

خلاصه
دادههای توپوگرافی تشخیص و محدوده نور هوابرد (LiDAR) اطلاعات دیجیتالی بسیار دقیقی را ارائه میدهد که به طور گسترده در برنامههایی مانند ایجاد نقشههای نرخ بیمه سیل، مطالعات جنگل و درخت، نقشهبرداری تغییرات ساحلی، طبقهبندی خاک و منظر، مدلسازی سه بعدی شهری، ساحل رودخانه استفاده میشود. مدیریت، مطالعات محصولات کشاورزی و غیرهدر این مقاله، ما عمدتا بر روی استفاده از دادههای LiDAR در مدلسازی زمین/مدل ارتفاعی دیجیتال (DEM) تمرکز میکنیم. پیشرفتهای فناوری در ساخت حسگرهای LiDAR، ابرهای نقطهای LiDAR بسیار دقیق و متراکم را فعال کرده است که مدلسازی با وضوح بالا سطوح زمین را ممکن میسازد. با این حال، دادههای با چگالی بالا منجر به حجم عظیم دادهها میشوند که مشکلات محاسباتی را ایجاد میکنند. زمان محاسباتی مورد نیاز برای انتشار، پردازش و ذخیره سازی این داده ها با حجم داده ها رابطه مستقیم دارد. ما یک تکنیک جدید را بر اساس نقشه شیب زمین توصیف می کنیم، که به مشکل چالش برانگیز در منطقه تجزیه و تحلیل داده های مکانی، کاهش این داده های متراکم LiDAR بدون به خطر انداختن دقت آن می پردازد. با بهترین دانش ما، این اولین الگوریتم کاهش داده مبتنی بر چشم انداز است. ما همچنین یک مطالعه تجربی انجام میدهیم، که نشان میدهد در مقایسه با DEM تولید شده از یک مجموعه داده اصلی و کامل LiDAR، هیچ افت قابلتوجهی در دقت برای DEM ایجاد شده از مجموعه دادههای LiDAR کاهشیافته 52 درصدی تولید شده توسط الگوریتم ما وجود ندارد. برای دقت تجزیه و تحلیل آماری خود، به جای مقایسه چند نقطه کنترل تصادفی، خطای میانگین مربعات ریشه (RMSE) را با مقایسه تمام نقاط شبکه DEM اصلی با DEM تولید شده توسط داده های کاهش یافته انجام می دهیم. علاوه بر این، الگوریتم کاهش داده چند هسته ای ما بسیار مقیاس پذیر است. ما همچنین یک روش درونیابی فضایی با فاصله معکوس موازی (IDW) را توصیف میکنیم و نشان میدهیم که DEMهایی که تولید میکند از نظر زمان کارآمد هستند و دقت بهتری نسبت به روش تولید شده توسط روش سنتی IDW دارند. که نشان میدهد در مقایسه با DEM تولید شده از یک مجموعه داده اصلی و کامل LiDAR، هیچ افت قابلتوجهی در دقت برای DEM ایجاد شده از مجموعه دادههای LiDAR کاهشیافته 52 درصدی ایجاد شده توسط الگوریتم ما وجود ندارد. برای دقت تجزیه و تحلیل آماری خود، به جای مقایسه چند نقطه کنترل تصادفی، خطای میانگین مربعات ریشه (RMSE) را با مقایسه تمام نقاط شبکه DEM اصلی با DEM تولید شده توسط داده های کاهش یافته انجام می دهیم. علاوه بر این، الگوریتم کاهش داده چند هسته ای ما بسیار مقیاس پذیر است. ما همچنین یک روش درونیابی فضایی با فاصله معکوس موازی (IDW) را توصیف میکنیم و نشان میدهیم که DEMهایی که تولید میکند از نظر زمان کارآمد هستند و دقت بهتری نسبت به روش تولید شده توسط روش سنتی IDW دارند. که نشان میدهد در مقایسه با DEM تولید شده از مجموعه دادههای LiDAR اصلی و کامل، افت قابلتوجهی در دقت برای DEM ایجاد شده از مجموعه دادههای LiDAR کاهشیافته 52 درصدی ایجاد شده توسط الگوریتم ما وجود ندارد. برای دقت تجزیه و تحلیل آماری خود، به جای مقایسه چند نقطه کنترل تصادفی، خطای میانگین مربعات ریشه (RMSE) را با مقایسه تمام نقاط شبکه DEM اصلی با DEM تولید شده توسط داده های کاهش یافته انجام می دهیم. علاوه بر این، الگوریتم کاهش داده چند هسته ای ما بسیار مقیاس پذیر است. ما همچنین یک روش درونیابی فضایی با فاصله معکوس موازی (IDW) را توصیف میکنیم و نشان میدهیم که DEMهایی که تولید میکند از نظر زمان کارآمد هستند و دقت بهتری نسبت به روش تولید شده توسط روش سنتی IDW دارند. ما به جای مقایسه چند نقطه کنترل تصادفی، خطای میانگین مربع ریشه (RMSE) را با مقایسه تمام نقاط شبکه DEM اصلی با DEM تولید شده توسط داده های کاهش یافته انجام می دهیم. علاوه بر این، الگوریتم کاهش داده چند هسته ای ما بسیار مقیاس پذیر است. ما همچنین یک روش درونیابی فضایی با فاصله معکوس موازی (IDW) را توصیف میکنیم و نشان میدهیم که DEMهایی که تولید میکند از نظر زمان کارآمد هستند و دقت بهتری نسبت به روش تولید شده توسط روش سنتی IDW دارند. ما به جای مقایسه چند نقطه کنترل تصادفی، خطای ریشه میانگین مربع (RMSE) را انجام می دهیم و تمام نقاط شبکه DEM اصلی را با DEM تولید شده توسط داده های کاهش یافته مقایسه می کنیم. علاوه بر این، الگوریتم کاهش داده چند هسته ای ما بسیار مقیاس پذیر است. ما همچنین یک روش درونیابی فضایی با فاصله معکوس موازی (IDW) را توصیف میکنیم و نشان میدهیم که DEMهایی که تولید میکند از نظر زمان کارآمد هستند و دقت بهتری نسبت به روش تولید شده توسط روش سنتی IDW دارند.
کلید واژه ها:
تجزیه و تحلیل داده های مکانی ; داده های بزرگ LiDAR ; الگوریتم موازی ؛ DEM ; GIS
1. معرفی
1.1. بررسی اجمالی
تشخیص و محدوده نور هوابرد (LiDAR) یکی از مؤثرترین ابزارها برای جمعآوری دادههای زمین با چگالی بالا و دقت بالا است. تصویربرداری فضایی سه بعدی با فناوری LiDAR یک روش سنجش از دور قدرتمند است که می تواند برای تهیه نقشه های دقیق از اشیاء، سطوح و زمین در مقیاس های بسیار متفاوت استفاده شود [1 ] . فنآوریهای اسکن بهبودیافته، تولید ابرهای نقطهای LiDAR با چگالی بالا و بنابراین، مدلهای زمینی دقیقتر و فشردهتر و دیگر نمایشهای سهبعدی را آسانتر کرده است [2 ]]. داده های توپوگرافی LiDAR اطلاعات دیجیتالی بسیار دقیقی را ارائه می دهد که به طور گسترده در برنامه هایی مانند به روز رسانی و ایجاد نقشه های نرخ بیمه سیل، مطالعات جنگل ها و درختان، نقشه برداری تغییرات ساحلی، طبقه بندی خاک و منظر، مدل سازی سه بعدی شهری، مدیریت سواحل رودخانه، محصولات کشاورزی استفاده می شود. مطالعات، و غیره . با این حال، تولید چنین مدل های بهبود یافته از چگالی بالا و حجم عظیمی از داده ها، چالش های بزرگی را با توجه به ذخیره سازی، پردازش و دستکاری داده ها تحمیل می کند.
در طول 15 سال گذشته، استفاده از داده های LiDAR برای تولید مدل های ارتفاعی دیجیتال قابل اعتماد و دقیق (DEMs) به طور گسترده در جوامع علوم زمین فضایی استفاده شده است [ 3]]. دقت DEM تولید شده به طور مستقیم با چگالی داده های LiDAR زمین نمونه استفاده شده متناسب است. از این رو، استراتژیهایی برای پردازش حجم زیادی از دادههای متراکم LiDAR بدون به خطر انداختن دقت ضروری هستند. در این مقاله، ما یک تکنیک الگوریتمی جدید را برای کاهش دادههای LiDAR برای دستیابی به یک معادله بهینه بین چگالی و حجم دادهها توصیف میکنیم که تولید دقیق و کارآمد DEMها را تسهیل میکند. الگوریتم ما نقاط LiDAR را بر اساس توپوگرافی، عمدتاً نقشه شیب، زمین مورد نظر کاهش می دهد. تا جایی که ما می دانیم، این اولین تکنیک کاهش داده مبتنی بر چشم انداز است. ما همچنین از برنامهنویسی موازی برای بهرهبرداری از معماری چند هستهای CPU استفاده میکنیم، بنابراین الگوریتم خود را بسیار مقیاسپذیر و از نظر زمان کارآمد میکنیم.
یک سطح زمین طبیعی یک سطح پیوسته است که از نقاط بی نهایت تشکیل شده است [ 4 ]. ما از تکنیک های نمونه برداری نقطه ای برای تقریب دقت DEM های تولید شده به وضوح مورد نیاز استفاده می کنیم. متداول ترین DEM های مورد استفاده شبکه DEM، خط خطوط DEM و شبکه نامنظم مثلثی (TIN) DEM هستند. یک شبکه DEM را می توان به عنوان یک ماتریس نشان داد که دارای نقاط داده مرتبط است که اطلاعات توپوگرافی زمین را به تصویر می کشد. هر سلول شبکه ای مقداری دارد که نشان دهنده ارتفاع کل سلول است [ 5 ]. هر یک از سلول های شبکه این مقدار ارتفاع را با درون یابی (رویه تقریب) نقاط نمونه گیری مجاور به دست می آورند. در [ 6]، درون یابی به عنوان فرآیندی برای تفسیر مقادیر در نقاط یافت شده در مناطق نمونه برداری نشده، بر اساس مقادیر در نقاط داخل منطقه محدود مطالعه تعریف می شود. تکنیک های درون یابی در DEM های شبکه برای تعیین مقدار ارتفاع زمین یک نقطه بر اساس مقادیر شناخته شده ارتفاع نقاط در همسایگی استفاده می شود [ 7 ]. کیفیت DEM ها بر اساس تفاوت بین مقدار واقعی و درون یابی شده در نقاط کل یا مکان های انتخاب شده ارزیابی می شود [ 8 ].
عملاً اعمال درون یابی فضایی یک کار محاسباتی پرهزینه است و به منابع محاسباتی قدرتمندی نیاز دارد. درونیابی فضایی بیشتر برای تجزیه و تحلیل داده های عظیم اعمال می شود که به زمان پردازش بیشتری نیاز دارد. برای کاربردهای خاص، مانند نقشه برداری بلادرنگ از مناطق، وسایل نقلیه مزرعه بدون راننده و غیره .، استفاده از حسگر LiDAR روی برد عمدتاً روی پوشش گیاهی کم استفاده می شود. الگوریتم تولید DEM ما همراه با الگوریتم کاهش داده ما این پتانسیل را دارد که کارایی چنین برنامه هایی را بهبود بخشد. در این مقاله، ما یک تکنیک درونیابی فضایی IDW اصلاحشده موازی را ارائه میکنیم که از چندین هسته CPU برای عملکرد محاسباتی بهتر از IDW سنتی استفاده میکند. ما همچنین DEM تولید شده توسط الگوریتم خود را با الگوریتم تولید شده توسط IDW سنتی با استفاده از اعتبارسنجی مقایسه می کنیم. علاوه بر این، ما همچنین مقایسه را با استفاده از رویکردهای آماری، مانند RMSE ارزیابی میکنیم.
1.2. کار مرتبط
1.2.1. رویکردهای کاهش داده ها
پیشرفت در فناوریهای جمعآوری دادهها، تولید حجم عظیمی از دادهها را امکانپذیر کرده است، که مشکلات محاسباتی را هنگام انتشار، پردازش و ذخیره دادهها ایجاد میکند. داده ها تنها زمانی ارزشمند هستند که بتوانند اطلاعات مفیدی را منتقل کنند. همه نقاط در کل ابر نقطه LiDAR اطلاعات ارزشمندی را در مورد زمین مورد بررسی ارائه نمی دهند [ 9 ]. برای اینکه یک DEM مفید باشد، باید اندازه دلخواه داشته باشد تا هر زمان که نیاز باشد در فناوری مورد استفاده برای رندر کردن آن، بتوان آن را دستکاری کرد. این یکی از چالشهای اصلی در پردازش گسترده دادههای جغرافیایی فضایی است: کاهش مجموعه داده برای دستیابی به تعادل بهینه بین اندازه مجموعه داده مورد نیاز و وضوح مورد نظر. کار شرح داده شده در [ 10] اثرات چگالی داده LiDAR را بر روی DEM های تولید شده برای طیف وسیعی از وضوح نشان می دهد. آنها همچنین نشان دادند که دادههای LiDAR را میتوان به میزان قابل توجهی کاهش داد، با این حال هنوز میتوان DEMهای دقیقی را برای پیشبینی ارتفاع تولید کرد. اثرات چگالی داده های LiDAR بر دقت DEM های تولید شده و میزانی که داده های LiDAR را می توان کاهش داد و همچنان به DEM ها با دقت مورد نیاز دست یافت، در [11] مطالعه شده است . روشی برای حذف رأس یعنی حذف انتخابی نقاطی از ابر نقطه LiDAR که اطلاعات کافی را منتقل نمیکنند در [ 12 ] معرفی شد. هگمن و همکاران یک روش پیشنهاد کرد [ 13] که در آن هر نقطه بر اساس واریانس z ابر نقطه در ناحیه کوچک محلی برای حذف در نظر گرفته شد. یک آستانه واریانس در ابتدا به عنوان یک پارامتر ورودی تنظیم شد. مناطق محلی که دارای واریانس z کمتر از آستانه هستند، اکثر نقاط مرکزی خود را حذف می کنند. آنها به این نتیجه رسیدند که برای رژیمهای خاص، این تکنیک نقطهزنی به طور قابلتوجهی بهتر از کاهش تصادفی عمل میکند. برخی از الگوریتم های فیلتر کردن داده ها، مانند [ 14 ، 15]، روی مناطق پرشیب و جنگلی که در آن سایر الگوریتمهای فیلتر معمولاً در تمایز بین بازگشتهای زمین و نقاط خارج از زمین که در پوشش گیاهی منعکس میشوند، مشکل دارند، تمرکز کرده و عملکرد خوبی دارند. با این حال، این رویکردها در جایی که پوشش گیاهی کم یا کم وجود دارد کارآمد نیستند. برای کاربردهای خاص، مانند نقشه برداری بلادرنگ از زمین ها (زمین مزرعه)، وسایل نقلیه مزرعه بدون راننده مانند (تراکتور، بذرپاش، سمپاش و غیره )، ماشین برداشت با تنظیم خودکار زاویه تیغه و غیره ، با استفاده از حسگر LiDAR روشن تخته عمدتاً قبل از ظهور پوشش گیاهی یا با پوشش گیاهی کم استفاده می شود. الگوریتمی که در این مقاله ارائه می کنیم برای چنین کاربردهایی کارآمد است.
1.2.2. رویکردهای درونیابی فضایی
در میان تمام تکنیکهای درونیابی فضایی، تولید DEM با استفاده از تکنیکهای DEM شبکهای، دامنه ذخیرهسازی و دستکاری کارآمدتری دارد [ 4 ]. DEM های تولید شده با استفاده از شبکه ها خطاهایی را ایجاد می کنند، زیرا زمین به صورت گسسته نمایش داده می شود، اما این خطا برای مجموعه داده های متراکم در مقایسه با TIN، کریجینگ و غیره نسبتاً کمتر است . اندازه شبکه مورد استفاده برای تولید DEM مستقیماً با تقریب متناسب است. نسبت نمایش سطح زمین از آنجایی که داده های LiDAR متراکم هستند، چنین محدودیت هایی از روش DEM شبکه ای را می توان حذف کرد. کار در [ 16] مدل های پیچیده را برای تولید DEM های حاصل از تکنیک های ترکیبی مورد مطالعه قرار داد. با این حال، در عمل، تمام DEM های تولید شده از LiDAR با استفاده از تکنیک های شبکه انجام می شود [ 17 ]. با توجه به در دسترس بودن انواع زیادی از تکنیک های درون یابی، به سوالاتی که مناسب ترین تکنیک برای زمین های مختلف است باید پاسخ داده شود. مطالعات تجربی برای پاسخ به این سوالات و ارزیابی اثرات تکنیک های مختلف درونیابی بر کیفیت DEM در [ 4 ، 18 ، 19 ] نشان داده شده است. هیچ تکنیک درونیابی وجود ندارد که برای همه داده های سطح زمین بهینه باشد [ 20]. ثابت شده است که روش درونیابی IDW زمانی که داده های نمونه برداری چگالی بالایی دارند، عملکرد بهتری را نشان می دهد. از آنجایی که داده های LiDAR چگالی بالایی دارند، IDW یک انتخاب ارجح برای تولید DEM است [ 21 ، 22 ].
2. مجموعه داده
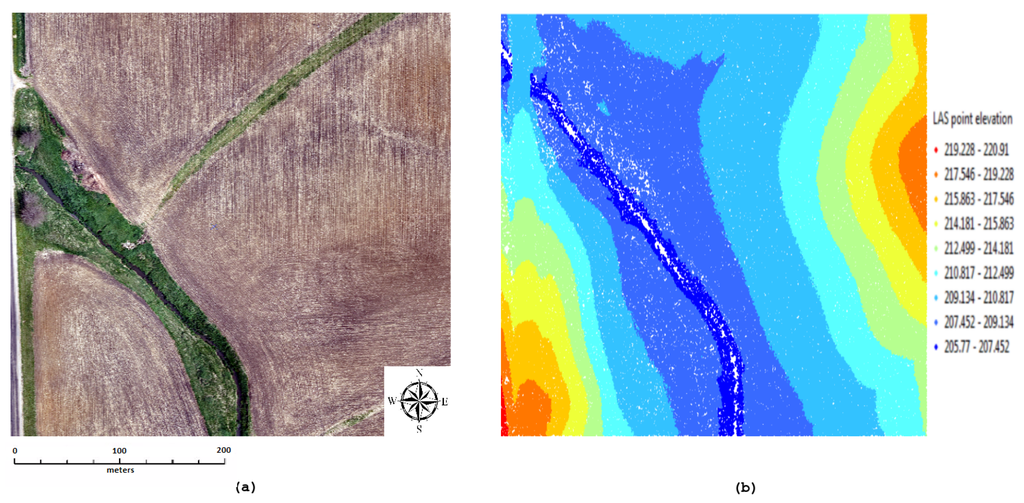
مجموعه داده آزمایشی LiDAR که برای آزمایشهای خود استفاده میکنیم 300 متر است × 380×380کاشی متر، از زمین در آیووا. تصاویر منطقه مورد مطالعه در شکل 1 الف نشان داده شده است. این مجموعه داده LiDAR جالب است زیرا ترکیب خوبی از زمین مسطح، زمین با شیب متوسط و شیب های تند دارد. بنابراین، به جای زمینهای ایدهآل محاسباتی متشکل از زمینهای هموار، به یک زمین واقعی شبیه است. زاویه شیب برای کل زمین بین آنها متفاوت است 0.030.03° و 63.1863.18درجه این مجموعه داده LiDAR با استفاده از Airborne LiDAR توسط Aerial Services, Inc. (ASI)، آیووا، ایالات متحده جمع آوری شده است. مجموعه داده شامل 6.946.94میلیون نقطه، با تراکم نقطه ای تقریباً 120 نقطه در هر متر مربع. در آزمایشها، فایلهای ورودی با فرمت فایل ASPRS LAS، نسخه 1.0 فرمت شدند. اندازه این مجموعه داده بود 1.51.5گیگابایت علاوه بر این، برای اهداف تجسم، دادههای ورودی با پسوند .LAS را با استفاده از LASTools به xyz. تبدیل کردیم. ابر نقطه LiDAR برای داده های فوق با استفاده از ArcGIS، ArcMap v تولید می شود 10.310.3همانطور که در شکل 1 ب نشان داده شده است. وضوح مکانی داده های LiDAR برآورد شد 0.02540.0254متر به صورت عمودی و 0.02540.0254متر به صورت افقی
3. روش کاهش داده ها
3.1. آماده سازی داده ها
در ابتدا، ما از داده های ارتفاعی موجود برای منطقه مورد مطالعه برای ایجاد یک نقشه شیب استفاده می کنیم. برای این مقاله، ما این داده های ارتفاعی را با استفاده از داده های LiDAR که برای کل منطقه جمع آوری کردیم، تولید می کنیم. دادههای ارتفاع نیز بهطور رایگان در مجموعه دادههای ارتفاعی ملی (NED) [ 23 ] در دسترس هستند ، که محصول دادههای ارتفاعی اولیه سازمان زمینشناسی ایالات متحده (USGS) است و به عنوان لایه ارتفاعی «نقشه ملی» عمل میکند. NED اطلاعات ارتفاع را برای مطالعات علوم زمین و برنامه های نقشه برداری در ایالات متحده ارائه می دهد. ما یک تجزیه و تحلیل آماری از نقشه شیب برای مجموعه داده خود، با استفاده از گسست های طبیعی (جنکس) انجام دادیم.روش در ArcGIS این تجزیه و تحلیل نشان داد که زاویه شیب برای زمین ما از محدوده 0.030.03° به 63.1863.18°، با مقدار میانگین از 6.526.52° و مقدار انحراف استاندارد از 5.735.73درجه همانطور که در شکل 2 ب نشان داده شده است، نقشه شیب دارای چهار منطقه با دامنه های شیب متفاوت بر اساس این تجزیه و تحلیل آماری انجام شده با استفاده از جنکس (نشان داده شده در شکل 2 a) ایجاد شد. محدوده ها بودند اسl o pهgr e e n= [ 0.03 درجه ، 4 درجه ]����������=[0.03°,4°]، اسl o pهye l l o w= [ 4.00 درجه ، 8.00 درجه ]�����������=[4.00°,8.00°]، اسl o pهo r a n gه= [ 8.00 درجه ، 13.00 درجه ]�����������=[8.00°,13.00°]و اسl o pهr e d= [ 13.00 ° , 63.18 ° ]��������=[13.00°,63.18°]. اسl o pهgr e e n����������نشان دهنده مسطح ترین مناطق در زمین است، در حالی که اسl o pهr e dاسل�په�هدناهموارترین و ناهموارترین مناطق را نشان می دهد.
پس از ایجاد لایه نقشه شیب، نقاط LiDAR را که برای همان زمین جمع آوری کرده ایم، روی آن قرار می دهیم و در عین حال ارجاع جغرافیایی مکانی را حفظ می کنیم. بر اساس محدوده شیب نقطه LiDAR، یک پارامتر جدید اضافه می کنیم، به عنوان مثال، اسl o p eاسل�پهبرای هر نقطه LiDAR پس از پردازش، مجموعه داده LiDAR ما شامل x ، y ، z و اسl o p eاسل�پهمقادیری که به عنوان ورودی الگوریتم کاهش داده خود استفاده می کنیم. کل این فرآیند با استفاده از ArcGIS و LASTools انجام می شود.
3.2. الگوریتم
در الگوریتم کاهش داده LiDAR ما، در ابتدا، یک شبکه 1 متر مربع را پوشش می دهیم. سلول های روی داده های LiDAR، با حفظ ارجاع جغرافیایی مکانی. اولین سلول در شبکه را انتخاب کنید و یک نقطه LiDAR را به طور تصادفی از بین تمام نقاط LiDAR که در آن سلول شبکه قرار دارند انتخاب کنید. ما به انتخاب نقاط مختلف تصادفی LiDAR از سلول انتخاب شده ادامه می دهیم تا زمانی که یک نقطه LiDAR به دست آوریم که در اسl o pهgr e e nاسل�په��هه�منطقه یا تا زمانی که تمام نقاط LiDAR بررسی شوند. اگر نقطه LiDAR را پیدا کنیم که در آن قرار دارد اسl o pهgr e e nاسل�په��هه�منطقه، بررسی می کنیم که آیا β%�%(ورودی کاربر) از نقاط LiDAR در آن سلول متعلق به اسl o pهgr e e nاسل�په��هه�منطقه یا نه اگر این کار را کرد، تمام نقاط آن سلول را که به آن تعلق دارند حذف می کنیم اسl o pهgr e e nاسل�په��هه�منطقه، به جز نقطه انتخاب شده (مثلاً سلول (i) در شکل 3 ، با β= 90 ٪�=90%). اگر هیچ نقطه LiDAR در آن پیدا نکنیم اسl o pهgr e e nاسل�په��هه�منطقه، نقاط LiDAR را بررسی می کنیم که در آن قرار دارند اسl o pهye l l o wاسل�په�هلل��ناحیه (مثلاً سلول (ii) در شکل 3 ) و مانند بالا عمل کنید. اگر هیچ نقطه LiDAR را در مناطق پیدا نکردیم اسl o pهgr e e nاسل�په��هه�یا اسl o pهye l l o wاسل�په�هلل��یا هیچ نقطهای در سلول حذف نمیشود (مثلاً هیچ دادهای در سلول (iii) حذف نخواهد شد)، ما به سادگی به سلول بعدی در شبکه میرویم. مراحل بالا را تا زمانی که تمام سلولهای شبکه را پردازش کنیم، به شکل چپ به راست و بالا به پایین تکرار میکنیم. انگیزه پشت این الگوریتم کاهش داده LiDAR این واقعیت است که ما برای نشان دادن یک زمین صاف در مقایسه با یک زمین نامنظم به نقاط LiDAR زیادی نیاز نداریم.
3.3. پیاده سازی موازی
الگوریتم 1، زمانی که به صورت متوالی اجرا شود، از نظر زمان اجرا بسیار ناکارآمد است. پردازش یک ابر نقطه LiDAR تقریباً شش ساعت طول می کشد 6 . 946.94میلیون نقطه به صورت متوالی، زیرا در بدترین حالت می توان مقایسه درجه دوم بین نقاط هر سلول وجود داشت. در این بخش، یک پیادهسازی موازی از الگوریتم کاهش داده LiDAR را ارائه میکنیم که بسیار سریعتر از نسخه متوالی و همچنین مقیاسپذیری بالایی دارد. ما دادههای LiDAR را بر روی چندین هسته پردازندهها توزیع میکنیم و آنها را به صورت موازی با استفاده از تخصیص بلوکی و چرخهای پردازش میکنیم.
| الگوریتم 1 الگوریتم کاهش داده LiDAR. |
|
یک شبکه m ردیف × n ستون در نظر بگیرید ( m , n ∈ Nمتر،�∈ن) که بر روی داده های LiDAR همانطور که در بخش 3.2 توضیح داده شده و در شکل 4 نشان داده شده است، پوشانده شده است . برای یک پردازنده k هسته ای (m ≥ kمتر≥ک) یک هسته اصلی را اختصاص می دهیم که k اولین ردیف m را برش می دهد و هر یک از آنها را به هر پردازنده جداگانه اختصاص می دهیم (تخصیص بلوک برش ها). هر یک از این k برش ها دارای n سلول هستند که توسط هر هسته ای که برش مربوطه به آن اختصاص داده شده است، یک به یک پردازش می شود (تخصیص چرخه ای سلول ها). هنگامی که هر سلول در تمام برشهای k پردازش شد، k ردیف بعدی m برش داده میشود (تخصیص چرخهای برشها) و به طور مشابه به هستههای CPU توزیع میشوند. نتایج تست های مقیاس پذیری با استفاده از 1، 2، 4، 8 و 16 هسته CPU و افزایش سرعت در بخش 3.4 نشان داده شده است .
3.4. نتایج
با داده های متراکم LiDAR که داریم، متشکل از 6 . 946.94میلیون امتیاز، دقت بالا (دقت عمودی و افقی 1 متر) و DEM با وضوح بالا، که یک منطقه را پوشش می دهد 300 × 380300×380متر مربع از یک زمین نامنظم در آیووا، با استفاده از روش درونیابی IDW (نشان داده شده در شکل 5 ) ایجاد شد. ما الگوریتم خود را برای مقادیر ورودی مختلف آزمایش می کنیم β%�%به منظور یافتن تعادل بهینه بین دقت و چگالی داده های LiDAR. همانطور که در جدول 1 نشان داده شده است، ما همچنین دستورالعملی برای انتخاب مقدار β برای زمین های مختلف ایجاد می کنیم . در شکل 6 الف، ما تست افزایش سرعت و مقیاس پذیری الگوریتم کاهش داده LiDAR خود را برای 1، 2، 4، 8 و 16 هسته CPU نشان داده ایم. با استفاده از یک پردازنده Xeon Phi 16 هسته ای، زمان اجرای الگوریتم را با 15 . 8115.81×، یعنی از ≈ 6≈6ساعت به ≈ 20≈20دقیقه، برای مجموعه داده مورد بررسی. مقیاسپذیری که ما به آن دست مییابیم به بهبود k برابر برای یک پردازنده k هستهای نزدیکتر است (k ≥ 1ک≥1).
ما مشاهده کردیم که در مقایسه با DEM تولید شده از مجموعه داده اصلی و کامل LiDAR، کاهش قابل توجهی در دقت برای DEM ایجاد شده از 52 %52%مجموعه داده کاهش یافته با استفاده از الگوریتم ما برای β= 90 ٪�=90%به مجموعه داده اصلی LiDAR به عنوان ورودی. ما DEM را از مجموعه داده کامل LiDAR تولید می کنیم و از آن به عنوان حقیقت پایه برای مقایسه با DEM تولید شده از مجموعه داده LiDAR کاهش یافته با استفاده از مقایسه سلول به سلول استفاده می کنیم. ریشه میانگین مربعات خطا (RMSE) و انحراف استاندارد که از آن پشتیبانی می کنند در شکل 6 ب نشان داده شده است. در مقایسه با DEM اصلی، RMSE در DEM تولید شده معرفی شد، زمانی که β= 90 ٪�=90%، تنهاست 0.140.14متر در شکل 7 الف، DEM های دوبعدی و سه بعدی تولید شده از آن را نشان داده ایم 66 %66%مجموعه داده کاهش یافته با استفاده از الگوریتم ما برای β= 80 ٪�=80%و در شکل 7 ب، DEM تولید شده از 52 %52%کاهش داده به دست آمده برای β= 90 ٪�=90%. از شکل 6 ب و شکل 7 a، می بینیم که دقت قابل توجهی در DEM ایجاد شده از مجموعه داده کاهش یافته به دست آمده برای β= 80 ٪�=80%و β≤ 85 ٪�≤85%، به ترتیب. برای β= 80 ٪�=80%، چگالی داده ها کاهش می یابد 66 %66%، اما یک RMSE از وجود دارد 0.290.29m، که دقت DEM را به میزان قابل توجهی کاهش می دهد. در حالی که برای ارزش های β> 90 درصد�>90%، درصد کاهش داده ها معنی دار نیست.
زمان پردازش برای تولید DEM به طور مستقیم با اندازه داده های LiDAR استفاده شده برای تولید آن متناسب است [ 24 ]. نیمی از زمان برای تولید DEM از 52 %52%کاهش داده برای β= 90 ٪�=90%در مقایسه با مجموعه داده اصلی LiDAR. هرچه مقدار β کوچکتر باشد ، چگالی داده های کاهش یافته LiDAR کمتر است و دقت DEM های تولید شده کمتر است. ما باید مقدار β را بر اساس نوع زمین تعیین کنیم. سابق. بر اساس مطالعه ما، β= 90 ٪�=90%برای زمین هایی که ترکیب خوبی از زمین های مسطح، زمین هایی با شیب متوسط و شیب های تند دارند، بهینه است. چگالی داده ها را به نصف اندازه مجموعه داده اصلی کاهش می دهد و همچنین دقت بالای DEM های تولید شده را حفظ می کند. برای زمینهایی که تحت تسلط زمینهای مسطح هستند، مقادیر β بالاتر ممکن است به کاهش بهینه دادههای LiDAR منجر شود، در حالی که برای زمینهای تحت سلطه شیبهای متوسط، شیبدار و مناطق ناهموار، مقادیر کمتر β ممکن است انتخاب صحیحی باشد (مقدار بتا زمانی که بهینه است. تعادل بهینه بین دقت و اندازه داده برای نسل های DEM حفظ می شود). بنابراین ما نشان میدهیم که الگوریتم کاهش داده LiDAR ما میتواند زمان پردازش و اندازه فایل نسلهای DEM را به طور قابل توجهی بهبود بخشد.
برای کاربردهای خاص، مانند نقشه برداری بلادرنگ زمین ها با استفاده از حسگرهای LiDAR، زمان محاسباتی به دست آمده توسط فیلتر کاهش داده LiDAR که در بخش 3 توضیح داده شده است، همراه با الگوریتم درونیابی فضایی متوالی در قفسه کافی نیست. از این رو، با در نظر گرفتن چنین کاربردهایی، ما یک تکنیک درونیابی فضایی موازی IDW را توسعه میدهیم که DEMهای با کیفیت بهتر یا مشابه را در زمان محاسباتی کمتر، در مقایسه با IDW سنتی تولید میکند.
4. درون یابی فضایی
درونیابی داده های مکانی یک تکنیک حیاتی در یک سیستم اطلاعات جغرافیایی (GIS) است که مقادیر ارتفاع زمین ناشناخته نقاط را بر اساس مقادیر ارتفاعی شناخته شده نقاط در همسایگی محاسبه می کند [7 ] . پردازش دادههای فضایی عظیم یک فرآیند محاسباتی پرهزینه و پیچیده است و الگوریتمهای متوالی سنتی نمیتوانند تقاضا برای سرعت پردازش سریعتر همراه با حفظ دقت را برآورده کنند. در این بخش، ما یک الگوریتم درون یابی فضایی موازی را توضیح می دهیم که اصلاحی در QuickGrid [ 25 ] و IDW سنتی است.. این اصلاح در الگوریتم و همچنین پیاده سازی آن انجام می شود، جایی که از چند هسته CPU برای افزایش سرعت محاسبات استفاده می کند.
4.1. الگوریتم
ما الگوریتم را با همپوشانی شبکه ای از k sq.m مقداردهی اولیه می کنیم. سلول ها ( k > 0ک>0) روی داده های LiDAR، با حفظ ارجاع جغرافیایی مکانی. ما با استفاده از k = 0.0254ک=0.0254متر مربع برای شبیه سازی های ما هر نقطه LiDAR دارای مختصات x، y و z است و ما می خواهیم مقادیر z را به هر سلول شبکه درون یابی کنیم. مراحل الگوریتم درونیابی فضایی ما به شرح زیر است:
-
نقاط تقاطع هر سلول در شبکه (نشان داده شده در شکل 8 a) را به صورت چپ به راست، بالا به پایین تجزیه کنید.
-
برای هر نقطه تقاطع، وزنی را به صورت زیر محاسبه و تخصیص می دهیم:
-
در ابتدا یک شعاع برش برای دایره ای که مرکز آن نقطه تقاطع است انتخاب کنید (توصیه می شود برای مجموعه داده های بسیار متراکم، شعاع های برش کوچکی را انتخاب کنید، در مقایسه با مجموعه داده های کم تر).
-
سپس دایره را به هشت بخش مساوی تقسیم کنید و در صورت وجود، نزدیکترین نقاط LiDAR را در هر بخش انتخاب کنید (نشان داده شده در شکل 8 ب). نقطه تقاطع شبکه را روی میانگین این نقاط LiDAR انتخاب شده با وزن 1/(فاصله از تقاطع شبکه) تنظیم کنید .
-
-
پس از تخصیص وزن به تمام نقاط تقاطع شبکه، به هر سلول شبکه میانگین وزن چهار نقطه تقاطع شبکه اطراف آن را اختصاص می دهیم (نشان داده شده در شکل 8 ج).
4.2. پیاده سازی موازی
اجرای متوالی الگوریتم شرح داده شده در بخش 4.1 از نظر زمان پردازش بسیار ناکارآمد است. تجزیه هر سلول شبکه و نقاط تقاطع شبکه به صورت جداگانه، چندین بار، می تواند یک کار محاسباتی پرهزینه و وقت گیر باشد. در این بخش، یک پیادهسازی موازی برای الگوریتم فوق طراحی میکنیم که شامل دو فاز است: فاز تقسیم ، که در آن دادهها را روی چندین هسته یک CPU توزیع میکنیم تا آنها را همزمان پردازش کنیم، و فاز ادغام ، که در آن دادههای پردازششده را دوباره ادغام میکنیم. با یکدیگر.
در ابتدا، در فاز تقسیم ، یک هسته اصلی را اختصاص می دهیم که شبکه (به همراه داده های LiDAR) را به k قسمت مساوی تقسیم می کند، جایی که k تعداد کل هسته های CPU موجود برای پردازش است. هر یک از k بخش های شبکه را به صورت جداگانه به هر هسته توزیع و اختصاص می دهد (تخصیص بلوک)، که در شکل 9 نشان داده شده است . سپس هر هسته به طور همزمان الگوریتم ذکر شده در بخش 4 را برای بخشی از داده های شبکه که به آن اختصاص داده شده است، اجرا می کند.
هنگامی که همه هستهها محاسبات خود را به پایان رساندند، هسته اصلی فاز ادغام را راهاندازی میکند ، جایی که نقاط تقاطع شبکه مشترک بین دو بخش شبکه به طور میانگین و ادغام میشوند (نشان داده شده در شکل 9 )، تا شبکه اصلی با تمام تقاطعهای شبکه به دست آید. امتیاز محاسبه شده سپس، هسته اصلی شبکه را به k قسمت مساوی تقسیم میکند و هر یک از k بخشها را به صورت جداگانه به هر هسته اختصاص میدهد، که میانگین وزن چهار نقطه تقاطع شبکه اطراف آن را محاسبه و به هر سلول شبکه اختصاص میدهد. تست های مقیاس پذیری با استفاده از 1، 2، 4، 8 و 16 هسته CPU و افزایش سرعت در بخش 4.3 نشان داده شده است .
4.3. نتایج
در این بخش، الگوریتم درون یابی فضایی خود را با برش ثابت آزمایش می کنیم 1.51.5متر در دو زمین آزمایشی مختلف نشان داده شده در شکل 5 ، که “مجموعه داده 1” ما است، و در شکل 10 ، که “مجموعه داده 2” ما است. مجموعه داده 2 است 200 × 500200×500متر، نسبتاً مسطح با دره های کم عمق و کمتر ناهموار با زاویه شیب از 0.07 درجه0.07درجهبه 43.8 درجه43.8درجهدر مقایسه با Dataset 1، که ترکیبی از دره های عمیق تر، شیب های تند و زمین های مسطح کمی است. مجموعه داده 2 شامل 2.1 میلیون امتیاز LiDAR است. تمام کاهش چگالی داده LiDAR با استفاده از الگوریتم شرح داده شده در بخش 3 انجام می شود . β= 90 ٪�=90%. با اعمال الگوریتم کاهش داده LiDAR خود در مجموعه داده 1، چگالی داده ها را کاهش می دهیم 52 %52%، و هنگامی که برای مجموعه داده 2 اعمال می شود β= 80 ٪�=80%، تراکم داده ها را کاهش می دهیم 71 درصد71%. سپس ما DEM ها را با داده های LiDAR کاهش یافته و همچنین مجموعه داده کامل LiDAR با استفاده از IDW سنتی و IDW اصلاح شده تولید می کنیم.
برای به دست آوردن دقت بالا در تجزیه و تحلیل آماری خود، به جای بررسی چند نقطه کنترل، مقادیر ارتفاعی هر یک از نقاط LiDAR را با مقدار ارتفاع متناظر DEM های تولید شده مقایسه می کنیم. این روش به عنوان اعتبار سنجی شناخته می شود . RMSEs برای مطالعه عملکرد الگوریتم درون یابی فضایی ما در مقایسه با الگوریتم IDW سنتی، برای تراکم داده های مختلف LiDAR محاسبه شد . از مطالعه تجربی ما که در شکل 11 ب نشان داده شده است، می توانیم به موارد زیر نتیجه گیری کنیم:
-
RMSE برای هر دو الگوریتم درون یابی با کاهش چگالی داده LiDAR برای هر دو مجموعه داده افزایش می یابد.
-
RMSE برای زمین های پیچیده تر، یعنی مجموعه داده 1، بالاتر از مجموعه داده 2 است که نسبتاً مسطح است و دره های کم عمق و ناهمواری کمتری دارد.
-
کیفیت نتایج بهدستآمده با IDW اصلاحشده حداقل به خوبی IDW سنتی برای زمینهای پیچیده و چگالی کاهشیافته است (مثلاً 52٪ کاهش LiDAR مجموعه داده 1 یک RMSE از 0 . 220.22m برای هر دو الگوریتم).
-
کیفیت نتایج به دست آمده توسط IDW اصلاح شده بهتر از IDW سنتی برای زمین های متراکم، پیچیده و نسبتاً مسطح است.
-
زمان تولید DEM با استفاده از IDW اصلاح شده بسیار کمتر از زمان استفاده شده توسط IDW سنتی متوالی است.
همانطور که در شکل 11 نشان داده شده است، با استفاده از یک پردازنده Xeon Phi 16 هسته ای، زمان اجرای الگوریتم را با 13.513.5X، یعنی 190 ثانیه با استفاده از یک هسته در مقابل 14 ثانیه. ما الگوریتم کاهش داده LiDAR را پیاده سازی کردیم و IDW را با استفاده از C++ اصلاح کردیم. ما از دستورالعمل های OpenMP/p-threads برای پیاده سازی نسخه های موازی الگوریتم های بالا استفاده می کنیم. شبیه سازی مجموعه داده LiDAR بر روی سیستمی انجام می شود که بر روی CentOS اجرا می شود 6.36.3، یک سیستم عامل لینوکس مبتنی بر لینوکس Red Hat با گره های 512 گیگابایتی، 2.92.9گیگاهرتز، 16 هسته Xeon Phi، گره با حافظه بالا. ابر نقطه LiDAR، نقشه شیب و آمار شیب با استفاده از ArcGIS، ArcMap v تولید و تجسم می شود.10.310.3. الگوریتم IDW برای تولید DEM برای داده های LiDAR کاهش یافته استفاده می شود (الگوریتم درون یابی فضایی جدید ما نیست). ما از ابزار QuickGrid برای تجسم DEM های تولید شده توسط الگوریتم درون یابی فضایی و همچنین الگوریتم کاهش داده استفاده می کنیم. تمام نمودارها با استفاده از Gnuplot و LibreDraw انجام می شود . تمام نتایج بهدستآمده، میانگین پنج اجرا هستند.
5. نتیجه گیری و کار آینده
مشاهده شده است که همه داده های LiDAR به طور موثر در تولید دقیق DEM ها کمک نمی کنند. شناسایی نقاطی که نمایانگر ویژگیهای خاص زمین هستند که حاوی اطلاعات مهمتری در مقایسه با سایر نقاط هستند، مهم است [ 9 ، 11 ]. هنگام طراحی الگوریتم کاهش داده LiDAR، ما عمدتاً شیب زمین را در نظر می گیریم تا نقاط کمتر مهم را حذف کنیم و نقاط بحرانی را حفظ کنیم. شیب های زمین تغییرات در سطوح زمین را برجسته می کند که اطلاعات ارتفاعی یک نقطه را ارائه می دهد و همچنین اطلاعاتی را در مورد محیط اطراف خود به نمایش می گذارد. تغییرات قابل توجه در شیب های زمین نشان دهنده نقاطی با اطلاعات بحرانی تر در مقایسه با سایر نقاط می باشد. 7]]. بنابراین، با استفاده از الگوریتم کاهش داده LiDAR، تعداد نقاط داده مورد نیاز برای تولید DEM را کاهش می دهیم، همراه با حفظ دقت بالا. نتایج نشان می دهد که اجرای موازی ما از این الگوریتم از نظر زمان پردازش بسیار مقیاس پذیر و کارآمد است.
تکنیک درونیابی فضایی اصلاح شده IDW، که در این مقاله ارائه میکنیم، به نتایجی دست مییابد که حداقل به خوبی IDW سنتی برای کاهش تراکم، زمین پیچیده و بهتر از IDW سنتی برای زمینهای متراکم، پیچیده و نسبتاً مسطح است. همچنین مقیاس پذیری خوبی را به دست می آورد و در مقایسه با IDW سنتی زمان بسیار کمتری برای تولید DEM می برد.
برای آزمایش الگوریتم درون یابی فضایی خود، برش را بر روی تنظیم می کنیم 1.51.5متر برای کل زمین. با این حال، برش های بزرگتر برای قسمت های مسطح زمین و برش های کوچکتر برای قطعات ناهموار و پیچیده ایده آل هستند. بنابراین، تکنیکی که برشهای الگوریتم ما را بر اساس ویژگیهای توپوگرافی زمین تغییر میدهد، جالب خواهد بود. برای دستیابی به سرعتهای بالاتر از هستههای بیشتر، الگوریتمهای مبتنی بر GPU را میتوان در راستای همان الگوریتمهای چند هستهای ما توسعه داد. علاوه بر این، الگوریتم IDW موازی ما نیز میتواند با الگوریتم کاهش داده ما ادغام شود و به عنوان یک زیربرنامه اصلی در برخی از برنامههای مبتنی بر جریان استفاده شود.
اختصارات
در این نسخه از اختصارات زیر استفاده شده است:
| LiDAR |
تشخیص و محدوده نور هوابرد
|
| DEM |
مدل دیجیتال ارتفاع
|
| IDW |
وزن معکوس فاصله
|
| TIN |
مثلث سازی شبکه های نامنظم
|
| RMSE |
ریشه میانگین مربعات خطا
|
| GIS |
سیستم اطلاعات جغرافیایی
|
| NED |
داده های ملی ارتفاع
|
منابع
- حبیب، ع. غانما، م. مورگان، ام. ثبت داده های الروزوق، ر. فتوگرامتری و لیدار با استفاده از ویژگی های خطی. فتوگرام مهندس Remote Sens. 2005 ، 71 ، 699-707. [ Google Scholar ] [ CrossRef ]
- سیتول، جی. Vosselman, G. گزارش کامل: مقایسه ISPRS فیلترها. در دسترس آنلاین: http://www.itc.nl /isprswgIII-3/filtertest/ (دسترسی در 30 آوریل 2016).
- هاجسون، من؛ برسناهان، ص. دقت ارتفاع ناشی از LiDAR در هوا. فتوگرام مهندس Remote Sens. 2004 , 70 , 331-339. [ Google Scholar ] [ CrossRef ]
- الشیمی، ن. والئو، سی. حبیب، الف. مدلسازی زمین دیجیتال: اکتساب، دستکاری، و کاربردها . آرتک هاوس: لندن، بریتانیا، 2005. [ Google Scholar ]
- رامیرز، جی آر رویکردی جدید برای بازنمایی امدادی. Surv. Land Inf. علمی 2006 ، 66 ، 19-25. [ Google Scholar ]
- بارو، PA; مک دانل، RA اصول سیستم های اطلاعات جغرافیایی ; انتشارات دانشگاه آکسفورد: نیویورک، نیویورک، ایالات متحده آمریکا، 2011. [ Google Scholar ]
- لی، ز. زو، سی. Gold, C. مدلسازی دیجیتالی زمین: اصول و روش شناسی ; CRC Press: Boca Raton، FL، USA، 2004. [ Google Scholar ]
- بونهام-کارتر، سیستم های اطلاعات جغرافیایی GF برای دانشمندان زمین شناس: مدل سازی با GIS . الزویر: آمستردام، هلند، 2014. [ Google Scholar ]
- چو، Y.-H. لیو، P.-S. دزانی، RJ پیچیدگی زمین و کاهش داده های توپوگرافی. جی. جئوگر. سیستم 1999 ، 1 ، 179-198. [ Google Scholar ] [ CrossRef ]
- اندرسون، ES; تامپسون، جی. اثرات تراکم آستین، RE LiDAR و درون یاب خطی بر برآورد ارتفاع. بین المللی J. Remote Sens. 2005 ، 26 ، 3889-3900. [ Google Scholar ] [ CrossRef ]
- لیو، ایکس. کاهش داده های Zhang, Z. LiDAR برای تولید DEM کارآمد و با کیفیت. بین المللی قوس. فتوگرام حسگر از راه دور اسپات. Inf. علمی 2008 ، 37 ، 173-178. [ Google Scholar ]
- اوریسپایف، دی. سوگوماران، ر. دی گروت، جی. Gray, P. LiDAR کاهش داده با استفاده از decimation و پردازش راس با GPGPU و فناوری CPU چند هسته ای. محاسبه کنید. Geosci. 2012 ، 43 ، 118-125. [ Google Scholar ] [ CrossRef ]
- هگمن، JW; سردشمخ، VB; سوگوماران، ر. آرمسترانگ، MP، پردازش داده LiDAR را در یک محیط محاسبات ابری با حافظه بالا توزیع کرد. ان GIS 2014 ، 20 ، 255-264. [ Google Scholar ] [ CrossRef ]
- کوبلر، ا. فایفر، ن. Ogrinc، P. تودورفسکی، ال. اوستیر، ک. Džeroski، S. درونیابی مکرر: یک الگوریتم قوی برای تولید DTM از دادههای اسکنر لیزری هوایی در زمینهای جنگلی. سنسور از راه دور محیط. 2007 ، 108 ، 9-23. [ Google Scholar ] [ CrossRef ]
- ZakÅ¡ek، K. فایفر، ن. IAPÅ، ZS یک فیلتر مورفولوژیکی بهبود یافته برای انتخاب نقاط تسکین از یک ابر نقطه LiDAR در مناطق شیب دار با پوشش گیاهی متراکم . موسسه مطالعات انسان شناسی و فضایی، مرکز تحقیقات علمی آکادمی علوم و هنر اسلوونی: لوبلیانا، اسلوونی. موسسه جغرافیا، دانشگاه اینسبروک: اینسبروک، اتریش، 2006. [ Google Scholar ]
- کراوس، ک. Otepka، J. DTM Modeling and Visualization-The Scop Approach. در مجموعه مقالات هفته فتوگرامتری 05، هایدلبرگ، آلمان؛ 2005; ص 241-252. [ Google Scholar ]
- لیو، ایکس. ژانگ، ز. پیترسون، جی. اطلاعات کنترل زمینی با کیفیت بالا و DEM برای تصحیح تصویر به دست آمده از Chandra، S. Lidar. GeoInformatica 2007 ، 11 ، 37-53. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- زیمرمن، دی. پاولیک، سی. راگلز، ا. آرمسترانگ، MP مقایسه تجربی کریجینگ معمولی و جهانی و وزن دهی فاصله معکوس. ریاضی. جئول 1999 ، 31 ، 375-390. [ Google Scholar ] [ CrossRef ]
- لیو، ایکس. ژانگ، ز. Peterson, J. ارزیابی عملکرد الگوریتم های درونیابی DEM برای داده های LiDAR. در مجموعه مقالات کنفرانس بین المللی دوسالانه مؤسسه نقشه برداری و علوم فضایی (SSC 2009)، آدلاید، استرالیا، 28 سپتامبر تا 2 اکتبر 2009. صص 771-779.
- فیشر، پی اف. Tate، NJ علل و پیامدهای خطا در مدلهای ارتفاعی دیجیتال. Prog. فیزیک Geogr. 2006 ، 30 ، 467-489. [ Google Scholar ] [ CrossRef ]
- Podobnikar, T. DEM مناسب برای کاربرد مورد نیاز. در مجموعه مقالات چهارمین سمپوزیوم بین المللی زمین دیجیتال، توکیو، ژاپن، 28 تا 31 مارس 2005.
- علی، TA در انتخاب یک روش درونیابی برای ایجاد یک مدل زمین (TM) از داده های LiDAR. در مجموعه مقالات کنگره آمریکا در مورد نقشه برداری و نقشه برداری (ACSM) کنفرانس، نشویل، TN، ایالات متحده; 2004. [ Google Scholar ]
- نقشه ملی – ارتفاع. در دسترس آنلاین: http://ned.usgs.gov/ (در 30 آوریل 2016 قابل دسترسی است).
- لیو، ایکس. ژانگ، ز. پیترسون، جی. چاندرا، اس. اثر چگالی داده LiDAR بر دقت DEM. در مجموعه مقالات کنگره بین المللی مدل سازی و شبیه سازی (MODSIM07)، کرایست چرچ، نیوزیلند، 10-13 دسامبر 2007. صص 1363–1369.
- Coulthard, J. Quikgrid: رندر سه بعدی سطحی که توسط نقاط داده پراکنده نشان داده شده است. در دسترس آنلاین: http://www.galiander.ca/quikgrid/ (دسترسی در 30 آوریل 2016).
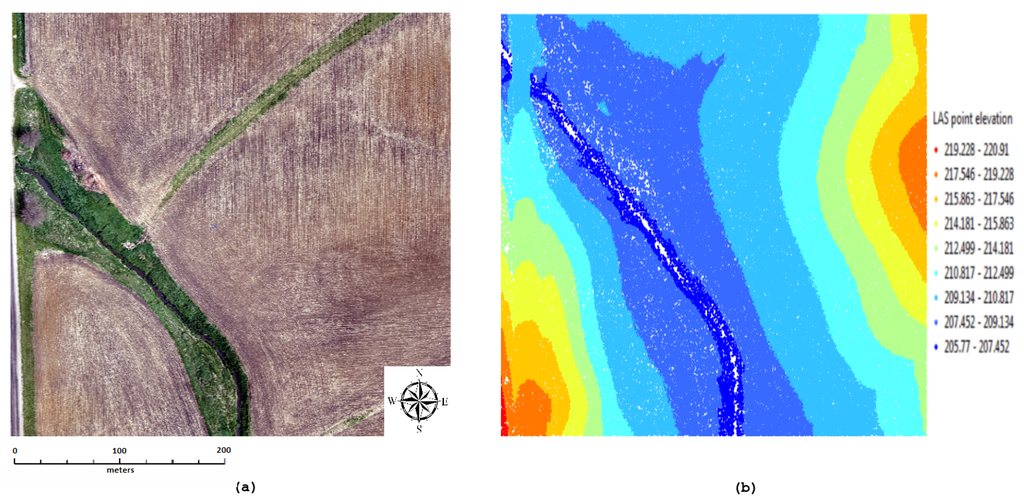
شکل 1. ( الف ) تصاویر منطقه مورد مطالعه و ( ب ) ابر نقطه LiDAR 2 بعدی از منطقه مورد مطالعه، که بر اساس تغییرات در ارتفاع رنگی شده است.
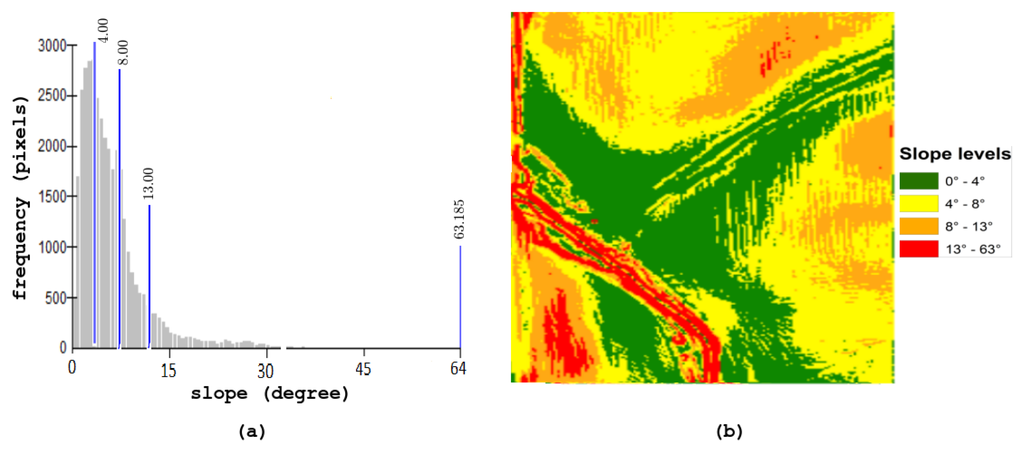
شکل 2. ( الف ) تجزیه و تحلیل آماری داده های ارتفاعی برای زمین. ( ب ) نقشه شیب شامل چهار محدوده شیب.
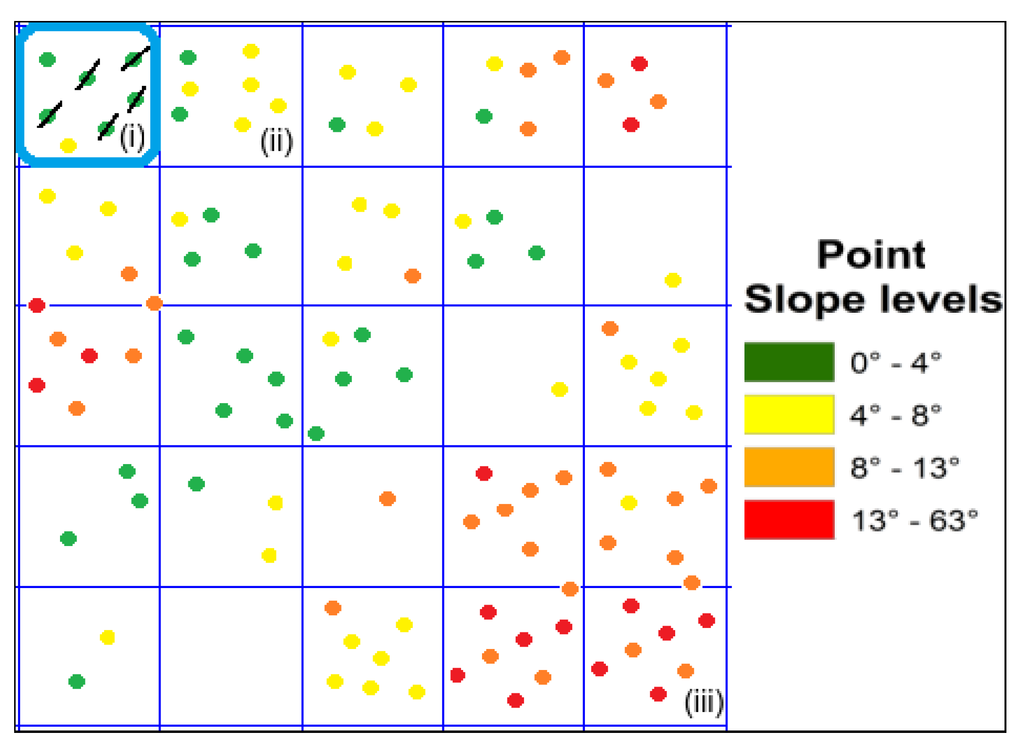
شکل 3. الگوریتم کاهش داده: شبکه روی داده های پردازش شده LiDAR پوشانده شده است.
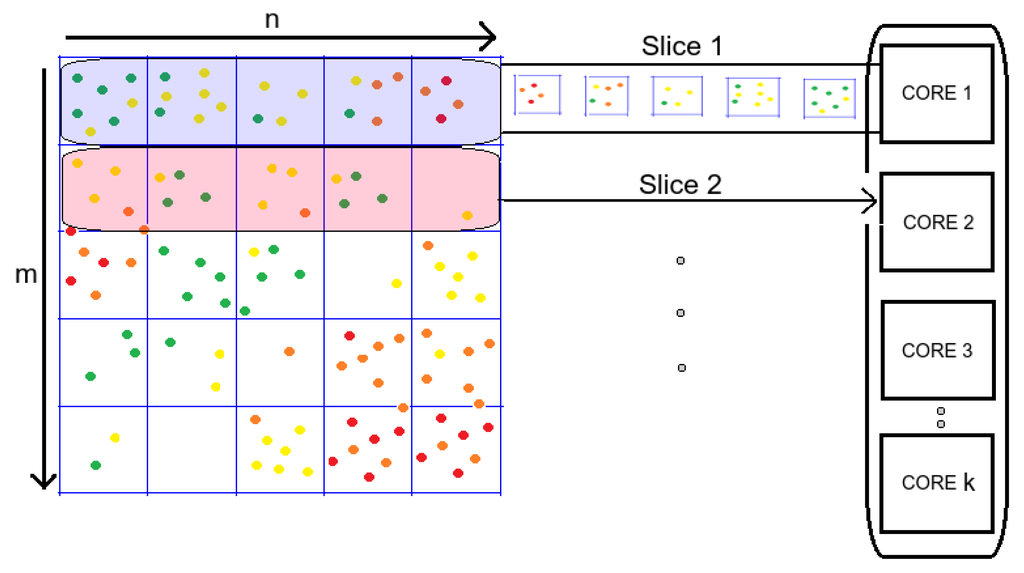
شکل 4. اجرای موازی الگوریتم کاهش داده ها.
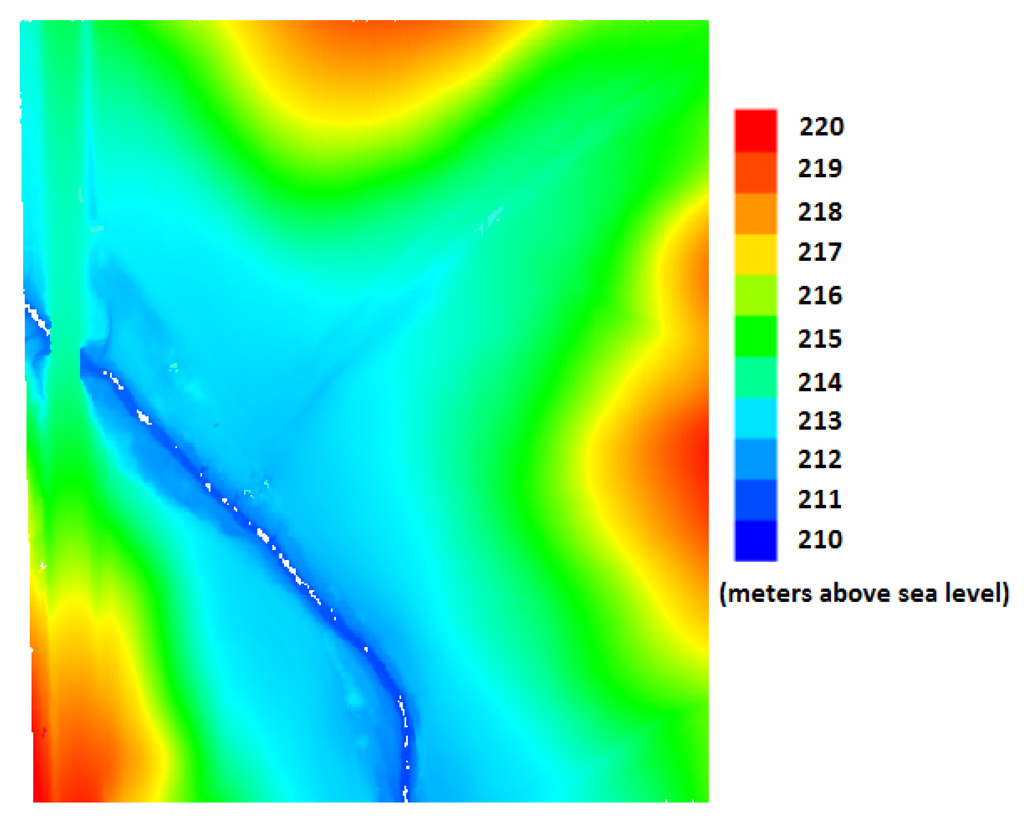
شکل 5. DEM تولید شده برای مجموعه داده اصلی دارای 6 . 946.94میلیون امتیاز LiDAR
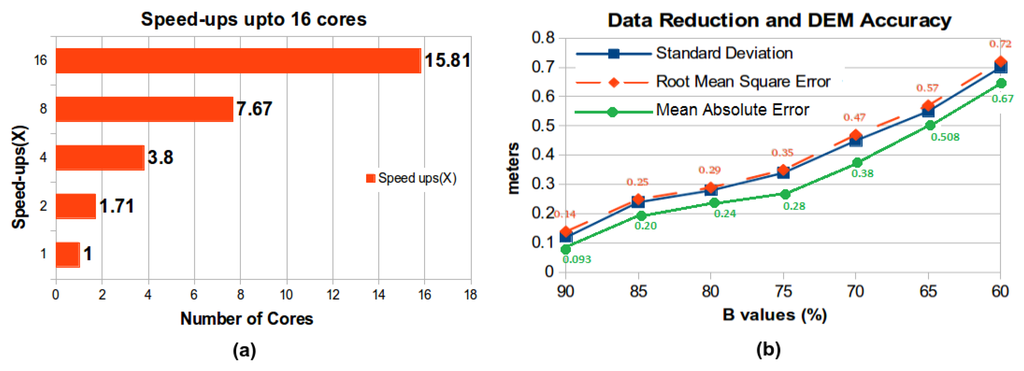
شکل 6. ( الف ) افزایش سرعت موازی برای الگوریتم کاهش داده LiDAR. ( ب ) کاهش داده ها و دقت DEM.
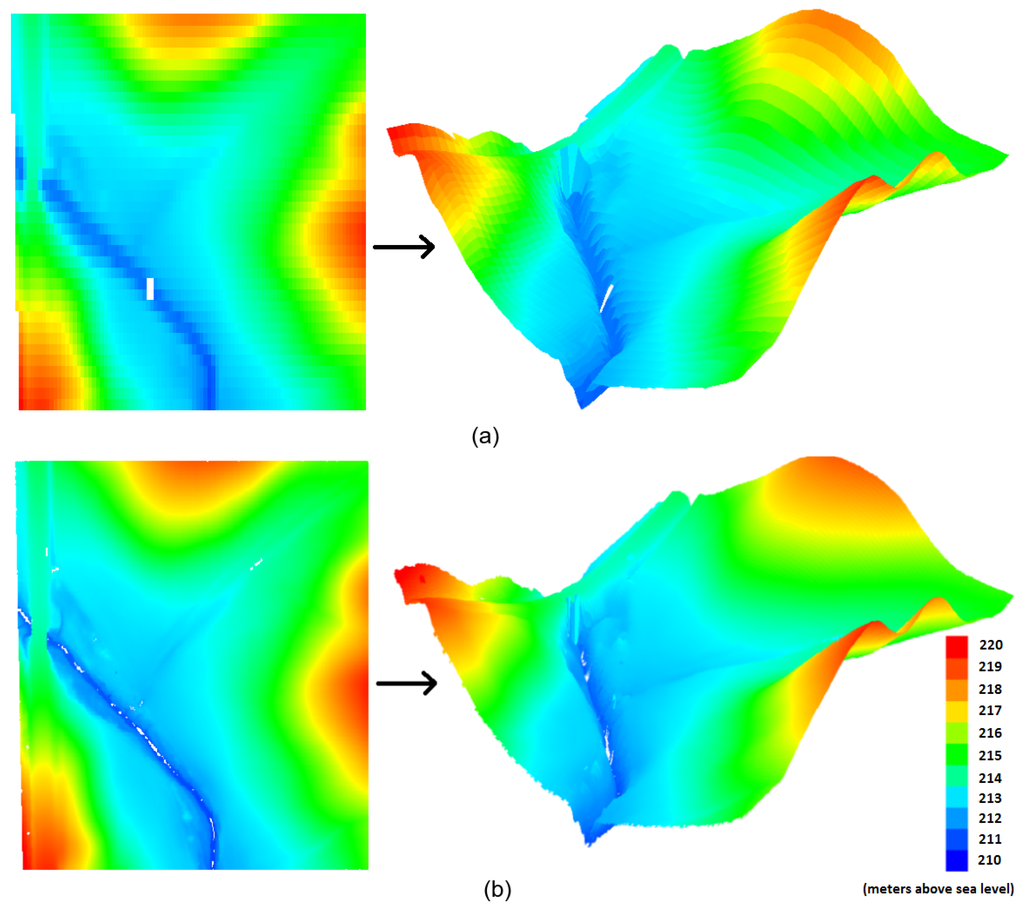
شکل 7. ( الف ) β= 80 ٪�=80%، مجموعه داده کاهش یافته شامل 2 . 22.2میلیون امتیاز؛ ( ب ) β= 90 ٪�=90%، کاهش داده های حاوی 3 . 13.1میلیون امتیاز

شکل 8. ( الف ) شبکه ای از k متر مربع. ( k > 0ک>0) روی داده های LiDAR پوشانده شده است. ( ب ) انتخاب شعاع های برش و تعیین وزن به تقاطع های شبکه. ( ج ) تعیین وزن به هر سلول شبکه.
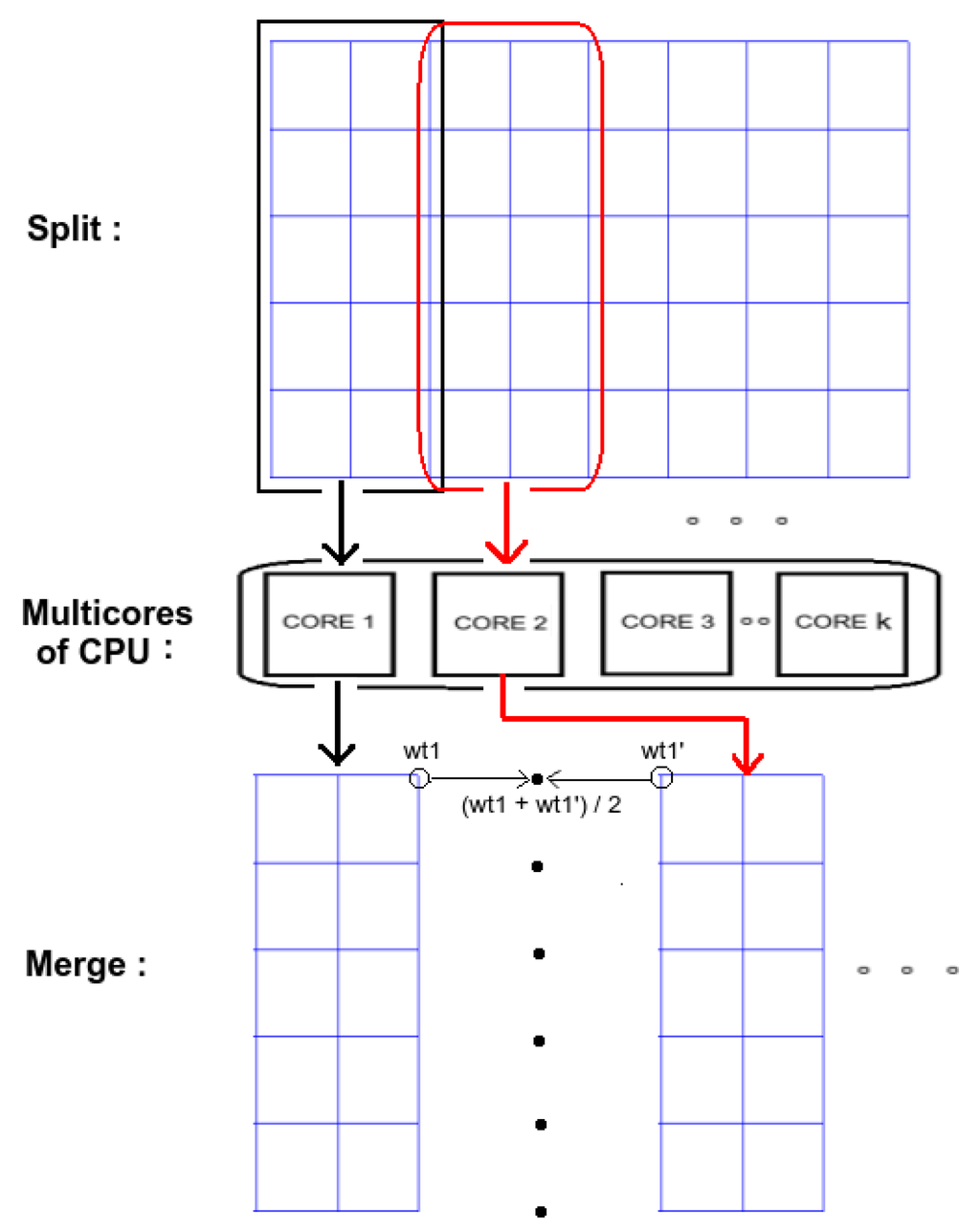
شکل 9. فازهای تقسیم و ادغام موازی الگوریتم درونیابی فضایی ما.
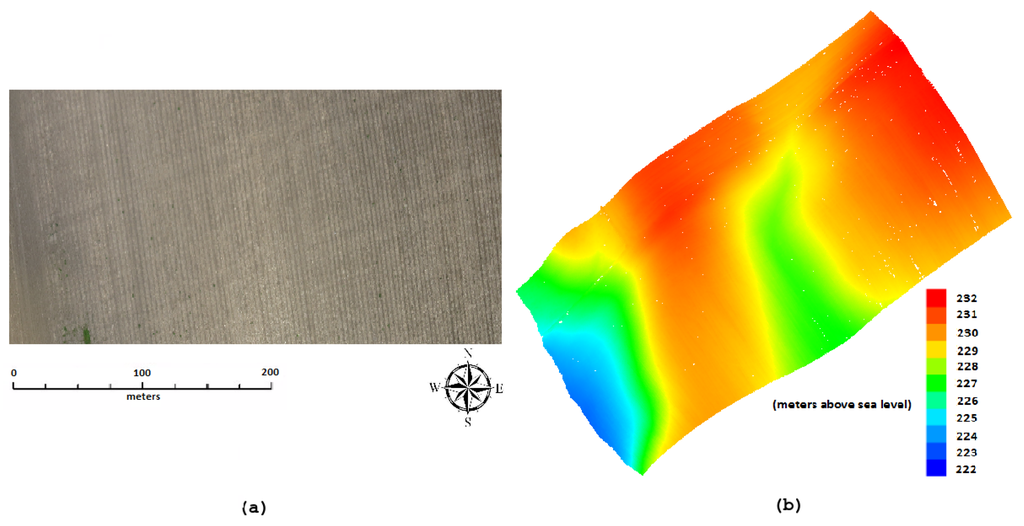
شکل 10. ( الف ) تصاویر منطقه مورد مطالعه برای مجموعه داده 2. ( ب ) نقشه ارتفاعی مجموعه داده 2 که زمین با ناهمواری کمتر، دره های کم عمق و مناطق مسطح را نشان می دهد.

شکل 11. ( الف ) افزایش سرعت موازی برای الگوریتم فضایی ما. ( ب ) RMSE برای IDW و IDW اصلاح شده در سطوح مختلف چگالی LiDAR برای دو مجموعه داده با استفاده از روش اعتبارسنجی.

جدول 1. دستورالعمل هایی برای انتخاب مقدار β برای زمین های مختلف.
© 2016 توسط نویسندگان؛ دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (CC-BY) (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر