

خلاصه
برنامه ریزی وظایف ؛ هایپرگراف + ; پردازش داده های مکانی ؛ پلت فرم های ارباب برده
1. معرفی
2. پیشینه و کارهای مرتبط
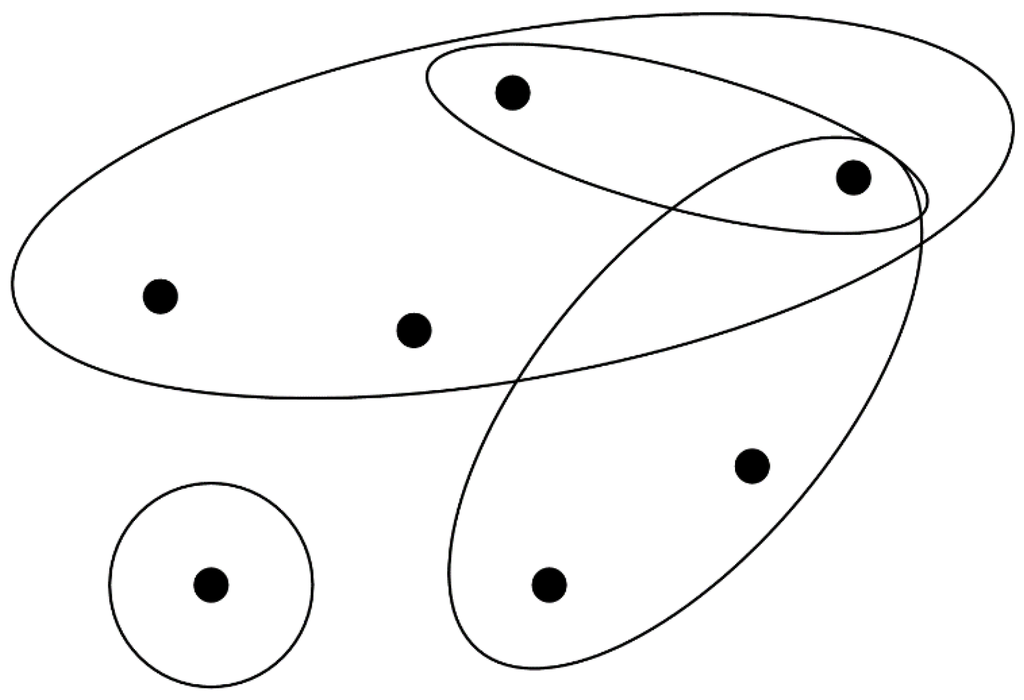
2.1. Hypergraph و Hypergraph Partitioning
که در آن N برش مجموعه ای از تمام لبه های برش خورده است و هر لبه برش n j هزینه ای را متحمل می شود جj(λj–1). این اندازه پارتیشن به عنوان معیار اتصال 1 نیز شناخته می شود .
جایی که دبلیوک=∑vمن∈Vکwمننشان دهنده مجموع اوزان رأس یک قسمت V k است . دبلیوآvg=∑Vمن∈Vwمنکمیانگین وزن است؛ و ε یک مقدار نامتعادل از پیش تعیین شده است.
2.2. اکتشافی زمانبندی برای برنامه های کاربردی داده فشرده
3. مدل زمانبندی کار مبتنی بر هایپرگراف
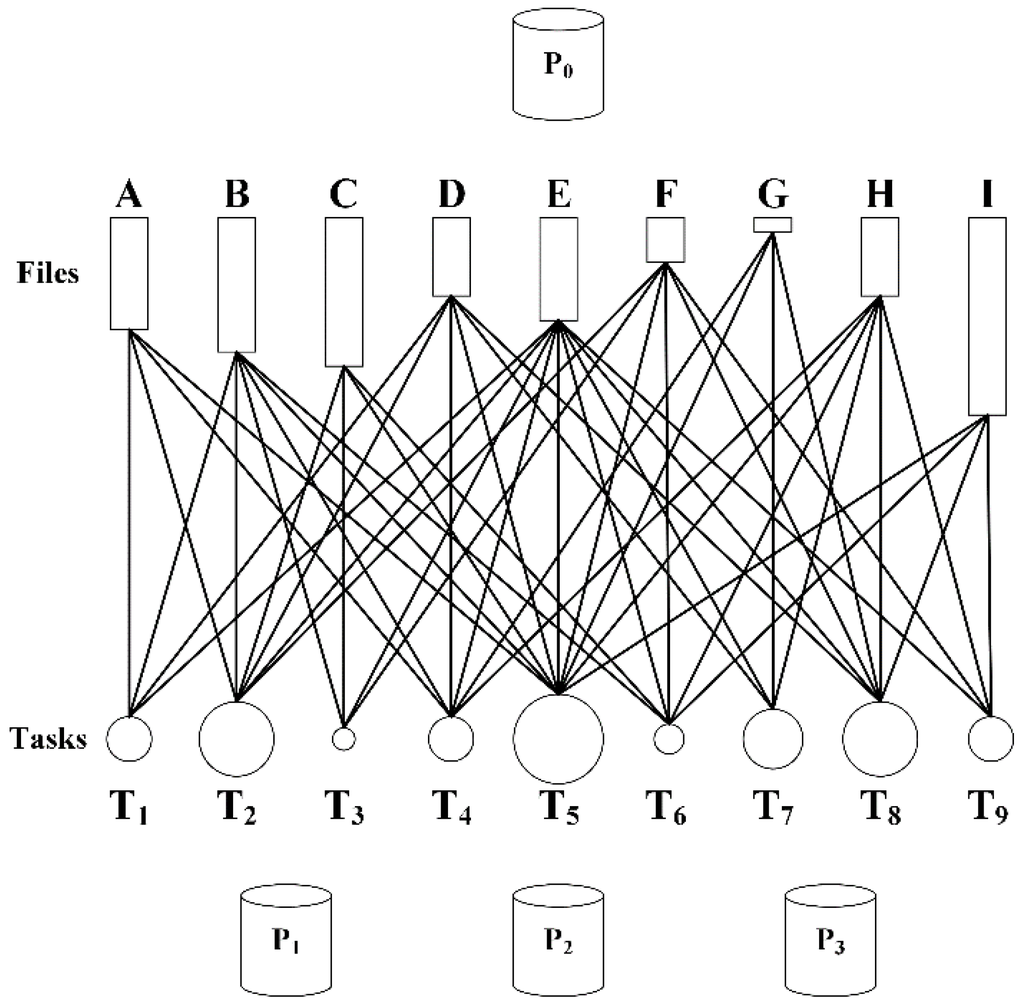
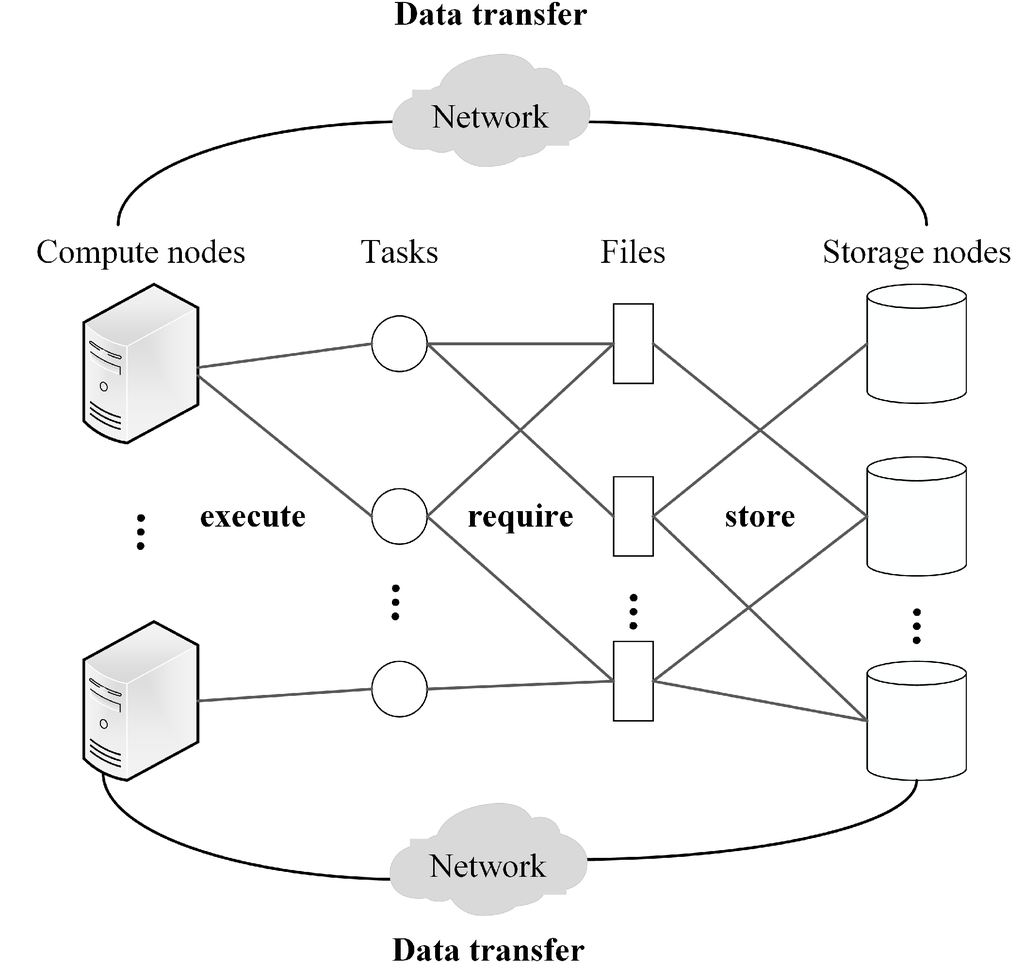
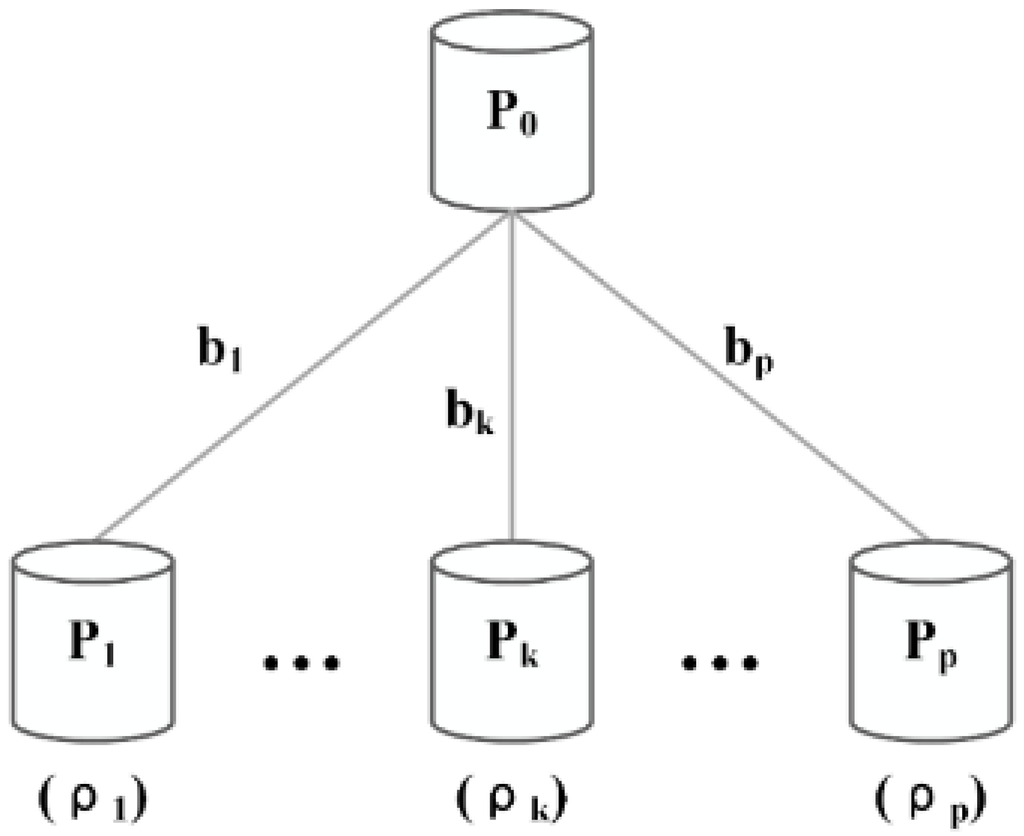
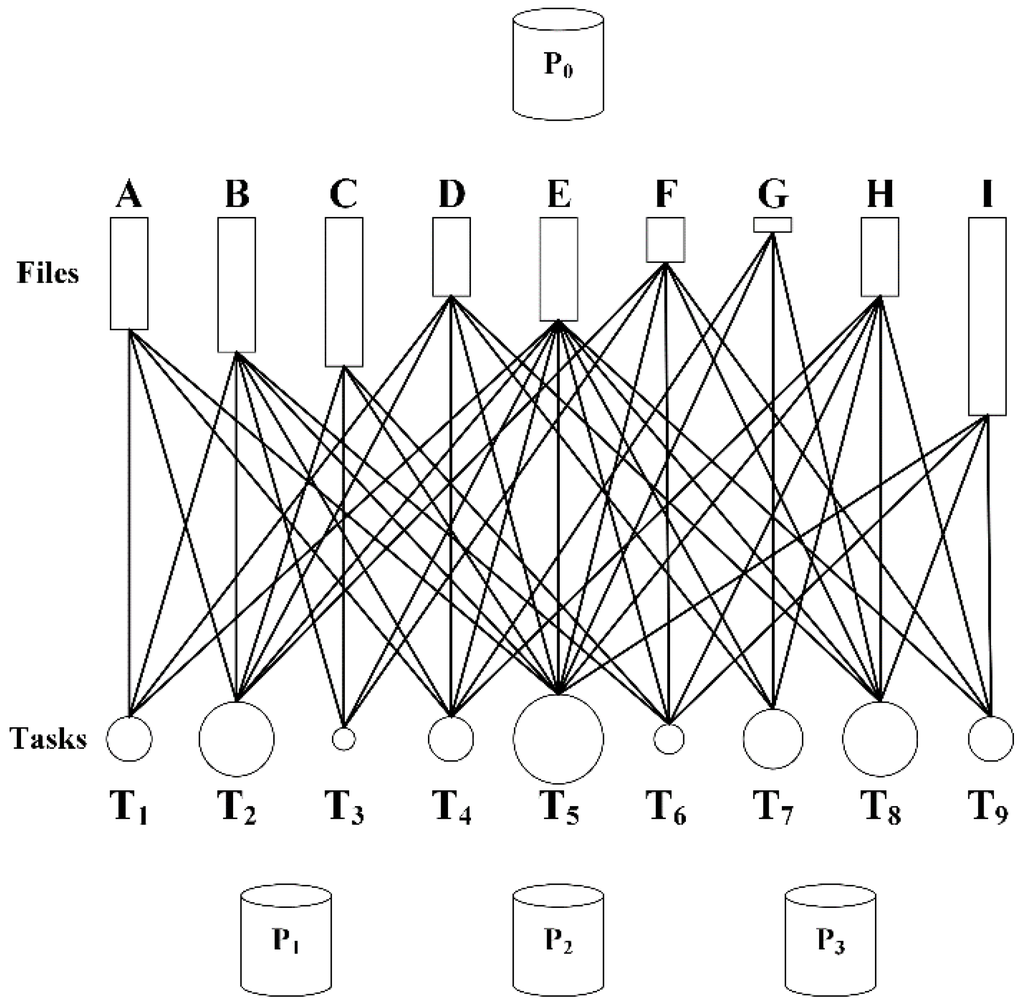
3.1. مدل پلت فرم
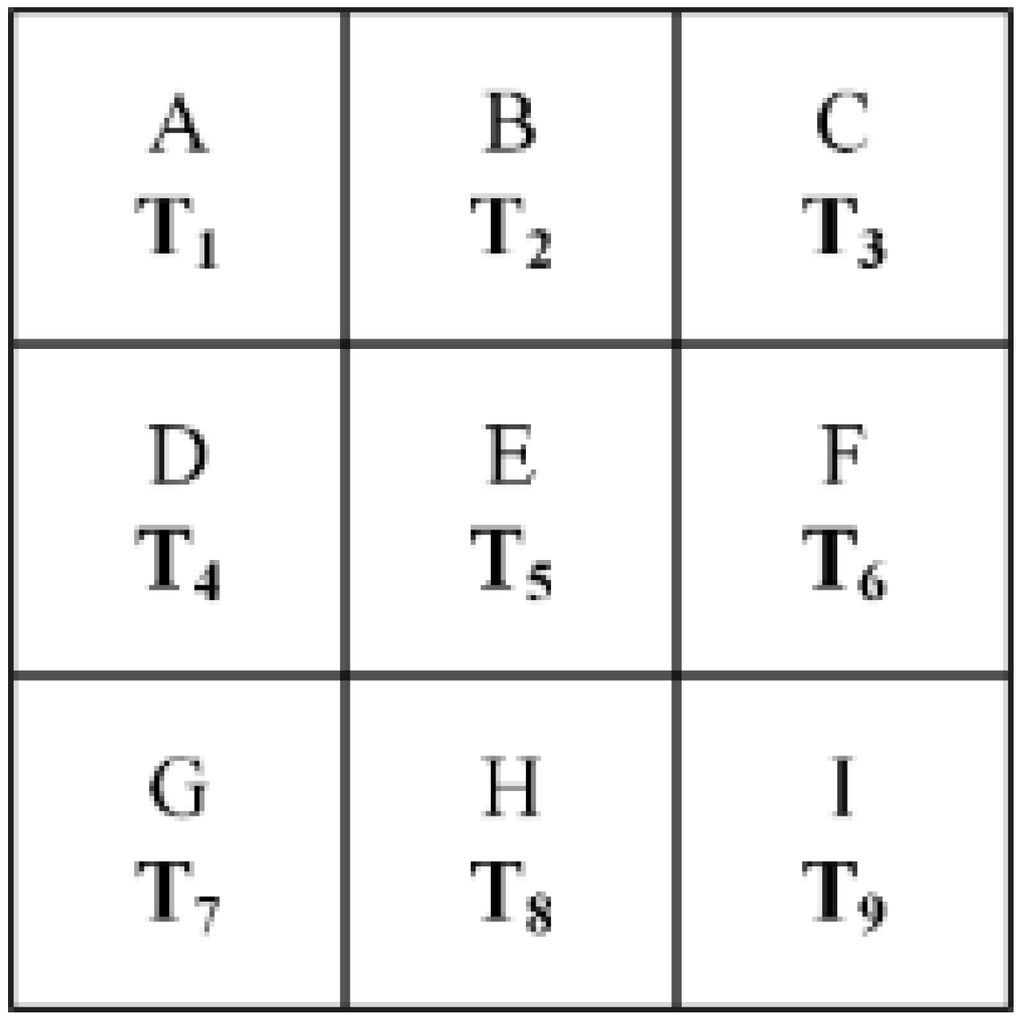
3.2. مدل کاربردی
3.3. هدف برنامه ریزی
جایی که ∑nj∈نجjبرابر با حجم کل فایل ورودی است و می تواند ثابت در نظر گرفته شود، بنابراین کام(Π)بستگی دارد به برش اندازه(Π). بنابراین، به حداقل رساندن اندازه برش معادل به حداقل رساندن انتقال کل داده است.
4. الگوریتم Hypergraph + Scheduling
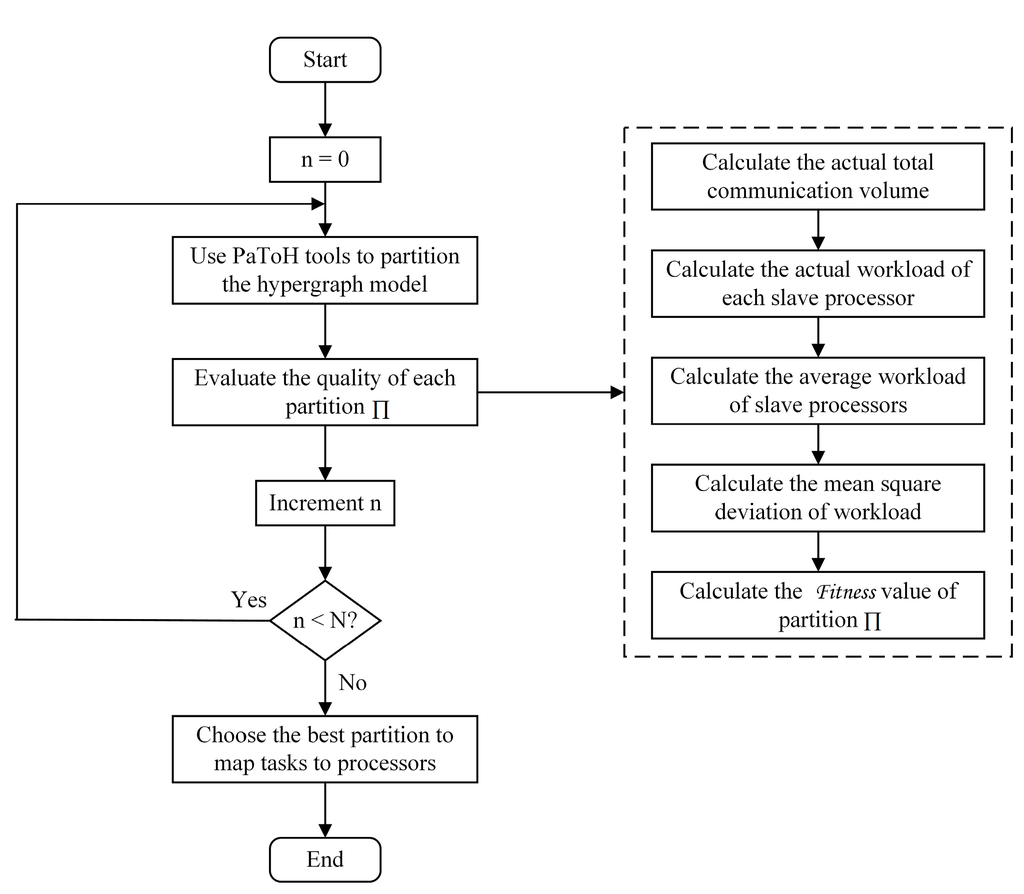
4.1. پارتیشن بندی هایپرگراف برای تطبیق وظایف
4.2. سفارش وظایف و انتقال فایل
| الگوریتم 1 ترتیب وظایف برای اجرا |
|
| الگوریتم 2 اکتشافی انتقال فایل در هر پردازنده |
|
5. آزمایش و بحث
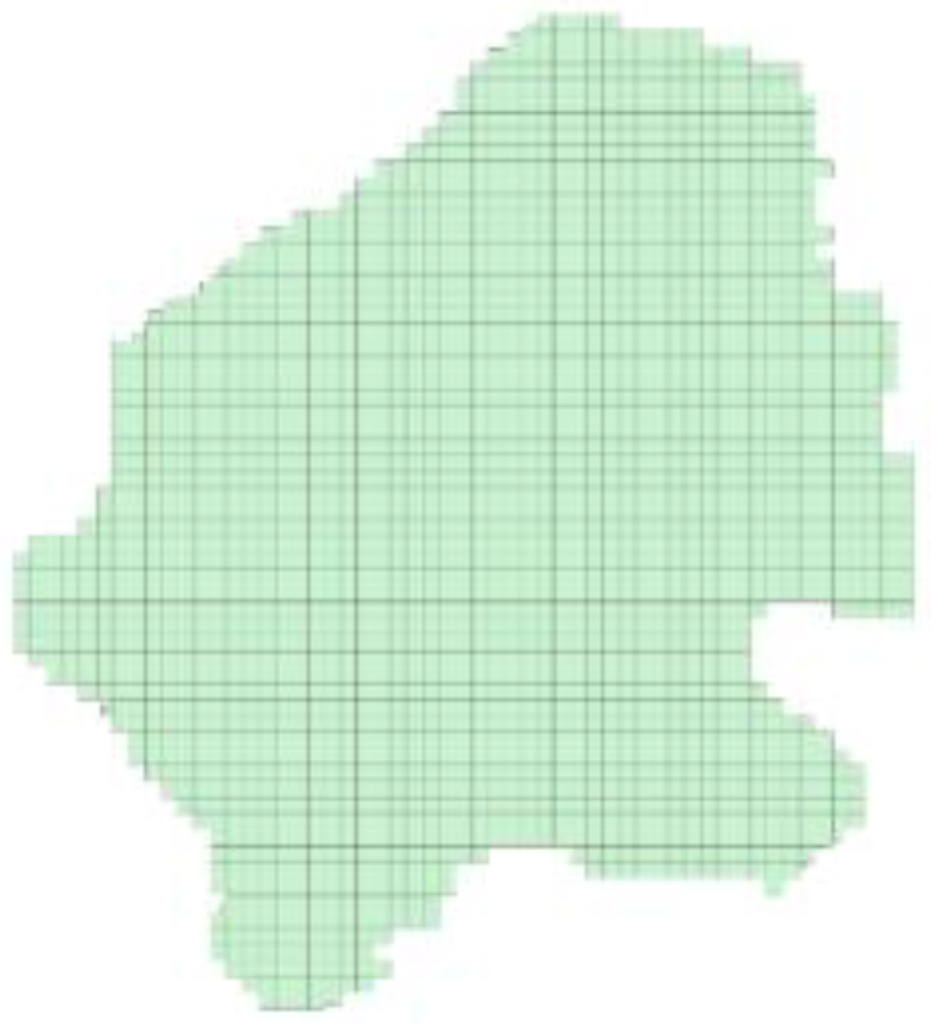
5.1. منابع شبیه سازی شده
5.2. برنامه تجربی و مجموعه داده ها
که در آن Z p مقدار درونیابی شده در نقطه هدف p است . Z i مقدار مشاهده شده در نقطه پراکندگی یکم p i در همسایگی p است . k تعداد نقاط پراکندگی گرفته شده در درونیابی در همسایگی از پیش تعریف شده p است . d i فاصله اقلیدسی از من نقطه پراکندگی p i تا p است . و β یک عدد مثبت دلخواه به نام توان وزنی است.
5.3. نتایج ارزیابی و بحث
6. نتیجه گیری
منابع
- لیو، ی. چن، بی. یو، اچ. ژائو، ی. هوانگ، ز. Fang, Y. استفاده از فناوریهای GPU و رشته POSIX در پردازش دادههای تصویر سنجش از راه دور. در مجموعه مقالات نوزدهمین کنفرانس بین المللی ژئوانفورماتیک 2011، شانگهای، چین، 24-26 ژوئن 2011; صص 1-6.
- آهنگ، دبلیو. یو، اس. وانگ، ال. ژانگ، دبلیو. لیو، دی. زمانبندی وظایف پردازش گسترده دادههای مکانی در مراکز داده توزیعشده: چه چیزی جدید است؟ در مجموعه مقالات 2011 IEEE هفدهمین کنفرانس بین المللی سیستم های موازی و توزیع شده، تاینان، تایوان، 7-9 دسامبر 2011. ص 976-981.
- زینگ، جی. سیبر، آر. Kalacska، M. چالشهای تقسیمبندی تصویر در دادههای تصویری سنجش از راه دور بزرگ. ان GIS 2014 ، 20 ، 233-244. [ Google Scholar ] [ CrossRef ]
- بویا، ر. Murshed، M. Gridsim: ابزاری برای مدلسازی و شبیهسازی مدیریت منابع توزیعشده و زمانبندی برای محاسبات شبکه. CCPE 2002 ، 14 ، 1175-1220. [ Google Scholar ] [ CrossRef ]
- ماهسواران، م. علی، س. Siegal، HJ; هنسگن، دی. فروند، تطبیق دینامیک RF و زمانبندی یک کلاس از وظایف مستقل بر روی سیستمهای محاسباتی ناهمگن. در مجموعه مقالات هشتمین کارگاه محاسباتی ناهمگن (HCW’99)، سان خوان، پورتوریکو، 12 آوریل 1999; صص 30-44.
- کازانووا، اچ. لگراند، ا. زاگورودنوف، دی. برمن، اف. اکتشافی برای برنامهریزی برنامههای جابجایی پارامترها در محیطهای شبکه. در مجموعه مقالات نهمین کارگاه محاسباتی ناهمگن (HCW’00)، کانکون، مکزیک، 1 مه 2000; صص 349-363.
- خانا، جی. ویدیاناتان، ن. کورک، تی. کاتالیورک، یو. ویکوف، پی. سالتز، جی. Sadayappan، P. یک رویکرد مبتنی بر پارتیشن بندی هایپرگراف برای زمان بندی وظایف با I/O به اشتراک گذاشته شده دسته ای. در مجموعه مقالات پنجمین سمپوزیوم بین المللی در محاسبات خوشه ای و شبکه (CCGrid 2005)، کاردیف، انگلستان، 9 تا 12 مه 2005. صص 792-799.
- Berge, C. نمودارها و هایپرگرافها ; North-Holland Publishing Company: آمستردام، هلند، 1973. [ Google Scholar ]
- کاریپیس، جی. کومار، V. پارتیشن بندی هایپرگراف چندسطحی k-way. VLSI Des. 2000 ، 11 ، 285-300. [ Google Scholar ] [ CrossRef ]
- Catalyürek، UV; Aykanat، C. PaToH (ابزار پارتیشن بندی برای هایپرگراف ها). در دایره المعارف محاسبات موازی 2011 ; Springer Science & Business Media: برلین، آلمان، 2011; ص 1479-1487. [ Google Scholar ]
- تریفونوویچ، آ. Knottenbelt، WJ Parkway 2.0: ابزار پارتیشن بندی هایپرگراف چند سطحی موازی. در مجموعه مقالات نوزدهمین سمپوزیوم بین المللی علوم کامپیوتر و اطلاعات (ISCIS 2004)، کمر-آنتالیا، ترکیه، 27-29 اکتبر 2004; صص 789-800.
- آلپرت، سی جی; Kahng، AB جهتهای اخیر در پارتیشنبندی فهرست شبکه: یک نظرسنجی. یکپارچه سازی VLSI J. 1995 ، 19 ، 1-81. [ Google Scholar ] [ CrossRef ]
- کاریپیس، جی. آگاروال، آر. کومار، وی. Shekhar, S. پارتیشن بندی هایپرگراف چندسطحی: کاربردها در حوزه VLSI. IEEE Trans. ادغام در مقیاس بسیار بزرگ. (VLSI) سیستم 1999 ، 7 ، 69-79. [ Google Scholar ] [ CrossRef ]
- مبشر، ب. جین، ن. هان، ای اچ. Srivastava, J. Web Mining: Pattern Discovery from the World Wide Web Transactions . گزارش فنی TR96-050; گروه علوم کامپیوتر، دانشگاه مینهسوتا: مینیاپولیس، MN، ایالات متحده آمریکا، 1996. [ Google Scholar ]
- دمیر، ای. ایکانات، سی. کامبازوغلو، BB خوشهبندی شبکههای فضایی برای پردازش پرس و جوی کل: یک رویکرد ابرگراف. Inf. سیستم 2008 ، 33 ، 1-17. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Catalyürek، UV; Aykanat، C. تجزیه مبتنی بر پارتیشن بندی هایپرگراف برای ضرب بردار ماتریس پراکنده موازی. IEEE Trans. توزیع موازی سیستم 1999 ، 10 ، 673-693. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کامبازاوغلو، بی بی. Aykanat، C. مدلهای نگاشت مجدد مبتنی بر پارتیشنبندی هایپرگراف برای رندر حجم مستقیم تصویر-فضا-موازی شبکههای بدون ساختار. IEEE Trans. توزیع موازی سیستم 2007 ، 18 ، 3-16. [ Google Scholar ] [ CrossRef ]
- کایا، ک. Aykanat، C. اکتشافی مبتنی بر بهبود تکراری برای زمانبندی تطبیقی وظایف اشتراکگذاری فایلها در محیطهای ناهمگن master-slave. IEEE Trans. توزیع موازی سیستم 2006 ، 17 ، 883-896. [ Google Scholar ] [ CrossRef ]
- دومبویا، مگابایت؛ کامسو فوگم، بی. کنفک، اچ. معناشناسی استدلال و ویژگی های نمودار. Inf. روند. مدیریت 2016 ، 52 ، 319-325. [ Google Scholar ] [ CrossRef ]
- کامسو فوگم، بی. Tchuenté-Foguem، G. فوگم، سی. عملیات گراف مفهومی برای استدلال بصری رسمی در حوزه پزشکی. IRBM 2014 ، 35 ، 262-270. [ Google Scholar ] [ CrossRef ]
- Kamsu-Foguem، B. پشتیبانی مبتنی بر دانش در آزمایش های غیر مخرب برای نظارت بر سلامت سازه های هواپیما. Adv. مهندس Inf. 2012 ، 26 ، 859-869. [ Google Scholar ] [ CrossRef ]
- کوثر، ت. بالمن، ام. پارادایم جدید: زمانبندی آگاهانه از داده در محاسبات شبکه. آینده. ژنر. محاسبه کنید. سیستم 2009 ، 25 ، 406-413. [ Google Scholar ] [ CrossRef ]
- Caíno-Lores، S. Carretero، J. نظرسنجی در مورد تکنیک های داده محور و آگاه از داده برای زیرساخت های مقیاس بزرگ. آکادمی جهانی علمی مهندس تکنولوژی بین المللی جی. کامپیوتر. برق خودکار. ادامه Inf. مهندس 2016 ، 10 ، 459-465. [ Google Scholar ]
- محمد، HH; Epema، DH ارزیابی پردازشگر نزدیک به فایل و سیاست تخصیص مشترک داده در چند خوشه. در مجموعه مقالات کنفرانس بین المللی IEEE در مورد محاسبات خوشه ای 2004، لس آلامیتوس، کالیفرنیا، ایالات متحده آمریکا، 20-23 سپتامبر 2004.
- ژانگ، YF; تیان، YC; فیج، سی. کلی، دبلیو. زمانبندی کار آگاه از داده برای مشکلات مقایسه همه به همه در سیستمهای توزیع ناهمگن. J. توزیع موازی. محاسبه کنید. 2016 ، 93 ، 87-101. [ Google Scholar ] [ CrossRef ]
- Szmajduch، M. Kołodziej، J. برنامه ریزی آگاهانه از داده در سیستم های ناهمگن عظیم. در مجموعه مقالات بیست و نهمین کنفرانس اروپایی مدلسازی و شبیه سازی ECMS 2015، وارنا، بلغارستان، 26-29 مه 2015. صص 608-614.
- دا سیلوا، FA; Senger, H. محدودیتهای مقیاسپذیری برنامههای Bag-of-Tasks که بر روی پلتفرمهای سلسله مراتبی اجرا میشوند. J. توزیع موازی. محاسبه کنید. 2011 ، 71 ، 788-801. [ Google Scholar ] [ CrossRef ]
- گوان، کیو. Clarke، KC یک برنامه آزمایشی کتابخانه برنامه نویسی برنامه نویسی پردازش شطرنجی موازی همه منظوره با استفاده از یک مدل اتوماتای سلولی جغرافیایی. بین المللی جی. جئوگر. Inf. علمی 2010 ، 24 ، 695-722. [ Google Scholar ] [ CrossRef ]
- موتوولو، ن. لیو، جی. Soe, NL; ونوگوپال، اس. سولیستو، ا. Buyya, R. یک زمانبندی مبتنی بر گروهبندی مشاغل پویا برای استقرار برنامههای کاربردی با وظایف دقیق در شبکههای جهانی. در مجموعه مقالات سومین کارگاه استرالیایی در محاسبات شبکه و تحقیقات الکترونیکی (AusGrid 2005)، نیوکاسل، استرالیا، 30 ژانویه تا 4 فوریه 2005. ص 41-48.
- گوان، ایکس. وو، اچ. استفاده از قدرت پلتفرمهای چند هستهای برای پردازش دادههای مکانی در مقیاس بزرگ: نمونهای از تولید DEM از ابرهای عظیم نقطه LiDAR است. محاسبه کنید. Geosci. 2010 ، 36 ، 1276-1282. [ Google Scholar ] [ CrossRef ]
- تریفونوویچ، آ. Knottenbelt، WJ الگوریتم های چند سطحی موازی برای پارتیشن بندی هایپرگراف. J. توزیع موازی. محاسبه کنید. 2008 ، 68 ، 563-581. [ Google Scholar ] [ CrossRef ]


© 2016 توسط نویسندگان؛ دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (CC-BY) (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر