

خلاصه
مدل ذخیره سازی فیزیکی یکی از فناوری های کلیدی برای نقشه های ناوبری وسایل نقلیه است که در یک سیستم ناوبری استفاده می شود. با این حال، عملکرد اکثر مدلهای ذخیرهسازی سنتی در ناوبری پویا به دلیل فرمت ذخیرهسازی استاتیکی که استفاده میکنند، محدود است. در این مقاله، ما یک مدل ذخیره سازی فیزیکی جدید، فرمت داده ناوبری چین (CNDF) را پیشنهاد کردیم که به دسترسی و به روز رسانی داده های ناوبری کمک کرد. مدل CNDF از روش سلسله مراتبی مبتنی بر دسترسی برای ساخت یک شبکه سلسله مراتبی جاده استفاده کرد که کارایی فشرده سازی داده ها را افزایش داد. همچنین از روش کدگذاری لینک خطی استفاده کرد که در آن موقعیت شروع با موقعیت پایانی به عنوان کد شناسایی پیوندهای چند سطحی ترکیب میشد و هر پیوند پیوندهای سطح بالا را به طور مداوم بدون ثبت آرایه شناساییها ردیابی میکرد. نقشه ناوبری شرق چین (شامل پکن، تیانجین، شاندونگ، هبی و جیانگ سو) در ساعت 1:10000، که با استفاده از مدل CNDF ایجاد شد، و اطلاعات ترافیک زمان واقعی در پکن برای آزمایش عملکرد یک سیستم ناوبری با استفاده از یک دستگاه ناوبری تعبیه شده نتایج نشان داد که هر بار به روز کردن نقشه ناوبری کمتر از 1 ثانیه هزینه داشت و دقت الگوریتم کوتاهترین مسیر سلسله مراتبی 99.9٪ بود. کار ما نشان داد که مدل CNDF در کاربردهای ناوبری خودرو کارآمد است. نتایج نشان داد که هر بار به روز کردن نقشه ناوبری کمتر از 1 ثانیه هزینه داشت و دقت الگوریتم کوتاهترین مسیر سلسله مراتبی 99.9٪ بود. کار ما نشان داد که مدل CNDF در کاربردهای ناوبری خودرو کارآمد است. نتایج نشان داد که هر بار به روز کردن نقشه ناوبری کمتر از 1 ثانیه هزینه داشت و دقت الگوریتم کوتاهترین مسیر سلسله مراتبی 99.9٪ بود. کار ما نشان داد که مدل CNDF در کاربردهای ناوبری خودرو کارآمد است.
کلید واژه ها:
نقشه های ناوبری پویا ; فرمت ذخیره سازی فیزیکی ؛ شبکه سلسله مراتبی مبتنی بر دسترسی کدگذاری لینک خطی
1. معرفی
فرمت ذخیره سازی فیزیکی (PSF) نقشه های ناوبری یکی از فناوری های کلیدی برای سیستم های ناوبری خودرو است. هدف آن بازسازی ساختار داده های مکانی برای برآوردن الزامات ناوبری وسیله نقلیه است. برخی از شرکت ها و سازمان های بزرگ PSF خود را برای محصولات ناوبری پیشنهاد کرده اند ( جدول 1 ).
زمانی که فرمت PSF در ابتدا پیشنهاد شد، نگرانی اصلی برای دستگاههای آنبورد نحوه دسترسی سریع به دادههای ناوبری به دلیل عملکرد ضعیف دستگاه بود. بنابراین، تعداد زیادی مدل PSF ثابت برای تسهیل دسترسی به داده ها توسعه داده شد. مدلهای استاتیک برای رسانههای ذخیرهسازی فقط خواندنی استفاده میشد که در میان آنها مدلهای SDAL و KIWI مدلهای معرف آن زمان بودند.
SDAL یک مدل PSF است که توسط NAVTEQ Corporation [ 1 ] توسعه یافته است. از شاخص درختی KD جهانی برای مدیریت داده های مکانی و داده های توپولوژی در یک ساختار چند مقیاسی استفاده می کند. دادههای مکانی و دادههای توپولوژی توسط بستههایی با توجه به مستطیل مرز فضایی گرههای KD-tree ذخیره میشوند. بسته عنصر اساسی برای دسترسی به داده است. بنابراین، کنترل سربار حافظه در تحلیل مسیر دشوار است، زیرا شعاع جستجو به دلیل سبک ذخیره سازی داده های فضایی و توپولوژی مورد استفاده توسط SDAL قابل ثبت نیست. علاوه بر این، SDAL از آدرس فیزیکی برای مرتبط کردن همه داده ها استفاده می کند، که نشان می دهد به روز رسانی داده ها را پشتیبانی نمی کند.
KIWI یکی دیگر از مدل های PSF محبوب است که برای ناوبری وسایل نقلیه استفاده می شود [ 2]. این اولین بار توسط انجمن KIWI ژاپن توسعه یافت و سپس به یک استاندارد صنعتی منتشر شده در ژاپن تبدیل شد. عنصر اصلی KIWI چارچوب داده است. همه فریمهای دادههای مکانی توسط شبکههای متنوعی که توسط یک شاخص شبکه سلسله مراتبی تعریف شدهاند، خوشهبندی میشوند. دادههای مکانی و دادههای توپولوژی در KIWI توسط Region تقسیم میشوند، یک زیرگراف از پیش پردازش شده که اتصال کامل را برای کنترل فضای جستجو برآورده میکند. بنابراین، KIWI مشکل کنترل کران جستجو را که SDAL با آن مواجه است حل کرده است. با این حال، سلسله مراتب در KIWI بر اساس انواع خیابان تعیین میشود، که نیاز به تنظیم دستی دادهها برای معاوضه بین سرعت محاسبات و زیر بهینه بودن مسیرهای محاسبهشده دارد. علاوه بر SDAL و KIWI، ISO TC204/WG3 استاندارد جهانی PSF را پیشنهاد کرده است [ 3 ].
مدلهای استاتیک PSF دو نقص عمده را نشان میدهند که مانع از کاربرد آنها در ناوبری پویا خودرو میشود. اول، مدلهای ذخیرهسازی آنها برای حالت دسترسی فقط خواندنی طراحی شدهاند، که اجازه بهروزرسانی دادهها را نمیدهد. دوم، روشهای سلسله مراتبی آنها مبتنی بر طبقات جادههای طبیعی است که نمیتوانند سازگاری شبکههای جادهای را با قضایای ریاضی حفظ کنند. برای حل مشکلات و همچنین حفظ نسبت موفقیت آمیز خروجی برنامه ریزی مسیر، چندین روند مصنوعی در طول فرآیند تدوین باید فراخوانی شود. با این حال، نرم افزار کامپایل برای مدل های PSF ایستا بسیار پیچیده است و با برنامه های ناوبری پویا سازگار نیست.
بنابراین، توسعه مدل های پویا PSF برای نقشه های ناوبری ضروری است. برای طراحی مدل های PSF پویا با کارایی بالا، باید برخی مسائل را در نظر گرفت. به عنوان مثال، مقدار زیاد داده های مکانی با ذخیره سازی محدود دیسک دستگاه های ناوبری متناقض است. الزامات پاسخ زمان واقعی برای ترسیم مجدد فشرده نقشه های ناوبری به دلیل ظرفیت حافظه ضعیف تجهیزات ناوبری محدود شده است. علاوه بر این، پیچیدگی بالای الگوریتمهای تحلیل کوتاهترین مسیر ممکن است با توجه به ظرفیت ضعیف عملیات ممیز شناور و سرعت محاسبات محدود امکانات ناوبری بیاثر باشد.
توسعه فناوری ارتباطات، تولید مدلهای پویا PSF را ارتقا داده است. محتوای تحقیقاتی کلیدی برای توسعه مدلهای PSF پویا، پیادهسازی روشهای بهروزرسانی برای دادههای ناوبری محلی است. روش های به روز رسانی را می توان به روش های به روز رسانی جایگزین یا روش های به روز رسانی افزایشی تقسیم کرد. برای روشهای جایگزینی بهروزرسانی، مانند i-Format ژاپنی، دادههای ناوبری محلی هر بار با دانلود نسخه نقشه جدید بهروزرسانی میشوند، زیرا حافظه پنهان مشتریان تلفن همراه یا جاسازیشده قرار است کوچک باشد. بنابراین، در هنگام استفاده از روش های به روز رسانی جایگزین، هزینه های ترافیکی زیادی را به همراه خواهد داشت.
برای روشهای بهروزرسانی افزایشی، بهروزرسانی دادههای ناوبری محلی هر بار بر بهروزرسانی و اصلاح رکوردهایی که باید منتقل و به دادهها اضافه میشد، متمرکز بود. با این حال، تغییر داده های محلی با جفت بالا و تضمین سرعت بالای دسترسی به داده ها به طور همزمان چالش برانگیز است. محققان بر بهبود روشهای اساسی تمرکز کردهاند و چندین مدل کاربردی ارائه کردهاند [ 4 ، 5 ، 6 ، 7 ، 8 ]. به عنوان مثال، Xu یک سیستم اطلاعات ترافیکی خودسازمانده و توزیع شده بر اساس تبادل اطلاعات خودرو به وسیله نقلیه برای بهینه سازی مسیر مدلسازی کرد [ 4]]. سیستم مرجع خطی و بخش دینامیک (LRS&DS) به عنوان مدل اولیه برای مدیریت اطلاعات ترافیک پویا، مانند اطلاعات ترافیک بلادرنگ، در نظر گرفته میشود که برای ناوبری پویا ضروری است.
در این مقاله، ما یک مدل PSF جدید، یعنی، فرمت داده ناوبری چین (CNDF)، برای داده های فضایی مورد استفاده توسط ناوبری پویا. از روش کدگذاری لینک خطی استفاده می کند که در ذخیره سازی دیسک برای به روز رسانی اطلاعات ترافیک بلادرنگ موثر است و از نقشه برداری سریع سلسله مراتبی سوابق پشتیبانی می کند. مدل شبکه اقتباس شده از الگوریتم LRS&DS توسط CNDF برای کدگذاری پیوند مدل شبکه مبتنی بر دسترسی سلسله مراتبی استفاده شد. مدل ما قابلیت تسریع برنامه ریزی مسیر را با استفاده از یک شبکه سلسله مراتبی دارد. همچنین قادر است رکوردهای هدف را به سرعت در هر سطح از شبکه جاده ترسیم کند و رکوردهای مرتبط را مجددا تنظیم کند تا از سازگاری سلسله مراتبی مدل پس از به روز رسانی داده ها اطمینان حاصل کند. بنابراین، مدل پویا PSF، CNDF، می تواند برای به روز رسانی های افزایشی استفاده شود.
CNDF بررسی کمیته مدیریت استاندارد ملی را گذرانده است و به عنوان یک استاندارد ملی رسما منتشر خواهد شد. استاندارد ملی با استاندارد موجود ISO 20452 تدوین شده است، اما شرایط خاص ناوبری در چین را نیز در نظر می گیرد، از جمله حجم عظیم داده، سرعت سریع ساخت و ساز جاده، قوانین و مقررات حمل و نقل، عادت نام مکان ها، و مشخصات داده های اساسی در بخش 2 ، ساختار و اجرای آن را نشان می دهیم. بخش 3 یک آزمایش و نتایج مربوطه را با استفاده از CNDF برای نقشههای ناوبری شرق چین در یک دستگاه ناوبری نشان میدهد. بخش 4شامل نتیجه گیری است کار ما نشان داد که مدل CNDF برای ناوبری پویا کارآمد است.
2. روش شناسی
در این بخش، فناوریهای کلیدی مورد استفاده برای توسعه مدل CNDF، از جمله ساختار فیزیکی دادههای مکانی، مدل محاسباتی برای تحلیل مسیر، و مکانیسم بهروزرسانی دادهها را نشان میدهیم.
2.1. ساختار مدل CNDF
2.1.1. شاخص شبکه چند مقیاسی
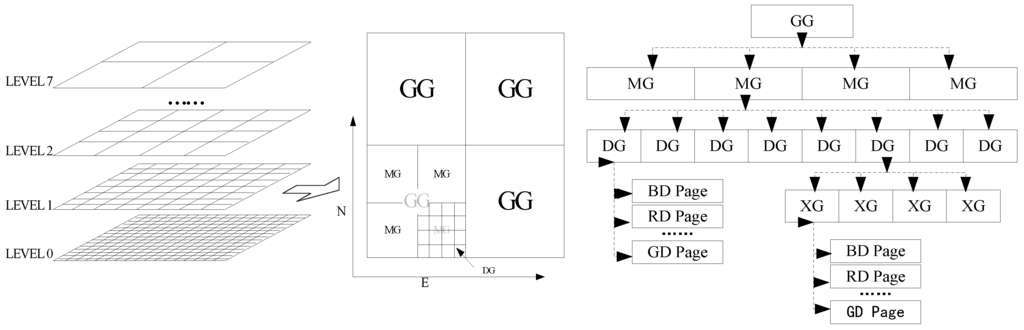
داده های مکانی با استفاده از مدل CNDF توسط شبکه های چند مقیاسی خوشه بندی می شوند. همه شبکه ها توسط شاخص شبکه چند مقیاسی (MSG) نمایه می شوند. MSG از گروه هایی از شاخص های شبکه سطح (LG) تشکیل شده است و هر LG داده ها را در مقیاس خاصی مدیریت می کند ( شکل 1 ). LG یک نوع چهار درختی است [ 9]. شبکههای الجی به چهار رتبه مختلف تقسیم میشوند که شامل یک شبکه عمومی (GG)، شبکه میانی (MG)، شبکه دقیق (DG) و شبکه گسترده (XG) میشود. عرض (یا ارتفاع) شبکه در همان رتبه معادل است. DG گره های برگ LG است و داده های مکانی در یک مقیاس خاص توسط DG در صفحات دسته بندی می شوند. در برخی مکانها، اندازه دادهها ممکن است سرریز شود، به عنوان مثال، CBD در شهرهای بزرگ. در این مورد، MSG به DG اجازه می دهد تا بیشتر به XG های کوچکتر تقسیم شود. برای پرس و جوهای فضایی، آدرس صفحات هدف را می توان با جستجوی مسیر از GG به DG (حتی به XG) که از مرزهای پرس و جو عبور می کند، پیدا کرد.
MSG به سه دلیل برای سیستم ناوبری مناسب است. اول، MSG فشرده است، که نیازی به اطمینان از حداقل مرز مستطیل (MRB) در گره های برگ (DG یا XG) ندارد. عرض شبکه (یا ارتفاع) هر رتبه را می توان توسط شبکه مرجع (پایین ترین سطح DG) با استفاده از رابطه (1) محاسبه کرد. ثانیا، MSG یک شاخص عملکرد بالا است. این β را تنظیم می کند که با 2 n ( n≥ 0) نشان داده شده است، که از عملیات نقطه شناور برای یک پرس و جو فضایی جلوگیری می کند. علاوه بر این، MSG نزدیک به متعادل شدن است. در نهایت، MSG دارای شاخص ظرفیت بالایی است. فرض کنید M ظرفیت یک LG منفرد را نشان می دهد، جایی که Μ = α 2 × β 2 × γ 2× حداکثر اندازه صفحه (MPS). اگر MPS = 64 KB، و α = β = γ = 16، M = 1 TB. بنابراین، ظرفیت MSG برای مدیریت داده های مکانی که مناطق وسیعی را پوشش می دهد کافی است.
wمن=w0 ∏منk = 1βک، ساعتمن= ساعت0 ∏منk = 1βمن, i > 0 �من=�0 ∏ک=1من�ک، ساعتمن= ساعت0 ∏ک=1من�من، من>0
که در آن w و h به ترتیب نشان دهنده عرض و ارتفاع شبکه هستند و β نشان دهنده نسبت بین دو رتبه مجاور است.
2.1.2. ساختار منطقی مدل CNDF
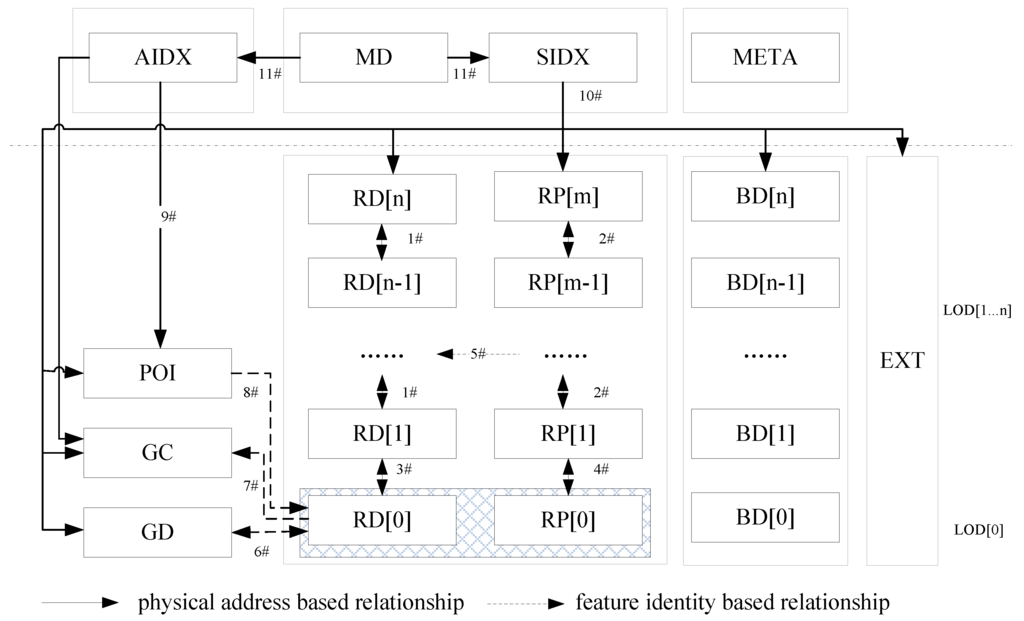
شکل 2 ساختار منطقی مدل CNDF را نشان می دهد. دادههای مکانی با استفاده از CNDF شامل دادههای پسزمینه چند سطحی (DB)، دادههای جاده چند سطحی برای اهداف نمایش (RD)، دادههای جاده چند سطحی برای برنامهریزی مسیر (RP)، دادههای راهنمایی راننده (GD)، دادههای کدگذاری جغرافیایی است. (GC) و داده های نشانه زمین (POI). داده های مدیریتی شامل داده های مدیریت حجم (MD)، شاخص فضایی (SIDX) و شاخص ویژگی (AIDX) است.
تمام دادههای مکانی بر اساس مقیاسهایشان توسط شاخص MSG سازماندهی و نمایهسازی میشوند. هر گره برگ MSG به گروهی از صفحات که توسط یک مستطیل تعریف شده اند اشاره می کند. هر پیوند از شبکه جاده دارای یک کد هویت منحصر به فرد است که از تگ گره شروع و تگ گره پایانی اختصاص داده شده توسط روش کدگذاری پیوند خطی (LLC) تشکیل شده است. روش LLC در ضمیمه A نشان داده شده است. به این ترتیب، یک رابطه نگاشت مفهومی بر روی پیوندهایی در چند سطح که یک بخش جاده را نشان می دهد ساخته می شود.
برنامه ها می توانند رکوردهای ذخیره شده در مکان های مختلف را بر اساس رابطه سلسله مراتبی ردیابی کنند. LLC آدرس فیزیکی فرار مرتبط با داده ها را ثبت نمی کند، اما رابطه را ذخیره می کند. ذخیره یک آدرس فیزیکی برای حفظ رابطه توپولوژی صحیح داده ها دشوار است، زیرا اصلاح یا به روز رسانی داده ها ممکن است منجر به موانع شود [ 10 ]. رابطه نگاشت سلسله مراتبی بین سطوح در کد LLC دخیل است. در مقایسه با روش ذخیرهسازی روابط با ثبت تمام شماره هویت پیوندها بین سطوح بالا و پایین، CNDF میتواند افزونگی دادهها را کاهش داده و با استفاده از LLC ذخیرهسازی دیسک را ذخیره کند.
ساختار دادههای CNDF از طریق اتخاذ استراتژی مبتنی بر دسترسی، کارآمد و انعطافپذیر است، زیرا متریک دسترسی، دانش اکتشافی است که از یک قضیه ریاضی بهجای یک مقدار تجربی مشتق شده است. محدوده تنظیم مجدد در بخش 2.2.3 ارزیابی شده است ، که ثابت می کند هزینه زمانی برای به روز رسانی پیوند در CNDF همگرا است. علاوه بر این، سازگاری داده ها پس از به روز رسانی پیوند را می توان حفظ کرد.
2.1.3. ساختار فیزیکی مدل CNDF
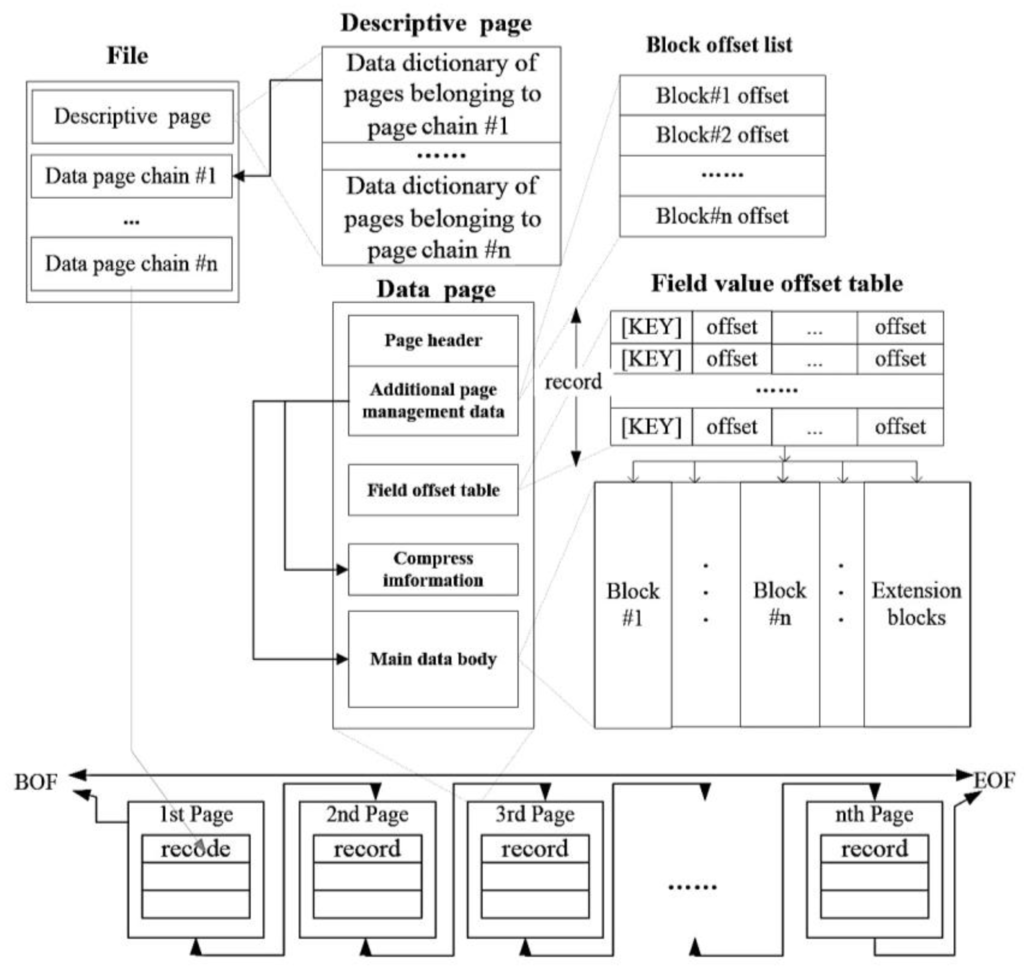
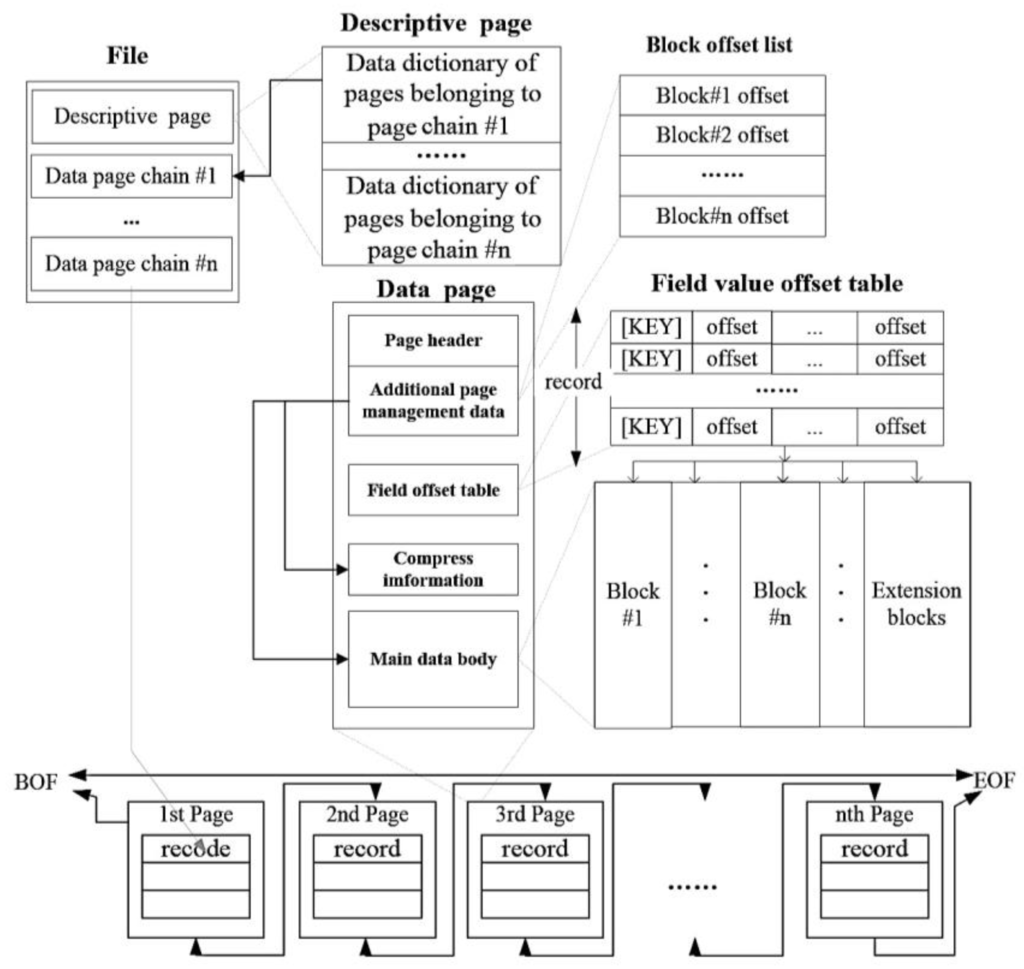
شکل 3 ساختار فیزیکی مدل CNDF شامل فایل، صفحه و بلوک را نشان می دهد. فایل حاوی صفحات است. دادههای مکانی و دادههای غیرمکانی در صفحاتی با استراتژیهای مختلف خوشهبندی میشوند. داده های مکانی با استفاده از شبکه های متنوع تعریف شده توسط MSG خوشه بندی می شوند. داده های غیرمکانی بر اساس ترتیب کلید اصلی آنها در صفحات تقسیم می شوند.
صفحات از یک هدر صفحه و چندین بلوک تشکیل شده اند. هدر صفحه اطلاعات لازم مربوط به ساختار صفحه را ثبت می کند، از جمله پرچم فشرده سازی، شماره بلوک و آفست بلوک از ابتدای صفحه. سرصفحه صفحه همچنین دو نشانگر آدرس را اختصاص می دهد که برای ذخیره صفحه قبلی و صفحه حاصل استفاده می شود. به این ترتیب، همه صفحات یک زنجیره تشکیل می دهند و بهینه سازی درج صفحه تحت محدودیت حفظ ترتیب رکورد. اولین بلوک صفحه جدول افست است که برای ذخیره افست هر فیلد استفاده می شود. زمانی که فیلد طولانی شد، جدول به همان نسبت به روز می شود. رکوردها در CNDF به ترتیب ردیف هستند که با سایر PSF ها متفاوت است. رکوردها به ترتیب ردیف می توانند از خواندن فیلدهای غیر ضروری در حافظه جلوگیری کنند. در CNDF، اندازه صفحه در MPS به 128 کیلوبایت محدود شده است.
2.2. مدلهای محاسبه مسیر مدل CNDF
بسیاری از مطالعات بر روی الگوریتمهای تحلیل مسیر بهینه مناسب برای ناوبری وسایل نقلیه متمرکز شدهاند و بیشتر آنها بر ساختار توپولوژیکی خاصی از شبکه جادهها تکیه دارند [ 11 ، 12 ، 13 ، 14 ]. به عنوان مثال، شبکه سلسله مراتب جاده های طبیعی نوعی ساختار توپولوژیکی است که توسط مدل های شبکه سلسله مراتبی استفاده می شود و برای کاربردهای ناوبری محبوب است. با این حال، نیاز به تنظیم دستی داده ها دارد و عملکرد آن به یک مبادله ظریف بین سرعت محاسبات و زیر بهینه بودن مسیرهای محاسبه شده بستگی دارد. از آنجایی که طبقات جادههای ارجاعشده بهطور مصنوعی بر اساس تجربه تعریف میشوند، جستجوی مسیر بر اساس شبکه سلسلهمراتبی جادههای طبیعی تنها میتواند راهحلهای تقریبی را ارائه دهد.
شبکه های سلسله مراتبی جاده های طبیعی نیز برای به روز رسانی داده های پویا مناسب نیستند. جستجوی مسیر ممکن است در صورت تغییر یا عدم نگهداری داده ها شکست بخورد. بنابراین عملیات تعمیر و نگهداری برای مدل های شبکه سلسله مراتبی با استفاده از شبکه های سلسله مراتب جاده طبیعی ضروری است. هدف عملیات تعمیر و نگهداری، حفظ محدودیتهای شبکههای جادهای است که توسط مدلها از پیش تعریف شدهاند، مانند محدودیتهای اتصال و جستجو، زیرا در صورت اصلاح شبکه جاده، محدودیتها ممکن است تغییر کرده یا حتی نامعتبر باشند. علاوه بر این، هیچ روش ریاضی برای ارزیابی عملکرد عملیات تعمیر و نگهداری استفاده نمیشود و هزینه غیرقابل پیشبینی و گرانقیمت، به یک مانع بزرگ برای بهروزرسانیهای پویا داده تبدیل میشود.
بنابراین، ما شبکه سلسله مراتبی مبتنی بر دسترسی را با الهام از الگوریتم جستجوی مسیر اکتشافی مبتنی بر دسترسی ساختیم. در بخش بعدی، شبکه سلسله مراتبی مبتنی بر دسترسی را تعریف میکنیم و الگوریتم تحلیل کوتاهترین مسیر را بر اساس شبکه پیشنهاد میکنیم، و همچنین در مورد ارزیابی محدوده تنظیم مجدد بحث میکنیم.
2.2.1. شبکه سلسله مراتبی مبتنی بر دسترسی
تعریف ریاضی دسترسی توسط [ 15 و 16 ] ارائه شد. با محاسبه مقدار دسترسی هر پیوند از شبکه راه ورودی، مقادیر دسترسی را می توان با استفاده از رابطه (2) به گروه های دنباله ای تقسیم کرد. شبکه جاده در سطح i با پیوندهایی بازسازی می شود که r ( e ) ≥ rمنm i n�مترمن�من، و ساده تر از آن در سطح ( i-1 ) است. بخشی از رکوردهای یک سطح برای ذخیره رابطه با رکوردهای مربوطه در سطح بالای آن استفاده می شود. به این ترتیب، توپولوژی چند سطحی ساخته می شود.
R L = { آرمن | آرمن= { r | rمنm i n≤ r ( e ) ≤ rمنm a x} },i=0,1,…,n−1 آر�= {آرمن | آرمن={� | �مترمن�من≤�(ه) ≤ �مترآایکسمن}}، من=0، 1، …، �–1
که در آن RL سطوح تعریف شده توسط گروه های توالی را نشان می دهد. R i نشان دهنده گروه مقدار دسترسی در سطح i است . rمنm i n�مترمن�منو rمنm a x�مترآایکسمننشان دهنده حداقل و حداکثر مقدار دسترسی، به ترتیب، در سطح i . و r(e) مقدار دسترسی پیوند e را نشان می دهد .
جستجوی مسیر با استفاده از مدل سلسله مراتبی مبتنی بر دسترسی مؤثرتر از مقادیر دسترسی تخصیص یافته به مدل تک سطحی به عنوان اطلاعات سلسله مراتبی است، زیرا تعداد پیوندها با افزایش سطوح به شدت کاهش می یابد. برای دستگاه های ناوبری با CPU کم سرعت و حافظه محدود بسیار مفید است. تعیین RL برای بهینه سازی مدل مهم است. افزونگی نقشه ناوبری به طور مستقیم با تعداد کل سطوح متناسب است. با این حال، سرعت همگرایی الگوریتم به طور متنوعی با تفاوت بین آنها متناسب است rمنm i n�مترمن�منو rمنm a x�مترآایکسمن.
2.2.2. الگوریتم کوتاهترین مسیر سلسله مراتبی مبتنی بر دسترسی
جستجو در یک سطح در الگوریتم کوتاهترین مسیر سلسله مراتبی مبتنی بر دسترسی (RHSP) مشابه الگوریتم دایکسترا است. در الگوریتم Dijkstra، کوتاهترین درخت به گونهای رشد میکند که کوتاهترین مسیرها از گره شروع به تمام گرههای دیگر را در بر بگیرد. در طول فرآیند رشد، هر گره با “Unfound”، “Found” یا “OnPath” مشخص می شود. جدول 2 دو مرحله جستجوی چند سطحی را نشان می دهد، یعنی جستجوی صعودی و جستجوی رو به پایین. جستجوی صعودی اولین مرحله است که می تواند با توجه به شبه کد نشان داده شده در خط (3) تا خط (15) در جدول 2 پیاده سازی شود . در جستجوی رو به بالا، محدوده دسترسی به طور مکرر افزایش می یابد، بنابراین تمام گره های با b i ≥ r ( v) ≥ m ( s, v, P ) 1 را می توان تضمین کرد که در سطح i شبکه جاده در بدترین وضعیت علامت گذاری می شود. جستجوی رو به پایین مرحله دوم است که می تواند با توجه به شبه کد نشان داده شده در ردیف (16) تا (26) در جدول 2 پیاده سازی شود . در جستجوی رو به پایین، محدوده دسترسی به طور مکرر کاهش می یابد. همه گرهها با b i ≥ r ( v ) ≥ d ( v, t ) 2 را میتوان تضمین کرد که در سطح i شبکه جادهای در بهترین وضعیت علامتگذاری میشوند.
ما می توانیم خواصی را استنباط کنیم که منجر به RHSP بهینه می شود.
تمام گره های روی P باید با RHSP “OnPath” علامت گذاری شوند. با توجه به لیست گره های V < v 1 , v 2 , v 3 … v n > در P , V را می توان به دو زیر مجموعه تقسیم کرد: V 1 = { u | r ( u , P ) = m ( s , u , P )} و V 2 = { v | r ( v ، P) = m ( v ، t ، P )}. در V 1 ، برای r ( u ، P ) ≤ r ( u )، m ( s ، u ، P ) ≤ r ( u ) داریم . به طور مشابه در V 2 ، برای d ( v ، t ) ≤ m ( v ، t ، P )، ما d ( v ، t) داریم.) ≤ r ( v ). بنابراین می توان گره های V 1 را در جستجوی رو به بالا و گره های V 2 را ابتدا در TT ثبت و سپس در جستجوی رو به پایین علامت گذاری کرد.
تمام گره هایی که توسط RHSP علامت گذاری نشده اند باید در مسیر P نباشند . فرض کنید که گره w روی P با RHSP مشخص نشده است، بنابراین m ( s , w , P ) > r ( w ) و d ( w , t ) > r ( w ). از آنجایی که r ( w ) < Min { m ( s , w , P ), d ( s , w ,t )} ≤ { m ( s ، w ، P )، m ( w ، t ، P )} = r ( w ، P )، که با r ( w ) ≥ r ( w ، P ) در تضاد است، بنابراین w ندارد وجود داشته باشد. بنابراین، نتیجه RHSP بهینه است. در مقایسه با جستجو در سطح پایین، الگوریتم RHSP زمان “ExtraMin” را در جستجو در سطح بالاتر کاهش می دهد، زیرا گره هایی با دسترسی کم در سطح پایین انتزاع می شوند.
علاوه بر این، هزینه حافظه RHSP نیز قابل ارزیابی است. فرض کنید که M i تعداد گره های واقع در چرخه با شعاع برابر با کران دسترسی سطح i است و N تعداد گره های سطح بالای سطح i است ، بنابراین تعداد گره کران بالایی در Heap درج می شود. ( یعنی O ( C ) ) را می توان با رابطه (3) محاسبه کرد.
O ( C) ≤ ∑n – 1i = 02ممن+ نO(سی)≤ ∑من=0�–12ممن+ن
2.2.3. ارزیابی دامنه تنظیم مجدد
فاصله مسیر به عنوان پارامتر طبقه بندی در شبکه سلسله مراتبی مبتنی بر دسترسی در نظر گرفته می شود. شبکه راه به صورت یک نمودار مسطح در نظر گرفته شده است. پیوند داده شده ( u ، v ) با m ( u ، v ) ≥ d ( u ، v )، که در آن d ( u ، v ) فاصله اقلیدسی بین دو گره است و m نشان دهنده طول مسیر از پیوند u تا پیوند v است ، ما می توانید اموال زیر را استنباط کنید.
e ( u , v ) و e’ ( u’ , v ‘ ) وجود دارند و r ( e ) را برآورده می کنند. rمنm a x�مترآایکسمنو d ( e’ , e ) > rمنm a x�مترآایکسمن. اگر هزینه e’ تغییر کند و r ( e ) بدون تغییر باقی بماند، d ( e’ , e ) حداقل مقدار در { d ( u , v’ ), d ( u’ , v ), d ( u’) است . u )، d ( v ، v’ )}.
با توجه به تعریف دسترسی، با توجه به یک گراف جهتدار G = ( V , E ) با وزنهای مثبت، مسیر P از G که از گره s شروع میشود و به گره t ختم میشود ، و گره v در مسیر P ، میتوان نتیجه گرفت که دسترسی به v روی P ( یعنی r ( v , P )) حداقل { m ( s ، v ، P )، m ( v ، t است .، P )}، و دسترسی به v در G ( یعنی r ( v ، G )) حداکثر r ( v ، Q ) است، که در آن Q مجموعه ای از مسیرهای کم هزینه متقاطع گره v است ، و دسترسی به پیوند e ( u ، v ) حداقل { r ( u )، r ( v )} است.
اگر e’ ∉ Q ( e ) بعد از هزینه e’ تغییر کند، آنگاه دسترسی e تحت تأثیر هزینه e’ قرار نمی گیرد .
اگر e’ ∈ Q ( e ) پس از تغییر هزینه e’ ، باید حداکثر مسیر هزینه P ( s , t ) از Q ( e ) باشد تا e’ , e ∈ P , فرض کنیم m ( v , t ) = m ( v ، u’ ، P ) + m ( u’ ، t ، P ). زیرا m ( v ,t ) ≥ d ( e’ , e ) > rمنm a x�مترآایکسمن, m ( v , t ) ≥ rمنm a x�مترآایکسمن. سپس به صورت r ( e ) < rمنm a x�مترآایکسمن, r ( e ) = r ( u ) = m ( s , u ) < m ( u , t ). حتی اگر هزینه e’ تغییر کرده باشد، باز هم m ( v , t ) ≥ d ( e’ , e ) > را برآورده می کندrمنm a x�مترآایکسمن. بنابراین، r ( e ) برابر با r ( u ) همچنان بدون تغییر است. فرض کنید m ( u , t ) = m ( s , v’ , P ) + m ( v’ , u , P ); اثبات همان شرح فوق است. بنابراین، هزینه e’ تغییر می کند، r ( e ) بدون تغییر است.
با توجه به ویژگی، دامنه محبت تغییر پیوند با دسترسی به سطح محدود می شود. بنابراین، مجموعه پیوند تنظیم مجدد تعریف می شود و به طور همزمان مقدار دسترسی را تغییر می دهد، زمانی که هزینه پیوند e با UE ( e ) تغییر می کند، که در آن UE = { e’ | d ( e’ ، e )< rمنm a x�مترآایکسمن} ( شکل 4 ).
عملیات تنظیم مجدد پایین به بالا RHSP با استفاده از یک الگوریتم تکراری پیاده سازی می شود. در یک لایه، مقدار دسترسی هر پیوند در اطراف پیوند اصلاح شده راضی کننده d ( e ‘ , e ) < rمنm a x�مترآایکسمندوباره محاسبه می شود. اگر دسترسی لینک افزایش یابد و بیشتر شود rمنm a x�مترآایکسمن(یکی از محدوده های دسترسی لایه) پس از تنظیم، پیوند در لایه بالایی لایه کپی می شود. اگر دسترسی لینک کاهش یابد و پایین بیاید rمن – 1m a x�مترآایکسمن–1(یکی از محدوده های دسترسی لایه)، پیوند به لایه پایین لایه اختصاص داده می شود.
در مقایسه با شبکه سلسله مراتبی که به طور مصنوعی بر اساس کلاس طبیعی جاده تعریف شده است، شبکه جاده سلسله مراتبی مبتنی بر دسترسی (RHN) به دلیل عملیات تنظیم مجدد پس از به روز رسانی داده های جاده سازگار است. فرض کنید هزینه زمانی تنظیم مجدد O ( Σ | UE i |) و | است UE i | تعداد پیوندهایی است که d ( e’ , e ) < را برآورده می کندrمنm a x�مترآایکسمن. محدوده دسترسی با سطوح افزایش می یابد، اما اندازه کل شبکه کاهش می یابد. بنابراین، O ( Σ | UE i |) را می توان به عنوان O ( N · C ) توصیف کرد ، که در آن N تعداد کل RHN است، و C حداقل ثابت با C ≥ | UE i |. یعنی عملیات تنظیم مجدد همگرا است.
2.3. مکانیسم به روز رسانی داده مدل CNDF
یک روش به روز رسانی افزایشی داده برای به روز رسانی نقشه های ناوبری محلی هنگام دریافت نسخه جدید داده استفاده می شود. اگر یک سطح از شبکه جاده اصلاح شود، به دلیل طراحی چند سطحی شبکه، سطوح دیگر باید تغییر کنند تا داده ها ثابت بماند. بنابراین، روشهای بهروزرسانی برای دادههای ناوبری باید نه تنها کارایی مکانیسم بهروزرسانی، بلکه نگهداری مداوم پس از بهروزرسانی دادهها را نیز در نظر بگیرد.
2.3.1. مکانیسم به روز رسانی برای داده های ناوبری
صفحه عنصر اساسی برای به روز رسانی داده ها است. صفحه ابتدا در حافظه بارگذاری می شود و اگر اندازه آن از MPS بیشتر شود، پارتیشن بندی می شود. سپس، آن را تغییر داده و دوباره به دیسک بازنویسی می کند. هنگامی که بر روی دیسک نوشته می شود، صفحه جدید اصلاح شده باید در زنجیره صفحه درج شود.
به روز رسانی داده های بلادرنگ عمدتاً یک به روز رسانی میدانی را فراخوانی می کند ( شکل 5 ). در اکثر مدل های مبتنی بر صفحه محبوب، طول فیلد به طور کلی ثابت است. برای یک فیلد با طول ثابت، فقط باید مقدار فیلد انتخابی را در رکوردی که توسط جدول افست در صفحه نشان داده شده است، بازخوانی کند. با این حال، استراتژی متفاوتی برای زمینه هایی با طول متغیر اتخاذ می شود. اگر طول فیلد پس از بهروزرسانی فیلد از طول فیلد فعلی بیشتر شود، فیلد بهروزرسانی شده به انتهای بلوک سمت راست اضافه میشود و جدول افست نیز تازهسازی میشود. در جدول افست، “OxFFFF” یک تگ تجویزی است که نشان دهنده فیلد با مقدار NULL است.
برای مدلهایی که برای مدیریت دادههای مکانی استفاده میشوند، برای بهروزرسانی دادهها ضروری است که ابتدا صفحه سرریز را رد کرده و سپس درخت شاخص را تنظیم کنید. به این ترتیب، یکپارچگی شاخص فضایی حفظ می شود، اما هزینه محاسبات بسیار گران است. با این حال، به دلیل حجم کم داده های به روز رسانی و فرکانس کم به روز رسانی، برای به روز رسانی نقشه های ناوبری مناسب نیست. انتشار نسخه جدید وصله های نقشه ناوبری ممکن است چند ماه طول بکشد. بنابراین مدل CNDF از این روش پیروی نمی کند.
در مدل CNDF، اگر صفحه پس از درج رکوردها سرریز شود، صفحه جدید حاوی رکوردهای اضافی در پشت صفحه جاری قلاب می شود ( شکل 6 ). هنگام پرس و جو از شبکه، تمام صفحات فهرست شده توسط شبکه ( به عنوان مثال ، صفحه 0، صفحه 1، و صفحه 2) به طور همزمان در حافظه بارگذاری می شوند. بازسازی شاخص فضایی که هزینه زمانی بهروزرسانی فهرست را کاهش میدهد، غیر ضروری است، و غیرممکن است که وصلههای نقشه ناوبری در تعداد کمی از شبکهها متمرکز شوند. به این ترتیب تعداد صفحات ایندکس شده توسط هر شبکه به شدت افزایش نمی یابد و سرعت جستجوی MSG به طور مشخص کاهش نمی یابد.
2.3.2. فرآیند نگهداری برای داده های ناوبری
داده هایی که از الگوی ذخیره سازی چند سطحی استفاده می کنند معمولاً اضافی هستند. سوابق هویت در هر سطح باید به طور همزمان هنگام به روز رسانی رکورد اصلی اصلاح شوند. فرآیند تعمیر و نگهداری به این معنی است که داده های ناوبری، به ویژه شبکه جاده ها، پس از به روز رسانی باید سازگار باشند. اولین مرحله در فرآیند نگهداری، ردیابی سوابق هویتی در هر سطح، و اصلاح همزمان آنها هنگام بهروزرسانی رکورد اصلی است. مرحله دوم تغییر رکوردهای مربوط به موارد به روز شده در هر سطح است. به عنوان مثال، هنگامی که مشتری این اطلاعات را دریافت می کند که هزینه ترافیک پیوندها تغییر کرده است، پیوندهای UEباید مقادیر دسترسی خود را برای حفظ ثبات کل RHN دوباره تنظیم کنند. نقشه برداری سلسله مراتبی فناوری کلیدی برای ردیابی مجموعه رکورد هویت است.
3. آزمایش و نتایج
نقشه ناوبری برای شرق چین (شامل پکن، تیانجین، شاندونگ، هبی، و جیانگ سو) در آزمایش ما استفاده شد. این به طور کامل با استفاده از مدل CNDF با جاده طبقه بندی شده توسط متریک دسترسی ساخته شده است. جدول 3 مقایسه تعداد پیوندهای بین سلسله مراتب طبیعی و سلسله مراتب دسترسی را نشان می دهد. برای شبیه سازی برنامه های ناوبری واقعی وسیله نقلیه، از یک سیستم تعبیه شده برای آزمایش ما استفاده شد و اطلاعات دستگاه در جدول 4 نشان داده شده است .
این آزمایش برای اعتبارسنجی عملکرد CNDF با توجه به عملیاتی از جمله پرس و جو فضایی، جستجوی مسیر و نقشه برداری سلسله مراتبی بود. برای آزمایش کارایی MGS، زمانی که نقشههای 1:50,000 و 1:500,000 به ترتیب در حال جابجایی و بزرگنمایی بودند، هزینه زمانی «QuerybyBound» بهطور پیوسته توسط سیستم تعبیهشده ثبت شد. سپس عملیات با استفاده از نقشه نمایه شده توسط R-tree انجام شد. نتایج نشان می دهد که میانگین هزینه زمانی MGS کمتر از R-tree بوده و مقدار پیک در زمان تعویض سطوح رخ داده است ( شکل 7 ).
بر اساس شبکه سلسله مراتبی مبتنی بر دسترسی، الگوریتم RHSP به صورت تکراری با استفاده از گره های شروع ورودی با فواصل مختلف تا گره پایانی اجرا شد. تعداد پیوندهای درج شده به پشته ثبت شد. نتایج نشان می دهد که میانگین تعداد پیوندهای جستجو شده پس از 1000 بار اجرا به 11000 محدود شده است ( شکل 8 ). این نشان داد که شبکه سلسله مراتبی مبتنی بر دسترسی برای کنترل فضای محدود جستجوی مسیر و محدود کردن زمان محاسبات به یک مقدار تقریباً ثابت مؤثر است.
برای اعتبارسنجی سرعت نگاشت سلسله مراتبی با الگوریتم LLC، از اطلاعات ترافیک بلادرنگ در پکن استفاده شد. سیستم تعبیه شده به پلت فرم اطلاعات اداره مدیریت ترافیک پکن متصل می شود و هر 5 دقیقه یک بار اطلاعات ترافیک را از طریق GPRS دریافت می کند. مقدار پیک شماره پیوند به روز شده بیش از 4000 در چرخه اندازه گیری بود ( شکل 9 ). تأیید شد که LLC در برآوردن نیاز بهروزرسانی بیدرنگ برای شهرهای بزرگ مؤثر است. با توجه به اینکه پیوند بدون تغییر نیازی به به روز رسانی نداشت، ما دامنه نامزد را برای به روز رسانی با استراتژی تفاوت زمانی، استراتژی تفاوت حالت و استراتژی ترکیبی برای اطلاعات ترافیک زمان واقعی محدود کردیم. شکل 9هزینه زمانی آزمون های مقایسه ای را تحت استراتژی های مختلف نشان می دهد.
4. نتیجه گیری
یک مدل ذخیره سازی پویا برای برنامه های ناوبری خودرو بسیار مهم است. در این مقاله، ما یک قالب ذخیرهسازی فیزیکی جدید، فرمت داده ناوبری چین (CNDF)، بر اساس شاخص شبکه چند مقیاسی، رویکرد سلسلهمراتب مبتنی بر دسترسی، و الگوریتم کدگذاری لینک خطی ایجاد کردیم. بنابراین، مدل CNDF دارای ساختار سلسله مراتبی و مبتنی بر صفحه است. همچنین یک فرمت ذخیره سازی فیزیکی پویا است و داده های ناوبری فضایی ساخته شده توسط CNDF را می توان به صورت افزایشی تغییر داد. نقشه ناوبری شرق چین به طور کامل با استفاده از CNDF ساخته شده است و اطلاعات ترافیک در زمان واقعی برای یک سیستم ناوبری تعبیه شده برای آزمایش عملکرد CNDF استفاده شد. نتایج نشان داد که هزینه زمان، هزینه حافظه و ذخیره سازی دیسک به طور چشمگیری کاهش یافت. CNDF برای ناوبری نسل بعدی با سیستم حمل و نقل هوشمند مناسب خواهد بود. با این حال، بهروزرسانی توپولوژی شبکه جادهای سلسله مراتبی برای CNDF در نظر گرفته نشد، که در کارهای بعدی مورد مطالعه قرار خواهد گرفت.
ضمیمه
الگوریتم کدگذاری لینک خطی (LLC).
مدل نگاشت سلسله مراتبی CNDF بر اساس الگوریتم Linear Link Coding (LLC) توسعه یافته است. رکورد اصلی ( یعنی جاده سطح جزئیات) باید به سوابق هویت ( یعنی پیوندهای انتزاعی) مرتبط باشد تا ثبات به روز رسانی های چند سطحی را تضمین کند. با در نظر گرفتن ذخیره سازی فشرده، رابطه با 1:M کارآمدتر از N:M بود. بنابراین، در این مقاله از رابطه حاوی ضمنی کد پیوند برای الگوریتم LLC برای پیاده سازی رابطه با 1:M استفاده شد. تعریف الگوریتم LLC به شرح زیر بود.
تعریف 1:
یک سیستم مرجع خطی (LRM) λ = (μ, ε, ξ) است، که در آن λ بیان مکان از جمله روش مرجع خطی است، μ عنصر خطی است، ε فاصله را بیان می کند، و ξ نشان دهنده معناشناسی است. در الگوریتم LLC، λ پست گره، μ پیوند، و ξ فاصله مسیری است که با εi = ε i-1 + m(i-1, i)/K + 1 با ε 0 = 0 تعریف شده است. که در آن m(i-1, i) نشان دهنده فاصله پیوند e(i-1,i)، K واحد طول از پیش تعریف شده است، و ε نشان دهنده مجموع فاصله پیوندهای کدگذاری شده است.
تعریف 2:
e(u، v) یک پیوند است، و LLC(e) در LRM یک جفت پست گره است، به عنوان مثال ، <FP، TP>، با FP = λ(u)، و TP = λ(v). LLC(e) منحصر به فرد است، زیرا λ(u) در LRM منحصر به فرد است.
تعریف 3:
رابطه LLC دو پیوند e 1 و e 2 با e 1 ⊆ e 2 , FP e 1 ≥ FP e 2 و TP e 1 ≤ TP e 2 داده شده است .
تعریف 4:
در شبکه سلسله مراتبی سازگار، برای هر پیوند e i در سطح i، e j وجود دارد که در آن T j ⊆ T i با j < i وجود دارد.
طبق تعریف 4، اگر یک شبکه سلسله مراتبی سازگار باشد، رابطه بین پیوند سطح بالا و پیوند سطح تفصیلی ( یعنی پایین) 1:M است. کد پیوند با کد پیوند سطح بالا در خط 7 در جدول A1 نشان داده شده است که الگوریتم LLC را نشان می دهد. بنابراین، هر کدی از پیوند سطح بالا میتواند حاوی کد پیوندهای سطح پایین مرتبط باشد، که ثبات شبکه سلسله مراتبی کد شده توسط الگوریتم LLC را حفظ میکند. با استفاده از FP و TP، پیوندهای انتزاعی را می توان با مرزهای پیوندهای دقیق با اطلاعات ترافیک در زمان واقعی هنگام به روز رسانی داده ها جستجو کرد. به این ترتیب، مدل CNDF رابطه 1:M را بین پیوندهایی که با آرایه شناسایی پیوندها توزیع شده اند، پیاده سازی می کند.

جدول A1. کد شبه الگوریتم کدگذاری پیوند خطی سلسله مراتبی (LLC).
منابع
- مشخصات NAVTECH PSF برای فرمت SDAL نسخه 1.7. در دسترس آنلاین: http://www.janczinsky.cz/dwn/SDAL_spec.pdf (دسترسی در 5 نوامبر 2015).
- مشخصات فرمت KIWI نسخه 1.2.2 (JIS D0810). در دسترس آنلاین: http://www.jsa.or.jp/default_english/default_english.html (دسترسی در 5 نوامبر 2015).
- الزامات و مدل داده های منطقی برای فرمت ذخیره سازی فیزیکی (PSF) و رابط برنامه کاربردی (API) و سازماندهی داده های منطقی برای PSF مورد استفاده در فناوری پایگاه داده سیستم های حمل و نقل هوشمند (ITS). در دسترس آنلاین: http://www.iso.org/iso/iso_catalogue/catalogue_tc/catalogue_detail.htm?csnumber=39447 (دسترسی در 5 نوامبر 2015).
- خو، ی. Recker، W. مدلسازی ناوبری پویا وسیله نقلیه در یک سیستم اطلاعات ترافیکی توزیع شده خودسازمانده، نظیر به همتا. جی. اینتل. ترانسپ Sys تکنولوژی طرح. اپراتور 2006 ، 10 ، 185-204. [ Google Scholar ]
- پاز، ا. ویرامیستی، ن. خانال، آی. بیکر، جی. Fuente-Mella، H. توسعه یک سیستم پایگاه داده جامع برای تحلیلگر ایمنی. علمی World J. 2015 ، 2015 ، 1-14. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- سیمندل، ج.ک. گرتینگر، ای جی; اسمیت، RK; ابزار فهرستبندی دادههای تقاطع غیر علامتدار مبتنی بر Barnett، TE GIS برای بهبود ایمنی ترافیک. در مجموعه مقالات نشست سالانه 94 هیئت تحقیقات حمل و نقل، واشنگتن، دی سی، ایالات متحده آمریکا، 11 تا 15 ژانویه 2015.
- الوانکی، ف. گونکالوس، آر. ایوانووا، م. Kyzirakos، K. ناوبری GIS توسط فروشگاه های ستون تقویت شده است. Proc. VLDB Enddow. 2015 ، 8 ، 1956-1959. [ Google Scholar ] [ CrossRef ]
- پارک، ای. کیم، اچ. اهم، JY درک پذیرش راننده از سیستم های ناوبری خودرو با استفاده از مدل پذیرش فناوری توسعه یافته. رفتار اطلاعات تکنولوژی 2015 ، 34 ، 741-751. [ Google Scholar ] [ CrossRef ]
- فنگ، جی. Watanabe, T. Index Techniques. در روش های فهرست و پرس و جو در شبکه های جاده ای ; Feng, J., Watanabe, T., Eds. انتشارات بین المللی Springer: چم، سوئیس، 2014; صص 11-39. [ Google Scholar ]
- وو، اچ. لیو، ز. ژانگ، S. مدل تقسیم بندی پویا مکانی-زمانی. در مجموعه مقالات دهمین کنفرانس بین المللی متخصصان حمل و نقل چینی، پکن، چین، 4 تا 8 اوت 2010.
- واگنر، دی. ویلهام، تی. تکنیکهای افزایش سرعت برای محاسبات کوتاهترین مسیر. در STACS 2007: بیست و چهارمین سمپوزیوم سالانه جنبه های نظری علوم کامپیوتر ; Thomas, P., Well, P., Eds. Springer: برلین/هایدلبرگ، آلمان، 2007; صص 23-36. [ Google Scholar ]
- چن، سی. جیا، ی. شو، م. وانگ، ی. کنترل ردیابی مسیر تطبیقی سلسله مراتبی برای وسایل نقلیه خودران. IEEE Trans. هوشمند ترانسپ سیستم 2015 ، 16 ، 1-13. [ Google Scholar ]
- لی، کیو. زنگ، ز. ژانگ، تی. لی، جی. Wu, Z. مسیریابی از طریق شبکه های جاده ای سلسله مراتبی انعطاف پذیر: یک رویکرد تجربی با استفاده از داده های مسیر تاکسی. بین المللی J. Appl. زمین Obs. اطلاعات جغرافیایی 2011 ، 13 ، 110-119. [ Google Scholar ] [ CrossRef ]
- ونگ، ام. جیانگ، اس. Qu, R. استدلال فضایی سلسله مراتبی و مورد راهیابی. اطلاعات جغرافیایی فضایی علمی 2008 ، 11 ، 269-272. [ Google Scholar ] [ CrossRef ]
- شوبرت، ای. زیمک، ا. کریگل، پرس و جوهای فاصله جغرافیایی HP روی درختان r برای نمایه سازی داده های جغرافیایی. لکت. یادداشت ها محاسبه. علمی 2013 ، 8098 ، 146-164. [ Google Scholar ]
- دلینگ، دی. سندرز، پی. شوتس، دی. واگنر، دی. الگوریتم های برنامه ریزی مسیر مهندسی. در الگوریتم شبکه های بزرگ و پیچیده: طراحی، تحلیل و شبیه سازی . Lerner, J., Wagner, D., Zweig, KA, Eds. Springer: برلین/هایدلبرگ، آلمان، 2009; صص 117-139. [ Google Scholar ]
شکل 1. تصویر شاخص شبکه چند مقیاسی.
شکل 2. ساختار منطقی فرمت داده ناوبری چین (CNDF).
شکل 3. ساختار فیزیکی قالب داده ناوبری چین (CNDF).
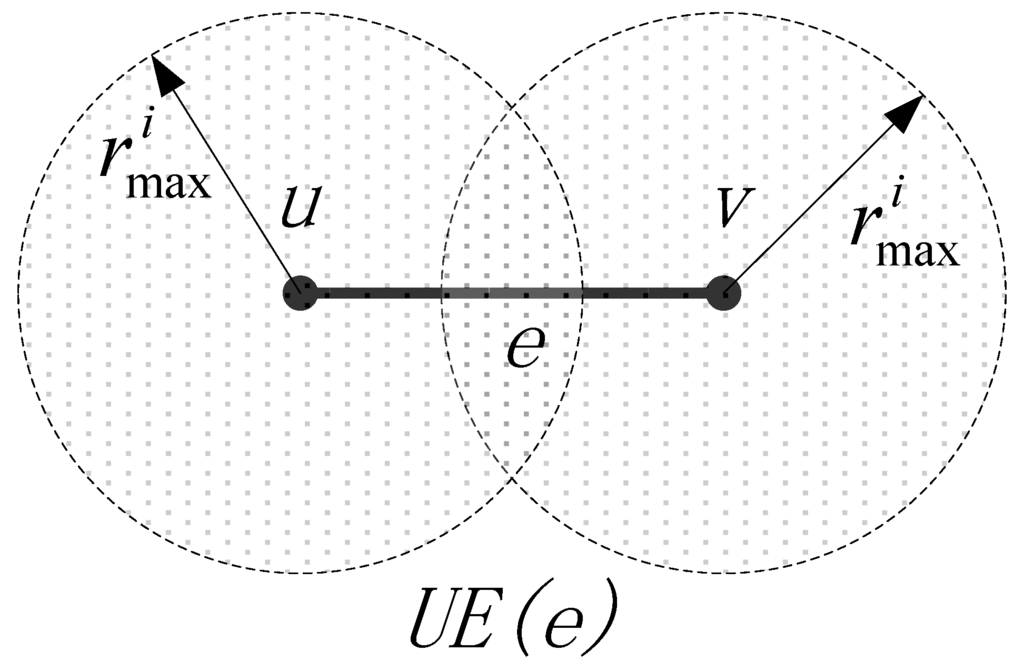
شکل 4. مجموعه پیوند تنظیم مجدد.

شکل 5. مکانیسم به روز رسانی میدانی در روش به روز رسانی داده های بلادرنگ.
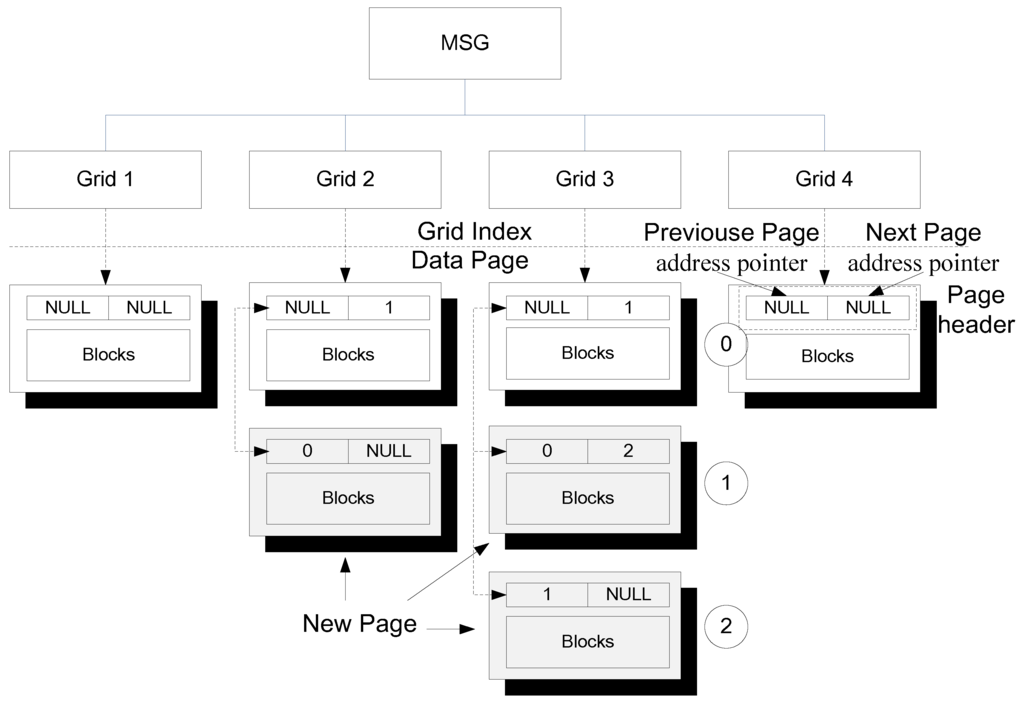
شکل 6. مکانیسم به روز رسانی افزایشی در روش به روز رسانی افزایشی داده ها.
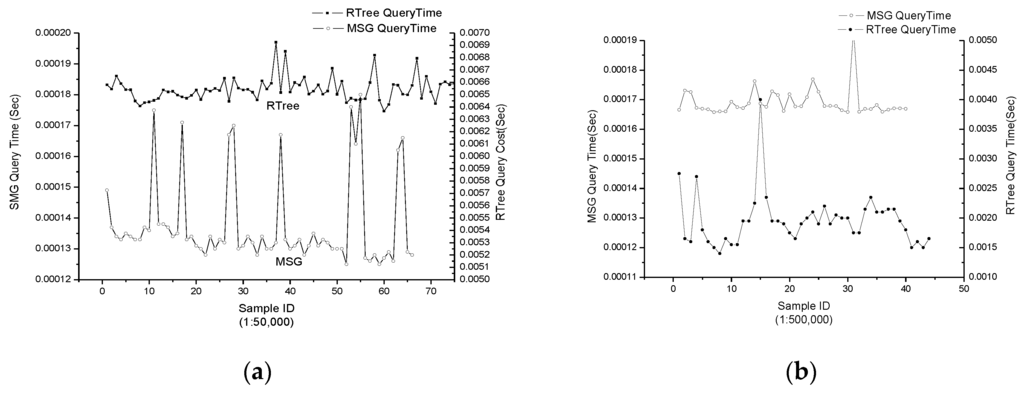
شکل 7. هزینه زمانی “QuerybyBound” در طول ( الف ) حرکت نقشه و ( ب ) بزرگنمایی.
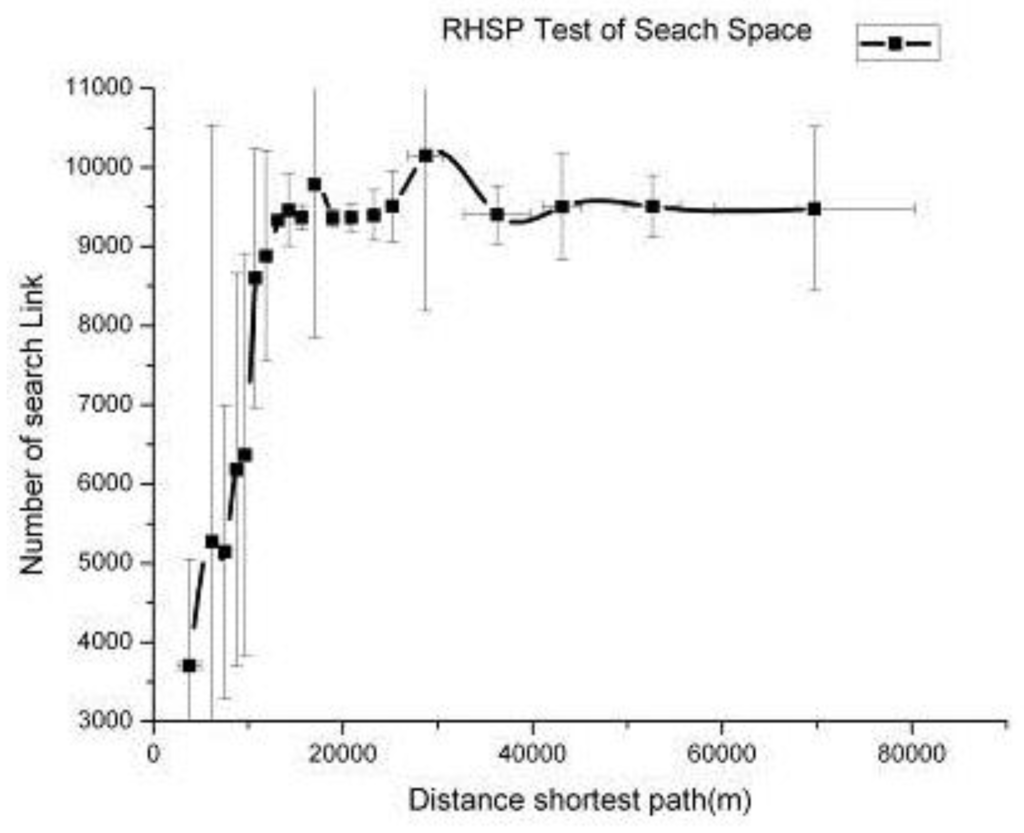
شکل 8. تعداد پیوندهای جستجو شده الگوریتم کوتاهترین مسیر سلسله مراتبی (RHSP).
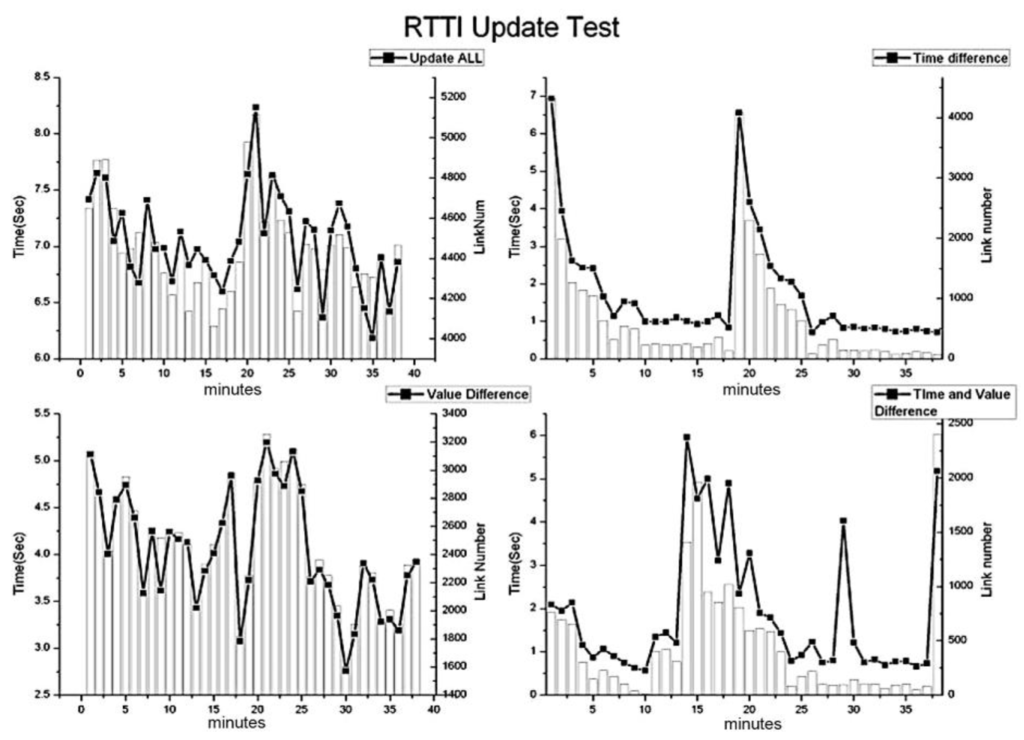
شکل 9. هزینه زمانی و تعداد ثبت شده برای به روز رسانی اطلاعات ترافیک در زمان واقعی (RTTI) هر 5 دقیقه.
جدول 1. قالب اصلی ذخیره سازی فیزیکی (PSF) مورد استفاده برای نقشه های ناوبری خودرو.
جدول 2. کد شبه الگوریتم کوتاهترین مسیر سلسله مراتبی مبتنی بر دسترسی.
جدول 3. سلسله مراتب نقشه ناوبری برای شرق چین.
جدول 4. اطلاعات دستگاه مورد استفاده در آزمایش ما.
© 2016 توسط نویسندگان؛ دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (CC-BY) (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر