


خلاصه
تطبیق نقشه ; داده های مسیر و شی متحرک ؛ منشور فضا-زمان ؛ k – الگوریتم کوتاهترین مسیر
1. معرفی
سازمان
2. مروری بر رویکردهای موجود برای تطبیق نقشه
2.1. طبقه بندی الگوریتم های تطبیق نقشه
2.2. مروری کوتاه بر الگوریتم های تطبیق نقشه
2.2.1. الگوریتم های هندسی
2.2.2. الگوریتم های توپولوژیکی
2.2.3. الگوریتم های احتمالی
2.3. الگوریتمهایی برای دادهها با نرخ نمونهگیری پایین
3. الگوریتم تطبیق نقشه مبتنی بر عدم قطعیت
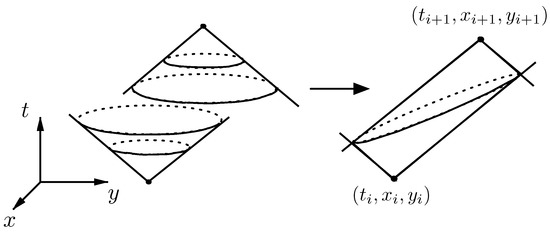
3.1. مقدمه ای بر منشورهای فضا-زمان
3.2. استفاده از منشورهای فضا-زمان برای تطبیق نقشه
3.2.1. محاسبات پروجکشن منشور فضا-زمان و جعبه مرزی آن
قضیه 1.
اجازه دهید (ایکس1،y1)(ایکس1،�1)و (ایکس2،y2)(ایکس2،�2)نقاط (که نشان دهنده کانون ها است) در آر2آر2، و اجازه دهید L > 0�>0یک عدد واقعی باشد (که نشان دهنده محور نیمه اصلی است). اجازه دهید (ایکسج،yج)(ایکسج،�ج)نقطه وسط کانون باشد و دfد�فاصله بین آنها باشد. اگر ایکس1≠ایکس2ایکس1≠ایکس2، جعبه مرزی [ایکس1،Y1] × [ایکس2،Y2][ایکس1،�1]×[ایکس2،�2]از رابطه زیر بدست می آید:
-
ایکس1=ایکسج–س2ℓ2+L21 +س2——√،ایکس1=ایکسج-س2ℓ2+�21+س2، Y1=yج–س2L2+ℓ21 +س2——√،�1=�ج-س2�2+ℓ21+س2،
-
ایکس2=ایکسج+س2ℓ2+L21 +س2——√،ایکس2=ایکسج+س2ℓ2+�21+س2، Y2=yج+س2L2+ℓ21 +س2——√،�2=�ج+س2�2+ℓ21+س2،
جایی که ℓ =124L2–د2f——-√ℓ=124�2-د�2(محور نیمه فرعی) و s =y1–y2ایکس1–ایکس2.س=�1-�2ایکس1-ایکس2.اگر ایکس1=ایکس2ایکس1=ایکس2، سپس ایکس1=ایکسج– ℓایکس1=ایکسج-ℓ، ایکس2=ایکسج+ ℓایکس2=ایکسج+ℓ، Y1=yج– ال�1=�ج-�و Y2=yج+ ال�2=�ج+�(با L = ℓ�=ℓاگر y1=y2�1=�2). ☐
3.2.2. استفاده از جعبههای مرزی پروجکشن منشورهای فضا-زمان در تطبیق نقشه
تعریف 1.
استفاده از جعبه مرزی طرح منشور فضا-زمان، به جای خود بیضی، انگیزه عملی دارد. در پایان، شبکه های جاده ای با استفاده از گزاره در پایگاه داده های GIS ذخیره می شوند نقطه ( x ، y )نقطه(ایکس،�)، که توسط OpenGIS در قالب متن شناخته شده استاندارد شده است. برای تأیید اینکه یک نقطه شبکه جاده در کادر مرزی قرار دارد [ایکس1،Y1] ×[ایکس2،Y2][ایکس1،�1]×[ایکس2،�2]، از پرس و جوی SQL زیر می توان استفاده کرد:
این پرس و جو به دلیل شاخص فضایی در رئوس در یک شبکه جاده ای ساده و کارآمد است.
3.2.3. الگوریتمی برای مسیریابی k -کوتاهترین مسیر
مثال 1.
3.2.4. شرح الگوریتم تطبیق نقشه منشورهای فضا-زمان
مثال 2.
به طور خلاصه، الگوریتم MM ما به شرح زیر است:
- مرحله 1.
-
بخشهای مربوطه شبکه جادهای را با محاسبه برای هر جفت نقطه متوالی، انتخاب کنید که MO میتوانست روی کدام بخشهای جاده حرکت کند (با استفاده از جعبههای مرزی پیشبینی منشورهای فضا-زمان، همانطور که در بخش 3.2 توضیح داده شد ) .
- گام 2.
-
برای هر نقطه نمونه، نزدیکترین بخش جاده را محاسبه کنید، همانطور که در بخش 3.2.4 توضیح داده شد ، و امتیازهایی را به هر بخش جاده اختصاص دهید. یک امتیاز برای یک بخش s با جمع کردن وزن تمام بخش هایی که با s مطابقت دارند محاسبه می شود .
- مرحله 3.
-
در داخل شبکه جاده محدود تعیین شده در مرحله 1، k- کوتاه ترین مسیرها را محاسبه کنید و به عنوان خروجی، کوتاه ترین مسیر را با حداکثر وزن کل انتخاب کنید. اگر دو مسیر با وزن یکسان بدست آوریم، مسیر اول انتخاب می شود.
4. ارزیابی بهبود یافته الگوریتم های تطبیق نقشه
4.1. منابع و ویژگی های داده
4.2. روشهایی برای اندازهگیری کیفیت الگوریتم تطبیق نقشه
3. دقت بر اساس طول منهای جاده اشتباه: این روش (نگاه کنید به [ 2 ]) از طول کل بخش های جاده که به اشتباه اضافه و حذف شده اند استفاده می کند. از نظر طول دارای همان مزایای دقت است. تفاوت اصلی این است که بخش های جاده ای که به اشتباه اضافه شده اند جریمه بیشتری دارند. از آنجایی که این اندازه گیری به ما ایده ای درباره دقیق بودن مسیر محاسبه شده نمی دهد، آن را با دقت اندازه گیری طول ترکیب می کنیم و فرمول زیر را برای دقت بر اساس طول منهای جاده اشتباه می دهیم: مقدار را می گیریم:
اگر این مقدار مثبت باشد و صفر را بگیریم در غیر این صورت.
4. فاصله فرشه ضعیف، متوسط و قوی: این روش [ 11 ، 12 ] از اندازه گیری فاصله فرشه بین دو منحنی استفاده می کند. میانگین فاصله فرشت میانگین فواصل فرشت ضعیف و قوی است که در بخش 2 توضیح داده شده است . یکی از مزایای استفاده از روش فاصله فرشه این است که به جای نگاه کردن به بخش های جاده، به خود منحنی نگاه می کنیم. یک مسیر منطبق ممکن است دقت پایینی با سایر معیارها داشته باشد، اما همچنان می تواند بسیار نزدیک به مسیر واقعی باشد. استفاده از این روش فاصله به ما امکان می دهد محاسبه کنیم که این مسیرها چقدر نزدیک هستند. با این حال، میتوانیم برای مسیری که هیچ بخش جاده مشترکی با مسیر اصلی ندارد (به عنوان مثال، یک مسیر موازی) امتیاز دقت بالایی کسب کنیم. A را فرض کنید و راB دو منحنی هستند. فاصله Fréchet به طور رسمی به این صورت تعریف می شود:
که در آن reparametrizations α ، β: [ 0 , 1 ] → [ 0 , 1 ]�،�:[0،1]→[0،1]A و B جراحيهاي پيوسته و بدون كاهش هستند. در فرمول فوق، d تابع فاصله اقلیدسی استاندارد است. فاصله Fréchet ضعیف نیاز غیر کاهشی را حذف می کند.
4.3. مشکلات در اندازه گیری دقت
4.4. اندازه گیری دقت جدید: CL-Accuracy
برای محاسبه این اندازه گیری جدید، ابتدا امتیازی بین صفر تا 100 برای هر بخش انتخاب شده توسط الگوریتم MM محاسبه می کنیم. برای این کار، فاصله اقلیدسی را تا نزدیکترین قطعه در مسیر صحیح، با حداکثر 100 متر محاسبه می کنیم. این محدودیت بر اساس دقت دستگاه های GPS فعلی است (اگر نقطه ای بیش از 100 متر دورتر باشد، تقریباً به طور قطع یک نقطه پرت است). نمره کل برای مسیر منطبق با جمع کردن تمام امتیازات بخش و سپس با استفاده از فرمول زیر محاسبه می شود:
عبارت maxScore در فرمول فوق حداکثر امتیاز ممکن برای مسیر منطبق (100 برابر تعداد بخش ها) است. این فرمول امتیازی را برای فاصله منحنی بین مسیر صحیح و منطبق محاسبه می کند. یک نمره از 100 %100%به این معنی که هر بخش از مسیر منطبق بر مسیر صحیح است. یک نمره از 0 %0%به این معنی که هر قطعه 100 متر یا بیشتر از مسیر صحیح فاصله دارد. در مرحله بعد، طول هر دو مسیر را در نظر می گیریم و امتیاز بالا را در ضریب بین طول کوچکترین و بزرگترین مسیر ضرب می کنیم. اگر O مسیر اصلی و M نسخه مطابق نقشه آن باشد، O می تواند طولانی تر یا کوتاه تر از M باشد (بسته به الگوریتمی که استفاده می شود). از آنجایی که میخواهیم اندازهگیری تشابه را در محدوده 0% تا 100% بدست آوریم، اگر | O | > | م||�|>|م|، ما استفاده می کنیم | م|| O ||م||�|بجای. در نتیجه، اگر، برای مثال، M باشد 10 درصد10%طولانی تر از O ، این دقیقاً به همان روشی جریمه می شود که اگر O بود 10 درصد10%طولانی تر از M. با این روش، یک مسیر منطبق که دو برابر طول مسیر صحیح است، فقط نصف امتیاز را می گیرد.
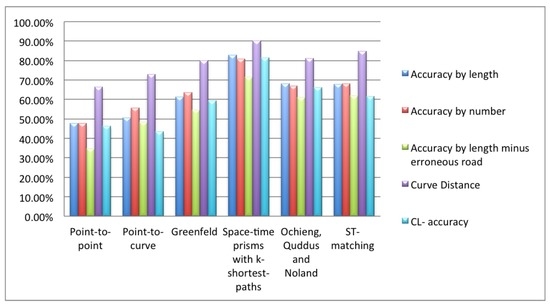
5. مقایسه تجربی الگوریتم های تطبیق نقشه
5.1. آزمایش بر روی داده های برچسب انسانی
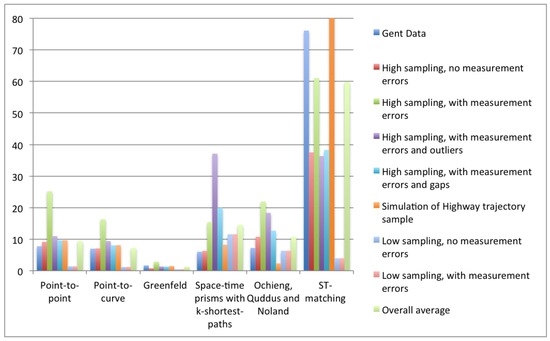
5.2. آزمایشات روی داده های تولید شده توسط کامپیوتر
5.2.1. نرخ نمونه برداری بالا
نمونه های مسیر شبیه سازی شده بدون خطای اندازه گیری
نمونه های مسیر شبیه سازی شده با خطاهای اندازه گیری
نمونه های مسیر شبیه سازی شده با خطاهای اندازه گیری و نقاط پرت
نمونه های مسیر شبیه سازی شده با خطاها و شکاف های اندازه گیری
نمونه های مسیر شبیه سازی شده در بزرگراه با خطاهای GPS
نمونه های مسیر شبیه سازی شده در مسافت طولانی با خطاهای اندازه گیری
تبصره 1.
5.2.2. نرخ نمونه برداری پایین
نمونه های مسیر شبیه سازی شده بدون خطای اندازه گیری
نمونه های مسیر شبیه سازی شده با خطاهای اندازه گیری
5.3. بحث
6. نتیجه گیری و مسائل باز
ضمیمه الف. محاسبات طرح ریزی یک منشور فضا-زمان و جعبه مرزی آن

برای در نظر گرفتن طول عبارات، چند اختصار را معرفی می کنیم. مرکز بیضی نقطه است
فاصله بین کانون ها به اختصار با دfد�، به این معنا که
محور نیمه فرعی بیضی با ℓ نشان داده می شود . بنابراین، 2 ℓ2ℓطول محور فرعی بیضی است.
برای تعیین ℓ ، به شکل A2 نگاه می کنیم ، که در آن a و b به ترتیب نقاط تقاطع بیضی با محور اصلی و فرعی آن هستند. اگر به ساختار طناب کشی بیضی فکر کنیم، می توانیم ببینیم که:
از آنجایی که هر دو سمت چپ و راست در این برابری برابر با طول طناب هستند که برای کشیدن بیضی لازم است. ما هم این را می دانیم د((ایکس1،y1) ، الف ) +د((ایکس2،y2) ، a ) =2لیترد((ایکس1،�1)،آ)+د((ایکس2،�2)،آ)=2�، طول محور اصلی.
علاوه بر این، ما می دانیم که د( (ایکس1،y1) ، ب ) = د( (ایکس2،y2) ، ب ) = H،د((ایکس1،�1)،ب)=د((ایکس2،�2)،ب)=اچ،از آنجایی که یک مثلث متساوی الاضلاع داریم، اگر طول پاره خطی را که یک نقطه کانونی را با b به هم وصل می کند (یعنی طول هیپوتنوز مثلثی که توسط یک نقطه کانونی، مرکز بیضی و b تشکیل شده است ) بنامیم. بنابراین، دریافت می کنیم دf+ 2 لیتر =دf+ 2 Hد�+2�=د�+2اچیا L = H�=اچ. قضیه فیثاغورث، اعمال شده بر مثلثی که مرکز بیضی، نقطه کانونی تشکیل شده است. (ایکس1،y1)(ایکس1،�1)و نقطه b ، سپس می دهد اچ2=(دf2)2+ℓ2اچ2=(د�2)2+ℓ2. از آنجا که L = H�=اچ، ما بدست می آوریم
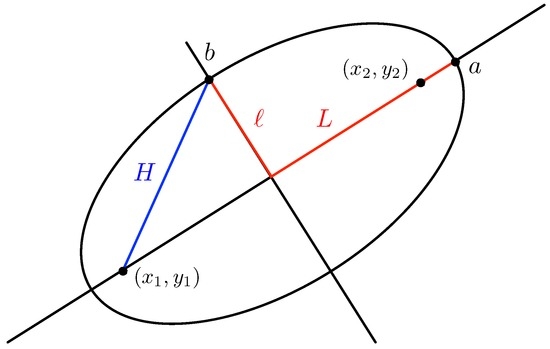
در نهایت، اگر ایکس1≠ایکس2ایکس1≠ایکس2، شیب خط اتصال را مخفف می کنیم (ایکس1،y1)(ایکس1،�1)و (ایکس2،y2)(ایکس2،�2)توسط s ، یعنی:
قضیه 2.
اجازه دهید (ایکس1،y1)(ایکس1،�1)و (ایکس2،y2)(ایکس2،�2)امتیاز در آر2آر2، و اجازه دهید L > 0�>0یک عدد واقعی باشد معادله بیضی با کانون (ایکس1،y1)(ایکس1،�1)و (ایکس2،y2)(ایکس2،�2)و محور نیمه اصلی L و جعبه مرزی آن با عبارات زیر به دست می آید:
-
اگر (ایکس1،y1) =(ایکس2،y2)(ایکس1،�1)=(ایکس2،�2)، سپس:
(x- _ایکسج)2+(y–yج)2=L2(ایکس-ایکسج)2+(�-�ج)2=�2معادله بیضی است و جعبه مرزی با استفاده از ایکس1=ایکسج– الایکس1=ایکسج-�، ایکس2=ایکسج+ الایکس2=ایکسج+�، Y1=yج– ال�1=�ج-�و Y2=yج+ ال�2=�ج+�;
-
اگر ایکس1=ایکس2ایکس1=ایکس2و y1≠y2�1≠�2، سپس:
(x- _ایکسج)2ℓ2+(y–yج)2L2= 1(ایکس-ایکسج)2ℓ2+(�-�ج)2�2=1معادله بیضی است و جعبه مرزی با استفاده از ایکس1=ایکسج– ℓایکس1=ایکسج-ℓ، ایکس2=ایکسج+ ℓایکس2=ایکسج+ℓ، Y1=yج– ال�1=�ج-�و Y2=yج+ ال�2=�ج+�;
-
اگر ایکس1≠ایکس2ایکس1≠ایکس2و y1=y2�1=�2، سپس:
(x- _ایکسج)2L2+(y–yج)2ℓ2= 1(ایکس-ایکسج)2�2+(�-�ج)2ℓ2=1معادله بیضی است و جعبه مرزی با استفاده از ایکس1=ایکسج– الایکس1=ایکسج-�، ایکس2=ایکسج+ الایکس2=ایکسج+�، Y1=yج– ℓ�1=�ج-ℓو Y2=yج+ ℓ�2=�ج+ℓ;
-
اگر ایکس1≠ایکس2ایکس1≠ایکس2و y1≠y2�1≠�2، سپس:
( y–yج− s ( x −ایکسج) )2ℓ2+( s ( y–yج) + ( x −ایکسج) )2L2= ( 1 +س2)(�-�ج-س(ایکس-ایکسج))2ℓ2+(س(�-�ج)+(ایکس-ایکسج))2�2=(1+س2)معادله بیضی است و جعبه مرزی به صورت زیر بدست می آید:
-
ایکس1=ایکسج–س2ℓ2+L21 +س2——√،ایکس1=ایکسج-س2ℓ2+�21+س2،
-
ایکس2=ایکسج+س2ℓ2+L21 +س2——√،ایکس2=ایکسج+س2ℓ2+�21+س2،
-
Y1=yج–س2L2+ℓ21 +س2——√�1=�ج-س2�2+ℓ21+س2و
-
Y2=yج+س2L2+ℓ21 +س2——√.�2=�ج+س2�2+ℓ21+س2.
-
اثبات
مورد 1.
فرض می کنیم (ایکس1،y1) = (ایکس2،y2)(ایکس1،�1)=(ایکس2،�2). در این حالت بیضی دایره ای با مرکز است (ایکسج،yج) = (ایکس1،y1) = (ایکس2،y2)(ایکسج،�ج)=(ایکس1،�1)=(ایکس2،�2)و شعاع L. با معادله به دست می آید:
جعبه مرزی این دایره با تعیین می شود ایکس1،ایکس2=ایکسج± Lایکس1،ایکس2=ایکسج±�و Y1،Y2=yج± L�1،�2=�ج±�.
مورد 2.
فرض می کنیم ایکس1=ایکس2ایکس1=ایکس2و y1≠y2�1≠�2. در این حالت یک بیضی داریم که محور اصلی در جهت محور y و محور فرعی در جهت محور x قرار دارد . معادله این بیضی به صورت زیر است:
جعبه مرزی این دایره با تعیین می شود ایکس1،ایکس2=ایکسج± ℓایکس1،ایکس2=ایکسج±ℓو Y1،Y2=yج± L�1،�2=�ج±�.
مورد 3.
فرض می کنیم ایکس1≠ایکس2ایکس1≠ایکس2و y1=y2�1=�2. در این حالت یک بیضی داریم که در آن محور اصلی در جهت محور x و محور کوتاه در جهت محور y قرار می گیرد . معادله این بیضی به صورت زیر است:
جعبه مرزی این دایره با تعیین می شود ایکس1،ایکس2=ایکسج± Lایکس1،ایکس2=ایکسج±�و Y1،Y2=yج± ℓ�1،�2=�ج±ℓ.
مورد 4.
خط ” F ” که کانون ها را به هم وصل می کند (ایکس1،y1)(ایکس1،�1)و (ایکس2،y2)(ایکس2،�2)معادله دارد اف( x ، y) = 0اف(ایکس،�)=0، جایی که:
خط ” P “، عمود بر F و از طریق (ایکسج،yج)(ایکسج،�ج)، معادله دارد پ( x ، y) = 0پ(ایکس،�)=0، جایی که:
بیضی با کانون (ایکس1،y1)(ایکس1،�1)و (ایکس2،y2)(ایکس2،�2)و محور نیمه اصلی L معادله دارد E( x ، y) = 0�(ایکس،�)=0، با E( x ، y) =اف( x ، y)2آ2+پ( x ، y)2ب2– 1�(ایکس،�)=اف(ایکس،�)2آ2+پ(ایکس،�)2ب2-1یا:
با A ، B > 0آ،ب>0.
به طور مشابه، A را با الزام به راه حل های سیستم می یابیمE( x ، y) = 0 ∧ P( x ، y) = 0�(ایکس،�)=0∧پ(ایکس،�)=0هستند 2 ℓ2ℓجدا از هم. اگر فاصله بین نقاط را تعیین کنیم (ایکسج–s A1 +س2،yج+آ1 +س2)(ایکسج-سآ1+س2،�ج+آ1+س2)و (ایکسج+s A1 +س2،yج–آ1 +س2)(ایکسج+سآ1+س2،�ج-آ1+س2)به 2 ℓ2ℓ، ما بدست می آوریم آ2=ℓ2( 1 +س2)آ2=ℓ2(1+س2).
بنابراین، معادله بیضی با کانون (ایکس1،y1)(ایکس1،�1)و (ایکس2،y2)(ایکس2،�2)و محور نیمه اصلی L با معادله به دست می آید E( x ، y) = 0�(ایکس،�)=0، جایی که:
برای تعیین جعبه مرزی این بیضی، بردار را در نظر می گیریم:
که برای یک امتیاز (ایکس0،y0)(ایکس0،�0)روی بیضی (یعنی برای آن E(ایکس0،y0) = 0�(ایکس0،�0)=0) جهت عمود بر بیضی را هنگامی که در ارزیابی می شود می دهد (ایکس0،y0)(ایکس0،�0).
وقتی تنظیم کردیم ∂E∂ایکس= 0���ایکس=0، این عمود در جهت محور y است . معادله ∂E∂ایکس= 0���ایکس=0است:
یا:
که خطی را مشخص می کند که بیضی را در دو نقطه قطع می کند. وقتی جایگزین می کنیم x –ایکسجایکس-ایکسجاز معادله این خط در معادله بیضی، مرزهای پایین و بالایی جعبه مرزی را به دست می آوریم:
و:
وقتی تنظیم کردیم ∂E∂y= 0����=0، عمود بر بیضی در جهت محور x است . معادله ∂E∂y= 0����=0است:
یا:
که خطی را مشخص می کند که بیضی را در دو نقطه قطع می کند. وقتی جایگزین می کنیم y–yج�-�جاز معادله این خط در معادله بیضی، کران چپ و راست کادر مرزی را بدست می آوریم:
و:
منابع
- جیانوتی، اف. Pedreschi, D. Mobility, Data Mining and Privacy-Geographic Knowledge Discovery ; Springer: برلین، آلمان، 2008. [ Google Scholar ]
- سفید، CE; برنشتاین، دی. Kornhauser، AL برخی از الگوریتم های تطبیق نقشه برای دستیاران ناوبری شخصی. ترانسپ Res. قسمت C Emerg. تکنولوژی 2000 ، 8 ، 91-108. [ Google Scholar ] [ CrossRef ]
- گوتینگ، RH; Schneider, M. Moving Object Databases ; مورگان کافمن: سانفرانسیسکو، کالیفرنیا، ایالات متحده آمریکا، 2005. [ Google Scholar ]
- ین، JY یافتن طول تمام کوتاه ترین مسیرها در شبکه های کامل با فاصله غیرمنفی گره N با استفاده از 1212N 3 اضافات و N 3 مقایسه. J. ACM 1972 , 19 , 423-424. [ Google Scholar ] [ CrossRef ]
- هاشمی، م. کریمی، HA مروری انتقادی از الگوریتم های تطبیق نقشه بلادرنگ: مسائل جاری و جهت گیری های آینده. محاسبه کنید. محیط زیست سیستم شهری 2014 ، 48 ، 153-165. [ Google Scholar ] [ CrossRef ]
- برنشتاین، دی. Kornhauser، AL مقدمه ای بر تطبیق نقشه برای دستیارهای ناوبری شخصی ؛ گزارش فنی؛ هیئت تحقیقات حمل و نقل: واشنگتن، دی سی، ایالات متحده آمریکا، 1998. [ Google Scholar ]
- Eddy, SR مدل مخفی مارکوف چیست؟ نات. بیوتکنول. 2004 ، 22 ، 1315-1316. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- نیوزون، پی. Krumm, J. Hidden Markov نقشه مطابق با نویز و پراکندگی. در مجموعه مقالات هفدهمین سمپوزیوم بین المللی ACM SIGSPATIAL در مورد پیشرفت در سیستم های اطلاعات جغرافیایی، نیویورک، نیویورک، ایالات متحده آمریکا، 4 تا 6 نوامبر 2009.
- کروم، جی. لچنر، جی. Horvitz، E. تطبیق نقشه با محدودیت های زمان سفر. در مجموعه مقالات انجمن مهندسان خودرو (SAE) کنگره جهانی 2007، دیترویت، MI، ایالات متحده آمریکا، 3-6 آوریل 2007.
- Greenfeld، JS تطبیق مشاهدات GPS با مکانهای روی نقشه دیجیتال. در مجموعه مقالات هشتاد و یکمین نشست سالانه هیئت تحقیقات حمل و نقل، واشنگتن دی سی، ایالات متحده آمریکا، 13 تا 17 ژانویه 2002.
- برکاتسولاس، اس. Pfoser، D.; سالاس، آر. Wenk, C. در مورد داده های ردیابی وسیله نقلیه مطابق با نقشه. در مجموعه مقالات سی و یکمین کنفرانس بین المللی پایگاه های داده بسیار بزرگ، تورنتو، ON، کانادا، 31 اوت تا 3 سپتامبر 2005.
- ونک، سی. سالاس، آر. Pfoser، D. پرداختن به نیاز به سرعت تطبیق نقشه: بومی سازی الگوریتم های تطبیق منحنی جهانی. در مجموعه مقالات هجدهمین کنفرانس بین المللی مدیریت پایگاه داده های علمی و آماری، وین، اتریش، 3 تا 5 ژوئیه 2006.
- کالمن، RE یک رویکرد جدید برای فیلتر کردن خطی و مشکلات پیشبینی. ترانس. ASME J. مهندس پایه. 1960 ، 82 ، 35-45. [ Google Scholar ] [ CrossRef ]
- قدوس، م. ژائو، ال. Ochieng، WY; Noland, RB یک الگوریتم فیلتر کالمن توسعه یافته برای یکپارچه سازی GPS و داده های سیستم محاسبه مرده کم هزینه برای عملکرد خودرو و نظارت بر انتشار گازهای گلخانه ای. جی. ناویگ. 2003 ، 56 ، 257-275. [ Google Scholar ]
- لی، ال. قدوس، م. ژائو، ال. الگوریتم نظارت بر یکپارچگی با دقت بالا برای تطبیق نقشه. ترانسپ Res. قسمت C Emerg. تکنولوژی 2013 ، 36 ، 13-26. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- قدوس، م. Ochieng، WY; نولاند، تطبیق نقشه RB در شبکه های پیچیده جاده های شهری. براز جیم کارتوگر. Revista Brasil. کارتوگر. 2003 ، 55 ، 1-18. [ Google Scholar ]
- Zadeh, LA Fuzzy sets. Inf. کنترل 1965 ، 8 ، 338-353. [ Google Scholar ] [ CrossRef ]
- Zhao, Y. سیستم های مکان یابی و ناوبری خودرو: سیستم های حمل و نقل هوشمند . سمینارهای Navtech و تامین GPS: اسکندریه، ویرجینیا، ایالات متحده آمریکا، 1997. [ Google Scholar ]
- سید، س. Cannon، ME الگوریتم تطبیق نقشه مبتنی بر منطق فازی برای سیستم ناوبری خودرو در دره های شهری. در مجموعه مقالات نشست فنی ملی 2004 موسسه ناوبری، مونتری، کالیفرنیا، ایالات متحده آمریکا، 26-28 ژانویه 2004.
- Quddus، MA الگوریتم های تطبیق نقشه با یکپارچگی بالا برای برنامه های کاربردی تله ماتیک حمل و نقل پیشرفته. دکتری پایان نامه، امپریال کالج، لندن، انگلستان، 2006. [ Google Scholar ]
- لو، ی. ژانگ، سی. ژنگ، ی. Xie، X. وانگ، دبلیو. Huang, Y. تطبیق نقشه برای مسیرهای GPS با نرخ نمونه برداری پایین. در مجموعه مقالات هفدهمین سمپوزیوم بین المللی ACM SIGSPATIAL در مورد پیشرفت در سیستم های اطلاعات جغرافیایی، سیاتل، WA، ایالات متحده آمریکا، 4-6 نوامبر 2009.
- لی، ی. هوانگ، Q. کربر، م. ژانگ، ال. Guibas، L. تطبیق نقشه مشترک در مقیاس بزرگ از ردیابی GPS. در مجموعه مقالات بیست و یکمین کنفرانس بین المللی ACM SIGSPATIAL در مورد پیشرفت در سیستم های اطلاعات جغرافیایی، نیویورک، نیویورک، ایالات متحده آمریکا، 5 تا 8 نوامبر 2013.
- تانگ، جی. آهنگ، ی. میلر، اچ جی; ژو، X. تخمین محتمل ترین مسیرهای فضا-زمان، زمان اقامت و عدم قطعیت های مسیر از داده های مسیر وسیله نقلیه: یک روش جغرافیایی زمانی. ترانسپ Res. قسمت C Emerg. تکنولوژی 2016 ، 66 ، 176-194. [ Google Scholar ] [ CrossRef ]
- چن، توسط; یوان، اچ. لی، کیو. لام، WHK; شاو، اس. Yan, K. الگوریتم تطبیق نقشه برای دادههای ماشین شناور با فرکانس پایین در مقیاس بزرگ. بین المللی جی. جئوگر. Inf. علمی 2014 ، 28 ، 22-38. [ Google Scholar ] [ CrossRef ]
- وانگ، دبلیو. جین، جی. ران، بی. Guo, X. نظارت بر ترافیک شبکه آزادراه در مقیاس بزرگ: یک الگوریتم تطبیق نقشه بر اساس داده های کاوشگر GPS با فرکانس پایین ثبت. جی. اینتل. ترانسپ سیستم 2011 ، 15 ، 63-74. [ Google Scholar ] [ CrossRef ]
- میوا، تی. کیوچی، دی. یاماموتو، تی. موریکاوا، تی. توسعه الگوریتم تطبیق نقشه برای داده های پروب فرکانس پایین. ترانسپ Res. قسمت C Emerg. تکنولوژی 2016 ، 22 ، 132-145. [ Google Scholar ] [ CrossRef ]
- رحمانی، م. کوتسوپولوس، اچ. استنتاج مسیر از دادههای خودروی شناور پراکنده برای شبکههای شهری. ترانسپ Res. قسمت C Emerg. تکنولوژی 2013 ، 30 ، 41-54. [ Google Scholar ] [ CrossRef ]
- هانتر، تی. آببل، پ. باین، AM فیلتر استنتاج مسیر: تطبیق نقشه کم تأخیر مبتنی بر مدل دادههای خودروی کاوشگر. IEEE Trans. هوشمند ترانسپ سیستم 2014 ، 15 ، 507-529. [ Google Scholar ] [ CrossRef ]
- زنگ، ز. ژانگ، تی. لی، کیو. وو، زی. زو، اچ. Gao, C. ویژگی انحنای تطبیق نقشه محدود برای دادههای خودروی کاوشگر فرکانس پایین. بین المللی جی. جئوگر. Inf. علمی 2016 ، 30 ، 660-690. [ Google Scholar ] [ CrossRef ]
- Pfoser، D.; جنسن، CS ثبت عدم قطعیت بازنماییهای شی متحرک. در یادداشت های سخنرانی در علوم کامپیوتر ; Güting, RH, Papadias, D., Lochovsky, FH, Eds. Springer: برلین، آلمان، 1999; صص 111-132. [ Google Scholar ]
- Egenhofer، MJ تقریب خطوط حیاتی جغرافیایی. در SpadaGIS، کارگاه آموزشی داده های مکانی و سیستم های اطلاعات جغرافیایی ; Bertino, E., Floriani, LD, Eds. دانشگاه جنوا: جنوا، ایتالیا، 2003. [ Google Scholar ]
- هورنسبی، ک. Egenhofer، MJ مدل سازی اجسام متحرک بر روی دانه بندی های متعدد. ان ریاضی. آرتیف. هوشمند 2002 ، 36 ، 177-194. [ Google Scholar ] [ CrossRef ]
- Wolfson, O. مدیریت اطلاعات اشیاء متحرک: چالش پایگاه داده. در یادداشت های سخنرانی در علوم کامپیوتر ; Halevy, AY, Gal, A., Eds. Springer: برلین، آلمان، 2002; صص 75-89. [ Google Scholar ]
- Hägerstrand، T. در مورد افراد در علم منطقه چطور؟ ثبت اوراق علمی دانشیار 1970 ، 24 ، 7-21. [ Google Scholar ] [ CrossRef ]
- میلر، HJ نظریه اندازه گیری برای جغرافیای زمانی. Geogr.l مقعدی. 2005 ، 37 ، 17-45. [ Google Scholar ] [ CrossRef ]
- Othman, W. مدیریت عدم قطعیت در پایگاه های داده مسیر. دکتری پایان نامه، دانشگاه هاسلت، هاسلت، بلژیک، 2009. [ Google Scholar ]
- هارت، PE; نیلسون، نیوجرسی؛ رافائل، بی. مبنایی رسمی برای تعیین اکتشافی مسیرهای حداقل هزینه. IEEE Trans. سیستم علمی سایبرن. 1968 ، 4 ، 100-107. [ Google Scholar ] [ CrossRef ]
- Dijkstra، EW در مورد دو مشکل در ارتباط با نمودارها. عدد. ریاضی. 1959 ، 1 ، 269-271. [ Google Scholar ] [ CrossRef ]
- غیس، ک. کویجپرز، بی. مولانز، بی. عثمان، دبلیو. ونگوئیدسنهوون، دی. Vaisman، تطبیق نقشه AA و عدم قطعیت: یک الگوریتم و آزمایش های دنیای واقعی. در مجموعه مقالات هفدهمین سمپوزیوم بین المللی ACM SIGSPATIAL در مورد پیشرفت در سیستم های اطلاعات جغرافیایی، سیاتل، دی سی، ایالات متحده آمریکا، 4 تا 6 نوامبر 2009.






© 2016 توسط نویسندگان؛ دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (CC-BY) (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر