1. معرفی
درون یابی فضایی (SI) فرآیندی است که برای تخمین مقادیر خواص در نقاط ناشناخته در یک منطقه تحت پوشش نقاط مشاهده شده موجود استفاده می شود [ 1 ]. در بسیاری از موقعیتها، SI برای ارائه خطوط انجام میشود تا بتوان دادهها را به صورت گرافیکی نمایش داد، برای محاسبه مقادیر ویژگی برای سطح در یک نقطه مشخص یا برای تجزیه و تحلیل و پیشبینی سطح روند. در تحقیقات Digital Earth (DE)، SI همیشه یک ابزار قدرتمند برای مدلسازی و شبیهسازی بوده است [ 2 ، 3]]. پیشرفتهای فناوری، روشهای موجود برای دستیابی و دسترسی به دادهها را بسیار غنی کرده است و در بسیاری از کاربردهای مهندسی در مقیاس بزرگ، حجم عظیمی از دادهها باید با استفاده از الگوریتمهای درون یابی پردازش شوند. در واقع، SI به ویژه برای پیشبینی و نمایش در بسیاری از زمینهها، از جمله سیستمهای اطلاعات جغرافیایی و سنجش از دور [ 4 ، 5 ، 6 ]، زمینشناسی [ 7 ]، معدن [ 8 ]، هیدروژئولوژی [ 9 ]، تحقیقات خاک [ 10 ] مهم است. ژئوفیزیک [ 11 ]، اقیانوس شناسی [ 12 ]، هواشناسی [ 13 ]، اکولوژی و مطالعات زیست محیطی [ 14 ،15 ].
چندین نوع مختلف از روشهای طبقهبندی توسط رویههای SI مورد استفاده قرار میگیرند، بهعنوان مثال، نقطه-منطقه، جهانی-محلی و درونیابی دقیق-تقریبی [ 16]]. تکنیک های زیادی برای درون یابی جهانی و محلی وجود دارد. تحلیل سطح روند و سری فوریه نمونههایی از تکنیکهای جهانی هستند، در حالی که پروگزیمال، کریجینگ و B-spline تکنیکهای محلی هستند. به طور خاص، الگوریتم کریجینگ SI یک الگوریتم درون یابی محلی معمولی است. الگوریتم درون یابی جهانی کریجینگ نوعی از الگوریتم کریجینگ بهینه SI خطی و بی طرفانه است که به طور گسترده در بسیاری از کاربردهای علمی و مهندسی استفاده می شود. با این حال، در بسیاری از کاربردها، هنگام استفاده از الگوریتم کریجینگ جهانی سریال، گلوگاه های عملکردی شدید رخ می دهد زیرا هزینه محاسباتی با اندازه داده های ورودی به صورت تصاعدی افزایش می یابد [ 17 ، 18 ].
به منظور تسریع فرآیند و دستیابی به عملکرد بهتر، محققان در دهههای گذشته روشهای مختلفی را برای پیادهسازی الگوریتمهای SI موازی که سیستمهای محاسباتی با کارایی بالا را هدف قرار میدهند، توسعه دادهاند، به عنوان مثال، MasPar [19]، Cray T3D [20] ، خوشههای موازی [ 21 ] ، پلتفرم های چند هسته ای [ 22 ] و محیط های محاسباتی شبکه ای [ 23 ]. به طور خاص، مطالعات متعددی در مورد طراحی الگوریتم درون یابی کریجینگ موازی انجام شده است. به عنوان مثال، کری و همکاران. [ 24] از یک کامپیوتر اختصاصی با کارایی بالا برای پیاده سازی یک الگوریتم کریجینگ موازی استفاده کرد که زمان CPU را تا حد زیادی کاهش می دهد. با این حال، این روش بسیار گران است و به پیکربندی سخت افزاری استاندارد بالایی برای تسریع پردازش نیاز دارد. پیدلتی و همکاران [ 25 ] یک الگوریتم کریجینگ موازی را با استفاده از مدل برنامهنویسی موازی رابط ارسال پیام بر روی یک خوشه کالا پیادهسازی کرد، جایی که پیادهسازی آنها به عملکرد رضایتبخش و کارایی خوب دست یافت. با این حال، نیاز به پردازش بلادرنگ و رشد سریع در اندازه دادهها، گرههای محاسباتی بیشتری را میطلبد، که ناگزیر باعث افزایش هزینههای سختافزار و تعمیر و نگهداری و همچنین نیاز به مصرف انرژی بالا میشود [26] .]. برخی از مطالعات نیز الگوریتم های کریجینگ موازی را با استفاده از روش های موازی سازی چند هسته ای توسعه داده اند. به عنوان مثال، Strzelczyk و همکاران. [ 27 ] یک الگوریتم کریجینگ موازی بر اساس چندین هسته طراحی کرد، اما زمانی که موازی سازی چند هسته ای برای کاربردهای علمی تخصصی، به عنوان مثال، پردازش داده های بزرگ، به دلیل دسترسی آهسته به حافظه سیستم، به کار رفت، مشکلات کارایی وجود داشت.
اخیراً با توجه به افزایش سریع ظرفیت محاسباتی شتابدهندهها، مانند واحدهای پردازشگر گرافیکی (GPU) و Intel Xeon Phi (معماری هستههای مجتمع چندگانه اینتل (MIC))، استفاده از شتابدهندهها برای پردازش دادههای بزرگ به یک تحقیق داغ تبدیل شده است. موضوع در زمینه های مختلف مطالعات زیادی در مورد GPU ها در زمینه علوم زمین انجام شده است [ 28 ، 29 ، 30 ، 31 ]. به طور خاص، مطالعاتی در مورد الگوریتم های کریجینگ جهانی انجام شده است. برای مثال، چنگ و همکاران. یک الگوریتم کریجینگ جهانی موازی را با استفاده از NVIDIA Compute Unified Device Architecture (CUDA) بر روی یک پلت فرم GPU پیاده سازی کرد [ 32]. با این حال، مطالعات کمی در مورد پلت فرم Intel MIC انجام شده است زیرا MIC یک فناوری شتاب دهنده نسبتاً جدید است. مطالعات قبلی مبتنی بر MIC عمدتاً بر مقایسه با GPU یا جنبههای برنامهنویسی پلتفرم به جای طراحی یا پیادهسازی الگوریتم یا برنامههای کاربردی SI موازی متمرکز بود. به عنوان مثال، هاینک و همکاران. [ 33 ] معماری و عملکرد یک GPU عمومی (GPGPU) را با یک MIC اینتل مقایسه کرد و مزایای MIC را نشان داد. وانگ و همکاران [ 34 ] اقداماتی را برای جلوگیری از تنگناها در ظرفیت حافظه، پهنای باند شبکه و غیره شرح داد.، و توسعه پذیری رشته برنامه نویسی موازی را در پلت فرم MIC افزایش داد. با این حال، پیادهسازی آنها در پلتفرمهای مختلف قابل حمل نبود، زیرا پلتفرمهای محاسباتی مختلف، یعنی GPU و MIC، به مدلها و ابزارهای برنامهنویسی متفاوتی نیاز دارند.
یک سیستم محاسباتی ناهمگن یک سیستم محاسباتی است که می تواند GPU و اجزای شتاب دهنده Intel Xeon Phi را در سیستم های محاسباتی معمولی برای اجرای وظایف محاسباتی همراه با CPU ادغام کند. محاسبات ناهمگن هر پلتفرم ناهمگن را به روشی ناهمزمان با استفاده از منابع جداگانه برای محاسبات یا زمانبندی کار یکپارچه میکند، در نتیجه کارایی کلی یک سیستم محاسباتی را با تخصیص وظایف بر اساس در نظر گرفتن ظرفیتهای هر دستگاه محاسباتی به حداکثر میرساند [35 ] .
محاسبات ناهمگن نقش فزاینده ای مهمی در پردازش کلان داده ایفا می کند و ما پذیرش سریع محاسبات ناهمگن را برای پردازش درونیابی داده های فضایی در مقیاس بزرگ با استفاده از الگوریتم های بهبود یافته تصور می کنیم. این رویکرد به طور بالقوه میتواند به عملکرد بالایی در پلتفرمهای محاسباتی کمکپردازنده با سرعتهای بیش از 10× دست یابد، و همچنین به طور موثر از مشکلات فوقالذکر که در خوشههای سنتی فقط CPU با آن مواجه میشوند، اجتناب کند. همچنین مطلوب است که یک پیادهسازی متقابل پلتفرم بهینه از یک الگوریتم کریجینگ جهانی موازی که بر روی پلتفرمهای ناهمگن مختلف اجرا میشود، داشته باشیم. تا جایی که ما می دانیم، مطالعات کمی به کاربرد محاسبات ناهمگن در زمینه علوم زمین پرداخته است.
در این مطالعه، ما طراحی و اجرای یک الگوریتم کریجینگ جهانی موازی، و همچنین نشان دادن عملکرد و ویژگیهای کراس پلتفرم آن را ارائه میکنیم. ادامه این مقاله به شرح زیر سازماندهی شده است. در بخش 2 ، مقدمهای کوتاه بر الگوریتم کریجینگ جهانی، محاسبات ناهمگن و مدل توسعه OpenCL ارائه میکنیم. بخش 3 بر اجرای الگوریتم کریجینگ سریال، تجزیه و تحلیل نقاط حساس و تکنیک های موازی سازی مربوطه تمرکز دارد. در بخش 4 ، طراحی و اجرای الگوریتم کریجینگ جهانی موازی را شرح می دهیم. بخش 5 نتایج تجربی و تجزیه و تحلیل را ارائه می دهد. در نهایت، ما نتایج خود را در بخش 6 بیان می کنیم.
2. پس زمینه
2.1. اصل الگوریتم درون یابی جهانی کریجینگ
الگوریتم کریجینگ جهانی نوعی از الگوریتم SI بهینه خطی بدون سوگیری است. برخلاف سایر الگوریتمهای متداول SI، مانند Voronoi و روش وزندهی معکوس فاصله [ 36 ]، همبستگی فضایی بین نقاطی که باید درون یابی شوند و نقاط مجاور آنها را در نظر میگیرد و همچنین خطای تخمین را ارائه میدهد. الگوریتم کریجینگ جهانی نتایج درون یابی دقیق تری را ارائه می دهد و به طور گسترده در منطقه درونیابی زمین شناسی کاربرد دارد. اصل الگوریتم با رابطه (1) بیان می شود:
جایی که ز∗(ایکس0)ز*(ایکس0)مقدار در نقطه ای است که باید درون یابی شود و λمن�مننشان دهنده ضریب وزنی نقطه است منمن، با مقدار اندازه گیری شده ز(ایکسمن)ز(ایکسمن). زمانی که انتظار متغیر تصادفی ز( x )ز(ایکس)یک متغیر در منطقه مورد علاقه است، ما داریم،
در این مورد، الگوریتم کریجینگ جهانی برای درونیابی مورد نیاز است. در معادله (2) m ( x )متر(ایکس)تابع دریفت است که می تواند به صورت زیر نمایش داده شود
جایی که fل( x )�ل(ایکس)یک معادله شناخته شده است و تولتولپارامتر ناشناخته است. برای اطمینان از اینکه مقادیر ارزیابی شده و برآورد شده تا حد امکان مشابه هستند، الگوریتم درون یابی جهانی کریجینگ باید دو شرط زیر را برآورده کند.
-
شرط 1: شرط بدون تعصب، یعنی مقدار مورد انتظار تفاوت بین مقادیر ارزیابی شده و تخمینی صفر است. E[ز∗(ایکس0) – Z(ایکس0) ]≡0�[ز*(ایکس0)–ز(ایکس0)]≡0، که منجر به معادله می شود: ∑ni = 1λمن= 1∑من=1��من=1. با ترکیب آن با معادلات (1) و (3)، الگوریتم کریجینگ جهانی را می توان با معادله (4) بیان کرد.
-
شرط 2: شرایط حداقل واریانس برآورد شده. برای به حداقل رساندن واریانس بین مقدار تخمینی و اندازه گیری شده، الگوریتم درون یابی کریجینگ جهانی باید شرایط زیر را برآورده کند.
با استفاده از معادلات (1) و (5) می توانیم معادله (6) را بدست آوریم.
جایی که γ�به معنای تابع تغییر است. با استفاده از روش ضریب لاگرانژ و معادلات (4) و (6) می توانیم تابع هدف را همانطور که در رابطه (7) نشان داده شده است، بدست آوریم.
با گرفتن مشتقات جزئی از λمن�منو تولتولو با صفر کردن آنها، مجموعه معادلات الگوریتم کریجینگ جهانی را بدست می آوریم. مقادیر تخمینی نقاط مورد نظر با حل معادلات مربوطه به صورت ماتریسی به دست می آید که شامل یک سری عملیات محصول برای مقدار اندازه گیری شده و وزن متناظر هر نقطه است.
2.2. محاسبات ناهمگن
یک سیستم محاسباتی ناهمگن شامل پردازندههای مختلف با عملکرد یا عملکرد متنوع است که از طریق یک ساختار ارتباطی خاص به یکدیگر متصل میشوند. به طور کلی، آنها شامل یک یا چند ریزپردازنده همه منظوره و پردازنده های شتابدار ویژه هستند. در حال حاضر، پرکاربردترین پلتفرمهای محاسباتی ناهمگن شامل CPU و GPU هستند. NVIDIA اولین GPU عمومی را در سال 1999 منتشر کرد که یک پردازنده مشترک اختصاصی بود که برای حل مشکل محاسبات پیچیده طراحی شده بود [ 37]]. به دلیل ساختار چند هسته ای بسیار موازی و پهنای باند دسترسی بالاتر به حافظه، GPU ظرفیت محاسباتی بالاتر و توان عملیاتی حافظه بالاتری را نسبت به CPU امروزی ارائه می دهد. با پشتیبانی CUDA و OpenCL، به تدریج به یک نوع پردازنده همه منظوره تبدیل شده است. در 18 ژوئن 2012، Intel Cooperation پلت فرم MIC (معماری هسته های یکپارچه بسیاری) را معرفی کرد که یک معماری چند هسته ای است که با یک GPU متفاوت است [ 38] .]. MIC یک پردازنده مشترک با معماری چند هسته ای × 86 است. این هسته ها در یک گره محاسباتی به عنوان تجهیزات جانبی سخت افزاری کمک پردازنده ادغام می شوند و با CPU کار می کنند. MIC با مجموعه دستورات CPU × 86 و مجموعه دستورالعمل های تک دستورالعمل-چندین داده سازگار است، که می تواند دشواری پیوند را از یک کلاستر سنتی به معماری MIC کاهش دهد. علاوه بر این، از استراتژی های برنامه نویسی پیچیده اما انعطاف پذیر پشتیبانی می کند. بنابراین، MIC توسعه اپلیکیشن را وارد دوره جدیدی کرده است. ترکیب CPU و MIC گزینه جدیدی برای محاسبات ناهمگن فراهم می کند.
آزمایش های ارائه شده در این مطالعه بر روی دو پلت فرم محاسباتی ناهمگن انجام شد: یک پلت فرم CPU + GPU به نام Shelob واقع در دانشگاه ایالتی لوئیزیانا در ایالات متحده و یک پلت فرم CPU + MIC در دانشگاه Tsinghua در چین.
2.3. مدل برنامه نویسی OpenCL
OpenCL اولین استاندارد عمومی برنامه نویسی موازی برای محاسبات ناهمگن است. در اصل توسط Apple Incorporated توسعه داده شد، و رایگان، کراس پلتفرم، با قابلیت همکاری خوب است [ 39 ]. OpenCL یک محیط برنامه نویسی یکپارچه را برای توسعه دهندگان نرم افزار فراهم می کند. توسعه نرم افزار برای سرورهای محاسباتی با کارایی بالا، سیستم های محاسباتی رومیزی و دستگاه های دستی، و همچنین برنامه های کاربردی در پردازنده های چند هسته ای (CPU/MIC)، پردازنده های گرافیکی، پردازنده های سیگنال دیجیتال و سایر پردازنده های چند هسته ای را تسهیل می کند. OpenCL زمینه های کاربردی زیادی دارد و آینده امیدوار کننده ای در بازار مصرف دارد.
OpenCL به جای یک زبان در حال توسعه یک پیاده سازی است. این زبان برنامه نویسی C مانند (بر اساس C99) را برای توسعه یک تابع هسته که می تواند بر روی دستگاه های OpenCL مختلف و گروهی از رابط های برنامه نویسی برنامه (API) اجرا شود، ارائه می دهد که می تواند پلتفرم های ناهمگن را تعریف و کنترل کند. OpenCL دو مکانیزم محاسباتی موازی [ 35 ] را فراهم می کند، به عنوان مثال: (1) بر اساس تقسیم بندی کار. و (2) بر اساس تقسیم بندی داده ها. طبق کتابچه راهنمای رسمی توسعه OpenCL، الگوریتم ها/برنامه های ساخته شده می توانند روی تجهیزات مختلفی اجرا شوند. علاوه بر این، OpenCL از اجرای چندین سطح موازی سازی پشتیبانی می کند و هر سطح موازی را می توان به طور موثر بر روی سخت افزار در معماری های همگن یا ناهمگن نگاشت. در طول طراحی و توسعه یک الگوریتم موازی که با مشخصات OpenCL مطابقت دارد، پیروی از چهار مدل تجویز شده مهم است .، مدل پلت فرم، مدل پیاده سازی، مدل حافظه و مدل برنامه نویسی. مدل پلتفرم یک توصیف سطح بالا از سیستم محاسباتی ناهمگن با انتزاعاتی از پایه سخت افزاری سیستم است. مدل پیادهسازی نحوه اجرای کرنلها بر روی پلتفرم OpenCL و نحوه تعامل هسته با پایان میزبان را توضیح میدهد. مدل حافظه انتزاعی از فضای حافظه زیربنایی است که ناحیه حافظه تنظیم شده در OpenCL را توصیف می کند و تعاملات فضاهای حافظه مختلف را در طول محاسبات تعریف می کند. مدل برنامه نویسی یک انتزاع سطح بالا از برنامه های کاربردی است که توسط توسعه دهندگان برنامه پیاده سازی شده است، که نگاشت برنامه OpenCL با میزبان و واحد پردازش را با فضاهای حافظه تعریف می کند.
اگر در برنامه نویسی OpenCL انواع حافظه مناسب در نظر گرفته شود، یک الگوریتم موازی به عملکرد بهتری دست خواهد یافت. OpenCL یک سلسله مراتب حافظه چهار سطحی را برای دستگاه محاسباتی تعریف می کند: حافظه جهانی، ثابت، محلی و خصوصی. حافظه جهانی می تواند توسط همه عناصر پردازش به اشتراک گذاشته شود، اما تاخیر دسترسی بالایی دارد. حافظه ثابت همچنین برای همه واحدهای محاسباتی دستگاه قابل مشاهده است، جایی که بخشی از حافظه جهانی است. هر عنصر از حافظه ثابت به طور همزمان برای همه موارد کار قابل دسترسی است. حافظه محلی متعلق به واحد محاسباتی است و معمولاً روی تراشه پیادهسازی میشود، جایی که همه موارد کاری در یک گروه کاری به اشتراک گذاشته میشوند. تأخیر دسترسی پایینی دارد، اما ظرفیت آن محدود است. حافظه خصوصی متعلق به یک مورد کاری است،
OpenCL پشتیبانی گسترده ای را از تولید کنندگان عمده کمک پردازنده به دست آورده است، و دارای مزایای متن باز و چند پلت فرم بودن [ 39 ] است، بنابراین در این مطالعه، ما از OpenCL به عنوان ابزار توسعه خود برای پیاده سازی الگوریتم کریجینگ جهانی موازی بر روی محاسبات ناهمگن مختلف استفاده کردیم. بستر، زمینه.
3. الگوریتم کریجینگ جهانی سریال
3.1. پیاده سازی الگوریتم کریجینگ جهانی سریال
وظیفه اصلی در اجرای الگوریتم سریال، انتخاب یک مدل تابع تغییر فضای مناسب و همچنین توسعه کد برای این مدل تابع تغییر است. در این مطالعه، ما مقدار تخمین زده شده برای هر نقطه را با استفاده از رویکرد جستجوی نقاط همسایه محاسبه می کنیم.
3.1.1. انتخاب مدل تابع تغییر
مدل تابع تغییرات را می توان به سه دسته در آمار زمین تقسیم کرد: (1) مدل با آستانه [ 40 ] که شامل یک مدل کروی، یک مدل شاخص و یک مدل گاوسی است. (2) مدل بدون آستانه [ 2 ] که شامل یک تابع توان و یک مدل خطی است. و (3) مدل اثر حفره [ 41 ]. ما از مدل کروی، که اغلب در آمار زمین استفاده میشود، به عنوان تابع واریوگرام الگوریتم کریجینگ جهانی سریال خود استفاده میکنیم. مدل کروی را می توان با رابطه (8) بیان کرد:
جایی که ج0ج0اثر قطعه، c آستانه جزئی مدل نیمه واریوگرام و a محدوده تأثیر است.
3.1.2. پیاده سازی الگوریتم سریال
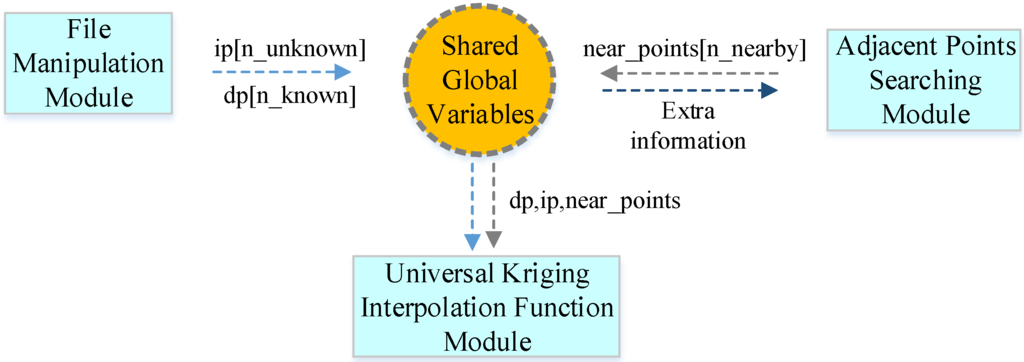
با پیروی از اصل الگوریتم کریجینگ جهانی، با استفاده از تابع تغییر انتخاب شده، الگوریتم سریال را می توان بر اساس سه جزء پیاده سازی کرد: (1) ماژول دستکاری فایل (FMM). (2) ماژول جستجوی نقاط مجاور (APSM). و (3) ماژول تابع درونیابی جهانی کریجینگ (UKIFM). FMM مسئول خواندن فایل شکل ورودی برای بدست آوردن مختصات سه بعدی برای نقاط شناخته شده و سایر اطلاعات است. هنگامی که نتایج درون یابی آماده شد، این ماژول داده ها را نیز به عنوان خروجی می نویسد. این توابع با استفاده از یک کتابخانه تبدیل فرمت داده های مکانی منبع باز، GDAL (کتابخانه انتزاعی داده های مکانی) [ 16 ] پیاده سازی می شوند. APSM عمدتاً بر محاسبه مختصات صفحه تمرکز دارد ( x ، y )(ایکس، �)از نقاط مجهول با توجه به محدوده مختصات نقاط شناخته شده و با استفاده از یک گام ثابت. n نقطه همسایه هر نقطه ناشناخته جستجو می شود که در آن روش جستجو از الگوریتم k-نزدیکترین همسایگی [ 42 ] استفاده می کند ، که k همسایه نقطه جستجو را جستجو می کند. ماژول UKIFM هسته عددی مورد استفاده برای درونیابی است ( شکل 1 را ببینید ).
همه ماژول ها از برخی متغیرهای جهانی مشترک برای تکمیل تعامل داده ها و پردازش داده ها استفاده می کنند. اول، الگوریتم سریال به دو آرایه سراسری نیاز دارد، یعنی dp دوگانه[n_known] و ip[n_unknown] در FMM، که در آن اولی برای نقاط شناخته شده و دومی برای نقاطی است که درون یابی انجام می شود. بنابراین، آرایه dp[n_known] برای ذخیره داده های استخراج شده از فایل شکل ورودی مقداردهی اولیه می شود و آرایه ip[n_unknown] با اطلاعات مختصات صفحه پر می شود، به عنوان مثال ، ( x ، y )(ایکس، �)، برای هر نقطه ناشناخته با جستجوی نقاط مناسب با طول گام ثابت در مقیاس جهانی برای کل تصویر ورودی. دوم، در طول فرآیند جستجو، یک آرایه اضافی به نام double near_points[n_nearby] معرفی می شود تا n_nearby نقطه مجاور یافت شده برای هر نقطه ناشناخته را ذخیره کند. سوم، UKIFM از مختصات هواپیما استفاده می کند ( x ، y )(ایکس، �)از نقاط مجهول و مختصات نقاط مجاور متناظر آنها برای محاسبه مقادیر تخمینی، که همراه با مختصات خروجی می شوند، به عنوان مثال ، ( x ، y ، z )(ایکس، �، �)برای این نکات ناشناخته
به طور خاص، الگوریتم سریال را می توان با چهار مرحله زیر به تفصیل بیان کرد.
-
مرحله (1): اطلاعات داده را بخوانید، به عنوان مثال ، ( x ، y ، z )(ایکس، �، �)مختصات سه بعدی نقاط شناخته شده از فایل های منبع.
-
مرحله (2): مختصات صفحه نقاط مجهول را با توجه به محدوده مختصات نقاط شناخته شده محاسبه کنید. بر اساس نقاط شناخته شده، نقاطی را که باید با یک فاصله زمانی مشخص درون یابی شوند انتخاب کنید و سپس مختصات صفحه مربوطه آنها را محاسبه کنید. ( x ، y )(ایکس، �).
-
مرحله (3): یک درخت kd با استفاده از اطلاعات مختصات سه بعدی برای نقاط شناخته شده ایجاد کنید و سپس طبق الگوریتم نقاط مجاور (در میان نقاط شناخته شده) را برای هر نقطه مجهول جستجو کنید.
-
مرحله (4): اطلاعات مختصات را انتقال دهید ( x ، y )(ایکس، �)برای نقاط مجهول و مختصات سه بعدی ( x ، y ، z )(ایکس، �، �)از نقاط همسایه آنها به UKIFM برای محاسبه مقادیر تخمینی نقاط مجهول.
به طور خاص، مرحله (2) و مرحله (3) برای ارائه نقاط شناخته شده و اطلاعات مختصات صفحه برای نقاطی که باید درج شوند استفاده می شود، در حالی که مرحله (4) جزء اصلی محاسبه الگوریتم کریجینگ جهانی سریال است. . در واقع، اجرای مرحله (4) پیچیده است و میتوان آن را به هفت مرحله فرعی (Sub-steps a–g) ( شکل 2 ) به شرح زیر تقسیم کرد.
-
مرحله فرعی الف: فاصله بین نقطه ای که باید درون یابی شود و نقاط مجاور آن (نقاط شناخته شده، که مجموع آن n است ) را محاسبه کنید، به عنوان مثال ، د1، د2، ⋯ ، دnد1، د2، ⋯، د�.
-
مرحله فرعی b: مقادیر فاصله بدست آمده را به ترتیب صعودی مرتب کنید.
-
مرحله فرعی ج: مقادیر مرتب شده را به k گروه تقسیم کنید.
-
مرحله فرعی د: میانگین فاصله را محاسبه کنید ساعتمن¯¯¯ساعتمن¯در هر گروه با توجه به ارزش هایشان. سپس پارامترهای تخمین زده شده تابع تغییرات با استفاده از رابطه (8) محاسبه می شود. با توجه به حالت نظری انتخاب شده تابع تغییرات، برازش تابع برای تعیین تابع تغییرات و ضریب رگرسیون انجام می شود.
-
مرحله فرعی e: مقادیر فاصله نقاط نمونه برداری و نقطه را در تابع تغییرات قرار دهید تا ماتریس ضریب ساخته شود.
-
مرحله فرعی f: حل ماتریس معکوس ماتریس ضریب در مرحله فرعی (ه).
-
مرحله فرعی g: مقدار تخمینی نقطه مجهول را تا زمانی که تمام نقاط پردازش نشده اند محاسبه کنید.
3.2. تجزیه و تحلیل نقاط داغ و رویکرد موازی سازی مربوطه
پس از انجام تحلیل مصرف زمان با استفاده از الگوریتم کریجینگ جهانی سریال، متوجه شدیم که مرحله 4، یعنیماژول تابع درون یابی کریجینگ، به 85.2٪ تا 97.6٪ از کل زمان سپری شده برای اندازه های مختلف داده، به عنوان مثال، مجموعه داده های کوچک، متوسط و بزرگ نیاز دارد. درصد مصرف زمان ارتباط نزدیکی با تعداد نقاط درونیابی درگیر و جستجوی نقاط مجاور داشت. بنابراین، با افزایش تعداد، درصد مصرف زمان تمایل به افزایش داشت. به عنوان مثال، تعداد نقاط جستجو در آزمایش ما روی 6 تنظیم شد، اما زمانی که این عدد 12 بود، که توسط اکثر برنامههای کاربردی دنیای واقعی استفاده میشود، نسبت مصرف زمان به 90.0% تا 95.6% با گروههای داده مشابه افزایش یافت. . واضح است که مرحله 4 نقطه اتصال در الگوریتم سریال است.
بنابراین، برای تسریع کامل الگوریتم کریجینگ جهانی سریال برای به دست آوردن عملکرد خوب، نقطه اتصال، یعنی مرحله 4، نیاز به بررسی کامل دارد. در این مرحله، محاسبات نقاط مجهول مستقل از یکدیگر است که روند موازی سازی را تسهیل می کند. بنابراین، مطالعه حاضر عمدتاً بر اجرای موازی سازی برای این مرحله متمرکز شده است. لازم به ذکر است که در اجرای موازی برخی از مسائل کاربردی خاص مانند تخمین واریوگرام و تنظیمات پارامترها در نظر گرفته نمی شود. بنابراین، پارامترهای مورد استفاده در الگوریتم موازی پیشنهادی با درون یابی سریال شناسایی می شوند.
4. طراحی و پیاده سازی الگوریتم کریجینگ جهانی موازی با OpenCL
4.1. طراحی و چارچوب الگوریتم موازی
با توجه به تحلیل داده شده در بالا، واضح است که مرحله 4 باید موازی شود. با این حال، در طول طراحی و اجرای الگوریتم موازی کارآمد متناظر، جنبههایی مانند ساختار داده، انتقال داده بین میزبان و دستگاهها، دانهبندی پارتیشن وظیفه و متعادلسازی بار برای انواع مختلف تجهیزات همکار نیز نیازمند توجه کامل است [43 ] . برخی از این موضوعات مستقل از برخی دیگر هستند، در حالی که وابستگی های خاصی به برخی دیگر وجود دارد.
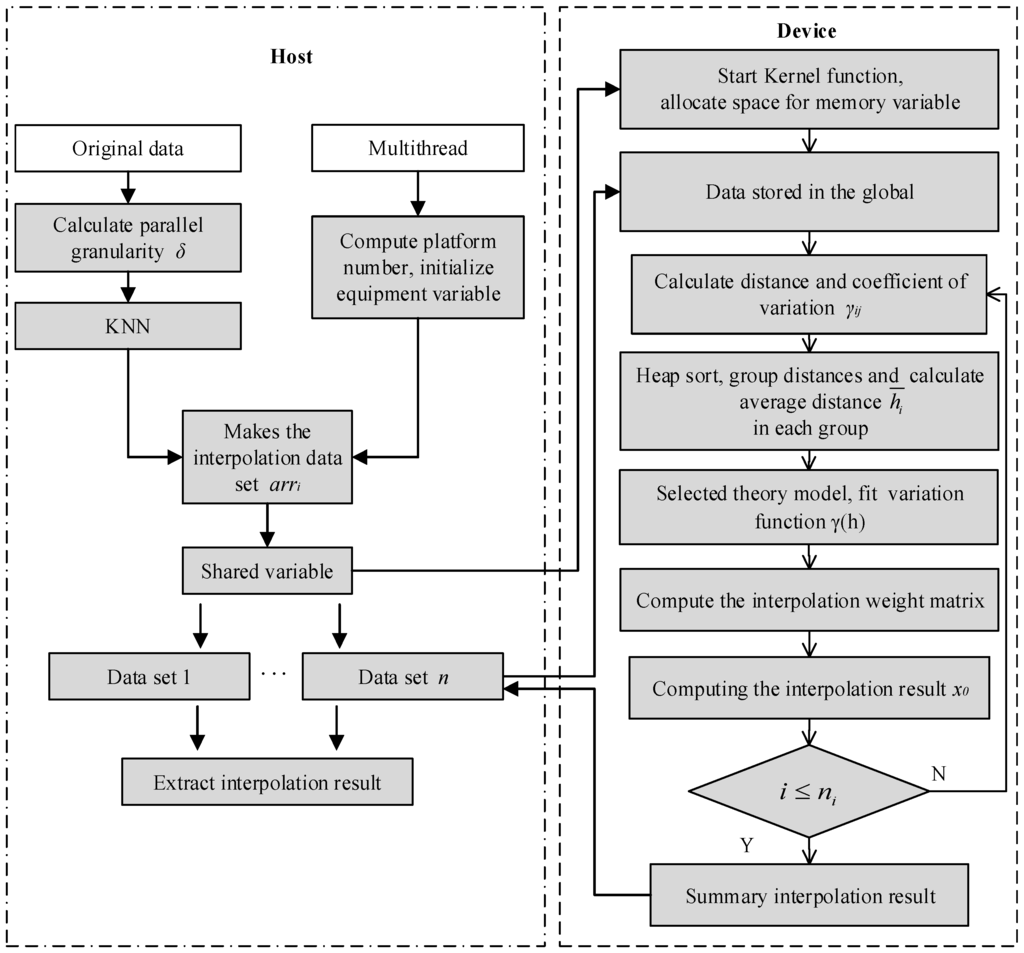
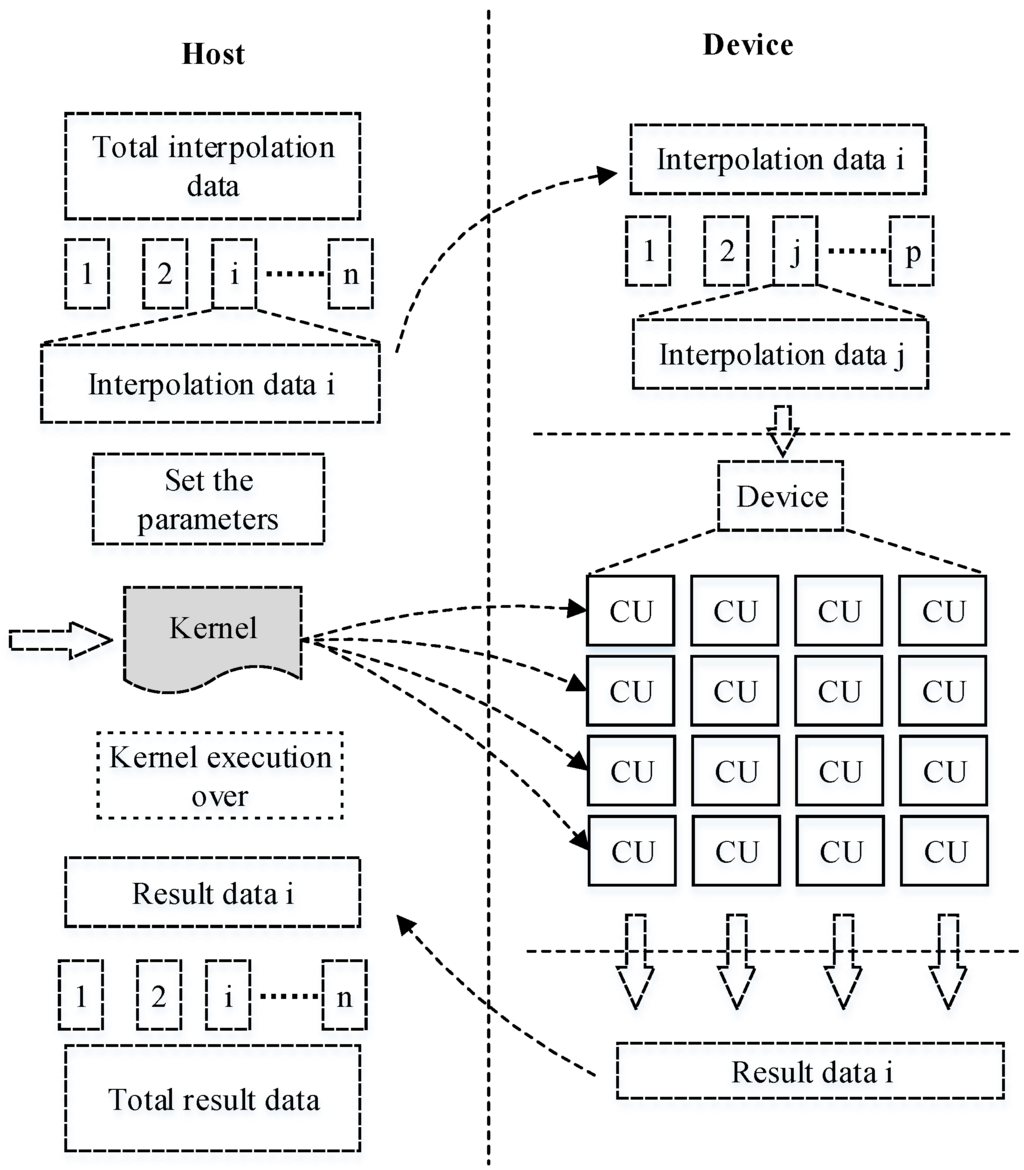
برای در نظر گرفتن کامل جنبههایی مانند پلتفرمهای مختلف، تعداد پردازندههای تسریعشده مجهز و محدودیتهای حافظه سیستم، چارچوب کلی الگوریتم موازی نشاندادهشده در شکل 3 را پیشنهاد میکنیم .
مطابق شکل 3 ، چارچوب را می توان به دو بخش تقسیم کرد: میزبان و انتهای دستگاه. بدیهی است که محاسبه اصلی در دستگاه انجام می شود. میزبان فقط وظایف کنترلی مانند توزیع داده ها و جمع آوری نتایج را انجام می دهد. میزبان و دستگاه توسط برخی از متغیرهای مشترک مرتبط هستند.
برای توسعه یک الگوریتم موازی با OpenCL، طراحی و پیادهسازی ماژولهایی که به شدت با چارچوب OpenCL مطابقت دارند، بسیار مهم است. هنگام طراحی الگوریتم کریجینگ جهانی موازی برای تجهیزات محاسباتی با کارایی بالا، تمرکز اصلی بر این است که چگونه مرحله 4، نقطه اتصال، به طور کامل با چارچوب موازی در OpenCL ترکیب شود. این مشکل عمدتاً به ترکیب خاص، طراحی و اجرای چهار مدل برنامه نویسی مختلف بستگی دارد: (1) مدل پلت فرم. (2) مدل اجرا. (3) مدل حافظه. و (4) مدل برنامه نویسی. این مدل های برنامه نویسی مکمل یکدیگر هستند و در چارچوب کلی ادغام می شوند. بنابراین، ممکن است مدل های دیگری در هنگام طراحی و اجرای یک مدل خاص درگیر شوند. طبق این قاعده در ادامه
4.2. پیاده سازی مدل پلت فرم
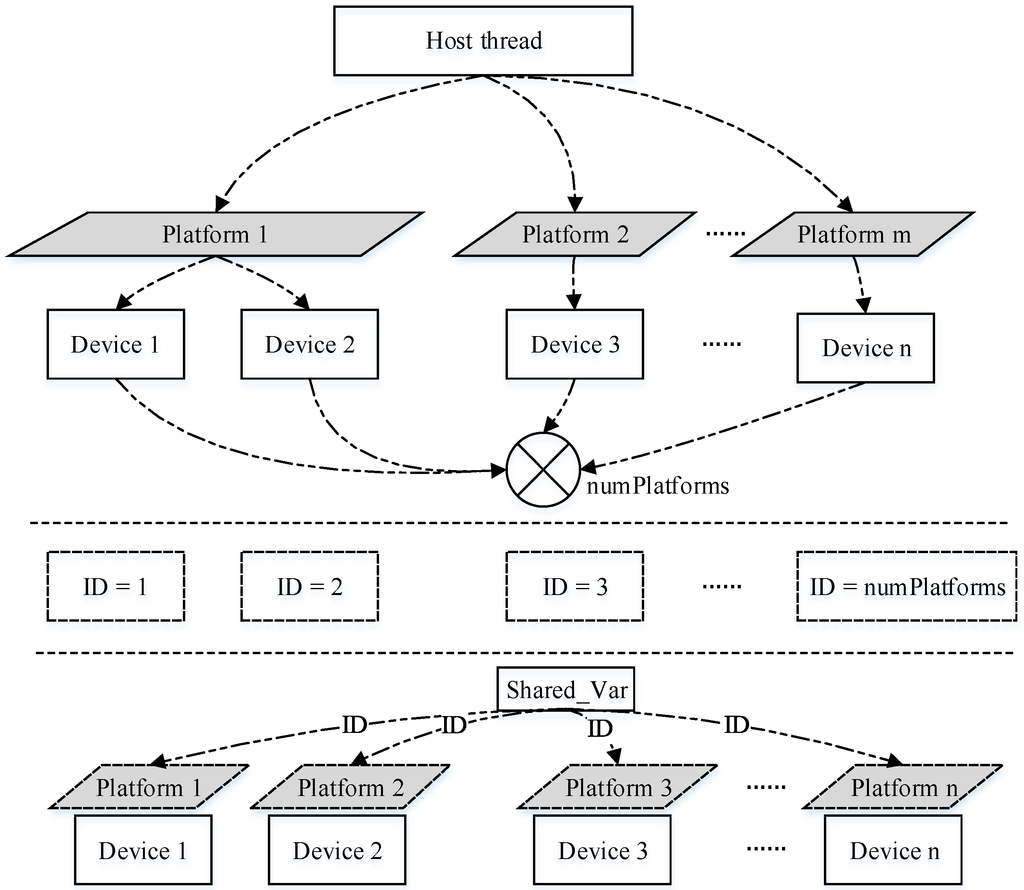
مدل پلت فرم OpenCL یک تجلی را در هنگام استفاده از یک پلت فرم ناهمگن تعریف می کند [ 44 ]. این امر اجرای زیربنایی تجهیزات را مسدود می کند، زیرا توسعه دهندگان فقط می توانند در قالب یک دستگاه از آن استفاده کنند، بنابراین باید یک الگوی همکاری اضافی بین میزبان و چندین دستگاه طراحی شود. ابتدا تابع ایجاد thread ها با توجه به تعداد دستگاه ها نخ های مناسب ایجاد می کند. سپس، مراحل بعدی شامل ایجاد پلتفرم، انتخاب تجهیزات و ایجاد بافر است. بنابراین، دستگاهها میتوانند تمام وظایف محاسباتی را به صورت مشترک انجام دهند و پیادهسازی مربوطه در شکل 4 نشان داده شده است .
در شکل 4، رشته اصلی اطلاعات را با رشته های فرزند خود به اشتراک می گذارد. این اطلاعات شامل اطلاعات انتساب کار، اطلاعات پلت فرم که به تجهیزات فعلی اشاره می کند و اطلاعات متغیر برای زمان درج به اشتراک گذاشته شده توسط نخ ها می باشد. رشته اصلی ابتدا تعداد پلتفرمهای موجود و دستگاههای موجود در هر پلتفرم را به دست میآورد، قبل از اینکه تعداد کل دستگاههای موجود را محاسبه کند. در مرحله بعد، تعداد معادلی از رشته ها ایجاد می شود و برخی از متغیرهای مشترک که اطلاعات را با نخ های فرزند تغییر می دهند ساخته می شوند. بنابراین، شماره شناسه دستگاه ذخیره شده در متغیرهای مشترک توسط هر قطعه از تجهیزات، مقداردهی اولیه می شود. متعاقباً، نخهای فرزند عملیاتی را برای بازآفرینی پلتفرمها انجام میدهند و میتوانند اطلاعات دستگاه مربوطه را که توسط رشتههای اصلی ارائه میشود، به دست آورند.
در آزمایشهای زیر، از دو پلتفرم محاسباتی ناهمگن استفاده کردیم: یک پلتفرم GPU مجهز به دو کارت GPU و یک پلت فرم Intel Xeon Phi مجهز به سه کارت MIC. به طور کلی برای پیاده سازی پلتفرم ها رویه مشابهی دنبال شد. در پلتفرمهای محاسباتی GPU، دو کارت GPU به عنوان دستگاههای OpenCL در نظر گرفته میشوند. ابتدا، فرآیند اصلی در انتهای میزبان ایجاد شد، جایی که مسئولیت آن مدیریت پلتفرمهای OpenCL و دستگاههای OpenCL بود. در مرحله بعد، پس از اینکه فرآیند اصلی این دو دستگاه OpenCL را پیدا کرد، دو فرآیند فرعی ایجاد شد که عمدتاً پس از مقداردهی اولیه دستگاه OpenCL عمل میکردند. فرآیند اولیه سازی عمدتاً شامل ایجاد زمینه، ایجاد بافر، ایجاد صف فرمان، ایجاد برنامه و تنظیم پارامترهای هسته بود. سرانجام،
4.3. پیاده سازی مدل اجرا
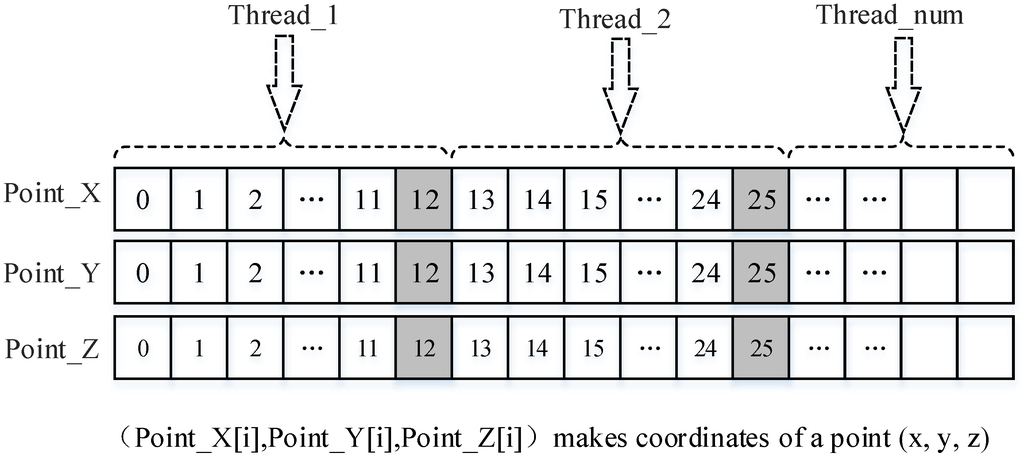
مدل اجرای OpenCL روشی را برای اجرای تابع هسته که روی تجهیزات پشتیبانی کننده OpenCL اجرا می شود، تعریف می کند. برنامه OpenCL شامل دو بخش است: برنامه ماشین میزبان و یک یا چند هسته. با این حال، مدل اجرای OpenCL جزئیات برنامه ماشین میزبان را تعریف نمی کند. بنابراین، هنگامی که چندین دستگاه وجود دارد، توسعه دهنده همچنان به کار دقیقی نیاز دارد تا حجم کار را تقسیم کند و وظایف را به طور مشترک طراحی کند. در این مطالعه، تابع هسته از بخشی از تابع کریجینگ جهانی سریال که نیاز به موازی سازی دارد، تبدیل شد. هنگام استفاده از روش موازی تجزیه داده ها، دستگاه میزبان برنامه های تابع هسته را در هر دستگاه توزیع می کند (در این مورد، واحدهای محاسباتی (CUs)). این برنامه های هسته توسط رشته های مربوطه خود اجرا شدند.شکل 5 ). لازم به ذکر است که محاسبات برای هر نقطه مجهول مستقل از یکدیگر هستند، بنابراین نیازی به در نظر گرفتن ارتباط بین هسته ها یا نخ ها نبود.
همانطور که در شکل 5 نشان داده شده است ، محاسبه را می توان در یک زمان برای یک مجموعه داده کوچک تکمیل کرد. این فرآیند شامل عملیات هایی مانند پر کردن داده ها، محاسبه و بازیابی نتایج است. با توجه به اینکه مجموعه داده های نسبتاً بزرگی باید محاسبه شوند، استفاده از یک عملیات حلقه برای انجام کار به دلیل محدودیت های حافظه مفید است. در این حالت ابتدا داده ها با توجه به ظرفیت حافظه و تعداد CU به n گروه تقسیم می شوند (نشان داده شده در سمت چپ در شکل 5 ). هر گروه، به عنوان مثال، گروه i ، در طول یک تکرار به دستگاه ها تبدیل می شود و سپس به p تجزیه می شود.بخش هایی که برای محاسبه با یک CU مناسب هستند. به این ترتیب، این عملیات را می توان چندین بار در طول یک تکرار برای پردازش مقادیر زیادی از داده ها تکرار کرد. علاوه بر این، میزبان باید توزیع داده ها را بر روی چندین دستگاه فرموله کند تا از پردازش منظم داده ها اطمینان حاصل کند.
4.4. پیاده سازی مدل حافظه
مدل حافظه نشان می دهد که چگونه OpenCL حافظه را بین میزبان و دستگاه ها برای تعامل داده ها تقسیم می کند، جایی که ما از شی حافظه برای تکمیل انتقال داده استفاده می کنیم. در این مطالعه، مشکل پیاده سازی حافظه دارای دو جنبه است: (1) پیاده سازی حالت حافظه بر روی میزبان. و (2) اجرای حالت حافظه در دستگاه های محاسباتی. که در ادامه به تفکیک توضیح داده شده است.
برای جلوگیری از اتلاف وقت در تخصیص و تخصیص مکرر حافظه و همچنین مشکل کمبود حافظه در دستگاه های محاسباتی، حافظه باید در حین درونیابی تا حدی کنترل شود. در این مطالعه حداکثر حد مجاز است V�، که با کنترل درصد حافظه یا دادن اندازه مشخص مشخص می شود. کد بهینه سازی به شرح زیر است.
در نهایت، بافرها توسط رشته های مربوطه در هر دستگاه ساخته می شوند. بنابراین، عملیاتی مانند انتقال واحد داده درون یابی به بافر و بازگرداندن نتایج را می توان به طور مداوم پردازش کرد. انتقال داده ها بین استاد و تجهیزات طی چندین بار تکرار انجام می شود.
- 2.
-
پیاده سازی حالت حافظه در دستگاه های محاسباتی: واحدهای داده ای که نیاز به پردازش دارند را می توان در قالب یک حافظه جهانی بین تابع هسته و تابع فراخوانی هسته به اشتراک گذاشت. تابعی که در دستگاه های محاسباتی قرار دارد، متغیرهایی را در قالب یک حافظه خصوصی برای تکمیل پردازش داده ها در دستگاه ها تعریف می کند.
مقادیر زیادی از داده ها در برنامه پردازش داده های عظیم دخیل هستند، جایی که تعداد زیادی رشته بر روی دستگاه های محاسباتی اجرا می شود، بنابراین حافظه مشترک و حافظه خصوصی ارزشمند می شوند زیرا این منابع معمولاً روی سخت افزار محدود هستند. بنابراین، ما از روشی استفاده میکنیم که مستقیماً متغیر سراسری را چندین بار میخواند و مینویسد، نه اینکه هر بار تمام دادههای درون یابی از متغیر سراسری را در دستگاهها بارگذاری کنیم. این روش بهینهسازی تا حدی بر سرعت پردازش تأثیر میگذارد، اما تعداد رشتههایی را که میتوان همزمان روی دستگاهها اجرا کرد، افزایش میدهد و در نتیجه عملکرد کلی را بهبود میبخشد.
4.5. پیاده سازی مدل برنامه نویسی
مدل برنامه نویسی استراتژی عملیاتی را تعیین می کند که به الگوریتم اجازه می دهد تا موازی شده و بر روی دستگاه های OpenCL اجرا شود. دو مدل برنامه نویسی مختلف در OpenCL وجود دارد: وظایف به صورت موازی و داده ها به صورت موازی [ 39 ]. استفاده از مناسب ترین حالت برای این الگوریتم مهم است.
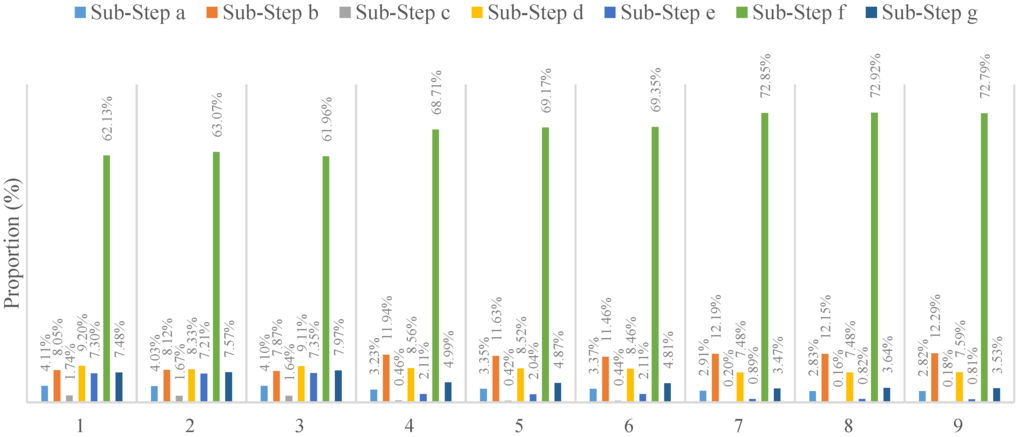
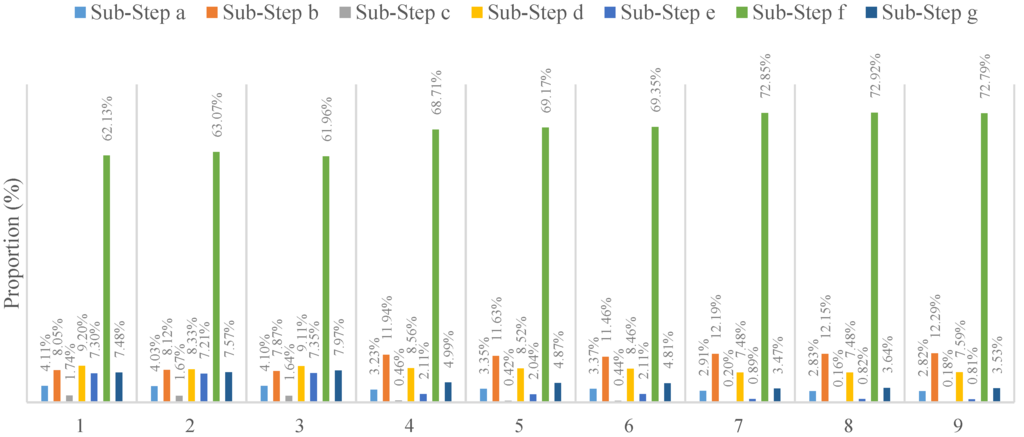
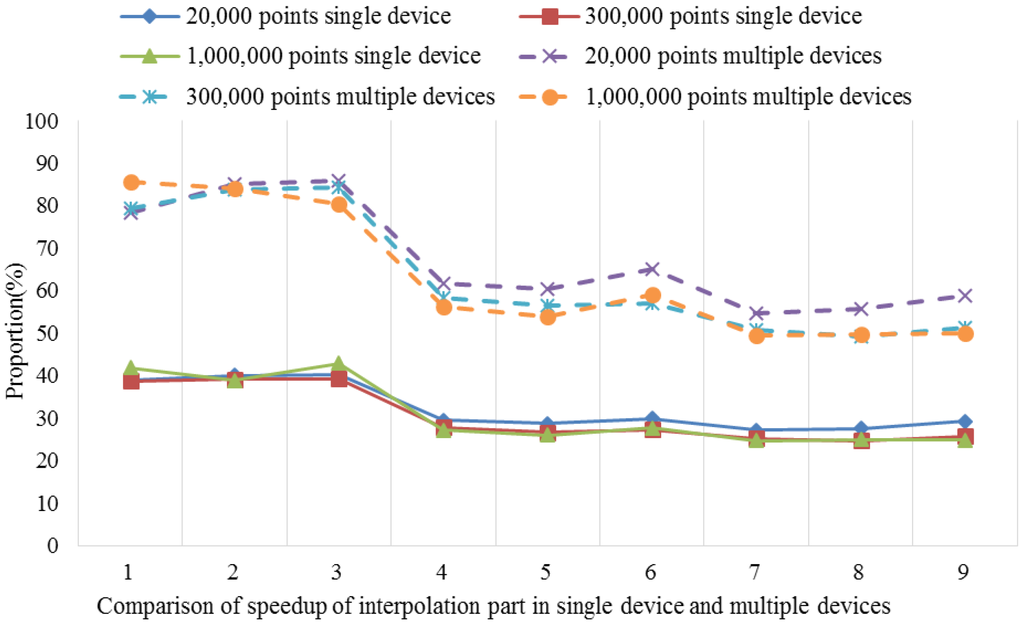
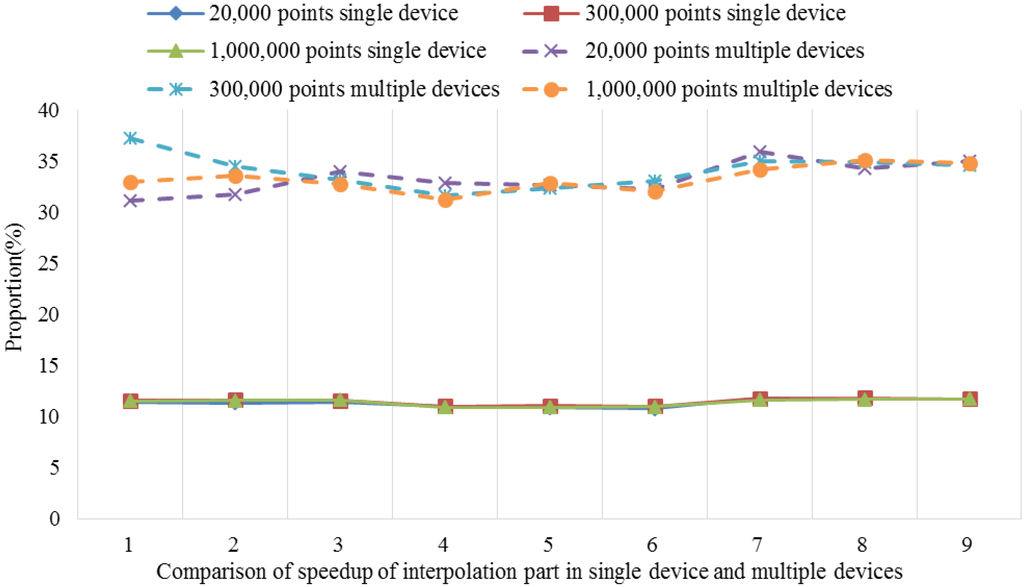
بر اساس بخش 3.1.2 ، هنگام اجرای الگوریتم کریجینگ جهانی موازی، مرحله کلیدی موازی سازی مرحله 4 است که توسط تابع کریجینگ جهانی پیاده سازی می شود. این تابع همچنین دارای هفت مرحله فرعی (a-g) است که عملیاتی مانند مرتب سازی، گروه بندی و محاسبه وارونگی ماتریس را نشان می دهد. با توجه به تجزیه و تحلیل زمان مصرف شده توسط هر مرحله فرعی با استفاده از یک تحلیلگر عملکرد حرفه ای، نتایج برای اندازه های مختلف مجموعه داده با پارامترهای تنظیم مختلف در شکل 7 نشان داده شده است .
شکل 7نشان می دهد که روش محاسبه وارونگی ماتریس 61.9٪ – 72.9٪ از زمان اجرا را برای الگوریتم سریال به خود اختصاص می دهد که بالاترین نسبت در بین تمام مراحل فرعی است و هیچ مرحله دیگری مانند خواندن داده یا جستجوی مجاور ندارد. نکته ها. با این حال، اگر این مرحله را به عنوان نقطه داغ در نظر بگیریم، اثر شتاب بسیار محدود خواهد بود. علاوه بر این، وابستگی هایی در میان مراحل دیگر وجود دارد، بنابراین حالت موازی سازی سطح کار برای این الگوریتم مناسب نیست. در مقابل، داده هایی که نیاز به پردازش دارند را می توان با استفاده از ساختار طراحی شده به صورت موازی اجرا کرد، جایی که هر آیتم کاری نیازی به تعامل با داده های دیگر ندارد و هیچ وابستگی به داده وجود ندارد. بنابراین، این مناسب ترین سطح برای موازی سازی داده ها است.شکل 3 ).
4.6. استراتژی متعادل کردن بار برای چندین دستگاه
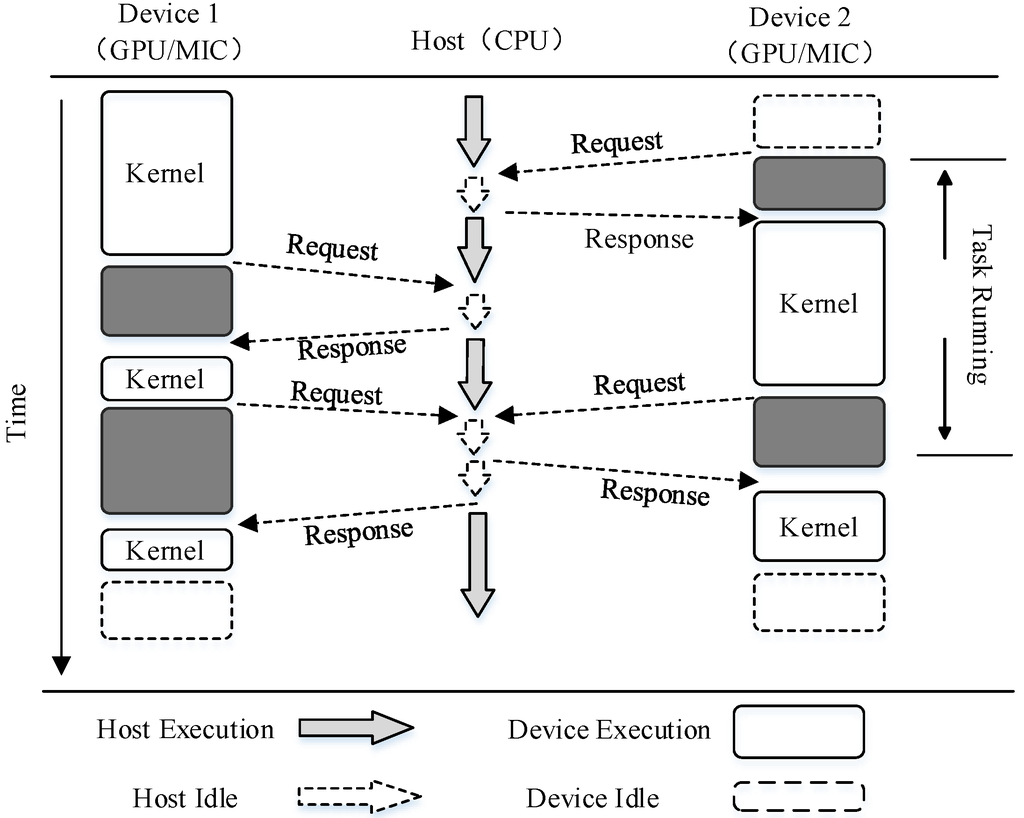
زمانی که چندین دستگاه محاسباتی وجود دارد، باید به ریزدانه بودن پارتیشن وظیفه و مشکل تعادل بار پرداخته شود. رشته اصلی باید قبل از جمع آوری و ترکیب نتایج محاسباتی برای به دست آوردن نتایج نهایی SI، وظیفه کلی را به چندین دستگاه برای پردازش توزیع کند. بر اساس راستیآزمایی تجربی ما، الگوریتم موازی از استراتژی استفاده میکند که حافظه خاص را بر اساس تعداد متوسط تجهیزات تقسیم میکند، جایی که حداکثر تعداد نقاطی را که حافظه میتواند برای درج اجازه دهد به عنوان دانهبندی موازی در نظر میگیرد. علاوه بر این، ما از مکانیسم قفل برای پیاده سازی استراتژی پویا متعادل کننده بار برای محاسبه زمان بندی توزیع کار استفاده می کنیم. اجرای دقیق استراتژی برنامه ریزی متعادل بار در شکل 8 نشان داده شده است.
5. آزمایش ها و تجزیه و تحلیل
5.1. پیکربندی محیط آزمایشی
ما آزمایشهایی را روی دو نوع پلتفرم انجام دادیم: (1) یک پلتفرم مبتنی بر GPU. و (2) یک پلت فرم مبتنی بر Xeon Phi اینتل. پیکربندی سخت افزار در جدول 1 نشان داده شده است . در معماری و طراحی سخت افزاری این دو پلتفرم تفاوت هایی وجود داشت. در این آزمایشها، هدف ما تعیین تفاوتها در شتاب بهدستآمده و ناهمگنی الگوریتم موازی در پلتفرمهای محاسباتی ناهمگن مختلف بود.
5.2. روش و رویه تجربی
در طراحی آزمایش ها ویژگی های زیر را در نظر گرفتیم.
-
تفاوت در عملکرد در پلتفرمهای محاسباتی ناهمگن مختلف همچنین نشاندهنده قابلیت متقابل پلتفرم الگوریتم موازی است.
-
هر پلتفرم محاسباتی ناهمگن به چندین کارت شتاب مجهز بود، به عنوان مثال ، Shelob دارای دو کارت GPU و Tsinghua Intel Xeon Phi سه کارت MIC بود، بنابراین ممکن است به دلیل سخت افزار به کار رفته تفاوت هایی وجود داشته باشد.
-
تعداد رشتههای ایجاد شده میتواند متفاوت باشد، و بنابراین، نحوه انتخاب مناسبترین عدد برای آزمایشها را بررسی کردیم.
-
مجموعه داده های تجربی در اندازه متفاوت بودند، به عنوان مثال ، تعداد نقاط گسسته ای که نیاز به درونیابی در مقیاس متفاوت بود.
-
تنظیمات پارامترهای مورد استفاده توسط الگوریتم می تواند بر عملکرد تأثیر بگذارد، به عنوان مثال، اندازه پیکسل تصویر خروجی و تعداد نقاط همسایه جستجو شده.
-
برای پرداختن به مسائل تعریف شده در بالا، از طرح آزمایشی زیر استفاده کردیم.
-
آزمایش ها بر اساس تعداد کارت های شتاب به دو گروه تقسیم شدند. اولی از یک کارت در هر پلت فرم محاسباتی ناهمگن استفاده کرد و دومی از همه کارت های شتاب دهنده استفاده کرد.
-
در هر گروه آزمایشی، برای هر پلتفرم محاسباتی، تعداد نخ های مناسبی تعیین شد. مجموعه داده ها از نظر اندازه متفاوت بودند و پارامترهای الگوریتم نیز در هر آزمایش تغییر می کردند.
به منظور ارزیابی تفاوت در عملکرد، الگوریتمهای متوالی و موازی در آزمایشها مورد آزمایش قرار گرفتند. برای الگوریتم موازی، تعداد رشتههای ایجاد شده T به انتگرال چند برابر تعداد هستههای ارائه شده توسط پلتفرم تنظیم شد. با این حال، تعداد نهایی نخ ها به مدت زمان سپری شده بستگی داشت. بنابراین، عملکرد سخت افزار می تواند به حداکثر درجه استفاده شود. با توجه به آزمایشهای مختلف با استفاده از مجموعه دادههای مختلف، تعداد رشتههایی با کمترین زمان سپری شده برای Shelob 26880 و برای پلتفرم Intel Xeon Phi 24000 بود.
به منظور تأیید صحت برنامه موازی و عملکرد شتاب، از چندین مجموعه داده با اندازههای مختلف برای ارزیابی الگوریتمهای متوالی و موازی استفاده کردیم. اطلاعات دقیق مربوط به مجموعه داده ها در جدول 2 ارائه شده است .
جدول 2 نشان می دهد که سه گروه از مجموعه داده ها از تصویر اصلی به نام srtm_41_14.tif (دانلود از srtm.csi.cgiar.org) با عملیات تجزیه و تحلیل سریال، مانند تولید خط کانتور و پوشش اشیاء به نقاط با استفاده از نرم افزار ArcGIS، تولید شده است. بر اساس جدول 2 ، تعداد نقاط در مجموعه داده های کوچک، متوسط و بزرگ را می توان به سه مقیاس مختلف اختصاص داد: 20 هزار، 300 هزار و یک میلیون.
برای اجرای الگوریتم موازی روی این پلتفرمهای محاسباتی ناهمگن، از خط فرمان زیر استفاده کردیم:
در جایی که “-d” مسیر مجموعه داده ورودی است که باید توسط الگوریتم کریجینگ جهانی درون یابی شود، “-p” اندازه پیکسل برای تصویر خروجی تولید شده است و “-n” تعداد نقاط جستجو را نشان می دهد.
ما از سرعت بالا برای ارزیابی عملکرد الگوریتم موازی پیشنهادی استفاده کردیم که محبوبترین شاخص برای این منظور است. افزایش سرعت اسپاسپبه صورت زیر تعریف می شود:
جایی که تی1تی1نشان دهنده زمان اجرای برنامه سریال و تیپتیپزمان اجرای الگوریتم موازی با پردازنده های p است . در این مطالعه، الگوریتم کریجینگ جهانی موازی تحت تأثیر عوامل مختلفی مانند اندازه مجموعه داده و تنظیمات پارامتر قرار گرفت. به منظور تعیین تفاوت عملکرد در شرایط مختلف، چندین مقدار افزایش سرعت را در این آزمایش محاسبه کردیم. ابتدا طبق رابطه (9)، سرعت کل الگوریتم موازی و سرعت خاص را فقط برای قسمت UKIFM محاسبه کردیم. دوم، مصرف نسبی زمان توسط هات اسپات به دلیل عوامل مختلف تغییر کرد، بنابراین ما سرعت تئوری فعلی را نیز محاسبه کردیم. سرعت تئوری با استفاده از قانون امدال [ 45 ] محاسبه شد.
برای نابرابری، p c t Pa rپجتیپآ�درصدی از برنامه سریال را نشان می دهد که باید موازی شود و تعداد رشته ها/هسته ها p است . هنگامی که p به بالاترین مقدار در تئوری می رسد، معادله محدودیت شتاب برای برنامه به صورت زیر است.
برای سادگی، استفاده می کنیم اسp e edتوپآاسپههدتوپآ، اسp e edتوپمناسپههدتوپمنو اسp e edتوپتیاسپههدتوپتیبه ترتیب مقادیر افزایش سرعت فوق الذکر را نشان دهد.
5.3. نتایج آزمایش و تجزیه و تحلیل
5.3.1. نتایج تست با یک دستگاه محاسباتی واحد
جدول 3 ، جدول 4 و جدول 5 نتایج تجربی بهدستآمده با استفاده از یک دستگاه شتابدهنده منفرد با سه اندازه مجموعه دادههای مختلف در پلت فرم شلوب را نشان میدهد. برای شرایط یکسان، نتایج تجربی بهدستآمده بر روی پلتفرم Intel Xeon Phi در جدول 6 ، جدول 7 و جدول 8 آورده شده است . در این جداول، n تنظیم پارامتر برای شماره جستجوی همسایگی و p مقدار تفکیک فضایی اصلی است، جایی که وضوح تصویر خروجی در این آزمایش کمتر، مساوی یا بزرگتر از p تنظیم شده است. داده های مورد استفاده برای محاسبه اسp e edتوپتیاسپههدتوپتیاز تشخیص نقطه اتصال الگوریتم سریال به دست آمد.
جدول 3 ، جدول 4 و جدول 5 موارد زیر را نشان می دهد. (1) به طور کلی، الگوریتم موازی عملکرد شتاب خوبی را به دست آورد و می تواند زمان پردازش را تا حدی کاهش دهد. به ویژه، زمانی که ما فقط بخش درون یابی کریجینگ جهانی را در نظر گرفتیم، بالاترین سرعت تا 40× رسید، اما مقدار اسp e e dتوپمناسپههدتوپمنبا افزایش تعداد نقاط جستجو کاهش یافت. (2) اسp e e dتوپمناسپههدتوپمنو اسp e e dتوپتیاسپههدتوپتیهمچنین با افزایش اندازه مجموعه داده کاهش یافت. در تئوری، این روندهای کاهشی عمدتاً به دلیل نیاز به ثبت بیشتر در هر رشته زمانی که شماره رشته ثابت می شد، ایجاد شد. در این شرایط، دانه بندی موازی کاهش یافت و زمان اجرای طولانی تری مورد نیاز بود.
جدول 6 ، جدول 7 و جدول 8 موارد زیر را نشان می دهد. (1) افزایش سرعت روند مشابهی را در Shelob نشان داد. (2) سرعت به دست آمده در پلت فرم Intel Xeon Phi بسیار کمتر از Shelob بود. این عمدتا به دلیل تفاوت در ظرفیت محاسباتی کارت MIC و کارت NVIDIA بود. پیک عدد برای کارت MIC در تئوری 508 GFLOPS (عملیات ممیز شناور گیگا در ثانیه) بود، در حالی که برای کارت NVIDIA 1311 GFLOPS بود و بنابراین، از قبلی قدرتمندتر بود.
5.3.2. نتایج تست با چندین دستگاه محاسباتی
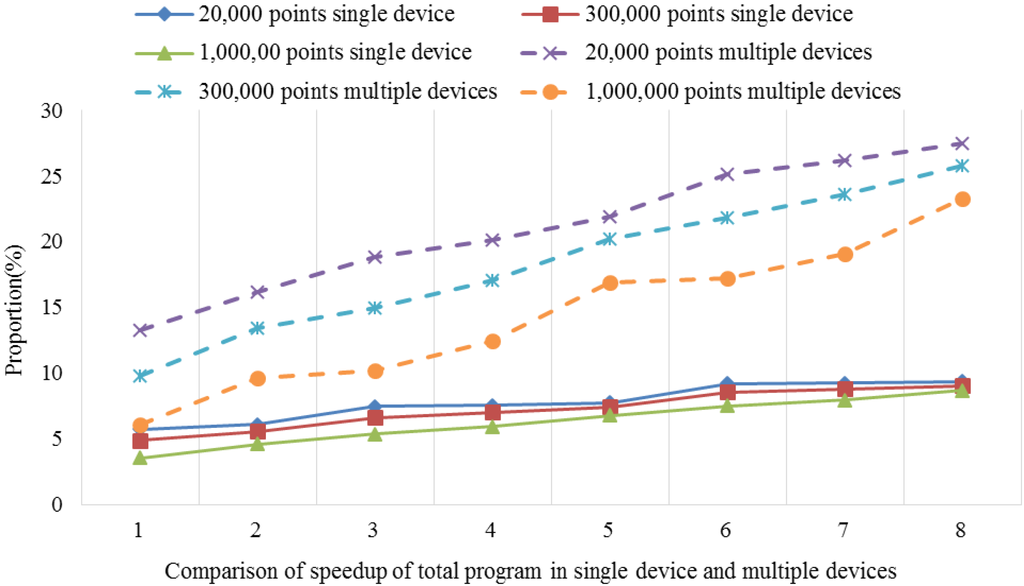
زمانی که از تمام کارت های شتاب دهنده استفاده می شد، یعنی دو کارت GPU در Shelob و سه کارت MIC در Intel Xeon Phi، تعادل بار نیز نقش داشت. به همان روشی که آزمایشهایی که در بالا توضیح داده شد، ما آنها را مقایسه کردیم اسp e e dتوپمناسپههدتوپمنو اسp e e dتوپآاسپههدتوپآبا کارت های شتاب مختلف محاسبه می شود. شکل 9 و شکل 10 سرعت به دست آمده در سکوی شلوب را مقایسه کردند.
با استفاده از چندین دستگاه، سرعت در هر دو مورد تقریبا دو برابر شد. علاوه بر این، نسبت سرعت افزایش زمانی که اندازه مجموعه داده بزرگتر بود افزایش یافت.
شکل 11 و شکل 12 نتایج افزایش سرعت به دست آمده با یک کارت و چند کارت را در پلت فرم Intel Xeon Phi مقایسه می کنند.
به طور مشابه، در مقایسه با یک دستگاه واحد، اسp e e dتوپمناسپههدتوپمنو اسp e e dتوپآاسپههدتوپآسه برابر افزایش یافت که تعداد دستگاه های متعدد بود. علاوه بر این، نسبت سرعت نیز افزایش یافته است.
بنابراین، نتایج این آزمایشها نشان میدهد که افزایش سرعت به صورت خطی در مقایسه با یک دستگاه واحد زمانی که از چندین دستگاه استفاده میکنیم، تغییر میکند، که تأیید میکند استراتژی متعادلسازی بار ما مفید و مؤثر بوده است.
6. نتیجه گیری و جهت گیری های آینده
در این مطالعه، ما عمدتا بر طراحی و اجرای یک الگوریتم درون یابی کریجینگ جهانی موازی با استفاده از مدل برنامه نویسی OpenCL بر روی پلتفرم های ناهمگن تمرکز کردیم. در آینده، کدهای منبع در GitHub در دسترس قرار خواهند گرفت. بر اساس نتایج تجربی می توان نتیجه گیری های زیر را انجام داد.
-
الگوریتم درون یابی جهانی کریجینگ توسعه یافته با OpenCL می تواند بر روی پلتفرم های محاسباتی ناهمگن مختلف بدون هیچ گونه تغییری اجرا شود، به عنوان مثال ، پلت فرم های مبتنی بر GPU یا مبتنی بر MIC. بنابراین، روش پیشنهادی قابلیت کراس پلتفرم رضایت بخشی دارد.
-
در مقایسه با الگوریتم سریالی که فقط بر روی پلت فرم CPU اجرا می شود، الگوریتم کریجینگ جهانی موازی، به ویژه قسمت محاسبه درون یابی آن، می تواند نسبت شتاب خوبی را در پلت فرم های ناهمگن مختلف به دست آورد.
-
استفاده از دستگاههای محاسباتی متعدد، یعنی کارتهای GPU/MIC بیشتر برای محاسبات، افزایش تقریباً خطی در نسبت شتاب و عملکرد بهتر نسبت به دستگاههای محاسباتی منفرد به دست آورد. با این حال، رویکرد محاسباتی ناهمگن مبتنی بر OpenCL نیز دارای نقاط ضعفی است، از جمله برنامهنویسی پیچیده، نیازهای بالای حافظه، استفاده کم از توابع بازگشتی و راندمان نسبتا پایین در مقایسه با CUDA.
علاوه بر این، هنوز امکان بهینه سازی بیشتر برنامه کریجینگ جهانی موازی پیشنهادی وجود دارد. به عنوان مثال، با استفاده از یک مقیاس درونیابی بزرگتر، مرحله به کار گرفته شده برای جستجوی نقاط همسایه در برنامه موازی به تدریج به کانون اصلی تبدیل می شود. بنابراین، این هات اسپات برای افزایش بیشتر عملکرد الگوریتم موازی نیاز به توجه بیشتری دارد.





بدون نظر