18 ]، Citizen Science [ 19 ، 20 ] واطلاعات جغرافیایی داوطلبانه (VGI) [ 21 ]. این برچسب ها و به خصوص VGI، به خوبی با کمک های ناشی از کمپین های رصد اپراتورهای یخبندان که دارای هدف علمی روشن، ماهیت داوطلبانه و محتوای مرتبط با جغرافیا هستند، مناسب است. اصطلاح “داوطلبانه” به اقداماتی اشاره دارد که به شیوه ای آگاهانه و عمدی، بدون پاداش شخصی – معمولاً اقتصادی – انجام می شود. با این حال، نادرست است که ادعا کنیم همه دادههای غیرکارشناسی در دسترس عموم، که بالقوه برای علم جالب هستند، «داوطلبانه» هستند. در واقع، عمل ارائه اطلاعات عمومی که در این مورد به یخبندان شناسی مربوط می شود، نه همیشه آگاه است و نه بدون پاداش. در انتشار هر یک از این اطلاعات، نویسنده در واقع از ارائه مشاهدات خود در صفحات وب عمومی آگاه است، اما او اغلب از سهمی که از نظر اطلاعات جغرافیایی و یخبندان شناسی در آن وجود دارد، بی اطلاع است. حتی ماهیت بدون پاداش این مشارکتها همیشه آشکار نیست، زیرا اقدام انتشار برخی اطلاعات میتواند برای ارائهدهندگان آنها مزایایی – اقتصادی یا حرفهای – که مستقل از کمک ناخودآگاه به علم به آنها اعطا میشود، به همراه داشته باشد. بنابراین، این کمکهای غیرکارشناسی و غیر داوطلبانه به فرقه دیگری نیاز دارند. ما نام مناسب تر “داده های اتفاقی” را پیشنهاد می کنیم، که با مفهوم آنالوگ “اطلاعات اتفاقی” مطابقت دارد. اصطلاح «تصادفی» در اینجا هم به ارتباط علمی مشارکت و هم به ارزش جزئی آن برای تحقیق اشاره دارد. از آنجا که اقدام انتشار برخی اطلاعات می تواند برای ارائه دهندگان آنها مزایایی – اقتصادی یا حرفه ای – به همراه داشته باشد که مستقل از کمک ناخودآگاه به علم به آنها اعطا می شود. بنابراین، این کمکهای غیرکارشناسی و غیر داوطلبانه به فرقه دیگری نیاز دارند. ما نام مناسب تر “داده های اتفاقی” را پیشنهاد می کنیم، که با مفهوم آنالوگ “اطلاعات اتفاقی” مطابقت دارد. اصطلاح «تصادفی» در اینجا هم به ارتباط علمی مشارکت و هم به ارزش جزئی آن برای تحقیق اشاره دارد. از آنجا که اقدام انتشار برخی اطلاعات می تواند برای ارائه دهندگان آنها مزایایی – اقتصادی یا حرفه ای – به همراه داشته باشد که مستقل از کمک ناخودآگاه به علم به آنها اعطا می شود. بنابراین، این کمکهای غیرکارشناسی و غیر داوطلبانه به فرقه دیگری نیاز دارند. ما نام مناسب تر “داده های اتفاقی” را پیشنهاد می کنیم، که با مفهوم آنالوگ “اطلاعات اتفاقی” مطابقت دارد. اصطلاح «تصادفی» در اینجا هم به ارتباط علمی مشارکت و هم به ارزش جزئی آن برای تحقیق اشاره دارد. که با مفهوم آنالوگ “اطلاعات اتفاقی” مطابقت دارد. اصطلاح «تصادفی» در اینجا هم به ارتباط علمی مشارکت و هم به ارزش جزئی آن برای تحقیق اشاره دارد. که با مفهوم آنالوگ “اطلاعات اتفاقی” مطابقت دارد. اصطلاح «تصادفی» در اینجا هم به ارتباط علمی مشارکت و هم به ارزش جزئی آن برای تحقیق اشاره دارد.
3. مواد و روشها
3.1. تعریف منابع داده در دسترس
قبل از توصیف یک سیستم یکپارچه برای مدیریت داده های یخبندان ناهمگن، باید منابع داده ای را که در آن نقش دارند دسته بندی کنیم. برای انجام این کار، ابتدا بر سه معیار تأثیرگذار تمرکز می کنیم:
-
الف- تخصص: تخصص نویسنده یا زمینه ای که داده ها در آن ایجاد می شوند.
-
ب- هدفمندی: آگاهی از ارتباط داده ها برای علم به طور کلی یا برای یک پروژه تحقیقاتی و در نتیجه تمایل به همکاری.
-
ج-پاداش: سودی که برای توزیع داده به نویسنده اختصاص داده شده است.
اکنون می توانیم سه دسته داده را تعریف کنیم که با ترکیب این معیارها به دست می آیند:
-
داده های رسمی: متخصص، عمدی و با پاداش
-
داده های داوطلبانه: عمدی و بدون پاداش
-
داده های اتفاقی:
-
(مورد 1) غیر عمدی
-
(مورد 2) غیر متخصص، عمدی و با پاداش
-
بسیاری از داده های اتفاقی برای تحقیقات یخچال شناسی در مورد 1 قرار می گیرند – غیر عمدی. تعداد کمی از دادهها، که در قلمرو آلپ بسیار غیرمعمول هستند، در مورد 2 قرار میگیرند. این دادهها رسمی نیستند، غیر متخصص هستند، و همچنین داوطلبانه نیستند و پاداش دریافت میکنند. به دلیل ارزش اندک آنها برای تحقیق، میتوان آنها را به طور تصادفی در نظر گرفت.
این دسته بندی ها را می توان به طور موثر بر اساس نظریه مجموعه ها ( شکل 1 ) نشان داد، زیرا بدون ابهام و عاری از همپوشانی هستند. آنها در توصیف منابع داده حتی فراتر از قلمرو یخبندان مفید هستند. این چارچوب نظری مقدمه بحث بعدی خواهد بود.
3.1.1. داده های رسمی یخبندان
داده های رسمی یخبندان شناسی، همانطور که قبلاً مورد بحث قرار گرفت، توسط متخصصان تحت رویه های مستند و اغلب استاندارد شده به دست می آید یا پردازش می شود. تولیدکنندگان معمولی موسسات تحقیقاتی، دانشگاهها، مقامات محلی، نقشهبرداران، شرکتهای تجاری دارای تجهیزات شناسایی یا مدیریت تصاویر سنجش از دور هستند. مزایای اختصاص داده شده به نویسندگان داده برای انتشار آنها ممکن است جبران مستقیم خدمات، حقوق عادی یا یک جایزه غیرنقدی مانند امتیاز یا ارزیابی مثبت باشد که مزایای حرفه ای را برای نویسنده به ارمغان می آورد.

شکل 1. نمایش داده های رسمی، داوطلبانه و اتفاقی بر اساس نظریه مجموعه ها.
دادهها و محصولات از این طریق ارزش اقتصادی پیدا میکنند، که باعث میشود گاهی اوقات با هزینه یا بر اساس قراردادهای تجاری توزیع شوند. در برخی موارد، برعکس، این داده ها به صورت رایگان و معمولاً از طریق وب ارائه می شوند. این انتخاب معمولاً نتیجه سیاستهای باز کردن داده است (مثلاً جنبش دادههای باز برای ادارات دولتی) و همچنین توسط دستورالعمل اروپایی INSPIRE [ 22 ] و اجرای احکام ملی آن پشتیبانی میشود. این ابتکارات دولت ها و نهادهای خصوصی را تحت فشار قرار می دهند تا اطلاعات جغرافیایی خود را از طریق وب در قالب های استاندارد به اشتراک بگذارند.
توزیع وب داده های رسمی اغلب از طریق انتشار در مجلات علمی یا گزارش های فنی صورت می گیرد. دادهها و تفصیلهای جغرافیایی آنها را میتوان از طریق ژئوپورتالهای سازمانی، در قالب خدمات وب یا لایههای GIS، منتشر کرد.
دادههای میدانی که معمولاً در یخچالشناسی آلپ جمعآوری میشود، اندازهگیری تغییرات طول یخچالها و ضخامت پوشش برف است. هر دو اندازه گیری را می توان با روش های مختلفی انجام داد که بستگی به محیط کار، تجهیزات تیم و اهداف تحقیق دارد. برای مثال، اندازهگیری اول ممکن است از خوانشهای نواری مکرر از فاصله بین حاشیه یخچال و نقاط دیدنی در جلوی یخچال تا استفاده از دستگاههایی مانند ایستگاههای توتال یا GPS متغیر باشد. مورد دوم را می توان با خواندن ارتفاع بر روی یک تیر فرو رفته در پوشش برف، یا حتی با انجام بررسی های پیچیده با رادار، لیزر یا سایر تکنیک های ژئوفیزیکی اجرا کرد.
سایر دادههای مهم از سنجش از دور، از جمله تصاویر ماهوارهای، LIDAR و بررسیهای هوای فتوگرامتری به دست میآیند. یخشناسان با ادغام مشاهدات میدانی و از راه دور، تغییرات ناحیه و حجم و تعادل جرم سطحی را ارزیابی میکنند. این دادهها اغلب بهعنوان ورودی برای مدلسازی هیدرولوژیکی و پیشبینی تکامل مخازن آب شیرین که توسط یخچالها نشان داده میشوند، استفاده میشوند.
این داده ها، به دلیل ماهیت و هدف خود، اشکال و محتوای تکراری را ارائه می دهند که اغلب در ساختارهای همگن سازماندهی می شوند. این بدان معنی است که می توان آنها را با یکدیگر مقایسه کرد، به طور مداوم در مجموعه ها و مجموعه ها قرار داد و بدون سوء تفاهم تفسیر کرد.
اعتبار این داده ها با پیشینه حرفه ای منابع تضمین شده است و صحت آنها منوط به بررسی جامعه علمی است. در این زمینه، در واقع، قابلیت اطمینان اطلاعات توسط فرآیند بررسی، به عنوان رویه رایج در نشریات علمی، پشتیبانی میشود. این روش کاری به شدت انگیزه نویسندگان را برای حفظ استانداردهای با کیفیت بالا، شرط لازم برای کسب اعتبار و اعتبار [ 23 ] می کند.
3.1.2. داده های یخبندان شناسی داوطلبانه
داوطلبانی که وظایف نظارت بر یخبندان آلپ را انجام می دهند از پیشینه های بسیار متفاوتی هستند. گاهی اوقات آنها همکاران موقتی هستند، اما در بیشتر موارد، افرادی هستند که پس از آشنایی با ابتکارات نظارتی و قدردانی از اهداف آنها، به طور خودجوش مسئولیت مشاهده تغییرات یخچال های طبیعی را بر عهده می گیرند. در چنین مواردی، داوطلبان معمولاً اعضای یک گروه هستند و با یک هماهنگی علمی هدایت می شوند. هماهنگکننده دستورالعملهای گروه را ترسیم میکند، در تولید محتوا قانون میگذارد، و گاهی اوقات از طریق کتابچهها، کتابچهها و دورههای خاص، به آموزش داوطلبان میپردازد.
نظارت علمی می تواند کم و بیش در هنگام ایجاد داده ها مشخص شود. به هر حال به طور قابل توجهی بر تولید مجموعه داده های با کیفیت بالا تأثیر می گذارد. در مرحله گزارش دهی، داوطلبان گاهی با ابزارهای کمکی برای گردآوری (نمودارها، کدها، پروتکل ها) و مکانیسم های بازنگری برای اصلاح مجموعه داده های جمع آوری شده پشتیبانی می شوند. رویکرد بررسی کیفیت دادههای داوطلبانه یکی از دغدغههای اصلی برای استفاده نهایی علمی است.
داده ها معمولاً با استفاده از فضاهای وب و برنامه های کاربردی توزیع می شوند، که در آن همکاران (یخچال شناسان یا اپراتورها) گاهی اوقات می توانند فرم های وب را پر کنند، یا اغلب تصاویر و اسناد را آپلود کنند، نکات را تبادل کنند، و محتوا و تجربیات را به اشتراک بگذارند.
داده های داوطلبانه یخبندان شناسی، همانطور که قبلا توضیح داده شد، اغلب توسط پروژه های تحقیقاتی مورد بهره برداری قرار می گیرند یا برای نظارت بر طرح های مورد علاقه عمومی مورد استفاده قرار می گیرند. در چنین مواردی، انتشار داده های داوطلبانه مطابق با خط مشی داده های پروژه، همانطور که توسط هماهنگی نهادی/علمی تعیین شده است، صورت می گیرد.
دادههای یخشناسی داوطلبانه اغلب اشیاء ترکیبی پیچیدهای هستند که تصاویر (عمدتاً تصاویر)، حاشیهنویسیهای متنی، مشاهدات عددی و گاهی اوقات ویژگیهای جغرافیایی (مثلاً نقاط GPS در قالبهای GIS) را ترکیب میکنند.
به طور معمول، داوطلبان تصاویری از یخچالهای طبیعی آلپ را ارائه میدهند، که اغلب از مکانهای دیدنی درست گرفته شدهاند، به دنبال یک جهت از پیش تعیینشده (زیموت) و تکرار در زمان (به صورت سالانه)، به منظور ایجاد یک سری مشاهدات بصری از یک یخچال طبیعی که در آن گرفته شده است. همان شرایط در چند سال اخیر، تصاویر توسط دوربینهای دیجیتال گرفته میشوند و ممکن است شامل برخی ابردادههای مفید برای توصیف صحنه مشاهدهشده باشد (مختصات GPS، تاریخ و زمان). در بیشتر موارد، تصاویر دارای اسنادی هستند که جزئیاتی مانند نویسنده، نام یخچال، نام مکان یا کد نقطه عطف، آزیموت، کانونی، شرایط هواشناسی و یادداشتهای نویسنده را گزارش میدهند.
مشارکتهای متنی رایگان داوطلبان میتوانند مشاهدات مربوط به وضعیت یخچال و همچنین پدیدههای خاص، یا جزئیات تصاویر و اندازهگیریها را گزارش کنند. آنها می توانند اشکال، نحو و مطالب بسیار متفاوتی را ارائه دهند.
مشارکت های عددی می تواند شامل اندازه گیری طول یخچال، ضخامت برف، موقعیت و برآورد ارتفاع برای عناصر یخبندان قابل توجه باشد.
مشارکت در قالب ویژگی های فضایی کمتر رایج است. دلایل آن را می توان در کمبود تجهیزات فنی و اغلب در دانش محدود داوطلبان جستجو کرد که نمی توان از آنها انتظار داشت که ابزار و روش های کافی برای کارتوگرافی داشته باشند. ویژگیهای فضایی معمولاً بردارهایی (ذخیرهشده به عنوان فایلهای SHP یا KML) هستند که نقاط و مرزهای معنیدار در توصیف یخچالها را نشان میدهند.
پیشرفتهای اخیر در فنآوریهای هوشمند میتواند سناریوهای آینده را پیشبینی کند که در آن دستگاههای موبایل سبک (تلفنهای هوشمند، تبلتها) با استفاده از برنامهها و دستگاهها، حاشیهنویسی کاغذی سنتی را برای ثبت مشاهدات یخچالشناسی در این زمینه، و کمکی ارزشمند برای ادغام آنها در این زمینه جایگزین خواهند کرد. فرآیندها و آرشیوهای خطی دستگاه های هوشمند در حال حاضر در زمینه جغرافیا و همچنین بررسی های زمین شناسی مورد استفاده قرار می گیرند و در برخی چارچوب های پیشرفته برای جمع آوری انواع مشاهدات و اتصال به پایگاه های داده از راه دور و برنامه های کاربردی آنلاین استفاده می شوند. آنها میتوانند رابطهای کاربرپسند و ابزارهای تعاملی را فراهم کنند و به نقشهنگاران غیرمتخصص در جمعآوری و نقشهبرداری اطلاعات جغرافیایی کمک کنند.
3.1.3. داده های اتفاقی یخبندان
پس از آموزش داوطلبان، مراحل عملیاتی و جمعآوری بسیار سخت است و بنابراین، تعداد داوطلبانی که در تحقیقات یخچالشناسی مشارکت میکنند در مقایسه با کل جمعیت آماتوری که برای به اشتراک گذاشتن دادههای یخچالهای طبیعی در وب استفاده میشوند، کم است. با وجود محدودیتهایشان، دادههای اتفاقی در درک پدیدهها همکاری میکنند و فراوانی مشاهدات را بهطور قابلتوجهی بهبود میبخشند. این واقعیت، داده های یخبندان شناسی اتفاقی را به یک مکمل آموزنده جالب برای یخبندان آلپ تبدیل می کند.
ارائه دهندگان مطالبی که اتفاقاً مورد علاقه یخبندان هستند به یک دسته تعلق ندارند. به عنوان مثال، اطلاعات اتفاقی می تواند توسط یک کارمند مدنی، یک کوهنورد، یک کلبه کوهستانی یا یک دانش آموز ارائه شود. مشاهدات آنها گاهی اوقات میتواند ناخواسته به اعتبارسنجی دادهها کمک کند، دیدگاههای جدیدی درباره پدیدهها باز کند، یا برای نظارت بر شاخصهای روند همکاری کنند. این تنوع عظیم منابع و رویکردها، مدیریت و ارزیابی این نوع داده ها را به ویژه دشوار می کند.
داده های اتفاقی یخبندان، فرم های ترکیبی را حتی بیشتر از اطلاعات داوطلبانه ارائه می دهند: تصاویر، فیلم ها، حاشیه نویسی ها، اندازه گیری ها، ویژگی های فضایی معمولاً در ساختارهای ناهمگن و متغیر ترکیب می شوند.
مشارکتها اغلب در قالب گزارشهای سفر تولید میشوند که توسط کوهنوردان و کوهنوردان در وب منتشر میشوند. آنها اغلب اطلاعاتی در مورد شرایط برف و یخ و وجود تشکل ها یا خطرات خاص (بلوک های آویزان، شکاف ها، شکاف ها و غیره ) ارائه می دهند.). مجموعههای عکس دیگر محصولات اتفاقی معمولی هستند که بالقوه برای تحقیقات یخچالشناسی مفید هستند. این عکسها اغلب برای مستندسازی سفرها یا سفرها گرفته میشوند و وقتی در وب به اشتراک گذاشته میشوند، میتوانند اطلاعاتی درباره شرایط زمینشناسی، بیولوژیکی و هیدرولوژیکی ارائه دهند. سایر اطلاعات جانبی و جانبی برای یخبندان شناسی را می توان توسط مقامات محلی و مجلات اینترنتی تهیه کرد و اخبار محلی را در وب منتشر کرد، از جمله ریزش سنگ ها، تصادفات، بهمن ها و رویدادهای شدید هواشناسی در نهایت مورد توجه یخدان شناسان است.
همه این نوع اطلاعات اتفاقی معمولاً از طریق وب با استفاده از انجمنها، وبلاگها، صفحات وب، آلبومهای عکس وب و برنامههای اجتماعی و جغرافیایی (به عنوان مثال، برنامههای کاربردی برای نقشهبرداری اجتماعی یا کرههای مجازی) توزیع میشوند. آنها معمولاً برای عموم به صورت رایگان در دسترس هستند و اغلب با ابزارهای اجتماعی برای اشتراک گذاری، نظر دادن و رتبه بندی محتوا ارائه می شوند. دادههای اتفاقی اغلب با ابردادههای کمیاب یا مبهم همراه هستند. گاهی اوقات آنها حتی در طول مراحل ویرایش، اشتراک گذاری اجتماعی و اظهار نظر، عدم اطمینان را جمع می کنند. این امر بازیابی و تفسیر اطلاعاتی مانند تألیف، موقعیت جغرافیایی، تاریخ و زمان و حقوق توزیع را دشوار می کند.
توصیف جریان های کاری مختلف، همانطور که در پاراگراف های قبلی توضیح داده شد، در شکل 2 ترکیب شده است.
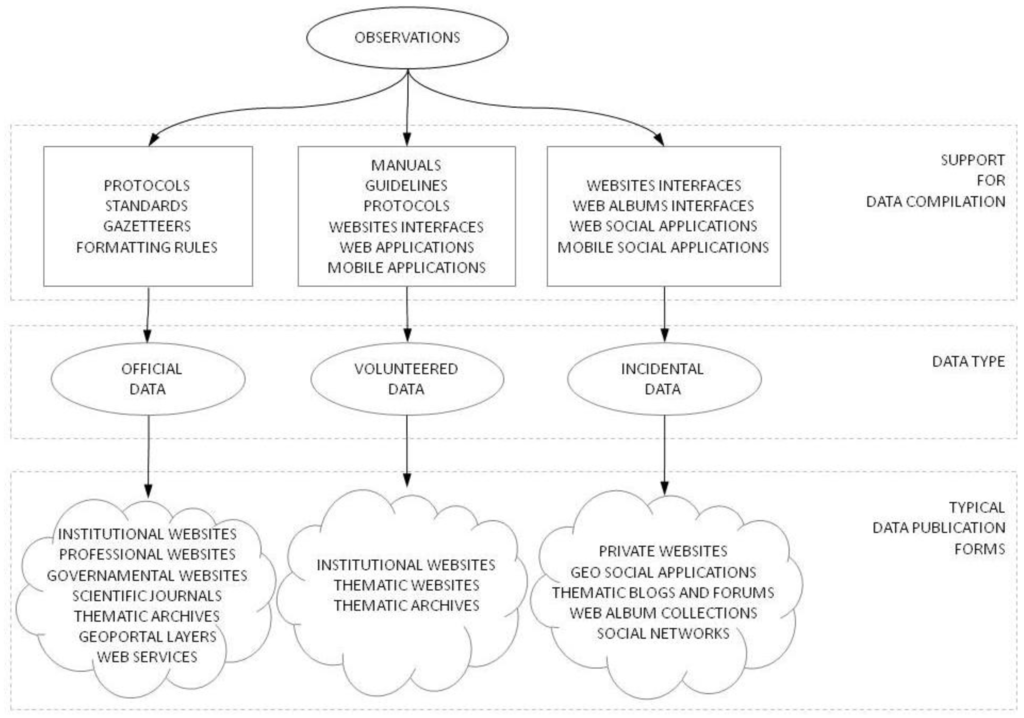
شکل 2. نمایش ترکیبی گردش کار برای داده های رسمی، داوطلبانه و اتفاقی.
3.2. مدیریت منابع داده ناهمگن یخبندان – مروری بر الزامات کاربر برای سیستم یکپارچه
در یخبندان آلپ، مدیریت اطلاعات ناهمگن متمایز با توجه به معناشناسی، ماهیت، قالب و ویژگی های منابع مطلوب است. در واقع، دو دلیل قوی برای اتخاذ راه حلی وجود دارد که بتواند چنین اطلاعاتی را مدیریت کند. اولین عامل علاقه ای است که توسط افراد نهادی و خصوصی برای نظارت بر یک منظره بزرگ و دورافتاده ابراز می شود. چنین منافعی با بودجه کافی برای نظارت پشتیبانی نمی شود. این امر باعث می شود تا با تحریک همکاری ها و مشارکت هرچه بیشتر داوطلبان پراکنده در امتداد دره های آلپ، همه منابع موجود بهینه شود. عامل دوم این است که اگر از یک طرف علاقه شدید بسیاری از مردمی که از کوه ها مراقبت می کنند وجود دارد، از طرف دیگر، کانالی برای انتقال اطلاعات یخبندان شناسی به عموم مردم به روشی ساده، واضح و قابل دسترس وجود ندارد. فقدان یک “فضای” مشترک وجود دارد که در آن همه منافع بتوانند جای خود را پیدا کنند. علاوه بر این، متخصصان و ذینفعان می توانند نیاز به یک سیستم یکپارچه را برای دسترسی و تجزیه و تحلیل این نوع اطلاعات نیز به اشتراک بگذارند، زیرا هنوز دروازه ای برای به دست آوردن اطلاعات به روز در مورد وضعیت یخچال های طبیعی در کل زنجیره آلپ وجود ندارد.
3.3. نمای کلی معماری یک سیستم مدیریت داده یکپارچه
سیستمی برای مدیریت داده های ناهمگن چندمنبعی یخبندان باید به گونه ای طراحی شود که تمام نیازهای توصیف شده را به درستی برطرف کند. عملکردهای اساسی سیستم، همانطور که در زمینه یخبندان شناسی تصور می شود، باید شامل موارد زیر باشد: جمع آوری مطالب موضوعی. پشتیبانی از ذخیره سازی و مدیریت داده ها در قالب های همگن و تایید شده؛ امکان انتشار، به روشی روشن و مفید، برای عموم، ناهمگن و گسترده؛ و ارتقای پردازش و تجزیه و تحلیل داده ها برای متخصصان و ذینفعان.
ما یک رویکرد چندمنبعی موثر و مشارکتی برای یخبندان آلپ را پیشنهاد می کنیم که در اینجا با مراحل فنی آن شرح داده شده است. هر مرحله، از بازیابی داده تا نوردهی نهایی، به صورت گرافیکی در شکل 3 (پانل سمت چپ)، همراه با اجزای سیستم (در پانل سمت راست) توضیح داده شده است.
اولین مرحله ورودی داده به صورت آفلاین توسط سیستم و به صورت ناهمزمان با توجه به مرحله کشف و دسترسی بعدی انجام می شود و بسته به نرخ به روز رسانی و ایجاد اطلاعات از طریق منابع نظارت شده می تواند با فرکانس معین تکرار شود.
ورودی داده با اجرای چهار فرآیند بعدی انجام می شود: خزیدن داده های منتشر شده در وب، ایجاد ابرداده، اعتبارسنجی داده ها بر اساس پایه های کیفیت و سازماندهی نهایی داده ها در یک پایگاه داده.
خزیدن شامل بازدید از بخشی از وب با شروع از مخازن منابع شناخته شده و معتبر، علاوه بر مخازن جالب بالقوه غنی از اطلاعات یخچالشناسی ( به عنوان مثال ، از URL های شناخته شده) برای واکشی صفحات وب به منظور استخراج یا ایجاد از آنها است. حاوی فراداده است (A در شکل 3 ).
خزیدن مخازن منبع معتبر، مانند مخازن حاوی داده های رسمی، می تواند با استفاده از یک خزنده ساده انجام شود، زیرا می دانیم که اطلاعات در آنجا توسط یک طرح واره شناخته شده خاص برای مجموعه داده، آرشیو یا مخزن ادبیات خزیده شده ساختار یافته است. داده های داوطلبانه اغلب در مخازن نیمه ساختار یافته سازماندهی می شوند که توسط مدیران پروژه های تحقیقاتی در دسترس قرار می گیرند. آنها را می توان به راحتی توسط یک خزنده ساده بازدید و دریافت کرد. در موارد دیگر، داده های داوطلبانه هماهنگ نیستند و در نتیجه در منابع وب غیرمعتبر همراه با داده های اتفاقی پراکنده می شوند. برای چنین منابع غیرمعتبر، ما به یک خزنده متمرکز نیاز داریم که فقط زیرمجموعههای محتوای صفحات وب را که میتوانند مورد توجه یخچالشناسی باشند، فیلتر کند.
خزندهای که از دادههای رسمی و داوطلبانه بازدید میکند، که مخازن و طرحوارههای (نیمه ساختاریافته) آن شناخته شده است، میتواند قوانینی را اعمال کند که فقط فیلدهای مرتبط را در دادههای ساختاریافته، مانند اندازهگیریها، مشاهدات، تصاویر و نمودارها انتخاب میکند. خزنده تمرکز، که باید داده های غیرساختارمند مربوطه را شناسایی کند (عمدتاً تصادفی و گاهاً داوطلبانه)، باید با مجموعه ای از قوانین اکتشافی تعریف شود که صفحات وب حاوی عبارات خاصی را انتخاب می کند، مانند نام یخچال های طبیعی آلپ در عنوان تصاویر، و اصطلاحات خاص حوزه یخبندان، برگرفته از یک هستی شناسی.
هنگامی که صفحات وب حاوی اطلاعات مورد علاقه شناسایی و انتخاب شدند، محتویات آنها باید برای استخراج یا ایجاد ابرداده تجزیه و تحلیل شود [ 24 ]. این ایجاد ابرداده همچنین میتواند از حاشیهنویسیهای معنایی، برچسبها و رتبهبندیهای قدردانی مرتبط با محتویات صفحات وب بهرهبرداری کند [ 24 ] (B در شکل 3 ).
برای این منظور، تکنیک های تحلیل واژگانی، پردازش زبان طبیعی و متن کاوی می تواند مفید باشد. هدف بهرهبرداری از تکنیکهای چندگانه بازیابی بیشترین تعداد ممکن ابرداده است که از دادههای صریح و ساختار یافته (جعبه مرزی، نویسنده، تاریخ و زمان، اصل و نسب، و غیره ) و از دادههای ضمنی (نامهای نام، برچسبها، نمایههای کاربران، پیوندها، آدرسها و غیره )، زیرا این امر بر کیفیت نهایی اطلاعات تأثیر میگذارد [ 25 ]. استخراج ابرداده های مکانی و زمانی را می توان به صورت خودکار یا نیمه خودکار از تصاویر [ 26 ]، متن آزاد، کلمات کلیدی و برچسب ها [ 27 ، 28 ] انجام داد.] یا ساختارهای متنی، رمزگذاری شده برای برنامه های اجتماعی، مانند اجزای توییت های توییتر [ 29 ].

شکل 3. نمایش روش پیشنهادی: ( الف ) عملکردها و ( ب ) اجزا.
پس از تولید فراداده، کیفیت آنها باید برای تایید بررسی شود. همانطور که بعداً در این مقاله مورد بحث قرار گرفت، این یک موضوع حساس است، به ویژه در هنگام در نظر گرفتن اطلاعات داوطلبانه و اتفاقی.
تکنیک های اعمال شده به شدت به نوع منبع بستگی دارد. کیفیت اطلاعات رسمی معمولاً قبل از انتشار ارزیابی میشود و لازم است ارتباط آن با تحقیقات یخچالشناسی تخمین زده شود. برعکس، ما باید اعتبار اطلاعات داوطلبانه و اتفاقی را همراه با قابلیت اطمینان مشارکت کنندگان غیرمتخصص ارزیابی کنیم (C در شکل 3 ). ارزیابی کیفیت را می توان با محاسبه شاخص های کیفیت مناسب برای هر نوع فیلد فراداده (تألیف، مهر زمانی، ردپای جغرافیایی و غیره ) با رعایت معیارهایی مانند کامل بودن، صحت، دقت، قابل فهم بودن و سازگاری انجام داد. فقط مشارکتهای داوطلبانه که شاخصهای کیفی آنها از حداقل آستانههای ثابت فراتر میرود، تأیید و حفظ خواهند شد [ 30 ]]. در نهایت، برای ارزیابی کیفیت اطلاعات تصادفی جمعآوریشده در بیشتر موارد، باید روشهای مورد استفاده برای اطلاعات داوطلبانه را با کمک یک ناظر انسانی تکمیل کنیم، که به صورت دستی امتیازهای کیفیت را به مشارکتها اختصاص میدهد. مشارکتهای اتفاقی که کیفیت آنها از حداقل آستانه بیشتر باشد، تأیید و حفظ میشود.
فراداده پاک شده در نهایت می تواند نمایه شود و در یک پایگاه داده جغرافیایی سازماندهی شود تا برای مرحله کشف در دسترس باشد (C در شکل 3 ).
تمام فرآیندهای فوق باید به طور دوره ای مجدداً اجرا شوند، با فرکانسی که باید به عنوان تابعی از چرخه عمر اطلاعات (تاریخ ایجاد، تجدید نظر و حذف) تعیین شود. سایتهایی که اغلب بهروزرسانی میشوند، باید مرتباً توسط خزنده بازدید شوند.
پایگاه داده باید همیشه منبع داده و نویسنده تک تک اطلاعات را ردیابی کند تا امکان تعیین یا تخمین قابلیت اطمینان در هر زمان فراهم شود. در همین حال، بازنمایی مناسب منابع داده به منظور تخمین اعتبار، محبوبیت و نفوذ آنها بسیار مهم است. چنین داده های جانبی می تواند برای بهبود اعتبارسنجی کیفیت انجام شده در تکرارهای بعدی، با حذف اطلاعات نادرست یا عمداً نادرست، استفاده شود، زیرا اغلب توسط منابع به ندرت قابل اعتماد تولید می شود.
اطلاعات نمایه شده باید به طرق مختلف ارائه شود تا امکان کشف و دسترسی به آن فراهم شود. برای این منظور، روشهای کشف متفاوتی را میتوان بر اساس تکنیکهای فیلتر کردن، بازیابی یا مرور اتخاذ کرد. در یک رویکرد فیلترینگ (یا فشار)، مجموعهای از اطلاعات به صورت دورهای به آدرس خود کاربر، با توجه به ترجیحات او از نظر محتوا و فرکانس، واکشی میشود. در رویکرد بازیابی (یا کشش)، سیستم پرس و جوهای صریح کاربر را تفسیر کرده و آیتم های اطلاعاتی مربوطه را بازیابی می کند. در رویکرد مرور، یک مرورگر مشتری به کاربر کمک میکند تا در خوشهها یا کلاسهایی از آیتمهای اطلاعاتی در صورتی که در درختهای سلسله مراتبی سازماندهی شده باشد، حرکت کند. همه این تکنیکهای جایگزین به یک تجزیهکننده زبان پرس و جو برای تفسیر ترجیحات کاربران نیاز دارند.شکل 3 ). پرسشها و ترجیحات را میتوان به چند شکل بیان کرد: متون زبان طبیعی، اصطلاحات کنترلشده از فرهنگ فهرستها یا از یک اصطلاحنامه موضوعی، نامهای نامگذاری انتخاب شده از روزنامه جغرافیایی، مختصات مکانی یا جعبههای مرزی، بازههای زمانی، یا حتی پرسوجوهای پیچیده حاوی Boolean و عملگرهای رابطه ای که در یک زبان رسمی بیان می شوند (مانند SQL، Xquery، Xpath، SPARQL، و غیره ).
اطلاعات کشف شده باید به روشی آسان و در دسترس به کاربر ارائه شود. برای دستیابی به این امر، آنها باید واسط های وب و موبایل مناسبی را راه اندازی کنند تا کاربران بتوانند اطلاعات را بررسی کنند (E در شکل 3)). آیتم های اطلاعاتی را می توان با نمادها و سبک ها نشان داد تا دسته بندی منابع آنها – رسمی، داوطلبانه یا اتفاقی – و امتیازات کیفی کلی آنها مشخص شود. اقلام اطلاعات یخبندان معمولاً حاوی یک یا چند مرجع فضایی هستند که با مختصات یا نام های توپی بیان می شوند. این اجازه می دهد تا مجموعه ای از اقلام اطلاعاتی را روی یک نقشه تعاملی نمایش دهید، جایی که می توان آنها را از طریق نشانگرهای سبک، که در مرکز ردپای جغرافیایی قرار داده شده اند، نشان داد. نمایشگر نقشه ابزارهای بزرگنمایی و متحرک کردن را ارائه می دهد، در حالی که یک ابزار پرس و جو و فیلتر می تواند درخواست های متنی و بصری را با کلیک بر روی نقشه امکان پذیر کند. یک روزنامه جغرافیایی همراه با ابزارهای geocoding (معکوس) میتواند امکان ترجمه خودکار نامها را در مکانهای جغرافیایی مربوطه فراهم کند. حالت دسترسی بیشتر، مناسب برای اقلام جغرافیایی و غیرجغرافیایی، می تواند لیستی از اطلاعات بازیابی شده را که بر اساس معیارهای زمانی و/یا کیفیت مرتب شده اند نمایش دهد. حتی در این حالت ارائه، کاربر باید با ابزارهای پرس و جو و فیلتر ارائه شود.
اقلام بازیابی شده را می توان با برخی از ویژگی های آنها، مانند دسته منبع، زمان ایجاد، شاخص کیفیت و ارتباط با پرس و جو، خلاصه یا ترکیب کرد.
برای محافظت از داده های خصوصی و مدیریت بهتر دسترسی کاربر، ممکن است لازم باشد یک سیستم احراز هویت فعال شود و حقوق خواندن و نوشتن تنظیم شود.
داده های میزبانی شده بر روی سرور پروژه را می توان به کاربران ارائه داد و امکان دانلود آن را نیز فراهم کرد. دانلودها باید با خط مشی های حق چاپ و مجوز، همراه با حقوق مالکیت معنوی مطابقت داشته باشند (به بحث در ادامه این مقاله مراجعه کنید).
فرمتهای موجود برای دانلود باید تا حد امکان با پراکندهترین برنامهها در زمینههای فنی و آماتور مطابقت داشته باشد تا به بهترین قابلیت بهرهبرداری از اطلاعات توسط کاربران نهایی مختلف دست یابد. برخی از عملکردهای ساده اضافی باید در داخل سیستم برای بهبود بهره برداری از اطلاعات پیاده سازی شود. به عنوان مثال، ابزارهای GIS مانند که لایههای داده همزمان را پوشش میدهند، سبکهای لایهها (رنگها، نمادها، شفافیت و غیره ) را سفارشی میکنند، مضامین خاص (ویژگیها) را انتخاب میکنند و بزرگنمایی میکنند، یا پنجرههای جغرافیایی و زمانی برای اجرای فضایی و جغرافیایی ساده. تجزیه و تحلیل های آماری بر روی داده های انتخاب شده (F در شکل 3). در نهایت، برخی از ابزارها را می توان به منظور ارتقاء ارزیابی کیفیت مشترک بر روی داده های ارائه شده پیاده سازی کرد. جامعه کاربران را می توان با ابزارهای اجتماعی ارائه کرد که به وسیله آن نظرات و رتبه بندی مشارکت ها، ارزیابی آنها از نظر معیارهای سازگاری و قابلیت اطمینان، بی نظمی ها و مغایرت ها را نشان می دهد. بازخورد به دست آمده توسط این تلاش مشترک می تواند با یادگیری تکراری وارد فرآیند اعتبار سنجی کیفیت شود.
4. بحث در مورد جنبه های انتقادی
مدیریت یکپارچه اطلاعات یخبندان شناسی تولید شده توسط منابع داده متمایز، مزایای غیر قابل انکاری را ارائه می دهد، اگرچه برخی نگرانی ها را مطرح می کند، عمدتاً در رابطه با کیفیت داده ها، ویژگی های مکانی و زبانی، حفاظت و حق چاپ، و مشارکت کاربران وب.
4.1. کیفیت داده
جنبههای کیفی که عمدتاً بر قابلیت استفاده از دادههای یخچالشناسی تأثیر میگذارند، موارد متعددی هستند که از جمله آنها میتوان به دقت و دقت موقعیت جغرافیایی و مشاهدات، کامل بودن و قابل فهم بودن مطالب و همچنین قابلیت اطمینان اطلاعات و قابل اعتماد بودن منبع دادهها اشاره کرد.
در ادبیات، منابع مفیدی در مورد مدل سازی و ارزیابی کیفیت اطلاعات، حتی در مورد اطلاعات جغرافیایی (GI) و VGI [ 31 ] وجود دارد.
ارزیابی کیفیت مرحله ای است که نمی توان از آن اجتناب کرد یا دست کم گرفت. برای اینکه ابتدا اطلاعات را به درستی مدیریت کنیم و سپس با تجسم، تحلیل های فضایی، مدل سازی و غیره به طور مداوم از آن بهره برداری کنیم، باید در رابطه با خط مشی کیفیت، استراتژی داشت .
اعتبار/قابلیت استفاده محتوای اطلاعاتی و اعتبار آن دو معیار اساسی هستند که کیفیت داده ها را می توان تعیین کرد.
اعتبار محتوای اطلاعات، که به عنوان کیفیت ذاتی [ 30 ] نیز شناخته می شود، به ترکیبی از عوامل مانند اصل و نسب، دقت موقعیتی، دقت ویژگی، سازگاری منطقی و کامل بودن [ 32 ] بستگی دارد که به طور کلی، داده ها را برای یک استفاده شده [ 33 ]. بنابراین به ویژگی های ذاتی محتوا وابسته است.
روشهای قابل استفاده برای ممیزی این ویژگیهای کیفی میتواند شامل تکنیکهای پیشقدم و پسبعدی باشد که به روشهای مختلف ترکیب شدهاند. تکنیک های پیشین با جلوگیری از ایجاد مشارکت های اشتباه و راهنمایی مشارکت کننده در ارائه داده های مؤثر عمل می کنند. برخی از نمونههایی از این تکنیکها عبارتند از پر کردن هدایتشده پروتکلها، استفاده از فرمهای وب با فیلدهای ثابت، استفاده از ابردادههایی که بهطور خودکار توسط دستگاه اندازهگیری ایجاد میشوند (به عنوان مثال ، اطلاعات GPS مرتبط با یک عکس گرفته شده با گوشی هوشمند)، استفاده از هستی شناسی ها و روزنامه های جغرافیایی [ 34 ، 35 ]، انتخاب و آموزش مشارکت کنندگان داوطلب [ 36 ].
در مقابل، تکنیکهای پس از ارسال در طول عملیات تعمیر برای محتوای ایجاد شده از قبل، اصلاح اجزای معیوب یا مرتبسازی دادههای ورودی بر اساس معیارهای اثربخشی کیفیت اعمال میشوند. چندین نمونه از این نوع استراتژی در ادبیات گزارش شده است. به عنوان مثال، پایگاه داده های عظیم پروژه هایی مانند eBird [ 37 ] و FeederWatch [ 38 ] توسط فیلترهای آماری زمین به طور خودکار پردازش می شوند، اما همچنین توسط متخصصان انسانی، به منظور شناسایی سوگیری ها و حفظ ثبات داده ها [ 39 ].
در رابطه با اعتبار اطلاعات جغرافیایی، در مجموع می توان بیان کرد که هم به قابلیت اعتماد و هم به تخصص نویسنده [ 40 ] بستگی دارد و تنها ترکیبی از این دو جنبه می تواند اعتبار را به اطلاعات اختصاص دهد [ 23 ]. ، 41 ].
مفهوم اساسی اعتبار هم برای تولید متعارف اطلاعات علمی متخصص و هم محتوای تولید شده توسط کاربر (UGC) مناسب است، حتی اگر مورد دوم به دلیل برخی جنبه های خاص دامنه وب، مانند ردیابی دشوار نویسندگان، فقدان استانداردها، پیچیده باشد. و انتخاب های شایسته و جستجوی پرهزینه برای منابع. در دهه گذشته، مطالعات متعددی بر روی ساخت مدلهای اعتبار [ 41 ]، تجزیه و تحلیل کمی و کیفی جریانهای محتوای تولید شده توسط کاربر در وب با بحث در مورد ویژگیهای ذاتی، منابع، موضوعات، محرکها [ 42 ، 43 ، 44 ] و موضوع هنوز باز و مورد بحث است.
در ادبیات، ما استراتژیها و رویههایی را با هدف مدیریت کیفیت اطلاعات جغرافیایی غیرمتخصص، همانطور که در چارچوبهای پروژه خاص با هدف استفاده همراه با اطلاعات معتبر جمعآوری شده است، گزارش کردیم. این مورد Huang و همکاران است. [ 45 ]، که سیستم شهرت جدیدی را پیشنهاد میکنند که از تابع Gompertz برای محاسبه امتیاز شهرت دستگاه برای تخمین قابل اعتماد بودن دادههای ارائهشده استفاده میکند.
ردی و همکاران [ 46 ] معیارهای خاصی را برای تعیین کمیت تخصص و مشارکت شرکت کنندگان توسعه داد. دی لونگویل و همکاران [ 47 ]، و بعد، Ostermann و Spinsanti [ 25 ] با پیشنهاد یک گردش کار، یکپارچه با زیرساختهای داده مکانی موجود، برای ارزیابی خودکار کیفیت VGI، به این مشکل پرداختند. متفاوت از هوانگ، این نویسندگان یک روش پیچیده را طراحی کردند که از طریق چندین مرحله و تکراری، کیفیت را با در نظر گرفتن نه تنها قابل اعتماد بودن، بلکه ارتباط و کامل بودن محتوای جغرافیایی منبع و ابرداده های مرتبط را ارزیابی می کند.
معمولاً پذیرفته میشود که دادههای رسمی دارای تمرکز بیشتری از اطلاعات قابل اعتماد و مفید برای علم هستند، در حالی که دادههای داوطلبانه و غیرتخصصی بیشتر تحت تأثیر نادرستی قرار میگیرند و دارای ارزش علمی کمتری هستند.
برخی از نویسندگان تلاش هایی را برای اثبات چنین حدسی با تجزیه و تحلیل مجموعه داده های مشاهدات داوطلبانه و تخصصی انجام داده اند. دیکینسون [ 39 ] مجموعه ای از مطالعات را گزارش می دهد که در آن تغییرات در کیفیت ناظر با آماده سازی نویسنده مرتبط است. از جمله عوامل مؤثر بر چنین تغییراتی، پیشینه و تجربه [ 36 ] همراه با نوع کار [ 48 ، 49 ، 50 ]، سطح آموزش، شرکت متخصص در این زمینه [ 51 ] و سن و تحصیلات نویسنده [ 51] است. 52 ].
علیرغم ویژگیهای کیفی نامطلوب دادههای داوطلبانه و اتفاقی، تعداد بیشتر مشارکتهای بالقوه نقطه قوت قابل توجهی برای آن نوع دادهها است.
چندین مطالعه نشان دادهاند که استفاده خلاقانه و کلی از مشارکتهای غیر متخصص میتواند اطلاعات ارزشمند جدیدی تولید کند [ 47 ، 53 ، 54 ]، و موقعیتهایی را مستند کرده است که در آن دانش یا تخصص محلی اطلاعاتی با ارزش بیشتر از دانش تخصصی ارائه میدهد [ 55 ] . شواهدی از پتانسیل بالای اطلاعات جغرافیایی داوطلبانه در زمانی که در زمینههای ساختار یافته جمعآوری و مدیریت شوند، وجود دارد. همچنین در نتایج تجزیه و تحلیل انجام شده توسط نویسندگانی مانند Haklay [ 56 ]، Girres and Touya [ 57 ]، Cipeluch و همکاران. [ 58] که دقت داده های OpenStreetMap را در برابر منابع مرجع ارزیابی کرده اند.
تخصیص اختیار در اطلاعات متخصص محور سنتی با یک مدل مقتدرانه از بالا به پایین حاصل می شود. برعکس، در محتوای تولید شده توسط کاربر غیر متخصص، ارزیابی قابلیت اطمینان از یک پارادایم دموکراتیک مطابق با مدل پایین به بالا پیروی می کند [ 59 ]. با این حال، ترکیب این دو روش نه تنها ممکن است، بلکه می تواند نتایج قابل توجهی را نیز به همراه داشته باشد. در این زمینه، ما نباید قدرت وب را به عنوان محل ملاقات برای ارزیابی های مشارکتی دست کم بگیریم: دسترسی مستمر به محتوای وب توسط یک تیم ترکیبی از کارشناسان، افراد محلی، آماتور و بازدیدکنندگان گاه به گاه مجاز به ارزیابی آن، که ممکن است باعث شود به نوعی ارزیابی اعتبار جمع سپاری با پتانسیل بالا برای انتخاب و قضاوت [ 23 ، 60 ] افزایش یابد.].
4.2. دامنه فضایی و خط مشی زبان
موضوع دومی که در پیادهسازی یک سیستم یکپارچه یخچالشناسی باید به آن پرداخته شود، مربوط به انتخاب حوزه فضایی برای جمعآوری و بازیابی دادهها، و در ارتباط نزدیک با آن، سیاست زبان کل سیستم، از جمله زبان طبیعی برای پرسوجو است.
در حالت ایدهآل، با گسترش بازیابی دادهها به منابع بالقوه اطلاعات یخچالشناسی در سرتاسر جهان، به بهینه میتوان رسید. در واقع، عملی کردن این هدف ایدهآل بیشتر به یک مشکل تبدیل میشود. اولاً، برای مدیریت اصطلاحات و مفاهیمی که از جوامع جغرافیایی مختلف میآیند، به ابزارهای خزنده متمرکزی نیاز دارد که بتوانند با هر زبان و اصطلاحنامهای ارتباط برقرار کنند. ثانیاً، مشاوره توسط کاربران چنین مجموعه دادههای چندزبانه به شدت به زبانهایی که کاربر میداند بستگی دارد، و بنابراین انتخاب زبان میتواند به طور جدی با مشکل مواجه شود. حتی با فرض استفاده از بازیابی اطلاعات بین زبانی، سطح قابل فهم بودن و در نتیجه درک اطلاعات دچار افت اجتناب ناپذیر و غیرقابل سنجش خواهد شد.
ثالثاً، بازیابی داده های یخبندان آلپ اروپایی از همه منابع جهان در مقایسه با مقدار محدود و حاملگی داده های بازیابی شده، مستلزم تلاش قابل توجهی است.
جایگزین شامل پذیرش یک یا چند زبان رسمی (به عنوان مثال، انگلیسی، ایتالیایی، فرانسوی)، و محدود کردن منابع برای خزیدن داده ها بر اساس معیارهای اداری، جغرافیایی یا موضوعی (به عنوان مثال، اروپا، منطقه آلپ، و غیره ) است.
این سناریو شامل مسائل دیگری نیز می شود که نیاز به ارزیابی دارند. هنگام پذیرش یک زبان رسمی، باید چندین معیار مانند سهولت پرس و جو، به حداکثر رساندن به ثمر رساندن اطلاعات توسط کاربران بالقوه، حداکثر کردن سهولت برای ایجاد اطلاعات با کیفیت بالا را در نظر گرفت. همه این معیارها می توانند انتخاب های متمایزی را تعیین کنند که می توانند با یکدیگر در تضاد باشند.
4.3. حفاظت از داده ها، حق چاپ و حقوق مرتبط
مشکل حفاظت از داده های شخصی به طور قابل توجهی با ظهور وب 2.0، انتشار دستگاه های ارتباطی شخصی موبایل (MPCD) و افزایش تعداد برنامه های کاربردی برای اشتراک گذاری مطالب چندرسانه ای آنلاین جمع آوری شده توسط کاربران وب (آلبوم های وب مانند Flickr، Panoramio) به وجود می آید. ؛ پلتفرم های نقشه برداری مشترک مانند Google Earth و Google Maps؛ سایت های اشتراک گذاری ویدیو مانند یوتیوب؛ شبکه های اجتماعی مانند فیس بوک، مای اسپیس و غیره ). این فناوریها همچنین مسائل مربوط به مدیریت حفاظت از حریم خصوصی را تقویت کردهاند و از یک طرف منجر به درخواست دستورالعملهای جوامع علمی و حرفهای میشوند [ 61 ]]، و از طرف دیگر، ادعاها و اقدامات قانونی انجام شده توسط آسیب دیدگان (نمونه معروف تعداد اعتراضات و اصلاحات بعدی است که توسط فعالیت های تصویربرداری گوگل برای برنامه نمای خیابان آن معرفی شده است). مشاهدات، داوطلبانه یا تصادفی، بهویژه زمانی که توسط MPCD جمعآوری میشوند، میتوانند حاوی اطلاعات خصوصی باشند، در حالی که ردیابی مکانهای کاربر و دانش اطلاعات شخصی وی، یا دادههای مربوط به مکانها یا موضوعات مورد سنجش را ایجاد میکنند، که نیاز به راه حل های حفاظت از داده ها [ 62 ].
سیستم پیشنهادی ما میتواند با مسائل حفاظت از دادههای شخصی در سه مورد مختلف دادههای رسمی، داوطلبانه و اتفاقی مقابله کند.
راهحلی برای دادههای داوطلبانه که مستقیماً در پلتفرم وارد میشوند، علامت یک فرم رضایت آگاهانه (همچنین به طور ضمنی ساخته شده است) است. این راه حل نه برای داده های رسمی و اتفاقی متعلق به سایر منابع اطلاعاتی اعمال می شود و نه در برابر خطر انتشار اطلاعات خصوصی یا غیر افشایی (اثر “دود دست دوم” در [ 63 ]).
برای کاهش خطر انتشار تصادفی محتویات خصوصی یا محدود، برخی از نویسندگان الگوریتمهایی را برای بینام کردن مشارکتها [ 64 ] و همچنین برای تنزل رتبه یا فیلتر کردن اطلاعات شخصی اعمال کردند [ 46 ، 65 ]. با این حال، چنین راه حل های احتیاطی عوارض جانبی برای جلوگیری از مشارکت و نادیده گرفتن ویژگی های فکری مشارکت کنندگان دارد.
یکی از موانع اصلی هنگام برخورد با حفاظت از حریم خصوصی در مورد دادههای اتفاقی این است که برخلاف دادههای رسمی، ابردادههای ضبط شده و زمینه مشاهده اغلب فاقد، کاملاً ناقص، نامشخص یا در قالبی هستند که پردازش آنها دشوار است. (پیوند به سایر محتوای وب، نام مستعار، برچسب ها و غیره ).
همین مشکلات بر بازیابی اطلاعات حق چاپ در مورد داده ها تأثیر می گذارد. چنین اطلاعاتی در قالب های بسیار متفاوت توسط وب سایت ها، انجمن ها، گالری های وب و هر برنامه وب دیگری که به داده ها دسترسی دارد ارائه می شود. پیوندهای آبشاری و ارجاعات متقابل از طریق صفحات وب، ردیابی اطلاعات اصلی حق چاپ را بسیار دشوار می کند، که به راحتی می تواند از بین برود. سیستم باید این مشکل را با بازیابی محدودیت های داده بر روی وب سایت های مبدأ (سایت های موضوعی، کاتالوگ ها، انجمن ها، آلبوم های وب و غیره ) و سپس با رعایت سیاست های داده ای که در منبع وب تعیین شده است، برطرف کند.
در واقع، موانعی که در بازیابی و تفسیر صحیح محدودیتهای مربوط به دادهها به وجود میآیند، میتواند مانعی برای پیشنهاد انتخاب منابع دادهای باشد که بر اساس سیاستهای توزیع وبسایتها حاکم است.
مدیریت حقوق مالکیت معنوی (IPR) یکی دیگر از موضوعات حساس در پروژه هایی است که در آن به اشتراک گذاری داده ها و دانش علمی مورد توجه قرار می گیرد. چندین تجربه ثابت کردهاند که اشتراکگذاری دادههای علمی در وب میتواند بدون تحقیر IPR مدیریت شود و در عوض، میتواند آن را تقویت کند و به نفع نویسندگان یا گروههایی باشد که مشارکت دارند.
به عنوان مثال، در پروژه هایی مانند EnvEurope [ 66 ]، یا در موسسات تحقیقاتی مانند NERC [ 67 ]، سیاست هایی برای اشتراک گذاری داده ها تنظیم شده است که از یک طرف، نویسندگان را متعهد می کند که داده های خود را به صورت عمومی به اشتراک بگذارند، و از طرف دیگر، از کاربران میخواهد که اعتبارات را ذکر کنند و امکاناتی را برای نویسندگان ارائه دهند تا به پروژههای مرتبط بپیوندند. به این ترتیب، نویسندگان تشویق می شوند تا داوطلبانه داده ها را در بستر وب به اشتراک بگذارند.
در سیستم یکپارچه یخچالشناسی، به مشارکتکنندگان داوطلب پیشنهاد داده میشود که از بین سیاستهای (یا مجوزها) استفاده از دادههای مختلف انتخاب کنند تا با مشارکت خودشان مرتبط باشند. نمونههایی از این رویکرد وجود دارد: در FLUXNET [ 68 ]، نویسندگان میتوانند از میان سه خطمشی استفاده از دادههای مختلف انتخاب کنند: (1) دسترسی محفوظ به مشارکتکنندگان (به عنوان LaThuile)؛ (ii) دسترسی بر اساس پیشنهادات علمی (داده های باز). (iii) آزادانه توزیع شده (استفاده منصفانه رایگان).
لازم به یادآوری است که حفاظت از حقوق مالکیت معنوی یک موضوع قانونی است که در هر کشور به طور متفاوتی تنظیم می شود. به هر حال این سیستم بنا به تعریف فراملیتی است، هم بر اساس موجودیت جغرافیایی – آلپ – که از کشورهای مختلف عبور می کند و هم بر اساس مکان اطلاعات جمع آوری شده چنین موجودات جغرافیایی که در شبکه جهانی وب پراکنده شده اند.
دستورالعمل های مرجع در این مورد می تواند آنهایی باشد که توسط سازمان جهانی مالکیت معنوی (WIPO) معرفی شده است، که احتمالاً توسط قوانین اروپایی در مورد حق چاپ و حقوق مرتبط (به ویژه توسط [ 69 ، 70 ، 71 ]) اصلاح شده است.
4.4. استراتژی های مشارکت
این سیستم می تواند به عنوان یک کاتالیزور در ترویج مشارکت و تقویت اشتراک دانش عمل کند. برای تحقق این امر، سیستم باید بر اساس سه دیدگاه ظاهر، کیفیت و کمیت به صورت استراتژیک طراحی شود.
ظاهر رابط های کاربری گرافیکی هم برای ایجاد اطلاعات توسط داوطلبان و هم برای کشف بازدیدکنندگان برای استفاده از آن بسیار مهم است. این باید از همان نگاه اول ارتباط و اعتبار علمی ارتباط برقرار کند. این نیاز باید با یک رابط کاربر پسند وجود داشته باشد که نه کاربران بالقوه را بترساند و نه مشارکت کنندگان بالقوه را دلسرد کند. تنظیمات صفحه باید به بازدیدکنندگان کمک کند تا تمام اطلاعات لازم برای درک عمیقتر محتوا را بیابند و در عین حال از ارائه اطلاعات ناخواسته به کاربران سبک خودداری کنند.
برای ایجاد احساس راحتی در کاربر، رابط کاربری گرافیکی شناخته شده، مانند سایت های محبوب ترین نقشه های وب (Google maps، Google Earth و غیره ) وجود دارد.) می تواند اتخاذ شود. حتی ساختار داده باید از تعادل بین معیارهای کامل بودن، خوانایی و قابلیت استفاده ناشی شود. روش ورود داده ها (تعداد الزامات در روش ورود داده ها) باید انعطاف پذیر باشد تا به بهترین شکل با مهارت ها، نیازها و اهداف مشارکت کنندگان سازگار شود. فرمهای وب موقتی را میتوان برای ارائه پشتیبانی در مرحله کامپایل استفاده کرد، مشارکتکنندگان را به وارد کردن دادههای دقیق و خوانا هدایت میکند و اصطلاحات استاندارد را از یک واژگان مشترک به آنها پیشنهاد میکند. برای این منظور می توان از چک لیست ها، منوهای چند گزینه ای و فیلدهای اختیاری استفاده کرد. ابزارهای خودارزیابی می توانند با نشان دادن درجه قابلیت اطمینان مشارکت وارد شده و اعلام سطح اطمینان خود به ارائه دهندگان کمک کنند.
علاوه بر این، برخی از تجربیات و نظریههای علوم اجتماعی نشان میدهند که نشان دادن دیدگاههای بیرونی نویسندگان درباره ارزش مشارکت آنها میتواند مشارکت را تشویق کند [ 72 ].
با راهحلهای متعدد، میتوان بر اهمیت مشارکتهای داوطلبانه در موفقیت پروژه تأکید کرد و از رضایتبخش بودن تجربه مشارکتکنندگان اطمینان حاصل کرد. به عنوان مثال، با اطلاع رسانی منظم به جامعه داوطلبان در مورد دستاوردهای پروژه، یا برجسته کردن مشارکت های مهم، یا استقبال عمومی از ثبت نام داوطلبان جدید.
اقدامات دیگری که به ایجاد انگیزه در داوطلبان کمک می کند، اقداماتی است که به منظور گسترش امکانات تعامل کاربر با پلت فرم وب، به عنوان مثال با اشتراک گذاری محتوا با شبکه های اجتماعی، یا با استفاده از کانال های ارتباطی جایگزین مانند ایمیل، برنامه های کاربردی برای تلفن های هوشمند یا پیامک عمل می کند. (و geoSMS).
سیستم پاداش یکی دیگر از مکانیسم های موثر در حمایت از مشارکت داوطلبان است. کلمن و همکاران [ 43 ]، تجزیه و تحلیل دلایلی که کاربران را به تولید اطلاعات به صورت داوطلبانه سوق می دهد، نشان می دهد که “پاداش اجتماعی” و “شهرت شخصی” از جمله عوامل اصلی تحریک کننده مشارکت هستند. سیستمهای رتبهبندی اجتماعی (شست بالا/پایین، رتبهبندی ستاره و غیره )، رایگیری، ارتقای نقش بر اساس فعالیت کاربر میتواند برای فشار دادن به این عوامل و تشویق مشارکت در پلتفرم استفاده شود.
با توجه به مشارکت کارشناسان و متخصصان بهعنوان داوطلب، میتوان همکاری آنها را – همانطور که قبلاً در پاراگراف قبلی مورد بحث قرار گرفت – با یک سیاست داده تشویق کرد که حقوق مالکیت معنوی را فراهم میکند و کاربران داده را تشویق میکند تا از نویسندگان استناد کنند یا آنها را در پروژههای خود مشارکت دهند. (به عنوان مثال، این چیزی است که در پروژهای مانند EnvEurope [ 66 ] یا FLUXNET [ 73 ] اتفاق میافتد.
5. نتیجه گیری ها
داده های یخبندان شناسی جمع آوری شده در حوزه آلپ اروپا برای پایش و درک تغییرات آب و هوای جهانی و پدیده های مرتبط بسیار مهم است. در واقع، حتی اگر یخچال های طبیعی آلپ اروپایی، مقدار کمی از کل سطح زمین یخ زده سیاره را تشکیل دهند، به دلیل اندازه کوچک آنها، نقش پراکسی های واکنش سریع و شاخص های تغییرات جهانی را بازی می کنند.
علیرغم اهمیت آنها، مجموعه داده های یخبندان شناسی اغلب در مقایسه با ارتباط محیطی آنها کوچک هستند. این بیشتر به دلیل دور بودن مناطق مورد بازرسی و فقدان منابع مالی کافی و استراتژی های مشترک برای نظارت بر یخچال های طبیعی از آلپ به عنوان یک کل است. این امر از طریق تلاشها و سیاستهایی انجام میشود که معمولاً در سطح ملی یا حتی محلی تنظیم میشوند و در نتیجه مجموعههایی ایجاد میشوند که هم از نظر پارامترهای مشاهده شده و هم از نظر پروتکلهای نقشهبرداری متفاوت هستند. این سناریو به دلیل پویایی سریع بدنه های یخچالی پیچیده تر می شود، که به فرکانس بالایی از بررسی ها نیاز دارد که انجام آن دشوار است. این دلایل از لحاظ تاریخی، انجمن های داوطلبانه را همراه با جامعه علمی، بخشی مهم و فعال از صحنه مشاهده و نظارت کرده است.
تکه تکه شدن و ناهمگونی مشاهدات یخبندان شناسی حاصل از این سیستم رصد پراکنده بسیار زیاد است و نیازمند تلاش قوی برای هماهنگ سازی و پیش پردازش به منظور دستیابی به دانش و تجزیه و تحلیل جامع پدیده ها در مقیاس منطقه ای آلپ است.
در این زمینه، طغیان اخیر آگاهی جغرافیایی مشارکتی جدید، که توسط فناوریهای وب 2.0 توانمند شده است، فرصت جمعآوری و مدیریت بسیاری از محتوای جغرافیایی غیررسمی را از منابع مختلف ارائه میکند.
در این کار، ما سیستمی برای مدیریت اطلاعات چندمنبعی و ناهمگن برای سازماندهی و تجمیع مجموعههای دادههای سنتی یخچالشناسی و مشاهدات ارائهشده توسط منابع جایگزین، خارج از قلمرو علمی، که در وب پراکنده هستند و در حال حاضر استفاده نمیشوند، پیشنهاد کردیم.
برای این هدف، ما ابتدا منابع داده های مختلف مفید برای تحقیقات و نظارت بر یخبندان را بر اساس تخصص، قصد و پاداش شناسایی و دسته بندی کرده ایم. این منجر به طبقهبندی دادههای یخچالشناسی بهعنوان رسمی (متخصص، عمدی و با پاداش)، داوطلبانه (عمدی اما بدون پاداش) یا اتفاقی (چه غیرعمدی یا غیر کارشناسی، عمدی و با پاداش) شد.
پس از آن، ما یک گردش کار را تعریف کردیم که در آن راهحلهای روششناختی و فناوری برای شناسایی و مدیریت دادههای یخبندانشناسی، چند منبعی و ناهمگن پیشنهاد میشوند.
در این مرحله از تحقیق، برخی از اجزای سیستم توصیف شده طراحی شده و در دست توسعه است. در میان آنها یک روزنامه جغرافیایی-یخچال شناسی، یک پایگاه دانش برای خزیدن تمرکز، و یک متریک نمایه سازی کیفیت وجود دارد. یک سیستم نمونه اولیه برای آزمایش، مشاهده و استفاده از پرس و جو برای اطلاعات داوطلبانه و اتفاقی، محدود به سه یخچال طبیعی آزمایشی آلپاین راه اندازی شده است. اهداف آتی تکمیل قطعات و مونتاژ نهایی در یک سیستم جامع خواهد بود.
مشارکتهای اتفاقی، که عمدتاً تاکنون مورد بهرهبرداری قرار نگرفتهاند، میتوانند اطلاعات جدیدی را ارائه دهند که در غیر این صورت پنهان و ناشناخته باقی میمانند و میتوانند با مقایسه و تجزیه و تحلیل بین این دادهها به چالشهای جدیدی در تحقیق منجر شوند و موارد سنتی میتوانند زمینههای کاربردی جدیدی را با تقاطع بین این دادهها معرفی کنند. رشته های مختلف: علوم طبیعی، علوم کامپیوتر و علوم اجتماعی.
استفاده از یک سیستم یکپارچه، به عنوان یک کانال مطلوب برای ورود و دسترسی به دادهها، میتواند فرصتی را برای ایجاد یک شبکه مشترک برای تقویت جوامع موجود و برای مشارکت افراد جدید با نقش داوطلبان، هماهنگکنندگان و یا ایجاد کند. ارائه دهندگان
مزایای دیگری را می توان از انتشار و انتشار اطلاعات علمی به دست آورد که می تواند از راه های اصلی و سفارشی پخش شود تا در سطوح مختلف ارتباطی، هم به جامعه متخصصان این حوزه و هم به افراد غیرمتخصص علاقه مند دسترسی پیدا کند. ، علاوه بر نمایندگان سازمان های دولتی و خصوصی، آگاهی خود را بهبود می بخشند.
برای نتیجهگیری، اصالت اصلی پیشنهاد نشان دادن روشی برای ادغام دادههای یخبندانشناسی متخصص و داوطلبانه سنتی با دادههای یخچالشناسی استخراجشده بهطور خودکار از منابع تصادفی است، تا با کمبود مکانی-زمانی اطلاعات در مورد یخچالهای آلپ مقابله شود.
این کار همچنین راهحلهایی را برای مسائل مهم مانند کیفیت/قابلیت اطمینان دادهها، ویژگیهای فضایی و زبانی، حفاظت و حق چاپ و مشارکت کاربران وب مورد بحث و پیشنهاد قرار میدهد.
منابع
- لمکه، پ. رن، جی. کوچه، RB; آلیسون، آی. کاراسکو، جی. فلاتو، جی. فوجی، ی. کاسر، جی. موته، پ. توماس، RH; و همکاران مشاهدات: تغییرات در برف، یخ و زمین یخ زده. در تغییرات آب و هوایی 2007: پایه علوم فیزیکی. مشارکت گروه کاری I در گزارش ارزیابی چهارم هیئت بین دولتی در مورد تغییرات آب و هوایی . Solomon, S., Qin, D., Manning, M., Chen, Z., Marquis, M., Averyt, KB, Tignor, M., Miller, HL, Eds.; انتشارات دانشگاه کمبریج: نیویورک، نیویورک، ایالات متحده آمریکا، 2007; صص 338-383. [ Google Scholar ]
- برنامه زیست محیطی سازمان ملل. تغییرات جهانی یخچال: حقایق و ارقام. در دسترس آنلاین: http://www.grid.unep.ch/glaciers/ (دسترسی در 30 آوریل 2013).
- هابرلی، دبلیو. هولزل، ام. پل، اف. زمپ، ام. پایش یکپارچه یخچال های طبیعی کوهستانی به عنوان شاخص های کلیدی تغییرات آب و هوایی جهانی: آلپ های اروپایی. ان گلاسیول. 2007 ، 46 ، 150-160. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- بریثویت، تعادل جرمی یخچال های طبیعی RJ: 50 سال اول نظارت بین المللی. برنامه فیزیک Geogr. 2002 ، 26 ، 76-95. [ Google Scholar ] [ CrossRef ]
- پل، اف. کاب، ع. مایش، ام. کلنبرگر، تی. Haeberli، W. تجزیه سریع یخچالهای طبیعی آلپ با داده های ماهواره ای مشاهده شد. ژئوفیز. Res. Lett. 2004 ، 31 . [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- هابرلی، دبلیو. Beniston، M. تغییر آب و هوا و تأثیرات آن بر یخچالهای طبیعی و منجمد دائمی در کوههای آلپ. Ambio 1998 ، 27 ، 258-265. [ Google Scholar ]
- زمپ، م. هابرلی، دبلیو. هولزل، ام. پل، اف. یخچال های طبیعی آلپ تا چند دهه ناپدید می شوند؟ ژئوفیز. Res. Lett. 2006 ، 33 . [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- پل، اف. کاب، ع. Haeberli، W. تغییرات اخیر یخچال های طبیعی در کوه های آلپ مشاهده شده توسط ماهواره: پیامدها برای استراتژی های نظارت آینده. سیاره جهانی. تغییر 2007 ، 56 ، 111-122. [ Google Scholar ] [ CrossRef ]
- Parr، TW; فرتی، م. سیمپسون، آی سی; فورسیوس، م. Kovács-Láng، E. به سوی یک برنامه نظارتی یکپارچه بلند مدت در اروپا: طراحی شبکه در تئوری و عمل. محیط زیست نظارت کنید. ارزیابی کنید. 2002 ، 78 ، 253-290. [ Google Scholar ] [ CrossRef ]
- Bruns، A. Toward Produsage: Futures for User-Led Content Production. در مجموعه مقالات نگرش های فرهنگی نسبت به ارتباطات و فناوری، تارتو، استونی، 28 ژوئن تا 1 ژوئیه 2006.
- ترنر، الف. مقدمه ای بر جغرافیای جدید . رسانه O’Really: سباستوپل، کالیفرنیا، ایالات متحده آمریکا، 2006. [ Google Scholar ]
- هیپک، سی. دادههای جغرافیایی جمعسپاری. ISPRS J. Photogramm. 2010 ، 65 ، 550-557. [ Google Scholar ] [ CrossRef ]
- شبکه اشتراکی باران، تگرگ و برف. در دسترس آنلاین: http://www.cocorahs.org/ (دسترسی در 30 آوریل 2013).
- پروژه آلپ آمریکا. در دسترس آنلاین: http://alpineamericas.com/ (در 30 آوریل 2013 قابل دسترسی است).
- Applicazione Experimentale per la Raccolta di Informazioni Legate Alla Condizioni di Innevamento در Piemonte. در دسترس آنلاین: http://remotesensing.arpa.piemonte.it/neve/ (در 30 آوریل 2013 قابل دسترسی است).
- SnowALP. در دسترس آنلاین: http://www.arpa.vda.it/ (دسترسی در 30 آوریل 2013).
- Ghiacciai di un Volta. در دسترس آنلاین: http://www.ghiacciaidiunavolta.it/ (در 30 آوریل 2013 قابل دسترسی است).
- هاکلی، م. سینگلتون، ا. پارکر، سی. نقشه برداری وب 2.0: جغرافیای جدید ژئو وب. Geogr. Compass 2008 , 22 , 2011-2039. [ Google Scholar ] [ CrossRef ]
- Cohn، JP Citizen Science: آیا داوطلبان می توانند تحقیقات واقعی انجام دهند؟ BioScience 2008 ، 58 ، 192-197. [ Google Scholar ] [ CrossRef ]
- سیلورتاون، جی. طلوع جدیدی برای علم شهروندی. Trend Ecol. Evolut. 2009 ، 24 ، 467-471. [ Google Scholar ] [ CrossRef ]
- Goodchild، MF Citizens به عنوان حسگر: دنیای جغرافیای داوطلبانه. ژئوژورنال 2007 ، 69 ، 211-221. [ Google Scholar ] [ CrossRef ]
- پارلمان اروپا و شورای اتحادیه اروپا دستورالعمل 2007/2/EC پارلمان اروپا و شورای 14 مارس 2007 مبنی بر ایجاد زیرساختی برای اطلاعات مکانی در جامعه اروپا (INSPIRE). دفتر. J. Eur. اتحادیه 2007 ، 108 ، 1-14.
- Flanagin، AJ; Metzger, MJ اعتبار اطلاعات جغرافیایی داوطلبانه. جئوژورنال 2008 ، 72 ، 137-148. [ Google Scholar ] [ CrossRef ]
- اسپسیا، ال. موتا، ای. ادغام فولکسونومی با وب معنایی. در وب معنایی: تحقیقات و کاربردها ; Franconi, E., Kifer, M., May, W., Eds.; Springer: برلین/هایدلبرگ، آلمان، 2007; صص 624-639. [ Google Scholar ]
- اوسترمن، اف. Spinsanti، L. یک گردش کار مفهومی برای ارزیابی خودکار کیفیت اطلاعات جغرافیایی داوطلبانه برای مدیریت بحران. در مجموعه مقالات چهاردهمین کنفرانس بین المللی AGILE در علم اطلاعات جغرافیایی، اوترخت، هلند، 18-21 آوریل 2011.
- اسمولدرز، AWM; نگران، م. سانتینی، اس. گوپتا، ا. جین، آر. بازیابی تصویر مبتنی بر محتوا در پایان سالهای اولیه. IEEE Trans. پت مقعدی ماخ بین المللی 2000 ، 22 ، 1349-1380. [ Google Scholar ] [ CrossRef ]
- Wood, J. توصیف مکان از طریق محتوای تولید شده توسط کاربر. در دسترس آنلاین: http://firstmonday.org/ojs/index.php/fm/article/view/3710/3035 (در 30 آوریل 2013 قابل دسترسی است).
- کسلر، سی. مائوئه، پی. هیور، جی. Bartoschek, T. Bottom-Up Gazetteers: یادگیری از معناشناسی ضمنی برچسب های جغرافیایی. در Semantics GeoSpatial SE-6 ; Janowicz, K., Raubal, M., Levashkin, S., Eds. Springer: برلین/هایدلبرگ، آلمان، 2009; صص 83-102. [ Google Scholar ]
- MacEachren، AM; رابینسون، AC; جیسوال، ا. پزانوفسکی، اس. ساولیف، آ. بلانفورد، جی. Mitra, P. Geo-Twitter Analytics: Applications in Crisis Management. در مجموعه مقالات بیست و پنجمین کنفرانس بین المللی کارتوگرافی، پاریس، فرانسه، 3 تا 8 ژوئیه 2011.
- بوردوگنا، جی. کریسکوئولو، ال. کارارا، پی. پپه، ام. رویکرد تصمیم گیری زبانی برای ارزیابی کیفیت اطلاعات جغرافیایی داوطلبانه برای علم شهروندی. به اطلاع رساندن. علوم 2013 ، در دست چاپ. [ Google Scholar ]
- باتینی، سی. Scannapieco, M. کیفیت داده ها: مفاهیم، روش ها و تکنیک ها . Springer: برلین، آلمان، 2006. [ Google Scholar ]
- Moellering, H. A Draft Proposed Standard for Digital Cartographic Data ; کمیته ملی استانداردهای داده های کارتوگرافی دیجیتال: کلمبوس، OH، ایالات متحده آمریکا، 1987. [ Google Scholar ]
- کریسمن، NR مسائل و مشکلات مربوط به استفاده، تبادل و انتقال داده های نقشه برداری: نقش اطلاعات با کیفیت در عملکرد بلند مدت یک سیستم اطلاعات جغرافیایی. Cartographica 1984 , 21 , 79-88. [ Google Scholar ] [ CrossRef ]
- پوپسکو، آ. گرفنستت، جی. بوامور، اچ. استخراج یک روزنامه جغرافیایی چند زبانه از وب. در مجموعه مقالات کنفرانس مشترک بین المللی IEEE/WIC/ACM در زمینه هوش وب و فناوری عامل هوشمند، میلان، ایتالیا، 15 تا 18 سپتامبر 2009.
- کوهن، دبلیو. هستی شناسی در حمایت از فعالیت ها در فضای جغرافیایی. بین المللی جی. جئوگر. Inf. علمی 2001 ، 15 ، 613-631. [ Google Scholar ] [ CrossRef ]
- گالووی، AWE; تودور، MT; هیگن، دبلیو. واندر، ام. قابلیت اطمینان علم شهروندی: مطالعه موردی بررسیهای پایه بلوط سفید اورگان. انجمن حیات وحش گاو نر 2006 ، 34 ، 1425-1429. [ Google Scholar ] [ CrossRef ]
- پروژه eBird. در دسترس آنلاین: http://ebird.org/content/ebird/ (دسترسی در 30 آوریل 2013).
- ساعت تغذیه پروژه. در دسترس آنلاین: http://www.birds.cornell.edu/pfw/ (دسترسی در 30 آوریل 2013).
- دیکینسون، جی ال. زاکربرگ، بی. Bonter، DN Citizen Science به عنوان یک ابزار تحقیقاتی زیستمحیطی: چالشها و مزایا. آنو. کشیش اکول. تکامل. سیستم 2010 ، 41 ، 149-172. [ Google Scholar ] [ CrossRef ]
- Hovland، CI; ایروینگ، ال جی. هارولد، ارتباطات و ترغیب هنگ کنگ: مطالعات روانشناختی تغییر عقیده . انتشارات دانشگاه ییل: نیوهیون، CT، ایالات متحده آمریکا، 1953. [ Google Scholar ]
- Metzger، MJ ایجاد حس اعتبار در وب: مدل هایی برای ارزیابی اطلاعات آنلاین و توصیه برای تحقیقات آینده. مربا. Soc. Inf. علمی تکنولوژی 2007 ، 58 ، 2078-2091. [ Google Scholar ] [ CrossRef ]
- آیزنباخ، جی. Köhler, C. چگونه مصرف کنندگان اطلاعات بهداشتی را در شبکه جهانی وب جستجو و ارزیابی می کنند؟ مطالعه کیفی با استفاده از گروه های متمرکز، آزمون های قابلیت استفاده و مصاحبه های عمیق. بریتانیایی پزشکی J. 2002 , 324 , 573-577. [ Google Scholar ] [ CrossRef ]
- کلمن، دی جی; جورجیادو، ی. Labonte, J. اطلاعات جغرافیایی داوطلبانه: ماهیت و انگیزه تولیدکنندگان. بین المللی J. Spat Data Infrastr. Res. 2009 ، 4 ، 332-358. [ Google Scholar ]
- Van Dijck, J. کاربرانی مثل شما؟ آژانس نظریه پردازی در محتوای تولید شده توسط کاربر. فرقه رسانه. Soc. 2009 ، 31 ، 41-58. [ Google Scholar ] [ CrossRef ]
- هوانگ، KL; Kanhere, SS; هو، دبلیو. آیا داده های قابل اعتمادی را ارائه می کنید؟ موردی برای سیستم شهرت در سنجش مشارکتی. در مجموعه مقالات سیزدهمین کنفرانس بین المللی ACM در مورد مدل سازی، تحلیل و شبیه سازی سیستم های بی سیم و سیار، بدروم، ترکیه، 17 تا 21 اکتبر 2010.
- ردی، اس. شیلتون، ک. بورک، جی. استرین، دی. هانسن، ام. Srivastava، M. ارزیابی مشارکت و عملکرد در حس مشارکتی. در مجموعه مقالات کارگاه بین المللی در مورد کاربردهای شهری، اجتماعی و اجتماعی سیستم های سنجش شبکه، رالی، NC، ایالات متحده آمریکا، 4 نوامبر 2008.
- دی لونگویل، بی. لوراشی، جی; اسمیتز، پی. پیدل، اس. de Groeve, T. شهروندان به عنوان حسگرهای خطرات طبیعی: گردش کار یکپارچه سازی VGI. Geomatica 2010 ، 64 ، 355-363. [ Google Scholar ]
- دی سولا، اس آر. Shirose, LJ; فرنی، کی جی؛ بارت، جی سی; Brousseau، CS; بیشاپ، کالیفرنیا اثرات تلاشهای نمونهبرداری و قابلیت شناسایی گونهها بر برنامههای نظارت بر آنوران داوطلبانه. Biol. حفظ کنید. 2005 ، 121 ، 585-594. [ Google Scholar ] [ CrossRef ]
- ژنت، KS; سارجنت، الجی ارزیابی روشها و کیفیت دادهها از نظرسنجی فراخوانی دوزیستان مبتنی بر داوطلب. انجمن حیات وحش گاو نر 2003 ، 31 ، 703-714. [ Google Scholar ]
- لوتز، آ. سوگیری آلن، CR Observer در نظرسنجی های فراخوانی anuran. جی. مدیریت حیات وحش. 2007 ، 71 ، 675-679. [ Google Scholar ] [ CrossRef ]
- فیتزپاتریک، ام سی؛ پریسر، EL; الیسون، AM; Elkinton، تعصب JS Observer و تشخیص جمعیت های کم تراکم. Ecol. Appl. 2009 ، 19 ، 1673-1679. [ Google Scholar ] [ CrossRef ]
- دیلینی، دی جی؛ اسپرلینگ، سی دی; آدامز، CS; Leung، B. گونه های مهاجم دریایی: اعتبار سنجی علم شهروندی و پیامدهای آن برای شبکه های نظارت ملی. Biol. Invasions 2007 , 10 , 117-128. [ Google Scholar ]
- آنتونیو، بی. مورلی، جی. Haklay, M. Web 2.0 عکس های دارای برچسب جغرافیایی: ارزیابی بعد فضایی پدیده. Geomatica 2010 ، 64 ، 99-110. [ Google Scholar ]
- فریدلند، جی. چوی، جی. محاسبات معنایی و حریم خصوصی: مطالعه موردی با استفاده از موقعیت جغرافیایی استنباط شده. بین المللی ج. سمنت. محاسبه کنید. 2011 ، 5 ، 79-93. [ Google Scholar ] [ CrossRef ]
- فیشر، ف. شهروند، کارشناسان و محیط زیست: سیاست دانش محلی . انتشارات دانشگاه دوک: دورهام، NC، ایالات متحده آمریکا، 2000. [ Google Scholar ]
- Haklay, M. اطلاعات جغرافیایی داوطلبانه چقدر خوب است؟ مطالعه تطبیقی مجموعه داده های نظرسنجی OpenStreetMap و مهمات. محیط زیست طرح. B-Plan Design 2010 , 37 , 682-703. [ Google Scholar ] [ CrossRef ]
- گیرس، جی اف. Touya, G. ارزیابی کیفیت مجموعه داده OpenStreetMap فرانسه. ترانس. GIS 2010 ، 14 ، 435-459. [ Google Scholar ] [ CrossRef ]
- سیپلوچ، بی. یعقوب، ر. وینستانلی، ا. Mooney, P. مقایسه دقت OpenStreetMap برای ایرلند با Google Maps و Bing Maps. در مجموعه مقالات نهمین سمپوزیوم بین المللی ارزیابی دقت فضایی در منابع طبیعی و علوم محیطی، لستر، بریتانیا، 20 تا 23 ژوئیه 2010.
- Goodchild، MF Citizens به عنوان حسگرهای داوطلبانه: زیرساخت داده های مکانی در دنیای وب 2.0. بین المللی جی. اسپات. Data Infrastr. Res. 2007 ، 2 ، 24-32. [ Google Scholar ]
- کانرز، جی پی؛ لی، اس. کلی، ام. علم شهروندی در عصر نئوجغرافی: استفاده از اطلاعات جغرافیایی داوطلبانه برای نظارت بر محیط زیست. ان Assn. عامر Geogr. 2012 ، 102 ، 1267-1289. [ Google Scholar ] [ CrossRef ]
- الوود، اس. Goodchild، MF; سوئی، دی. ان Assn. عامر Geogr. 2012 ، 102 ، 571-590. [ Google Scholar ] [ CrossRef ]
- فرستر، سی جی; Coops، NC مروری بر رصد زمین با استفاده از دستگاه های ارتباطی شخصی سیار. محاسبه کنید. Geosci. 2013 ، 51 ، 339-349. [ Google Scholar ] [ CrossRef ]
- لین، ن. میلوزو، ای. لو، اچ. پیبلز، دی. چودوری، تی. کمپبل، ای. بررسی سنجش تلفن همراه. IEEE Commun. Mag. 2010 ، 48 ، 140-150. [ Google Scholar ]
- دی کریستوفارو، ای. Soriente، C. PEPSI: زیرساخت سنجش مشارکتی ارتقا یافته با حریم خصوصی. در مجموعه مقالات چهارمین کنفرانس ACM در مورد امنیت شبکه بی سیم ACM، هامبورگ، آلمان، 14 تا 17 ژوئن 2011.
- گانتی، RK; فام، ن. Tsai، YE; عبدالظاهر، TF Pool View: حریم خصوصی جریان برای سنجش مشارکتی مردمی. در مجموعه مقالات ششمین کنفرانس ACM در مورد سیستم حسگر شبکه جاسازی شده، رالی، NC، ایالات متحده، 4 تا 7 نوامبر 2008.
- پروژه EnvEurope. در دسترس آنلاین: http://www.enveurope.eu/ (دسترسی در 30 آوریل 2013).
- خط مشی داده NERC – یادداشت های راهنمایی. در دسترس آنلاین: http://www.nerc.ac.uk/research/sites/data/documents/datapolicy-guidance.pdf (دسترسی در 30 آوریل 2013).
- LATHUILE FLUXNET DATA – خط مشی داده و شرایط مرجع. در دسترس آنلاین: http://fluxnet.ornl.gov/sites/default/files/Policy_LaThuile_Final.pdf (دسترسی در 30 آوریل 2013).
- پارلمان اروپا و شورای اتحادیه اروپا دستورالعمل 95/46/EC پارلمان اروپا و شورای اروپا در 24 اکتبر 1995 در مورد حمایت از افراد در مورد پردازش داده های شخصی و در مورد جابجایی آزادانه این داده ها. دفتر. J. Eur. اتحادیه L 1995 ، 281 ، 31-50.
- پارلمان اروپا و شورای اتحادیه اروپا دستورالعمل 2002/58/EC پارلمان اروپا و شورای 12 ژوئیه 2002 در مورد پردازش داده های شخصی و حفاظت از حریم خصوصی در بخش ارتباطات الکترونیکی. دفتر. J. Eur. اتحادیه L 2002 ، 201 ، 37-47.
- پارلمان اروپا و شورای اتحادیه اروپا دستورالعمل 2001/29/EC پارلمان اروپا و شورای 22 مه 2001 در مورد هماهنگی برخی از جنبه های حق چاپ و حقوق مرتبط در جامعه اطلاعاتی. دفتر. J. Eur. Union L 2001 , 167 , 10-19.
- رشید، ع.م. لینگ، ک. Tassone، RD; رسنیک، پی. کرات، آر. ریدل، جی. مشارکت انگیزشی با نمایش ارزش مشارکت. در مجموعه مقالات کنفرانس SIGCHI در مورد عوامل انسانی در سیستم های محاسباتی، مونترال، QC، کانادا، 22-27 آوریل 2006.
- بالدوکی، دی. فالج، ای. گو، ال. اولسون، آر. هالینگر، دی. دویدن، اس. آنتونی، پ. برنهوفر، سی. دیویس، ک. ایوانز، آر. و همکاران FLUXNET: ابزاری جدید برای مطالعه تغییرپذیری زمانی و مکانی دی اکسید کربن در مقیاس اکوسیستم، بخار آب و چگالی شار انرژی. گاو نر عامر هواشناسی Soc. 2001 ، 82 ، 2415-2434. [ Google Scholar ] [ CrossRef ]
© 2013 توسط نویسندگان; دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (http://creativecommons.org/licenses/by/3.0/) توزیع شده است.
بدون نظر