

خلاصه
با پیشرفت فناوری وب جهانی (WWW)، مردم می توانند به راحتی محتوا را در وب به اشتراک بگذارند، از جمله داده های مکانی و خدمات وب. بنابراین، مسائل “مدیریت داده های جغرافیایی بزرگ” توجه را به خود جلب می کند. در میان مسائل بزرگ داده های جغرافیایی، این تحقیق بر کشف منابع جغرافیایی توزیع شده متمرکز است. از آنجایی که منابع در WWW پراکنده هستند، کاربران نمی توانند منابع مورد علاقه خود را به طور کارآمد پیدا کنند. در حالی که WWW دارای موتورهای جستجوی وب است که به مسائل مربوط به کشف منابع وب می پردازند، ما تصور می کنیم که وب جغرافیایی (یعنی GeoWeb) به موتورهای جستجوی GeoWeb نیز نیاز دارد. برای ایجاد یک موتور جستجوی GeoWeb، یکی از اولین گامها این است که به طور فعال منابع GeoWeb را در WWW کشف کنید. از این رو، در این مطالعه، ما خزنده GeoWeb را پیشنهاد می کنیم، یک چارچوب خزنده وب توسعه پذیر که می تواند انواع مختلفی از منابع GeoWeb را پیدا کند، مانند خدمات وب کنسرسیوم فضایی باز (OGC)، زبان نشانه گذاری کلید سوراخ (KML) و Shapefiles مؤسسه تحقیقات سیستم های محیطی، Inc (ESRI). علاوه بر این، ما از مفهوم محاسبات توزیع شده برای ارتقای عملکرد خزنده GeoWeb استفاده می کنیم. نتیجه نشان می دهد که برای 10 نوع منبع هدف، خزنده GeoWeb 7351 سرویس مکانی و 194003 مجموعه داده را کشف کرد. در نتیجه، ثابت شده است که چارچوب خزنده GeoWeb پیشنهادی قابل توسعه و مقیاس پذیر است تا یک نمایه جامع از GeoWeb ارائه دهد. ما از مفهوم محاسبات توزیع شده برای ارتقای عملکرد خزنده GeoWeb استفاده می کنیم. نتیجه نشان می دهد که برای 10 نوع منبع هدف، خزنده GeoWeb 7351 سرویس مکانی و 194003 مجموعه داده را کشف کرد. در نتیجه، ثابت شده است که چارچوب خزنده GeoWeb پیشنهادی قابل توسعه و مقیاس پذیر است تا یک نمایه جامع از GeoWeb ارائه دهد. ما از مفهوم محاسبات توزیع شده برای ارتقای عملکرد خزنده GeoWeb استفاده می کنیم. نتیجه نشان می دهد که برای 10 نوع منبع هدف، خزنده GeoWeb 7351 سرویس مکانی و 194003 مجموعه داده را کشف کرد. در نتیجه، ثابت شده است که چارچوب خزنده GeoWeb پیشنهادی قابل توسعه و مقیاس پذیر است تا یک نمایه جامع از GeoWeb ارائه دهد.
کلید واژه ها:
وب جغرافیایی ؛ کشف منابع ؛ خزنده وب ؛ کنسرسیوم فضایی باز
چکیده گرافیکی
1. معرفی
1.1. داده های بزرگ جغرافیایی
داده های مکانی برای کمک به تصمیم گیری، طراحی و آمار در زمینه های مختلف مانند مدیریت، تحلیل های مالی و تحقیقات علمی استفاده می شود [ 1 ، 2 ، 3 ، 4 ]. با پیشرفت شبکه جهانی وب (WWW)، وب 2.0 مفهومی را نشان میدهد که به همه اجازه میدهد تا به راحتی وبسایتها را راهاندازی کنند یا محتوا را در وب ارسال کنند [ 5 ]. کاربران می توانند داده ها یا خدمات خود را در پلتفرم های مختلف وب 2.0 مانند فیس بوک، ویکی پدیا و یوتیوب به اشتراک بگذارند. در میان تمام منابع (از جمله داده ها و خدمات) موجود به صورت آنلاین، منابعی که حاوی اطلاعات مکانی هستند، “GeoWeb” را تشکیل می دهند [ 6 ]]. هدف اصلی GeoWeb فراهم کردن دسترسی به دادهها یا خدمات مکانی از طریق پوشش جهانی WWW است. به عنوان مثال، یکی از معروف ترین منابع GeoWeb، خدمات نقشه برداری وب است، مانند نقشه های گوگل [ 7 ]. با توجه به [ 6 ]، GeoWeb بر اساس چارچوبی از استانداردهای باز و فناوری های مبتنی بر استانداردها، مانند خدمات جغرافیایی و زیرساخت داده های مکانی (SDI) [ 8 ] است. سپس کاربران می توانند به این منابع متصل شوند تا داده ها/اطلاعات مکانی را برای تحلیل های بیشتر بازیابی کنند.
در حالی که داده های بیشتری در وب سریعتر از هر زمان دیگری در گذشته تولید می شود، مفهوم “داده های بزرگ” توجه ها را به خود جلب می کند. Laney [ 9 ] ویژگی های 3V کلان داده را ارائه کرد که عبارتند از: حجم، سرعت و تنوع. به طور خاص، داده ها در وب با سرعت (سرعت) بالا تولید می شوند، به ذخیره سازی های بزرگ (حجم) نیاز دارند و انواع مختلفی دارند (تنوع)، مانند متن، تصویر و ویدیو. داده ها در GeoWeb همچنین با ویژگی 3 ولت داده های بزرگ مطابقت دارند [ 10]. به عنوان مثال، تصاویر ماهواره ای مشکل ذخیره سازی را ایجاد می کنند زیرا اندازه هر تصویر ممکن است تا چندین گیگابایت باشد. برای سرعت، با توجه به پیشرفت تکنولوژی حسگر و ارتباطات، تعداد حسگرها به سرعت در حال افزایش است و سنسورها مشاهداتی را با فرکانس بالا ایجاد می کنند. علاوه بر این، مشاهدات حسگر در GeoWeb [ 11 ] توسط تعداد زیادی گره حسگر تولید میشوند که انواع مختلفی از پدیدهها مانند دما، رطوبت و فشار هوا را رصد میکنند و تنوع زیادی در رابطه با قالبهای داده، پروتکلهای وب و چارچوب های معنایی
1.2. مشکلات در کشف منابع جغرافیایی
در حالی که کلان داده فرصت هایی را برای کشف پدیده هایی فراهم می کند که قبلاً قابل کشف نبودند، مسائل مختلف مدیریت کلان داده باید مورد توجه قرار گیرد [ 10 ]. از میان موضوعات، این مطالعه عمدتاً بر پرداختن به موضوع کشف منبع ژئو وب متمرکز است. در حال حاضر، اگر دانشمندان بخواهند دادههای مکانی را در WWW جستجو کنند، معمولاً با یافتن یک پورتال داده یا یک SDI شروع میکنند. پورتال های داده، وب سایت ها/خدماتی هستند که ارائه دهندگان داده میزبانی می کنند، مانند پورتال داده ناسا ( https://data.nasa.gov/ ) و مرکز ملی داده های آب و هوایی ( http://www.ncdc.noaa.gov/ )). SDI ها عمدتاً کاتالوگ هستند و خدمات رجیستری ورودی های خدمات داده را ارائه می دهند. در حالی که ارائه دهندگان می توانند خدمات را به تنهایی مدیریت کنند، کاربران می توانند ورودی های سرویس را از SDI پیدا کرده و مستقیماً به خدمات دسترسی داشته باشند. INSPIRE ( http://inspire-geoportal.ec.europa.eu/ )، Data.gov ( http://www.data.gov/ )، و GEOSS ( http://www.geoportal.org/web/ guest/geo_home_stp ) نمونه هایی از SDI هستند.
با این حال، یک مسئله مهم در رویکردهای موجود این است که کاربر ممکن است نداند پورتال های داده یا SDI هایی را که داده ها یا خدمات مورد نیاز کاربر را ارائه می دهند را پیدا کند. علاوه بر این، در حالی که دادهها در پورتالها توسط سازمانهای مختلف میزبانی میشوند و دادهها در SDI توسط ارائهدهندگان مختلف ثبت میشوند، هیچ پورتال داده یا SDI واحدی نمیتواند فهرست کامل داده را در GeoWeb ارائه دهد. علاوه بر این، مشکل ناهمگونی در رابط های کاربری و داده ها بین هر پورتال یا SDI وجود دارد. کاربران باید زمان بیشتری را برای یادگیری روش های دسترسی به داده ها و درک داده ها صرف کنند. از نظر SDI، ثبت پیچیده و فقدان انگیزه تمایل ارائه دهندگان به ثبت داده های خود را کاهش می دهد. به طور کلی، این مشکلات (جزئیات بیشتر در بخش 2.1 مورد بحث قرار خواهد گرفت) باعث ناکارآمدی کشف منابع GeoWeb می شود.
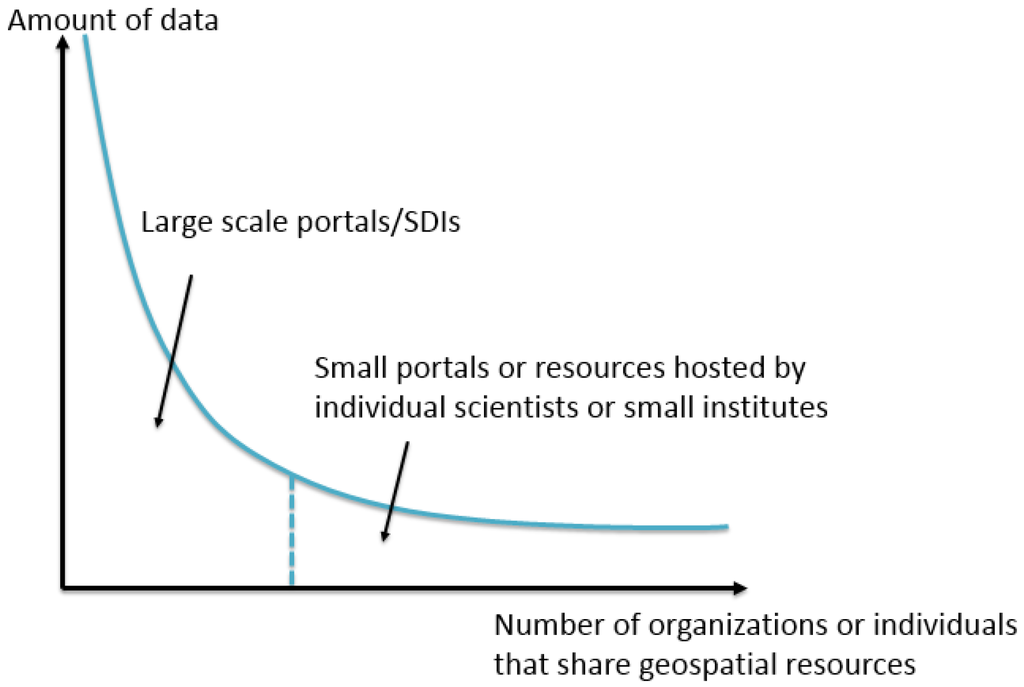
علاوه بر این، منابع خارج از پورتال داده های جغرافیایی/SDI نیز مهم هستند. بر اساس [ 12 ]، منابع GeoWeb را می توان به عنوان یک دم بلند مدل کرد ( شکل 1 ). در حالی که بیشتر پورتالهای دادههای مکانی و SDI توسط تعداد کمی از موسسات دولتی یا تحقیقاتی مدیریت میشوند، این پورتالها و SDIها مقدار قابلتوجهی از دادههای مکانی را ارائه میکنند. این داده ها به عنوان “سر” در دم بلند نامیده می شوند و معمولاً برای کاربران قابل دسترسی هستند. از سوی دیگر، پورتال های داده کوچک و منابع GeoWeb وجود دارند که توسط تعداد زیادی از دانشمندان یا مؤسسات کوچک میزبانی می شوند که «دم» را تشکیل می دهند. طبق نظریه دم بلند [ 13]، مقدار داده در دم برابر با مقدار در سر است. با این حال، منابع موجود در دم توسط پورتال های داده یا SDI های موجود در سر ایندکس نمی شوند و معمولا برای اکثر کاربران غیرقابل کشف هستند. همچنین یکی از ویژگی های مهم GIS (سیستم اطلاعات جغرافیایی) پوشاندن لایه های بین رشته ای و کشف روابط بین آنهاست. به خصوص برای دانشمندان داده، آنها ممکن است همیشه ندانند که داده های مکانی مورد نیاز خود را از کجا بیابند [ 14 ]. در این مورد، داشتن یک مخزن برای سازماندهی انواع مختلف داده های مکانی مهم است. بنابراین، به منظور ارائه یک فهرست کامل از GeoWeb به کاربران و یک ورودی یک مرحله ای برای یافتن هر منبع GeoWeb، ما به راه حلی نیاز داریم که بتواند به طور خودکار هر منبع جغرافیایی به اشتراک گذاشته شده آنلاین را کشف کند.
برای انجام یک کشف جامع در WWW، یکی از موثرترین راه حل ها موتور جستجوی وب مانند گوگل، بینگ و یاهو است. این موتورهای جستجو از رویکرد خزنده وب برای یافتن هر صفحه وب با عبور از هر لینک استفاده می کنند [ 15 , 16]. با این حال، جستجو برای منابع جغرافیایی آسان نیست زیرا بیشتر موتورهای جستجو برای جستجوی صفحات وب متن ساده طراحی شده اند. کاربران هنوز باید منابع مکانی را از صفحات وب توسط خودشان شناسایی کنند. علاوه بر این، GeoWeb دارای انواع منابع مختلف است، مانند خدمات وب کنسرسیوم فضایی باز (OGC)، دادههای مکانی مانند GeoTiff، GeoJSON، و Shapefile و خدمات کاتالوگ. هیچ راه حل کلی برای شناسایی هر نوع منبع وجود ندارد. بر اساس این دلایل، GeoWeb به یک موتور جستجوی خاص با مکانیزم خزیدن قابل گسترش برای شناسایی انواع مختلف منابع GeoWeb نیاز دارد.
علاوه بر این، پیروی از استانداردهای باز کلید شناسایی آسان منابع GeoWeb است. از آنجایی که استانداردهای باز پروتکلهای ارتباطی مشتری-سرور و مدلها/فرمتهای داده را تنظیم میکنند، منابع GeoWeb میتوانند تا زمانی که مشتری و سرور از استانداردهای باز پیروی کنند، مانند استانداردهای OGC و سازمان بینالمللی استاندارد (ISO) قابل همکاری باشند. در غیر این صورت، از نظر منابعی که به دنبال پروتکل های اختصاصی منتشر می شود. اگرچه این منابع اختصاصی نیز قابل شناسایی هستند، هزینه اضافی برای سفارشی کردن کانکتورهای خاص وجود دارد.
1.3. هدف پژوهش
برای ساخت موتور جستجوی GeoWeb، اولین قدم جمع آوری فهرست جامعی از منابع GeoWeb است. از این رو، تمرکز اصلی این مطالعه شناسایی و نمایه سازی هر منبع جغرافیایی در WWW است. برای مشخص بودن، ما یک چارچوب خزنده GeoWeb در مقیاس بزرگ، GeoWeb Crawler، برای کشف فعال منابع GeoWeb پیشنهاد میکنیم. اگرچه خزنده های وب به طور گسترده در موتورهای جستجوی وب برای کشف صفحات وب مورد استفاده قرار گرفته اند، خزنده GeoWeb باید برای شناسایی انواع مختلف منابع جغرافیایی قابل توسعه باشد. بنابراین، یکی از کلیدهای این مطالعه، تعریف قوانین شناسایی برای انواع مختلف منابع GeoWeb و اعمال این قوانین در یک چارچوب خزنده است. در این مورد، خزنده GeoWeb را می توان به راحتی برای یافتن انواع منابع دیگر گسترش داد. علاوه بر این، از آنجایی که خزیدن وب یک فرآیند زمانبر است،17 ] در GeoWeb Crawler برای اجرای فرآیند خزیدن به صورت موازی. به طور کلی، این تحقیق یک چارچوب خزیدن GeoWeb توسعهیافته و مقیاسپذیر را پیشنهاد کرد که پتانسیل شناسایی فعالانه هر منبع جغرافیایی به اشتراک گذاشته شده در وب را دارد. ما معتقدیم که GeoWeb Crawler می تواند پایه و اساس یک موتور جستجوی GeoWeb باشد.
ادامه این مقاله به شرح زیر سازماندهی شده است. بخش 2 رویکردهای موجود برای کشف منابع GeoWeb را مورد بحث قرار می دهد. بخش 3 توزیع منابع GeoWeb و دامنه تحقیق را تعریف می کند. در بخش 4 ، ما جزئیات خزنده GeoWeb، از جمله استخراج مکان یاب منبع یکنواخت (URL) از صفحات وب متن ساده، شناسایی انواع مختلف منابع، گردش کار محاسباتی توزیع شده، و فیلتر کردن URL های اضافی را ارائه می کنیم. بخش 5 نتایج و ارزیابی های خزیدن را از دیدگاه های مختلف توضیح می دهد. در بخش 6، ما نمونه اولیه یک موتور جستجوی GeoWeb به نام GeoHub را بر اساس منابع کشف شده توسط GeoWeb Crawler نشان می دهیم. در نهایت، نتیجه گیری و کار آینده این مطالعه در بخش 7 ارائه شده است .
2. کارهای مرتبط
2.1. رویکردهای موجود برای کشف منابع GeoWeb
همانطور که قبلا ذکر شد، ما رویکردهای موجود برای یافتن منابع GeoWeb را در رویکردهای پورتال/سرویس داده و کاتالوگ دسته بندی می کنیم. همانطور که در جدول 1 نشان داده شده است، می توان این دو رویکرد را به راه حل های استاندارد باز و راه حل های غیر استاندارد باز تفکیک کرد.. خدمات وب مانند وب سرویس OGC و سرویس نقشه کاشی بنیاد زمین فضایی منبع باز (OSGeo) نمونه هایی برای پورتال/سرویس داده های زیر استانداردهای باز هستند. منابع جغرافیایی با توجه به مشخصات منتشر شده است. از سوی دیگر، اکثر پورتال های داده مانند پورتال داده ناسا و مرکز ملی داده های آب و هوایی بر اساس هیچ استاندارد باز نیستند. مدلهای داده و پروتکلهای ارتباطی این پورتالها/سرویسهای استاندارد غیرباز متفاوت است. برای کاتالوگ ها، آنها ورودی برای یافتن منابع هستند. خدمات کاتالوگ OGC برای وب (CSW) یک استاندارد باز برای تنظیم رابط خدمات کاتالوگ است در حالی که SDI هایی مانند Data.gov و GEOSS به طور مستقل توسعه یافته اند. در اینجا به مشکلات این چهار دسته می پردازیم.
از نظر پورتال های داده و وب سرویس ها، یکی از بحرانی ترین مشکلات این است که کاربران ممکن است هر پورتال داده و وب سرویسی را که حاوی منابع مورد نیازشان است، نشناسند. به عنوان مثال، اگر کاربری بخواهد تصاویر ماهوارهای را برای تحقیقات تغییر پوشش زمین جمعآوری کند تا تمام تصاویر ماهوارهای را در منطقه مورد نظر بازیابی کند، کاربر باید هر پورتال داده و خدماتی را که تصاویر ماهوارهای را ارائه میکند، بشناسد. به طور مشابه، برای رویکردهای کاتالوگ، کاربران نمی توانند مطمئن شوند که داده های مورد نظر خود را از هر سرویس کاتالوگ جستجو کرده اند، زیرا هیچ کاربری از خدمات کاتالوگ اطلاعی ندارد. یکی دیگر از مشکلات مهم رویکرد کاتالوگ این است که ارائه دهندگان داده معمولاً انگیزه ای برای صرف زمان و تلاش برای ثبت داده ها یا خدمات خود در یک یا چند سرویس کاتالوگ ندارند. در نتیجه،
علاوه بر مشکلات ذکر شده در بالا، برای پورتال های داده/خدمات و کاتالوگ هایی که از استانداردهای باز پیروی نمی کنند، مشکلات ناهمگونی نیز وجود دارد. به عنوان مثال، رابط های کاربری و رویه های بین هر پورتال/سرویس یا کاتالوگ تا حد زیادی متفاوت است، همانطور که در شکل 2 نشان داده شده است . کاربران باید روش های دسترسی به داده ها از پورتال های مختلف را بیاموزند. ناهمگونی ها در مدل های داده و پروتکل های ارتباطی نیز وجود دارد. داده های ارائه شده توسط پورتال ها/سرویس ها و کاتالوگ های غیر استاندارد از مدل ها و پروتکل های داده اختصاصی استفاده می کنند. کاربران باید زمان و تلاش بیشتری را صرف سفارشی کردن کانکتورها برای بازیابی و درک داده ها کنند.
به طور کلی، این مشکلات رویکردهای کشف منابع GeoWeb موجود، کشف داده های مکانی را ناکارآمد می کند و رشد ژئو وب را محدود می کند. برای پرداختن به این موضوع، این مطالعه از راهحلهای کشف منبع WWW یاد میگیرد، زیرا WWW همچنین دارای منابع بسیار گستردهای است. به طور خاص، هدف ما ساخت یک موتور جستجوی GeoWeb برای ارائه خدمات یک مرحله ای به کاربران برای کشف داده های مکانی است و در عین حال از درخواست از ارائه دهندگان داده برای ثبت منابع اجتناب می کنیم. با این حال، برای دستیابی به این چشم انداز موتور جستجوی GeoWeb، یکی از اولین گام ها جمع آوری یک فهرست کامل از GeoWeb است. همانطور که موتورهای جستجوی وب عمومی از خزندههای وب برای جمعآوری فهرست صفحات وب استفاده میکنند، موتور جستجوی GeoWeb به یک خزنده منبع GeoWeb نیز نیاز دارد. از این رو، راه حل های موجود خزنده منابع GeoWeb را در زیربخش بعدی بررسی می کنیم.
2.2. راه حل های خزنده منابع GeoWeb موجود
خزنده های اولیه وب را می توان به سال 1993 ردیابی کرد، از جمله World Wide Web Wanderer، Jump Station، World Wide Web Worm و مهندسی نرم افزار مبتنی بر مخزن (RBSE) که برای جمع آوری اطلاعات و آمار در مورد وب پیشنهاد شد [18] .]. امروزه یکی از کاربردهای اصلی خزنده های وب، کاوش در صفحات وب و نمایه سازی خودکار آن صفحات برای موتورهای جستجوی وب مانند گوگل و یاهو است! یک خزنده وب از فهرستی از URL ها به عنوان دانه برای شروع فرآیند خزیدن استفاده می کند. خزنده به هر Seed (به عنوان مثال، صفحه وب) متصل می شود، تمام لینک های موجود در این دانه ها را شناسایی می کند، و سپس از طریق آن لینک ها به صفحات وب دیگر پیوند می دهد. این فرآیند تا زمانی تکرار می شود که خزنده تمام صفحات وب پیوند شده در WWW را بخزد. با این رویکرد خزیدن وب، موتورهای جستجوی وب می توانند فهرست کاملی از صفحات وب را در اختیار کاربران قرار دهند.
تحقیق ما بر اساس همان مفهوم خزیدن وب است و هدف آن توسعه خزنده منابع GeoWeb برای کشف منابع مکانی در وب است، مانند سرویس وب OGC (OWS)، فایلهای Keyhole Markup Language (KML) و موسسه تحقیقات سیستمهای محیطی. , Inc (ESRI) Shapefiles. طبق [ 19 ]، اولین خزنده OWS پیشنهادی، موتور جستجوی اطلاعات فضایی (SISE) بود که توسط [ 20 ] توسعه یافت. پروژه PolarHub با بودجه NSF ( http://polar.geodacenter.org/polarhub2/ ) همچنین یک خزنده OWS را توسعه داد و بر تحلیل معنایی متمرکز شد [ 21 ]. استخوان و همکاران [ 22 ] موتور جستجوی مکانی (GSE) را ساخت ( http://www.wwetac.us/GSE/GSE.aspx) که سرویس نقشه وب OGC (WMS)، ArcIMS، سرور ArcGIS و Shapefile را ارائه می دهد. استخوان و همکاران همچنین در مورد عملکردهای موتور جستجو مانند جستجو و رتبه بندی بحث شد. کارهای دیگر عبارتند از [ 23 ] که یک خزنده WMS را برای بهبود پایگاه داده اطلاعات مکانی نیروی دریایی ایالات متحده ایجاد کرد، [ 24 ] که ماژولی را برای یافتن سرویس ویژگی های وب OGC (WFS)، سرویس پوشش وب (WCS) و CSW طراحی کرد، [ 25 ] که تمرکز بر خزیدن کارآمد برای WMS، [ 26 ] که یک خزنده متمرکز بر OGC را توسعه داد و بر آمار OWS تأکید کرد، [ 27 ] که برای WFS خزیده و بر بازیابی حاشیه نویسی های معنایی منبع داده توسط هستی شناسی تمرکز کرد، و [ 28 ]] که یک موتور جستجوی تخصصی برای کشف Shapefiles ESRI ساخت.
این آثار موجود، خزندههای GeoWeb را برای کشف منابع جغرافیایی توسعه دادند و تمرکزهای مختلفی داشتند، مانند کارایی خزیدن، توسعه موتور جستجوی GeoWeb، تجزیه و تحلیل معنایی، و غیره. هنوز بخش بزرگی از منابع GeoWeb مانند KML یا منابع غیر استاندارد باز خزیده نشده است. بنابراین، در این مطالعه سعی شده است تا یک چارچوب خزنده توسعه پذیر و مقیاس پذیر برای یافتن انواع منابع GeoWeb ایجاد کنیم. برای توضیح بیشتر و تعریف دامنه این مطالعه، بخش بعدی توزیع منابع GeoWeb در WWW را معرفی میکند.
3. گستره تحقیق و توزیع منابع ژئو وب
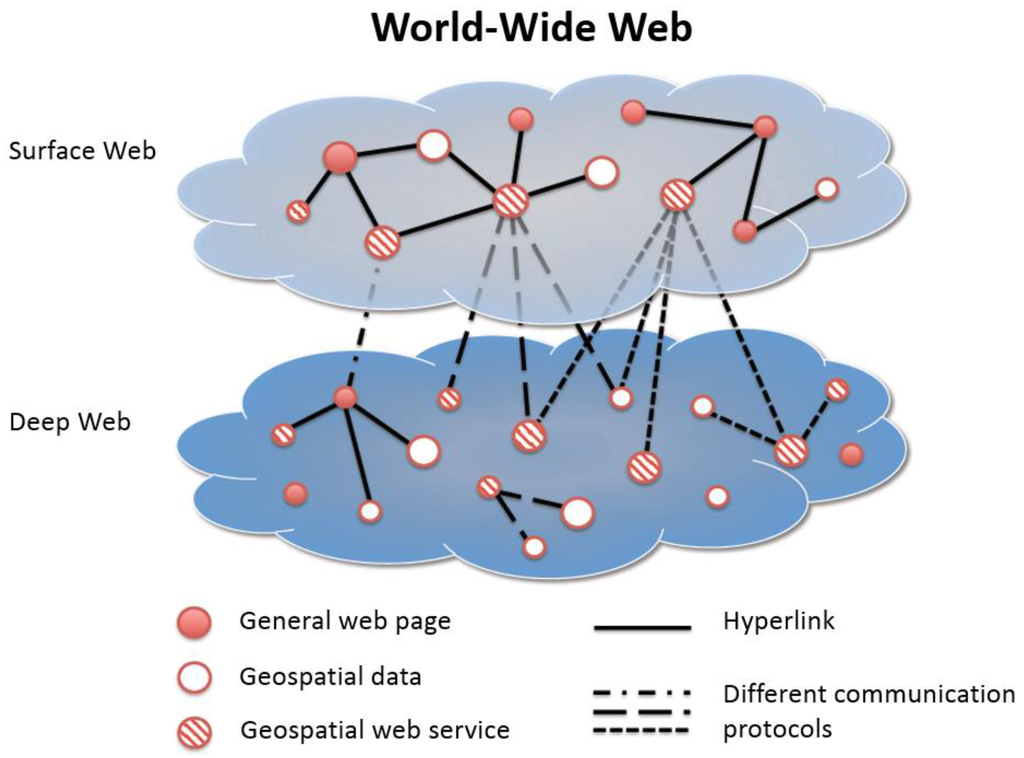
برای داشتن تعریف واضحتر از اهداف جستجوی خود، WWW را به چهار بخش طبقهبندی میکنیم: (1) وب سرویس فضایی در سرفیس وب. (2) داده های جغرافیایی در سطح وب. (3) وب سرویس جغرافیایی در وب عمیق. و (4) داده های مکانی در دیپ وب. این مفهوم در شکل 3 نشان داده شده است . لی [ 21] “Surface Web” و “Deep Web” را در WWW تعریف می کند. سرفیس وب به معنای وب است که کاربران می توانند از طریق لینک ها به آن دسترسی داشته باشند و برای خزنده های وب عمومی قابل مشاهده است. با این حال، برخی از منابع در WWW پنهان هستند که آدرسهای آنها از طریق سرفیس وب از طریق لینکها قابل دسترسی نیست. این منابع در دیپ وب نامیده می شوند، مانند مجموعه داده ها در سرویس های وب یا پورتال های داده/SDI. برای یافتن منابع در دیپ وب، باید با پیروی از پروتکلهای ارتباطی خاص، سرویسهای سرفیس وب را طی کنیم.
همانطور که قبلا ذکر شد، برای شناسایی و دسترسی به منابع مکانی در WWW، استانداردهای باز ضروری هستند زیرا ارتباطات بین مشتری و سرور را تنظیم می کنند. اگر ارائه دهندگان منابع را بدون پیروی از هیچ استاندارد باز به اشتراک بگذارند، یک مشکل قابلیت همکاری وجود خواهد داشت که کاربران نمی توانند به طور کلی این منابع را شناسایی یا به آنها دسترسی داشته باشند. بنابراین، با استانداردهای باز، میتوان مکانیسمهای شناسایی مختلفی را طراحی کرد تا منابعی را مطابق با این استانداردها پیدا کنیم و منابع را بیشتر تجزیه و فهرستسازی کنیم.
در حالی که برخی از استانداردهای خدمات وب مکانی باز مانند OSGeo TMS، OGC WMS، WFS و WCS وجود دارد، استانداردهایی برای فرمت های داده مانند ESRI Shapefile، TIFF/GeoTIFF، GeoJSON، OGC Geographic Markup Language (GML) و KML وجود دارد. . از سوی دیگر، همانطور که در بالا ذکر شد، منابع جغرافیایی ممکن است در خدمات کاتالوگ نمایه شوند، مانند OGC CSW که از استاندارد باز پیروی می کنند یا SDI هایی که از پروتکل های ارتباطی اختصاصی استفاده می کنند.
از آنجایی که خزندههای وب میتوانند منابع مکانی را با مکانیسمهای شناسایی طراحیشده بر اساس استانداردها کشف کنند، برای منابعی که از استانداردها پیروی نمیکنند، میتوان آنها را نیز کشف کرد، اما با هزینههای اضافی، اتصالهای سفارشیسازی شده را توسعه داد. در حالی که انواع مختلفی از منابع جغرافیایی وجود دارد، یک چارچوب خزنده GeoWeb باید برای شناسایی انواع منابع مختلف قابل توسعه باشد. برای اثبات مفهوم، اهداف جستجو در این مطالعه در جدول 2 نشان داده شده است. برای پورتالهای داده و سرویسهایی که از استانداردهای باز پیروی میکنند، ما بر روی OGC WMS، WFS، WCS، Web Map Tile Service (WMTS)، خدمات پردازش وب (WPS) و Sensor Observation Service (SOS) تمرکز کردیم. این OWS نقشهها (مثلاً تصاویر ماهوارهای)، دادههای برداری (مثلاً مرزهای کشور)، دادههای شطرنجی (مثلاً مدل ارتفاعی دیجیتال)، کاشیهای نقشه (مانند کاشیهای تصویری یک عکس هوایی)، پردازش جغرافیایی (مثلاً فرآیند بافر کردن) را ارائه میکنند. ) و مشاهدات حسگر (به عنوان مثال، سری زمانی داده های دما)، به ترتیب. کاربران باید از عملیات خاصی که در هر OWS تعریف شده است برای بازیابی داده های مکانی از سرویس ها استفاده کنند. در حالی که از نظر منابع غیر استاندارد باز، سیستم پرس و جو تصویر آرشیو سازمان فضایی ملی (NSPO) را به عنوان هدف انتخاب می کنیم که قابلیت های جستجو برای تصاویر ماهواره ای FORMOSAT-2 را فراهم می کند. برای کاتالوگ ها OGC CSW و US data.gov به ترتیب اهداف استاندارد باز و غیر استاندارد باز ما هستند. علاوه بر این، این تحقیق قالبهای دادههای مکانی، از جمله فایلهای KML و Shapefiles ESRI را نیز مورد هدف قرار میدهد. KML نیز یک استاندارد OGC است که یک فرمت فایل برای ذخیره ویژگی های جغرافیایی مانند نقاط، چند خط و چند ضلعی و سبک های ارائه آنها است. KMZ یک فایل KML فشرده است که یکی از اهداف جستجوی ما نیز می باشد. ESRI Shapefile یک فرمت داده برداری مکانی محبوب است. اگرچه این مقاله تمام انواع منابع GeoWeb ممکن را مورد هدف قرار نداده است، اما راه حل پیشنهادی هنوز تنوع بیشتری از منابع را نسبت به هر راه حل موجود ارائه می دهد. از جمله فایل های KML و Shapefiles ESRI. KML نیز یک استاندارد OGC است که یک فرمت فایل برای ذخیره ویژگی های جغرافیایی مانند نقاط، چند خط و چند ضلعی و سبک های ارائه آنها است. KMZ یک فایل KML فشرده است که یکی از اهداف جستجوی ما نیز می باشد. ESRI Shapefile یک فرمت داده برداری مکانی محبوب است. اگرچه این مقاله تمام انواع منابع GeoWeb ممکن را مورد هدف قرار نداده است، اما راه حل پیشنهادی هنوز تنوع بیشتری از منابع را نسبت به هر راه حل موجود ارائه می دهد. از جمله فایل های KML و Shapefiles ESRI. KML نیز یک استاندارد OGC است که یک فرمت فایل برای ذخیره ویژگی های جغرافیایی مانند نقاط، چند خط و چند ضلعی و سبک های ارائه آنها است. KMZ یک فایل KML فشرده است که یکی از اهداف جستجوی ما نیز می باشد. ESRI Shapefile یک فرمت داده برداری مکانی محبوب است. اگرچه این مقاله تمام انواع منابع GeoWeb ممکن را مورد هدف قرار نداده است، اما راه حل پیشنهادی هنوز تنوع بیشتری از منابع را نسبت به آنچه که هر راه حل موجود ارائه می دهد ارائه می دهد.
4. روش شناسی
در این بخش، چارچوب پیشنهادی خزیدن وب، GeoWeb Crawler، را برای کشف منابع جغرافیایی در وب ارائه میکنیم. به طور کلی، ما چهار چالش را در GeoWeb Crawler در نظر گرفتیم. اولاً، از آنجایی که منابع جغرافیایی ممکن است قادر به دسترسی مستقیم با لینکها نباشند، گاهی اوقات منابع در قالب متن ساده در صفحات وب ارائه میشوند. برای کشف این URLهای متن ساده، از تطبیق رشته عبارات منظم برای یافتن URLهای احتمالی به جای دنبال کردن پیوندهای HTML استفاده می کنیم. ثانیاً، از آنجایی که منابع جغرافیایی انواع مختلفی دارند، برای شناسایی منابع جغرافیایی هدفمند، مکانیسم های شناسایی خاصی برای هر نوع منبع باید طراحی شود. ثالثاً، خزیدن منابع در وب فرآیندی زمانبر است. به منظور بهبود کارایی خزیدن وب، چارچوب پیشنهادی به گونه ای طراحی شده است که با مفهوم محاسبات توزیع شده مقیاس پذیر باشد. در نهایت، در حالی که فرآیند خزیدن وب از هر URL در صفحات وب عبور می کند، URL های یکسان را می توان در صفحات وب مختلف یافت. در این تحقیق از فیلتر بلوم [29 ] برای فیلتر کردن URL های اضافی. در زیر بخشهای بعدی، ابتدا گردش کار کلی GeoWeb Crawler را معرفی میکنیم و سپس راهحلهای چهار چالش را ارائه میکنیم.
4.1. جریان کار
همانطور که قبلا ذکر شد، برای راه اندازی یک خزنده وب، خزنده دانه ها مورد نیاز است. با این حال، به جای اینکه بذرها را به صورت دستی و ذهنی انتخاب کنیم، از قدرت موتورهای جستجوی عمومی وب استفاده می کنیم. در این تحقیق از موتور جستجوی گوگل استفاده می کنیم. از آنجایی که گوگل قبلاً صفحات وب را در سرفیس وب فهرست کرده است، میتوانیم مستقیماً صفحات وب مرتبط را با ارسال کلمات کلیدی طراحی شده به موتورهای جستجوی وب بازیابی کنیم. علاوه بر این، همانطور که موتور جستجوی گوگل نتایج جستجو را بر اساس ارتباط با کلمه کلیدی درخواست رتبه بندی می کند [ 30]، گوگل میتواند فهرستی از URLهای نامزدی را که احتمال بالایی برای داشتن منابع مکانی هدف دارند در اختیار ما قرار دهد. بنابراین، با استفاده از مکانیسمهای نمایهسازی و رتبهبندی موتور جستجوی گوگل، میتوانیم منابع مکانی را با درخواستهای خزیدن کمتر پیدا کنیم.
از آنجایی که هدف ما کشف منابع مکانی است که از استانداردهای خدمات OGC یا فرمتهای داده خاص پیروی میکنند، میتوانیم کلمات کلیدی جستجوی مختلفی مانند «OGC SOS»، «خدمات نقشه وب»، «WFS» و «دانلود KML» را برای غنیسازی طراحی کنیم. دانه های خزنده ما علاوه بر این، با استفاده از قدرت موتور جستجوی وب موجود، GeoWeb Crawler میتواند به سادگی با تعریف مکانیسمهای شناسایی و کلمات کلیدی جستجو، اهداف منابع جستجوی خود را گسترش دهد. در این مطالعه، برای هر جستجوی کلمه کلیدی، از URL های موجود در 10 صفحه جستجوی برتر گوگل به عنوان دانه های خزنده استفاده کردیم.
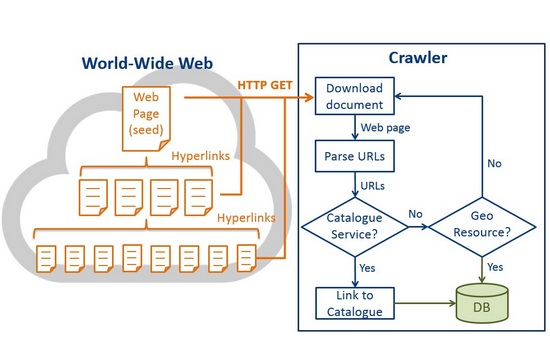
شکل 4 معماری سطح بالای GeoWeb Crawler است. پس از بازیابی دانه های خزنده، خزنده GeoWeb ابتدا درخواست های HTTP GET را برای دانلود اسناد HTML از صفحات وب اولیه ارسال می کند. در حالی که پیوندهای زیادی در عناصر لنگر HTML <a> ارائه می شوند، خزنده URL ها را از ویژگی “href” در عناصر لنگر استخراج می کند. سپس خزنده URL ها را از طریق برخی محدودیت های ساده فیلتر می کند، به عنوان مثال، URL هایی را که با “.doc”، “.pdf، “.ppt.، و غیره ختم می شوند، حذف کنید. با این حال، URL ها ممکن است به صورت متن های ساده در صفحات وب ارائه شوند. برای کشف این URL ها، از تطبیق رشته عبارات منظم استفاده می کنیم (مورد بحث در بخش 4.2). در نهایت، تمام URL های معتبر در صورتی که متعلق به سرویس های کاتالوگ هدفمند باشند، شناسایی می شوند که OGC CSW در این تحقیق است. اگر درست باشد، خزنده برای یافتن منابع مکانی و ذخیره منابع در پایگاه داده، به خدمات کاتالوگ پیوند می دهد. در غیر این صورت، خزنده بررسی خواهد کرد که آیا URL ها به منابع مکانی هدفمند مطابق با مکانیسم های شناسایی تعلق دارند (مورد بحث در بخش 4.3)). برای آن دسته از URLهایی که به هیچ منبع مکانی تعلق ندارند، ما به URL ها پیوند می دهیم و اسناد HTML آنها را دانلود می کنیم. این فرآیند تا زمانی که تمام صفحات وب در یک سطح خزیدن خزیده شوند تکرار می شود. در این مطالعه، سطح خزیدن را روی 5 قرار دادیم، به این معنی که خزنده GeoWeb میتواند تمام منابع مورد نظر را در پنج پیوند پیوند از صفحات seed پیدا کند. منظور ما از “link-hop” پیوند دادن از یک صفحه وب به صفحه وب دیگر است. این سطح خزیدن با توجه به زمان خزیدن تست ترجیحی ما با ماشینهای موجود تنظیم میشود. با این حال، خزنده میتواند منابع بیشتری را با پیوندهای پرشتر پیدا کند، و مطمئناً راهحل پیشنهادی میتواند برای خزیدن پوشش بزرگتری با ماشینهای بیشتر و پهنای باند اینترنت، کوچکتر شود. از آنجایی که ما فقط پنج سطح از دانه ها را خزیدیم، وقتی خزنده به سطح پنجم رسید، خزنده روند خزیدن را متوقف می کند. در حالی که پنج پیوند پیوند فقط به دلیل محدودیت سخت افزاری تنظیم شده بود، فلوچارت برای ترسیم فرآیند خزیدن کامل بود، که باید شامل یک حلقه برای خزیدن مداوم صفحات وب جدید باشد.
گردش کار بالا برای خزیدن منابع زیر استانداردهای باز است. از نظر منابع غیر استاندارد باز، خزنده GeoWeb نیاز به سفارشی سازی خزنده ها تا حد خاصی دارد که تا حد زیادی به هر منبع بستگی دارد. به عنوان مثال، برای خزیدن منابع از data.gov، ما مستقیماً دانه های خزنده را با جستجوی کلیدواژه در data.gov تنظیم می کنیم. در حالی که برای سیستم پرس و جو تصویر بایگانی NSPO ( http://fsimage.narlabs.org.tw/AIQS/imageSearchE )، از آنجایی که سیستم برای استفاده توسط انسان طراحی شده بود، که خزنده پسند نیست، ما از رابط برنامه نویسی برنامه استفاده کردیم. (API) از سرویس داده پشت سیستم برای ایجاد یک رابط سفارشی و بازیابی متاداده تصویر ماهواره ای FORMOSAT-2 به صورت دوره ای.
4.2. کشف URLهای متن ساده با عبارات منظم
همانطور که قبلاً اشاره کردیم، برخی از URL ها در فرم هایپرلینک HTML نشان داده نمی شوند، اما به عنوان متن های ساده نشان داده می شوند، به ویژه برای منابع مکانی که فقط از طریق پروتکل های ارتباطی خاص مانند OWS قابل دسترسی هستند. بنابراین، ما باید متون ساده در صفحات وب را برای بازیابی URL های احتمالی تجزیه کنیم.
به منظور کشف هر URL بالقوه، عبارت منظم [ 31 ] را اعمال می کنیم. از آنجایی که میخواهیم URLهای متن ساده را در صفحات وب پیدا کنیم، الگوی عبارت منظم زیر را طراحی میکنیم “\b(https?)://[-a-zA-Z0-9+&@#/%?=~_| !:,.;]*[-a-zA-Z0-9+&@#/%=~_|]، که میتواند نشانیهای اینترنتی را که با «http» یا «https» در یک سند HTML شروع میشود، کشف کند.
4.3. مکانیسم های شناسایی برای منابع مختلف جغرافیایی
با استانداردها، داده ها یا خدمات می توانند با هرکسی که از همان استاندارد پیروی می کند قابل همکاری باشد. در حالی که منابع جغرافیایی از نظر مدلهای داده، پروتکلهای ارتباطی و فرمتهای فایل تنوع زیادی دارند، ما باید مکانیسمهای شناسایی مختلفی را با توجه به استانداردهای مختلف طراحی کنیم. با توجه به اهداف جستجوی مشخص شده در جدول 2 ، در اینجا مکانیسم های شناسایی پیشنهادی را به شرح زیر مورد بحث قرار می دهیم.
در حالی که OGC استانداردهای باز بسیاری را برای منابع جغرافیایی تعریف کرده است، ما برخی از آنها را به عنوان اهداف جستجو انتخاب می کنیم. ما ابتدا خدمات وب OGC را مورد بحث قرار می دهیم. اکثر OWS ها از یک عملیات اجباری به نام “GetCapabilities” برای تبلیغ فراداده و محتوای داده این سرویس ها پشتیبانی می کنند. این طراحی یک راه آسان برای شناسایی OWS ها در اختیار ما قرار می دهد. با ارسال درخواست GetCapabilities به هر URL کاندید، اگر URL یک پاسخ معتبر برگرداند، URL متعلق به یک OWS است.
برای ارسال درخواست GetCapabilities، از HTTP GET با رمزگذاری KVP در هنگام شناسایی استفاده می شود. برخی از پارامترهای رایج در عملیات GetCapabilities وجود دارد که می تواند برای شناسایی منابع مفید باشد، از جمله “سرویس” که می تواند برای شناسایی نوع OWS استفاده شود، “درخواست” برای تعیین عملیات GetCapabilities. نمونه ای از درخواست GetCapabilities برای WMS این است: http://hostname:port/path?service=WMS&request=GetCapabilities .
برای شناسایی انواع دیگر OWS، میتوانیم به سادگی مقدار پارامتر “service” را جایگزین کنیم. به طور کلی، برای هر URL نامزد، GeoWeb Crawler گزینه های پرس و جو لازم را برای ارسال درخواست GetCapabilities اضافه می کند. اگر URL یک OWS باشد، خزنده یک سند معتبر قابلیتها را از سرویس دریافت میکند. بنابراین، ما باید قوانینی را طراحی کنیم تا بیشتر تشخیص دهیم که آیا یک پاسخ یک سند قابلیت معتبر برای منبع هدف است یا خیر.
در حالی که اسناد قابلیتها در قالب XML هستند، اگر URL یک OWS باشد، سند باید حاوی نام عنصر خاصی باشد (مثلاً «قابلیتها»). با این حال، نسخه های مختلف انواع مختلف OWS ها ممکن است نام عناصر متفاوتی داشته باشند. در این مورد، ما باید قوانینی را برای تأیید اسناد قابلیت ها برای OWS های مختلف و نسخه های مختلف تعریف کنیم:
-
OGC WMS: با توجه به مشخصات WMS [ 32 ، 33 ]، سند قابلیت ها باید حاوی یک عنصر ریشه به نام “WMT_MS_Capabilities” یا “WMS_Capabilities” برای نسخه 1.0.0 و 1.3.0 WMS باشد.
-
OGC SOS: طبق مشخصات SOS [ 34 ، 35 ]، سند قابلیت ها باید حاوی یک عنصر ریشه به نام «Capabilities» برای نسخه 1.0.0 و 2.0 SOS باشد.
-
OGC WFS: طبق مشخصات WFS [ 36 ، 37 ]، سند قابلیت ها باید حاوی یک عنصر ریشه به نام “WFS_Capabilities” برای نسخه 1.0.0 و 2.0 WFS باشد.
-
OGC WCS: طبق مشخصات WCS [ 38 ، 39 ، 40 ]، سند قابلیت ها باید حاوی یک عنصر ریشه به نام “WCS_Capabilities” برای نسخه 1.0.0 و “Capabilities” برای نسخه 1.1 و 2.0 WCS باشد.
-
OGC WMTS: طبق مشخصات WMTS [ 41 ]، سند قابلیت ها باید حاوی یک عنصر ریشه به نام «Capabilities» برای نسخه 1.0.0 WMTS باشد.
-
OGC WPS: طبق مشخصات WPS [ 42 ]، سند قابلیت ها باید حاوی یک عنصر ریشه به نام «Capabilities» برای نسخه 1.0.0 و 2.0 WPS باشد.
علاوه بر این، در مورد فایلهای دادههای مکانی مانند KML و ESRI Shapefile، از آنجایی که این فایلها معمولاً بهعنوان لینک دانلود در صفحات وب وجود دارند، قوانین شناسایی با قوانین مربوط به خدمات وب متفاوت است:
-
OGC KML: از آنجایی که KML یک فرمت داده است، پسوندهای فایل “.kml” یا “.kmz” خواهند بود (یعنی فایل .kml فشرده شده). بنابراین اگر یک رشته URL به “.kml” یا “.kmz” ختم شود، آن را به عنوان یک فایل KML در نظر می گیریم.
-
ESRI Shapefile: طبق استاندارد ESRI Shapefile [ 43 ]، یک Shapefile منفرد باید حداقل شامل یک فایل اصلی (به عنوان مثال، شامل “.shp”)، یک فایل فهرست (به عنوان مثال، “.shx”) و یک فایل پایگاه داده (به عنوان مثال، باشد. ، “.dbf”). بنابراین، Shapefiles اغلب به عنوان فایل ZIP در هنگام اشتراک گذاری در صفحات وب فشرده می شود. تنها راه برای تشخیص اینکه آیا فایل ZIP حاوی Shapefile است یا خیر، دانلود و استخراج فایل فشرده است. سپس اگر فایلها/پوشههای استخراجشده حاوی فایلهای «.shp» باشند، URL به عنوان یک منبع Shapefile در نظر گرفته میشود. با توجه به محدودیت سخت افزاری ما، ما فقط فایل های ZIP را که کوچکتر از 10 مگابایت هستند برای اثبات مفهوم دانلود و بررسی می کنیم.
علاوه بر این، برای خدمات کاتالوگ، از آنجایی که OGC CSW نیز یک OWS است، CSW را می توان با ارسال درخواست GetCapabilities شناسایی کرد.
-
OGC CSW: طبق مشخصات CSW [ 44 ]، سند XML باید حاوی عنصر ریشه ای به نام «Capabilities» برای نسخه 1.0.0 و 2.0 CSW باشد.
از آنجایی که CSW به عنوان یک سرویس کاتالوگ میزبان فهرست های منابع جغرافیایی عمل می کند، ما فقط می توانیم منابع را با پیروی از پروتکل های ارتباطی CSW بازیابی کنیم. در این مورد، خزنده GeoWeb از عملیات “GetRecords” برای بازیابی منابع پنهان در سرویس کاتالوگ استفاده می کند. علاوه بر CSW، خزنده GeoWeb پیشنهادی همچنین میتواند منابع جغرافیایی را در کاتالوگهای استاندارد غیرباز بخزد. با این حال، از آنجایی که بسیاری از کاتالوگهای غیر استاندارد باز مناسب خزنده نیستند، data.gov کاتالوگ قابل خزیدن است. ما کلمات کلیدی منابع مختلف را برای جستجو در data.gov اختصاص می دهیم. سپس فهرستی از صفحات وب کاندید را به عنوان دانه های خزنده برای شروع فرآیند خزیدن به دست آوردیم.
در نهایت، خزیدن منبع سیستم پرس و جو تصویر آرشیو NSPO ( http://fsimage.narlabs.org.tw/AIQS/imageSearchE ) با منابع دیگر متفاوت است. از آنجایی که سیستم برای خزنده مناسب نیست، ما یک کانکتور سفارشی را مطابق با رابط سرویس داده پشتیبان آن می سازیم تا به طور دوره ای ابرداده های تصاویر ماهواره ای جدید FORMOSAT-2 را بازیابی کنیم. به طور کلی، با پیوند دادن به وب عمیق، میتوانیم منابع پنهان را کشف کنیم تا فهرست منابع جغرافیایی جامعتری ارائه کنیم.
4.4. فرآیند خزیدن توزیع شده برای مقیاس پذیری
برای بهبود عملکرد GeoWeb Crawler، مفهوم MapReduce [ 17 ] را برای اجرای فرآیند خزیدن به صورت موازی اعمال می کنیم. مفهوم MapReduce توسط گوگل برای رسیدگی به مسائل مقیاس پذیری مانند محاسبه شاخص ها در موتور جستجوی گوگل پیشنهاد شد. به طور کلی، MapReduce یک چارچوب پردازشی است که شامل دو فاز است، یعنی فاز نقشه و فاز کاهش . در مرحله نقشه ، داده های ورودی به چندین بخش مستقل تقسیم می شوند. تمام قطعات را می توان به صورت موازی پردازش کرد و نتایج جزئی ایجاد کرد. در فاز کاهش ، تمام نتایج جزئی در نقشه تولید می شودفاز به عنوان خروجی نهایی ادغام می شوند. فرآیندهای MapReduce را می توان به طور متوالی اجرا کرد تا فرآیند را تا زمانی که تمام وظایف به پایان برسد، تکرار کند.
به طور کلی، ما خزنده GeoWeb را با مفهوم MapReduce طراحی می کنیم. همانطور که در شکل 5 نشان داده شده است ، یک ماشین به عنوان اصلی اختصاص داده شده و به تعدادی از ماشین های کارگر متصل می شود . هر کارگر درخواستی را برای بازیابی URLهای نامزد به عنوان وظایف به استاد می فرستد. سپس کارگران با قوانین ارائه شده در بخش 4.3 شناسایی می کنند که آیا آن URL ها متعلق به منابع جغرافیایی هستند یا خیر . اگر URL یک منبع مکانی نباشد، کارگر فایل HTML را برای URL های جدید بازیابی و تجزیه می کند. منابع جغرافیایی شناسایی شده و URL های جدید سپس به اصلی بازگردانده می شوند . استاد _منابع جغرافیایی را در یک پایگاه داده ذخیره می کند و وظایف جدید (یعنی URL ها) را به کارگران اختصاص می دهد . از آنجایی که فرآیندهای خزیدن مستقل هستند، هر کارگر می تواند به صورت موازی کار کند. با گردش کار پردازشی طراحی شده، خزنده GeoWeb را می توان به صورت افقی برای افزایش کارایی مقیاس کرد.
4.5. فیلتر کردن URL های اضافی
در طول فرآیند خزیدن، URL های اضافی زیادی پیدا می شود. به عنوان مثال، با استفاده از “OGC SOS” به عنوان کلمه کلیدی جستجو، خزنده GeoWeb به طور کامل 9،911،218 آدرس اینترنتی را در fvie link-hops از صفحات اولیه خزیده است. با این حال، 7,813,921 از آنها URL اضافی هستند. به عبارت دیگر، تنها 2,097,297 URL منحصر به فرد هستند. این تعداد زیاد افزونگی به طور جدی بر عملکرد خزیدن تأثیر می گذارد زیرا همان URL ها می توانند به طور مکرر خزیده شوند. با این حال، ضبط همه URL ها برای تعیین اینکه آیا آنها خزیده شده اند یا خیر، ناکارآمد خواهد بود.
بنابراین، برای مقابله با این مشکل، فیلتر Bloom [ 29 ] را برای شناسایی URL های اضافی اعمال می کنیم. مفهوم فیلتر بلوم انتقال رشته به یک آرایه باینری است که می تواند فضای ذخیره را کوچک نگه دارد. همانطور که در شکل 6 نشان داده شده است ، ابتدا یک m (اندازه BitSet) BitSet ایجاد کنید و همه بیت ها را روی 0 تنظیم کنید. سپس k تابع هش مختلف را برای مدیریت n (تعداد رشته های URL) رشته انتخاب کنید. تابع هش هر تابعی است که بتوان از آن برای نگاشت داده های دیجیتال با اندازه دلخواه به داده های دیجیتال با اندازه ثابت استفاده کرد که به آن مقادیر هش می گویند. در این مورد، k اعداد صحیح را از k توابع هش از 0 تا m استخراج می کنیم– 1.
در این مطالعه، ما تمام کاراکترهای یک رشته URL را به کدهای اسکی (عدد صحیح) تبدیل می کنیم، سپس تابع هش ما مقادیر هش را بر اساس این کدهای اسکی محاسبه می کند. از این رو، هر رشته URL مربوط به مجموعه ای از بیت ها است که توسط مقادیر هش تعیین می شود. سپس این بیت ها را مانند شکل 6 از 0 تا 1 تنظیم کنید . با توجه به BitSet، ما می توانیم تعیین کنیم که آیا دو URL یکسان هستند یا نه. اگر بیتی مربوط به URL وجود دارد که روی 1 تنظیم نشده باشد، می توانیم نتیجه بگیریم که URL خزیده نشده است. در غیر این صورت، URL به عنوان افزونگی در نظر گرفته می شود.
با این حال، مطابقت های مثبت کاذب امکان پذیر است، اما منفی های کاذب امکان پذیر نیست. از آنجایی که اندازه BitSet محدود است، هر چه عناصر بیشتری به مجموعه اضافه شود، احتمال مثبت کاذب بیشتر می شود. بین ذخیره سازی و دقت تطبیق یک موازنه وجود دارد. بنابراین، باید مقدار مناسب m و k را با توجه به n تنظیم کنیم . با توجه به [ 45 ]، فرض کنید kn < m ، زمانی که تمام n عنصر به m BitSet توسط k توابع هش نگاشت می شوند ، احتمال یک بیت همچنان 0 (یعنی p’) و احتمال مثبت کاذب است (یعنی ، f’) در معادلات (1) و (2) نشان داده شده است.
پ“=( 1- _1متر)k n≈ه–k nمترپ“=(1–1متر)ک�≈ه–ک�متر
f“=( 1- _( 1- _1متر)k n)ک≈( 1- _پ“)ک�“=(1–(1–1متر)ک�)ک≈(1–پ“)ک
به عنوان مثال، اگر ما 10 تابع هش را تنظیم کنیم، و اندازه BitSet 20 برابر بیشتر از تعداد URL ها باشد، احتمال مثبت کاذب 0.00889٪ خواهد بود. به عبارت دیگر، حدود 9 خطا هنگام مدیریت 100000 URL رخ می دهد. با این وجود، چنین کیفیت تطبیقی همچنان در این مطالعه قابل قبول است. به طور کلی، با فیلتر بلوم، میتوانیم URLهای اضافی با فضای ذخیرهسازی کوچکتر را حذف کنیم.
5. نتایج و بحث
در این بخش، نتیجه خزیدن و ارزیابی ها را در دیدگاه های مختلف ارائه می کنیم. ابتدا، بخش 5.1 آخرین تعداد منابع کشف شده توسط GeoWeb Crawler را نشان می دهد. در مرحله دوم، ما تعداد منابع مکانی را بین GeoWeb Crawler و سایر رویکردهای موجود مقایسه میکنیم. ثالثاً، برای درک بهتر کارایی خزیدن، توزیع منابع کشف شده را بر اساس سطوح مختلف خزیدن (یعنی لینک هاپ) تجزیه و تحلیل می کنیم. در نهایت، از آنجایی که مفهوم محاسبات توزیعشده را برای اجرای موازی فرآیند خزیدن به کار میگیریم، عملکرد خزیدن را با استفاده از تعداد ماشینهای مختلف ارزیابی میکنیم.
5.1. نتایج خزیدن منابع جغرافیایی
در این مقاله، ما یک چارچوب خزنده GeoWeb، GeoWeb Crawler، برای جمع آوری منابع جغرافیایی طراحی و پیاده سازی می کنیم. در حالی که خزنده GeoWeb به گونه ای طراحی شده است که قابل توسعه باشد، این مقاله منابع مختلفی را هدف قرار داده است و نتیجه خزیدن در جدول 3 نشان داده شده است . در مجموع، ما 7351 سرویس جغرافیایی و 194003 مجموعه داده را در پنج ابرپیوند-hops از دانهها کشف کردیم. در میان این مجموعه داده ها، 1088 سرویس و 77874 مجموعه داده از data.gov و سرویس NSPO مشتق شده اند که نشان دهنده خدمات داده و کاتالوگ غیر استاندارد در این مطالعه است.
از آنجایی که سرویسهای وب ممکن است حجم زیادی از دادههای مکانی داشته باشند، ما ایده مجموعه دادهها را برای هر نوع سرویس تعریف میکنیم و تعداد مجموعههای داده را در جدول 3 نشان میدهیم . به طور خاص، برای OWS ها، ما سند قابلیت ها را تجزیه می کنیم و تعداد مجموعه داده ها را می شماریم.
اساساً، ما تعریف می کنیم که یک تصویر نقشه به عنوان “لایه” در WMS نشان داده می شود، یک مجموعه داده برداری “FeatureType” در WFS است، یک مجموعه داده شطرنجی “CoverageSummary” یا “CoverageOfferingBrief” در WCS است، یک تصویر کاشی نقشه است. «TileMatrix» در WMTS، پردازش جغرافیایی «فرایند» در WPS است و مجموعه دادههای مشاهده حسگر «ObservationOffering» در SOS است. اگرچه این تعاریف ممکن است مناسب ترین نباشند (به عنوان مثال، “ObservationOffering” به عنوان تعداد مجموعه داده هایی که در واقع از گروهی از مشاهدات تشکیل شده است)، استخراج اطلاعات مجموعه داده ها از اسناد قابلیت ها ما را از بازیابی داده های واقعی از سرویس ها باز می دارد. از آنجایی که WMS یک سرویس شناخته شده در OGC است، هم تعداد WMS های کشف شده و هم تعداد مجموعه داده ها در بین OWS ها بالاترین است. با توجه به میانگین زمان خزیدن، زمان عمدتاً به تعداد URLهای خزیده شده و اتصال اینترنت بین مشتری و سرور بستگی دارد. از آنجایی که شناسایی فایل ها نسبتاً ساده است، زمان خزیدن برای KML و Shapefile بسیار کمتر از خدمات GeoWeb است.
5.2. مقایسه بین خزنده GeoWeb و رویکردهای موجود
برخی از خدمات کاتالوگ موجود هستند که منابع جغرافیایی را ارائه می دهند. همانطور که در مقدمه ذکر شد، ارائه دهندگان داده باید منابع خود را در سرویس کاتالوگ ثبت کنند تا منابع را به اشتراک بگذارند. با این حال، هیچ انگیزه ای برای ارائه دهندگان وجود ندارد که منابع خود را در هر کاتالوگ ثبت کنند. این مشکل باعث می شود که کاتالوگ های مختلف منابع مختلفی را ارائه دهند و هیچ کدام جامع نباشد. برای پرداختن به این موضوع، از مفهوم خزنده وب برای کشف منابع مختلف جغرافیایی استفاده می کنیم. علاوه بر این، ارائه دهندگان داده تا زمانی که منابع را طبق استانداردها منتشر می کنند و در سرفیس وب به اشتراک می گذارند، نیازی به ثبت منابع ندارند.
به طور کلی، شکل 7 مقایسه مجموعه دادهها را بین GeoWeb Crawler و راهحلهای موجود نشان میدهد، که در آن 76065 تصویر ماهوارهای موجود در سرویس NSPO در شکل گنجانده نشده است زیرا هیچ یک از رویکردهای مقایسه شده این منبع را ارائه نمیدهند. همانطور که انتظار می رفت، تعداد مجموعه داده ها و تنوع منابعی که GeoWeb Crawler ارائه می دهد بسیار بیشتر از سایر روش ها است. به خصوص، یک نکته قابل توجه این است که مجموعه داده های سایر راه حل های مقایسه شده ممکن است بیش از حد تخمین زده شوند. به عنوان مثال، هنگامی که “WMS” را در GEOSS با استفاده از کلمه کلیدی “WMS” جستجو می کنیم، به طور مستقیم از تعداد کل نتایج استفاده می کنیم در حالی که هر نامزد WMS نیست، همانطور که در شکل 8 نشان داده شده است .
علاوه بر این، رویکردهای موجود در خزیدن OWS وجود دارد، مانند PolarHub [ 21 ] در سال 2014، Sample et al. [ 23 ] در سال 2006، لی و یانگ [ 25 ] در سال 2010، و لوپز-پلیسر و همکاران. [ 26 ] در سال 2010. در شکل 9 ، ما تعداد OWS را بین این کارها و خزنده GeoWeb مقایسه می کنیم. می بینیم که خزنده GeoWeb می تواند انواع بیشتری از منابع OWS را نسبت به کارهای دیگر جمع آوری کند. با چارچوب خزیدن در مقیاس بزرگ، GeoWeb Crawler می تواند OWS های بیشتری را نسبت به سایر روش ها کشف کند. به طور کلی، خزنده GeoWeb 3.8 تا 47.5 برابر بیشتر از هر راه حل کشف منابع جغرافیایی موجود (از جمله تصاویر ماهواره ای) منابع جمع آوری می کند.
5.3. توزیع سطح خزیدن منابع کشف شده
از آنجایی که خزنده وب پیشنهادی به دلیل محدودیت منابع سخت افزاری نمی تواند کل WWW را بخزد، ما GeoWeb Crawler را بر اساس موتور جستجوی Google طراحی می کنیم. موتور جستجوی گوگل با مکانیسم های نمایه سازی و رتبه بندی گوگل می تواند کاندیداهایی را در اختیار ما قرار دهد که با جستجوی کلمات کلیدی امکان در بر داشتن منابع جغرافیایی بالا را داشته باشند. در این مورد، خزنده GeoWeb میتواند منابع مکانی را با لینکهای کمتری پیدا کند. در حال حاضر، سطح خزیدن را روی 5 تنظیم می کنیم. یعنی دامنه خزیدن تمام URL های موجود در fvie link-hops از صفحات نتایج جستجوی گوگل است. در این مطالعه، ما استراتژی بازدید اولین نفس را برای خزیدن هر سطح کامل یکی یکی اتخاذ کردیم.
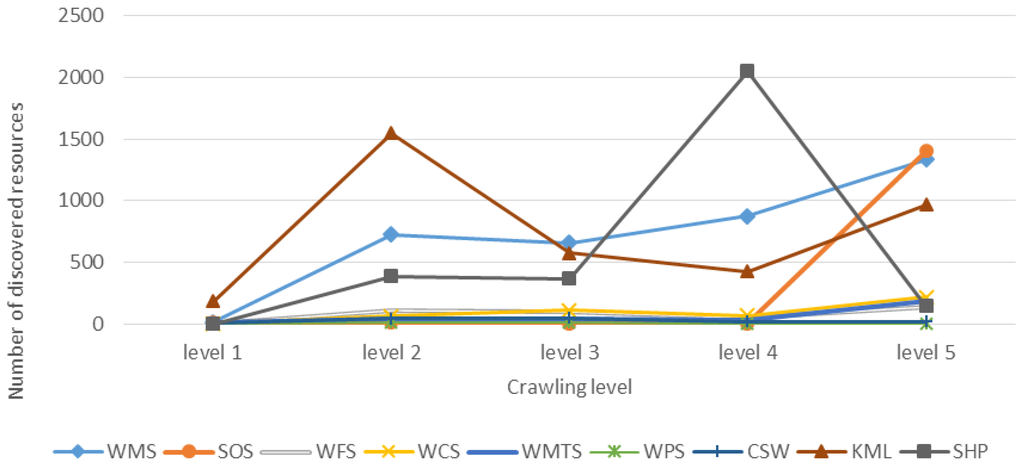
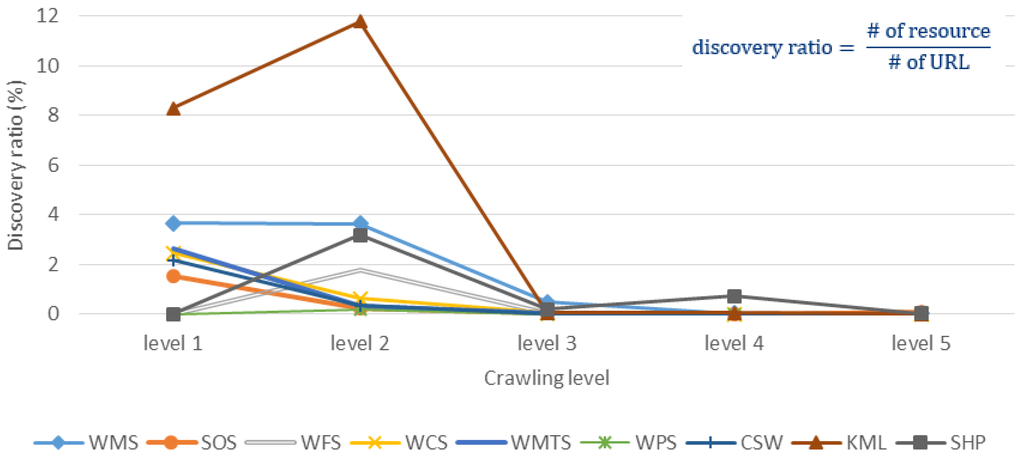
برای درک توزیع منابع مکانی، تعداد منابع کشف شده (سرویس ها و فایل ها) را در هر سطح خزنده در شکل 10 نمایش می دهیم . شکل نشان می دهد که منابع بیشتری را می توان با سطح خزیدن بزرگتر برای اکثر منابع پیدا کرد. با این حال، در شکل 11 ، نسبت کشف هر منبع را در هر سطح خزنده نشان میدهیم، که تعداد منابع کشفشده تقسیم بر تعداد کل URLها در هر سطح خزنده است. در حالی که نسبت کشف نشان دهنده تلاش لازم برای خزیدن است، میتوانیم ببینیم که روند نسبت کشف در امتداد سطوح خزیدن به دلیل رشد سریع اعداد URL در حال کاهش است.
به طور کلی، این دو رقم ابتدا نشان می دهد که موتور جستجوی گوگل می تواند دانه های نسبتا خوبی ارائه دهد تا بتوانیم منابعی را با سطوح خزیدن کوچک کشف کنیم. با سطوح بیشتری که می خزیم، منابع بیشتری را می توانیم کشف کنیم. با این حال، نسبت های کشف نیز به طور قابل توجهی با سطح خزیدن بزرگتر کاهش می یابد، که نشان دهنده تلاش غیرضروری بیشتر است. علاوه بر این، از نظر رفتار روند عجیب Shapefiles خزنده، ما معتقدیم دلیل آن این است که ما فقط فایل های ZIP کوچکتر از 10 مگابایت را برای اثبات مفهوم مورد بررسی قرار می دهیم، که به طور اجتناب ناپذیری بر رفتار روند تأثیر می گذارد. برای اوج KML در سطح 2، وب سایتی وجود دارد که تعداد زیادی فایل KMZ را ارائه می دهد. اساساً به دلیل رشد سریع اعداد URL همراه با سطح خزیدن،
5.4. مقایسه تأخیر خزیدن بین پردازش مستقل و موازی
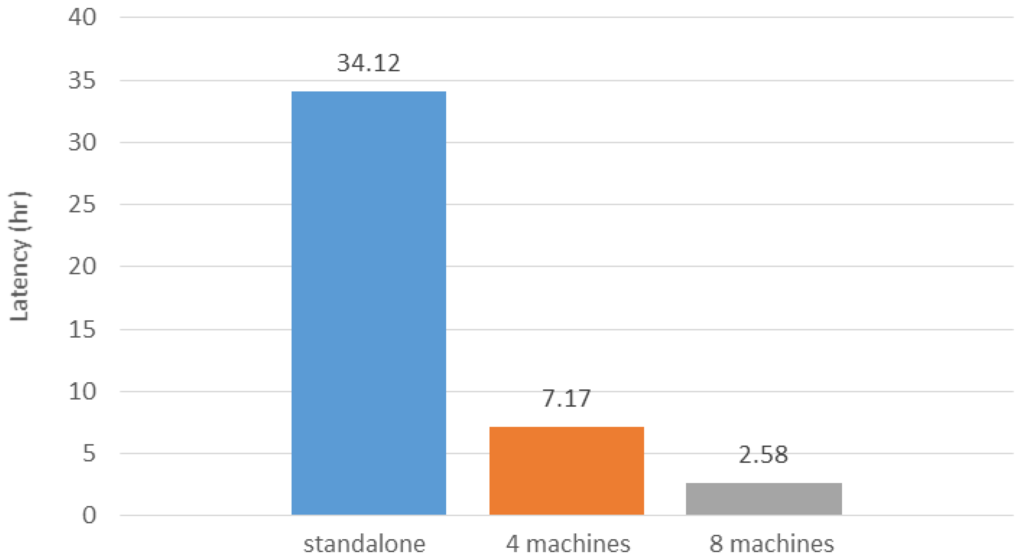
در این مطالعه، ما از مفهوم محاسبات توزیع شده برای بهبود عملکرد خزنده وب و مقیاس پذیر ساختن چارچوب خزیدن استفاده می کنیم. منظور ما از مقیاس پذیر این است که عملکرد خزیدن را می توان تنها با افزایش تعداد رایانه ها بهبود بخشید. در حالی که گلوگاه اصلی در منبع محاسباتی نیست، بلکه اتصال اینترنت است، ما استدلال میکنیم که مشخصات ماشین و ناهمگنی ماشین تاثیر زیادی بر عملکرد خزیدن ندارند. برای ارزیابی عملکرد پردازش موازی، شکل 12 تأخیرهای خزیدن استفاده از یک ماشین واحد (به عنوان مثال، مستقل)، چهار ماشین و هشت ماشین را به عنوان کارگر نشان می دهد.در چارچوب خزیدن پیشنهادی ما انتخاب کردیم که فایلهای KML را در این ارزیابی بخزیم زیرا روش شناسایی سادهترین روش است که میتواند تأخیر را کوتاه کند. خزیدن سایر منابع برای تنظیم مستقل زمان بسیار بیشتری (مثلاً بیش از یک هفته) می برد. همانطور که در شکل 12 نشان داده شده است ، حتی برای خزیدن فایل KML، فرآیند خزیدن هنوز به حدود یک و نیم روز برای تنظیم مستقل نیاز دارد. با این حال، با افزایش تعداد کارگران ، تاخیر خزیدن را می توان به طور قابل توجهی کاهش داد. این ارزیابی نشان میدهد که عملکرد خزیدن مقیاسپذیر است و میتواند برای خزیدن پوشش وسیعتری از وب برای کشف یک فهرست جامع منابع GeoWeb استفاده شود.
6. GeoHub – نمونه اولیه موتور جستجوی GeoWeb
از آنجایی که WWW دارای موتورهای جستجوی وب است که به مسائل مربوط به کشف منابع وب می پردازند، تصور می کنیم که GeoWeb همچنین به موتورهای جستجوی GeoWeb نیاز دارد تا کاربران بتوانند به طور موثر منابع GeoWeb را پیدا کنند. در این بخش، نمونه اولیه موتور جستجوی GeoWeb پیشنهادی، GeoHub را نشان میدهیم که در حال حاضر به کاربران اجازه میدهد OWSها را جستجو کنند. با رابط کاربری GeoHub، همانطور که در شکل 13 نشان داده شده است ، کاربران می توانند از جستجوی کلمه کلیدی برای یافتن OWS های مورد علاقه خود استفاده کنند. برای دستیابی به جستجوی کلمات کلیدی، موتور جستجوی GeoWeb به یک پایگاه داده برای مدیریت ابرداده هایی که به عنوان اطلاعات برای عملیات پرس و جو استفاده می شوند، نیاز دارد.
پس از شناسایی منابع GeoWeb، اطلاعات لازم را در یک پایگاه داده ذخیره می کنیم. در حالی که یک موتور جستجو میتواند از اطلاعات مختلف برای رتبهبندی نتایج جستجو استفاده کند، این نمونه اولیه به سادگی پرسشهای کاربر را با اطلاعات زیر مطابقت میدهد: URL منبع، نوع منبع، کلمه کلیدی مورد استفاده در موتور جستجوی Google، محتوا (به عنوان مثال، سند قابلیتها) و منبع صفحه وب. اسناد قابلیتها ابردادههایی را درباره OWS ارائه میکنند. نمونه ای از سند قابلیت های WMS در شکل 14 نشان داده شده است. در حال حاضر، ما همچنین اطلاعات خاصی را از اسناد قابلیت ها مانند نام سرویس، عنوان، چکیده، کلمات کلیدی، ابرداده محتوا و غیره استخراج می کنیم و سپس آنها را در پایگاه داده ذخیره می کنیم. از این رو، هر زمان که کلمات کلیدی جستجوی کاربران در اطلاعات استخراج شده وجود داشته باشد، خدمات مربوطه به کاربران بازگردانده می شود ( شکل 15 ).
7. نتیجه گیری و کار آینده
با استفاده از وب به عنوان یک پلتفرم، GeoWeb به طور مداوم حجم عظیمی از داده های مکانی را جمع آوری می کند. این پدیده بزرگ داده های جغرافیایی هنگام جستجوی داده های خاص از چنین حجم وسیعی از داده ها با به روز رسانی های مکرر و تنوع زیاد، مشکلاتی را ایجاد می کند. به منظور پرداختن به این مسئله کشف دادههای مکانی، هدف نهایی ما ایجاد یک موتور جستجوی GeoWeb مشابه موتورهای جستجوی وب موجود است. برای تحقق چنین موتور جستجوی GeoWeb، اولین گام این است که همه منابع داده های جغرافیایی در وب را کشف و فهرست بندی کنیم. بنابراین، در این مقاله، ما یک چارچوب خزنده GeoWeb به نام GeoWeb Crawler طراحی و توسعه میدهیم. با توجه به استانداردهای مختلف منابع جغرافیایی، خزنده GeoWeb می تواند مکانیسم های شناسایی مختلفی را برای کشف منابع در سرفیس وب اعمال کند. برای منابع موجود در Deep Web مانند OGC CSW و پورتال ها/SDI ها، GeoWeb Crawler می تواند از اتصال دهنده ها برای بازیابی منابع پشتیبانی کند. علاوه بر این، برای بهبود عملکرد خزنده های وب، فیلتر Bloom را برای حذف URL های اضافی و مفهوم محاسبات توزیع شده برای اجرای فرآیند خزیدن به صورت موازی اعمال می کنیم.
با توجه به نتیجه آزمایش، رویکرد پیشنهادی ما قادر به کشف انواع مختلفی از منابع جغرافیایی آنلاین است. در مقایسه با راه حل های موجود، GeoWeb Crawler می تواند منابع جامعی را از نظر تنوع و مقدار ارائه دهد. علاوه بر این، به جای اینکه ارائه دهندگان داده را ملزم به ثبت داده های خود کند، GeoWeb Crawler می تواند منابع را به طور فعال کشف کند تا زمانی که ارائه دهندگان از استانداردها پیروی کنند و پیوندهای منابع را در وب به اشتراک بگذارند.
به طور خلاصه، از آنجایی که موتورهای جستجوی WWW به طور قابل توجهی کارایی کشف منابع وب را بهبود می بخشند، چارچوب خزنده پیشنهادی پتانسیل تبدیل شدن به پایه موتور جستجوی GeoWeb را دارد. موتورهای جستجوی GeoWeb میتوانند نسل بعدی چارچوب کشف دادههای مکانی باشند که میتوانند دید و استفاده از منابع جغرافیایی را در زمینههای مختلف ارتقا دهند و به تجزیه و تحلیل جامع علم داده دست یابند.
از نظر سایر مسیرهای آینده، برای ارائه یک نمایه کامل GeoWeb، خزنده ها را گسترش می دهیم تا انواع دیگر منابع جغرافیایی مانند GeoTiff و GeoJSON را شناسایی کنند. ما همچنین به دنبال فرصتی برای گسترش زیرساخت های خود برای خزیدن در وب عمیق تر و گسترده تر خواهیم بود.
منابع
- Densham، PJ سیستم های پشتیبانی تصمیم فضایی. Geogr. Inf. سیستم پرنس Appl. 1991 ، 1 ، 403-412. [ Google Scholar ]
- کراسلند، MD؛ وین، بی. Perkins، WC سیستمهای پشتیبانی تصمیم فضایی: مروری بر فناوری و آزمون کارایی تصمیم می گیرد. سیستم پشتیبانی 1995 ، 14 ، 219-235. [ Google Scholar ]
- بارو، PA اصول سیستم های اطلاعات جغرافیایی برای ارزیابی منابع زمین. Geocar Int. 1986 ، 1 . [ Google Scholar ] [ CrossRef ]
- رائو، ام. فن، جی. توماس، جی. چریان، جی. چودیواله، وی. Awawdeh, M. یک سیستم پشتیبانی تصمیم گیری مبتنی بر وب برای مدیریت و برنامه ریزی برنامه ذخیره حفاظتی ایالات متحده آمریکا (CRP). محیط زیست مدل. نرم افزار 2007 ، 22 ، 1270-1280. [ Google Scholar ] [ CrossRef ]
- هاکلی، م. سینگلتون، ا. پارکر، سی. نقشه برداری وب 2.0: جغرافیای جدید geoweb. Geogr. Compass 2008 , 2 , 2011-2039. [ Google Scholar ] [ CrossRef ]
- لیک، آر. Farley، J. زیرساخت برای وب جغرافیایی. در وب جغرافیایی ؛ Springer: لندن، انگلستان، 2009; صص 15-26. [ Google Scholar ]
- تیلور، بی. جهان صدف شما با جاوا اسکریپت فعال است. وبلاگ رسمی گوگل در دسترس آنلاین: https://googleblog.blogspot.com/2005/06/world-is-your-javascript-enabled_29.html (در 29 ژوئن 2005 قابل دسترسی است).
- کوهن، دبلیو مقدمه ای بر زیرساخت های داده های مکانی. ارائه در مارس 2005 برگزار شد. در دسترس به صورت آنلاین: https://collaboration.worldbank.org/docs/DOC-3031 (در 1 اوت 2016 قابل دسترسی است).
- Laney, D. مدیریت داده های سه بعدی: کنترل حجم، سرعت و تنوع داده ها . گروه متا: ترنی، ایتالیا، 6 فوریه 2001. [ Google Scholar ]
- لیانگ، SH. هوانگ، سی.-ای. Geocens: یک زیرساخت سایبری مکانی برای شبکه حسگر جهانی. Sensors 2013 , 13 , 13402-13424. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- بوتس، ام. پرسیوال، جی. رید، سی. فعال سازی وب حسگر دیویدسون، J. OGC : نمای کلی و معماری سطح بالا. در شبکه های ژئوسنسور ؛ Springer: برلین، آلمان، 2006; صص 175-190. [ Google Scholar ]
- لیانگ، اس. چن، اس. هوانگ، سی. لی، آر. چانگ، ی. Badger، J. Rezel, R. گرفتن دم دراز شبکه حسگر. در مجموعه مقالات کارگاه بین المللی نقش اطلاعات جغرافیایی داوطلبانه در پیشرفت علم، زوریخ، سوئیس، 14 سپتامبر 2010.
- کریس، ای. دم بلند: چرا آینده کسب و کار فروش کمتری دارد . Hyperion: نیویورک، نیویورک، ایالات متحده آمریکا، 2006. [ Google Scholar ]
- Morais, CD عبارت “80% داده ها جغرافیایی هستند” از کجا آمده است؟ در دسترس آنلاین: https://www.gislounge.com/80-percent-data-is-geographic/ (در 28 دسامبر 2014 قابل دسترسی است).
- سالیوان، دی. موتورهای جستجو و فهرست راهنمای اصلی. در دسترس آنلاین: http://www.leepublicschools.net/Technology/Search-Engines_Directories.pdf (در 1 اوت 2016 قابل دسترسی است).
- هیکس، سی. شفر، ام. نگو، ق. Sheng, QZ کشف و فهرست نویسی منابع وب عمیق. در مجموعه مقالات سیزدهمین کنفرانس بین المللی IEEE در سال 2012 در مورد استفاده مجدد و یکپارچه سازی اطلاعات (IRI)، لاس وگاس، NV، ایالات متحده آمریکا، 8 تا 10 آگوست 2012. ص 224-230.
- دین، جی. Ghemawat، S. Mapreduce: پردازش داده های ساده در خوشه های بزرگ. اشتراک. ACM 2008 ، 51 ، 107-113. [ Google Scholar ] [ CrossRef ]
- میرطاهری، س.م. دینچکتورک، ME; هوشمند، س. بوخمن، جی وی. جردان، جی.- وی. Onut, IV تاریخچه مختصری از خزنده های وب. در مجموعه مقالات کنفرانس 2013 مرکز مطالعات پیشرفته در تحقیقات مشترک، ریورتون، نیوجرسی، ایالات متحده، 18 نوامبر 2013; صص 40-54.
- لوپز-پلیسر، FJ; Rentería-Agualimpia، W.; نوگراس-ایسو، جی. Zarazaga-Soria، FJ; Muro-Medrano، روابط عمومی به سمت فهرست فعال خدمات وب جغرافیایی. در پل زدن علوم اطلاعات جغرافیایی ; Springer: برلین، آلمان، 2012; صص 63-79. [ Google Scholar ]
- بای، ی. یانگ، سی. گوا، ال. Cheng, Q. Opengis wms نمونه اولیه سیستم موتور جستجوی اطلاعات مکانی. در مجموعه مقالات سمپوزیوم بین المللی زمین شناسی و سنجش از دور IEEE 2003، 2003. IGARSS’03، تولوز، فرانسه، 21-25 جولای 2003. صص 3558–3560.
- Li, W. Polarhub: یک مرکز جهانی برای کشف داده های قطبی. در مجموعه مقالات خلاصههای نشست پاییز AGU، سانفرانسیسکو، کالیفرنیا، ایالات متحده آمریکا، 3 تا 7 دسامبر 2014.
- استخوان، سی. آگر، ا. بونزل، ک. Tierney, L. یک موتور جستجوی مکانی برای کشف دادههای مکانی چند قالبی در سراسر وب. بین المللی J. Digital Earth 2014 ، 9 ، 1-16. [ Google Scholar ] [ CrossRef ]
- نمونه، JT; لدنر، آر. شولمن، ال. آیوپ، ای. پتری، اف. وارنر، ای. شاو، کیلوبایت؛ McCreedy، FP تقویت پورتال gidb نیروی دریایی ایالات متحده با خدمات وب. IEEE Internet Computing 2006 ، 10 ، 53-60. [ Google Scholar ] [ CrossRef ]
- چن، ن. Liping Di B, GYB; Chen, Z. خدمات کشف و بازیابی داده های وب سنسور جغرافیایی مبتنی بر میان افزار. 2008. در دسترس آنلاین: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.184.4226 (در تاریخ 1 اوت 2016 قابل دسترسی است).
- لی، دبلیو. یانگ، سی. یانگ، سی. یک خزنده فعال برای کشف خدمات وب جغرافیایی و الگوی توزیع آنها – مطالعه موردی سرویس نقشه وب OGC. بین المللی جی. جئوگر. Inf. علمی 2010 ، 24 ، 1127-1147. [ Google Scholar ] [ CrossRef ]
- لوپز-پلیسر، FJ; بیجار، ر. فلورچیک، ای جی؛ مورو مدرانو، روابط عمومی؛ Zarazaga-Soria، وضعیت FJ خدمات وب OGC در سراسر وب. در مجموعه مقالات کنفرانس INSPIRE، کراکوف، لهستان، 23 تا 25 ژوئن 2010.
- پاتیل، اس. باتاچارجی، اس. Ghosh, SK یک خزنده وب فضایی برای کشف سرورهای جغرافیایی و ارجاع معنایی با ویژگی های فضایی. در مجموعه مقالات کنفرانس بین المللی محاسبات توزیع شده و فناوری اینترنت، Bhubaneswar، هند، 6-9 فوریه 2014. صص 68-78.
- Gibotti، FR; کامارا، جی. Nogueira, RA Geoinfo 2015. در Geodiscover—یک موتور جستجوی تخصصی برای کشف داده های مکانی در وب . GeoInfo: Campos do Jordão، برزیل، 2005; صص 3-14. [ Google Scholar ]
- Bloom، BH فضا/زمان مبادله در کدگذاری هش با خطاهای مجاز. اشتراک. ACM 1970 ، 13 ، 422-426. [ Google Scholar ] [ CrossRef ]
- پیج، ال. برین، اس. متوانی، ر. وینوگراد، تی. رتبه بندی استنادی صفحه رتبه: نظم بخشی به وب. در دسترس آنلاین: http://ilpubs.stanford.edu:8090/422/ (در تاریخ 1 اوت 2016 قابل دسترسی است).
- کلین، نمایندگی SC از رویدادها در شبکه های عصبی و اتوماتای محدود. در دسترس آنلاین: www.dtic.mil/cgi-bin/GetTRDoc?Location=U2&doc=GetTRDoc.pdf&AD=ADA596138 (در 1 اوت 2016 قابل دسترسی است).
- De La Beaujardiere, J. Open GIS ® Web Map Server Interface Implementation Specification. ویرایش 1.0.0. در دسترس آنلاین: http://portal.opengeospatial.org/files/?artifact_id=7196 (در 4 اوت 2016 قابل دسترسی است).
- De La Beaujardiere, J. Open GIS ® Web Map Map Server Implementation. نسخه: 1.3.0. در دسترس آنلاین: http://portal.opengeospatial.org/files/?artifact_id=14416 (در 4 اوت 2016 قابل دسترسی است).
- Na، A. کشیش، M. سنسور خدمات مشاهده. در دسترس آنلاین: http://portal.opengeospatial.org/files/?artifact_id=26667 (در 4 آگوست 2016 قابل دسترسی است).
- برورینگ، آ. استاش، سی. Echterhoff، استاندارد رابط سرویس مشاهده سنسور J. OGC. در دسترس آنلاین: https://portal.opengeospatial.org/files/?artifact_id=47599 (در 4 آگوست 2016 قابل دسترسی است).
- Vretanos، مشخصات پیاده سازی خدمات وب ویژگی PA. در دسترس آنلاین: http://portal.opengeospatial.org/files/?artifact_id=7176 (در 4 اوت 2016 قابل دسترسی است).
- Vretanos، PA Opengis Web Feature Service 2.0 Interface Standard. در دسترس آنلاین: http://portal.opengeospatial.org/files/?artifact_id=39967 (در 4 آگوست 2016 قابل دسترسی است).
- ایوانز، سرویس پوشش وب JD (WCS)، نسخه 1.0. 0 (تصحیح). در دسترس آنلاین: https://portal.opengeospatial.org/files/05-076 (در 4 اوت 2016 قابل دسترسی است).
- وایتساید، ا. ایوانز، استاندارد اجرای سرویس پوشش وب JD (WCS). در دسترس آنلاین: https://portal.opengeospatial.org/files/07-067r5 (در 4 اوت 2016 قابل دسترسی است).
- Baumann, P. OGC WCS 2.0 Interface Standard—Core. کنسرسیوم فضایی باز در دسترس آنلاین: https://portal.opengeospatial.org/files/09-110r4 (در 4 آگوست 2016 قابل دسترسی است).
- ماسو، جی. پوماکیس، ک. جولیا، ن. استاندارد پیادهسازی سرویس نقشه وب سایت GIS. در دسترس آنلاین: http://portal.opengeospatial.org/files/?artifact_id=35326 (در 4 اوت 2016 قابل دسترسی است).
- شوت، پی. Whiteside, A. Open GIS Web Processing Service, OGC Project Document. در دسترس آنلاین: http://portal.opengeospatial.org/files/?artifact_id=24151 (در 4 آگوست 2016 قابل دسترسی است).
- ESRI، U. PaperdJuly، W. ESRI shapefile توضیحات فنی. محاسبه کنید. Stat 1998 , 16 , 370-371. [ Google Scholar ]
- نبرت، دی. وایتساید، ا. Vretanos, P. Open GIS Catalog Services Specification. در دسترس آنلاین: http://portal.opengeospatial.org/files/?artifact_id=20555 (دسترسی در 4 اوت 2016).
- برودر، ا. Mitzenmacher، M. کاربردهای شبکه فیلترهای شکوفه: یک بررسی. ریاضی اینترنتی 2004 ، 1 ، 485-509. [ Google Scholar ] [ CrossRef ]
شکل 1. دم بلند GeoWeb.
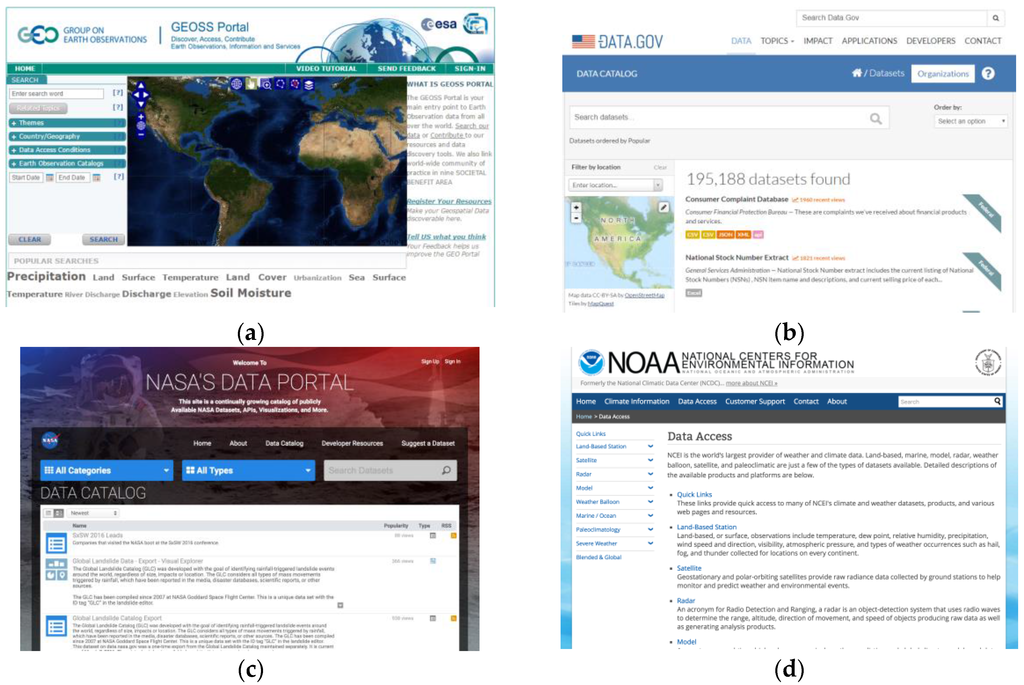
شکل 2. نمونه هایی از پورتال های داده/SDI: ( الف ) سیستم های جهانی رصد زمین (GEOSS). ( ب ) Data.gov; ( ج ) پورتال داده سازمان ملی هوانوردی و فضایی (ناسا). و ( د ) مرکز ملی داده های اقلیمی.
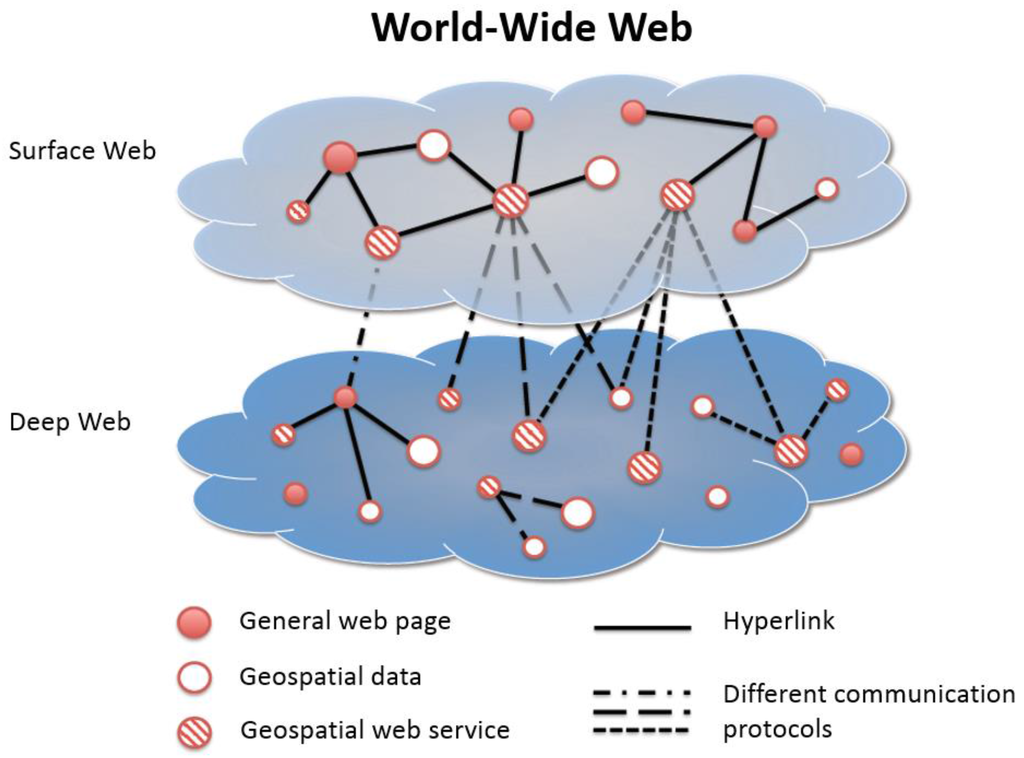
شکل 3. مفهوم سرفیس وب و وب عمیق.
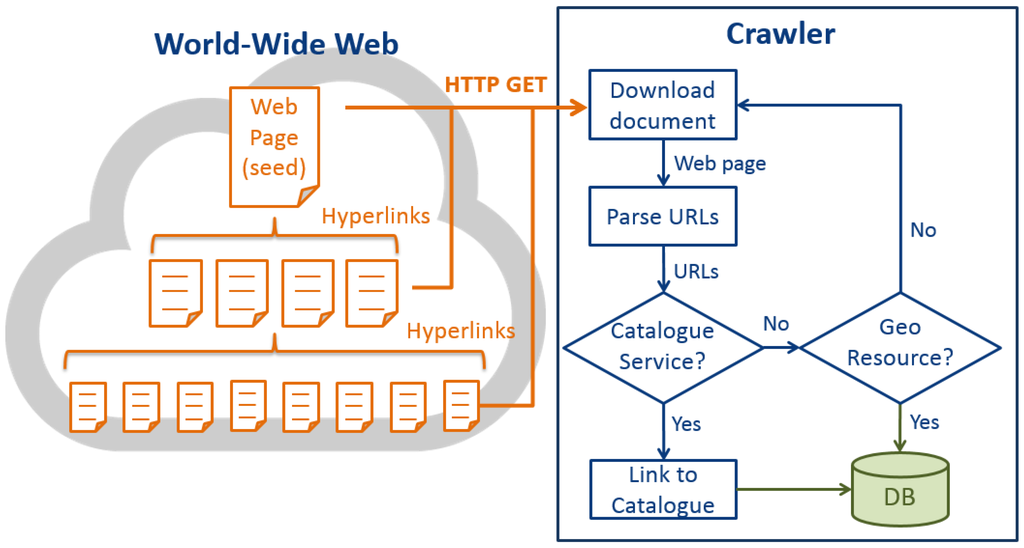
شکل 4. معماری خزنده GeoWeb.

شکل 5. معماری اجرای محاسبات توزیع شده.
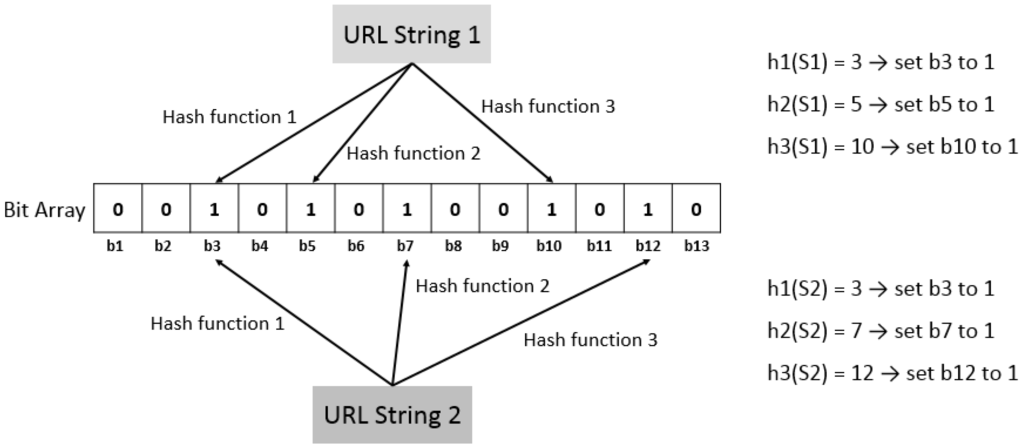
شکل 6. مفهوم فیلتر بلوم.

شکل 7. مقایسه تعداد مجموعه داده ها بین GeoWeb Crawler و رویکردهای موجود.

شکل 8. نمونه ای از جستجوی WMS در GEOSS.
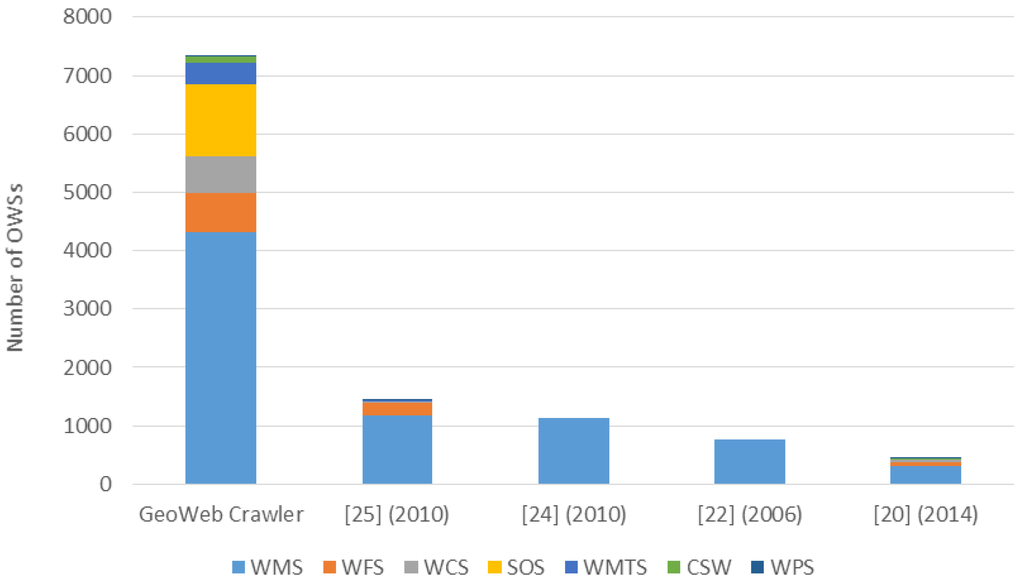
شکل 9. مقایسه تعداد OWS ها بین GeoWeb Crawler و رویکردهای موجود.
شکل 10. تعداد منابع کشف شده در سطوح مختلف خزیدن.
شکل 11. نسبت کشف منابع در سطوح مختلف خزیدن.
شکل 12. مقایسه عملکرد بین پردازش مستقل و موازی.

شکل 13. رابط کاربری GeoHub.

شکل 14. نمونه ای از سند قابلیت های WMS.
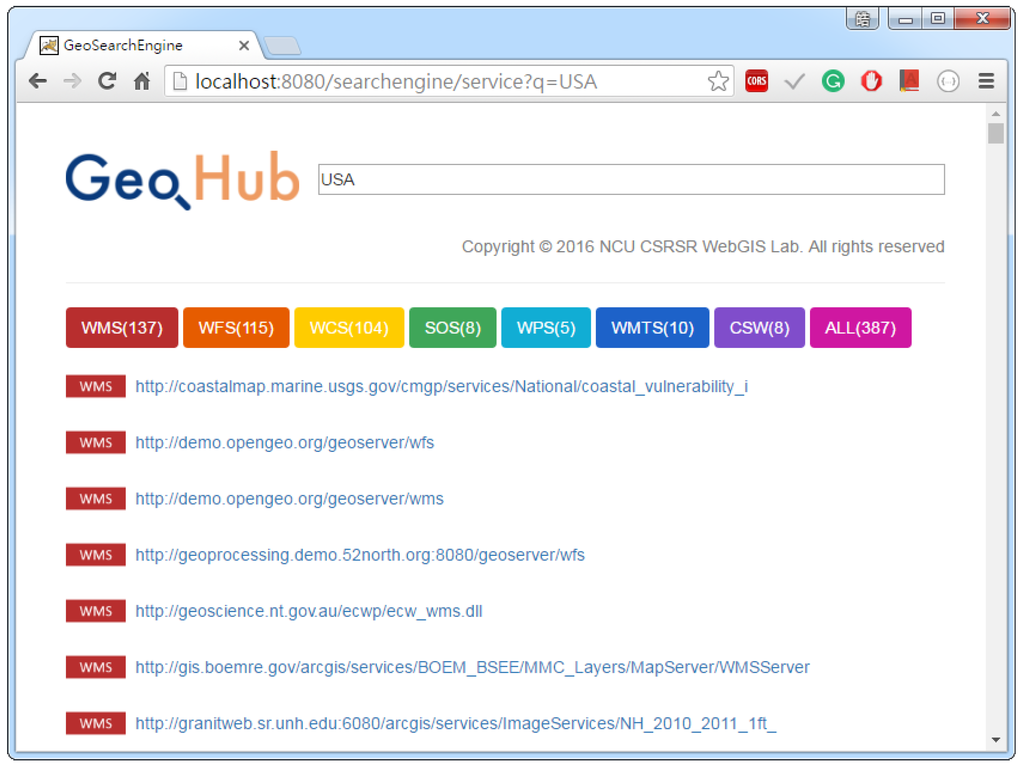
شکل 15. نمونه ای از یک نتیجه جستجوی GeoHub.

جدول 1. دسته های رویکردهای کشف منابع ژئو وب موجود.
جدول 2. اهداف جستجوی منابع GeoWeb.
جدول 3. نتیجه خزیدن GeoWeb.
© 2016 توسط نویسندگان؛ دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (CC-BY) (http://creativecommons.org/licenses/by/4.0/) توزیع شده است
بدون نظر