1. معرفی
با توسعه سریع ترافیک شهری، موج وسایل نقلیه شهری و فشار بر ظرفیت های ترافیکی به شدت افزایش می یابد. بنابراین، مشکلات ترافیکی جدی می شود و توسعه یک شهر را محدود می کند. در چین، شرایط جاده ها و وسایل نقلیه کاملاً نامناسب است و ازدحام ترافیک باعث ایجاد مشکلات اجتماعی و اقتصادی قابل توجهی شده است. در این حالت، ترافیک نه تنها باعث اتلاف وقت، تاخیر در کار و کاهش راندمان می شود، بلکه باعث اتلاف قابل توجه سوخت، افزایش احتمال تصادفات و تشدید مشکلات جدی پیش روی کنترل و مدیریت ترافیک می شود. از دهه 1980 سیستم های حمل و نقل هوشمند (ITS) متشکل از فناوری کامپیوتری یکپارچه، فناوری کنترل خودکار، فناوری ارتباطات و فناوری پردازش اطلاعات به نتایج قابل توجهی در سراسر جهان دست یافته است. علاوه بر این، بسیاری از جنبه های ITS بر اساس اطلاعات ترافیکی است. علاوه بر این، پردازش اطلاعات ترافیک به یک جنبه مهم از ITS تبدیل شده است.1 ]. عملکرد حیاتی یک ITS مدیریت و کنترل جریان ترافیک و جلوگیری از ایجاد ترافیک است. هنگامی که ترافیک رخ می دهد، چنین سیستم هایی باید راه حل های به موقع و موثر ارائه دهند و فشار ترافیک را کاهش دهند. بنابراین، خوشه بندی و ارزیابی تراکم ترافیک شهری از اهمیت بالایی برخوردار است و بنابراین پیش نیازی برای بازرسی صحیح ازدحام ترافیکی است. برای تعیین میزان تراکم جاده، تعاریف مختلفی از تراکم ترافیک ارائه شده است. روتنبرگ رتبه تراکم ترافیک را به عنوان تعداد وسایل نقلیه در جاده بیش از ظرفیت حمل در سطح خدمات جاده ای قابل قبول عمومی تعریف کرد [ 2]]. تحت چنین تعریفی، مقامات ایالات متحده سطح خدمات (LOS) را بر اساس نسبت جریان واقعی وسیله نقلیه (حجم) و ظرفیت جاده به شش سطح از A تا F تقسیم می کنند : V / C. در ویرجینیا، زمانی که V / Cکمتر از 0.77 است، LOS در سطح D است و وضعیت ترافیک به عنوان یک جریان ترافیک با تراکم بالا اما پایدار در نظر گرفته می شود. وقتی LOS در سطح E است، ترافیک شروع به بدتر شدن می کند و منجر به ترافیک جدی می شود. یک روش برای ارزیابی سطح تراکم ترافیک (رتبه) با مقایسه یک پارامتر ترافیکی خاص با یک آستانه است. هنگامی که پارامتر از یک آستانه معین بیشتر باشد، ترافیک ایجاد شده در نظر گرفته می شود. به طور خاص، این روش می تواند تشخیص دهد که آیا تراکم ترافیک رخ می دهد یا خیر، اما نمی تواند یک روش ارزیابی اطلاعات جامع برای تراکم ترافیک را نشان دهد. در حال حاضر، ما اطلاعات جریان ترافیک را بر اساس سه ویژگی برای جادههای تنه شهری نانجینگ جمعآوری میکنیم تا به طور جامع سطح تراکم ترافیک را در همان دوره زمانی بسنجیم. علاوه بر این، ما قضاوت میکنیم که کدام جاده اجازه میدهد ترافیک روان باشد،شکل 1 ناحیه شبکه حمل و نقل نانجینگ را در بافت جغرافیایی آن نشان می دهد. با استفاده از اطلاعات فوق می توانیم مقادیر مرجع برای مدیریت ترافیک ارائه کنیم.
در حال حاضر، روش قضاوت ازدحام ترافیک را می توان به سه دسته تقسیم کرد: (1) روش تشخیص مستقیم، مانند روش تشخیص ویدیویی. این روش نیاز به نصب دوربین های زیادی دارد و هزینه آن بیشتر است. (2) روش تشخیص غیرمستقیم، که عمدتاً بر اساس تأثیر رویدادها بر جریان ترافیک است، برای تشخیص وجود رویداد استفاده می شود. این روش دارای هزینه کم، ساده و آسان برای کار است، اما دارای نرخ تشخیص پایین تر و نرخ هشدار نادرست بالا است. (3) بر اساس مدل تئوری، الگوریتم طراحی برای قضاوت ازدحام ترافیک. این روش در حال استفاده است و برخی از نظریه های بالغ مانند تحلیل خوشه ای، نظریه سیستم خاکستری و نظریه مجموعه های ناهموار به کار گرفته شده است. کار ما بر خوشهبندی اطلاعات جریان ترافیک بر اساس تجزیه و تحلیل رابطه خاکستری برای قضاوت در موقعیتهای تراکم ترافیک تمرکز دارد [ 3].
مقاله بصورت زیر مرتب شده است. ابتدا، خلاصهای از کارهای مرتبط قبلی در بخش 2 ارائه میکنیم . سپس، نحوه ساخت مدل خوشهبندی رابطهای خاکستری را در بخش 3 معرفی میکنیم . در بخش 4 ، الگوریتم خوشهبندی درجه عضویت رابطه خاکستری (GMRC) توضیح داده شده است. سپس، نتایج تجربی را در بخش 5 نشان میدهیم . در نهایت، مقاله را در بخش 6 به پایان میرسانیم .
2. کارهای مرتبط
2.1. نظریه های مرتبط
کار ما به ویژه شامل نظریه سیستم خاکستری است. تئوری سیستم خاکستری توسط پروفسور جولونگ دنگ در سال 1982 ارائه شد و شامل جنبه های بسیاری مانند نسل خاکستری، تجزیه و تحلیل خاکستری، مدل سازی خاکستری و پیش بینی خاکستری می شود [ 4] .]. این تئوری به طور گسترده در پردازش تصویر، امنیت شبکه و مدیریت لجستیک استفاده شده است. علاوه بر این، تجزیه و تحلیل رابطه خاکستری نه تنها یک جنبه مهم از نظریه خاکستری است، بلکه یک نوع روش اندازه گیری برای مطالعه شباهت داده ها است. این تحلیل همچنین هیچ الزام دقیقی در مورد اندازه نمونه ندارد و معمولاً برای تجزیه و تحلیل و مقایسه اشکال هندسی منحنی ها که توسط چندین نقطه در فضا توصیف می شود استفاده می شود. هرچه به آرایه استاندارد ارجاع شده نزدیکتر باشد، درجه رابطه بین استاندارد مرجع بالاتر و رتبه آن بالاتر است. در ادامه، به طور خلاصه به معرفی نظریه مجموعههای خشن میپردازیم، که یک روش تئوری ریاضی است که برای پرداختن به اطلاعات نامشخص، غیر دقیق و مبهم استفاده میشود. این نظریه در یادگیری ماشین، داده کاوی، تجزیه و تحلیل تصمیم گیری و غیره کاربرد دارد. علاوه بر این، نظریه مجموعه های خشن شاخه مهمی از محاسبات عدم قطعیت است که شامل نظریه های دیگری مانند مجموعه های فازی، شبکه های عصبی و نظریه شواهد می شود. در این مقاله، ما اطلاعات ترافیک جادهای شهری را با استفاده از خوشهبندی رابطهای خاکستری تجزیه و تحلیل میکنیم و نتایج را با نظریه مجموعههای خشن برای ایجاد یک سیستم جدول تصمیم ترکیب میکنیم. در نهایت میزان تراکم ترافیک شهری را قضاوت می کنیم.
2.2. تکنیک های خوشه بندی
تجزیه و تحلیل خوشه بندی موضوع تحقیقات فعال در چندین زمینه مانند آمار، تشخیص الگو، یادگیری ماشین و داده کاوی است. هدف آن تقسیم تعداد زیادی از داده ها به زیر مجموعه ها یا گروه های مختلف است تا الزامات همگنی و ناهمگنی برآورده شود. همگنی مستلزم آن است که داده ها در یک خوشه باید تا حد امکان مشابه باشند و ناهمگنی به این معنی است که داده ها در خوشه های مختلف باید تا حد امکان متفاوت باشند.
در حال حاضر، تعدادی از روشهای خوشهای به طور گسترده مورد استفاده قرار گرفتهاند، که در میان آنها یک الگوریتم تطبیقی وزندار مبتنی بر رویکرد تعادل پیشنهاد شده است که در آن روش خاکستری به یک الگوریتم خوشهبندی طیفی [5] برای اندازهگیری شباهت بین دادهها معرفی میشود . نتایج تجربی نشان میدهد که الگوریتم پیشنهادی میتواند به طور موثر بر کاستیهای خوشهبندی طیفی در مورد حساسیت پارامترها غلبه کند. الگوریتم خوشه بندی دیگری بر اساس آنتروپی که می تواند به طور خودکار تعداد خوشه ها را بر اساس ویژگی های توزیع نمونه داده تعیین کند و مشارکت کاربر را کاهش دهد در [ 6] پیشنهاد شد.]. نتیجه عینی تر است و الگوریتم می تواند خوشه های بزرگ و کوچک را با هر شکلی پیدا کند. از معایب الگوریتم می توان به انتخاب نقاط اولیه و اثرات نویز و نقاط پرت اشاره کرد. با این حال، این کاستی ها را می توان با غربالگری و پرداختن به نویز و نقاط پرت داده اصلی، حذف داده های نادرست و بهبود قابلیت اطمینان و جداسازی داده ها برای به حداقل رساندن تأثیر نویز و نقاط پرت برطرف کرد. این دو روش الهام بخش کار ما هستند به طوری که ما استفاده از رویکردی را برای ارزیابی جامع داده ها در نظر می گیریم. بنابراین، ما از نظریه رابطه خاکستری استفاده می کنیم، که می تواند به طور موثر داده های ویژگی چند بعدی را پردازش کند. با این حال، آن الگوریتمهای سنتی عمدتاً یک خوشهبندی ساده از دادههای مشابه هستند و در نظر نمیگیرند که چه ویژگیهای دادهای چه ویژگیهای شاخصی دارند. علاوه بر این،
2.3. الگوریتم K-Means و الگوریتم FCM
در حال حاضر، الگوریتم K-means و الگوریتم فازی C-Means (FCM) معمولاً برای خوشه بندی داده ها استفاده می شوند. ما این دو الگوریتم را در مقایسه با الگوریتم پیشنهادی خود در کار خود در نظر می گیریم. ابتدا، کار ما معرفی مختصری از الگوریتم K-means را ارائه خواهد کرد. الگوریتم K-means یک الگوریتم کلاسیک خوشه بندی است که به طور گسترده در زمینه های موضوعی مختلف استفاده می شود. علاوه بر این، الگوریتم های مختلف بهبود یافته بر اساس الگوریتم K-means تکامل یافته اند. با این حال، الگوریتم K-means یک مسئله بهینه سازی NP-hard است (به طور کلی، مسائلی که برای حل آنها زمان چند جمله ای هزینه دارد و پرداختن به آنها آسان است معمولاً به عنوان مسائل P در نظر گرفته می شوند. مسائل دشوار و به عنوان مسائل NP-hard شناخته می شوند.7 ]. فاصله اقلیدسی معمولاً به عنوان تابع معیار الگوریتم K-means استفاده می شود، جایی که گاهی اوقات فاصله بین دو نقطه داده با واحدهای مختلف محاسبه می شود. فاصله اقلیدسی فاصله واقعی بین دو نقطه در فضای m-بعدی است و عمدتاً توسط عناصر با نوسان شدید تعیین می شود. عناصر کمی نوسان اغلب نادیده گرفته می شوند و این پدیده با افزایش نسبت تفاوت بین عناصر متناظر آشکارتر می شود.
الگوریتم FCM نوعی الگوریتم خوشه بندی فازی بر اساس تابع هدف است. ابتدا مفهوم فازی را معرفی می کنیم: فازی عدم قطعیت است. علاوه بر این، معمولاً می گوییم یک شی همان چیزی است که مسلم است. با این حال، عدم قطعیت شباهت بین دو شی را نشان می دهد [ 8 ، 9]. برای مثال، ما بیست سالگی را معیاری برای قضاوت در مورد جوان بودن یا نبودن یک فرد میدانیم. بنابراین، یک فرد 21 ساله بر اساس این تقسیم یقین، جوان نیست; با این حال، 21 سالگی به نظر ما بسیار جوان است. بنابراین، در این لحظه، ما میتوانیم به طور مبهم به این احتمال فکر کنیم که یک فرد 21 ساله متعلق به 90٪ جوان و متعلق به غیر جوان به عنوان 10٪ است. در اینجا 90% و 10% احتمال نیستند. بلکه درجه تشابه هستند. اگرچه الگوریتم FCM می تواند به طور موثر خوشه بندی را انجام دهد، اما رتبه ای را که خوشه بندی به آن تعلق دارد متمایز نمی کند.
با توجه به مشکلات فوق، ما روابط اطلاعات جریان ترافیک را با ویژگیهای مختلف از طریق خوشهبندی رابطهای خاکستری استخراج میکنیم. علاوه بر این، ما الگوریتم GMRC را برای قضاوت در مورد اولویت خوشهبندی پیشنهاد میکنیم. به طور همزمان، ما الگوریتم های K-means و FCM خوشه بندی را ترکیب می کنیم و نتایج را با نتایج الگوریتم GMRC برای ارزیابی عملکرد الگوریتم خود مقایسه می کنیم.
3. مدل خوشه بندی رابطه ای خاکستری
در این مقاله، فرض میکنیم که وضعیت تراکم ترافیک جادهها به چهار رتبه (نه چهار خوشه) تقسیم میشود، یعنی هموار، گیر سبک، گیر و جم سنگین، که پیششرط ما است، جایی که صاف بهترین حالت را نشان میدهد، متعلق به رتبه اول، و مربا سنگین مشخصه بدترین وضعیت، متعلق به رتبه چهارم است. با توجه به توصیف تعاریف مختلف ازدحام ترافیک، تراکم ترافیک تنها به پارامترهای خاصی مربوط نمی شود [ 10]] (مانند حجم ترافیک و سرعت ترافیک) اما شامل عوامل بسیاری نیز می شود. بنابراین، تنها یک پارامتر مورد استفاده برای توصیف وضعیتهای تراکم ترافیک کافی نیست: وقتی سرعت وسیله نقلیه صفر است، ممکن است توسط وسایل نقلیه زیادی در جاده مسدود شود که نمیتوانند حرکت کنند یا ممکن است صاف باشد و هیچ وسیله نقلیهای در جاده رانندگی نمیکند. بنابراین، یک جریان ترافیکی سبک میتواند با دو حالت مطابقت داشته باشد: ترافیک سنگین و روان. علاوه بر این، تراکم کم ممکن است ترافیکی را مشخص کند که روان است و همچنین ممکن است کامیون های بیشتری و سایر وسایل نقلیه بزرگ در جاده را شامل شود. با این حال، تجزیه و تحلیل جامع از سه متغیر جریان ترافیک (سرعت جریان ترافیک، تراکم جریان ترافیک و حجم ترافیک) میتواند وضعیت واقعی ترافیک را منعکس کند. هدف ما ارزیابی میزان ترافیک جاده های مختلف بر اساس شاخص چند ویژگی است. بدین ترتیب، ما سه متغیر جریان ترافیک را برای ارزیابی میزان ترافیک معرفی می کنیم. با این حال، برای رسیدگی به دادههای ویژگیهای ترکیبی چند بعدی و بهدست آوردن سطوح خوشهبندی دادهها، از نظریه تحلیل رابطه خاکستری استفاده میکنیم.
جریان های ترافیکی با سه ویژگی [ 11 ] مشخص می شوند: سرعت جریان ترافیک، تراکم جریان ترافیک و حجم ترافیک. سرعت جریان ترافیک میانگین سرعت وسایل نقلیه در جاده را بر حسب کیلومتر در ساعت نشان می دهد. تراکم جریان ترافیک، یعنی تراکم وسایل نقلیه، تعداد وسایل نقلیه در واحد طول جاده را نشان می دهد. حجم ترافیک به عنوان تعداد وسایل نقلیه ای که از یک بخش جاده خاص در واحد زمان حرکت می کنند تعریف می شود. این مقاله از این سه ویژگی جریان ترافیک برای قضاوت در مورد وضعیت تراکم ترافیک استفاده می کند.
تعریف 1.
مجموعه داده های حوزه تحلیل را فرض کنید X={Xi|Xi=(Xi1,Xi2,Xi3)} i∈NX={��|��=(��1,��2,��3)} �∈� به عنوان مجموعه شی مقایسه ای، جایی که Xi�� ith شی داده را نشان می دهد که هر کدام دارای سه ویژگی است: سرعت جریان ترافیک، تراکم جریان ترافیک و حجم ترافیک.
تعریف 2.
فرض کنید یک آرایه استاندارد مرجع به صورت تنظیم شده است Y={Yi|Yi=(Yi1,Yi2,Yi3)} (i=1, 2,…,p) Y={��|��=(��1,��2,��3)} (�=1, 2,…,�) (مجموعه اشیاء مرجع). ما اطلاعات جریان ترافیک (زمانی که جاده در حالت صاف است یا وسایل نقلیه با سرعت جریان آزاد حرکت می کنند) را به عنوان یک مجموعه آرایه استاندارد مرجع در نظر می گیریم.
هر گروه از یک دنباله مرجع می تواند یک نتیجه خوشه بندی را زمانی که با یک شی مقایسه ای با روش خوشه بندی رابطه ای خاکستری ترکیب می شود به دست آورد. بنابراین، گروههای p از آرایههای مرجع، نتایج خوشهبندی p را تولید خواهند کرد . علاوه بر این، گروه استانداردهای مرجع استخراجشده از دادهها برای خوشهبندی زمانی که با مجموعههای شی مقایسهای ترکیب میشود، استفاده میشود که میتواند یک نتیجه خوشهبندی ایجاد کند. بنابراین، در کل فرآیند، می توانیم نتایج خوشه بندی p + 1 را به دست آوریم.
تعریف 3.
اطلاعات ارزیابی M به عنوان اطلاعات خروجی سیستم خوشه بندی رابطه خاکستری S در نظر گرفته می شود و F به عنوان تابع ارزیابی تعریف می شود. سپس، رابطه بین S و M به صورت نشان داده می شود
که در آن G نشان دهنده ماتریس مشابه رابطه خاکستری است. تابع ارزیابی F مدل فوق از سیستم جدول تصمیم تئوری مجموعههای خشن برای سنجش میزان مشارکت اعضای خوشه در نتایج خوشهبندی استفاده میکند. F را تابع عضویت رابطه ای خاکستری نیز می نامند که ورودی های آن X و Y و خروجی M است که شباهت بین عناصر داخل یک کلاس و شباهت بین کلاس ها را منعکس می کند.
در این مقاله، ما الگوریتم GMRC را جهت دادههای ویژگی چند بعدی برای قضاوت در اولویت رتبهبندی خوشهبندی پیشنهاد میکنیم. روش این روش شامل پیش پردازش داده ها، تبدیل داده ها به فرم ماتریس، تنظیم آستانه، و فیلتر کردن و حذف اشیاء داده غیرعادی است. سپس، اشیاء داده حوزه تحلیل را از طریق تجزیه و تحلیل خوشهبندی رابطهای خاکستری خوشهبندی میکنیم و سپس تحلیل تصمیمگیری وزنی را از نظریه مجموعههای خشن اعمال میکنیم. در نهایت، نتایج خوشه بندی با استفاده از نظریه احتمال محاسبه می شود.
4. الگوریتم GMRC
معماری الگوریتم GMRC از مراحل زیر تشکیل شده است ( شکل 2 ):
با توجه به ویژگی شاخص سه ویژگی داده های جریان ترافیک، استاندارد مرجع بهینه از مجموعه داده های حوزه تحلیل استخراج می شود. سپس، استاندارد مرجع بهینه و مجموعه آرایه مرجع برای محاسبه درجه رابطه خاکستری در ترکیب با مجموعه داده حوزه تحلیل استفاده می شود. پس از آن، ماتریس رابطه خاکستری را می توان به دست آورد، و اعضای خوشه را می توان محاسبه کرد. در مرحله بعد، از نظریه مجموعههای خشن استفاده میکنیم، جایی که اعضای خوشه اعمال میشوند، و جدول اطلاعات تصمیم را برای تکمیل ترکیب وزن اعضای خوشه میسازیم، که بر اساس آن باید رتبه هر شی داده را با استفاده از نظریه احتمال محاسبه کنیم. ما دسته اول را بالاترین اولویت می دانیم،
4.1. مراحل خوشه بندی رابطه ای خاکستری
4.1.1. استخراج استاندارد مرجع بهینه با توجه به ویژگی های داده های جریان ترافیک
از آنجایی که مشکل تجزیه و تحلیل خوشه بندی بر اساس یک سیستم شاخص معین حل می شود، انتخاب شاخص مناسب برای دستیابی به خوشه بندی معقول و مناسب بسیار مهم است. برای هر کدام سه ملک وجود دارد Xi��از یک منبع داده، و بر اساس ویژگی شاخص شی داده، استاندارد مرجع بهینه X0�0می توان از منبع داده استخراج کرد. دستورالعمل های خاص به شرح زیر است.
ما می دانیم که سه واحد ویژگی متفاوت است. بنابراین، ابتدا باید داده ها را به همان فرمت تبدیل کنیم. “↑” نشان می دهد که ارزش دارایی بیشتر و در نتیجه بهتر است. “↓” نشان دهنده مخالفت است. (a ، b )، که در آن a و b اعداد هستند، نشان می دهد که اگر مقدار ویژگی یک شی داده در این بازه باشد، مقدار بهتر خواهد بود.
استاندارد مرجع بهینه را استخراج کنید X0�0با توجه به ویژگی های سه گانه، و بیان آن است X0={X01,X02,X03}�0={�01,�02,�03}، که به شرح زیر است:
با در نظر گرفتن مشخصه سرعت جریان ترافیک به صورت “↑”، استفاده می کنیم
با در نظر گرفتن مشخصه تراکم جریان ترافیک به صورت “↓”، استفاده می کنیم
با در نظر گرفتن مشخصه حجم جریان ترافیک به صورت “↓”، استفاده می کنیم
4.1.2. پردازش عادی سازی داده ها
از آنجایی که داده ها انواع مختلفی دارند، واحدها نیز متفاوت هستند. با توجه به ویژگیهای ویژگیها، دادههای حوزه تحلیل با معیارهای مختلف پردازش میشوند و دادهها به (۰، ۱) فشرده میشوند. پردازش به شرح زیر است:
برای سرعت جریان ترافیک کل مجموعه داده، استفاده می کنیم
برای چگالی جریان ترافیک کل داده ها، ما استفاده می کنیم
برای حجم ترافیک کل مجموعه داده، استفاده می کنیم
ایکسمن جایکسمن�عنصر ماتریس اصلی در معادلات (5)-(7) بالا است و به نرمال می شود ایکسمن( j )ایکسمن(�)، جایی که ایکسj m a x ایکس� مترآایکسنشان دهنده حداکثر ستون j ام و ایکسj min�� ���حداقل ستون j را نشان می دهد و هر چیزی در داخل مهاربندها شرط محدود کننده است. پس از نرمال سازی، ماتریس های ( p + 1) را به دست می آوریم ، یعنی: A0, A1,…, Ap�0, �1,…, ��جایی که A0�0می توان با عادی سازی استاندارد مرجع بهینه به دست آورد X0�0و مجموعه شی مقایسه ای. در همین حال، A1, A2,…, Ap�1, �2,…, ��را می توان با عادی سازی مجموعه آرایه ارجاع شده و مجموعه شی مقایسه ای، که در آن به دست آورد A0�0و Ap��به عنوان تعریف می شوند
آخرین ردیف ماتریس A0�0به دنباله استاندارد مرجع بهینه و آخرین ردیف ماتریس نرمال می شود Ap��آرایه استاندارد مرجع نرمال شده pth است .
4.1.3. محاسبه درجه رابطه خاکستری و تولید ماتریس مشابه رابطه خاکستری
(1) درجه رابطه خاکستری نشان دهنده درجه بالای بین دو شیء مقایسه است. به عنوان مثال، ما بر محاسبه درجه رابطه خاکستری ماتریس تمرکز می کنیم A0�0. فرمول ها به شرح زیر است (معادلات (9) و (10)):
جایی که σ�ضریب تفکیک است که محدوده ای از 0 تا 1 دارد. به طور کلی، ما آن را فرض می کنیم σ�0.5 است. γo من( ک )���(�)ضریب همبستگی بین ایکسمن��و ایکس0�0در نقطه kth درجه رابطه خاکستری با بیان می شود γo من( ک )���(�)، جایی که ایکس0�0به عنوان دنباله مرجع و ایکسمن��به عنوان دنباله مقایسه ای در نظر گرفته می شود. به طور مشابه، ما می توانیم به دست آوریم γمن ج���چه زمانی Xi��به عنوان دنباله مرجع و Xj��به عنوان دنباله مقایسه ای در نظر گرفته می شود. سپس، X1, X2,…, Xn, X0�1, �2,…, ��, �0به عنوان دنباله مرجع در نظر گرفته می شوند. در همین حال، دنباله های ( n + 1) به عنوان دنباله های مقایسه ای در نظر گرفته می شوند (دنباله های ( n + 1) نه تنها دنباله های مرجع هستند، بلکه دنباله های مقایسه ای نیز هستند). در نهایت، ماتریس درجه رابطه خاکستری را محاسبه می کنیم Γ0(n + 1) × (n + 1)Γ(� + 1) × (� + 1)0با توجه به تجزیه و تحلیل رابطه خاکستری، که در آن Γ0(n + 1) × (n + 1)Γ(� + 1) × (� + 1)0بر اساس A 0 به دست می آید و از هر یک تشکیل می شود γij��� (i=1, 2,…,n,n+1, j=1,2,3)(�=1, 2,…,�,�+1, �=1,2,3). به طور مشابه، ما می توانیم ماتریس های درجه رابطه خاکستری را محاسبه کنیم Γ1, Γ2,…,ΓpΓ1, Γ2,…,Γ�بر اساس A0, A1,…, Ap�0, �1,…, ��.
(2) ماتریس G مشابه رابطه ای خاکستری را محاسبه کنید
ما عناصر تشابه را محاسبه می کنیم gij=(γij+γji)/2���=(���+���)/2در جی . به عنوان مثال، G 0 ماتریس مشابه خاکستری رابطه ای است که زمانی به دست می آید X0�0به عنوان دنباله ارجاع شده در نظر گرفته می شود، و عناصر شباهت رابطه ای خاکستری ( n + 1) ردیف G 0 زمانی محاسبه می شود که ایکس0�0به عنوان دنباله مرجع بهینه در نظر گرفته می شود. به طور مشابه، ما می توانیم ماتریس های مشابه رابطه ای p + 1 خاکستری را بدست آوریم: جی0،جی1, … ,جیپ �0,�1,…,��.
4.1.4. تجزیه و تحلیل خوشه بندی درجه رابطه ای خاکستری
بر اساس G ، یعنی ماتریس مشابه رابطه ای خاکستری، درخت رابطه ای حداکثری را می سازیم که از مقادیر آخرین عناصر ردیف در G تشکیل شده است . این در شکل 3 نشان داده شده است .
بر اساس G 0 می توانیم بدست آوریم gمن ج���که به آن درجه نزدیکی بین نیز می گویند ایکسمن��و ایکسjایکس�. بزرگتر gمن ج�من�است، نزدیک تر است ایکسمنایکسمنو ایکسjایکس�هستند؛ متقابلا، ایکسمنایکسمنو ایکسjایکس�برای کاهش دورتر هستند gمن ج�من�. بر اساس شکل 3 ، درخت رابطه ای حداکثر با درجه نزدیکی تولید می شود، همانطور که در شکل 4 نشان داده شده است ، جایی که آمنآمننشان دهنده درجه نزدیکی بین ایکسمنایکسمنو ایکسjایکس�.
بر اساس شکل 4 ، ضریب نقطه ایزوله را تنظیم می کنیم λ�، که در بازه (0، 1) است. درخت را زمانی قطع می کنیم که درجه نزدیکی کمتر از λ�و هنگامی که شاخه های مجاور تفاوت های اساسی را نشان می دهند. بنابراین، درخت قطع شده برای اینکه شاخههای متصل آن k سطح از خوشهها را در امتداد افقی تشکیل دهند، استفاده میشود . ما نزدیکترین شاخه را به عنوان اولین سطح و شل ترین شاخه را به عنوان سطح k در نظر می گیریم (اگر k ≥ 4 باشد، شاخه پنجم، شاخه ششم، شاخه هفتم و حتی شاخه k ام را نیز به عنوان رتبه چهارم طبقه بندی می کنیم. بگوییم صاف مربوط به رتبه اول و مربا سنگین مربوط به رتبه چهارم است). بنابراین، به این ترتیب، می توانیم عضو خوشه ای از G را به دست آوریم . بنابراین، استفاده می کنیم Γ0، Γ1, … , ΓپΓ0، Γ1،…، Γپبرای محاسبه p + 1 ماتریس شباهت رابطه ای خاکستری جی0، جی1, … , جیپجی0، جی1، …، جیپ، که از آن می توانیم رابطه نزدیکی بین هر شی را پیدا کنیم. بنابراین، می توانیم نتایج خوشه بندی p + 1، یعنی اعضای خوشه را به دست آوریم.
4.2. ایجاد تابع ارزیابی برای سیستم خوشهبندی رابطهای خاکستری
با توجه به نتایج خوشهبندی اولیه بالا، ما از نظریه مجموعههای خشن برای ایجاد سیستم جدول تصمیم استفاده میکنیم که برای وزن دادن سهم اعضای خوشه به نتایج خوشهبندی و وزن دادن به اعضای خوشه اعمال میشود.
4.2.1. تشریح نحوه ایجاد سیستم جدول تصمیم
ابتدا استاندارد مرجع بهینه و مجموعه استاندارد مرجع با مجموعه شی مقایسه ای از طریق روش خوشه بندی رابطه خاکستری ترکیب می شوند تا سیستم جدول تصمیم را بسازند. اف= ⟨ U، سی ، دی ، وی ، اف⟩اف=〈�، سی، �،�،�〉،جایی که U= {ایکس1، ایکس2, … , ایکسn}�={ایکس1، ایکس2،…، ایکس�}داده های حوزه تجزیه و تحلیل را نشان می دهد. سی= {ج1، ج2, … , جپ}سی={ج1، ج2،…، جپ}ویژگی های شرطی هستند و اعضای خوشه ای هستند که توسط مجموعه استاندارد مرجع تشکیل شده اند. D = { d}�={د}به عنوان ویژگی تصمیم گیری، عضو خوشه ای است که با استفاده از استاندارد مرجع بهینه به دست می آید. V=Vسی∪VD،Vسی= _ Vجساعت، ج ∈ سی �=�سی∪را��،�سی= ∪را�جساعت، ج∈سیمحدوده مجموعه ای از ویژگی های جریان ترافیک هستند که در آن Vجساعت�جساعتنشان دهنده سطح در عضو خوشه است جساعتجساعت (h = 1, 2, …, p) ; f نشان دهنده تابع ارزیابی است، f: U× ( C∪راد ) →V�:�×(سی∪را�)→�; و f(ایکسمن،جساعت) ∈Vجساعت�(ایکسمن،جساعت)∈�جساعتنشان دهنده سطح است ایکسمنایکسمندر عضو خوشه جساعتجساعت.
4.2.2. محاسبه آنتروپی اطلاعات
در سیستم جدول تصمیم، وزن آنتروپی اطلاعات من(جساعت، د )من(جساعت،�)نشان می دهد که عضو خوشه چقدر مهم است جساعتجساعت(اطلاعات مشروط) برای نتیجه D (اطلاعات تصمیم گیری) زمانی است که استاندارد مرجع بهینه برای محاسبه عضو خوشه انتخاب شود. با توجه به آنتروپی اطلاعات نظریه مجموعه های خشن، من(جساعت، د )من(جساعت،�)به شرح زیر است:
جایی که i = 1 ، 2 ، … ، k من=1، 2،…، ک( k تعداد خوشه ها است) آرسیمنآرسیمننشان دهنده امین خوشه تقسیم شده عضو خوشه c است ، | آرسیمن||آرسیمن|تعداد عناصر در خوشه i را نشان می دهد و | ایکس| = n|ایکس|=�. یک ویژگی شرطی بزرگتر c برای اطلاعات تصمیمی D مهمتر است . علاوه بر این، اچ( ج )اچ(ج)و اچ( D | { c } )اچ(�|{ج})توسط آنتروپی اطلاعات شرطی نظریه مجموعه های خشن تعیین می شوند. بنابراین، وزن نسبی هر یک از اعضای خوشه را می توان تعیین کرد، و یک عضو خوشه مهم تر با وزن بیشتر مطابقت دارد.
4.3. محاسبه سطح عضویت خوشه بندی اشیاء داده
مرحله 1: اهمیت آنتروپی اطلاعات ویژگی را محاسبه کنید Eساعت= من(جساعت، د )�ساعت=من(جساعت،�)برای هر عضو خوشه جساعتجساعتدر سیستم تصمیم گیری، جایی که h = 1 , 2 , … , p ساعت=1، 2،…، پ.
مرحله 2: وزن نسبی هر یک از اعضای خوشه را تنظیم کنید:
مرحله 3: از نظریه احتمال برای محاسبه احتمال ظهور هر شی داده در هر خوشه بندی بر اساس وزن های نسبی استفاده کنید تا سطحی را انتخاب کنید که در آن احتمال به حداکثر می رسد. علاوه بر این، نتایج خوشه بندی نهایی را به دست آورید. علاوه بر این، شی داده ایکسمنایکسمنمتعلق به سطح j( j = 1 ، 2 ، … ، k )(�=1، 2،…،ک)به عنوان … تعریف شده است
جایی که ممن کممنکسطح شی داده را نشان می دهد ایکسمنایکسمندر عضو خوشه جساعتجساعت، که در خوشه بندی رابطه ای خاکستری محاسبه شده است. بنابراین، سطح درجه عضویت رابطه خاکستری از ایکسمنایکسمنرا می توان به صورت زیر بیان کرد:
نتیجه نهایی این است C={C1,C2,…,Ck}�={�1,�2,…,��}، جایی که Ck��شامل تمام اشیاء دادهای است که سطح درجه عضویت رابطهای خاکستری آن سطح k ام است :
4.4. توضیحات الگوریتم GMRC
در این مقاله، ما مشکل خوشهبندی اطلاعات چند بعدی را برای جریان ترافیک مطالعه کرده و الگوریتم GMRC را پیشنهاد میکنیم. ابتدا مجموعه داده را به شکل ماتریسی تبدیل می کنیم، استاندارد مرجع بهینه را از مجموعه داده استخراج می کنیم و سپس پردازش نرمال شده را برای حذف اثرات واحدهای مختلف انجام می دهیم. علاوه بر این، نتایج خوشهبندی اولیه را با توجه به تحلیل نظریه رابطه خاکستری به دست میآوریم. در نهایت، یک سیستم جدول تصمیم برای محاسبه وزن نسبی برای هر عضو خوشه ایجاد می کنیم. الگوریتم به شرح زیر است.
- ورودی:
-
مجموعه داده های دامنه تجزیه و تحلیل X={Xi|Xi=(Xi1,Xi2,Xi3)} i∈N�={��|��=(��1,��2,��3)} �∈�،
مجموعه آرایه مرجع Y={Yi|Yi=(Yi1,Yi2,Yi3)} (i=1, 2,…,p)�={��|��=(��1,��2,��3)} (�=1, 2,…,�).
- خروجی:
-
مجموعه سطح (رتبه) اشیاء داده حوزه تجزیه و تحلیل
| الگوریتم 1: GMRC (X,Y) |
- 1
-
سطح = پوچ; وزن = صفر عضو = null; آنتروپی = پوچ.
// مقداردهی اولیه مجموعه ها Level, Weight; عضو ماتریس، آنتروپی
- 2
-
Data_ Preprocessing (X,Y); // پیش پردازش داده ها
- 3
-
X 0 = ExtractOptimal (X); // استاندارد مرجع بهینه را استخراج کنید
- 4
-
S = عادی سازی (X,Y); // پردازش عادی سازی
- 5
-
T = MaxRelTrees (S) // حداکثر درخت های رابطه ای را بسازید
- 6
-
T’ = ClosenessTrees (T) // حداکثر درخت رابطه ای را با درجه نزدیکی بسازید
- 7
-
عضو 0 = GrayCluster (X,X 0 )؛ // X 0 را به عنوان استاندارد مرجع برای محاسبه عضو خوشه در نظر بگیرید
- 8
-
Foreach (Y i در Y)
- 9
-
عضو i = خوشه خاکستری (X,Y i ); // Y i را به عنوان استاندارد مرجع برای محاسبه عضو خوشه در نظر بگیرید
- 10
-
پایان
- 11
-
F = DecisionSystem (اعضا)؛ // سیستم جدول تصمیم F را ایجاد کنید
- 12
-
آنتروپی = CalculateEntropy (F); // محاسبه آنتروپی اطلاعات برای هر عضو خوشه
- 13
-
وزن = محاسبه وزن (آنتروپی)؛ // محاسبه وزن نسبی برای هر عضو خوشه
- 14
-
CalculateLevel (X)؛ // سطح درجه عضویت X i در X را محاسبه کنید
|
مراحل بالا از الگوریتم به شرح زیر است:
مرحله 1: پارامترها را راه اندازی کنید، داده های جریان ترافیک را از قبل پردازش کنید، آستانه را برای فیلتر کردن و حذف اشیاء داده غیرعادی تنظیم کنید (خطوط 1 و 2).
مرحله 2: با توجه به ویژگی های سه ویژگی داده های جریان ترافیک، استاندارد مرجع بهینه را از داده های حوزه تحلیل استخراج کنید (خط 3).
مرحله 3: مجموعه داده های حوزه تحلیل را در ترکیب با توالی های استاندارد مرجع (خط 4) عادی کنید.
مرحله 4: درجه رابطه خاکستری ماتریس مربوطه را محاسبه کنید. علاوه بر این، ماتریسهای شباهت رابطهای خاکستری را تعیین کنید و سپس حداکثر درختهای رابطهای را بر اساس عناصر ردیف (n + 1) آن ماتریسها بسازید ( خط 5 ).
مرحله 5: بر اساس مرحله 4، حداکثر درخت رابطه ای را با درجه نزدیکی بسازید (خط 6).
مرحله 6: درجه نزدیکی را بین اشیاء داده مقایسه کنید، وقتی درجه نزدیکی کمتر از آن است درخت را قطع کنید λ�و شاخه های مجاور تفاوت های زیادی را نشان می دهند و سپس k سطح نتایج خوشه بندی را به دست می آورند. به طور مشابه، در مجموع اعضای خوشه p + 1 را از آرایه های ارجاع شده p + 1 به دست می آوریم (خطوط 7-10).
مرحله 7: سیستم جدول تصمیم را بر اساس اعضای خوشه p به عنوان ویژگی های شرطی به دست آمده از مجموعه آرایه استاندارد مرجع ایجاد کنید. علاوه بر این، تنها عضو خوشه به دست آمده از استاندارد مرجع بهینه (خط 11) به عنوان ویژگی تصمیم گیری در نظر گرفته می شود.
مرحله 8: محاسبه آنتروپی اطلاعات اعضای خوشه برای تصمیم گیری، که برای سنجش سهم هر یک از اعضای خوشه در نتایج خوشه بندی استفاده می شود (خط 12).
مرحله 9: وزن هر یک از اعضای خوشه را محاسبه کنید (خط 13).
مرحله 10: احتمال ظهور هر شی داده در هر خوشه بندی را محاسبه کنید. سپس، سطحی را انتخاب کنید که احتمال به حداکثر برسد. علاوه بر این، نتایج خوشه بندی نهایی را به دست آورید (خط 14).
4.5. تابع عضویت رابطه خاکستری
عملکرد نتایج خوشه بندی سنتی به فاصله بین عناصر داخل کلاس ها و فاصله بین کلاس ها بستگی دارد. فاصلههای کوتاهتر بین عناصر داخل یک کلاس نشاندهنده کلاسهای بهتر است. در مقابل، فاصله های طولانی تر بین کلاس ها نشان دهنده کلاس های بهتر است [ 12 ]. هدف ما از خوشه بندی به دست آوردن رتبه درجه عضویت کلاس ها و قضاوت در مورد رتبه اشیاء داده است. بنابراین، ما یک تابع عضویت می سازیم که شباهت بین عناصر داخل یک کلاس و شباهت بین کلاس ها را بر اساس درجه شباهت رابطه خاکستری منعکس می کند. فرض کن که γX,Y��,�به عنوان درجه شباهت رابطه خاکستری بین شی نشان داده می شود X�و اعتراض Y�، و C={C1,C2,…,Ck}�={�1,�2,…,��}نشان دهنده خوشه های تقسیم شده است. SC��، که برای وزن کردن تقسیم استفاده می شود C�، به عنوان … تعریف شده است
5. نتایج تجربی و تجزیه و تحلیل
در این مقاله، ما دادههای ترافیکی را برای جادههای اصلی نانجینگ جمعآوری کردیم، که مناطق تجاری اصلی را به هم متصل میکند و شامل حجم ترافیک بالا و مناطق مسکونی با تراکم بالا است. این جاده ها باید قبل از ایجاد ترافیک به موقع پاکسازی شوند. به طور کلی، روال روزانه افراد بسیار منظم است [ 13]: صبح به سر کار بروید و هنگام غروب به خانه بروید. با این حال، این می تواند به سرعت منجر به ازدحام ترافیک در ساعات شلوغی شود. یک مطالعه قبلی اشاره کرد که یک پارامتر واحد، مانند سرعت، که برای توصیف وضعیتهای تراکم ترافیک استفاده میشود، کافی نیست. برای به دست آوردن دانش دقیق برای قضاوت تراکم ترافیک، تجزیه و تحلیل جامع از سه متغیر جریان ترافیک برای تعیین وضعیت جریان ترافیک می تواند برای انعکاس شرایط واقعی جاده برای پیش بینی ترافیک [14] استفاده شود .]. برای آزمایش الگوریتم خود، به طور تجربی دادههای جریان ترافیک را از 50 نقطه نظارتی در امتداد جادههای اصلی نانجینگ در بازههای زمانی تقریباً 7:00 تا 9:30 صبح و 4:30 تا 7:00 بعد از ظهر، که مطابق با ساعات شلوغی است، جمعآوری کردیم. علاوه بر این، ما 30 راننده با بیش از پنج سال تجربه رانندگی را به عنوان آزمایشکننده انتخاب کردیم و فیلمهای رانندگی وسیله نقلیه آنها را تماشا کردیم تا ارزیابی آنها را از چهار حالت جریان ترافیک (هموار، گیر کردن سبک، گیر کردن و گیر کردن سنگین) بدست آوریم [15 ] . سپس، ما نتایج خوشهبندی را ارزیابی کردیم تا دقت الگوریتم خود را در مقایسه با سایر روشهای خوشهبندی مانند الگوریتم K-means و الگوریتم FCM تأیید کنیم.
در این آزمایش ما ضریب تفکیک را فرض کردیم σ�از آنجایی که الگوریتم ماهیت تصادفی دارد، میانگین نتایج 20 آزمون برای هر الگوریتم در هر مجموعه داده به عنوان نتایج تجربی استفاده می شود. جدول 1 آنتروپی اطلاعات مربوط به چهار عضو خوشه را نشان می دهد که توسط نمونه داده های خوشه بندی اولیه به دست آمده است، یعنی وزن نسبی اعضای خوشه. برای تأیید عملکرد الگوریتم ما، شش نقطه نمونه به طور تصادفی از مجموعه داده انتخاب شدند، همانطور که در جدول 2 نشان داده شده است . در جدول 2، متوجه شدیم که خوشه بندی وضعیت ترافیک بیشترین ارتباط را با سرعت جریان ترافیک دارد. با این حال، سرعت نمی تواند به طور کامل وضعیت ترافیک را تعیین کند. به عنوان مثال، سرعت جریان ترافیک در گروه 459 40.3 کیلومتر در ساعت است و حالت ترافیک سبک است. با این حال، سرعت جریان ترافیک در گروه 812 45.5 کیلومتر در ساعت است که بیشتر از 40.3 کیلومتر در ساعت است، اما حالت حالت گیر کرده است. این پدیده عمدتاً به این دلیل رخ می دهد که حجم ترافیک دومی بیشتر از اولی است. سه ویژگی جریان ترافیک باید به طور جامع در نظر گرفته شود نه فقط سرعت.
5.1. تحلیل پیچیدگی
فرض می کنیم k سطح، n شی داده، m ابعاد و p توالی استاندارد ارجاع داده شده است. پیچیدگی الگوریتم GMRC در ادامه توضیح داده شده است.
5.1.1. تحلیل پیچیدگی زمانی
زمان ساخت ماتریس اولیه است O(m×n)�(�×�). استخراج استاندارد مرجع بهینه مستلزم دسترسی به تمام عناصر در ماتریس اولیه است و پیچیدگی زمانی نیز وجود دارد. O(m×n)�(�×�). پیچیدگی زمانی نرمال سازی ماتریس است O(p×n×m)�(�×�×�). محاسبه درجه رابطه خاکستری نیاز به دسترسی به تمام عناصر موجود در n ماتریس درجه تشابه رابطه خاکستری دارد. بنابراین پیچیدگی زمانی آن تقریباً است O(n×m×p×n)�(�×�×�×�). پیچیدگی زمانی مرتبسازی عناصر درجه رابطه خاکستری ردیف ( n + 1) برای ماتریسهای درجه تشابه رابطه خاکستری p است.O(p×n2)�(�×�2). محاسبه آنتروپی اطلاعات برای نیازهای اعضای خوشه O(p×k)�(�×�). زمان مورد نیاز برای محاسبه داده های حوزه تحلیل درجه عضویت خوشه بندی می باشد O(n×p×k)�(�×�×�). با توجه به تحلیل فوق، میانگین پیچیدگی زمانی الگوریتم GMRC است O(k×m×p×n2)�(�×�×�×�2).
5.1.2. تحلیل پیچیدگی فضا
پیچیدگی تجزیه و تحلیل ماتریس اولیه دامنه است O(m×n)�(�×�)در فضا، و پیچیدگی تحلیل ماتریس درجه تشابه با پیچیدگی فضا است O(p×n2)�(�×�2). علاوه بر این، پیچیدگی فضایی تعیین درجه عضویت رابطه خاکستری در الگوریتم GMRC است. O(k×p)�(�×�). بنابراین، پیچیدگی فضای کل الگوریتم است O(k×p×n2)�(�×�×�2).
5.2. تاثیر ضریب نقطه ایزوله λ بر نتایج خوشه بندی
از شکل 5 ، می توان دریافت که بر اساس تعداد مختلف نمونه داده، مقدار تابع عضویت رابطه خاکستری به تدریج با افزایش افزایش می یابد. λ�. زیرا با افزایش λ�، درجه شباهت رابطه خاکستری بین عناصر داخل کلاس ها افزایش می یابد و این موقعیت غالب را به حساب می آورد. واضح است، چه زمانی λ�بین 0.84 و 0.87 است، مقدار تابع حداکثر شده است. سپس، به عنوان λ�به تدریج افزایش می یابد، مقدار تابع کاهش می یابد. این به این دلیل است که درجه شباهت رابطه خاکستری بین کلاس ها موقعیت غالب را اشغال می کند. از منظر درجه تشابه رابطه خاکستری بین اشیاء داده، درجه نزدیکی را در داخل کلاس ها و در بین کلاس ها تجزیه و تحلیل می کنیم و به طور کامل از ویژگی اطلاعات چند بعدی و تغییر کلی در سه ویژگی برای توصیف بهتر درجه نزدیکی بین اشیاء داده استفاده می کنیم. بنابراین، در آزمایش بعدی، محدوده از λ�به عنوان (0.84، 0.87) تنظیم شده است.
5.3. مقایسه با سایر الگوریتم ها
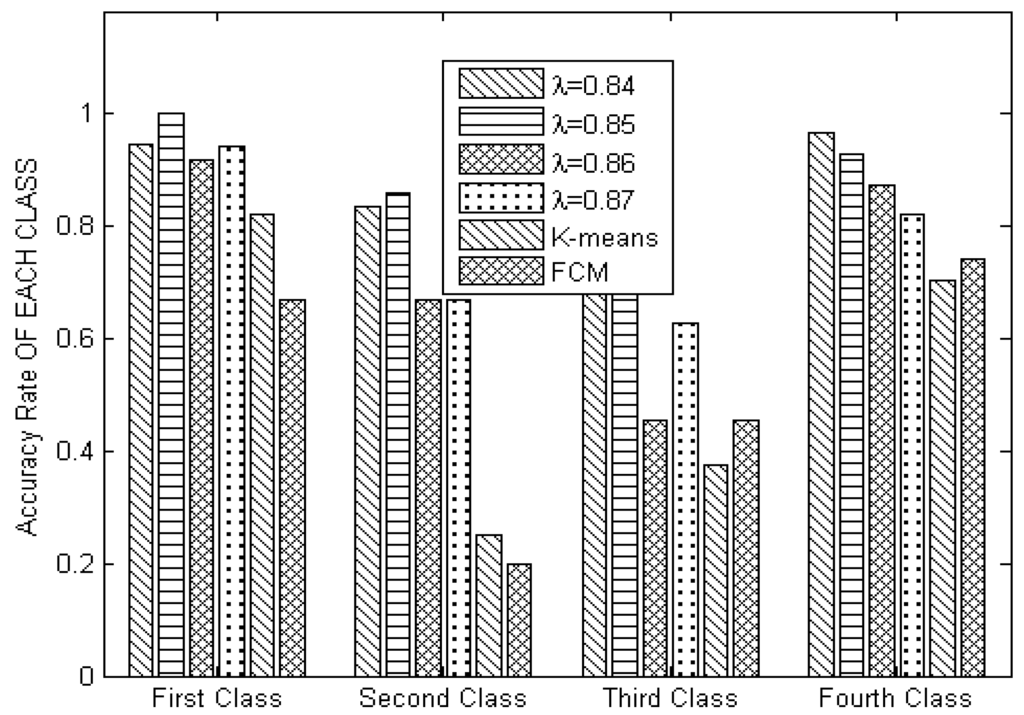
شکل 6 میزان دقت الگوریتم های خوشه بندی GMRC، K-means و FCM را در هر کلاس نشان می دهد. ما متوجه شدیم که دقت GMRC در هر کلاس و در زیر متفاوت است λ�بالاتر از الگوریتم های K-means و Fuzzy است. این به این دلیل است که الگوریتم GMRC از ویژگی شاخص ویژگی داده برای محاسبه درجه شباهت رابطه خاکستری استفاده می کند و کیفیت اعضای خوشه را در نظر می گیرد. بنابراین، الگوریتم به طور موثر شباهت کلاس داخلی را برای دستیابی به خوشه بندی رتبه بندی شده بهبود می بخشد.
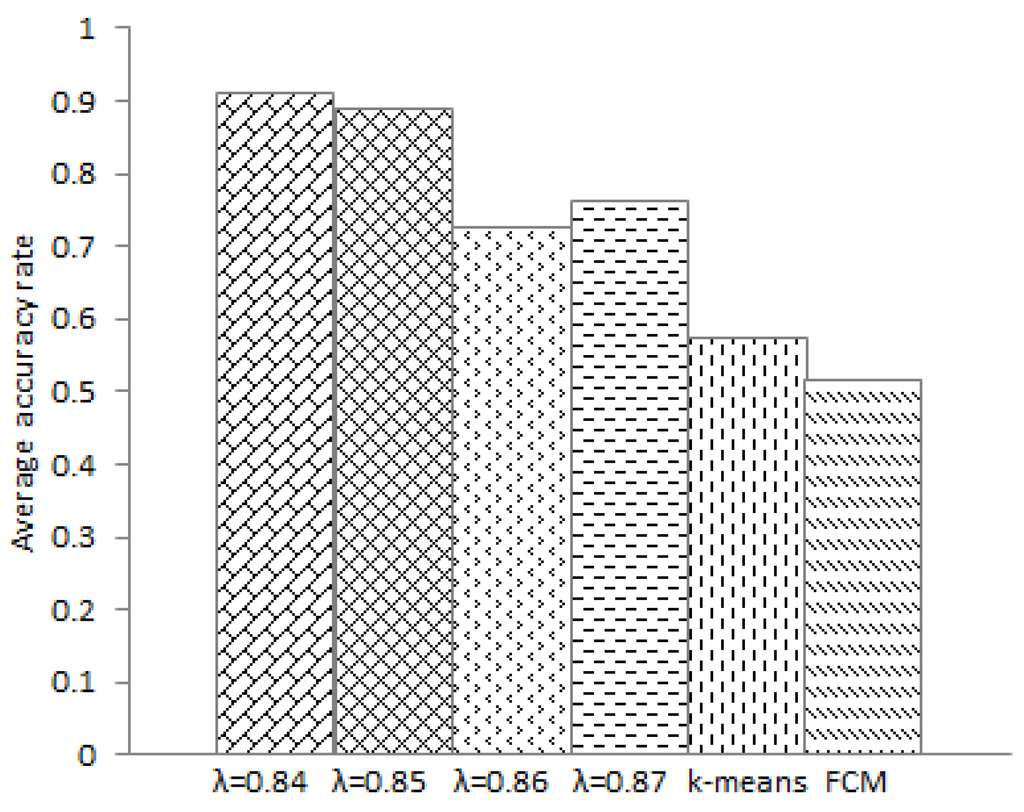
شکل 7 میانگین دقت الگوریتم GMRC ما را در موارد مختلف نشان می دهد λ�و الگوریتم های K-means و FCM. از شکل 6 و شکل 7 ، می توان نتیجه گرفت که میانگین دقت الگوریتم GMRC بیشتر از الگوریتم های K-means و FCM است. علاوه بر این، میانگین دقت الگوریتم GMRC 24.9 درصد بیشتر از الگوریتم K-means و 30.8 درصد بیشتر از الگوریتم FCM است. علاوه بر این، الگوریتم جدید ما پایداری بهتری را نشان میدهد. از آنجا که الگوریتم ما نیازی به انتخاب تصادفی نقطه مرکزی اولیه ندارد، همانطور که در الگوریتم K-means، پایداری الگوریتم تحت تأثیر ماهیت تصادفی الگوریتم قرار نمی گیرد.
6. نتیجه گیری
قضاوت در مورد وضعیتهای ازدحام ترافیک، پیشفرض و مبنایی برای هشدار تراکم ترافیک پویا، راهنماییهای ترافیکی، اجتناب فعالانه از تراکم ترافیک و تضمین جادههای هموار است. با این حال، ترافیک معمولا با تجربه قضاوت می شود. این مقاله دادههای جریان ترافیک را جمعآوری میکند و روش قضاوت مؤثرتری ارائه میدهد. ما هر دو تجزیه و تحلیل رابطه خاکستری و نظریه مجموعه خشن را به الگوریتم GMRC معرفی می کنیم و درجه عضویت در خوشه بندی اشیاء داده را با استفاده از اطلاعات جامع در مورد داده ها می سنجیم. در این فرآیند، ما حداکثر درخت رابطه ای را با درجه نزدیکی می سازیم و درجه نزدیکی را بین اشیاء داده مقایسه می کنیم. زمانی درخت را قطع می کنیم که درجه نزدیکی کمتر از λ�و زمانی که شاخه های مجاور تفاوت های زیادی از خود نشان می دهند. در نتیجه، p را بدست می آوریم+ 1 عضو خوشه. در مرحله بعد، ما یک سیستم جدول تصمیم را بر اساس اعضای خوشه p به عنوان ویژگی های شرطی به دست آمده از مجموعه های آرایه استاندارد مرجع ایجاد می کنیم. سپس، احتمال ظهور هر شی داده در هر خوشه بندی را محاسبه می کنیم، زمانی که احتمال به حداکثر می رسد، رتبه را انتخاب می کنیم و در نهایت نتایج خوشه بندی نهایی را به دست می آوریم. بنابراین، الگوریتم ما شکاف های موجود در ادبیات را پر می کند که به موجب آن الگوریتم های K-means و FCM نمی توانند متمایز کنند که یک خوشه بندی به کدام رتبه تعلق دارد. نتایج تجربی نشان میدهد که الگوریتم پیشنهادی که ویژگیهای شی دادههای چند بعدی را در نظر میگیرد، یک الگوریتم برتر است. در مرحله بعد، ما قصد داریم شباهت رابطه خاکستری را به دیگر الگوریتم ها اعمال کنیم و پیچیدگی محاسباتی الگوریتم را کاهش دهیم.







بدون نظر