1. مقدمه
بر اساس گزارش سازمان جهانی بهداشت، سالانه 600000 نفر در تصادفات رانندگی جان خود را از دست می دهند و 15 میلیون نفر مجروح می شوند . طبق گزارش وزارت حمل و نقل ایالات متحده (USDOT)، تصادفات وسایل نقلیه موتوری علت اصلی مرگ و میر افراد 1 تا 33 ساله است. خسارات اقتصادی اجتماعی ناشی از این تصادفات بسیار زیاد است، طبق برآورد اداره ملی ایمنی ترافیک بزرگراه ها در سال 2000 بیش از 230 میلیارد دلار برآورد شده است. 2 ]. در اسرائیل، تعداد تلفات ناشی از تصادفات رانندگی بیشتر از تعداد کل تلفات در تمام جنگهای اسرائیل است [ 3 ].
تصادفات جاده ای و پراکندگی فضایی آنها، از جمله مدل های شمارش و تخمین احتمال، توجه تحقیقاتی فزاینده ای را در دهه های اخیر به خود جلب کرده است. این امر به دلیل هزینه زیاد و اهمیت آنها برای جامعه از نظر جسمی، روحی و اقتصادی است. بسیاری از مطالعات عوامل مختلفی را در تصادفات جاده ای بررسی کرده اند تا متغیرهای توضیحی را از زمینه های مختلف فرموله کنند: ناوگان وسایل نقلیه (توزیع ناوگان بر اساس طبقه بندی و سن). مسیرها (طول جاده؛ توزیع طول بر اساس طبقات جاده)؛ قرار گرفتن در معرض (کیلومتر، کیلومتر بر اساس طبقات جاده، کیلومتر طی شده توسط کاربران جاده، مسافت پیموده شده مسافران بر اساس شیوه حمل و نقل، کیلومتر مسافت مسافران بر اساس سن و جنسیت، جریان ترافیک بر اساس طبقات جاده).جمعیت (جمعیت بر اساس سن و جنسیت، دارندگان گواهینامه بر اساس سن و جنسیت، درصد رانندگان مبتدی، تراکم)؛ هواشناسی (دما، سطوح بارندگی، نور خورشید، یخ)؛ ایمنی ترافیک (مصرف الکل؛ نرخ بستن کمربند ایمنی؛ سرعت؛ نرخ استفاده از کلاه ایمنی؛ نرخ تجهیزات کیسه هوا؛ محدودیتهای سرعت؛ حداقل سن برای رانندگی؛ مداخلات ایمنی (سیاستهای ایمنی)؛ اقتصاد (درآمد خانوار؛ مصرف خصوصی نهایی خانوار؛ قیمتهای مصرف. دستمزد؛ تولید ناخالص ملی؛ بیکاری؛ تولید صنعتی؛ جمعیت فعال؛ قیمت گاز؛ مصرف گاز؛ اقتصاد و ایمنی ترافیک(هزینه های ملی در مهندسی راه، هزینه های ملی در سرمایه گذاری راه، هزینه های ملی در اقدامات ایمنی راه، هزینه های ملی در پلیس راه). متفرقه (هزینه های تصادفات؛ سطح تحصیلات؛ سطح کیفری؛ خودکشی؛ اعتصابات) [ 1 ، 4 ، 5 ، 6 ، 7 ، 8 ، 9 ، 10 ، 11 ، 12 ، 13 ، 14 ، 15 ، 16 ].
حجم ترافیک، همانطور که توسط میانگین ترافیک روزانه سالانه (AADT) اندازهگیری میشود، یکی از رایجترین معیارهای مواجهه و متغیرهای توضیحی است. محققان در دهه های اخیر با استفاده از روش های مختلف به بررسی عمیق آن پرداخته اند. از آنجایی که AADT قرار بود اثر خطی داشته باشد، اولین و واضح ترین رویکرد مورد استفاده برای مطالعه آن، مدل های رگرسیون خطی بود. مدلهای استاندارد از تکنیکهای حداقل مربعات استفاده میکردند، گاهی اوقات با یک log-log یا یک فرمول درجه دوم برای دستیابی به تناسب بهتر. فرمول خطی مورد بحث قرار گرفت و تفسیر و فرضیات آماری آن زیر سوال رفت. به عنوان یک روش جایگزین، مدلهای رگرسیون دوجملهای پواسون و منفی توسعه داده شد. اینها به دلیل توزیع فرضی پواسون تعداد تصادفات جاده ای پیشرفته تر در نظر گرفته شدند [ 17].
درک این نکته مهم است که کاربرد سنتی پواسون یا توزیع دوجمله ای منفی به تنهایی این احتمال را که بیش از یک فرآیند زیربنایی ممکن است بر فرکانس های خرابی تأثیر بگذارد را برطرف نمی کند. به عنوان مثال، اگر بخشهای مطالعه بهطور تصادفی جمعآوری شوند، مشاهدات صفر تصادف در دادهها ظاهر میشوند زیرا تصادفات رویدادهای نادری هستند. این نمایش بیش از حد مشاهدات صفر تصادف در داده ها ممکن است به اشتباه نشان دهنده پراکندگی بیش از حد در داده ها باشد، حتی اگر توزیع پواسون در غیر این صورت درست باشد [ 13 ]. بنابراین، مدل رگرسیون پواسون تورم صفر اجازه می دهد تا در داده ها به دلیل صفرهای اضافی در مقایسه با مدل رگرسیون پواسون کلاسیک، پراکندگی بیش از حد داده شود [ 18 ].
سرعت یکی از متغیرهای مورد بررسی در مطالعات تصادفات جاده ای است. نویسنده [ 19 ] تأثیر سرعت های شدید، محیط جاده و هندسه را بر سرعت ترافیک و تصادفات بررسی کرد. در طول این تحقیق، مدلهای پیشبینی برای جادههای اتحادیه اروپا ساخته شد. وی اظهار داشت: تحقیقات زیادی در این زمینه انجام شده است، اما به نظر می رسد نظرات هنوز در بین محققان در مورد اینکه آیا میانگین سرعت یا واریانس سرعت بر تصادفات تأثیر می گذارد و اگر تأثیر دارد تا چه حد، متفاوت است. نویسندگان [ 15 ] آن را به صراحت مطرح کردند. آنها دریافتند که میزان تصادفات مطابق با افزایش سرعت در جاده های غیر اصلی افزایش یافته است. با این حال، در جادههای اصلی، مشخص شد که عرض مسیر، تراکم گرهها و ترافیک، همبستگی بیشتری با میزان تصادف دارند.
یکی از بزرگترین مشکلات مدلسازی آماری، فقدان متغیرهای مرتبط مستقیم با زیرساختهای جادهای (به جز هزینههای ملی یا سرمایهگذاری در مهندسی راه) است. با این حال، معمولاً توافق بر این است که طراحی و نگهداری جادهها در فرآیند تصادف ناچیز نیست. بهبودها و مهندسی ایمنی معمولاً بدون هیچ متغیر صریحی در روند مدل گنجانده شده است [ 1 ]. نویسندگان [ 17 ، 18] از اولین کسانی بودند که رابطه بین انواع خودرو و ویژگی های فیزیکی جاده را با استفاده از مدل های خطی و غیر خطی بررسی کردند. آنها در تحقیقات خود، روابط بین متغیرهای فیزیکی جاده (به عنوان مثال، طول قطعه، انحنا، عرض شانه و شیب)، متغیرهای حمل و نقل (به عنوان مثال، حجم ترافیک، سفر کامیون)، و تعداد تصادفات کامیون ها در یک جاده خاص را بررسی کردند. بخش. پس از آزمایش مدلهای توزیع پواسون، مطالعه آنها نشان داد که وقتی در بخشهای جاده بسیار کوتاه (کمتر از 80 متر) گنجانده میشوند، دقت مدل خطی خراب میشود. پارامترهایی مانند حجم ترافیک، انحنا و شیب همبستگی مثبتی با تصادفات رانندگی کامیونها دارند. بعداً، مطالعات کمی پارامترهای فیزیکی جاده را در مدل ترکیب کرده اند، مانند [20 ].
نویسندگان [ 2 ، 5 ، 6 ، 21 ، 22 ] جزو اولین کسانی بودند که قابلیت های سیستم اطلاعات جغرافیایی (GIS) را با تجزیه و تحلیل ایمنی جاده ها ترکیب کردند. برای مثال، نویسنده [ 3 ]، یک بسته نرم افزاری منحصر به فرد (بر اساس Arc\Info) برای تجزیه و تحلیل ایمنی جاده ایجاد کرد. GIS راه حل های پیشرفته ای را برای تحقیقات در سطح منطقه و مکان گرا ارائه می دهد. همچنین امکان تحلیل های پیچیده و بررسی های عمیق را نسبتاً آسان می کند.
همانطور که در بالا ذکر شد، مطالعات قبلی متغیرهای مرتبط با زیرساخت جاده، هندسه و دادههای مکانی را که میتوان به روشی نسبتاً ساده با استفاده از سیستمهای اطلاعات جغرافیایی (GIS) استخراج کرد، مطالعه نکرد. علاوه بر این، فرض بر این بود که اگر مدلها نتایج قابلتوجهی را برای مجموعه دادههای بخشهای کوتاه جاده ایجاد کنند، امکان تخصیص منابع به روشی متمرکز و اقتصادی را فراهم میکند، که در تضاد با روشی است که امروزه با آنها رفتار میشود. بنابراین، هدف تحقیق توسعه یک مدل پیشبینی مبتنی بر GIS برای ارزیابی تصادفات رانندگی در بخشهای کوتاه بزرگراه بود. با استفاده از پارامترهای فضایی و مبتنی بر ترافیک، پژوهش بر روی موضوعات زیر متمرکز شد:
-
طولهای متفاوت: آیا میتوانیم مدلهای پیشبینی قابلتوجهی برای بخشهای جاده کوتاه (500 متر) به دست آوریم. اگر چنین است، درمان هدفمند در بخشهای جادهای از نظر زیرساختی و اجرایی میتواند توصیه شود.
-
متغیرهای مهم: با توجه به ترافیک و دادههای مکانی در یک بخش بزرگراه، مهمترین متغیرهای مؤثر بر میزان تصادفات آن بخش کدامند؟
-
تعامل بین متغیرها: آیا بین متغیرهای زیر تعامل وجود دارد: (الف) انحنای سطح و قطعه: آیا انحنا تأثیر متفاوتی بر تعداد تصادفات در مناطق مختلف دارد؟ (ب) مساحت و شیب: آیا میتوانیم تعداد تصادفات مورد انتظار متفاوتی را برای شیبها در مناطق مختلف تعیین کنیم؟ ج) حجم و مساحت ترافیک (AADT): آیا تأثیر حجم ترافیک بر میزان تصادفات ناهماهنگ و وابسته به یک منطقه معین است؟
2. حوزه و روش مطالعه
2.1. منطقه مطالعه و ساخت مجموعه داده
این مطالعه در شبکه جاده اصلی اسرائیل انجام شد. این مطالعه از داده های تصادفات رانندگی استفاده می کند، همانطور که توسط اداره مرکزی آمار اسرائیل (CBS)، برای سال های 2005 تا 2007 گزارش شده است [ 23 ]]. پایگاه داده CBS بر اساس اطلاعاتی است که هر ماه توسط پلیس اسرائیل توزیع می شود. اینها فقط تصادفات با تلفات هستند. سایر حوادث، مانند گلگیر خم کن توسط پلیس اسرائیل رسیدگی نمی شود. در مطالعه حاضر تمام تصادفات رخ داده تنها در مقاطع بزرگراه (نه در تقاطع) ادغام شده است. این ما را با 2592 تصادف در سال 2005; 2558 تصادف در سال 2006 و 2373 تصادف در سال 2007 (مجموع 7523 تصادف). تصادفات در شبکه جاده ای اسرائیل قرار گرفته است. این کار با فرآیند تطبیق آدرس با استفاده از شماره جاده و طول دویدن ارائه شده در هر رکورد تصادف انجام شد. فرآیند تطبیق آدرس واقعی ابتدا بر اساس ترکیب دو لایه GIS از جادهها و تقاطعها (حاوی طول در حال اجرا) بود. بعداً تطبیق آدرس واقعی توسط ابزار ArcGIS “make route event” اعمال شد.
چهار مجموعه داده اولیه از شبکه اصلی جاده اصلی اسرائیل تولید شد. هر کدام از این ها با استفاده از طول های مختلف جاده ساخته شده اند: 500 متر، 750 متر، 1000 متر و 1500 متر. پس از حذف همه بخشهای موجود در مناطق شهری و آنهایی که در مجاورت تقاطعها قرار دارند، ما با 572، 1166، 1817 و 3259 بخشها در مجموعه دادههای «1500 متر»، «1000 متر»، «750 متر» و «500 متر» باقی ماندیم. ، به ترتیب. هر بخش جاده (در هر چهار مجموعه داده) با مقادیر مشخصه پارامترهای فضایی، به عنوان مثال، منطقه جغرافیایی (شمال، مرکز و جنوب) و مناطق فرعی مرتبط بود. شیب؛ انحنای؛ زاویه خورشیدی (تابش نور خورشید) و با مشخصه حمل و نقل به عنوان مثال،: تعداد تصادفات، AADT- میانگین ترافیک روزانه سالانه برای روزهای هفته: یکشنبه تا پنجشنبه.
سپس برای هر مجموعه داده، چهار مدل آماری با استفاده از نرم افزار SAS ساخته شد. اینها عبارت بودند از: پواسون; دو جمله ای منفی; پواسون صفر تورم; و دوجمله ای منفی با تورم صفر.
2.2. مدلسازی: اجراها و ملاحظات
به طور سنتی، ساخت یک مدل پیشبینی برای تصادفات جادهای از دادههای تاریخی برای ساخت مدل استفاده میکند. سپس این پیشبینیها با مشاهدات واقعی تصادفات (در مکانهای خاص و بدون تغییر) در آینده مقایسه میشوند. در مطالعه حاضر پایگاه داده ساخته شده مبتکرانه و منحصر به فرد است و پارامترهای اختصاصی را در خود جای داده است، همانطور که در بخش قبل توضیح داده شد. همانطور که گفته شد، یکی از آن ها حجم ترافیک (AADT) بود که در بسیاری از مطالعات دیگر در زمینه ایمنی راه ها پارامتر مهمی بود.
در مطالعه کنونی AADT عمدتاً به صورت دستی بر اساس مستندات CBS (در یک فرآیند زمانبر) به روز شد. برای هر بخش داده ها برای سه سال مطالعه به روز شد. گاهی اوقات، اسناد CBS فاقد برخی اطلاعات در مورد بخش های AADT بودند (هیچ داده ای برای یک سال از سه سال تحقیق وجود نداشت یا اصلاً داده ای وجود نداشت). بنابراین، برای اینکه کیفیت مدلسازی در حین ساخت مدلسازی آماری مختل نشود، تنها بخشهایی که تمام دادههای مورد نیاز برای کل سه سال تحقیق (2005-2007) را داشتند در مطالعه ادغام شدند. این منجر به مواردی شد که در آن ساخت یک مدل تخمین احتمال با استفاده از دادههای “تاریخی” 2005-2006 و سپس مقایسه پیشبینیها با مشاهدات آینده (به عنوان مثال، دادههای 2007) از نظر اعتبار مدل آماری امکانپذیر نبود.
متغیر افست مورد استفاده در مدلهای رگرسیون سمی، دادههای شمارشی (مثلاً تعداد وسایل نقلیه) و نرخهای بازگشتی (شمارش در واحد)، برای مثال تعداد خودروها در هر کیلومتر را میگیرد. در مطالعه حاضر، AADT به عنوان یک متغیر مستقل در مدل پیشبینی گنجانده شد اما نه یک افست. این، همانطور که در تحقیقی که می خواستیم رابطه بین AADT و تعداد تصادفات را بررسی کنیم. اگر AADT به عنوان افست ادغام می شد، نمی توان آن را انجام داد. همچنین AADT مربوط به بخش های جاده با اندازه مساوی بود، بنابراین عادی سازی اضافی مورد نیاز نبود.
هدف در اینجا اطمینان از حفظ پراکندگی داده ها و حفظ واریانس بود. این به منظور تأیید این بود که ما بخشها را بهعنوان «حوادث صفر» مدلسازی کردیم، نه تنها به این دلیل که دوره زمانی انتخاب شده خیلی کوتاه بود، نه به دلایل دیگر (مانند بخش جاده در واقع ایمن است). بنابراین، هر یک از چهار مجموعه داده (طول بخش های مختلف) به طور تصادفی به دو زیر مجموعه تقسیم شدند. اولی شامل دو سوم از رویدادها و دومی شامل یک سوم دیگر مشاهدات بود. زیرمجموعه بزرگتر (“2/3”) به عنوان “مجموعه آموزشی” برای تولید مدل استفاده شد، در حالی که زیر مجموعه کوچکتر (“1/3”) به عنوان “مجموعه کنترل” به منظور تأیید نتایج استفاده شد. یک مدل اضافی از یک سوم تصادفی دیگر از مجموعه داده ها ساخته شد تا به عنوان “مدل کنترل کامل 1/3” عمل کند. این مدل تمام پارامترهای موجود را در مجموعه داده ها گنجانده بود و برای بررسی نتایج قابل توجه (صرف نظر از “مدل آموزشی”) استفاده شد. همه اینها به منظور تعیین پایداری مدل انجام شد.
بخش 2.4 فرآیند “اعتبارسنجی متقاطع” را که با استفاده از هر سه مدل مختلف ساخته شده (طبق سه گروه ذکر شده در بالا) انجام شد، شرح خواهد داد. هدف این اعتبارسنجی ها این بود که به طور مستقل از متغیرهایی که به طور قابل توجهی در تصادفات رانندگی نقش دارند اطمینان حاصل شود. هدف از اعتبارسنجی و مقایسه مدلهای مختلف (به تفصیل در 2.4) این بود که اطمینان حاصل شود که «مدل پیشبینی آموزش» در پیشبینی میانگین خود مغرضانه نیست. توجه داشته باشید که این نشانگر کیفیت پیش بینی ها نیست. این موارد باید در تحقیقات آینده مورد آزمایش قرار گیرند.
در مطالعاتی که با مجموعه داده های بزرگ مشخص می شوند، بررسی ارزش معناداری کافی نیست. بنابراین، به دلیل تأثیر کمیت زیاد، گاهی اوقات حتی پارامترهای کم تأثیر نیز قابل توجه به نظر می رسد. یک راه حل برای این مشکل استفاده از معیار اطلاعات Akaike (AIC) به عنوان آزمونی برای ارزیابی کیفیت مدل است. این معیار مبتنی بر تابع درستنمایی است که نتایج پیشبینیشده را با مشاهدات واقعی مقایسه میکند. به عبارت دیگر، بهترین تطابق بین احتمال برآورد شده و احتمال واقعی (محاسبه شده با استفاده از مشاهدات نمونه) را تعیین می کند. مقادیر پایین تر AIC نشان دهنده سازگاری بهتر مدل است. AIC برای هر چهار مدل محاسبه شد: سم، دوجمله منفی، صفر باد شده سم و صفر دوجمله منفی باد شده.
2.3. تشخیص پارامترهای مهم
به منظور شناسایی مهمترین پارامترهای مؤثر بر تصادفات جادهای، روش GENMOD با استفاده از نرمافزار SAS بر روی “مجموعه آموزشی” به کار گرفته شد (رویه GENMOD مطابق با مدلهای خطی تعمیمیافته مطابق با [ 24 ] است. کلاس مدلهای خطی تعمیمیافته یک گسترش مدلهای خطی سنتی که به میانگین جمعیت اجازه میدهد از طریق یک تابع پیوند غیرخطی به یک پیشبینیکننده خطی وابسته باشد و به توزیع احتمال پاسخ اجازه میدهد تا هر عضوی از یک خانواده نمایی از توزیعها باشد. میز 1نتایج اجرای روش GENMOD بر روی مجموعه داده های بخش های “500 متر” را ارائه می دهد. این روش همچنین برای شناسایی چنین پارامترهایی در مدلهایی که برای مجموعه دادههای بخش 750، 1000 و 1500 متر ساخته شدهاند، اعمال شد.
جدول 1. نتایج روش GENMOD برای مدل آموزشی (دو سوم داده ها برای بخش هایی به طول 500 متر).
همانطور که در جدول 1 نشان داده شده است، متغیرهایی که با تصادفات مرتبط هستند عبارتند از: (1) AADT – میانگین سالانه حجم ترافیک روزانه در روزهای هفته پس از تبدیل لگاریتم طبیعی. (2 و 3) منطقه – وقایع رخ داده در ناحیه شمالی، تجزیه و تحلیل و با ناحیه مرکزی و جنوبی مقایسه شد (4) انحنا .
با بررسی مقادیر “پراکندگی” مجموعه آموزشی نشان داده شده در جدول 1 (از 1.4925 تا 2.0234)، می توان دریافت که مقدار “1” در فاصله اطمینان در سطح معناداری 95٪ قرار نمی گیرد. بنابراین، می توان نتیجه گرفت که داده ها با پراکندگی بیش از حد مشخص می شوند. این نشان می دهد که مدل مناسب یک دوجمله ای منفی است.
2.4. اعتبارسنجی متقاطع – ارزیابی سطح سازگاری مدلها
2.4.1. تصادفات مورد انتظار – اعتبار سنجی تصادفات واقعی
سازگاری مدل اول با مقایسه تعداد مورد انتظار تصادفات (همانطور که طبق مدل محاسبه می شود) با تعداد واقعی تصادفات در طول بخش های مختلف جاده تعیین شد. به دلیل تطابق ناکافی، روش تجربی بیز (EB) اعمال شد. روش EB تعداد تصادفات مورد انتظار را محاسبه می کند، در حالی که تعداد واقعی تصادفات رخ داده در بخش های جاده را در نظر می گیرد [ 25 ]. این روش طبق رابطه (1) (ارائه شده توسط [ 11 ، 26 ]) انجام شد.
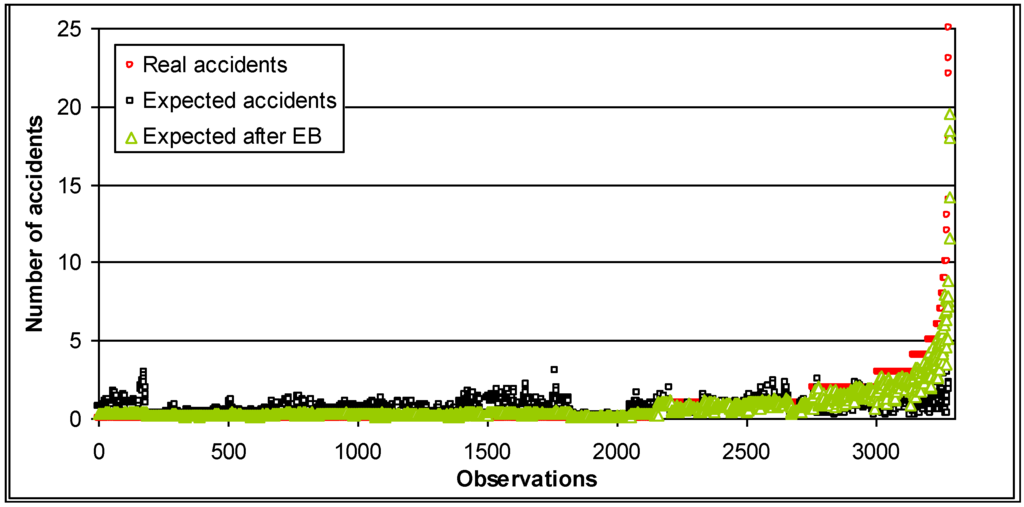
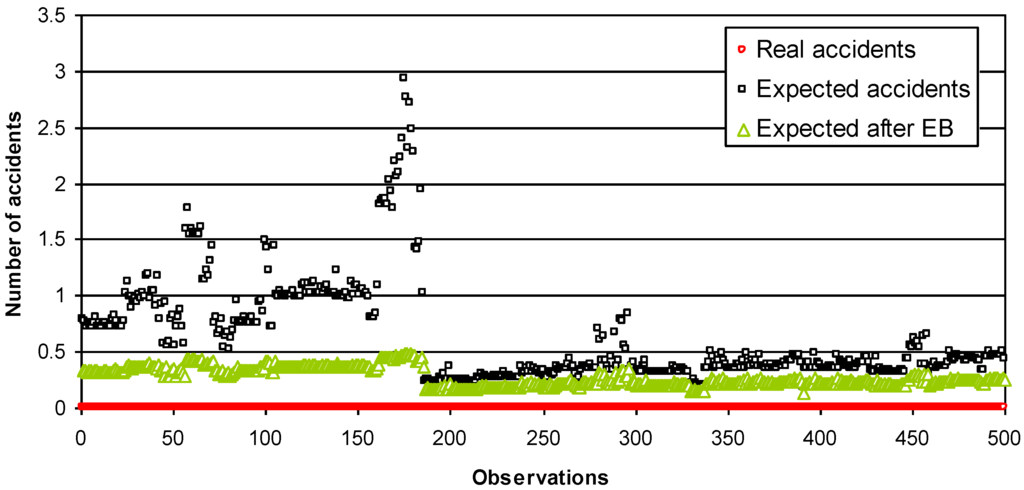
شکل 1 نتایج مقایسه را برای مجموعه داده های بخش جاده به طول 500 متر، از جمله روش EB نشان می دهد. شکل 2 و شکل 3 تجزیه داده های اصلی را به اعداد مشاهدات مختلف نشان می دهد.
شکل 1. تعداد تصادفات مورد انتظار با مقایسه تعداد واقعی تصادفات و تعداد پیش بینی شده پس از اعمال روش EB (بخش جاده 500 متر).
شکل 2. تعداد تصادفات مورد انتظار با مقایسه تعداد واقعی تصادفات و تعداد پیش بینی شده پس از اعمال روش EB (بخش جاده 500 متر) – مشاهده 0 تا 500.
شکل 3. تعداد تصادفات مورد انتظار با مقایسه تعداد واقعی تصادفات و تعداد پیش بینی شده پس از اعمال روش EB (بخش جاده 500 متر) – مشاهده 3000 تا 3300.
2.4.2. مقایسه مدل های آموزشی و کنترلی
روش GENMOD اعمال شده بر روی مدل آموزشی (دو سوم داده ها) روی مدل کنترل (یک سوم داده ها) نیز اعمال شد. پیش از این، تنها پارامترهایی که در مدل آموزشی مهم بودند در مدل کنترل ادغام شدند. جدول 2 ضرایب مدل کنترل را نشان می دهد.
جدول 2. نتایج روش GENMOD برای مدل کنترل (یک سوم داده ها برای بخش هایی به طول 500 متر).
هنگامی که برآوردها برای دو مدل محاسبه شد، ضرایب با آزمایش اینکه آیا برآوردهای ضریب مدل برای مدل کنترل در فاصله اطمینان مدل آموزشی در سطح اطمینان 95 درصد قرار میگیرند، ارزیابی شدند. به عنوان مثال، در مدل کنترل ( جدول 2 )، مقدار ضریب متغیر نشان دهنده حجم ترافیک ( AADT ) 0.8019 است. مشاهده می شود که این مقدار در محدوده 0.5883 تا 0.8423 قرار می گیرد ( جدول 1 را ببینید )، به این معنی که مدل از نظر آماری به اندازه کافی برای پیش بینی این متغیر قابل اعتماد است. از مقایسه جدول 1 و جدول 2 می توان دریافت که این موضوع برای همه متغیرهای مدل به جز متغیر صادق است.ناحیه: مرکزی (اشاره به تفاوت ناحیه مرکزی با ناحیه شمالی). در اینجا، مقدار ضریب -0.8810 در بازه اطمینان مدل آموزشی قرار نمیگیرد (از 0.3952- تا -0.7444). این بدان معنی است که مدل از نظر آماری به اندازه کافی برای پیش بینی این پارامتر قابل اعتماد نیست. علاوه بر این، ممکن است مشاهده شود که متغیر Curvature در مدل کنترلی اگر در مدل برای پایینترین AIC آن گنجانده شود، معنیدار نیست.
2.4.3. تست TOST برای هم ارزی
همانطور که در بالا گفته شد، می توان مقادیر مورد انتظار تصادفات را با توجه به مدل آموزشی (دو سوم داده ها) و تعداد مورد انتظار تصادف را با توجه به مدل کنترل (یک سوم داده ها) مقایسه کرد. در یک دنیای اتوپیایی، انتظار می رود که تفاوت میانگین بین دو مدل صفر باشد، زیرا هر دو مدل یک پدیده را پیش بینی می کنند. با این حال، در دنیای واقعی، برخی از تفاوت های مورد انتظار بین میانگین ها را می توان در محدوده صفر پیش بینی کرد. از این رو، تنها باید پرسید که آیا تفاوت ها در محدوده معقولی از پیش تعریف شده قرار دارند یا خیر. برای این منظور از آزمون دو یک طرفه (TOST) استفاده شد (تست T برای دو جمعیت مستقل برای رسیدگی به این موضوع کافی نیست زیرا آزمونهای T فرض میکنند که دادهها به طور معمول توزیع میشوند، برخلاف رویدادهای تصادفی، مانند به عنوان تصادفات رانندگی). علاوه بر این، از آزمونهای T برای اثبات نتایج نابرابر استفاده میشود، در حالی که در اینجا باید دقیقاً نتایج را ثابت کنیم) که اجازه میدهد برابری را برای هر محدوده مشخص تأیید کنیم. در این مطالعه، حداقل دامنه تصادفات 0.25- تا 0.25 برای ارزیابی تعریف شد. اگر تفاوت بین مقادیر میانگین (μ) در فاصله اطمینان اختلاف قرار گیرد، نشان می دهد که مدل پیش بینی های مورد انتظار مشابهی را ارائه می دهد. معادلات 2 و 3 فرضیه های آزمون را ارائه می کنند. این نشان می دهد که مدل پیش بینی های مورد انتظار مشابهی را ارائه می دهد. معادلات 2 و 3 فرضیه های آزمون را ارائه می کنند. این نشان می دهد که مدل پیش بینی های مورد انتظار مشابهی را ارائه می دهد. معادلات 2 و 3 فرضیه های آزمون را ارائه می کنند.
جدول 3 نتایج آزمایش TOST را برای بخش های جاده ای به طول 500 متر نشان می دهد. اگر مقادیر ستون “90% CL Mean” بین محدوده بالایی (Upper Bound) و محدوده پایین (Lower Bound) باشد، H0 را می پذیریم و H1 را رد می کنیم. این بدان معنی است که مقادیر حوادث مورد انتظار، همانطور که برای دو مجموعه داده (یک سوم و دو سوم) محاسبه می شود، به اندازه کافی نزدیک هستند.
جدول 3. نتایج TOST برای قطعات 500 متری.
2.4.4. مقایسه نسبت احتمالات
محاسبه تخمین احتمال وقوع تصادف صفر در بخشهای جاده، یک تصادف، دو تصادف و غیره اختیاری است. اگر مدل به اندازه کافی قابل اعتماد باشد، باید نسبت های مشابهی را با مقایسه درصد بخش هایی که در آنها “صفر تصادف” در عمل رخ داده است (با استفاده از دنیای “واقعی”، داده های “واقعی”) و میانگین احتمال “صفر تصادفات” مورد انتظار به دست آوریم. “، همانطور که توسط مدل محاسبه شده است.
جدول 4 احتمالات محاسبه شده برای وقوع N تصادف در بخش های جاده ای 500 متری را که از مدل محاسبه شده است، نشان می دهد. این برای نمونه ای از 9 بخش ارائه شده است. هر ردیف در جدول نشان دهنده یک بخش جاده خاص با طول مشخص است (همانطور که در مثال فعلی 500 متر گفته شد). هر ستون نشان دهنده احتمال وقوع N تصادف در آن بخش است. بنابراین، ستون PO0 نشان دهنده احتمال وقوع تصادفات صفر است. ستون PO1 نشان دهنده احتمال وقوع یک حادثه و غیره است.
جدول 4. احتمالات وقوع N تصادف برای نمونه ای از مقاطع به طول 500 متر.
جدول 5 میانگین ستون های PO0 و PO1 (متوسط احتمال تصادفات صفر، میانگین احتمال یک تصادف و غیره) را همانطور که در جدول 4 ارائه شده است، نشان می دهد.
جدول 5. میانگین احتمالات برای وقوع تصادفات صفر و یک در قطعات 500 متری.
جدول 6. نسبت تصادفات داده های واقعی برای N تصادف (بخش های جاده ای به طول 500 متر).
ستون “PO1” در جدول 5 ، احتمال محاسبه شده مدل را برای یک حادثه برای همه بخش های پایگاه داده ارائه می دهد. میانگین مقدار 0.1837 (18.37٪) بود. این مقدار بسیار نزدیک به مقدار 18.14٪ است که مقدار نسبت واقعی بخش هایی است که تنها یک تصادف روی آنها رخ داده است، در پایگاه داده به طول 500 متر در طول دوره مطالعه ( جدول 6 در ستون AccCNT = 1 را ببینید). .
2.4.5. مقایسه مدل آموزشی (داده های دو سوم) و مدل کنترل کامل (یک سوم داده ها)
یک مدل جدید بر اساس یک سوم داده ها ساخته شد تا به عنوان “مدل کنترل کامل” به دلیل استفاده از تمام پارامترهای موجود در مجموعه داده ها عمل کند، برخلاف مدل های “کنترلی” قبلی که در آن فقط پارامترهای مهم وجود داشت. ترکیب شدند. مقایسه بین دو مدل یک کنترل اضافی را فراهم کرد و یک آزمون اطمینان را در مورد نتایج مدل آموزشی (دو سوم داده ها) در سطوح مختلف فعال کرد. همچنین امکان اعتبارسنجی نوع مدل (جنبه توزیع داده) را فراهم کرد. بنابراین، به عنوان یک کنترل اضافی برای پارامترهای بهدستآمده از مدل معنیدار، و همچنین کنترلی برای تخمینهای بهدستآمده از مدل عمل کرد.
3. نتایج، تجزیه و تحلیل و بحث
3.1. مدل های بهینه
این مطالعه نشان میدهد که مجموعه دادههای بخش کوتاهتر آزمایششده (طول ۵۰۰ و ۷۵۰ متر) پایدارترین مدلها را به همراه داشت. این بدان معنی است که می توان در مورد سرمایه گذاری در زیرساخت و اجرای بخش های کوتاه، برخلاف نگرش رایج بهبود بخش های نسبتاً طولانی شبکه جاده، توصیه هایی ارائه کرد.
معادله (4) نرخ مورد انتظار تصادفات جاده ای (μ) را برای بخش های بزرگراهی به طول 500 متر نشان می دهد:
معادله (5) نرخ مورد انتظار تصادفات جاده ای (μ) را برای بخش های بزرگراهی به طول 750 متر نشان می دهد:
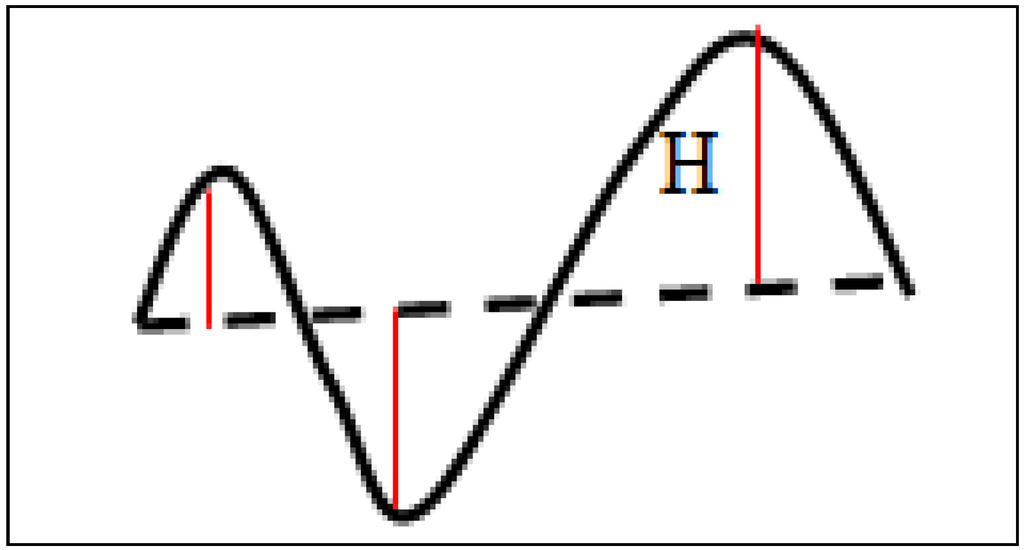
جایی که: AADT_Log – میانگین ترافیک روزانه سالانه پس از تبدیل آن با استفاده از یک لگاریتم طبیعی. منطقه—در حالی که Region1 = ناحیه جنوبی. منطقه 2 = منطقه شمالی; و منطقه 3 = منطقه مرکزی، مدل منطقه شمالی را در رابطه با دو منطقه دیگر مقایسه و تجزیه و تحلیل می کند. بنابراین، برای یک بخش واقع در منطقه 2، مقداری که در متغیرهای منطقه 3 و منطقه 1 قرار می گیرد 0 خواهد بود. خمیدگی – انحنای بخش. محاسبه شده با مجموع تفاوتهای بین نزدیکترین H، تقسیم بر طول قطعه (H به رنگ قرمز: فاصله عمودی بین نوک سهمی و پاره خطی که رشتهها را به هم متصل میکند – به صورت یک خط نقطه چین ظاهر میشود)، همانطور که در رابطه (6) مشخص شده است. و شکل 4 .
پس از محاسبه نرخ تصادفات مورد انتظار، از روش EB به منظور بهبود بیشتر مدل استفاده شد.
3.2. پارامترهای مدل
از بین تمامی پارامترهایی که در این مطالعه مورد بررسی قرار گرفت، انحنای بخش جاده، منطقه و حجم ترافیک از نظر تأثیرگذاری بر تصادفات مهمترین هستند. با توجه به نرخ بالای تصادفات مورد انتظار، منطقه شمالی برای مشاهده ویژه تعیین شد و به مناطق فرعی تقسیم شد که به طور جداگانه مورد تجزیه و تحلیل قرار گرفتند.
3.2.1. انحنا
یافته های انحنا و حجم ترافیک با مطالعه [ 18 ] مطابقت دارد. با این حال، بر خلاف تحقیقات Miaou، که رابطه بین انحنا و میزان تصادف را فقط برای کامیونهای بزرگ شناسایی کرد، مطالعه کنونی به همه انواع وسایل نقلیه پرداخته و قوانینی را برای دادهها با استفاده از روش EB انجام داد. پارامتر حجم ترافیک ( aadt log ) نیز معنی دار بود. این یافته با سایر مطالعات از جمله [ 5 ، 6 ، 10 ، 27 ] مطابقت دارد.
3.2.2. منطقه
سومین متغیری که مشخص شد منطقه بود. در اسرائیل، این متغیر با بخشهای اصلی «پیرامون» (شمال و جنوب) و منطقه مرکزی (کلان شهر تل آویو) سازگار است. همه تجزیه و تحلیل ها به طور مداوم بالاترین میزان تصادفات مورد انتظار را در ناحیه شمالی و به ویژه در غرب گالیله علیا نشان دادند. بنابراین، نتایج مربوط به این متغیر باید از چند جنبه بیشتر مورد تجزیه و تحلیل و بررسی قرار گیرد.
متغیر منطقه در مرحله اول ساخت مدل ها مورد تجزیه و تحلیل قرار گرفت. به نظر می رسد که این پارامتر در هر چهار مدل، همانطور که برای طول های مختلف بخش های جاده ساخته شده است، قابل توجه است. در هر چهار مدل، انتظار میرفت که نرخ تصادف برای بخش شمالی اسرائیل بیشتر از نرخ مورد انتظار برای بخشهای مرکزی و جنوبی اسرائیل باشد (تقریباً دو برابر).
تجزیه و تحلیل منطقه ای دوم تفاوت های آماری بین مناطق شمالی، جنوبی و مرکزی را بررسی کرد. این تجزیه و تحلیل با هدف بررسی تفاوت های آماری بین مناطق، و یادگیری اینکه آیا یک منطقه خاص بدون توجه به حجم ترافیک، تصادفات کمتر یا بیشتر را به تصویر می کشد. مجموعه داده به چندین محدوده حجم ترافیک تقسیم شد: “کم”، “متوسط-کم”، “متوسط-بالا” و “زیاد”. با توجه به نیاز به حفظ تعادل گروه ها برای تجزیه و تحلیل آماری، تنها گروه هایی با نمونه های کافی مورد تجزیه و تحلیل قرار گرفتند. در عمل، تنها گروه “متوسط-پایین” (5000 تا 15000 وسیله نقلیه در هر بخش جاده) و گروه “متوسط-بالا” (15000 تا 30000 وسیله نقلیه در هر بخش جاده) تجزیه و تحلیل شدند.
در این تحلیل، روندها در طول جادههای 500 و 750 متری برای بخشهای جادهای «متوسط-کم» و «متوسط-بالا» مشابه بود، با نرخ تصادفات مورد انتظار در منطقه شمالی بیشتر از حد انتظار در منطقه جنوبی و میزان تصادفات مورد انتظار در منطقه شمالی بیشتر از انتظار در منطقه مرکزی است. این روندها همچنین با نتایج بهدستآمده در تجزیه و تحلیل مناطق قبلی که بر روی مدل آموزشی انجام شده است (نرخ تصادف مورد انتظار در شمال بالاتر از انتظار در مناطق مرکزی و جنوبی است) سازگار است.
هنگام مقایسه میزان تصادفات پیش بینی شده در مناطق مرکزی و جنوبی، روابط متفاوتی پیدا شد:
(1) در حجم ترافیک “متوسط-کم”، نرخ تصادفات مورد انتظار در منطقه مرکزی بیشتر از انتظار در منطقه جنوبی بود. این را می توان با این واقعیت توضیح داد که در جنوب، علیرغم برخورد با تصادفات در حجم های به اصطلاح ترافیکی متوسط و کم، حجم ترافیک واقعا کمتر است، به این معنی که جاده ها در واقع ترافیک بسیار پراکنده ای دارند. منطق ساده است: با توجه به اینکه وسایل نقلیه بسیار کمی (مقدار برد کم) وجود دارند، احتمال تصادف در این منطقه به شدت کاهش می یابد، در مقایسه با منطقه مرکزی، جایی که وسایل نقلیه در انتهای بالاتر “متوسط-پایین” حضور دارند. محدوده حجم ترافیک
(2) در حجم ترافیک “متوسط تا زیاد”، نرخ تصادفات مورد انتظار در منطقه جنوبی بیشتر از انتظار در منطقه مرکزی بود. توضیح فرضی این است که با افزایش ترافیک، در برابر اثرات کیفیت زیرساخت آسیبپذیرتر میشود، مانند تقاطعهای غیرقانونی که مستقیماً به بزرگراهها میریزند، خطوط کمتر و عدم جداسازی خطوط. از آنجایی که زیرساخت در منطقه جنوبی بسیار فقیرتر از منطقه مرکزی در زمان مطالعه بود، بر میزان حساسیت تصادف تأثیر گذاشت.
سومین جنبه تحلیل منطقه ای، تحلیل تعامل بود. برخلاف تحلیل های قبلی، در اینجا حجم ترافیک به عنوان یک پارامتر عمل می کند. بنابراین، تفاوت در تقسیم آستانه حجم ترافیک وجود دارد. این کار با تقسیم بندی بخش ها به سه گروه انجام شد: حجم ترافیک “کم” که با مقادیری از 0 تا 10766 مشخص می شود. حجم ترافیک “متوسط” که با مقادیری بین 10767 و 20033 مشخص می شود. و حجم ترافیک “بالا” که با مقادیر بیش از 20033 مشخص می شود.
یک تعامل بین منطقه و متغیرهای حجم ترافیک برای هر دو مجموعه داده مورد بررسی قرار گرفت. این بدان معنی است که اثر حجم ترافیک بر میزان مورد انتظار تصادفات یکنواخت نیست و به منطقه نیز بستگی دارد ( جدول 7 را ببینید ). یافته های تحلیل تعامل با نتایج تحلیل اول و دوم مطابقت دارد. همه برهمکنشهای دیگر مانند ناحیه و انحنا، و ناحیه و شیب معنیدار نبودند، و بنابراین، مانند AADT و منطقه بیشتر مورد بررسی قرار نگرفتند. آزمون معناداری با مقایسه مقدار AIC «مدل تهی» («مدل تهی» حاوی متغیرهای: انحنا، مساحت و حجم ترافیک بدون متغیر نشاندهنده تعامل) با سه مدل دیگر که شامل برهمکنشها به عنوان پارامتر بودند، انجام شد.
ناهنجاری همانطور که در جدول 7 نشان داده شده است که در آن نتایج مورد انتظار برای “ترافیک متوسط” بیشتر از “بالا” در منطقه جنوبی است، واقعاً جالب است. این به دلیل تقسیم بندی گروه های ترافیکی مغرضانه است. حداکثر تردد روزانه در منطقه جنوبی 23000 نفر بوده است. این همچنین نشان میدهد که گروه «ترافیک بالا» تقریباً از این منطقه خارج نمیشود. تنها 72 رکورد در منطقه جنوبی برای این گروه یافت شد و این در واقع نتایج را مغرضانه کرد.
جدول 7. فعل و انفعالات – تعداد تصادفات مورد انتظار تقسیم شده به مناطق (طول بخش 500 متر و 750 متر).
در آخرین تحلیل متغیر منطقه، منطقه شمالی به دلیل نرخ بالای تصادفات مورد انتظار برای مشاهده ویژه تعیین شد. منطقه به هشت زیر منطقه تقسیم شد و تجزیه و تحلیل بر روی داده های کامل تصادف (بدون تقسیم به 2/3 و 1/3) انجام شد. یک منطقه فرعی، “ارتفاعات جولان” به دلیل تعداد کم حوادث تصادفات در طول دوره تحقیق از تحلیل حذف شد. برای تشخیص نرخ کشف نادرست از روش مرحلهای خطی استفاده شد. نتایج تجزیه و تحلیل نرخ تصادفات مورد انتظار بالای قابل توجهی را در منطقه فرعی غرب گالیله علیا نشان داد. با توجه به این یافته، توصیه میشود که مجموعهای از فعالیتهای عملی از بهبود زیرساختها گرفته تا آموزش و حمایت انجام شود.
3.2.3. سرعت
جالب توجه است که متغیر سرعت در این مطالعه معنی دار نبود. این نتیجه گیری با سایر مطالعات منتشر شده مانند [ 15 ] مطابقت دارد که نشان می دهد میزان تصادفات مطابق با افزایش سرعت در جاده های غیر اصلی افزایش می یابد. با این حال، در جادههای اصلی، مشخص شد که عرض مسیر، تراکم گرهها و ترافیک همبستگی بیشتری با میزان تصادف دارند.
پارامتر سرعت، همانطور که در این مطالعه ادغام شده است، تنها تخمین زده شد. برای اینکه بتوان این پارامتر را با دقت بیشتری در مطالعات آتی ارزیابی کرد، لازم است دادههای سرعت دقیقتر، شاید حتی از زمانهای مختلف، مانند روز و شب، روزهای هفته و آخر هفته و غیره را به دست آورد و ادغام کرد.
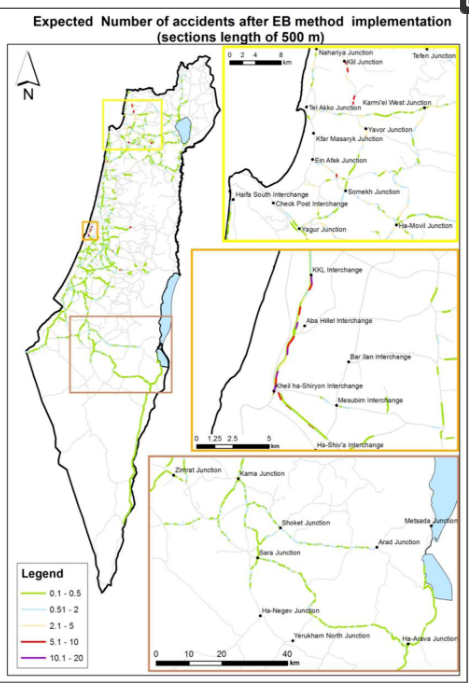
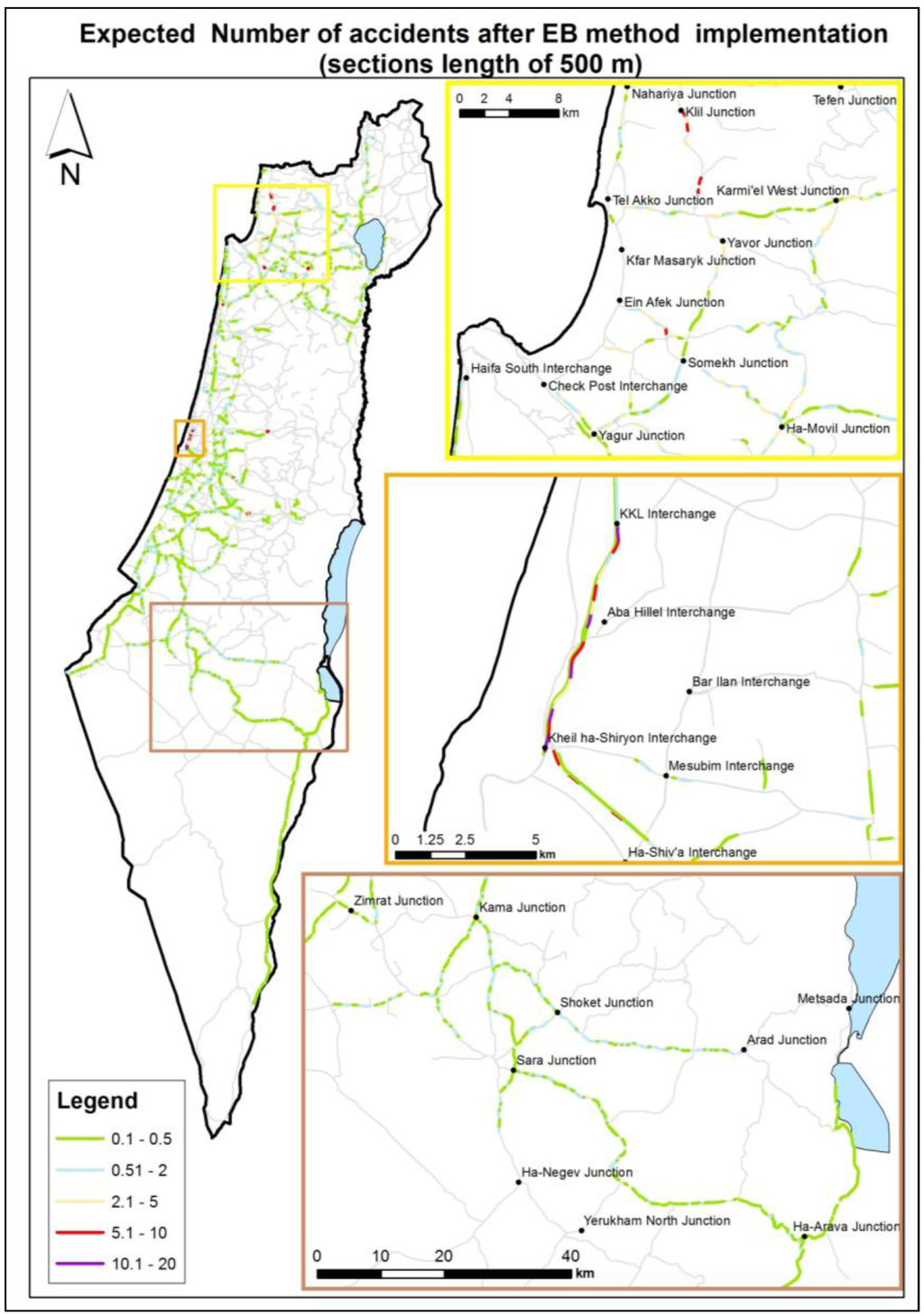
شکل 5. تعداد تصادفات مورد انتظار (بخش های جاده به طول 500 متر).
3.2.4. زاویه خورشید (تابش نور خورشید)
هر حادثه با استفاده از فرآیند تطبیق آدرس نرم افزار ESRI ArcGIS موقعیت یابی شد. پس از یافتن مکان، آزیموت و شیب خودرو بر اساس مدل ارتفاعی دیجیتال محاسبه شد.
مقدار تابش نور خورشید برای هر حادثه با استفاده از دسته ای از معادلات منتقل شده به نرم افزار MS Access محاسبه شد. به دلیل عدم قطعیت زیاد جهت خودرو در حین تصادف (بالا دست یا پایین دست) بسیاری از انحرافات حاصله نادرست بود. این یکپارچگی مقادیر تابش نور خورشید را تحت تأثیر قرار داد. بنابراین در این تحقیق تابش نور خورشید به عنوان پارامتری در نظر گرفته شده است، اما توصیه می شود پس از بدست آوردن اطلاعات دقیق و معتبر از آن استفاده شود.
3.2.5. نقشه های پیش بینی
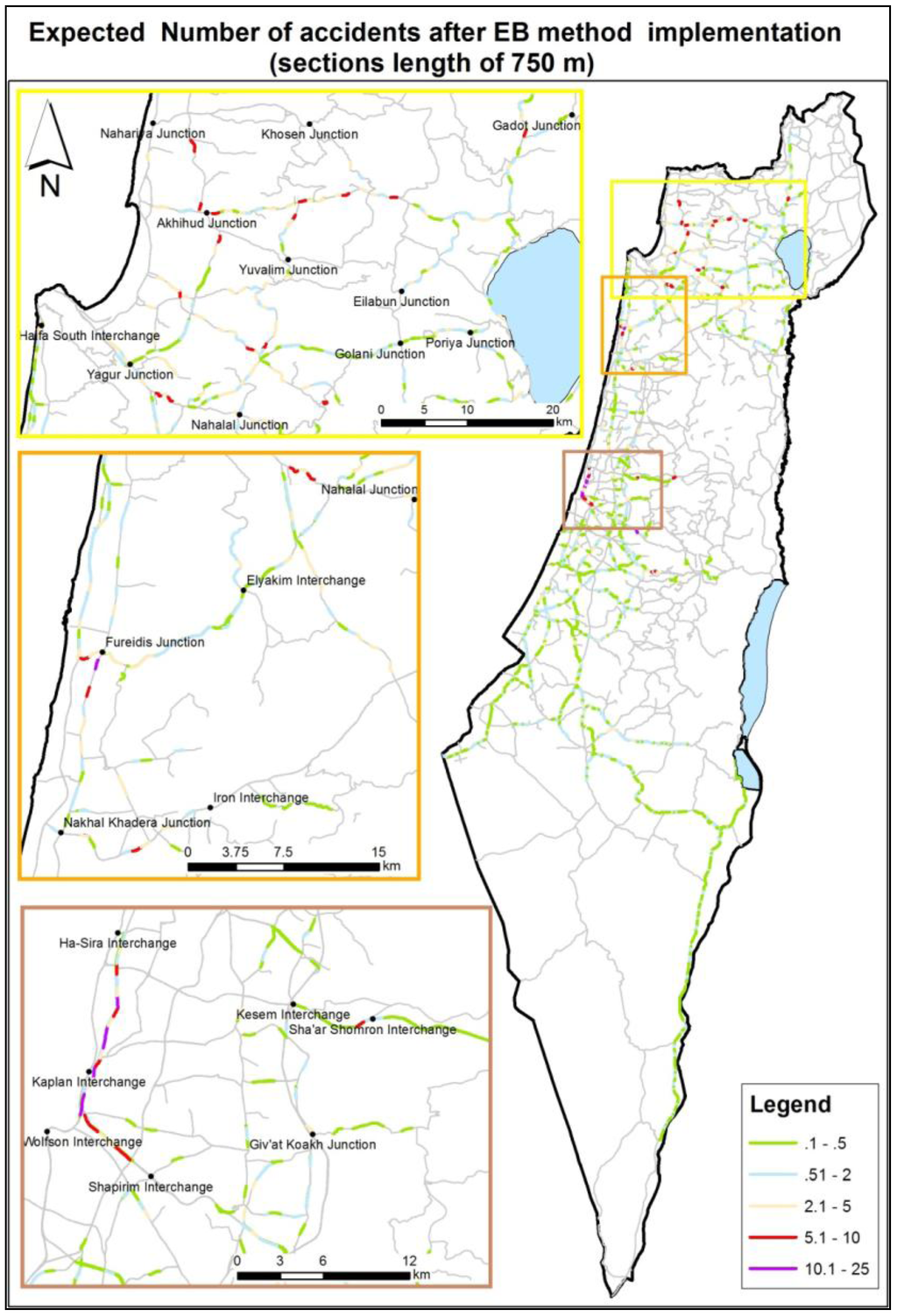
شکل 5 و شکل 6 برخی از خروجی های تحقیقاتی نهایی را نشان می دهد. نقشه ها تعداد مورد انتظار تصادفات در بخش های جاده را پس از مراحل تصحیح EB نمایش می دهند. دامنه تعداد تصادفات مورد انتظار با یک پالت رنگی، از سبز، که نشان دهنده بخش های جاده با تعداد تصادفات مورد انتظار کم است، تا قرمز و بنفش، که نشان دهنده بخش هایی با نرخ بالای تصادفات مورد انتظار است، نشان داده می شود. لازم به ذکر است که هنگام قرار دادن تصادفات در بخش های جاده، جهت با توجه به داده های CBS با وجود عدم دقت انتخاب شده است [ 23 ].]. منطق در اینجا این بود که از نظر پارامترهای فیزیکی جاده، می توان فرض کرد که بخش های جاده خطرناک از یک جهت در خط مخالف نیز خطرناک خواهند بود.
شکل 6. تعداد تصادفات مورد انتظار (مقاطع جاده به طول 750 متر).
4. تکرارپذیری و فرصت های مطالعات بیشتر
این مقاله توسعه مدلهای پیشبینی مبتنی بر GIS را برای ارزیابی تصادفات رانندگی در بخشهای بزرگراه، با استفاده از پارامترهای فضایی و مبتنی بر ترافیک تشریح کرد. یافته های این تحقیق مبنای و نقطه شروعی برای مطالعات متنوع دیگری در زمینه ایمنی راه ها می باشد. ابتدا و مهمتر از همه، پیشنهاد می شود کیفیت مدل بر روی داده های تصادفات سال های آینده بررسی شود. این مدل همچنین میتواند در سایر کشورها/مناطق و علاوه بر این، در بخشبندیهای مختلف مانند کلاسهای عملکردی جاده، پیکربندی خودرو، انواع تصادفها (مثلاً مواردی که شامل رانندگان مست هستند) و سطوح شدت تصادف (مثلاً کشنده، جراحت، و رویدادهای بدون آسیب). همچنین پیشنهاد میشود که همبستگی فضایی را با بررسی تأثیر بخشهای مجاور انجام دهید.
با توجه به یافته های تحقیق، تجزیه و تحلیل متغیر “منطقه” نرخ تصادفات مورد انتظار بسیار متمایز و نگران کننده ای را در منطقه شمالی ایجاد کرد. این امر به ویژه در منطقه فرعی غرب جلیل علیا متمایز است. همچنین یافته های اثبات شده تعامل بین متغیرهای “منطقه” و “حجم ترافیک” به طور قابل ملاحظه ای متمایز بود. نتیجه اینکه تأثیر «حجم ترافیک» بر میزان مورد انتظار تصادفات یکسان نیست و به منطقه نیز بستگی دارد. بنابراین، پیشنهاد میشود که متغیرهای «منطقه» و «زیر منطقه» را با دقت بیشتری بررسی کنیم و متغیرهای محیطی، اجتماعی-اقتصادی و اقتصادی را به مدل مرتبط کنیم. از جمله: سرمایه گذاری های زیرساختی، عرض شانه ها، جداسازی خطوط، تعداد خطوط و غیره.
پارامتر سرعت، همانطور که در این مطالعه ادغام شده است، تنها تخمین زده شد. برای ارزیابی دقیقتر این پارامتر در مطالعات آتی، لازم است دادههای سرعت دقیقتری به دست آوریم و ادغام شود. از این رو، در اینجا پیشنهاد می شود که داده های سرعت را از برنامه های ناوبری و گزارش های ترافیک بر اساس جامعه کاربر و تجزیه و تحلیل اثر سرعت در زمان های مختلف (روز و شب، روزهای هفته و آخر هفته و غیره) دریافت کنید.
ما معتقدیم که عرض شول و تعداد خطوط متغیرهای قابل توجهی از وجود تصادفات جاده ای هستند. این داده ها در حال حاضر آنطور که باید به طور مداوم و دقیق جمع آوری نمی شوند. دادههای دقیق برای هر دو این متغیرها با نتایج و مدلهای قابل اعتمادتری بهدست میآیند. علاوه بر این، دادههای جهتگیری حادثه که در این مطالعه غیرقابل اعتماد تلقی میشوند نیز توصیه میشود در مطالعات دیگر ضمن قرار دادن تصادف در محل وقوع آن، ادغام شوند.
5. نتیجه گیری ها
این مقاله توسعه یک مدل پیشبینی مبتنی بر GIS را برای ارزیابی تصادفات رانندگی در بخشهای بزرگراه، با استفاده از پارامترهای فضایی و مبتنی بر ترافیک تشریح کرد.
مهمترین و کاربردیترین «وحی» در این مطالعه این است که بخشهای کوتاه جاده پایدارترین مدلها را به دست میدهند. این اجازه می دهد تا درمان در بخش های کوتاه جاده را به عنوان راهی برای صرفه جویی در منابع و به طور بالقوه به دست آوردن حداکثر سود با حداقل سرمایه گذاری هدف قرار دهید. توانایی محدود کردن مناطق پرخطر به بخشهای جادهای خاص همچنین باعث میشود که تیمهای پلیس (و سایر) در آن بخشها برای نجات جان متمرکز شوند. مدلها با استفاده از روش بیز تجربی بهبود یافتند، که دقت ارزیابی را با در نظر گرفتن دادههای تاریخی و اصلاح سوگیریها از پدیده «رگرسیون به میانگین» افزایش داد. همچنین مشخص شد که مهمترین متغیرهای مؤثر بر میزان تصادفات عبارتند از: انحنای بخش جاده، منطقه و حجم ترافیک. علاوه بر این، یک تعامل بین منطقه و متغیرهای حجم ترافیک پیدا شد. این بدان معنی است که تأثیر حجم ترافیک بر میزان مورد انتظار تصادفات یکسان نیست و به منطقه نیز بستگی دارد. بررسی عمیق تر این موضوع احتمالاً یافته های بسیار جالبی را به دنبال خواهد داشت. طبقهبندی مجموعه دادهها بر اساس بخشهای جادهای با طولهای مختلف اما مساوی، امکان «خنثیسازی» پارامتر «طول قطعه» را فراهم کرد، که در بسیاری از مطالعات مشخص شد که پارامتر مهمی در مدل است. بررسی عمیق تر این موضوع احتمالاً یافته های بسیار جالبی را به دنبال خواهد داشت. طبقهبندی مجموعه دادهها بر اساس بخشهای جادهای با طولهای مختلف اما مساوی، امکان «خنثیسازی» پارامتر «طول قطعه» را فراهم کرد، که در بسیاری از مطالعات مشخص شد که پارامتر مهمی در مدل است. بررسی عمیق تر این موضوع احتمالاً یافته های بسیار جالبی را به دنبال خواهد داشت. طبقهبندی مجموعه دادهها بر اساس بخشهای جادهای با طولهای مختلف اما مساوی، امکان «خنثیسازی» پارامتر «طول قطعه» را فراهم کرد، که در بسیاری از مطالعات مشخص شد که پارامتر مهمی در مدل است.
این مطالعه بار دیگر قدرت و مزایای استفاده از سیستم های اطلاعات جغرافیایی (GIS) در زمینه ایمنی راه (GIS-T) را تایید می کند. این رویکرد امکان نمایش و بررسی داده ها را در فضای “واقعی” ( به عنوان مثال ، مکان فیزیکی که رویدادها در آن رخ می دهد)، تکرار، و انجام تحلیل های آماری-مکانی پیچیده به روشی نسبتا ساده را می دهد.






بدون نظر