


چکیده
ربات های کم هزینه با منابع محاسباتی کم و تامین انرژی محدود مشخص می شوند. هدف الگوریتم های برنامه ریزی مسیر یافتن مسیر بهینه بین دو نقطه است تا ربات تا حد ممکن انرژی کمتری مصرف کند. با این حال، این الگوریتمها با توجه به محدودیتهای محاسباتی (به عنوان مثال ، ظرفیت پردازش و حافظه) توسعه نیافتهاند. این مقاله الگوریتم برنامه ریزی مسیر HCTNav (الگوریتم ناوبری گروه تحقیقاتی HCTLab) را ارائه می دهد. این الگوریتم برای اجرا در ربات های کم هزینه برای ناوبری داخلی طراحی شده است. نتایج مقایسه الگوریتمهای HCTNav و Dijkstra نشان میدهد که پیک حافظه HCTNav در نقشههایی با بیش از 150000 سلول، 9 برابر کمتر از Dijkstra است.
کلید واژه ها:
ناوبری داخلی کم هزینه ؛ الگوریتم برنامه ریزی مسیر ; ربات خودمختار
1. مقدمه
کارایی برنامه ریزی مسیر برای مشکل ناوبری ربات مستقل هنوز یک چالش باز در رباتیک است. در دو دهه گذشته، تلاشها برای دستیابی به یک رفتار حرکتی هوشمند، مناسب برای وسایل نقلیه روباتیک، منجر به دو مورد از شناختهشدهترین رویکردها در ادبیات و صنعت شده است: راهحل قطعی، مبتنی بر جستجوی گراف اکتشافی، و روش واکنشی، مبتنی بر. نمونه برداری حسگر محیط [ 1]. هنگام انتخاب بین رویکردهای قبلی، مهم است که بفهمیم کدام عامل عملکرد برای سناریوی مورد واقعی حیاتی است. به عنوان مثال، الگوریتمهای قطعی اجرای بسیار سریع و راهحل بهینه را ارائه میدهند، اگرچه با مقیاسپذیری نقشه جریمه میشوند. از سوی دیگر، الگوریتمهای واکنشی مستقل از مقیاسبندی نقشه هستند و میتوانند تغییرات دینامیکی را مدیریت کنند، اما حداقل راهحل مسیر را تضمین نمیکنند [ 2 ].
الگوریتم Dijkstra [ 3 ] به دلیل استحکام ریاضی آن هنگام برنامه ریزی کوتاه ترین مسیر، مرجع اصلی راه حل های قطعی است. با این وجود، رویکرد Dijkstra دو مشکل شناخته شده را ارائه می دهد: (1) پوشاندن کل مرز جستجو، زمان اجرای الگوریتم را افزایش می دهد و در نتیجه عملکرد سرعت را کاهش می دهد. (2) استفاده از حافظه پویا رشد درجه دوم را نشان می دهد، بنابراین به مقدار زیادی RAM در نمودارهای عظیم نیاز دارد [ 4 ].
برای کاهش “مشکل سربار”، به عنوان مثال ، کاوش غیر ضروری مناطق نقشه که به هدف منتهی نمی شود، بسیاری از نویسندگان با افزودن یک تخمین اکتشافی فاصله باقیمانده تا هدف، مفهوم Dijkstra را بهبود بخشیده اند. این تخمین هنگام انتخاب گره بعدی از مرز جستجو اعمال می شود. این تحولات دایکسترا به عنوان خانواده A* (ستاره A) شناخته میشوند و تا حد زیادی برای حل مشکل برنامهریزی مسیر مورد استفاده قرار میگیرند [ 5 ]. اکتشافی اقلیدسی [ 6 ] از فاصله مستقیم به عنوان تخمین فاصله باقیمانده استفاده می کند، در حالی که اکتشافی منهتن [ 7 ] از مجموع پیش بینی های دکارتی بردار فاصله استفاده می کند. الگوریتمهای Dijkstra یک جستجوی مسیر بهینه را پیادهسازی میکنند [ 8و همیشه کوتاهترین مسیر را برمیگردانند، به همین دلیل است که آنها همچنان در بازار سیستمهای هدایت مسیر (مانند ناوبرهای GPS) [ 9 ]، برنامهریزان لجستیک [ 10 ] و حتی برای ناوبری رباتهای متحرک مستقل [ 11 ] همچنان انتخاب اول را نشان میدهند. , 12 , 13 ].
رویکردهای واکنشی را میتوان با الگوریتمهای نوع Bugs [ 14 ] ارجاع داد که تشخیص مانع مبتنی بر حسی را در طول حرکت به سمت هدف ترکیب میکند. این الگوریتمها در نسخههای مختلف در طول سالها، از VisBug [ 15 ] شروع شدهاند. DistBug [ 16 ] کیفیت مسیر نهایی باگ را با افزودن مجموعه ای از قوانین رسمی برای انتخاب بهترین جهت اطراف مانع و شرایط خروج مناسب در حین دنبال کردن مرز مانع، بهبود بخشیده است.
با ارزش ترین ویژگی برای این خانواده این است که ربات ها می توانند در یک محیط کاملاً ناشناخته حرکت کنند و بر اساس اطلاعات حسگرهای مجاورت (پردازش شده در زمان واقعی) به موانع واکنش نشان دهند [ 17 ]. این به عنوان رویکرد همگرایی محلی [ 18 ] شناخته می شود. علیرغم عملکرد آن، این راه حل حداقل مسیر را تضمین نمی کند (به دلیل حداقل “تله” محلی). در روش مقابل، که به عنوان رویکرد همگرایی جهانی [ 19 ] شناخته می شود، نقشه کاری در یک محدوده جهانی ساخته می شود، بنابراین، از “بن بست ها” اجتناب می شود و یک مسیر بهتر (اما نه حداقلی) ارائه می شود، هرچند با هزینه ای بیشتر. استفاده از منابع داخلی
در این کار ما الگوریتم خودمان را برای ناوبری ربات های داخلی به نام HCTNav (الگوریتم ناوبری گروه تحقیقاتی HCTLab) ارائه می کنیم. هدف اصلی الگوریتم یافتن یک مسیر موثر بین دو سلول در نقشه باینری داده شده، در صورت وجود، است. مانند ماتریس اشغال-شبکه مورد بحث در González-Arjona و همکاران. [ 20 ]. با توجه به الزامات عملکرد، اهداف این تحقیق (1) افزایش مقیاس پذیری در نقشه های بزرگتر با کنترل استفاده از حافظه پویا در زمان اجرا و (2) اعطای زمان اجرا قابل قبول است. ما HCTNav را به عنوان یک الگوریتم ترکیبی تصور کردیم که تکنیکهای جستجوی نمودار خانواده قطعی را با قوانین منطقی یک الگوریتم واکنشی ترکیب میکند.
ساختار مقاله به شرح زیر است: بخش 2 مدل محیطی و قوانین ناوبری منطقی را شرح می دهد. آنها مبنای بحث الگوریتم در بخش 3 هستند که بر جریان اجرای HCTNav و ساخت مسیر نهایی تمرکز دارد. نتایج تجربی و مقایسه با راهحلهای پیشرفته در بخش 4 مورد بحث قرار میگیرد و پس از آن یک نتیجهگیری کوتاه ارائه میشود.
2. محیط و مدل سیستم
مدل محیطی HCTNav به صورت یک نقشه دو بعدی شکل گرفته است. حرکت ربات هولونومیک است و از آنجایی که به مناطق داخلی محدود می شود، زمین را همیشه افقی فرض می کنیم. بنابراین سناریوی ما در مدلسازی دوبعدی که معمولاً در بازیهای ویدیویی استراتژی زمان واقعی استفاده میشود، قرار میگیرد [ 21 ]. زمین با شبکه ای از سلول های یکنواخت نشان داده می شود و محدوده حرکت به پرش های معتبر (بدون مانع در مسیر) از یک سلول به سلول دیگر محدود می شود. با پیروی از این اصول، نقشه ناوبری را می توان به یک ماتریس منطقی با ورودی های دامنه بولی کاهش داد ( B := [0,1]). هر سلول با مختصاتش مشخص می شود ( x,y) در ماتریس. وضعیت سلول در ورودی مربوطه ذخیره می شود: یک ‘0’ منطقی بیان می کند که سلول آزاد است، در حالی که ‘1’ نشان دهنده یک سلول مسدود شده است.
سلول با اندازه ربات تعریف می شود و ربات همیشه خود را در مرکز هندسی سلول قرار می دهد. بنابراین، هر سلول نیمه اشغالی یک سلول مسدود در نظر گرفته می شود. مختصات کاشی ها به حوزه اعداد طبیعی تعلق دارند ( N := {0, 1, 2, …} و در محدوده های x ∈ [0, c − 1], y ∈ [0, r − 1] قرار دارند که در آن c تعداد ستونها و r تعداد ردیفها را نشان میدهد. مرجع مبدا O ( x, y ) است که در گوشه سمت چپ بالا ثابت است ( شکل 1 را ببینید ).
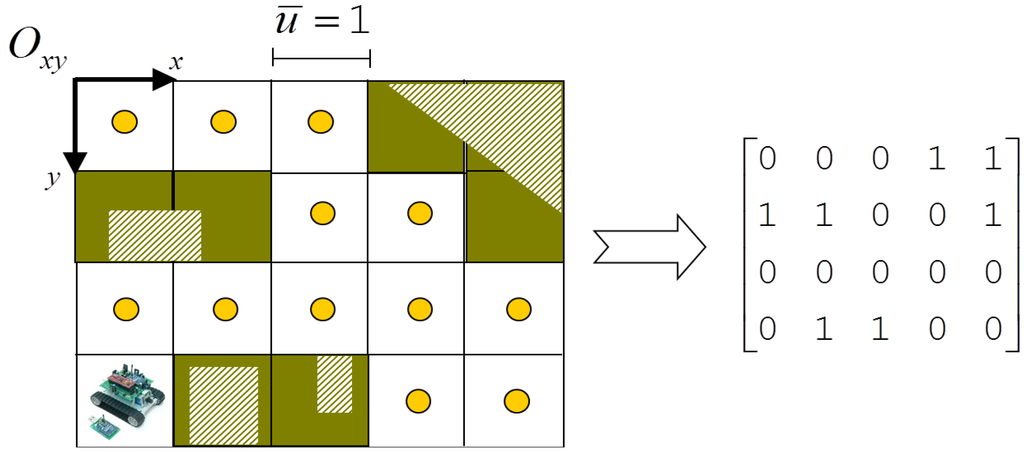
شکل 1. معادل سازی بین یک نقشه دو بعدی و مدل ماتریس باینری متناظر آن. ناحیه نوارهای مورب اشکال واقعی مانع را به تصویر میکشد، در حالی که کاشیهای تیره سلولهای مسدود شده مربوطه هستند. دایره ها نشان دهنده تمام مختصات ممکنی است که ربات ممکن است در نقشه اشغال کند.
بنابراین، ساختار داده ناوبری حاصل تنها مجموعه گره اولیه گراف V := { n i } را نشان می دهد که سلول های آزاد در شبکه دو بعدی را پوشش می دهد. یکی دیگر از انتزاعات مورد نیاز، عادی سازی واحد اندازه گیری نقشه برای ساده کردن نماد ریاضی است. در این مقاله ما یک سلول را به عنوان یک مربع واحد فرض می کنیم ( l ≡ u = 1).
3. الگوریتم HCTNav
در این بخش، پردازش الگوریتم خود را با توضیح چهار ماژول اصلی که سیستم برنامه ریزی حرکتی ربات را تشکیل می دهند، مورد بحث قرار می دهیم.
با توجه به هدفمان، ما از مجموعه ای از قوانین ناوبری منطقی الهام گرفته از استراتژی جنبش خانواده باگ شروع کردیم. يعنى: سعى كنيد مستقيم به سوى هدف برويد و در صورتى كه مانعى در راه وجود داشت، سعى كنيد آنها را احاطه كنيد. رویکرد Bug جهت اطراف را انتخاب می کند که ممکن است بهینه نباشد. همانطور که HCTNav قبل از حرکت ربات اجرا میشود، میتوانیم در هر دو جهت زیر مرزی کاوش کنیم. این روش درختی از مسیرهای ممکن از مبدا تا مقصد ایجاد می کند. هر مسیری بهینه میشود و زمانی که بیش از یک مسیر پیدا شد کوتاهترین مسیر برگردانده میشود.
الگوریتم به چهار ماژول اصلی تقسیم شده است که هر کدام وظیفه خاصی را انجام می دهند. ماژول اول تشخیص مانع را در یک مسیر مستقیم مشخص اجرا می کند ( بخش 3.1 ). مورد دوم، کاشی میانی را که نقطه عطف نامیده می شود ، در مجاورت مانع شناسایی شده که برای شروع اطراف مانع استفاده می شود، تعریف می کند ( بخش 3.2 ). ماژول سوم موانع اطراف را حل می کند ( زیر بخش 3.3 ). در نهایت، هدف چهارم بهینهسازی در نمودار ناوبری خام (با هرس کردن لبههای اضافی) است و معیار انتخاب بهترین مسیر را بیان میکند ( بخش 3.4 ).). ساختار داده اولیه الگوریتم متشکل از عناصری است که نقشه داده شده را مدل می کند و امکان ذخیره ویژگی های سلول مورد نیاز را فراهم می کند. تا زمانی که HCTNav لیست نقطه عطف را به روز می کند و به صورت پویا یال های میانی را می سازد، ساختار یکسان در سراسر اجرا تغییر می کند.
3.1. تشخیص مانع
با توجه به دو گره عمومی Node [ i ] و Node [ j ] در نقشه، اولین ماژول بررسی می کند که آیا مسیر مستقیم بین آنها بدون مانع است یا خیر. اگر یک یا چند مانع در طول مسیر پیدا شود، آنگاه مانعی که اولین برخورد «در دید» را از دید ربات نشان میدهد، برگردانده میشود.
خط سیر ربات را می توان به عنوان یک “راهرو” مدل سازی کرد که عرض جلوی ربات را از نقطه شروع به پایان می رساند. در اینجا هدف بررسی تمام کاشی های متعلق به راهرو برای جلوگیری از برخوردهای احتمالی است ( تشخیص مانع ارسال شده ).
برای هر سلول به راهرو، HCTNav تمام کاشی های مسدود شده را بررسی و علامت گذاری می کند ( مانع [ k ]) و نزدیک ترین آنها را به موقعیت فعلی پیدا می کند. همانطور که گفته شد، ما فواصل مربع از گره [ i ] فعلی تا مانع [ k ] را به صورت d 2 ( i, k ) = ( x i − x k ) 2 + ( y i − y k ) 2 در نظر می گیریم ، بنابراین از ریشه های مربع ماژول مانع k مانند d 2 را برمی گرداند( i, k* ) = min k { d 2 ( i, k )} که نشان دهنده اولین برخورد احتمالی شناسایی شده در طول مسیر است.
برای پیاده سازی این ویژگی در الگوریتم HCTNav باید هر سلولی که ممکن است در مسیر ربات اشغال شده باشد را تعریف کرد. با توجه به اینکه محاسبات ممیز شناور برای روباتهای کمهزینه نیازمند سختافزار هستند، ما نه از تکنیکهای مثلثاتی استفاده میکنیم و نه سیستمهای معادلات خطی را حل میکنیم. بقیه عملیات حسابی فقط جمع، تفریق و ضرب هستند. الگوریتم خط برزنهام [ 22] برای ترسیم خطوط در مانیتورهای صفحه با استفاده از جمع و تفریق برای جلوگیری از الزامات ممیز شناور در گرافیک کامپیوتری اولیه ایجاد شد. در روباتهای کمهزینه همین محدودیت ایجاد میشود و راهحل مشابهی نیز معتبر است. الگوریتم برزنهام پیکسل هایی (معادل سلول های نقشه) را که با خطی بین دو موقعیت مطابقت دارند تعریف می کند. اطلاعات بازگردانده شده لیست سلول هایی خواهد بود که برای وجود موانع بررسی می شوند.
مشکل اصلی در کار اسکن کل مسیر این است که یک خط برسنهام (از این پس، خط B ) تمام سلول های متعلق به راهرو را پوشش نمی دهد ( شکل 2 را ببینید ). از این رو، لازم است مجموعهای از خطوط B را با در نظر گرفتن شیبهای مختلف ( m∈ [0, 2 π ]) و جفتهای شروع پایان برای هر خط منفرد تعریف کنیم. با در نظر گرفتن این دو شرط، راهرو ممکن است به 1 تا 6 خط B به شرح زیر نیاز داشته باشد:
-
B-خطوط داخلی : با استفاده از ربع اول شکل 3 ، دو خط B از سلول [ i ] به سلول [ j ]، علامت شرط را تغییر میدهند (به زیر مراجعه کنید).
-
خطوط B خارجی سطح اول : با استفاده از ربع اول از شکل 3 ، دو خط B از سلول x+1 [ i ] به سلول y-1 [ j ] و از سلول y+1 [ i ] به سلول x −1 [ j ].
-
خطوط B خارجی سطح دوم : با استفاده از ربع 1 از شکل 3 ، دو خط B از سلول x+2 [ i ] به سلول y-1 [ j ] و از سلول y+1 [ i ] به سلول x −2 [ j ].
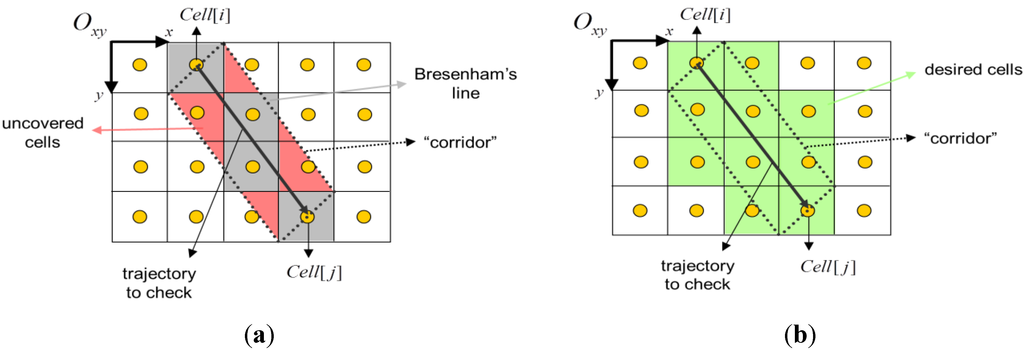
شکل 2. سناریوی تشخیص مانع: ( الف ) سلولهای بیخط و بدون پوشش. ( ب ) تمام سلول های متعلق به راهرو.
شکل 3 ویژگی های مجموعه خطوط B و طرح تحلیلی آن را از سر می گیرد، در حالی که در شکل 4 ما نتیجه ادغام خطوط را ارائه می دهیم. بسته به شرایطی که در الگوریتم برسنهام استفاده می شود، یعنی بزرگتر یا بزرگتر از ، دو خط B داخلی فقط با یک کاشی متفاوت خواهند بود ( سلول [68] و سلول [83] در شکل 4 الف). در مورد خط سیر ±90 درجه یا 45± درجه، آنها با یکدیگر همپوشانی دارند و توصیه می شود فقط از یک خط B داخلی استفاده کنید. کل جریان اجرای تشخیص مانع در کد 1 به تفصیل آمده است.
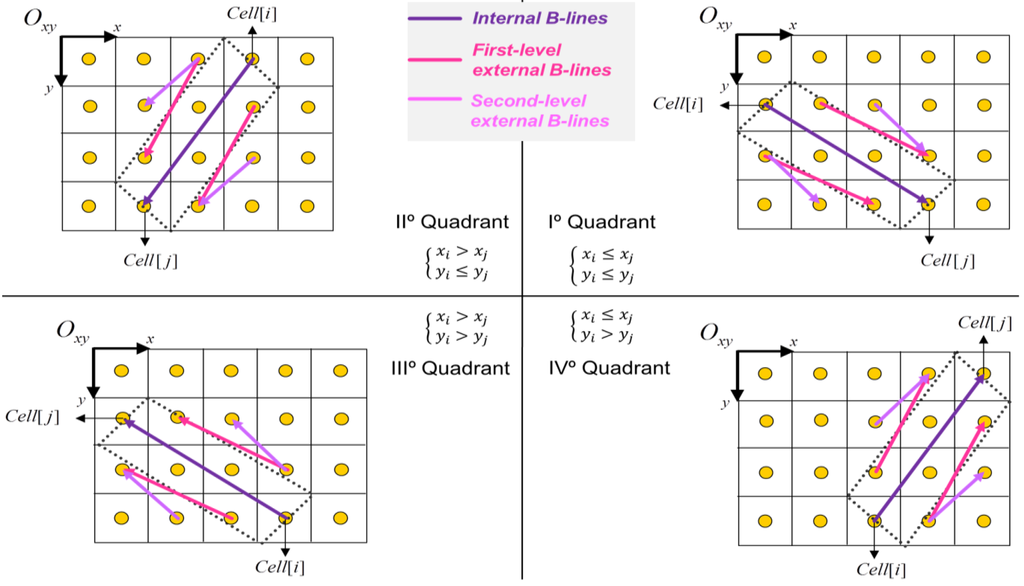
شکل 3. تعریف خطوط برزنهام در چهار ربع.
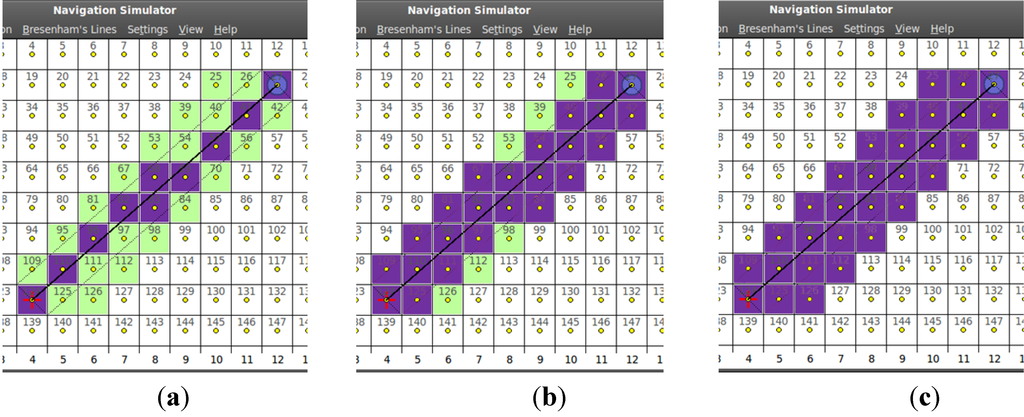
شکل 4. سه سطح پوشش مجموعه خطوط B. ( الف ) راهرو و سلولهای پوشیده شده توسط خطوط B داخلی. ( ب ) سلول های اضافی که توسط خطوط B خارجی سطح اول پوشانده شده اند. ( ج ) راهروی کامل تحت پوشش خطوط B خارجی سطح دوم.

کد 1. شبه دستورالعمل های تشخیص مانع.
3.2. انتخاب نقطه عطف بعدی
ماژول انتخاب نقطه عطف، با شروع از برخورد شناسایی شده قبلی (نقطه ضربه در شکل 5 را ببینید )، به ربات اجازه می دهد تا کاشی مناسب را مستقیماً در مقابل مانع فعلی انتخاب کند. با پیروی از کوتاه ترین اصول جستجوی مسیر، ماژول انتخاب نقطه عطف نزدیکترین سلول را از موقعیت فعلی برمی گرداند. سپس یک یال جدید که نشان دهنده پرش متوسط بعدی است به نمودار ناوبری افزایشی اضافه می شود.
با توجه به مانع [ k* ]، استراتژی ما این است که چهار کاشی متعامد ممکن ( سلول [ c ]) مجاور آن (شرق، جنوب، غرب و شمال در شکل 5 ) را در نظر بگیریم. الگوریتم چهار نامزد را ارزیابی میکند و فهرستی از شرایط را بررسی میکند که اعتبار هر نامزد را برای انتخاب تأیید میکند:
-
شرط-1: کاشی کانتور مانع.
-
شرط-2: کاشی ورودی و آزاد.
-
شرط-3: بازدید نشده و به عنوان نقطه عطف علامت گذاری نشده است.
-
شرط-4: مسیر بدون مانع (از موقعیت فعلی).
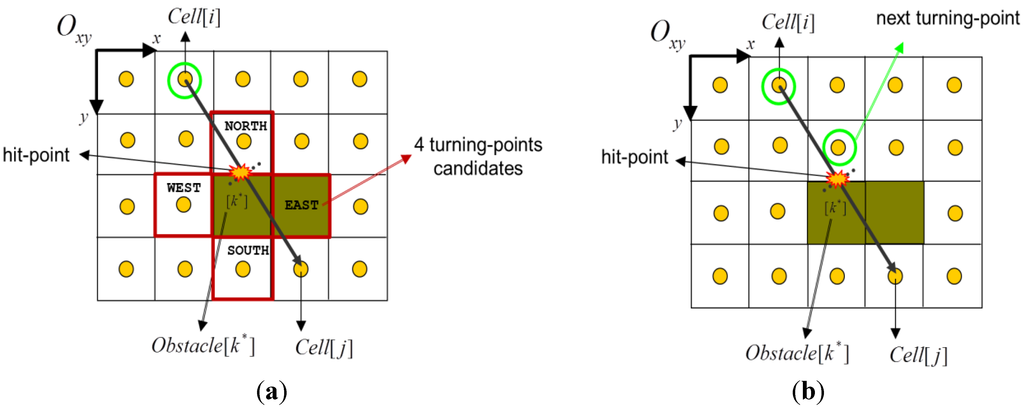
شکل 5. طرح انتخاب برای نقطه عطف بعدی: ( الف ) چهار نامزد اصلی احتمالی؛ ( ب ) گره بازگردانده شده توسط ماژول.
هنگامی که سلول های نامعتبر از لیست کاندید حذف شدند، الگوریتم با تنظیم پرچم “نقطه عطف” گره [ c* ] را مانند d 2 (i, c*) = min c {d 2 (i, c * ) } علامت گذاری می کند. گره [ c* ] نشان دهنده کوتاه ترین (متوسط) پرش از گره [ i ] فعلی به سمت هدف است و همچنین سلولی است که از آنجا شروع به احاطه کردن مانع پیشرو [ k* ] می کند. در این زمان، نقطه عطف جدید [ c*] در یک لیست نقطه عطف ثبت می شود و آماده پردازش در یک تکرار جدید است. دستورالعمل های پیاده سازی این ماژول در کد 2 ارائه شده است. بسته به خروجی انتخاب نقطه عطف، الگوریتم HCTNav بین یکی از این سه حالت سوئیچ می کند:
- 1)
-
اگر هیچ نامزد معتبری برگردانده نشد، یک بن بست شناسایی می شود (هیچ لبه جدیدی ایجاد نمی شود).
- 2)
-
اگر گره نقطه عطف جدید [ c* ] با موقعیت فعلی گره [ i ] متفاوت باشد، یک یال جدید به گراف مسیر اختصاص داده می شود. لبه اشاره گر [ c* ← i ] ذخیره می شود و وزن آن w با فاصله مستقیم بین مراکز سلول [ i ] و سلول [ c* ] مقداردهی اولیه می شود.
- 3)
-
اگر نقطه عطف با موقعیت فعلی مطابقت داشته باشد، HCTNav مانع را احاطه می کند (بخش بعدی را ببینید).
کد 2. شبه دستورالعمل های انتخاب نقطه عطف.
3.3. مانع جریان اطراف
با شروع از نقطه عطف جدید، HCTNav می تواند دو جایگزین اطراف را برای جلوگیری از مانع روبرو در نقشه تعیین کند. در سرتاسر ماژول سوم مسیر “تقسیم” می شود و نمودار ناوبری شروع به رشد می کند. در نتیجه مرز مانع به دنبال لیستی از نقاط عطف جدید، که نمایانگر کاشی های گوشه است (به عنوان مثال ، انحراف مسیر 90 درجه)، برگردانده می شود تا بعداً پردازش شود.
برای حل مشکل موانع اطراف، لازم است اطلاعاتی در مورد وضعیت خطوط کاشی بدانیم. به همین دلیل است که ما پرچم “contour” را در ویژگی های Node [ i ] معرفی کردیم. در طول اولیه سازی الگوریتم، نقشه از قبل پردازش می شود و برای هر کاشی کانتور لیستی از همسایگان کانتور مجاور ایجاد می کند (از این به بعد ContourList i ).
این باعث میشود که در طول زمان اجرا، زمانی که مانع اطراف شروع میشود، یک نقطه عطف از یک یا چند جهش بعدی که از آنها شروع به باز کردن مسیر فعلی در شاخههای ناوبری مختلف میکنند آگاه باشد. از این رو، با شروع از ContourList i اولیه TurningPoint [ i ] ، همسایه های کانتور ( Node [ b ]) به صورت بازگشتی بازدید و به لیست اضافه می شوند. همانند روش فیلتر کردن مورد استفاده در ماژول دوم (به بخش 3.2 مراجعه کنید )، افزونگی ها را می توان از اجرای بررسی شرایط مشابه حذف کرد، به جز مورد سوم:
-
شرط-3: نه موقعیت فعلی و نه در لیست خطوط اولیه.
کد 3. موانع اطراف شبه کد.
شرط دوم افزونگی های اطراف ناشی از تقارن های لیست همسایگان کانتور را محدود می کند، در حالی که شرط چهارم بررسی می کند که گره جدید [ b’ ] قابل دسترسی است (با استفاده از ماژول اول HCTNav برای بررسی راهرو). در غیر این صورت، اگر راه بازگشت به موقعیت اولیه مسدود شود، گوشه ای تشخیص داده می شود و شاخه اکتشاف مربوطه به پایان می رسد. گره [ b ] به عنوان نقطه عطف علامت گذاری شده و به لیست خروجی فشار داده می شود، که از تمام نقاط عطف کشف شده در طول فاز اطراف تشکیل شده است. HCTNavاین فهرست جزئی را به لیست نقطه عطف اصلی اضافه می کند و سپس الگوریتم را به تکرار بعدی ادامه می دهد. این ماژول از دو حلقه تشکیل شده است: یک حلقه خارجی، برای پردازش لیست کانتور نقطه عطف فعلی، و یک حلقه داخلی، برای کاوش بازگشتی همسایگان به ارث رسیده. شبه دستورالعمل های ماژول سوم در کد 3 نشان داده شده است. همانطور که مشاهده می شود، در حلقه خارجی نیز لازم است بررسی شود که آیا راه رسیدن به هدف بدون مانع است یا خیر. این مورد نقطه عطف یافت شده هدف (آخرین پرش قبل از گل) است.
3.4. ساختن مسیر نهایی
سه ماژول اصلی که در بخشهای فرعی قبلی توضیح داده شد، امکان کشف مجموعهای از نقاط عطف را میدهند که تقریباً در همه تکرارها بازخورد داده میشوند (به جز زمانی که هیچ نامزد معتبری در دسترس نباشد).
ماژول دو نقطه عطف بعدی را برمی گرداند، در حالی که ماژول سه سلول های گوشه کشف شده در اطراف را برمی گرداند. هنگامی که یک نقطه عطف علامت گذاری می شود، یک یال جدید که نشان دهنده پرش از موقعیت فعلی است ساخته می شود و سپس به نمودار مسیر اضافه می شود که به تدریج رشد می کند. الگوریتم زمانی به پایان می رسد که هیچ نقطه عطف دیگری در لیست نقاط عطف اصلی موجود نباشد، حتی اگر هدف پیدا نشود (این مورد در مسیری است که راه حلی ندارد).
هر نقطه عطفی دقیقاً یک یال را مشخص می کند و با آن مشخص می شود، به جز منبع (نه با هیچ لبه ای) و هدف (می توان با بیش از یک یال اشاره کرد). از این رو، بازسازی درخت مسیر به عقب راحت است، زیرا هدف تعداد دقیق مسیرهای ممکن را شناسایی می کند، بنابراین از ایجاد حلقه بین آنها جلوگیری می کند. نمودار مسیر خام P := { T, E } توسط لیست نقاط عطف T و یال های مجموعه E تعریف می شود ، مانند:

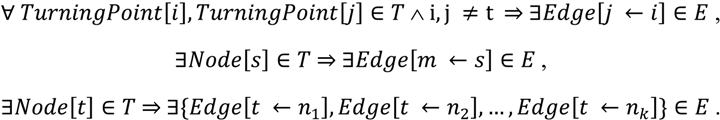
برای حذف افزونگیها در نمودار مسیر، به دلیل تعمیم قوانین ناوبری، ما یک پردازش پسپردازی ایجاد کردیم که لبهها را فیلتر میکند، از گره هدف شروع میشود و تا رسیدن به گره منبع به عقب ادامه میدهد.
در نتیجه، یک درخت مسیر برای انتخاب کوتاه ترین مسیر در دسترس است. در شکل 6 یک سناریوی شبیه سازی برای درک بهتر منطق های HCTNav و پردازش پس از آن تجزیه می شود: با توجه به موقعیت منبع، گره [89] در موقعیت (0، 9)، و نقطه هدف، گره [39] در (8) ، 3)، نمودار مسیر خام ابتدا ساخته می شود ( شکل 6 ب). تعداد مسیرهای ممکن (دو) دقیقاً مطابق با لبه هایی است که به گره هدف اشاره می کنند.
از این رو، فیلتر کردن در Node [39] آغاز می شود و از طریق Edge [39 ← 36] و Edge [39 ← 79] تقسیم می شود. این دو شاخه با شکاف مسیر اصلی در نقطه عطف [73] مطابقت دارند. افزونگیهایی که میتوانند رخ دهند را میتوان در دو دسته طبقهبندی کرد: (1) لبههای زائد ، زمانی که سه نقطه عطف یک انحراف غیرضروری را تشکیل میدهند که میتواند با یک یال مستقیم جایگزین شود، و (2) لبههای درون خطی ، زمانی که سه یا چند نقطه عطف در همان جهت دراز بکشید

شکل 6. مطالعه موردی کامل HCTNav : ( الف ) سناریوی نقشه اولیه. ( ب ) نمودار مسیر خام ایجاد شده. ( ج ) درخت مسیر بهینه شده. ( د ) کوتاهترین مسیر برگشته.
پس از پایان فرآیند بهینهسازی ( شکل 6 ج)، درخت مسیر آماده است: لبههای «لبههای زائد» Edge [58 ← 67] و Edge [67 ← 73] هرس شده و با لبه جدید [58 ← 73] جایگزین شدهاند. بنابراین گوشه در گره [67] حذف می شود). مانند Edge [74 ← 67] و Edge [67 ← 73] که با Edge [74 ← 73] جایگزین شده است، و برای Edge [36 ← 60] و Edge [60 ← 58]، هرس شده و با Edge [36 ← ] جایگزین شده است . 58] «لبههای درون خطی» Edge [79 ← 77]، Edge [77 ← 75]، Edge [75 ← 74] و Edge[74 ← 73] نرمال می شوند (با حذف نقطه عطف [77]، نقطه عطف [75]، نقطه عطف [74]) و با لبه مستقیم [79 ← 73] جایگزین می شوند .
یک مسیر نهایی F k توسط دنباله مرتب لبه هایی که از گره مبدا به گره هدف منتهی می شود، تعریف می شود. در طول بهینه سازی، برای هر مسیر F k ، فاصله تجمعی W k نیز به عنوان مجموع تمام یال ها در دنباله محاسبه می شود. هنگامی که درخت مسیر تکمیل شد، HCTNav به پایان می رسد ( شکل 6 د) و کوتاه ترین مسیر را در درخت بهینه شده برمی گرداند. تعاریف رسمی برای ساختار درخت مسیر G* ≔ { T* , E* } در رابطه (2) ارائه شده است.
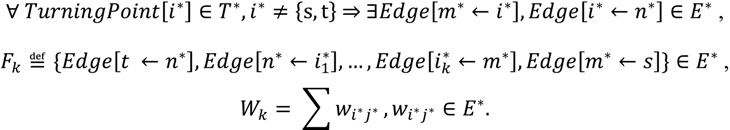
4. بخش تجربی
در این بخش مقایسهای بین الگوریتم ما و دو خانواده اصلی ارائه میشود که نشاندهنده پیشرفتهترین رویکردهای قطعی و واکنشی هستند (در مقدمه این کار بحث شده است). ابتدا، مروری کوتاه بر محیط توسعه ما داده خواهد شد تا روششناسی و ابزارهای آزمایشی ما را توصیف کنیم ( بخش 4.1 ). دوم، نتایج تجربی روی مجموعه آزمایشی نقشه مورد بحث قرار میگیرد و مستقیماً با الگوریتم Dijkstra و نسخههای اکتشافی آن مقایسه میشود (( زیر بخش 4.2 )). در نهایت، یک تجزیه و تحلیل کیفی، پیشرفتهای HCTNav را با توجه به راهحلهای Dijkstra و DistBug نشان میدهد ( بخش 4.3 ).
4.1. نیمکت آزمون
مجموعه آزمایشی نقشه ما ویژگیهای مدل مورد بحث در بخش 2 را دارد: هر نقشه یک ماتریس باینری با 15 ستون و 10 ردیف است که در مجموع 150 کاشی را شامل میشود. ما نمایههای موانع بیش از 30 نقشه را به منظور پوشش دادن مجموعهای از توپولوژیها، از نقشههای واقعیتر داخلی گرفته تا نقشههای بدترین حالتهای غیر محتمل، ترکیب کردیم ( شکل 7 دو نقشه از مجموعه آزمایشی ما را نشان میدهد که در آینده مورد استفاده قرار خواهند گرفت. بخش فرعی برای اهداف تجزیه و تحلیل مقیاس پذیری). مجموعه آزمایشی به عنوان مواد اضافی ارائه شده است.
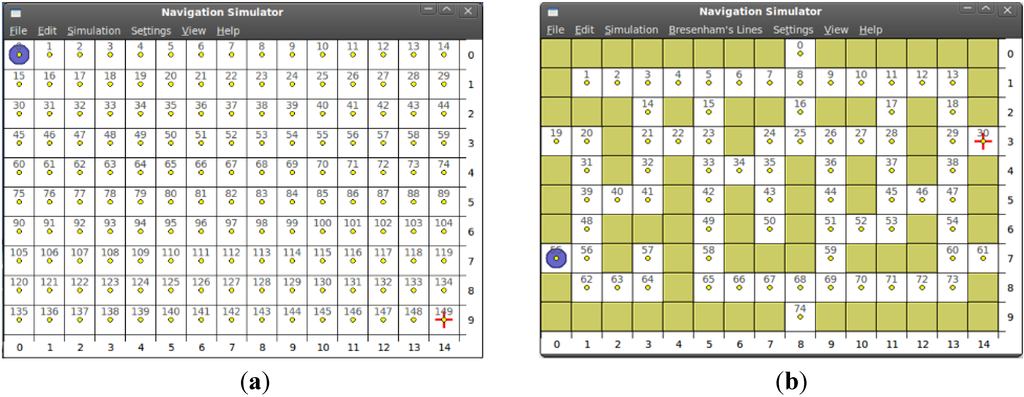
شکل 7. دو نمونه از مجموعه آزمایشی نقشه، طراحی شده توسط تیم HCTLab: ( الف ) یک نقشه “بدون مانع” ( نقشه-01 ). ( ب ) نقشه “لابیرنت” ( نقشه-13 ).
آخرین مورد به ما کمک کرد تا ماژول های الگوریتم را تحت فشار قرار دهیم و گلوگاه های بالقوه را در طول جریان اجرا کشف کنیم. ما همچنین نسخههای بزرگتری از نقشهها را برای مطالعه بهتر مقیاسپذیری الگوریتم خود و مقایسه آن با Dijkstra ایجاد کردیم. دو نوع مقیاس بندی تعریف شده است: (1) توپولوژی محافظه کارانه ، با حفظ نسبت ابعاد نمایه موانع، و (2) توپولوژی تکراری ، با تکرار توپولوژی نقشه به تعداد معین. عوامل پوستهگذاری از الگوی 2 توانی (رشد نمایی) پیروی میکنند: ×2، ×4، ×8، ×16، ×32.
4.1.1. پیاده سازی الگوریتم ها
کد تمام الگوریتم های آزمایش شده ( HCTNav ، Dijkstra، A* با استفاده از اکتشافی اقلیدسی) به زبان ANSI-C پیاده سازی شده است. پیاده سازی A* از دستورالعمل های نشان داده شده در [ 5 ] پیروی می کند. نمودار A* با استفاده از اتصال 8 شبکه ای ایجاد می شود که ادعا می کند لبه های مورب از برخورد جلوگیری می کنند. از این رو، نمودار تولید شده هنگام ایجاد نمودار، عرض ربات را در نظر می گیرد. این اتصال به این دلیل انتخاب شد که در ناوبری مبتنی بر نقشه شبکه داخلی، گسترده ترین است. اتصال بزرگتر منجر به نمودارهای بزرگتر می شود که به حافظه بیشتری نیاز دارند و در نتیجه مقایسه را جریمه می کند. خط مشی تساوی برای A* به طور تصادفی یک گره را از لیست گره های بالای f-value انتخاب می کند. در نهایت، مسیر بهدستآمده توسط Dijkstra و A* با استفاده از ماژول هرس مورد بحث در بهینهسازی میشودزیربخش 3.4 .
نسخه خط فرمان الگوریتم ها امکان مطالعه بهتر استفاده از حافظه پویا در زمان اجرا را بدون کتابخانه های گرافیکی و تخصیص حافظه فریمورک فراهم می کند. علاوه بر این، امکان راه اندازی جستجوهای فشرده نقشه را فراهم می کند و مسیر را برای همه جفت گره های ممکن در همه نقشه های ممکن از یک مجموعه مشخص محاسبه می کند. هر جستجوی مسیر منفرد، اجرای اتمی الگوریتم داده شده را نشان می دهد. برای نمونهبرداری از حافظه پویا، ما به برنامه Valgrind 3.8 (به http://valgrind.org مراجعه کنید ) و ابزار Massif-msprint آن اعتماد کردیم . خروجی تولید شده توسط این پروفایلر حافظه حاوی رکورد کامل تخصیص RAM مانند mallocs و callocs است.
4.2. نتایج شبیه سازی
در این بخش داده های تجربی HCTNav ارائه شده و به طور مستقیم با خانواده Dijkstra مقایسه می شود. چهار معیار مقایسه عبارتند از: (1) استفاده از حافظه پویا، (2) مقیاس پذیری در تغییر اندازه نقشه، (3) زمان اجرا، و (4) طول مسیر.
4.2.1. استفاده از حافظه پویا
همانطور که در مقدمه ذکر شد، هدف اصلی HCTNav به حداقل رساندن استفاده از حافظه برای کاهش هزینه های طراحی ربات است. بنابراین، چیزی که ما به آن علاقه مندیم، “اوج حافظه در زمان اجرا” است، زیرا حداقل نیاز به حافظه کران بالایی را نشان می دهد که در سیستم های کم هزینه حیاتی است. تخمین استفاده از حافظه استاتیک آسان تر است، زیرا با فایل های اجرایی و داده های استاتیک آن که در ریزپردازنده اجرا می شوند نشان داده می شود. در پیادهسازی خودمان، الگوریتمهای Dijkstra حدود 73.7 کیلوبایت را اشغال میکنند، در حالی که HCTNav 10٪ بیشتر است (حدود 81.1 کیلوبایت). برای هر نقشه در مجموعه آزمایشی، ما حافظه پویا مورد نیاز برای حل هر مسیر ممکن، گرفتن نمونه تخصیص حداکثر حافظه، یا “پیک” را در هر جستجو اندازه گیری کردیم (∀ i, j: i ≠ j → peak( i، j )).
در طول تجزیه و تحلیل خانواده Dijkstra دریافتیم که استفاده از حافظه پویا برای همه نسخهها (Dijkstra و Euclidean) یکسان است. این بدان معناست که بهبود اکتشافی خانواده A* فقط مشکل سربار را کاهش میدهد و زمان اجرا را افزایش میدهد، اما واقعاً تأثیری بر استفاده از حافظه ندارد.
مؤلفه اصلی تخصیص حافظه Dijkstra در طول مقداردهی اولیه رشد می کند و با فاز ساخت نمودار و ذخیره آن مطابقت دارد.
در شکل 8 مقایسه مستقیمی بین نیازهای حافظه HCTNav و Dijkstra در زمان اجرا (پیک های حافظه) ارائه می کنیم. در سمت چپ نمودار، جایی که نقشهها نرخ کاشیهای آزاد بیشتری دارند، الگوریتم ما مزیت قابلتوجهی را نشان میدهد، در حالی که Dijkstra به فضای حافظه بیشتری نیاز دارد.
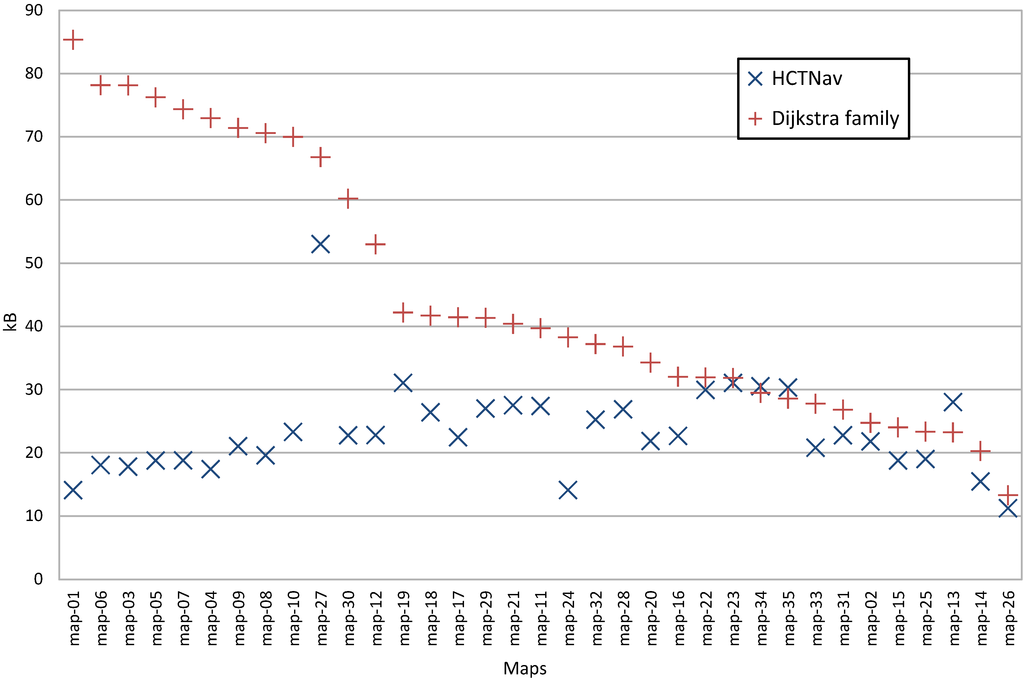
شکل 8. مقایسه “اوج” حافظه پویا ( HCTNav در مقابل خانواده Dijkstra). نقشه ها با توجه به نتیجه ارائه شده توسط راه حل Dijkstra سفارش داده شده اند.
4.2.2. مقیاس پذیری در تغییر اندازه نقشه
برای اعمال مزایای HCTNav در استفاده از حافظه، ما بر سناریوی شبیهسازی که نسخههای تغییر مقیاس نقشهها را در مجموعه خود اجرا میکند و پاسخ را با شبیهسازیهای Dijkstra مقایسه میکنیم، تاکید کردهایم. هرچه تعداد سلولهای ساختارهای نمودار بیشتر شود، فضای اولیه حافظه بیشتری برای اجرای جستجوی مسیر در نقشه بزرگشده مورد نیاز است.
دو سناریوی جالبی که ما میخواهیم در اینجا مورد بحث قرار دهیم، نقشه-01 ( شکل 7 الف) و نقشه-13 ( شکل 7 ب) هستند، زیرا آنها مطالعات موردی پیچیدگی نقشه کاملاً مخالف را نشان میدهند. دو روش مقیاس بندی مورد بحث در بخش فرعی 4.1 به کار گرفته شده است. در جدول 1 نتایج الگوریتم ارائه شده است. همانطور که مشاهده می شود، الگوریتم های Dijkstra به اندازه الگوریتم HCTNav مقیاس پذیر نیستند : استفاده از حافظه آنها در تمام سناریوها بزرگتر است، در حالی که راه حل ما گرادیان رشد کمتری را نشان می دهد.
جدول 1. نتایج شبیه سازی برای تجزیه و تحلیل مقیاس پذیری. پیک حافظه پویا بر حسب مگابایت بیان می شود.
4.2.3. تاثیر زمان اجرا
در مقایسه با دستورالعملهای سادهتر Dijkstra، پیادهسازی (و بهینهسازی) جریان اجرای الگوریتم HCTNav میتواند دشوار باشد و درجه پیچیدگی نامطلوبی را به الگوریتمهای جستجوی نموداری مرسوم اضافه میکند. با این حال، تجزیه و تحلیل داده های شبیه سازی نشان می دهد که عملکرد سرعت HCTNav قابل قبول است. برای اندازه گیری زمان اجرا، میانگین زمان جستجوی مسیر را در نظر گرفتیم ( یعنی کل مدت زمان کار دسته ای تقسیم بر تعداد مسیرهای موجود). شبیهسازیها روی یک ریزپردازنده معمولی رایانه شخصی، یعنی AMD-64 Turion X2 Dual-core در 2.00 گیگاهرتز، با 4 گیگابایت رم و لینوکس Debian SO (اوبونتو 9.10) راهاندازی شدهاند. نتایج نشان می دهد که HCTNavزمان اجرای ‘s به همان ترتیب بزرگی Dijkstra (میلی ثانیه) است.
در توپولوژی های پیچیده مانند نقشه های سبک هزارتویی، HCTNav عملکرد سرعت خود را از دست می دهد، به خصوص اگر نمایه موانع از یک الگوی پلکانی پیروی کند. این به دلیل افزایش جابجایی بین تشخیص موانع و ماژول های اطراف است. در اینجا مهم است که به یاد داشته باشید، با توجه به زمان پاسخ ربات در کار ناوبری (حدود 30 تا 40 ثانیه حرکت در یک سناریوی رایج)، زمان برنامه ریزی مسیر ناچیز است زیرا از کسری از ثانیه فراتر نمی رود.
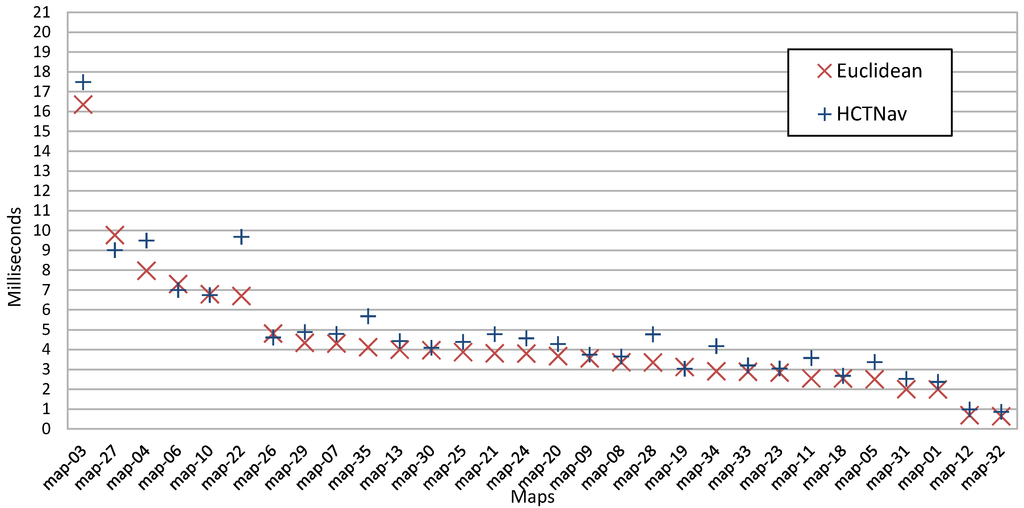
شکل 9. مقایسه زمان اجرا (میانگین جستجوی تک مسیری). نقشه ها با توجه به نتیجه ارائه شده توسط راه حل اقلیدسی (A*) مرتب شده اند.
در شکل 9 مقایسه زمان اجرا بین HCTNav و خانواده Dijkstra بر روی مجموعه آزمایشی نقشه ارائه شده است. بر روی محور مختصات، میانگین زمان جستجوی تک مسیری رسم می شود. HCTNav کمی کندتر از رویکرد A* است اما در مقایسه با الگوریتم Dijkstra از همان فاصله سرعتی رنج نمی برد.
4.2.4. مقایسه طول مسیر
مقایسه نهایی بین الگوریتم HCTNav پیشنهادی و راهحلهای توسعهیافته Dijkstra و A* طول مسیر نهایی را ارزیابی میکند. HCTNav یک بهینه سازی مسیر را انجام می دهد، همانطور که در بخش 3.4 ارائه شده است ، تا طول مسیر را کاهش دهد. بهینه سازی بررسی می کند که آیا امکان جابجایی بین دو گره غیر متوالی وجود دارد که راه حل را کوتاه می کنند یا خیر. این بهینهسازی برای راهحل ارائهشده توسط راهحلهای Dijkstra و A* نیز برای مقایسه منصفانه اعمال میشود.
جدول 2 نتایج مقایسه را در زیر مجموعه ای از نقشه ها نشان می دهد. تفاوت در دانه بندی راه حل های تولید شده و استفاده از الگوریتم بهینه سازی باعث می شود که درصد قابل توجهی از مسیرها دارای طول مسیرهای مختلف باشند ( یعنی تا 22 درصد از مسیرها در نقشه 11 متفاوت هستند). البته باید توجه داشت که میانگین اختلاف طول مسیر کمتر از یک سوم طول سلول است. همانطور که در بخش 2 بیان شد ، طول یک سلول با طول ربات برابر است. بنابراین، این تفاوت قابل توجه نیست. لازم به ذکر است که هر دو HCTNav و Dijkstra همیشه یک راه حل را به دست می آورند، هرچند که یک راه حل نیست.
جدول 2. نتایج مقایسه طول مسیر (میانگین و واریانس). عرض سلول واحد است ( u = 1).
4.3. بحث کیفی
4.3.1 HCTNav در مقابل . دایکسترا و A*
با توجه به خانواده Dijkstra و نسخههای اکتشافی آن (A*)، ما کاوش گراف مسیر بازگشتی و بخشی از ساختار دادهای را که در طول اجرا استفاده میشود، به اشتراک میگذاریم، اما با برخی تفاوتها:
-
HCTNav فقط به مجموعهای از گرهها نیاز دارد که سلولهای آزاد را در نقشه باینری نشان میدهند، در حالی که Dijkstra همچنین باید تمام لبههای ممکن را بداند. این ساده سازی صرفه جویی قابل توجهی در حافظه را در طول زمان اجرا نشان می دهد، به خصوص زمانی که نقشه ها از نظر تعداد سلول رشد می کنند.
-
لبه ها در طول اجرا تشکیل می شوند و می توانند چندین گره را پوشش دهند. در عوض، در پیادهسازیهای رایج خانواده Dijkstra، که برای این مقایسه استفاده میشود، تنها لبههای یکهاپ بهعنوان پیشپردازش نقشه ارزیابی و ذخیره میشوند، به دلیل هزینههای انفجاری ذخیرهسازی تمام یالهای ممکن در نمودار اولیه.
-
در HCTNav ما یک استراتژی کنترل موانع را برای یافتن گرههای ترانزیت میانی (نقاط عطف) که از آنجا شروع به احاطه کردن موانع میکنیم، معرفی کردیم. Dijkstra به سادگی موانع را در نظر نمی گیرد زیرا به طور ضمنی در ساخت نمودار اولیه حذف می شوند.
-
تفاوت بین طول مسیر بین HCTNav و Dijkstra کمتر از یک سوم سلول است. با توجه به اینکه یک سوم اندازه ربات نیز هست، قابل توجه نیست.
در شکل 10 مقایسه مستقیم خانواده HCTNav و Dijkstra در یک سناریوی مورد مطالعه دیگر ارائه شده است ( نقشه 11). در این شبیهسازیها، ما روی نرخ «سربار» تمرکز میکنیم، یعنی بخشی از نقشه که حتی اگر برای رسیدن به هدف مفید نباشد، کاوش میشود. این عامل بسیار مهم است زیرا مستقیماً بر عملکرد جستجوی مسیر تأثیر می گذارد. همانطور که مشاهده می شود، HCTNav سربار A* را تقریب می زند ( شکل 10d )، که به دلیل انتخاب مناسب next-hop کوچکتر از Dijkstra است.
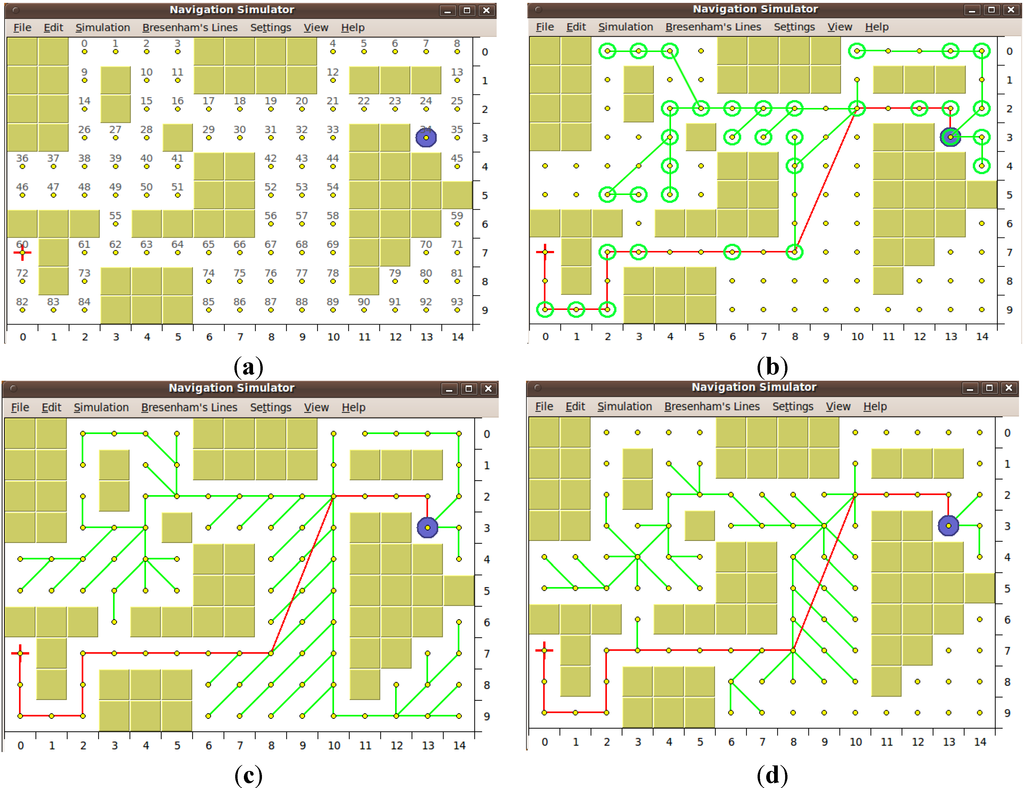
شکل 10. تحلیل کیفی در نقشه -11: ( الف ) سناریوی مسیر اولیه. ( ب ) محلول و سربار HCTNav . ( ج ) الگوریتم Dijkstra; ( د ) الگوریتم A*.
4.3.2. HCTNav در مقابل DistBug
با توجه به خانواده اشکالات، رویکرد HCTNav کاملاً متفاوت است: اشکالات مبتنی بر کمبود کامل اطلاعات نقشه هستند، در حالی که HCTNav دانش پیشینی از مدل نقشه دارد. در نتیجه، مفهوم ناوبری HCTNav مخالف خانواده Bugs است (کاوش گراف در مقابل حرکت مبتنی بر حس).
با این وجود، متوجه شدیم که قوانین ناوبری ما شبیه حالتهای عملیاتی DistBug است ( حرکت به سمت هدف و دنبال کردن مرز مانع ). این به دلیل این واقعیت است که هر دو الگوریتم از استراتژی شهودی مبتنی بر انسان برای رسیدن به مقصد با اجتناب از موانع الهام گرفته شدهاند.
همین معیار هم برای یک محیط ناشناخته و هم برای یک سناریوی برنامه ریزی نقشه معتبر است. انتخاب استراتژی برای پیادهسازی به مبادله بین هزینههای طراحی ربات و پیچیدگی الگوریتم بستگی دارد. لایه منطقی DistBug ساده تر از HCTNav است، اما هزینه لایه حسگر ربات DistBug بیشتر از HCTNav است.
در شکل 11 ما یک سناریوی شبیه سازی از کار کامون و ریولین [ 13 ] را بازتولید کرده ایم. اگرچه این نقشه فقط یک نتیجه نظری را برای الگوریتم DistBug نشان میدهد (شبیهسازی نشده)، این نقشه در مدل شبیهسازی ما، یعنی شبکهای با مشخصات موانع خطی قرار میگیرد. عرض ربات در DistBug نیز با تنظیم یک محدوده امنیتی مناسب در آرایه حسگر مجاورت در نظر گرفته می شود. یک مزیت واضح از پیش پردازش حرکت ربات در یک محیط داخلی شناخته شده این است که مسیر یافت شده به طور کلی کوتاهتر است و در نتیجه طول عمر باتری های روی برد را در یک سناریوی کاری طولانی افزایش می دهد. همانطور که انتظار می رود، درخت مسیر ناوبری ما شامل راه حل DistBug است (شاخه سمت چپ در شکل 11 ب): ما می توانیم مشاهده کنیم که حتینقاط H1 و H2 ( شکل 11 a) به عنوان نقاط عطف HCTNav منعکس می شوند . اما همچنین، HCTNav راه حل های ممکن دیگری را نیز پیدا می کند، که آنها نیز ارزیابی می شوند (که کوتاه تر نیز هستند). HCTNav همچنین شامل یک ماژول هرس است (به بخش فرعی 3.4 مراجعه کنید )، با بهره گیری از اطلاعات نقشه، گوشه های غیر ضروری را با جایگزین کردن آنها با لبه های جدید حذف می کند تا فاصله نهایی تجمعی را کاهش دهد. بهترین راه حل در اینجا با مسیر سمت راست در شکل 11 ب نشان داده شده است.

شکل 11. نتایج ناوبری DistBug و HCTNav . HCTNav کوتاه ترین مسیر را در سمت راست موانع (خط قرمز) پیدا می کند. ( الف ) راه حل نظری DistBug. ( ب ) محلول HCTNav .
5. نتیجه گیری ها
این مقاله یک الگوریتم برنامهریزی مسیر را برای روباتهای کمهزینه که در محیطهای داخلی جهتیابی میکنند، شرح داده است. شروع از تجزیه و تحلیل جوانب مثبت و منفی دو رویکرد محبوب در مسئله ناوبری: قطعی و واکنشی. ما یک راه حل ترکیبی، HCTNav را پیشنهاد کردیم .
هدف اولیه ما به حداقل رساندن نیازهای سخت افزاری لایه ناوبری ربات بود. در واقع، در رویکرد قطعی، که توسط الگوریتمهای خانواده Dijkstra ارجاع داده شده است، مقدار زیادی از حافظه RAM برای ذخیره ساختار نمودار مورد نیاز است. در رویکرد واکنشی، که توسط الگوریتمهای خانواده اشکال ارجاع میشود، هزینه اصلی توسط نمونهگیری فشرده حسگر و سختافزار کنترل مربوطه نشان داده میشود. مفهوم HCTNav ترکیب اصول جستجوی کوتاهترین مسیر رویکرد قطعی با تکنیکهای تشخیص موانع و اجتناب از روش واکنشی است.
برای کاهش محدودیت کران بالای حافظه پویا در زمان اجرا، ساختار دادههای الگوریتم را طراحی کردیم تا مجموعه لبهها را از نمودار اولیه حذف کنیم. علاوه بر این، ما توانستیم به جای نمونهبرداری از محیط با حسگرهای مجاورت، با پیادهسازی محدودیتهای موانع به عنوان نرمافزار خالص، الزامات لایه حسگر را کاهش دهیم. نیاز اصلی HCTNav این است که ربات باید از توپولوژی نقشه از قبل آگاه باشد. مدل نقشه ما یک ماتریس باینری است که نشان دهنده شبکه نقشه اشغال با وضعیت سلول (آزاد یا اشغال شده) است. یال های جدید در نمودار به صورت پویا و با اسکن مسیر مورد نظر با الگوریتم خط برزنهام کشف می شوند. هنگامی که یک برخورد احتمالی تشخیص داده می شود، یک نقطه عطف در مجاورت مانع اصلی به عنوان پرش بعدی مشخص می شود. با شروع از این نقطه میانی جدید، مسیر اولیه به شاخه های ناوبری مختلف تقسیم می شود و به ربات اجازه می دهد تا موانع را با پیروی از مرزهای آنها احاطه کند. از این رو، HCTNavیک نمودار ناوبری ایجاد می کند که از موقعیت اولیه به نقطه هدف هدایت می شود. برای به دست آوردن کوتاهترین مسیر از راهحلهای بهدستآمده، یک استراتژی پس از بهینهسازی، لبههای اضافی را به دلیل نقاط عطف خطی و گوشههای غیرضروری، با جایگزینی آنها با لبههای نرمالشده حذف میکند.
با در نظر گرفتن این موضوع که شبکههای نقشه در سناریوهای واقعی میتوانند هزاران سلول را در خود جای دهند، ما تلاش خود را بر روی مقیاسپذیر کردن الگوریتم تا حد امکان متمرکز کردیم. برای اندازهگیری عملکرد HCTNav ، ما با تکیه بر نمایهساز حافظه Valgrind و یک مجموعه آزمایشی نقشه سفارشی با توپولوژیهای مختلف، میز آزمایش خود را توسعه دادیم. همانطور که مشاهده شد، توپولوژی نقشه و نمایه موانع یک عامل مهم در عملکرد هر الگوریتم ناوبری است. HCTNav از نقشه هایی با وجود موانع کم بهره می برد، در حالی که خانواده Dijkstra در استفاده از حافظه جریمه می شوند که نسبت بین کاشی های آزاد و موانع زیاد باشد.
شبیهسازیها ثابت کردهاند که الگوریتم ما به فضای حافظه کمتری نسبت به الگوریتم Dijkstra یا نسخههای اکتشافی آن نیاز دارد، بهویژه زمانی که دانهبندی نقشه رشد میکند. به عنوان مثال، در یک سناریوی نقشه تغییر مقیاس 32× (بیش از 150000 سلول)، پیک حافظه HCTNav 9 برابر کمتر از خانواده Dijkstra است. علاوه بر این، نتایج تجربی نشان میدهد که الگوریتمهای Dijkstra و A* از حافظه مشابهی استفاده میکنند. این بدان معناست که راه حل A* فقط سربار Dijkstra و زمان اجرا را بهبود می بخشد اما استفاده از حافظه را کاهش نمی دهد، در حالی که HCTNavبرای پیاده سازی روی یک ریزپردازنده روباتی کم هزینه با منابع محدود مناسب تر است. زمان اجرا همچنان قابل قبول است زیرا در همان ترتیب بزرگی Dijkstra باقی می ماند. تفاوت طول مسیرها در درصد پایین مسیرهایی که این اختلاف به وجود آمده است معنی دار نیست. با توجه به مقایسه با خانواده اشکال، HCTNav هر دو طول مسیر نهایی را کاهش می دهد، بنابراین طول عمر باتری طولانی تری را به همراه دارد. و پیچیدگی لایه حسی، در نتیجه هزینه های سخت افزاری را کاهش می دهد.
منابع
- فو، ال. سان، دی. الگوریتمهای کوتاهترین مسیر اکتشافی Rilett، LR برای کاربردهای حملونقل: وضعیت هنر. محاسبه کنید. اپراتور Res. 2006 ، 33 ، 3324-3343. [ Google Scholar ] [ CrossRef ]
- آنتیچ، جی. اورتیز، ا. مینگز، جی. الگوریتم الهام گرفته از اشکال برای برنامه ریزی مسیر کارآمد در هر زمان. در مجموعه مقالات کنفرانس بین المللی IEEE/RSJ در مورد ربات ها و سیستم های هوشمند، سنت لوئیس، MO، ایالات متحده، 10-15 اکتبر 2009. صص 5407–5413.
- کورمن، تی. Leiserson، CE; Rivest، RL; استاین، الگوریتم سی دیکسترا. در مقدمه ای بر الگوریتم ها ، ویرایش دوم. مطبوعات MIT: کمبریج، MA، ایالات متحده آمریکا، 2001; صص 595-601. [ Google Scholar ]
- ادریس، م. باکار، س. تامیل، ای. رزاق، ز. نور، N. با سرعت بالا کوتاهترین مسیر طراحی کمک پردازشگر. در مجموعه مقالات سومین کنفرانس بین المللی آسیا در مدلسازی و شبیه سازی، بالی، اندونزی، 25-29 مه 2009. صص 626-631.
- Cain, T. بهینه سازی های عملی برای A* Path Generation. در AI Game Programming Wisdom , 2nd ed.; چارلز ریور ویراستاران: بوستون، MA، ایالات متحده آمریکا، 2003; صص 146-152. [ Google Scholar ]
- گرانت، ک. Mould, D. ترکیب جستجوی اکتشافی و نقطه عطفی برای برنامه ریزی مسیر. در مجموعه مقالات کنفرانس در بازی آینده: تحقیق، بازی، اشتراک گذاری، تورنتو، ON، کانادا، 3-5 نوامبر 2008. صص 9-16.
- گوتو، تی. کوزاکا، تی. Noborio, H. On the Heuristics of A* or A algorithm in ITS and Robot Path Planning. در مجموعه مقالات کنفرانس بین المللی IEEE/RSJ در مورد ربات ها و سیستم های هوشمند، لاس وگاس، NV، ایالات متحده، 27-31 اکتبر 2003. صص 1159–1166.
- بولوباس، بی. نظریه گراف مدرن . Springer: هایدلبرگ، آلمان، 1998; صص 252-259. [ Google Scholar ]
- سلامت، ع. ذوالف پور ارخلو، م. هاشم، SZ یک الگوریتم برنامه ریزی مسیر سریع برای سیستم هدایت مسیر. در مجموعه مقالات کنفرانس بین المللی IEEE در مورد سیستم ها، انسان و سایبرنتیک، انکوریج، AK، ایالات متحده، 9-12 اکتبر 2011. صص 2773-2778.
- لانگرویش، ام. واگنر، ب. برنامه ریزی مسیر پویا برای حرکت هماهنگ چند ربات متحرک. در مجموعه مقالات کنفرانس بین المللی IEEE در مورد سیستم های حمل و نقل هوشمند، واشنگتن، دی سی، ایالات متحده آمریکا، 5-7 اکتبر 2011. صفحات 1989-1994.
- ژو، جی. لین، اچ. تکنیک برنامه ریزی مسیر و مکان یابی خود برای ناوبری ربات موبایل. در مجموعه مقالات کنترل و اتوماسیون هوشمند (WCICA)، تایپه، چین، 21 تا 25 ژوئن 2011. صص 694-699.
- عبدالجبار، ج.م. الوان، MA; العبادی، م. معماری سخت افزاری جدید برای پردازشگر جستجوی کوتاه ترین مسیر موازی بر اساس فناوری FPGA. بین المللی جی. الکترون. محاسبه کنید. علمی مهندس 2012 ، 1 ، 2572-2582. [ Google Scholar ]
- جیانگ، ز. Wu, J. در مورد دستیابی به مسیریابی کوتاه ترین مسیر در مش های دو بعدی. در مجموعه مقالات سمپوزیوم پردازش موازی و توزیع شده، لانگ بیچ، کالیفرنیا، ایالات متحده آمریکا، 26 تا 30 مارس 2007. ص 26-30.
- لوملسکی، وی جی. استپانوف، الف. استراتژیهای برنامهریزی مسیر برای خودکار متحرک نقطهای که در میان موانعی با شکل دلخواه حرکت میکند. الگوریتمیکا 1987 ، 2 ، 403-430. [ Google Scholar ] [ CrossRef ]
- لوملسکی، وی جی. Skewis, T. گنجاندن حسگر محدوده در عملکرد ناوبری ربات. IEEE Trans. سیستم مرد سایبرن. 1990 ، 2 ، 1058-1068. [ Google Scholar ] [ CrossRef ]
- کمون، آی. Rivlin، E. برنامه ریزی حرکتی مبتنی بر حسی با اثبات جهانی. IEEE Trans. ربات. خودکار 1997 ، 13 ، 814-822. [ Google Scholar ] [ CrossRef ]
- نادسون، ام. Tumer, K. ناوبری تطبیقی برای روبات های خودمختار. Auton. Robots 2011 ، 59 ، 410-420. [ Google Scholar ] [ CrossRef ]
- Sharef, SM; سعید، WK; خوشابا، FS یک سیستم مبتنی بر قانون برای برنامه ریزی مسیر یک ربات موبایل داخلی. در مجموعه مقالات کنفرانس چندگانه بین المللی در مورد سیگنال ها و دستگاه های سیستمی، امان، اردن، 27 تا 30 ژوئن 2010. صص 1-7.
- یو، ن. Ma, C. ساخت نقشه ربات موبایل بر اساس اتوماتای سلولی. در مجموعه مقالات کنفرانس اقیانوس آرام-آسیا در مورد مدارها، ارتباطات و سیستم، ووهان، چین، 17-18 ژوئیه 2011. صص 1-4.
- گونزالس-آرجونا، دی. سانچز، آ. د کاسترو، آ. Garrido, J. نقشهبرداری داخلی شبکه اشغال با استفاده از رباتهای متحرک مبتنی بر FPGA. در مجموعه مقالات کنفرانس طراحی مدارها و سیستم های یکپارچه، آلبوفیرا، پرتغال، 16-18 نوامبر 2011. صص 345-350.
- Buckland, M. Programming Game AI by Example , 1st ed.; Wordware Publishing: Plano, TX, USA, 2005; صص 193-248. [ Google Scholar ]
- الگوریتم برسنهام، JE برای کنترل کامپیوتری پلاتر دیجیتال. سیستم آی بی ام J. 1965 , 4 , 25-30. [ Google Scholar ] [ CrossRef ]
© 2013 توسط نویسندگان; دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (http://creativecommons.org/licenses/by/3.0/) توزیع شده است.
بدون نظر