

خلاصه
روش پرکاربرد مبتنی بر کشش برای جمعآوری دادههای حسگر فرکانس بالا از سرویسهای مشاهده حسگر (SOS) در کاربردهای بلادرنگ کارآمد نیست. بنابراین، اگر شبکههای حسگر میخواهند به پتانسیل کامل خود دست یابند، باید به مکانیسمهای بلادرنگ در فرآیند ارائه توجه بیشتری شود. برای رسیدگی به این مشکل، یک مدل مشکل ارائه داده ایجاد کردیم، و الگوریتم بازگشتی Kalman Filter (KF) و دو الگوریتم خطی خود تطبیقی پیشنهادی ما افزایش و کاهش ضربی برداشت (H-AIMD) و افزایش ضربی برداشت و کاهش افزایشی (H-MIAD) با خط مشی استاتیک که معمولاً استفاده می شود، که داده ها را با فاصله زمانی بدون تغییر درخواست می کند. ما همچنین یک روش ارزیابی عملکرد جامع ایجاد کردیم که ظرفیت زمان واقعی و اتلاف منابع را برای مقایسه عملکرد چهار الگوریتم ارائه داده در نظر میگیرد. آزمایشها با دادههای حسگر واقعی نشان میدهد که سیاست استاتیک به دقت نیاز داردپارامترهای پیشینی ، فیلتر کالمن برای ارائه دادههای حسگرهایی با فواصل زمانی پایدار طولانیمدت مناسبتر است، و H-AIMD پایدارترین با کارایی بهتر و تعداد دادههای با تأخیر کمتر است، در حالی که با اتلاف منابع بیشتر نسبت به سایرین برای جریان دادهها. با نوسانات زیاد در فواصل زمانی مدل و الگوریتمهای پیشنهادی بهعنوان یک مرجع اساسی برای کاربردهای بلادرنگ با جمعآوری دادههای جریان مبتنی بر کشش مفید هستند.
کلید واژه ها:
وب سنسور ; ارائه در زمان واقعی ؛ دسترسی به داده مبتنی بر کشش ; فیلتر کالمن ; ارزیابی عملکرد نرمال
1. معرفی
تشخیص و هشدار زودهنگام خطرات طبیعی در حال ظهور و بلایای انسانی به اطلاعات جغرافیایی در زمان واقعی برای پشتیبانی از واکنش موثر و به موقع اضطراری نیاز دارد. حسگرهای زیادی در سرتاسر جهان مستقر شدهاند که به طور مداوم ویژگیها و ژئواشیاء را در سطح زمین نظارت میکنند [ 1 ، 2 ]، مانند صنعت معدن [ 3 ]، کشاورزی [ 4 ، 5 ]، کلان شهر [ 6 ] و جو. [ 7 ]، داده های جغرافیایی را بی وقفه تولید می کند. با توجه به توسعه علم سرویسمحور [ 8 ]، دادهها میتوانند توسط هر کسی، از هر کجا و به هر شکلی قابل دسترسی باشند [ 9]]. با این حال، مشاهدات حسگر باید در زمان واقعی [ 3 ، 10 ] برای برنامه های کاربردی متعدد از طریق سرویس های داده به راحتی در دسترس به دست آورد. با این حال، روشهای ارائه موجود فاقد مکانیسمهای موثر و کارآمد جمعآوری دادههای بلادرنگ هستند.
کنسرسیوم باز GIS (OGC) در سال 2003 سنسور Web Enablement (SWE) را پیشنهاد کرد که شامل یک سری استانداردهای خدماتی برای وب حسگر است. با این تعاریف یکسان، داده های حسگر را می توان از طریق پروتکل ها و رابط های استاندارد کشف و به دست آورد. بنابراین، برنامهها را میتوان بر اساس استانداردهای خدماتی بدون در نظر گرفتن جزئیات ارتباطی اساسی بین حسگرها و پیادهسازیهای سختافزاری ساخت [ 11 ]. یکی از مدلهای بسیار مهم رابط SWE، سرویس مشاهده حسگر (SOS) است که مکانیسم دسترسی به دادهها مبتنی بر کشش است [ 12 ]. معماری لایه میانی [ 13] شکاف بین شبکه های حسگر و اینترنت را پر کرده بود. با این حال، در نظر نمی گیرد که چگونه داده های حسگر می تواند توسط مصرف کنندگان از SOS در زمان واقعی بدست آید.
ثبت سرویس و کشف روش های SOS [ 14 ، 15 ، 16 ] و دسترسی به داده ها [ 17]] مورد مطالعه قرار گرفته بود. با این حال، این کار بر روی چگونگی سازگاری و انتشار داده ها توسط سرویس های SWE از حسگرها متمرکز شده است. تعداد کمی از محققان جریان داده های بعدی را از SOS به کاربران، به ویژه برای جریان های داده پیوسته با فرکانس بالا به پایگاه داده های برنامه بلادرنگ در نظر گرفته اند. تغییر فرکانس مشاهده حسگر به دلیل ماهیت پویای پدیده های دنیای واقعی، دریافت موثر داده های حسگر زمان واقعی را چالش برانگیزتر می کند. یک مشکل عمده هنگام ترسیم یک سیستم ارائه داده با کارایی بالا رخ می دهد زیرا ماشین ها اندازه و سرعت فضای کاری متفاوتی دارند، بنابراین آنها نیز فرکانس های مشاهده متفاوتی خواهند داشت [ 18 ].
دو روش دسترسی به داده برای وب حسگر برای آژانس محیط زیست اروپا (EEA) ارائه شد [ 17]. اولی یک رابط یکنواخت را فراهم می کند و منتظر ارسال داده توسط ارائه دهنده داده است. این یک وسیله کارآمد در زمان است و نیازی به استقرار سرورها برای انتشار داده ها نیست. روش دسترسی دیگر درخواست های داده را با فرکانس ثابت به SOS می فرستد، یعنی Static Policy، توسط Harvestor، یک ماژول جمع آوری داده. این یک روش فعال مبتنی بر کشش است که تعیین می کند چه محتوایی و با چه فرکانسی دریافت شود. از این رو، اولی برای مؤسسات بزرگی مانند EEA که مسئول ارائه رابط های یکنواخت برای انتقال داده ها به پایگاه های داده هستند، مناسب است. در مقابل، دومی انعطافپذیرتر و قابل تنظیمتر است اما زمان کمتری کارآمد است. علاوه بر این، بیشتر خدمات وب حسگر فعلی برای دسترسی به داده ها مبتنی بر کشش هستند [ 19]. بنابراین، نیاز مبرمی به راهحلهای پویا برای حل مسئله تصادفی سیستم از روشهای زمانبندی از پیش تعریفشده وجود دارد [ 20 ].
بسیاری از عوامل میتوانند منجر به مشکلات دینامیکی شوند که یکی از نگرانیهای اصلی کاربردهای حسگر زمان واقعی کنونی است. فاصله زمانی بین دو مشاهده به دلایل مختلف به سختی می تواند ثابت بماند. سر و صدای محیط رایج ترین است. برای مثال، ساختمانهای بزرگ میتوانند بر تغییر سیگنالهای حسگر تأثیر بگذارند، یا آب و هوای سخت نیز میتواند بر شرایط سختافزاری تأثیر بگذارد. دلیل دیگر مداخلات مصنوعی یا تنظیمات پویا است. برخی از حسگرهای هوشمند می توانند به طور خودکار فرکانس مشاهده خود را بسته به وضعیت اشیایی که در حال نظارت هستند تغییر دهند. علاوه بر این، خرابی سخت افزار می تواند باعث وقفه طولانی مدت شود که فواصل زمانی مشاهده را نیز تغییر می دهد.
علاوه بر ویژگیهای دینامیکی مشاهدات حسگر، توانایی مدیریت جریانهای دادههای حسگر پویا و فرکانس بالا در کاربردهای بلادرنگ فعلی نسبتاً ضعیف است. سنسورهای متعددی داده های با فرکانس بالا و پویا را در چند ساعت، دقیقه یا حتی ثانیه تولید می کنند. در عین حال، به دلیل تعداد زیاد حسگرها، حجم داده های تولید شده در زمان واقعی بسیار زیاد است. بنابراین، منابعی مانند پهنای باند شبکه و بار سرور داده باید به صورت مشورتی در نظر گرفته شوند. با این حال، اکثر دادههای حسگر در حال حاضر بهعنوان سوابق تاریخچه ثابت بهدست میآیند و به یکباره با ابزارهای خاص به پایگاههای اطلاعاتی مختلف وارد میشوند. علاوه بر این، سیاست Static معمولاً برای جمعآوری دادههای حسگر در زمان واقعی از SOS یا بازده زمانی محدودی دارد یا اگر فاصله زمانی به درستی از پیش تعیین نشده باشد، منابع زیادی را هدر میدهد. از این رو،
چندین الگوریتم را می توان برای تنظیم برای ارائه داده در نظر گرفت، اگر آنها بتوانند با محاسبات بسیار کمی پیش بینی کنند. فیلتر کالمن (KF) یک الگوریتم کارآمد است که به طور گسترده استفاده می شود، مانند اندازه گیری فرکانس سیستم قدرت [ 21 ]، جذب داده ها [ 22 ] و ترکیب داده ها [ 23 ]. همچنین می تواند به عنوان یک الگوریتم پیش بینی استفاده شود زیرا شامل یک مجموعه معادله پیش بینی است که می تواند به عنوان یک تخمین پیشینی از وضعیت فعلی قبل از تولید یک اندازه گیری جریان عمل کند. بنابراین، معقول است که KF را به عنوان یک الگوریتم بازگشتی در برنامه های کاربردی ارائه داده های حسگر در زمان واقعی معرفی کنیم. برخلاف KF، تحقیقات قابل توجهی بر روی الگوریتمهای فعالسازی حسگرهای قابل شارژ متمرکز شده است.20 ، 24 ، 25 ، 26 ]. ماداکاسیرا [ 26 ] فرآیند شارژ مجدد حسگرها را تجزیه و تحلیل کرد و عملکرد چهار الگوریتم شارژ خطی را مقایسه کرد: کاهش ضربی افزایش افزایشی (AIMD)، کاهش افزایشی افزایشی (AIAD)، کاهش ضربی افزایش ضربی (MIMD) و افزایش ضربی (کاهش افزایشی) MIAD). آنها فاصله خواب بعدی حسگرها را با توجه به سطوح انرژی تعیین می کنند. این دو الگوریتم، AIMD و MIAD، بر اساس این تحلیل، میتوانند به عنوان الگوریتمهای خطی برای پیشبینی بلادرنگ در ارائه دادههای حسگر اقتباس و استفاده شوند.
بر اساس تجزیه و تحلیل مسائل و الگوریتمهای دینامیکی، که میتوانند وظایف پیشبینی را انجام دهند، ما فرآیند مبتنی بر کشش ارائه دادههای حسگر در زمان واقعی را از سرویسهای مشاهده حسگر مدلسازی کردیم، و چهار سیاست از نظر مدل پیشنهادی مورد بحث قرار میگیرند. هدف ما به حداقل رساندن تأخیر زمان اکتساب داده، تعداد تأخیر دادهها و هزینههای منابع در سیستم بود. به نوبه خود، ما یک روش ارزیابی عملکرد جامع نرمال شده را با در نظر گرفتن عملکرد بلادرنگ و اتلاف منابع برای مقایسه این الگوریتمها در مدل ارائه دادههای زمان واقعی خود توسعه دادیم. بیشتر آزمایشها در تحقیقات جمعآوری دادهها در زمینه سختافزار حسگر بر اساس دادههای شبیهسازی شده است. با این حال، آزمایشهای ما بر اساس سه نوع داده حسگر واقعی است. با کار ما،
ادامه مقاله به شرح زیر تدوین شده است. معرفی جریانهای دادههای وب حسگر در بخش 2 و به دنبال روش ما در بخش 3 است که در آن مدل مشکل را در بخش 3.1 تعریف میکنیم ، سیاستهای ارائه و روشهای ارزیابی عملکرد را در بخش 3.2 و بخش 3.3 شرح میدهیم . آزمایش ها و نتایج در بخش 4 ارائه شده است . سپس، مدل و الگوریتمها در بخش 5 مورد بحث قرار میگیرند . بخش 6 مقاله را به پایان می رساند.
2. جریان داده از شبکه های حسگر
انواع زیادی از حسگرها وجود دارد که میتوان آنها را با توجه به فرکانس مشاهده و حجم داده به سه دسته طبقهبندی کرد: حسگرهای با فرکانس پایین، مانند سنسورهای ماهوارهای که حجم دادهها با یک مشاهده در روز به گیگابایت میرسد. یک ماه؛ سنسورهای با فرکانس بالا، مانند سنسورهای رطوبت خاک، بسیاری از سنسورهای درجا متعلق به این نوع هستند. سنسورهای با فرکانس بالا، مانند شبکه های حسگر ویدئو و دوربین، به دلیل مشاهده مداوم و حجم مگابایت در ثانیه.
بر اساس تجزیه و تحلیل بالا، این مطالعه، با این حال، بر روی ارائه دادههای بیدرنگ نوع دوم حسگرها متمرکز است که یک رکورد داده را با حجم زیر کیلوبایت یک بار در ساعت، یک دقیقه یا یک ثانیه جمعآوری میکند. از دید مشخصه های مشاهده شده، سه نوع جریان داده تولید شده توسط این نوع حسگرها وجود دارد. اول، دادههای کاملاً ثابت با نویز کم است و فاصله زمانی معمولاً یک مقدار ثابت به دلیل برنامههای زمانی دقیق است. دوم، داده های ثابتی است که فواصل زمانی آنها را می توان در صورت نیاز تغییر داد، اما بازه های مشاهده ثابت می ماند. سوم، دادههای ناپایدار تحت تأثیر نویز زیاد است، و مهرهای زمانی نمونه تغییرات زیادی خواهند داشت، بنابراین نوسانات متعددی در فواصل زمانی بین مشاهدات همسایه ایجاد میشود.
3. روش
3.1. مدل سازی فرآیند تامین
در این بخش، فرآیند ارائه داده را با در نظر گرفتن گسسته بودن زمان مدل میکنیم. ما یک توصیف ریاضی از مسئله میسازیم: با یک سری تمبر زمانی تاریخی [تی0،تی1،تی2, … ,تیn] [تی0،تی1،تی2،…،تی�]، n�یک عدد صحیح است، چه مهر زمان بعدی تیn + 1تی�+1است. برای پیش بینی یا ارزیابی این مقدار، ابتدا باید مشکل را تغییر دهیم. می توانیم سری بازه زمانی را بدست آوریم [ 🝛تی1، 🝛تی2، 🝛تی3, … , 𝛻تیn][𝛻�1,𝛻�2,𝛻�3,…,𝛻��]که در آن 🝛تیک=تیک–تیک− 1🝛تیک=تیک–تیک–1، k ∈ [ 1 , n ]ک∈[1،�]، اگر بتوانیم هر فاصله خواب بعدی را پیش بینی کنیم اسمنn e x t= 🝛تیn + 1اسمن�هایکستی=🝛تی�+1، سپس تیn + 1=تیn+ 🝛تیn + 1تی�+1=تی�+🝛تی�+1. در نتیجه، تیn + 1تی�+1را می توان با پیش بینی SI بعدی محاسبه کرد . برای معرفی بهتر این مدل، معنای برخی از اصطلاحات استفاده شده در این مقاله در جدول 1 نشان داده شده است . اقلام داده ای که به عنوان آخرین داده ها قابل دسترسی نیستند در این مقاله با تأخیر در نظر گرفته می شوند.
هنگامی که Harvestor شروع به ارسال درخواست های داده می کند، مهرهای زمانی داده های حسگر منتشر شده توسط SOS را می توان به صورت تعریف کرد. [ϕ0،ϕ1،ϕ2،ϕ3، …,ϕن][�0،�1،�2،�3،…،�ن]، که در آن ϕ0=تیn، ϕ1=تیn + 1، ϕ2=تیn + 2، …�0=تی�، �1=تی�+1، �2=تی�+2،…، و توتوبه عنوان شاخص تعریف می شود ϕ�، u ∈ [ 0 , N− 2 ]تو∈[0، ن–2]. از طریق الگوریتم های مختلف ارائه ΠΠ، می توانیم داده های تولید شده در مهر زمان را درخواست کنیم ϕ1�1توسط یک سری از مهرهای زمانی درخواست [ θ11، θ21, … , θساعت1�11، �12، … ، �1ساعت]، که در آن h ( h = 1 ، 2 ، 3 ، … )ساعت (ساعت=1، 2، 3،…)تعداد دفعات درخواست داده را نشان می دهد و زیرنویس ها نمایانگر ایندکس هستند ϕ �. تعداد داده های تاخیری است پ پ، و تعداد دفعات از دست رفته است من من، همه اعداد صحیح و دارای یک زیرنویس هستند v ( v = 1 , 2 ، 3 ، … )� (�=1، 2، 3،…)ایستاده برای شاخص داده های درخواست شده به موقع. در این مورد، v= 1�=1. چهار مورد در شکل 1 نشان داده شده است که در آنها توضیحات مربوطه به شرح زیر است.
- (آ)
-
ϕ1≤θ11<ϕ2�1≤�11<�2، داده های حسگر در زمان ϕ1�1از اولین درخواست داده، بدون داده های تاخیری یا درخواست های نامعتبر، قابل دسترسی است پ1= 0 ، من1= 0پ1=0، من1=0;
- (ب)
-
ϕ1≤θساعت1<ϕ2�1≤�1ساعت<�2، داده های حسگر در زمان ϕ1�1با موفقیت پس از ارسال h بار درخواست داده، بدون داده های تاخیری و h − 1ساعت–1پس درخواست های نامعتبر پ1= 0 ، من1= h − 1پ1=0، من1=ساعت–1;
- (ج)
-
ϕu + 1≤θساعت1<ϕu + 2�تو+1≤�1ساعت<�تو+2، داده در زمان ϕu + 1�تو+1پس از ارسال h بار درخواست های داده، h − 1 درخواست برای دسترسی بوده استϕ1�1شکست خورده اند، در حالی که درخواست h این را دریافت می کند ϕu + 1�تو+1با اقلام داده ϕ1، ϕ2, … , ϕتو�1، �2،…، �توبه تعویق افتادند، پس پ1= تو ، من1= h − 1پ1=تو، من1=ساعت–1;
- (د)
-
ϕu + 1≤θ11<ϕu + 2�تو+1≤�11<�تو+2، داده در زمان ϕu + 1�تو+1از اولین درخواست داده، با دادههای u تأخیر و بدون درخواست نامعتبر، قابل دسترسی است پ1= تو ، من1= 0 پ1=تو، من1=0.
بر اساس تجزیه و تحلیل درخواست ها برای اولین مورد داده، می توان به راحتی استنتاج کرد که در یک مورد معمول، داده های هدف را در مهر زمانی می گویند. ϕv��در سری های زمانی درخواست می شود [ θ1v، θ2v، … , θساعتv��1، ��2، …، ��ساعت]، ما میدانیم ϕu + 1≤θساعتv<ϕu + 2�تو+1≤��ساعت<�تو+2، و پv= تو ، منv= h − 1 پ�=تو، من�=ساعت–1. در نتیجه، مجموع از دست دادن بازدید δo(ن)��(ن)که در آن داده های جدید با موفقیت به دست نمی آیند را می توان با معادله (1)، تعداد کل درخواست محاسبه کرد δد(ن) �د(ن) ارسال شده به SOS را می توان با معادله (2)، تعداد داده های تاخیری محاسبه کرد εo(ن)��(ن)می تواند یک معادله جمع بندی تعریف شده توسط رابطه (3) و تعداد کل داده های SOS باشد εد(ن)�د(ن)همانطور که در رابطه (4) نشان داده شده است N است . V تعداد درخواست های موفق است. ظاهراً میتوانیم یک معادله داشته باشیم V=δد(ن) –δ0(ن) =εد(ن) –ε0(ن)�=�د(ن)–�0(ن)=�د(ن)–�0(ن)برای بررسی اینکه آیا اعداد آماری درست هستند یا خیر.
δ0(ن) =∑Vv = 1پv �0(ن)=∑�=1�پ�
δد(ن) =∑Vv = 1ساعتv �د(ن)=∑�=1�ساعت�
ε0(ن) =∑Vv = 1منv �0(ن)=∑�=1�من�
εد(ن) = N�د(ن)=ن
بر اساس مدل ایجاد شده، گردش کار در شکل 2 نشان داده شده است . SI نشان دهنده فاصله خواب است که زمان انتظار تا درخواست داده بعدی را نشان می دهد و SI – نشان دهنده آخرین زمان انتظار برداشت کننده است. Harvestor یک واحد عملکردی است که به طور فعال داده های حسگر را با ارسال درخواست “GetObservation” به سرویس مشاهده سنسور (SOS) جمع آوری می کند. 🝛🝛بازه زمانی تنظیم شده است که توسط الگوریتم های مختلف محاسبه می شود 🝛🝛t sum زمان انباشتهای است که در آن دادههای جدید را نمیتوان با چندین درخواست به دست آورد و T حداکثر آستانه زمانی است که برای تشخیص وجود وضعیت غیرعادی برای ارائه دادههای یک حسگر خاص مجاز است.
مدل نشان داده شده در شکل 2 روند ارائه نحوه عملکرد سیستم را نشان می دهد که آیا داده های جدید با موفقیت به دست آمده اند یا خیر. هنگامی که SI اولیه ، یعنی اولین زمان انتظار، به پایان رسید، هاروستور درخواستی را برای دریافت یک داده جدید به SOS ارسال می کند. اگر یک داده جدید با موفقیت کسب شود، SI بعدی یک مقدار کاهش می یابد 🝛 🝛و اگر نه، 🝛🝛t sum باید با T مقایسه شود . اگر 🝛🝛مجموع t بزرگتر از T است ، سپس ارائه خاص باید متوقف شود، و اگر نه، SI بعدی باید افزایش یابد 🝛🝛برای ورود به حلقه بعدی
لازم است دو پیش نیاز این مطالعه را برای حذف تأثیر برخی از عوامل نامرتبط اعلام کنیم زیرا تمرکز ما خود تأمین است. اول، ما فکر میکنیم که دادهها را میتوان در SOS منتشر کرد و بلافاصله پس از تولید توسط حسگرها به آن دسترسی داشت، یعنی هیچ تأخیر زمانی از تولید دادهها برای انتشار آن وجود ندارد. دوم، زمان صرف شده برای درخواست داده و حل پاسخ نسبت به کل فرآیند آنقدر کوتاه است که می تواند ناچیز باشد.
3.2. روش های ارائه داده ها
سه نوع گزینه زمانی برای ارائه داده های مبتنی بر کشش برای درخواست فعالانه داده های حسگر وجود دارد که توسط SOS منتشر شده است. اول سیاست استاتیک [ 17 ] است که در آن داده ها در یک بازه زمانی ثابت از پیش تعریف شده درخواست می شوند. این الگوریتم در بخش 3.2.1 بیان خواهد شد . دوم، Instant Policy است که به محض اتمام درخواست فعلی، درخواست دیگری به SOS ارسال می شود. این روش نوعی سرقت دسترسی است. ما آن را در بخش 5 مورد بحث قرار خواهیم داد . سومین خط مشی تطبیقی است که توسط آن فاصله زمانی خواب به صورت پویا قبل از هر درخواست داده حسگر محاسبه می شود. ما سه خط مشی تطبیقی را برای فرآیند ارائه داده شرح می دهیم: فیلتر Kalman در بخش 3.2.2.و کاهش ضربی افزایش افزایشی برای برداشت کننده (H-AIMD) و کاهش ضربی افزایشی برای برداشت کننده (H-MIAD) در بخش 3.2.3 .
3.2.1. خط مشی استاتیک
Static Policy به سادگی ارسال درخواست داده در یک بازه زمانی ثابت است. فاصله زمانی را می توان با دو روش تنظیم کرد. یکی این است که توسط کاربران تعریف شود، به این ترتیب، عملکرد زمان واقعی تا حد زیادی تحت تاثیر تجربه کاربر است. دیگری یادگیری آماری فواصل زمانی تاریخی است. میتوانیم یک هیستوگرام از فواصل زمانی رسم کنیم و مقدار پیک را انتخاب کنیم یا مقدار میانه را مستقیماً به عنوان بازه زمانی ثابت انتخاب کنیم. پس از تصمیم گیری بازه زمانی SI ، همانطور که در شکل 2 نشان داده شده است ، بازه زمانی تنظیم می شود 🝛🝛یک مقدار دائمی 0 خواهد داشت، به این معنی که Havestor پس از هر بازه زمانی ثابت SI یک درخواست داده ارسال می کند .
3.2.2. فیلتر کالمن
فیلتر کالمن (KF) [ 28 ] یک تکنیک تحلیل بازگشتی است که فرآیند و نویز اندازهگیری را با تخمین پارامترهای فیزیکی وابسته به زمان در نظر میگیرد. هنگامی که مدل نویز دقیق باشد، KF می تواند تخمین حالت بهینه را ارائه دهد. علاوه بر این، در محاسبات کارآمد است و به راحتی قابل درک است. همه این مزایا آن را به یک الگوریتم بسیار محبوب در سیستم های کنترل تبدیل می کند [ 23 ]. با این حال، تخمین دقیق نویز برای KF مورد نیاز است اگر دقت بالاتر مورد نظر باشد. با این تحلیلها، ما استفاده از KF را برای ارزیابی SI پیشینی حالت بعدی با SI قبلی در نظر میگیریم .
گردش کار KF در شکل 3 نشان داده شده است . شامل دو مرحله اصلی برای انجام گردش خون است. اولی به روز رسانی زمان (پیش بینی) و دومی به روز رسانی اندازه گیری (اصلاح). مرحله پیشبینی، ارزیابی وضعیت بعدی (کلمات قرمز رنگ در شکل 3 ) و انتشار خطا، با معادله (5) مربوطه برای محاسبه آنها است. در این معادله، ککشاخص شکاف زمانی گسسته است، با ایکس^k − 1ایکس^ک–1نشان دهنده وضعیت ارزیابی قبلی و ایکس^–کایکس^ک–تخمین اولیه وضعیت فعلی ( پیشینی ) است. پk − 1پک–1ماتریس کوواریانس خطای حالت قبلی است و پ–کپک–تخمین پیشینی ماتریس کوواریانس خطای فعلی است .توکتوکسیگنال کنترل است، و آآمخفف ماتریس انتقال حالت، ببماتریس پارامتر کنترل است و سسماتریس کوواریانس نویز فرآیند است.
{ایکس^–ک= Aایکس^k − 1+ بتوکپ–ک= Aپk − 1آتی+ س{ایکس^ک–=آایکس^ک–1+بتوکپک–=آپک–1آتی+س
پس از اینکه سیستم اندازه گیری جریان را دریافت کرد، KF به مرحله دوم، به روز رسانی اندازه گیری (تصحیح)، برای به روز رسانی ارزیابی اندازه گیری جریان، که در معادله (6) نشان داده شده است، می رود. کالمن Gain توسط کک کک، ایکس^کایکس^کبرآورد وضعیت فعلی است ( پسینی )، پکپککوواریانس خطا است. آرآرماتریس کوواریانس نویز اندازه گیری است، اچاچماتریس انتقال برای تغییر از فضای حالت به فضای اندازه گیری است، zک�کبردار اندازه گیری است:
⎧⎩⎨⎪⎪⎪⎪کک=پ–کاچتی( Hپ–کاچتی+ R )– 1ایکس^ک=ایکس^–ک+کک(zک– اچایکس^–ک)پک= ( من–ککاچ)پ–ک{کک=پک–اچتی(اچپک–اچتی+آر)–1ایکس^ک=ایکس^ک–+کک(�ک–اچایکس^ک–)پک=(من–ککاچ)پک–
تکرار KF از شروع می شود k = 0 ک=0، وقتی که ایکس0 و پ0ایکس0 و پ0به عنوان حالت اولیه ارائه می شود. سپس، میتوانیم با تکرار، که از تخمین حالت قبلی استفاده میکند، شروع کنیم ایکس^–کایکس^ک–و پ–کپک–به عنوان ورودی برای به دست آوردن تخمین پیشینی برای وضعیت فعلی. پس از آن، مجموعه معادله به روز رسانی اندازه گیری برای بدست آوردن مقدار تخمین استفاده می شود ایکس^کایکس^کاز ایکسایکسدر شکاف زمانی کک، که برای تکرار بعدی استفاده خواهد شد.
ما الگوریتم KF را به عنوان یک راه حل تک بعدی برای مدل پیشنهادی خود تطبیق می دهیم و سپس پارامترهای مربوطه را از پیش تعیین می کنیم. در این مطالعه، ککبه عنوان شاخص اقلام داده منتشر شده توسط SOS دیده می شود. ابتدا حالت اولیه را به صورت تنظیم می کنیم پ0= 1پ0=1و بازه زمانی اولیه به عنوان مقدار میانه فواصل تاریخ، یعنی ایکس0= میانه ( 𝛻تی1، 🝛تی2، 🝛تی3, … , 𝛻تیn)ایکس0=میانه(🝛تی1،🝛تی2،🝛تی3،…،🝛تی�). هیچ سیگنال کنترلی در فرآیند ارائه نیست، بنابراین توک= 0توک=0. بر این اساس، دیگر نیازی به در نظر گرفتن مقدار B نداریم . پارامتر نویز سسو آرآربه عنوان واریانس سری بازه زمانی تاریخی تعریف می شوند، بنابراین می توان آنها را با معادله (7) محاسبه کرد، که در آن n�تعداد بازه های زمانی است. در مسئله تک بعدی ما، هیچ انتقالی بین فضای حالت و فضای اندازه گیری لازم نیست، بنابراین A و H آ و اچهر دو ثابت 1 هستند:
Q = R =1n – 1∑l = 1n( _تیل–1n∑nl = 1🝛تیل)2س=آر=1�–1∑ل=1�(🝛تیل–1�∑ل=1�🝛تیل)2
3.2.3. H-AIMD و H-MIAD
یک الگوریتم جهانی بیداری وابسته به همبستگی تعادل انرژی (EB-CW) برای طرح شارژ مجدد حسگر برای تعیین رابطه بین فرآیند پویا گرههای حسگر قابل شارژ و وقوع رویداد پیشنهاد شد [25 ] . EB-CW می تواند به عملکرد مطلوب دست یابد اگر پارامترهای جهانی، مانند مقدار انرژی فرآیند شارژ و دشارژ حسگر، و احتمالات حالت بعدی، شناخته شده باشند. با این حال، در اکثر موارد نتوانستیم پارامترهای جهانی را بدست آوریم. سپس، الگوریتم محلی AIMD [ 20 ] به فعالسازی گره حسگر شارژ حسگر معرفی شد تا وضعیت و پارامترهای گرههای حسگر را به صورت پویا، از جمله بازههای زمانی فعالسازی، خواب و خواب تعیین کند.
ما بینشهایی را از AIMD قرض میگیریم و از آن در فرآیند ارائه دادههای حسگر به جای کاربرد اصلی آن در مطالعات تراکم شبکه [ 29 ] و شارژ مجدد حسگر [ 20 ، 24 ، 26 ] استفاده میکنیم. الگوریتم اصلاح شده H-AIMD، که در آن “H” نشان دهنده Harvestor است، برای محاسبه SI معرفی شده است. به طور مشابه، ما همچنین H-MIAD را در این بخش توصیف میکنیم و آزمایشها را بر روی آنها در بخش 4 انجام خواهیم داد، به دلیل تفاوت عملکرد بسیار زیاد بین الگوریتم AIMD و MIAD، که در [ 24 ] یافت میشود.
مراحل دقیق H-AIMD در الگوریتم 1 نشان داده شده است. اگر Harvestor داده های جدیدی دریافت نکرد، سپس SI را با مقدار افزایش دهید. ج1، ج1> 0 ج1، ج1>0; و اگر چنین شد، SI را با مقدار ضربی کاهش دهید ج2، ج2> 1 ج2، ج2>1. شرط تعیین کننده H-AIMD این است که Harvestor داده های جدیدی دریافت کند یا خیر، که ساده تر از مقایسه آستانه AIMD مورد استفاده برای فرآیند فعال سازی حسگر است. با در نظر گرفتن بسیاری از مطالعات که تأیید کرده اند که چه زمانی ج1= 1 ، ج2= 2 ج1=1، ج2=2، عملکرد بهترین است [ 24 ، 30 ]، ما از همان تنظیمات پارامتر در این مطالعه استفاده می کنیم. علاوه بر این، از آنجایی که Harvestor میتواند به راحتی مقادیر به دست آمده ( getNewData ، SI prev ) را به عنوان ورودی دریافت کند، این الگوریتم در عمل بسیار آسان است.
| الگوریتم 1 محاسبات تطبیقی SI از طریق H-AIMD | |
| 1. | ورودی: getNewData، SI prev |
| 2. | خروجی: SI بعدی |
| 3. | اگر getNewData = نادرست است ، پس |
| 4. | SI next = SI prev + c 1 |
| 5. | دیگر |
| 6. | SI بعدی = SI prev /c 2 |
| 7. | پایان اگر |
| الگوریتم پایان | |
به طور مشابه، H-MIAD از الگوریتم افزایش ضربی و کاهش افزایشی (MIAD) مشتق شده است و در ارائه داده هاروستور استفاده می شود. اگر Harvestor داده های جدیدی دریافت نکرد، SI next = SI prev × c 1 ، ج1> 1�1>1; و اگر چنین شد، SI next = SI prev − c 2 , ج2> 0ج2>0. در این تحقیق تعریف می کنیم ج1= 1.1 ، ج2= 1ج1=1.1، ج2=1.
3.3. سنجش عملکرد
در این مطالعه، ما یک ارزیابی عملکرد جامع را تعریف می کنیم پ= تابع ( E، دی ، دبلیو ) پ=تابع(�، �،دبلیو)با در نظر گرفتن سه عامل اول دقت SI next ( E ) است که نشان دهنده دقت مهرهای زمانی پیش بینی است. دوم، نرخ تأخیر داده ها ( D ) است که در بسیاری از برنامه ها نیز یکی از ملاحظات کلیدی است. و سوم اتلاف منابع ( W) که یک عنصر مورد بررسی برای افزونگی است. علاوه بر این، برای درک ویژگی های تعادل، باید از این که ارزش یک عامل آنقدر زیاد باشد که عوامل دیگر را سرکوب کند یا در ارزیابی بسیار کوچک باشد، پرهیز کرد. در این شرایط، ما فکر میکنیم که روش ارزیابی باید نرمالسازی شود تا بتوان الگوریتمهای مختلف را در کاربردهای مختلف با هم مقایسه کرد. در این بخش هر یک از این عوامل با توجه به این ملاحظات تعریف خواهد شد.
برای ارزیابی خطای SI ، میانگین مطلق خطای مقیاس شده (MASE) [ 31 ] استفاده می شود و با معادله (8) محاسبه می شود. E خطای ارزیابی است، Yتی�تیمشاهده در شکاف زمانی t است ، افتیافتیپیش بینی است و N تعداد آیتم های داده است. متفاوت از ریشه میانگین مربعات خطا (RMSE)، MASE مستقل از مقیاس است، که برای مقایسه خطا بین برنامه های مختلف بسیار مناسب است. اگر خطای پیشبینی کمتر از یک مرحله از سری دادهها باشد، MASE معمولاً کمتر از 1 است. E∈ [ 0 , 1 ]�∈[0، 1]، در غیر این صورت E= 1�=1. در این مطالعه، t ، i برای شاخص های بازه زمانی به جای شکاف های زمانی است.
E= ∑نt = 1|Yتی–افتی|نن– 1∑نi = 2|Yمن–Yمن – 1|�= ∑تی=1ن|�تی–افتی|نن–1∑من=2ن|�من–�من–1|
عامل دوم میزان تاخیر داده است D ( Π )�(Π). تحت الگوریتم ارائه داده ΠΠ، می توان آن را با رابطه (9) محاسبه کرد. تعداد کل داده های SOS εد( ن)�د(ن)و تعداد داده های با تاخیر εo( ن)��(ن)می توان به ترتیب با معادلات (3) و (4) به دست آورد. ظاهرا، D ( Π ) ∈ [ 0 , 1 ] ,�(Π)∈[0،1]،
D ( Π) = من _ _ن→ ∞εo( ن)εد( ن) �(�)= لمنمترن→∞��(ن)�د(ن)
سومین عامل میزان ضربه از دست رفته است دبلیو( Π )دبلیو(Π)، که طبق معادله (10) تحت الگوریتم ارائه داده قابل دستیابی است ΠΠ. تعداد کل درخواست δد( ن) �د(ن) ارسال شده به SOS را می توان با معادله (1) محاسبه کرد، کل درخواست های زباله که در آن داده های جدید با موفقیت به دست نیامده است δo( ن)��(ن)با رابطه (2) قابل محاسبه است. میتوتیم نتیجه بگیریم که دبلیو( Π ) ∈ [ 0 , 1 )دبلیو(Π)∈[0، 1).
دبلیو( Π ) = لیمن→ ∞δo( ن)δد( ن)دبلیو(Π)= لیمن→∞��(ن)�د(ن)
{پ= 1 – (ω1× E+ω2× D +ω3× W)ω1+ω2+ω3= 1{پ=1–(�1×�+�2×�+�3×دبلیو)�1+�2+�3=1
با همه عوامل تعریف شده، مدل ارزیابی عملکرد نرمال شده وزنی را می توان با رابطه (11) محاسبه کرد، که در آن ω1�1، ω2�2، ω3�3همگی ضرایب وزنی هستند و کمتر از 0 نیستند. زیرا E∈ [ 0 , 1 ] , D ( Π ) ∈ [ 0 , 1 ] , W ( Π ) ∈ [ 0 , 1 ) و _ ω1∈ [ 0 , 1 ]�∈[0، 1]، �(Π)∈[0، 1]، دبلیو(Π)∈[0، 1)، و �1∈[0، 1]، ω2∈ [ 0 , 1 ]�2∈[0، 1]، ω3∈ [ 0 , 1 ]�3∈[0، 1]، می توانیم دریافت کنیم ω1× E∈ [ 0 , ω1] ، ω2× D ∈ [ 0 ، ω2] ، ω3× W∈ [ 0 , ω3)�1×�∈[0، �1]، �2×�∈[0، �2]، �3×دبلیو∈[0، �3)، سپس (ω1× E+ω2× D +ω3× W) ∈ [ 0 , ω1+ω2+ω3) = [ 0 , 1 )(�1×�+�2×�+�3×دبلیو)∈[0، �1+�2+�3)=[0، 1). بنابراین، P∈ (0، 1]، بنابراین عملکرد مستقل از مقیاس است. با توجه به این طراحی معادله نرمال شده، عملکرد الگوریتم های مختلف را می توان در یک برنامه مقایسه کرد و همان الگوریتم را نیز می توان در برنامه های مختلف مقایسه کرد.
4. آزمایش ها و نتایج
این مطالعه سه محیط داده حسگر واقعی شامل غلظت متان معدن زغال سنگ WangJiaLing در استان شانشی، رطوبت خاک BaoXie و سوابق GPS تاکسی ووهان در استان هوبی، همه در چین را در نظر گرفت. دو مورد اول سنسورهای درجا هستند ، در حالی که سومی داده های سنسور موبایل است. در این بخش، آزمایش های چهار الگوریتم شرح داده شده در بخش 3.2 در این محیط ها انجام خواهد شد. علاوه بر این، نتایج بازده زمانی، میزان تاخیر و میزان اتلاف در شکل ها نشان داده شده و در جداول ذکر شده است.
4.1. غلظت گاز یک معدن زغال سنگ
متان یک گاز بسیار انفجاری است که در لایه های زغال سنگ به دام افتاده است [ 3 ]. هنگامی که غلظت گاز به حدی برسد، خفگی کشنده و خطر انفجار قابل توجه می شود. بنابراین، نظارت بدون وقفه حیاتی است [ 3 ]. بنابراین سنسورهای گاز منبع تغذیه بسیار پایداری دارند و قادر به دریافت مشاهدات در بازه های زمانی بسیار پایدار هستند. داده های آزمایشی مورد استفاده در این بخش از حسگرهای گاز مستقر در معدن زغال سنگ WangJiaLing با فرکانس نظارت استاتیک 30 ثانیه در رکورد بدست می آید. با این داده ها، دو آزمایش بر روی 500 رکورد انجام می شود.
اولین آزمایش بر روی رابطه بین تاخیر زمانی اولیه و ضریب عملکرد MASE چهار الگوریتم انجام می شود که در شکل 4 نشان داده شده است . فیلتر کالمن (KF) دارای کمترین مقادیر MASE است، کمتر از 0.001، که بسیار نزدیک به صفر است و باعث می شود خط با محور x منطبق شود . H-AIMD نیز بسیار پایدار است و دارای MASE کمتری نسبت به H-MIAD است که خط آن نوسانات بیشتری دارد. در عین حال، خط سیاست استاتیک با افزایش تاخیر زمانی به صورت خطی افزایش می یابد. این نشان می دهد که تأخیر زمانی اولین آیتم داده بر عملکرد سیاست استاتیک تأثیر زیادی دارد.
پس از آزمون تاخیر زمانی اولیه، تاثیر افزایش تعداد آیتم های درخواستی نیز بر روی فاکتورهای عملکرد بین چهار الگوریتم با تاخیر زمانی اولیه 10 ثانیه بررسی می شود، همانطور که در شکل 5 مشاهده می شود . شکل 5 a نشان دهنده تغییر MASE با تعداد آیتم های داده درخواستی است و شکل 5b بخشی از 50 مورد داده اول را در (a) بزرگ می کند. این دو نمودار فرعی نشان میدهند که خط مشی Static دارای یک مقدار MASE ثابت 0.33 است، در حالی که پس از برخی نوسانات، مقدار H-AIMD به حدود 0.25 همگرا میشود که کمتر از سیاست استاتیک است. مقدار KF به آرامی به مقدار بسیار نزدیک به 0 در حدود 50 مورد داده کاهش یافته است. این به دلیل تاخیر زمانی 10 ثانیه ای مورد اول است، MASE 0.17 است، اما از زمان درخواست داده دوم، KF می تواند یک بازه زمانی بسیار دقیق را با پارامترهای محاسبه شده از طریق معادلات (5)-(7) پیش بینی کند، بنابراین منجر به کاهش مداوم با درخواست داده های بیشتر می شود. علاوه بر این، H-MIAD نه تنها ناپایدار است، بلکه دارای MASE نسبتاً بالاتری نسبت به سیاست های دیگر است، و همچنین دارای نرخ تاخیر است در حالی که بقیه برابر با 0 هستند، مشاهده شده از شکل 5 ج . شکل 5d نشان می دهد که میزان اتلاف H-AIMD نسبتاً بالا با یک مقدار پایدار در حدود 0.52 است، و نرخ H-MIAD حدود 0.2 است. نرخ اتلاف Static و KF برابر با 0 است، به این معنی که آنها هیچ درخواست نامعتبری در این آزمایش ندارند.
4.2. مشاهدات رطوبت خاک
حسگرهایی که رطوبت خاک را مشاهده می کنند برای کشاورزی مدرن [ 4 ] در فضای باز مستقر می شوند و معمولاً توسط انرژی خورشیدی شارژ می شوند. در روز، اگر هوا آفتابی باشد یا نور روز بسیار مناسب باشد، نیروی جذب شده توسط باتری خورشیدی برای کارکرد سنسورها کافی است. در غیر این صورت، اگر شب باشد یا هوا بارانی یا ابری باشد، انرژی نمی تواند مشاهدات مداوم را پشتیبانی کند. بنابراین، منجر به توقف طولانی مدت بدون ثبت داده ها می شود. از آنجایی که این نوع کاربرد سختگیرانه زمانی نیست، به طور کلی فرکانس پایین است. در این مطالعه، دادههای یک سنسور رطوبت خاک مستقر در Baoxie، استان هوبی، چین، دارای 4554 رکورد در یک سال از ژانویه 2014 تا ژانویه 2015 است. واحد زمان حداقل است.
بخشی از داده های نمونه در شکل 6 نشان داده شده است . از شکل می توان نتیجه گرفت که فاصله زمانی پایدار 60 دقیقه با نوساناتی است که بیشتر آنها زیر خط پایدار 60 دقیقه است. برای مثال، دادههایی که با یک مستطیل قرمز مشخص شدهاند، نوسانات منظمی را نشان میدهند که میتواند ناشی از برخی عملیات مصنوعی باشد، در حالی که برخی دیگر بدون الگوهای واضح به احتمال زیاد ناشی از نویز محیطی هستند. فاصله زمانی که با یک دایره قرمز کوچک مشخص شده است، 3668 دقیقه، حدود دو روز و نیم است، که بسیار بزرگتر از مقدار معمولی 60 دقیقه است. این وضعیت ممکن است در اثر آب و هوای شدید یا خرابی ماشین ایجاد شود. در این بخش از فاصله زمانی میانه 60 دقیقه به عنوان SI اولیه استفاده شد که به صورت پیشین ارائه شده است.مقدار برای سیاست استاتیک.
با این داده ها، الگوریتم ها را آزمایش می کنیم و مقادیر عملکرد نشان داده شده در جدول 2 را بدست می آوریم . مشاهده می شود که میزان تاخیر داده ها و MASE H-AIMD بسیار کم و بسیار کمتر از سایرین است. در مقابل، نرخ تاخیر بسیار بالای داده، H-MIAD و KF را برای این نوع ارائه داده نامناسب می کند. با این حال، خط مشی Static دارای MASE و نرخ تاخیر نسبتاً پایینی است.
4.3. داده های GPS تاکسی شهری
تاکسی ها به عنوان یکی از مهم ترین ابزارهای حمل و نقل، به یک منبع داده مهم برای بسیاری از کاربردها مانند داده کاوی، برنامه ریزی جاده ها و ساخت زیرساخت های حمل و نقل تبدیل شده اند. سپس دادههای جمعآوریشده توسط ابزارهای GPS برای نظارت در زمان واقعی به مرکز ترافیک منتقل میشوند. باید توجه داشت که سیگنالهای GPS کمی تحت تأثیر محیطها قرار میگیرند، به عنوان مثال، دهانههای بلند ساختمان و پل، یا اگر رانندگان در حال استراحت، صرف وعدههای غذایی یا منتظر مسافران باشند، برای مدت نسبتاً طولانی اطلاعاتی وجود ندارد. در آزمایش این بخش، از سوابق داده های GPS 1309 یک تاکسی در یک روز در شهر ووهان، استان هوبی، چین استفاده می کنیم.
فواصل داده های نمونه در شکل 7 مشاهده می شود که ویژگی های بازه زمانی داده های GPS تاکسی را نشان می دهد. ما متوجه شدیم که یک فاصله زمانی پایدار 40 ثانیه وجود دارد، در حالی که نوسانات زیادی نیز وجود دارد که ناشی از محیط و تجربه رانندگی رانندگان است. سپس، اگر نگاهی به نقطه ای که با دایره قرمز کوچک مشخص شده است، بیندازید، نشان دهنده یک فاصله زمانی پنج دقیقه ای است. این وضعیت اغلب اتفاق می افتد زیرا راننده باید هر چند وقت یکبار منتظر مسافران باشد. علاوه بر این، ما همچنین یک بازه زمانی پیدا کردهایم که هیچ مشاهدهای را در حدود پنج ساعت نشان نمیدهد، که ممکن است ناشی از بازرسی و نگهداری خودرو یا استراحت راننده باشد. در این مطالعه، فاصله زمانی میانه 40 ثانیه به عنوان فاصله زمانی ثابت برای خط مشی استاتیک استفاده شد.
با استفاده از این دادههای حسگر موبایل، آزمایش عملکرد چهار الگوریتم در ارائه دادهها را که در جدول 3 نشان داده شدهاند، انجام دادیم . ما متوجه شدیم که مانند نتایج نشان داده شده در بخش 4.2 ، H-AIMD نیز دارای کمترین نرخ تاخیر و MASE است، اگرچه میزان ضایعات آن نسبتاً بالا است. به طور مشابه، خط مشی استاتیک مقادیر نسبتاً کمتری از این عوامل نسبت به KF و H-MIAD دارد. با این حال، فیلتر کالمن بدترین MASE و نرخ تاخیر را در این آزمایش به دلیل حساسیت بیش از حد به نوسانات نشان می دهد.
5. بحث
در این بخش ابتدا به مزایا و معایب روش های ارائه و سپس وضعیت کاربرد مدل ما و روش ارزیابی عملکرد پرداخته می شود. پس از آن، مقایسه چهار الگوریتم در آزمایش های ارائه داده های حسگر واقعی با داده های عملکرد جدول 1 و جدول 2 انجام شده است . سپس، تحلیل دقیق علت تأثیرگذاری بر عملکردها ساخته میشود. پس از آن، شرایط مختلف کاربردی الگوریتمها را در محیطهای حسگر فرکانس بالا مورد بحث قرار میدهیم.
در مورد روشهای ارائه، میتوانیم سیاست فوری را انتخاب کنیم، که با آن آخرین دادهها قرار است بلافاصله پس از درخواست قبلی، که در بخش 3.2 ذکر شده است، بهدست آیند.. بدیهی است که این روش دارای حداکثر کارایی زمان واقعی است، اما فرکانس بسیار بالا ممکن است منجر به هدر رفتن منابع عظیم شود. بدتر از آن، تا حد زیادی بار سرورهای داده SOS را افزایش می دهد، که منجر به پاسخ کم در هنگام دسترسی به داده های موازی عظیم می شود، بنابراین کارایی آن را به صورت معکوس کاهش می دهد. علاوه بر این، برخی از حسگرها فرکانس مشاهده خود را با توجه به برخی شرایط، مانند کنترل انسان، تامین انرژی کم، یا نظارت خودسازگاری محیط، تغییر میدهند. بنابراین، برای به حداقل رساندن تعداد تأخیر دادهها، کاهش بار کاری سرور داده و برداشتکننده، و بهدست آوردن مؤثر آخرین دادهها، سیاست Static و سایر الگوریتمهای خود تطبیقپذیر ترجیح داده میشوند.
ما یک مدل ارائه را برای تجزیه و تحلیل مشکل بلادرنگ روش دسترسی به داده مبتنی بر کشش برای سرویسهای مشاهده حسگر شبکههای حسگر پیشنهاد کردیم. این مدل بر روی ارائه دادههای یک حسگر واحد تمرکز میکند، اما میتوان آن را به راحتی برای تعداد زیادی از سنسورها استفاده کرد، با همکاری مکانیزم مدیریت تامین انعطافپذیر که توسط کار قبلی ما معرفی شد [27، 32 ] .]. این یک نوع روش پردازش دسته ای است که با آن داده های هر سنسور به طور مستقل به عنوان خط لوله پیکربندی شده و توسط یک واحد کنترل مدیریت می شود. بر اساس مکانیسم و مدل پیشنهادی ما، یک شرکت تاکسیرانی میتواند با پشتیبانی سختافزاری کافی، ارائه دادههای هزاران خودرو را انجام دهد، اگرچه تنها یک داده تاکسی برای آزمایش عملکرد بلادرنگ چهار سیاست در بخش 4.3 استفاده شد . علاوه بر این، این مدل نه تنها برای شبکه های حسگر مناسب است، بلکه برای سایر جمع آوری داده های زمان واقعی مبتنی بر کشش نیز استفاده می شود.
بر اساس مدل ریاضی، سه عامل ارزیابی عملکرد نیز مطرح شده است. MASE که مستقل از مقیاس است، خطای پیشبینی فواصل زمانی را نشان میدهد. هم MASE و هم نرخ تاخیر دلالت بر کارایی سیاست های مختلف دارند. اتلاف منابع درصد درخواستهای دادههای اضافی، یعنی استفاده نامعتبر از منابع را نشان میدهد. وزن سه عامل نشان داده شده در معادله (11) را می توان به طور انعطاف پذیر در کاربردهای مختلف تنظیم کرد تا بیشترین بازده زمانی را با کمترین اتلاف منابع تضمین کند. بر اساس این ملاحظات، ما عملکرد جامع را در بخش 4 محاسبه نکردیم . با این حال، طراحی نرمال سازی این عوامل ارزیابی را برای مقایسه عملکرد بین سیاست های مختلف یا سیاست های مشابه بین برنامه های مختلف بسیار سازگار می کند.
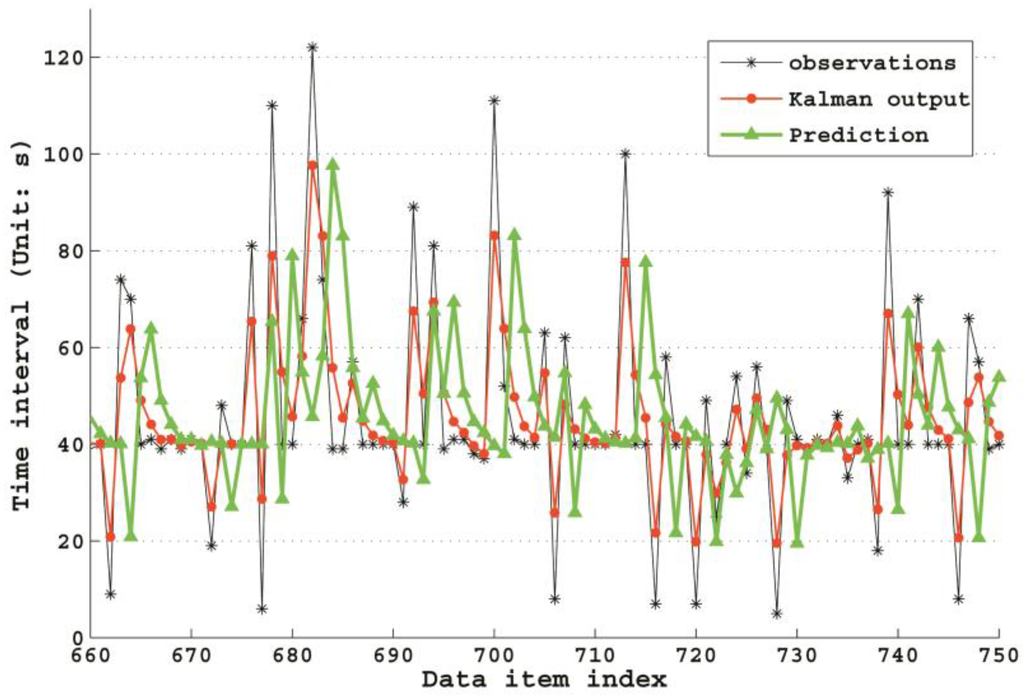
فیلتر کالمن عملکرد بسیار بالایی در یک برنامه بازه زمانی پایدار دارد. به این دلیل است که الگوریتم KF می تواند به تدریج به مقادیر واقعی همگرا شود، در حالی که در دو کاربرد دیگر، عملکرد آن به دلیل اینکه مدل نویز دقیق بدست نمی آید، ایده آل نیست، سپس با ارزیابی پیشینی وضعیت فعلی، خطاهای بزرگی ایجاد خواهد کرد. به عنوان مقدار پیش بینی اجازه دهید نگاهی عمیقتر به مکانیسم پیشبینی KF در شکل 8 بیندازیم ، که نمونهای از فواصل زمانی GPS را با پیشبینیهای پیشینی Kalman (خط سبز) و خروجی تصحیح پسینی (خط قرمز) نشان میدهد. با توجه به تنظیمات پارامتر در بخش 3.2.2 ، در این مطالعه، پیشینیمقادیر پیشبینی شده برابر با مقادیر پسینی ارزش حالت قبلی است. در شکل 8 ، اگر خط قرمز را در امتداد x حرکت دهیدمحور برای یک مرحله، می توانیم خط سبز را دریافت کنیم. بنابراین، میتوانیم نتیجه بگیریم که دلیل اینکه چرا عملکرد الگوریتم KF در دو آزمایش اخیر چندان ایدهآل نیست این است که نمیتوانیم نویز را به طور دقیق تخمین بزنیم، که باعث میشود خطای پیشبینی بسیار بالا باشد. با این تحلیلها، میتوان به راحتی درک کرد که الگوریتم KF دقت پیشبینی زمانی پایینی دارد، که منجر به نرخ تاخیر بالا در برنامههای کاربردی با نوسانات بازه زمانی زیاد تولید شده توسط نویزهای محیط میشود. با این حال، در کاربردهای بازه زمانی ثابت، عملکرد آن میتواند به تدریج به حد مطلوب حتی با مقدار اولیه ضعیف همگرا شود. بنابراین، الگوریتم KF برای ارائه داده های حسگر طولانی مدت با فواصل زمانی نسبتاً پایدار مناسب است.
ما H-MIAD و H-AIMD را پیشنهاد کردیم و بینشهایی از الگوریتمهای تراکم شبکه MIAD و AIMD را به عاریت گرفتیم. نشان داده شده توسط آزمایشات در بخش 4 ، H-AIMD عملکرد کلی بسیار پایدار و بالایی تحت انواع مختلف کاربردهای داده حسگر دارد. به طور کلی، H-AIMD با افزایش فرکانس درخواست داده، کارایی بالا در زمان واقعی و تعداد کم تاخیر داده را دریافت می کند، در نتیجه منجر به اتلاف منابع بیشتر می شود. در مقابل، عملکرد H-MIAD بسیار پایین است که نمیتوان از آن برای ارائه داده استفاده کرد. این یافته با کار قبلی در مورد شناسایی نظری الگوریتمهای MIAD و AIMD مطابقت دارد، که کشف میکند که AIMD بسیار پایدار است در حالی که MIAD یک الگوریتم نامطلوب است [ 24 ].
با تجزیه و تحلیل الگوریتم های بالا می توان دریافت که الگوریتم ها می توانند برای انواع مختلف کاربردها مناسب باشند. اگر یک سنسور دارای یک بازه زمانی مشاهدات ثابت باشد و هر مهر زمانی را بتوان به راحتی و با دقت استنباط کرد، در این صورت نیازی به اجرای الگوریتمهای ارائه پویا نیست زیرا سیاست استاتیک در این شرایط عملکرد عالی خواهد داشت. در واقع، سیاست استاتیک نیاز به پیشینی دقیق داردمولفه های. زمانی که بازه زمانی با برخی تنظیمات گهگاهی بسیار پایدار باشد، الگوریتم بازگشتی KF می تواند تغییر را جبران کند و به تدریج به مقدار جدید همگرا شود. بنابراین، KF عملکرد عالی در این شرایط دارد. الگوریتم خطی H-AIMD، در مقابل، زمانی که نویزهای محیطی نامشخصی وجود دارد، عملکرد پایدارتر و بالاتری نسبت به سایرین دارد. ظاهراً الگوریتمهای KF و H-AIMD میتوانند به صورت پویا فاصله زمانی را با توجه به حالتهای مختلف تنظیم کنند و هیچ مقدار پیشینی دقیقی مورد نظر نیست.
6. نتیجه گیری
استانداردهای متداول خدمات وب حسگر برای دسترسی به داده ها مبتنی بر کشش هستند که نمی تواند کارایی زمان واقعی را تضمین کند. ما فرآیند ارائه دادههای حسگر در زمان واقعی را مدلسازی کردیم، سه الگوریتم ارائه دینامیکی خود تطبیقی را پیشنهاد کردیم و آنها را با سیاست استاتیک با سه عامل ارزیابی عملکرد پیشنهادی در این مطالعه مقایسه کردیم. مدل ما برای پلتفرمهای اطلاعات جغرافیایی بلادرنگ مناسب است و روش ارزیابی عملکرد نیز نه تنها برای الگوریتمهای مختلف در یک برنامه، بلکه برای الگوریتم مشابه در برنامههای مختلف امکانپذیر است. با این حال، هنوز نگرانی هایی برای کار آینده ما وجود دارد. از آنجایی که برای تنظیم پارامترهای الگوریتم H-AIMD در این مقاله فقط به ادبیات مراجعه می کنیم، تجزیه و تحلیل دقیقتر و آزمایشهای کافی بر روی دادههای حسگر واقعی برای بررسی تنظیمات بهینه این پارامترها در آینده انجام خواهد شد. الگوریتم های ممکن بیشتری نیز می توانند در این مدل معرفی شوند.
منابع
- کولر، دی. مولدر، اچ. حسگرهای هوشمند برای شبکهسازی جهان. علمی صبح. 2004 ، 290 ، 84-91. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- خو، دبلیو. گونگ، جی. وانگ، ام. توسعه، کاربرد و چشمانداز ماهوارههای رصد زمینی چینی. ژئو اسپات. Inf. علمی 2014 ، 17 ، 102-109. [ Google Scholar ] [ CrossRef ]
- Dougherty، HN; Karacan, CO مجموعه نرم افزاری جدید کنترل و پیش بینی متان برای معادن لانگ وال. محاسبه کنید. Geosci. 2011 ، 37 ، 1490-1500. [ Google Scholar ] [ CrossRef ]
- چن، ن. ژانگ، ایکس. Wang, C. یکپارچه وب سرویس فضایی باز یکپارچه زیرساخت اطلاعات فیزیکی-سایبری را برای نظارت دقیق کشاورزی فعال کرد. محاسبه کنید. الکترون. کشاورزی 2015 ، 111 ، 78-91. [ Google Scholar ] [ CrossRef ]
- فن، اچ. لی، جی. چن، ن. هو، سی. مدل نمایش قابلیت برای سنسورهای سنجش از دور ناهمگن: مطالعه موردی در پایش رطوبت خاک. محیط زیست مدل. نرم افزار 2015 ، 70 ، 65-79. [ Google Scholar ] [ CrossRef ]
- یوان، نیوجرسی؛ ژنگ، ی. Xie، X. وانگ، ی. ژنگ، ک. Xiong، H. کشف مناطق عملکردی شهری با استفاده از مسیرهای فعالیت نهفته. IEEE Trans. بدانید. مهندسی داده 2015 ، 27 ، 712-725. [ Google Scholar ] [ CrossRef ]
- فییو، م. وی، جی. Yingying، M. بازیابی مشخصات نسبت لیدار آئروسل با ترکیب لیدارهای الاستیک مبتنی بر زمین و فضا. انتخاب کنید Lett. 2012 ، 37 ، 617-619. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- فاستر، I. علم خدمات محور. علوم 2005 ، 308 ، 814-817. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- اسزلای، ا. گری، جی. تلسکوپ جهانی. Science 2001 ، 293 ، 2037-2040. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- کیس، آر. Crofoot، MC; جتز، دبلیو. ویکلسکی، ام. ردیابی حیوانات زمینی به عنوان چشمی در زندگی و سیاره. Science 2015 , 348 . [ Google Scholar ] [ CrossRef ] [ PubMed ]
- چن، ن. دی، ال. یو، جی. Min, M. یک سرویس مشاهدات حسگر جغرافیایی انعطاف پذیر برای داده های حسگر متنوع بر اساس وب سرویس. ISPRS J. Photogramm. Remote Sens. 2009 , 64 , 234-242. [ Google Scholar ] [ CrossRef ]
- دواراجو، ع. جیرکا، س. کانکل، آر. Sorg، J. Q-SOS – یک سرویس مشاهده حسگر برای دسترسی به توضیحات با کیفیت داده های محیطی. ISPRS Int. J. Geo-Inf. 2015 ، 4 ، 1346-1365. [ Google Scholar ] [ CrossRef ]
- برورینگ، آ. فورستر، تی. Jirka, S. الگوهای تعامل برای پل زدن شکاف بین شبکه های حسگر و شبکه حسگر. در مجموعه مقالات هشتمین کنفرانس بین المللی IEEE 2010 در کارگاه های آموزشی فراگیر محاسبات و ارتباطات (کارگاه های آموزشی PERCOM)، مانهایم، آلمان، 29 مارس تا 2 آوریل 2010. صص 732-737.
- چن، ن. دی، ال. یو، جی. گونگ، جی. Wei, Y. استفاده از CSW مبتنی بر ابریم با خدمات مشاهده حسگر برای ثبت و کشف مشاهدات سنجش از دور. محاسبه کنید. Geosci. 2009 ، 35 ، 360-372. [ Google Scholar ] [ CrossRef ]
- چن، ن. چن، ز. دی، ال. Gong, J. روشی کارآمد برای بازیابی در زمان واقعی مشاهدات سنجش از دور. IEEE J. Sel. بالا. Appl. زمین Obs. Remote Sens. 2011 , 4 , 615-625. [ Google Scholar ] [ CrossRef ]
- جیرکا، س. بروینگ، ا. Stasch, C. مکانیسم های کشف برای وب حسگر. Sensors 2009 , 9 , 2661-2681. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- جیرکا، س. برویرینگ، آ. Kjeld، P. میدنز، جی. Wytzisk، A. یک رویکرد سبک وزن برای سرویس مشاهده حسگر برای به اشتراک گذاری داده های محیطی در سراسر اروپا. ترانس. GIS 2012 ، 16 ، 293-312. [ Google Scholar ] [ CrossRef ]
- صالح، AAA-A. زینی، NLACA; Zhahir, A. مناسب بودن نرخ به روز رسانی گیرنده های GPS برای برنامه های ناوبری. بین المللی Sch. علمی Res. نوآوری. 2013 ، 7 ، 1012-1019. [ Google Scholar ]
- هوانگ، سی. لیانگ، اس. یک سیستم فشاری هیبریدی برای اعلانهای تقریباً همزمان در وب حسگر. در مجموعه مقالات کنگره XXII ISPRS، کمیسیون فنی چهارم، ملبورن، VIC، استرالیا، 25 اوت تا 1 سپتامبر 2012. ص 421-425.
- مردی، اس آر. جگی، ن. Pendse، R. یک الگوریتم تطبیقی برای فعالسازی حسگر در سیستمهای حسگر مبتنی بر انرژیهای تجدیدپذیر. در مجموعه مقالات پنجمین کنفرانس بین المللی 2009 در مورد حسگرهای هوشمند، شبکه های حسگر و پردازش اطلاعات (ISSNIP)، ملبورن، VIC، استرالیا، 7-10 دسامبر 2009. صص 55-60.
- روتری، آ. پرادان، AK; Rao, KP یک فیلتر کالمن جدید برای تخمین فرکانس سیگنال های تحریف شده در سیستم های قدرت. IEEE Trans. ساز. Meas. 2002 ، 51 ، 469-479. [ Google Scholar ] [ CrossRef ]
- گروبر، آ. کلاغ، دبلیو. دوریگو، دبلیو. Wagner, W. پتانسیل فیلتر کالمن دو بعدی برای جذب داده های رطوبت خاک. سنسور از راه دور محیط. 2015 ، 171 ، 137-148. [ Google Scholar ] [ CrossRef ]
- فراگر، ر. درک اساس فیلتر کالمن از طریق یک مشتق ساده و شهودی. فرآیند سیگنال IEEE Mag. 2012 ، 29 ، 128-132. [ Google Scholar ] [ CrossRef ]
- جگی، ن. ماداکاسیرا، اس. ردی مردی، اس. Pendse، R. الگوریتمهای تطبیقی برای فعالسازی حسگر در سیستمهای حسگر مبتنی بر انرژیهای تجدیدپذیر. Ad Hoc Netw. 2013 ، 11 ، 1405-1420. [ Google Scholar ] [ CrossRef ]
- جگی، ن. کار، ک. Krishnamurthy، A. فعال سازی حسگر قابل شارژ تحت رویدادهای زمانی مرتبط. سیم. شبکه 2009 ، 15 ، 619-635. [ Google Scholar ] [ CrossRef ]
- ماداکاسیرا، اس. تحلیل عملکرد یک الگوریتم تطبیقی برای فعالسازی حسگر در سیستمهای حسگر مبتنی بر انرژیهای تجدیدپذیر. پایان نامه کارشناسی ارشد، دانشگاه ایالتی ویچیتا، ویچیتا، KS، ایالات متحده آمریکا، 2008. [ Google Scholar ]
- لی، اچ. فن، اچ. وو، اچ. فنگ، اچ. Li, P. Resdap: معماری سیستم ارائه داده در زمان واقعی برای شبکه های حسگر. در وب و سیستم های اطلاعات جغرافیایی بی سیم ; Springer: برلین، آلمان، 2014; صص 85-99. [ Google Scholar ]
- کالمن، RE یک رویکرد جدید برای فیلتر کردن خطی و مشکلات پیشبینی. J. Fluids Eng. 1960 ، 82 ، 35-45. [ Google Scholar ] [ CrossRef ]
- چیو، دی.-م. جین، آر. تجزیه و تحلیل الگوریتم های افزایش و کاهش برای جلوگیری از تراکم در شبکه های کامپیوتری. محاسبه کنید. شبکه سیستم ISDN 1989 ، 17 ، 1-14. [ Google Scholar ] [ CrossRef ]
- کای، ال. شن، ایکس. پان، جی. Mark, JW تجزیه و تحلیل عملکرد الگوریتم های aimd سازگار با tcp برای برنامه های چند رسانه ای. IEEE Trans. چندتایی. 2005 ، 7 ، 339-355. [ Google Scholar ] [ CrossRef ]
- Hyndman، RJ; کوهلر، AB نگاهی دیگر به معیارهای دقت پیشبینی. بین المللی J. پیش بینی. 2006 ، 22 ، 679-688. [ Google Scholar ] [ CrossRef ]
- فن، اچ. لی، اچ. یک مدل ارائه بر اساس تقاضا برای اطلاعات چندمنبعی جغرافیایی با خدمات خودسازگاری فعال. Proc. SPIE 2015 . [ Google Scholar ] [ CrossRef ]
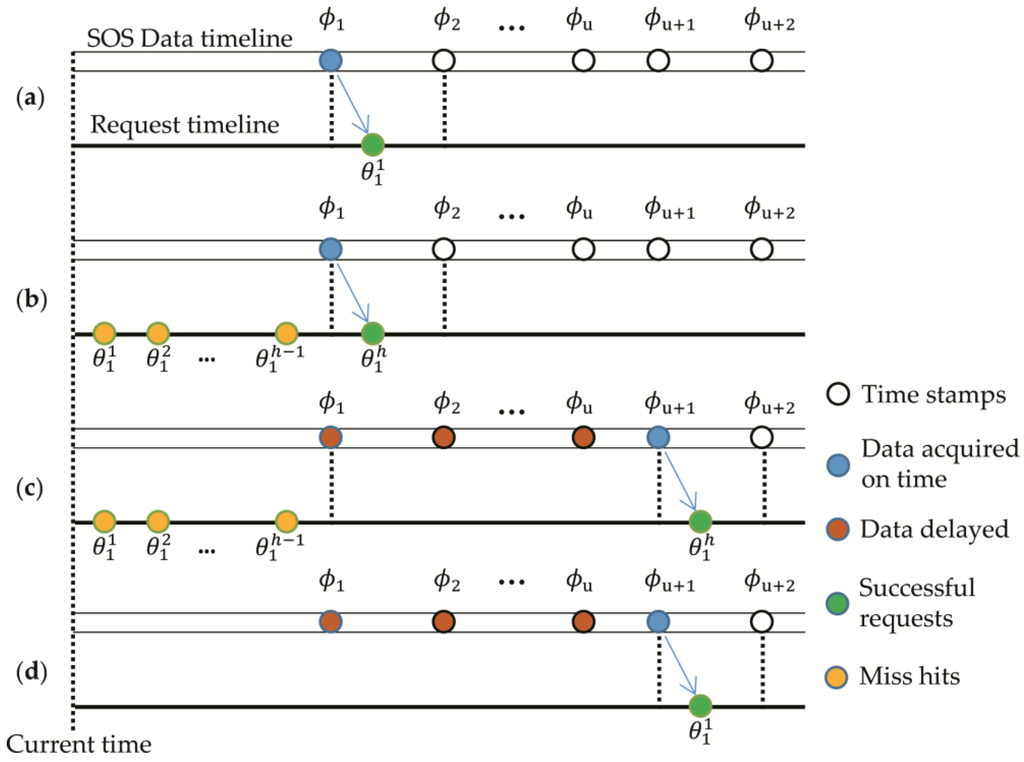
شکل 1. چهار مورد درخواست برای اقلام داده در مهر زمانی ϕ1 �1با جدول زمانی سمت راست
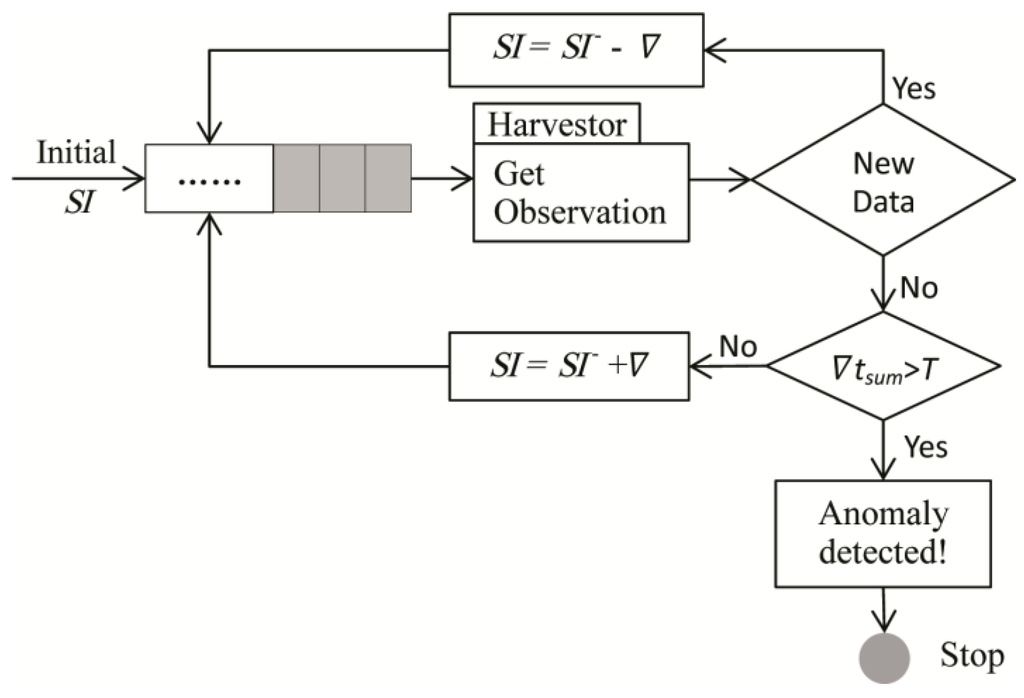
شکل 2. مدل ارائه زمان گسسته.

شکل 3. حلقه بازگشتی فیلتر کالمن.
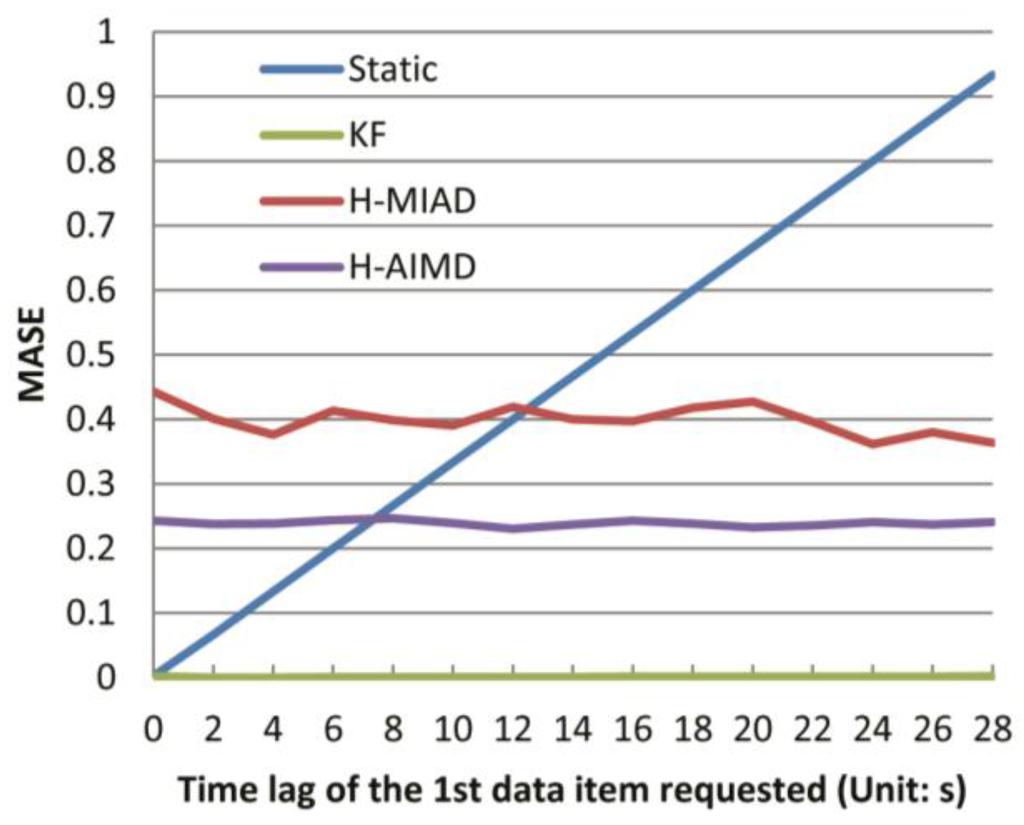
شکل 4. تأثیر تاخیر زمانی اولیه بر میانگین خطای مقیاس مطلق (MASE).
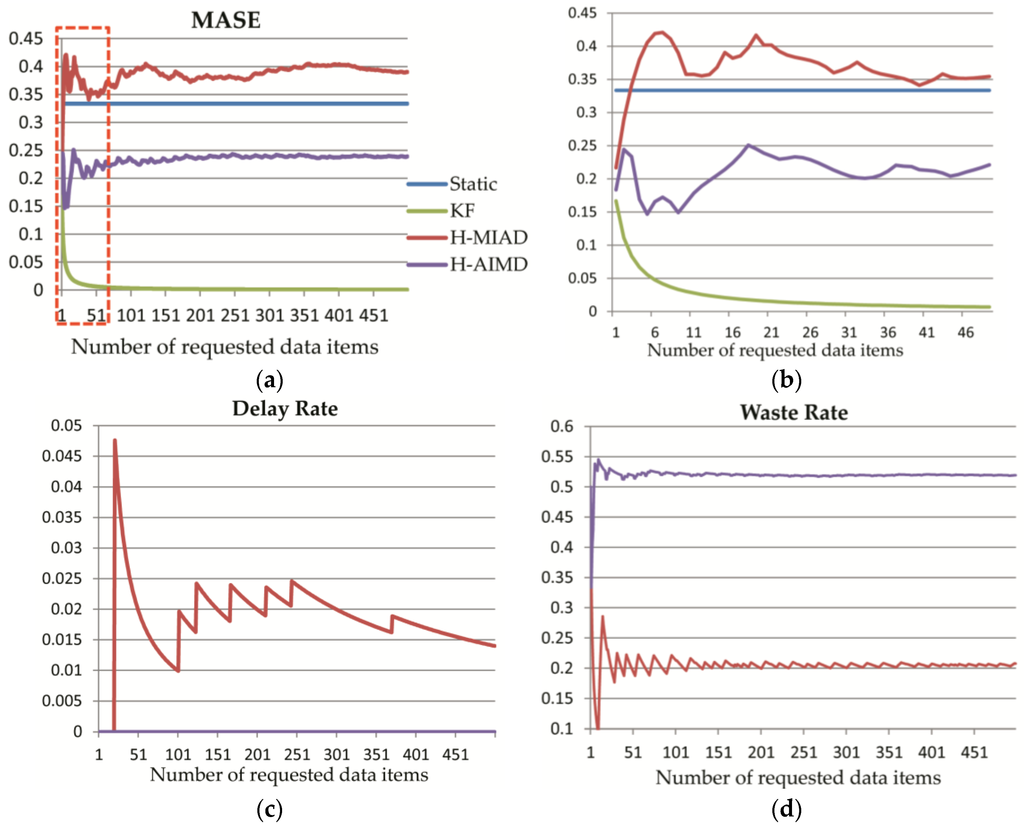
شکل 5. عملکرد متناظر خطمشیها با افزایش موارد درخواستی: ( الف ) تغییر میانگین مقیاس مطلق خطا (MASE)، که در آن کادر قرمز نقطهگذاری شده در (b) بزرگنمایی میشود. ( ب ) قسمت مستطیل قرمز رنگ (الف) با تعداد داده های درخواستی از 1 تا 50. ( ج ) نرخ تاخیر؛ ( د ) میزان ضایعات.
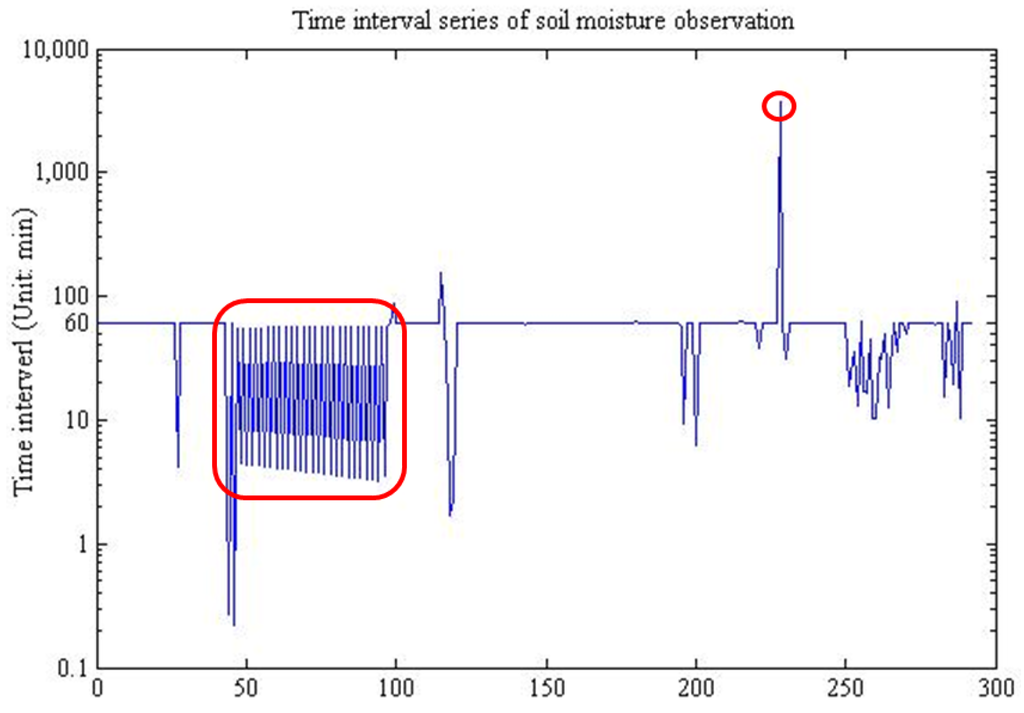
شکل 6. سری فاصله زمانی مشاهده رطوبت خاک.
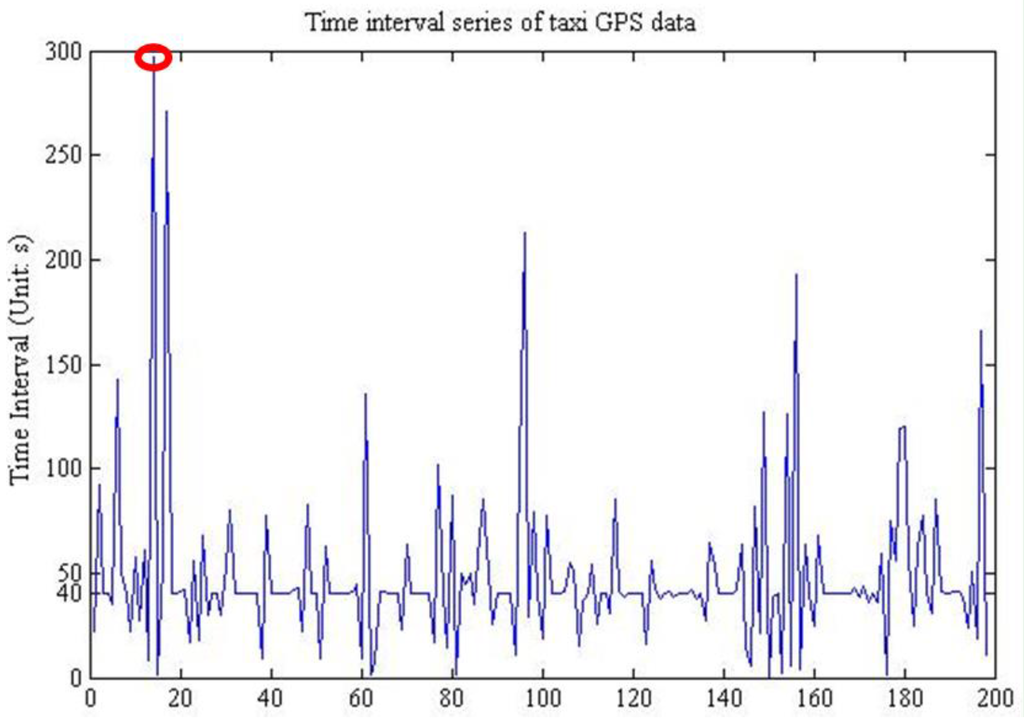
شکل 7. سری فاصله زمانی داده های GPS تاکسی.

شکل 8. پیش بینی و ارزیابی فواصل زمانی GPS تاکسی توسط فیلتر کالمن.

جدول 1. معنی اصطلاحات.
جدول 2. عملکرد الگوریتم های مختلف (واحد میانگین خطای مقیاس مطلق (MASE) دقیقه است).
جدول 3. عملکرد الگوریتم های مختلف (واحد میانگین خطای مقیاس مطلق (MASE) s است).
© 2016 توسط نویسندگان؛ دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons by Attribution (CC-BY) (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر