

خلاصه
سفرهای تاریخی رویدادهایی هستند که با ویژگی های اکتشافی، علمی، نظامی یا جغرافیایی مزه دار می شوند. چنین رویدادهایی اغلب در ادبیات، یادداشت های سفر یا خاطرات شخصی ثبت می شوند. یک اکسپدیشن تاریخی معمولی شامل بازدیدهای متعدد از سایت است و توضیحات آنها شامل زمینههای مکانی-زمانی و اسنادی است. اکسپدیشن ها شامل حرکاتی در فضا هستند که می توانند با ویژگی های سه گانه (موقعیت، زمان و شرح) نمایش داده شوند. با این حال، چنین ویژگی هایی جزء ضمنی و ذاتی اسناد متنی هستند. استخراج اطلاعات مکانی از این اسناد مستلزم درک موجودیت های متنی در متن است. به این منظور، ما یک چارچوب نیمه خودکار ایجاد کردیم که دارای اجزای متعدد بازیابی اطلاعات و پردازش زبان طبیعی است تا اطلاعات مکانی-زمانی را از یک روزنامه دو جلدی اکسپدیشن تاریخی استخراج کند. چارچوب ما دارای سه جزء اساسی است، یعنی پیش پردازشگر متن، ماشین پردازش Gazetteer و مبدل JAPE (موتور الگوی حاشیه نویسی جاوا). ما از روزنامه پرندهشناسی برزیل بهعنوان یک مجموعه داده تجربی استفاده کردیم و موجودیتهای مکانی و زمانی را از ورودیهایی استخراج کردیم که به بازدیدهای سایت سه اعزامی (که بین سالهای 1910 و 1926 انجام شد) اشاره میکردند و مسیر هر سفر را با استفاده از اطلاعات استخراجشده ترسیم کردیم. در نهایت، یکی از مسیرهای نقشهبرداری شده به صورت دستی با نقشه مرجع تاریخی آن سفر مقایسه شد تا قابلیت اطمینان چارچوب ما ارزیابی شود. ماشین پردازش Gazetteer و مبدل JAPE (موتور الگوی حاشیه نویسی جاوا). ما از روزنامه پرندهشناسی برزیل بهعنوان یک مجموعه داده تجربی استفاده کردیم و موجودیتهای مکانی و زمانی را از ورودیهایی استخراج کردیم که به بازدیدهای سایت سه اعزامی (که بین سالهای 1910 و 1926 انجام شد) اشاره میکردند و مسیر هر سفر را با استفاده از اطلاعات استخراجشده ترسیم کردیم. در نهایت، یکی از مسیرهای نقشهبرداری شده به صورت دستی با نقشه مرجع تاریخی آن سفر مقایسه شد تا قابلیت اطمینان چارچوب ما ارزیابی شود. ماشین پردازش Gazetteer و مبدل JAPE (موتور الگوی حاشیه نویسی جاوا). ما از روزنامه پرندهشناسی برزیل بهعنوان یک مجموعه داده تجربی استفاده کردیم و موجودیتهای مکانی و زمانی را از ورودیهایی استخراج کردیم که به بازدیدهای سایت سه اعزامی (که بین سالهای 1910 و 1926 انجام شد) اشاره میکردند و مسیر هر سفر را با استفاده از اطلاعات استخراجشده ترسیم کردیم. در نهایت، یکی از مسیرهای نقشهبرداری شده به صورت دستی با نقشه مرجع تاریخی آن سفر مقایسه شد تا قابلیت اطمینان چارچوب ما ارزیابی شود. ما از روزنامه پرندهشناسی برزیل بهعنوان یک مجموعه داده تجربی استفاده کردیم و موجودیتهای مکانی و زمانی را از ورودیهایی استخراج کردیم که به بازدیدهای سایت سه اعزامی (که بین سالهای 1910 و 1926 انجام شد) اشاره میکردند و مسیر هر سفر را با استفاده از اطلاعات استخراجشده ترسیم کردیم. در نهایت، یکی از مسیرهای نقشهبرداری شده به صورت دستی با نقشه مرجع تاریخی آن سفر مقایسه شد تا قابلیت اطمینان چارچوب ما ارزیابی شود. ما از روزنامه پرندهشناسی برزیل بهعنوان یک مجموعه داده تجربی استفاده کردیم و موجودیتهای مکانی و زمانی را از ورودیهایی استخراج کردیم که به بازدیدهای سایت سه اعزامی (که بین سالهای 1910 و 1926 انجام شد) اشاره میکردند و مسیر هر سفر را با استفاده از اطلاعات استخراجشده ترسیم کردیم. در نهایت، یکی از مسیرهای نقشهبرداری شده به صورت دستی با نقشه مرجع تاریخی آن سفر مقایسه شد تا قابلیت اطمینان چارچوب ما ارزیابی شود.
کلید واژه ها:
بازیابی اطلاعات جغرافیایی ; بازیابی اطلاعات زمانی ; پردازش زبان طبیعی ; استنتاج زمانی
1. معرفی
سفرهای تاریخی سفرهایی هستند که در گذشته با اهداف اکتشافی، علمی، نظامی یا جغرافیایی انجام شده اند [ 1]]. ویژگیهای مکانی و مضمونی چنین سفرهای تاریخی احتمالاً اغلب در اسناد چاپی، که ماهیت متنی دارند، نشان داده میشوند. به طور کلی، زمینه هایی که در اسناد سفرهای تاریخی وجود دارد، مکانی، زمانی و توصیفی است. استخراج عناصر از اسناد متنی، جایگزین هایی برای بازنمایی و تجسم آن رویدادهای تاریخی در یک محیط زمانی و مکانی فراهم می کند. سفرهای تاریخی مجموعهای از رویدادهای گذشته هستند که احتمالاً در قالبهای متنی بدون ساختار ثبت شدهاند و احتمالاً آثار خود را در تاریخ به جا گذاشتهاند. خواندن چنین اسنادی برای تجسم رویدادها با دیدگاه کامل مکانی و زمانی یا برای انجام مطالعات بیشتر کافی نیست. استخراج مطالب مکانی و زمانی و توصیفی از اسناد برای بدست آوردن زمینه های مرتبط الزامی است.
روزنامهنگاران اکسپدیشن (در اینجا به عنوان اسنادی که روایتی از مکانها و رویدادهای مربوط به اکسپدیشنها را ارائه میکنند) اغلب سه ویژگی اساسی دارند: مکانی، زمانی و توصیفی. سفرهای تاریخی برای اهداف مختلف انجام شد. با این حال، روزنامه نگاران چنین سفرهایی دارای ویژگی های مشترک هستند: همه آنها عبارات مکانی، زمانی و توصیفی در متون مربوطه خود دارند. از این رو، هدف اصلی این مقاله ارائه یک چارچوب استخراج اطلاعات مکانی-زمانی است که آن روزنامهها را مصرف میکند و موجودیتهای مکانی و زمانی را از متون استخراج میکند.
استخراج موجودیتهای مکانی-زمانی از روزنامههای اعزامی چالش برانگیز است زیرا ممکن است حاوی نامهای متداول ، نامهایی که مردم محلی به مکانها دادهاند، یا نامهای متعارف ، نامهایی که افراد خارجی به مکانها دادهاند، یا ممکن است عباراتی داشته باشند که روابط مکانی-زمانی را بیان میکنند. علاوه بر این، یک متن روزنامه ممکن است ابهام مکانی و زمانی را نشان دهد. یک موجود فضایی ممکن است با یک عبارت مبهم مانند « چند مایلی از مکان X» مشخص شودممکن است نام مکان یا مختصات وجود نداشته باشد، که منجر به نتایج مبهم استخراج اطلاعات می شود. دامنه این مقاله هم روابط فضایی و هم ابهام فضایی را پوشش نمی دهد. علاوه بر این، ابهام زمانی در متون روزنامه ممکن است باعث ایجاد ابهام در هنگام استخراج چنین مواردی شود. به عنوان مثال، نشانگر زمانی مانند ” ژانویه 1922” مبهم است زیرا تاریخ شروع و پایان رویدادهای توصیف شده صریح نیست و چنین ابهامی منجر به مدت زمان غیرقابل قطعی رویداد می شود. شناسایی و استخراج یک موجودیت زمانی و مکانی واضح – که به صراحت ذکر شد – نسبتا آسان است. با این وجود، استخراج موفقیتآمیز اطلاعات مکانی و زمانی نیاز به رفع این ابهام مکانی و زمانی دارد. در چارچوب خود، ما فقط به ابهام زمانی در متون روزنامه اعزامی می پردازیم. این چارچوب دارای یک استنتاج و ابزار استدلال زمانی برای تعیین، در صورت امکان، مرزهای زمانی از دست رفته است.
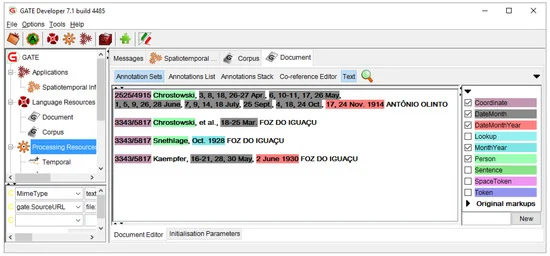
تقریباً 80٪ از کل اطلاعات جهان به عنوان اسناد متنی بدون ساختار ذخیره می شود و 85٪ از آن دارای ردپای مکانی – زمانی است [ 1 ]. در نتیجه، تقاضای زیادی برای روشهایی برای ساختار و استخراج چنین محتویاتی وجود دارد. به عنوان مثال، روزنامه پرندهشناسی برزیل [ 2 ، 3] – مجموعهای که ما برای این پروژه تحقیقاتی استفاده میکنیم – تقریباً 6000 مکان برزیلی را که در آن پرندگان مشاهده یا جمعآوری شدهاند شناسایی میکند (این مقاله بهویژه بر روی سه سفر در سالهای 1910-1926 تمرکز دارد). خواندن متن به طور کامل نیاز به تجسم سفر تاریخی انجام شده از منظر مکانی-زمانی را برآورده نمی کند، زیرا مملو از موجوداتی مانند نام افراد، نام مکان ها، نام مؤسسه ها و نشانگرهای مکانی و زمانی است که با زبان طبیعی توصیف شده است (شکل 1 را ببینید) . ). درک عمیق مکانی و زمانی می تواند به مشخص کردن زمان یا مکان واقعی رویدادها کمک کند، یا در غیر این صورت، احتمالاً می تواند به محدود کردن گزینه های زمان/مکان کمک کند.
بنابراین ما به روشهای پردازش زبان طبیعی (NLP) و بازیابی اطلاعات (IR) برای استخراج این موجودیتهای مکانی/زمانی/مکانی از متن برای تجسم رویدادها در یک محیط مکانی-زمانی و امکان تعیین دقیق نیاز داریم [1 ] . هدف کلی این مقاله ارائه و بحث در مورد یک چارچوب استخراج اطلاعات مکانی-زمانی نیمه خودکار با تکنیک های متعدد NLP و IR است که می تواند
-
استخراج اطلاعات مکانی-زمانی از متون روزنامه اعزامی تاریخی؛
-
کمک به درک روابط زمانی بین بازه های زمانی مبهم؛ و
-
استنتاج بازه های زمانی نسبی
رویکرد ما محدود به روزنامه پرندهشناسی برزیل نیست . قرار است برای هر روزنامه اعزامی که شامل عبارات مکانی، زمانی و توصیفی در متن خود باشد کار کند.
2. کارهای مرتبط
2.1. استخراج اطلاعات مکانی از وب و اسناد متنی
موتورهای جستجوی وب استاندارد، اصطلاحات مکانی را درست مانند عبارات توصیفی که به عنوان کلمات کلیدی برای جستجوی اسناد، اطلاعات یا خدمات خاص مورد استفاده قرار می گیرند، رفتار می کنند. این ممکن است منجر به شکست در یافتن نتایج جستجوی مرتبط شود. با این حال، ارتباط نمایه سازی فضایی و متنی در [ 4 ] به عنوان راه حل پیشنهاد شده است. مطالعه در [ 5 ] از آدرس ها و کدهای پستی، شماره تلفن، نام ویژگی های جغرافیایی و لینک ها به عنوان منابع زمینه مکانی برای کشف محتوای جغرافیایی در صفحات وب استفاده می کند. اگرچه بسیاری از مطالعات آکادمیک در حوزه فناوری جستجوی جغرافیایی عمدتاً بر تکنیکهای استخراج دانش جغرافیایی از وب متمرکز شدهاند، چن و همکاران. [ 6] مشکل پردازش پرس و جو کارآمد در موتورهای جستجوی جغرافیایی مقیاس پذیر را مطالعه کرده و چندین الگوریتم پردازش پرس و جو را پیشنهاد می کند که امتیاز اسنادی را که شامل عبارات پرس و جو هستند محاسبه می کند. این مطالعه به بررسی چگونگی به حداکثر رساندن توان پرس و جو برای اندازه مشکل و مقدار سخت افزار معین می پردازد.
در نتیجه اینترنت مرسوم که بعد جغرافیایی را به خود اختصاص داده است، اسناد وب در حال تبدیل شدن به اشیاء دارای برچسب جغرافیایی هستند. با در نظر گرفتن هم مجاورت فضایی و هم ارتباط متن در چنین اشیایی، وو و همکاران. [ 7 ] چارچوب نمایه سازی و پرس و جو جدیدی را پیشنهاد می کند که با ادغام موقعیت جغرافیایی و متن به دست می آید.
تحقیقات زیادی برای استخراج اطلاعات مکانی از محتوای متنی مختلف، مانند پرسشهای وب، پیامهای متنی خرد، ابردادهها و مدخلهای ویکیپدیا انجام شده است [ 8 ، 9 ، 10 ، 11 ، 12 ]، و برخی تحقیقات [ 13 ] انجام شده است. در مورد بازیابی اطلاعات زمانی از اسناد متنی. تلاش ما بر معرفی روشهای استخراج اطلاعات مکانی یا زمانی از محتوای متن نسبتاً ساختاریافته متمرکز است. با این حال، یک چالش مهم در پر کردن شکاف معنایی بین دادههای جغرافیایی ساختیافته که در یک GIS نگهداری میشود و اطلاعات مکانی که تجزیه و تحلیل آن دشوار است، به زبان طبیعی [14] باقی مانده است . مطالعه در [ 14] از یک پلت فرم پردازش اطلاعات زبان طبیعی به نام GATE (معماری عمومی برای مهندسی متن) برای استخراج موجودیتهای نامگذاری شده جغرافیایی و روابط فضایی مرتبط در زبان طبیعی، بر اساس قوانین نحوی از یک مجموعه حاشیهنویسی در مقیاس بزرگ استفاده میکند. مطالعه در [ 15 ] خود حاشیه نویسی را به عنوان یک رویکرد یادگیری تحت نظارت جدید برای توسعه و پیاده سازی سیستمی معرفی کرد که روابط دقیق بین موجودیت ها (مانند روابط جغرافیایی) را استخراج می کند. مزیت اصلی خود حاشیه نویسی این است که نیازی به برچسب زدن دستی ندارد. مطالعاتی برای استخراج اطلاعات مکانی و زمانی از اسناد انجام شده است. به عنوان مثال، استروتگن و همکاران. [ 16] رویکردی را ارائه میکند که حوزههای بازیابی اطلاعات زمانی (TIR) و بازیابی اطلاعات جغرافیایی (GIR) را در زمینه کاوش اسناد و وظایف استخراج اطلاعات ترکیب میکند. علاوه بر این، چارچوب ما بر استخراج اطلاعات مکانی و زمانی (جغرافیایی و زمانی) از روزنامهنگاران اکسپدیشن تاریخی متمرکز است.
GIR تعامل GIS و IR است. بریسابوآ و همکاران [ 17 ] دو نوع رویکرد بازیابی اطلاعات را ارائه میکند که در چنین حوزهای قرار دارند، بهویژه، یک تکنیک متنی و یک تکنیک فضایی، که به ترتیب جنبههای زبانی و فضایی اسناد را هدف قرار میدهند. از سوی دیگر، بوگورایف و آندو [ 13 ] چارچوب تحلیل زمانی را برای کشف بعد زمانی یک پیکره توصیف می کنند.
راهنماهای سفر و خاطرات سفر در [ 18 ] برای تشخیص صحیح اطلاعات جغرافیایی و ساخت مجموعه داده های مسیر واقعی که می توانند بر روی نقشه تجسم شوند استفاده شدند . در این پروژه تحقیقاتی به استخراج اطلاعات جغرافیایی نسبی و مطلق دست یافته است. مزیت اصلی روش مورد استفاده در [ 18 ] این است که فقط از اطلاعات زبانی، معنایی و زمینه ای موجود در اسناد ارائه شده استفاده می شود. مطالعه در [ 19 ] سیستمی را ارائه کرد که یک استدلال فضایی-زبانی را برای تفسیر زبان فضایی ذکر شده در شرح تصاویر اضافه می کند. این سیستم به تعیین مکان تصاویر بر اساس اطلاعات مکانی موجود در زیرنویس آنها کمک می کند.
2.2. تجزیه جغرافیایی
تجزیه جغرافیایی روشی است که موجودیت های مکانی را در اسناد متنی شناسایی و حاشیه نویسی می کند [ 20 ]. یک وب سرویس تجزیه جغرافیایی توسط [ 21] برای استخراج اطلاعات مکانی از روایات سفر با استفاده از Yahoo! Placemaker به عنوان یک ابزار برچسب گذاری جغرافیایی. این سرویس دارای دو مرحله اصلی است: استخراج موجودیت و ابهامزدایی. با این حال، موضوع موقعیت نسبی اشیاء فضایی مورد توجه قرار نگرفت. این سرویس میتواند موجودیتهای مکانی را استخراج کرده و آنها را تجسم کند، اما روابط مکانی-زمانی بین موجودیتها در این رویکرد مورد مطالعه قرار نگرفت. چنین روایاتی اغلب حاوی موجودیت های زمانی مبهم هستند که برای حل آنها به ابزار استنتاج زمانی نیاز دارند. برخلاف این رویکرد، چارچوب ما شامل یک ابزار استنتاج زمانی برای حل ابهام زمانی در متون روزنامه اعزامی است. علاوه بر این، این چارچوب بر استخراج اطلاعات مکانی و زمانی از روزنامهنگاران اکسپدیشن تاریخی تمرکز دارد. به این منظور،
2.3. استدلال زمانی
یک فعالیت استدلالی در یک حوزه پویا باید شامل یک دیدگاه زمانی باشد [ 22 ]. نیمه بازه زمانی یک زمان اولیه است که نقطه شروع یا پایان یک رویداد است (رویداد در مورد ما بازدید از مکان است). در [ 23 ]، از نیمه بازه های زمانی و روابط آنها به عنوان واحدهای اساسی دانش زمانی استفاده می شود. استدلال زمانی بین نیمفاصلههای زمانی نیاز به قابلیت استدلال برای محاسبه عضو موقت گمشده اولیه دارد، اعم از شروع یا پایان .از یک رویداد روزنامه پرندهشناسی برزیل دارای توضیحات مکان با علائم زمانی غیر واضح است، بهعنوان مثال، ” اوت 1922″، یک موجودیت زمانی مبهم، زیرا تاریخ دقیق شروع و پایان رویداد که با این علامت نشان داده میشود، صریح نیست. در چنین مواردی، یک روش استنتاج زمانی برای استنتاج مرزهای زمانی نسبی یک بازدید از مکان معین مورد نیاز است. برای انجام این کار، چارچوب ما ابزاری دارد که یک بازه زمانی نسبی را برای بازدیدهای مکان تعریف شده مبهم نسبت به سایر بازدیدهای مکان به وضوح تعریف شده استنباط می کند.
توصیفات تاریخی هنگام بازنمایی اطلاعات، زمان را به عنوان یک دغدغه اساسی دارند [ 24 ]. اگر توصیف زمانی یک رویداد تاریخی مبهم باشد، اطلاعات زمانی که باید استخراج شود در معرض عدم قطعیت است [ 24 ]. رویدادهای تاریخی همیشه با عبارات زمانی واضح نمایش داده نمی شوند، بلکه با عبارات غیردقیق و ذهنی نشان داده می شوند [ 24 ]. Nagypál و Motik [ 24 ] بیان میکنند که رویکردهای موجود برای مدلسازی زمانی مبتنی بر این فرض است که نمایش زمان واضح است. بنابراین این رویکردها را نمی توان برای تمام وظایف مدل سازی زمانی اعمال کرد. برای غلبه بر مشکلات بازنمایی اطلاعات مبهم زمانی، Nagypál و Motik [ 24 ] ارائه می کنند.مدل زمانی مبتنی بر فاصله فازی که قادر به گرفتن اطلاعات زمانی مبهم است.
لحظه های زمانی و فواصل زمانی به عنوان ابتدایی های زمانی در [ 24 ] ذکر شده است. با این حال، در صورتی که دانه بندی زمانی افزایش یابد و این فاصله یکی از فواصل زمانی شناخته شده معمول (مانند روز، هفته و ماه) باشد، یک لحظه زمانی به یک فاصله زمانی تبدیل می شود. به عنوان مثال، یک ماه زمانی در نظر گرفته می شود که در یک سال معین شمرده شود، اما یک ماه خود یک فاصله زمانی است که روزهای یک ماه معین، لحظه های زمانی در نظر گرفته می شوند. گزاره های زمانی در متون اعزامی تاریخی رایج هستند، اما همیشه واضح نیستند. در نتیجه، ممکن است با اطلاعات زمانی مبهم مواجه شویم. این دلیل اصلی گنجاندن ابزار استنتاج زمانی در چارچوب ما است.
3. منبع داده، ابزارها و روش ها
3.1. منبع اطلاعات
روزنامه پرندهشناسی برزیل، که دارای بیش از 6000 توصیف از مکانهایی است که در آن اکتشافات پرندهشناسی در سراسر برزیل فعالیت میکردند، توسط Paynter و Traylor گردآوری شد [ 2 ، 3 ]. روزنامه دارای سوابق بازدید از سایت توسط اکسپدیشن های شناخته شده است (در اینجا منظور از “اکسپدیشنر” شخصی است که اکسپدیشن ها را انجام می دهد). تادئوش کرستوفسکی (1878-1923، به شکل 2 مراجعه کنید)، ماریا امیلی اسنتلاج (1868-1929) و امیل هاینریش اسنتلاگ (1897-1939) سه نفر از اعزامیکنندگان مشهور هستند که نام آنها بارها در روزنامه ذکر شده است. از متون روزنامه که نام آن اعزامی ها را ذکر کرده بود برای آزمایش چارچوب ما استفاده شد. به عنوان مثال، نام “کرستوفسکی”در 58 مدخل ذکر شده است.
3.2. توسعه دهنده GATE
GATE (معماری عمومی برای مهندسی متن) یک پلت فرم پردازش متن است که برای توسعه برنامه هایی که زبان طبیعی را پردازش می کنند استفاده می شود [ 25 ]. این پلتفرم از اجزای پردازشی تشکیل شده است که می توانند برای سیستم های استخراج اطلاعات مورد استفاده قرار گیرند. GATE انواع مؤلفههای مختلفی دارد که به عنوان منابع شناخته میشوند، که قابل استفاده مجدد هستند، انواع تخصصی JavaBean، مؤلفههایی که میتوانند به صورت بصری در ابزار سازنده دستکاری شوند [ 25 ]. این منابع در سه نوع وجود دارند: منابع زبان (LRs)، منابع پردازش (PRs) و منابع بصری (VRs).
3.3. آنی
ANNIE (سیستم استخراج اطلاعات تقریباً جدید) یک ابزار استخراج اطلاعات است که با GATE توزیع شده است که بر اساس الگوریتم های پردازش متن متکی است که بر قطعه کردن جمله، تقسیم کردن، برچسب گذاری و تبدیل POS (بخشی از گفتار) و JAPE تمرکز دارد. Java Annotation Pattern Engine) زبانی است که برای تعریف الگوهای آیتم ها در یک نمایش متنی استفاده می شود [ 25 ].
3.3.1. توکنایزر ANNIE
Tokenizer ANNIE ابزاری است که یک متن را به تعدادی نشانه تایپ شده مانند کلمات و اعداد تقسیم می کند [ 25 ]. توکنایزر از قاعده ای استفاده می کند که دارای قسمت های LHS (سمت چپ) و RHS (سمت راست) است. LHS همیشه یک عبارت منظم است که باید با یک متن ورودی مقایسه شود، در حالی که RHS شامل عملی است که باید زمانی که عبارت LHS با متن ورودی تطبیق داده می شود انجام شود [25 ] . انواع توکن ایجاد شده توسط توکنایزر ANNIE در متون ورودی عبارتند از Word ، Number ، Punctuation و SpaceToken .
3.3.2. تقسیم کننده جمله ANNIE
تقسیمکننده جمله ANNIE یک مبدل است که یک متن ورودی را به تعدادی جمله تقسیم میکند. (در زمینه این مقاله، مبدل روشی با فازهای ورودی و خروجی است.) در بیشتر موارد، یک تقسیمکننده جمله قبل از یک نشانهساز قرار میگیرد، زیرا از علائم نگارشی در یک متن برای تقسیم سند به جملات استفاده میشود. تقسیمکننده جمله از فهرستی از اختصارات روزنامه استفاده میکند تا به آن کمک کند نقطه پایان جملهای را شناسایی کند [ 25 ]. به عنوان مثال، جمله ” آقای جانسون در فوریه 1989 به دنیا آمد ” را در نظر بگیرید. نقطه پایان بعد از « Mr” یک توقف جمله بندی نیست. لیست روزنامه اختصارات وابسته به کاربرد است و تابع ویژگیهای دستگاه پردازش متن است. پس از تقسیم، هر جمله به عنوان Sentence و هر شکست جمله به عنوان Sentence Split [ 25 ] حاشیه نویسی می شود.
3.3.3. ANNIE POS Tagger
برچسب ANNIE POS توکنایزر و تقسیم کننده را دنبال می کند. تگر یک تگ POS را به عنوان یک کلاس حاشیه نویسی در هر کد کلمه یا شماره تولید می کند . کلاس حاشیه نویسی تولید شده توسط برچسب توسط یک ماژول خط لوله برای استخراج موجودیت های نامگذاری شده استفاده می شود. هر تگ POS به عنوان یک دسته نشانه توسط سایر برنامه ها در نظر گرفته می شود، با این فرض که برنامه ها به یک POS برچسب گذاری شده نیاز دارند که از برچسب POS در خط لوله استخراج اطلاعات پیروی می کند.
پس از اینکه یک جمله توسط برچسب POS برچسب گذاری شد، کلاس های حاشیه نویسی خروجی به همراه دسته بندی های POS در قوانین دستور زبان JAPE برای تعریف قوانین LHS عبارات الگوی موجودیت استفاده می شوند. در اینجا، شایان ذکر است که کلاس های حاشیه نویسی بر روی جمله واقعی و دسته های POS دارای دستورات اجرایی هستند. مورد دوم همیشه قبل از حاشیه نویسی موجودیت ها – مکانی، زمانی و توصیفی در مورد ما – در متن واقعی اجرا می شود. بنابراین، دستههای POS ایجاد شده توسط برچسبگذار POS به همراه کلاسهای حاشیهنویسی ایجاد شده توسط روزنامه ANNIE ورودیهایی برای الگو هستند – مانند الگوهای تاریخ ” 14 ژانویه 1921″ و مختصات “9999/9999” – تعریف موجودیتها در متن روزنامه اعزامی.
3.3.4. روزنامه آنی
روزنامه ANNIE بخشی از ANNIE است که نام نهادها را در متن بر اساس لیست ها شناسایی می کند. با استفاده از روشی که متن را با فهرست موارد – نام مکان ها، نام افراد و ماه ها مطابقت می دهد، موجودات موجود در یک متن – نام مکان ها، نام افراد و ماه ها – را برچسب گذاری می کند. نام نهادها را در متن ورودی با بررسی وجود آنها در لیست آیتم ها شناسایی می کند. لیست ها فایل های متنی ساده با یک ورودی در هر خط هستند. هر فایل فهرست مجموعه ای از نام نهادها مانند شهرها، سازمان ها، روزهای هفته و ماه ها را نشان می دهد. موجودیت های دسته های مشابه باید فقط با انواع خود ذخیره شوند. این منبع برچسب گذاری را می توان به صورت حساس به حروف بزرگ یا غیر حساس تنظیم کرد.
لیست نام نهادها به عنوان یک فایل “.list” ذخیره می شود. یک فایل فهرست برای دسترسی به فایل های “.list” استفاده می شود. فایل “lists.def” تعریف هر فایل لیست را ارائه می دهد. این تعریف به ترتیب شامل نام فایل ، نوع اصلی ، نوع فرعی ، زبان و نوع حاشیه نویسی به عنوان ستون های یک تا پنج است .
3.4. JAPE: عبارات منظم بر روی حاشیه نویسی
JAPE (موتور الگوی حاشیه نویسی جاوا) اجازه می دهد تا عبارات منظم از پیش تعریف شده کلاس های حاشیه نویسی را بر روی اسناد متنی تشخیص دهد: یک عبارت منظم مجموعه ای از رشته ها است – شامل نمودارها نمی شود. مبدل JAPE همیشه از توکنایزر، تقسیمکننده، تگر POS و/یا ماژول پردازش روزنامه پیروی میکند. POS های برچسب گذاری شده یک متن ورودی و کلاس های حاشیه نویسی ایجاد شده توسط پردازنده gazetteer و قوانین دستور زبان JAPE توسط مبدل JAPE برای حاشیه نویسی یک متن ورودی استفاده می شود. این مجموعه از قوانین گرامری یکی از ماژول های اساسی در چارچوب ما است.
3.4.1. قانون گرامر JAPE
گرامر JAPE مجموعه ای از قوانین مبتنی بر الگو است که هر کدام از مجموعه ای از مراحل تشکیل شده است. این قوانین به عنوان یک فایل “.jape” ذخیره می شوند. اگر چند فاز تعریف شده باشد، از یک فایل فهرست برای دسترسی به مراحل دستور زبان JAPE استفاده می شود. هر یک از مراحل شامل مجموعه ای از قوانین الگو/عمل است. این قانون دارای یک بخش LHS و RHS است. LHS شامل الگویی از موجودیت ها در یک جمله است. قانون RHS شامل اقداماتی است که باید هر زمان که الگوی LHS در یک جمله تطبیق داده شود (متون ورودی) انجام شود. به طور کلی، قوانین دستور زبان JAPE از عملگرهای LHS زیر استفاده می کند:
-
(یا) |
-
(0 یا بیشتر موارد) *
-
(0 یا یک اتفاق)؟
-
(1 یا چند مورد) +
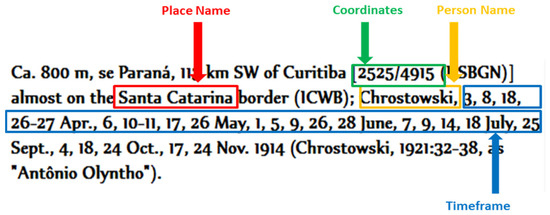
در زیر نمونهای از قانون JAPE است که فاصلهای را که با ترکیبی از کلمه، عدد و نشانههای نقطهگذاری نشان داده میشود، مشخص میکند، مانند «ca. 45.1 کیلومتر . در اینجا، “حدود”. یعنی تقریباً ( شکل 3 را ببینید ).
-
خط 1 نام فاز را تعریف می کند. هر یک از مراحل در گرامر JAPE باید یک نام منحصر به فرد داشته باشد، به عنوان مثال، در اینجا، فاز فاصله یاب نامیده می شود .
-
خط 2 حاشیه نویسی های ورودی را تعریف می کند که قانون LHS از آنها برای تطبیق الگو استفاده می کند و باید در ابتدای هر دستور زبان تعریف شود. در صورت عدم وجود تعریف صریح از حاشیه نویسی ورودی، پیش فرض ها Token ، SpaceToken و Lookup هستند .
-
خط 3 گزینه را تعریف می کند. دو نوع گزینه (کنترل و اشکال زدایی) وجود دارد که می توان در ابتدای هر قانون گرامری تنظیم کرد:
-
کنترل یک روش تطبیق قوانین است. گزینه های کنترل Appelt ، Brill ، All یا Once هستند . به عنوان مثال، Appelt قانون دستور زبان JAPE را مجبور می کند تا ابتدا یک قانون با اولویت بالاتر را راه اندازی کند.
-
اشکال زدایی را می توان روی true یا false تنظیم کرد. اگر روی درست تنظیم شود، تداخل بین بیش از یک تطابق احتمالی را اعلام می کند.
-
-
خط 4 نام قانون را تعریف می کند. در این مثال، نام فاصله است .
-
خط 5 اولویت قانون را تعریف می کند. اگر چندین قانون در یک فاز وجود داشته باشد، قوانین با اولویت بالاتر قبل از بقیه فعال و مطابقت داده می شوند.
-
خط 6-23 LHS قانون است. در اینجا قانون بخشی از متن ورودی را که ترکیبی از کلمه و عدد است جستجو می کند. این قانون الگوی LHS دارای سه الگوی فرعی است:
-
الگوی فرعی یک با ترکیبی از کلمه، علائم نگارشی و فضای سفید برابر با “Ca” مطابقت دارد. یا “حدود” ; به فضای سفید قبل از نقل قول های پایانی توجه کنید (خط 6-10) .
-
الگوی فرعی دو با رشتهای از ارقام در یکی از قالبهای زیر مطابقت دارد: «9»، «99»، «999»، «9999»، «99999» (خط 11-17).
-
الگوی فرعی سه با ترکیبی از علائم نگارشی، عدد، فضای سفید و کلمه ای که شبیه “0.1 کیلومتر” است مطابقت دارد (خط 18-21).
-
الگوهای فرعی در ترکیب یک قانون الگو ایجاد می کنند که با فاصله در یک متن مطابقت دارد (به عنوان مثال، “حدود 45 کیلومتر” ). هنگامی که بخشی از متن با این الگو تطبیق داده می شود، قانون LHS قسمت مطابقت شده را با یک برچسب موقت تگ می کند. در این مثال، برچسب موقت فاصله است .
-
خط 23 کلاس حاشیه نویسی موقت را تعریف می کند.
-
خط 24 LHS و RHS را از هم جدا می کند.
-
خط 25 RHS قانون تغییر نام برچسب موقت ( خط 23 ) به یک کلاس حاشیه نویسی دائمی است. در این مثال، فاصله برچسب موقت به یک برچسب دائمی ( Distance ) تغییر نام داده می شود. برچسب جدید به عنوان یک کلاس حاشیه نویسی توسط سایر مراحل JAPE شناخته می شود.
3.4.2. ماکرو LHS
ماکروهای LHS روش هایی هستند که امکان ایجاد تعریفی از یک عبارت منظم را فراهم می کنند که می تواند چندین بار در قوانین JAPE استفاده شود. ماکروهای LHS قوانین مستقلی نیستند که یک موجودیت را حاشیه نویسی کنند، اما از آنها به عنوان الگوهای فرعی از قانون دستور زبان JAPE استفاده می شود که با بخش های یک متن مشخص مطابقت دارد. این ماکروها در داخل قانون تعریف شده برای مطابقت با یک موجودیت خاص فراخوانی می شوند.
3.4.3. مبدل JAPE
یک مبدل محتویات ورودی خود، قانون LHS، را به محتوای خروجی جدید، قانون RHS ترجمه می کند. در زمینه ما، یک متن ورودی به نام Expedition Gazetteer را می گیرد و متنی را با کلاس های حاشیه نویسی باز می گرداند.
4. چارچوب استخراج اطلاعات فضایی و زمانی
چارچوب نیمه خودکاری که در این بخش ارائه کردیم دارای اجزای متعددی است. بیشتر مؤلفه ها از مؤلفه های پیش فرض برنامه پردازش متن GATE ساخته شده اند. با این حال، ما معتقدیم که این چارچوب دو کمک به زمینه های تحقیقاتی GIR و TIR دارد. سهم چارچوب برای میدان GIR نشان میدهد که چگونه میتوان اطلاعات مکانی-زمانی را با استفاده از تکنیکهای تطبیق الگو و فهرست از یک روزنامه اعزامی استخراج کرد. علاوه بر این، سهم چارچوب برای TIR الگوریتم استنتاج زمانی است (به بخش 4.7 مراجعه کنید ) – ما استنتاج زمانی را به عنوان نوآورانهترین بخش مقاله خود در نظر میگیریم.
تمام اجزای ANNIE برای ساخت چارچوب استخراج اطلاعات مکانی-زمانی استفاده می شود. چارچوب دارای سه جزء اساسی است، یعنی پیش پردازشگر متن، ماشین پردازش روزنامه و مبدل JAPE ( شکل 4 را ببینید.). این مؤلفهها چارچوب استخراج اطلاعات مکانی-زمانی متنی را تشکیل میدهند. ماژول پیش پردازشگر متن یک حاشیه نویس اولیه است که متن روزنامه اکسپدیشن را به توکن ها تقسیم می کند و برچسب گذاری POS را انجام می دهد. از سوی دیگر، ماشین پردازش gazetteer و مبدل JAPE ماژولهای اصلی هستند که موجودیتهای مکانی و زمانی را از متون روزنامه اعزامی شناسایی و حاشیهنویسی میکنند. پس از استخراج اطلاعات مکانی-زمانی از متون روزنامه اکسپدیشن، اطلاعات را در پایگاه داده PostgreSQL که برای این کار توسعه داده بودیم، ذخیره کردیم.
4.1. استخراج داده های خام (توضیحات مکان)
برخی از ورودیهای مجموعه داده ما حاوی توضیحاتی از بازدیدهای یک اکسپدیشنر منفرد هستند ( شکل 5 را ببینید ) در حالی که برخی دیگر حاوی توضیحات بازدیدهای چندین اعزامی هستند ( شکل 6 را ببینید ).
ما ابزاری را برای استخراج دادههای خام – توصیف مکان – از روزنامه توسعه دادیم. این یک فرآیند مقدماتی برای چارچوب اصلی استخراج اطلاعات مکانی و زمانی است. این ابزار توضیحات مکان اکتشافاتی را استخراج می کند که فرض می شود با یک اکسپدیشنر مرتبط هستند – در صورتی که نام اکسپدیشن ارائه شود – و توضیحات مکان استخراج شده را به عنوان یک سند XML (زبان نشانه گذاری توسعه پذیر) ذخیره می کند که در آن یک عنصر XML حاوی یک جمله ای که دارای عبارات زمانی، مکانی و اسنادی مکان های خاص بازدید شده است.
این ابزار با استفاده از یک نقطه ویرگول به عنوان علامت جداکننده بین دو زیر پاراگراف، توصیف مکان را که به شکل یک پاراگراف است به تعدادی زیر پاراگراف تجزیه می کند. روزنامه ما توضیحات مکان را به عنوان یک پاراگراف واحد در نظر می گیرد، که هر کدام معمولاً از یک نقطه ویرگول برای جدا کردن توصیف مکانی از توصیف تاریخی استفاده می کنند. در توصیفات تاریخی، نقطه ویرگول اغلب برای جدا کردن بازدیدهای مکان توسط اعزامی های مختلف استفاده می شود ( شکل 6 را ببینید ). با این حال، موارد متناقضی وجود دارد که به جای آن از کاما استفاده می شود. شکل 7 سند XML را با عبارات مکانی، زمانی و اسنادی استخراج شده از توضیحات مکان شکل 5 و شکل 6 نشان می دهد .
4.2. موجودات فضایی و زمانی
متون روزنامه اکسپدیشن که ما برای آزمایش چارچوب استفاده کردیم، ابعاد توصیفی متعددی دارند. ما بر استخراج موجودیت های مکانی و زمانی تمرکز کردیم. ترکیبی از ابعاد مکانی (موقعیت بازدید)، زمانی (بازه زمانی بازدید) و اسنادی (نام اعزام کننده) سه قلوهای مسیر اکسپدیشن را به ما می دهد.
4.2.1. سه قلوها با تایم فریم واضح
بعد زمانی یک سه قلو که از توضیحات مکان با تاریخ ، ماه و سال صریح استخراج میشود ، همیشه واضح است. شرح بازدید از مکان که یک تاریخ را ذکر می کند به عنوان یک رویداد یک روزه در نظر گرفته می شود. بنابراین، هر دو تاریخ شروع و پایان یکسان هستند. از سوی دیگر، بازدیدهای مکان با طیف وسیعی از تاریخها، مانند « 12 تا 28 مارس، 14 جولای تا دسامبر 1817» ، به عنوان رویدادهای تاریخ چندگانه در نظر گرفته میشوند. اولی یک بازه زمانی واضح دارد، اما دومی ندارد. ما از crisp-triplet برای نمایش سه قلوها با تایم فریم واضح استفاده می کنیم.
4.2.2. سه قلوها با بازه زمانی مبهم
برخلاف سه قلوهایی که از موجودیتهای زمانی واضح با تاریخ ، ماه و سال صریح نام میبرند ، آنهایی که بازه زمانی مبهم دارند، فقط ماه و سال بازدیدهای مکان را دارند که به صراحت ذکر شده است. به عنوان مثال، شرح بازدید از مکان را در نظر بگیرید که بازه زمانی آن ” ژانویه 1922″ است.مأمور اعزامی که از این مکان دیدن کرد، میتوانست بازدید را در هر زمانی بین 1 تا 31 ژانویه 1922 آغاز کرده و به پایان برساند، یا میتوانست تمام ماه را در سایت بماند. تا زمانی که اطلاعات اضافی در مورد این بازدید خاص یا سایر بازدیدهای سایت توسط همان اعزامی در همان بازه زمانی (همان ماه و سال) به ما ارائه نشود، هیچ راهی برای گفتن بازه های زمانی نسبی برای رویداد وجود ندارد. با این حال، به شرطی که سایر بازدیدهای سایت (که دارای بازههای زمانی واضح هستند) توسط همان اعزامی بین 1 و 31 ژانویه 1922 را بدانیم، میتوانیم از آنها برای استنباط نسبی دقیقتر تاریخ شروع و پایان استفاده کنیم، بهتر از فرض پیشفرض ما از 1 و 31 ژانویه. . برای مثال، اگر همان اعزامی از 15 تا 25 ژانویه از مکان Y دیگری بازدید کرده باشد، بازه زمانی منطقی برای بازدید در مکان X باید از 1 تا 15 یا از 25 تا 31 ژانویه باشد.“مبهم-سه گانه” نشان دهنده سه قلوها با بازه های زمانی مبهم است.
4.3. پیش پردازشگر متن
این حاشیه نویس اولیه، حاشیه نویسی های موقتی از کلاس های خاص، یعنی POS، تولید می کند و قبل از مبدل JAPE قرار می گیرد. حاشیه نویسی ایجاد شده توسط پیش پردازنده متن به عنوان مرجع ورودی توسط مبدل JAPE استفاده می شود. پیش پردازشگر متن حاوی توکنایزر ANNIE، تقسیم کننده ANNIE و برچسب ANNIE POS است. تمام این تقسیم بندی پاراگراف ها به جملات، جملات به نشانه ها و نشانه ها به دسته های POS در اینجا انجام می شود. ما از این ماژول برای شناسایی نشانه های کلمه و عدد از روزنامه اکسپدیشن استفاده می کنیم. به عنوان مثال، همانطور که شکل 1 نشان می دهد، یک متن روزنامه اعزامی معمولی دارای عناصر فضایی است که با ترکیبی از نشانه های اعداد و کلمه ( “سانتا کاتارینا، 2525/4915 (USBGN)” ) و عناصر زمانی توصیف شده به طور مشابه توصیف شده است (مانند“24 نوامبر 1914” ). با استفاده از پیش پردازشگر متن، متن gazetteer را به اعداد و کلمات توکن می کنیم و در نهایت این نشانه ها توسط مبدل JAPE برای استخراج اطلاعات مکانی-زمانی از متون اکسپدیشن مشابه استفاده می شود.
4.4. ماشین پردازش Gazetteer (تطبیق فهرست)
نهادهای نامگذاری شده مانند نام افراد، نام مکان و نام سازمان در متون روزنامه اعزامی رایج هستند و به راحتی اشتباه گرفته می شوند. تعریف الگویی برای استخراج این موجودات از متن با مبدل JAPE می تواند مبهم باشد، زیرا ممکن است برخی موارد دارای الگوهای یکسان باشند. به عنوان مثال، هر دو نام مکان و نام افراد با حروف بزرگ نوشته می شوند. مبدل JAPE نمی تواند آنقدر واضح باشد که بگوید کدام چیست. بهترین راه برای جلوگیری از ابهام، استفاده از ماشین پردازش gazetteer (تکنیک تطبیق لیست) برای شناسایی موجودیت های نامگذاری شده، مانند نام مکان و افراد است ( جدول 1 را ببینید ).
فرآیند تطبیق فهرست به مجموعه داده های مرجع ورودی نیاز دارد – مجموعه داده های نام مکان، زمانی (فهرست ماه)، سازمان و نام افراد. ما مجموعه داده نام مکان را با استفاده از GeoNames ( http://www.geonames.org ) آماده کردیم) متشکل از نام مکان های برزیلی. از آنجایی که مجموعه داده آزمایشی نام مکانها را به شکل پرتغالی ذکر میکرد، ما نام مکانهای مرجع را از GeoNames که به زبان پرتغالی نوشته شده بود کپی کردیم تا مشکلات هنگام تطبیق موجودیتها از طریق دستگاه پردازش gazetteer حل شود. مجموعه داده مرجع زمانی شامل فهرستی از ماه ها است. مجموعه دادههای نام سازمان و افراد شامل فهرستی از سازمانها و نامهای افراد است که به ترتیب از روزنامه اکسپدیشن استخراج شدهاند (این مجموعه دادهها به صورت دستی از جستجوهای الگوی هوشمند تهیه شدهاند). فرآیند تطبیق فهرست، هر نشانه ای از متن روزنامه اعزامی را بررسی می کند که آیا در مجموعه داده های مرجع مطابقت دارد یا خیر. اگر چنین باشد، آن نشانه با کلاس حاشیه نویسی منطبق حاشیه نویسی می شود.
فرآیند تطبیق فهرست در چارچوب ما کاملاً به مجموعه داده مرجع وابسته است. اگر قرار است از چارچوب برای کاربردهای استخراج اطلاعات عمومیتر استفاده شود، باید مجموعه دادههای بزرگتر – روزنامههای تازه ایجاد شده – برای بهروزرسانی مستمر مجموعه دادههای مرجع گنجانده شوند. ما این را به عنوان محدودیتی در چارچوب زمانی که برای برنامه های دیگر استفاده می شود، تصدیق می کنیم.
4.5. مبدل JAPE (تطبیق الگو)
با فرض اینکه موجودیتهای مکانی-زمانی در متون روزنامه اعزامی ذکر شدهاند، الگوهای چنین موجودیتهایی با قانون دستور زبان JAPE تعریف میشوند. هنگامی که الگوهای آیتم های مکانی-زمانی تعریف شدند، مبدل JAPE الگوهای از پیش تعریف شده موجودیت ها را با محتوای متنی روزنامه اعزامی مطابقت می دهد. الگوهای تعریف شده نمایش صریح موجودیت های ممکن در یک متن هستند، به عنوان مثال تاریخ، مختصات، یا اختصارات. اگر الگوها به خوبی تعریف شده باشند، چنین موجودیت هایی را می توان با کلاس های مربوطه خود حاشیه نویسی کرد. کامل بودن قوانین JAPE – تعریف قوانین برای هر الگوی موارد مکانی – زمانی در روزنامه اعزامی – بر عملکرد چارچوب در استخراج موجودیتهای مکانی و زمانی تأثیر میگذارد. برای تکمیل قوانین JAPE ما،جدول 2 ). از این رو، چارچوب ما – به طور خاص مبدل JAPE – شانس بینهایتی برای ناشناس گذاشتن بخشهای مکانی-زمانی متن سفر دارد، زیرا قوانین JAPE برای بیشتر موارد متن مکانی-زمانی تعریف شدهاند. JAPE را می توان در ترکیب با منبع پردازش متن (اجزای ANNIE) برای انجام وظیفه استخراج اطلاعات مکانی-زمانی استفاده کرد.
وظایف اصلی مبدل JAPE، حاشیه نویسی موجودیت های مکانی و زمانی از متن روزنامه است. دارای دو مبدل است، یعنی مبدل موجودیت فضایی و مبدل موجودیت زمانی. مبدل موجودیت فضایی از یک قانون JAPE به وضوح تعریف شده استفاده می کند که قادر به تطبیق الگوهای مختصات (طول/طول جغرافیایی) است. الگوهای معمولی مختصات در روزنامه اعزامی در جدول 2 فهرست شده است . به طور مشابه، مبدل موجودیت زمانی از یک قانون JAPE تک فازی برای حاشیه نویسی نه الگوی مختلف موجودیت های زمانی در روزنامه اعزامی استفاده می کند. این مبدل از ماه استفاده می کندکلاس حاشیه نویسی ایجاد شده توسط ماشین پردازش gazetteer و دسته بندی نشانه های ایجاد شده توسط پیش پردازشگر متن (ANNIE tokenizer) به عنوان ورودی برای تعریف بخش های LHS قانون دستور زبان JAPE. در متون روزنامه، الگوهای ممکن برای هر موجودیت زمانی آنهایی هستند که در جدول 2 فهرست شده اند . شکل 8 نسخه مشروح توضیحات مکان (نشان داده شده در شکل 7 ) را نشان می دهد که از مجموعه داده ما استخراج شده است. شکل، کلاس های حاشیه نویسی ایجاد شده روی متن ورودی را با استفاده از دستگاه پردازش gazetteer و مبدل JAPE نشان می دهد.
همانطور که شکل 1 نشان می دهد، متون روزنامه اعزامی، در بیشتر مواقع، سرشار از محتوای دقیق موجودیت های مکانی، زمانی و اسنادی هستند. به عنوان مثال، نام مکان ها، تاریخ ها، ماه ها و سال ها اغلب به صراحت ذکر می شود، به جز در برخی موارد که موجودیت های مکانی و زمانی مبهم و مبهم هستند. به عنوان مثال، زمانی که موجودیت های موقتی مبهم، مانند ” ژانویه 1921″، مبدل JAPE 1 و 31 ژانویه را به عنوان تاریخ شروع و پایان بازدید اختصاص می دهد، و هنگامی که تمام موجودیت های مکانی-زمانی و سایر موجودیت های اسنادی از متن gazetteer استخراج شدند، ابزار استنتاج زمانی مرزهای زمانی نسبی احتمالی را با در نظر گرفتن استنباط می کند. بازدیدهای دیگری که توسط همان اعزامی در همان ماه و سال انجام شده است. دامنه این مقاله به ابهام فضایی نمی پردازد. با این حال، برخی از ابهامات زمانی با استفاده از ابزاری که ما برای تعدادی از وظایف استنتاج زمانی ایجاد کردهایم برطرف میشود (به بخش 4.7 مراجعه کنید ).
4.6. پایگاه داده های مکانی
یک پایگاه داده در PostgreSQL طراحی و پیاده سازی شد. شکل 9 بخشی از مدل داده آن را نشان می دهد. پایگاه داده طراحی شده عناصر سه قلوهای استخراج شده (مکان، اعزام کننده و تایم فریم) را ذخیره می کند. JDBC (اتصال پایگاه داده جاوا) به عنوان پلی بین چارچوب استخراج اطلاعات مکانی و زمانی و پایگاه داده استفاده شد. اتوماسیون ذخیره سازی سه گانه استخراج شده را امکان پذیر می کند. این امکان وجود دارد که در یک توضیح مکان واحد، بازدیدهای چندین اعزامی ذکر شود. این نیاز به یک مدل داده ای دارد که سه قلوها را در یک رابطه مجزا ثبت می کند و امکان ایجاد یک مسیر در صورت تقاضا را فراهم می کند.
4.7. استنتاج زمانی
در زمینه این مقاله، استنتاج زمانی به عنوان فرآیند درونیابی یک مرز زمانی نسبی تعریف شده است. نتیجه مجموعه ای از سناریوهای زمانی برای سه قلوهای مبهم استخراج شده است. فرآیند استنتاج زمانی، همانطور که در شکل 10 نشان داده شده است، ارتباطات دو طرفه با پایگاه داده فضایی را برای واکشی سه قلوهای مرجع واضح و ذخیره موارد استنباط شده سرگرم می کند. این فرآیند بازههای زمانی جایگزین را درونیابی میکند و احتمال وقوع یک بازدید از مکان معین را در بازههای زمانی استنباطشده تعیین میکند. به عنوان مثال، فرض کنید یک اعزامی از سه سایت (X، Y و Z) در یک ماه بازدید کرده است. فرض کنید او از سایت X و Y با مرزهای زمانی واضح 5-21 ژانویه 1921 و 25-31 ژانویه 1921 بازدید کرده است. علاوه بر این، او از سایت Z با یک مرز زمانی مبهم بازدید کرد (ژانویه 1921). بازدید سوم باید بین 1 و 5 ژانویه 1921 یا 21 و 25 ژانویه 1921 آغاز و پایان یافته باشد. اما در مورد چارچوب ما، تاریخ های شروع و پایان پیش فرض تعیین شده توسط مبدل JAPE برای بازه زمانی ژانویه 1921، 1921 است. /01/01 و 1921/01/31، به ترتیب،شکل 11 )، تاریخ شروع و پایان دو سناریو خواهد بود، A: (1921/01/01–1921/01/05) و B: (1921/01/21–1921/01/25). با این حال، این سه قلوهای استنباط شده را می توان با در نظر گرفتن فاصله آنها تا بازدیدهای واضح اصلاح کرد. استنباط های واقع بینانه تر استنتاج های نزدیک به یکی از سه قلوهای واضح است. علاوه بر این، در مواردی که سهقلوهای استنباطشده به همان اندازه از سهقلوهای ترد فاصله دارند، میتوان یک مقدار احتمالی را به سهقلوهای استنباطشده مرتبط کرد.
با فرض وجود سهقلوهای واضح زمانی نزدیک برای یک سهگانه مبهم، ابزار استنتاج زمانی مرزهای زمانی نسبی را درونیابی میکند. این فرآیند دارای سه مرحله اساسی است ( شکل 11 را ببینید )، و در زیر مورد بحث قرار گرفته است. توجه داشته باشید که آخرین روز از ماه خاص مورد تجزیه و تحلیل باید در هنگام انجام فرآیند استنتاج در نظر گرفته شود. به عنوان مثال، 31 ام به عنوان آخرین روز ماه برای تصویر زیر در نظر گرفته شده است. اگر یک سه گانه واضح مرجع برای یک سه گانه مبهم وجود نداشته باشد، فرآیند استنتاج ممکن است موفقیت آمیز نباشد و مرز زمانی مبهم پیش فرض به عنوان تنها گزینه باقی بماند.
-
داده ها: سه قلوهای مبهم و واضح استخراج شده (از همان اعزامی) که بر اساس آن مرزهای زمانی نسبی برای سه قلوهای مبهم استنباط می شود.
-
فرآیند: فرآیند استنتاج مورد بحث در اینجا فقط برای سهقلوهای مبهم که بازههای زمانی باکلاس حاشیهنویسی MonthYear (نگاه کنید به جدول 2 ) توسط مبدل JAPE ثبت میشوند، قابل استفاده است.
-
نتیجه: نتیجه این الگوریتم مجموعه ای از سه قلوها با مرزهای زمانی استنباط شده است. سه قلوها با مرزهای زمانی استنباط شده در پایگاه داده ذخیره می شوند.
-
مرحله 1: یک سه گانه مبهم تجزیه شده و ذخیره شده را پیدا می کند.
-
مرحله 2: سه قلوهای ترد را پیدا می کند. تاریخهای واضح محدود شدهاند که تقریباً همان اکسپدیشنر، همان ماه و همان سال سهقلو مبهم در مرحله 1 باشد .
-
مرحله 3: مرزهای زمانی نسبی را استنباط می کند و احتمال وقوع آنها را برای آن سه قلوهای مبهم در مرحله 1 نسبت به آن سه قلوهای واضح در مرحله 2 تعیین می کند .
-
خط 8-14 ( شکل 11 را ببینید ): سه گانه مبهم VT و سه گانه واضح CT باشد. اگر ماه و سال VT و CT مشابه باشند، برای هر VT داده شده، حداقل یک یا حداکثر دو مرز زمانی استنباط می شود. اگر CT داده شده در اولین روز ماه شروع شود یا در آخرین روز ماه به پایان برسد، تنها یک مرز زمانی استنباط می شود. اگر CT داده شده بین روزهای اول و آخر ماه شروع و پایان یابد، دو مرز زمانی استنباط می شود. با توجه به VT و CT، موارد زیر صادق است ( شکل 12 را ببینید ).
-
4.8. تولید مسیر اعزامی
پس از استخراج و ذخیره تمامی سه قلوهای یک اکسپدیشنر مشخص، فرآیندی برای تولید مسیری که مسیرهای اکسپدیشن را به تصویر میکشد، دنبال میشود. سه قلوهای استخراج شده از یک اکسپدیشن معین در تعدادی اکسپدیشن گروه بندی می شوند. گروه بندی به تشخیص شکاف های زمانی بین بازدیدهای مکان بستگی دارد. چارچوب ما سه روش برای مدیریت تولید مسیر سفر دارد. روش اول بر اساس یک شکاف زمانی از پیش تعریف شده، سه گانه مرزی را بین دو اکتشاف یک اکسپدیشن معین پیدا می کند. با توجه به چنین مرزهایی، روش دوم و سوم مسیر سفر را ایجاد می کند. در اینجا، اختصاص شکاف زمانی منوط به استفاده خاصی از چارچوب است. به عنوان مثال، فاصله زمانی می تواند 60 روز باشد،
5. نتایج و بحث
ما بحث کردیم که مجموعه دادههای تجربی ما، روزنامه پرندهشناسی برزیل، شامل مکانهای نامگذاری شدهای است که در سفرهای تاریخی بسیاری از اکسپدیشنها حضور داشتند. تادئوش کرستوفسکی (1878-1923)، امیل هاینریش اسنتلیج (1897-1939) و ماریا امیلی اسنتلاج (1868-1929) از جمله این افراد بودند. ما از چارچوب خود برای استخراج اطلاعات مکانی-زمانی از متون روزنامه اکسپدیشن برای این اعزامی ها استفاده کردیم.
5.1. اعزامی: تادئوش کرستوفسکی
Tadeusz Chrostowski (1878-1923) یکی از اعزامیانی است که در روزنامه پرندهشناسی برزیل ذکر شده است. طبق ویکیپدیا، او سه اکسپدیشن در برزیل طی دوره 1910-1923 انجام داد. اولین سفر او در سال 1910 در کنار رودخانه ایگواسو انجام شد و پس از آن در سال 1911 به لهستان بازگشت. سفر دوم او از سال 1913 تا 1915 انجام شد و سپس در سال 1915 به دلیل اخبار وقوع جنگ جهانی اول به لهستان بازگشت . پس از استخراج اطلاعات مکانی و زمانی از 58 ورودی که نام وی ذکر شده است، توانستیم شش مسیر اعزامی با فاصله زمانی تولید کنیم.دو ماه بین دو سفر متوالی ( جدول 3 را ببینید ). همانطور که جدول نشان می دهد، اکسپدیشن های II، III و IV و اکسپدیشن های V و VI از نظر زمان به یکدیگر نزدیک هستند. بر اساس این نزدیکی، ما مجموعه های زیر را پیشنهاد می کنیم که فقط در سه مسیر اکسپدیشن حضور داشته باشند.
مورد 1: با نگاهی به اکسپدیشن های جدول 3 ، می توان مشاهده کرد که اکسپدیشن I با سایر اکسپدیشن های اندازه گیری شده در زمان فاصله زیادی دارد. فاصله بین تاریخ پایان اولین سفر و تاریخ شروع سفر دوم بیش از دو سال است: از 26 اوت 1911 تا 22 ژانویه 1914. بعید است که یک اکسپدیشن تا این حد طولانی ادامه داشته باشد. این به ما دلیلی می دهد تا Expedition I را همانطور که مشتق شده است نگه داریم.
مورد 2:فاصله زمانی بین اکسپدیشن II و III حدود دو ماه (13 ژوئیه 1914 تا 25 سپتامبر 1914) و فاصله زمانی بین اکسپدیشن های III و IV نیز حدود دو ماه است (2 دسامبر 1914 تا 10 فوریه 1915). علاوه بر این، تعداد بازدید از مکان در اکسپدیشن III و IV کمتر از اکسپدیشن II است. انتظار می رود که یک اکسپدیشن معمولی شامل تعداد قابل توجهی بازدید از مکان باشد. از این رو، ممکن است کمتر متقاعد کننده باشد که Expedition IV، که تنها یک بازدید از مکان دارد، در واقع یک اکسپدیشن است. می توان استدلال کرد که تیم های اعزامی در آن روزها قبل از ادامه کار میدانی به زمان نیاز داشتند تا دوباره انبار کنند. در نتیجه روزهای ذخیره سازی، یک مسیر اکسپدیشن ممکن است به عنوان دو در چارچوب ما تولید شود. این به ما دلیل مشخصی برای جمع آوری اکسپدیشن های II، III و IV می دهد. با توجه به تعداد بازدیدهای مکان و فاصله زمانی بین این اکسپدیشن ها، اگر فاصله زمانی دو یا سه ماه تنظیم شود، می توان آنها را به راحتی به عنوان یکی تولید کرد. نزدیکی زمان در بین این سه اکسپدیشن ما را به یک تجمیع مسیر اکسپدیشن هدایت می کند. بنابراین، مسیر مجموع اکسپدیشن، اکسپدیشن های II، III و IV را ادغام می کند و دوره 22 ژانویه 1914 تا 10 فوریه 1915 را پوشش می دهد.
مورد 3: اکسپدیشن های V و VI از نظر زمانی چهار ماه از یکدیگر فاصله دارند. فاصله زمانی از 31 اوت 1921 تا 1 ژانویه 1922 است. اکسپدیشن V فقط یک سه قلو دارد در حالی که اکسپدیشن VI 38 دارد. ممکن است امکان حفظ اکسپدیشن V در حالی که تعداد سه قلوها یک است، امکان پذیر نباشد. در عوض سه قلوهای هر دو مسیر را می توان برای تولید یکی جمع کرد. این اکتشاف به ما سفری را ارائه می دهد که بازه زمانی 1 اوت 1921 تا 5 مه 1923 را پوشش می دهد. با این حال، اکتشافات با تنها یک سه قلو ممکن است به دلیل برچسب گذاری اشتباه زمانی ظاهر شوند. در چنین حالتی، بررسی سازگاری بیشتر مورد نیاز است.
سفر سوم کرستوفسکی: 1921-1923
Straube و Urben-Filho ذکر می کنند که سومین اکسپدیشن کرستوفسکی از 1921-1923 انجام شد [ 26 ]. ما از متون روزنامه اکسپدیشن که نام او را ذکر کرده بودند برای آزمایش چارچوب استخراج اطلاعات مکانی و زمانی خود استفاده کردیم. بر این اساس، ما موفق شدیم عناصر مکانی و زمانی را از متن داده شده استخراج کنیم و با استفاده از اطلاعات مکانی-زمانی استخراج شده، ویژگی های مکانی را ایجاد کنیم که با نوع داده نقطه ای نمایش داده می شود و سپس با اتصال نقاط استخراج شده به صورت زمانی، مسیر مسیر سفر را ترسیم کردیم. بر اساس اطلاعات استخراج شده، این اکسپدیشن شامل 39 نفر است ( جدول 4 را ببینید) بازدیدهای سایت، که از این تعداد فقط 35 بازدید به عنوان بازدید از سایت مشخص شده است، به این معنی که چهار بازدید باقی مانده از مکان های یکسان در زمان های مختلف انجام شده است (به سوابق رنگی بنفش، آبی و سبز در جدول 4 مراجعه کنید)، یا این بازدیدها ممکن است بوده باشند . به اشتباه برچسب زده شده است.
برای ارزیابی قابلیت اطمینان اطلاعات مکانی-زمانی استخراجشده، ما یک الگوریتم ساده ایجاد کردیم که فاصله بین دو بازدید متوالی از سایت را محاسبه میکند و نتیجه را با فاصله متوسط و شکاف زمانی که از پیش تعریف کردهایم مقایسه میکند . در اینجا شایان ذکر است که تعیین میانگین فاصله و فاصله زمانی با این فرض که ما در دهه 1920 میتوانستیم 30 کیلومتر را در روز طی کنیم، صورت گرفت. سپس ما ارزیابی را انجام دادیم و میانگین مسافت سفر را 30 کیلومتر در روز تعیین کردیم، به این معنی که اگر فاصله بین دو بازدید از سایت بیش از 30 کیلومتر باشد و فاصله زمانی باشد .کمتر از یک روز است، سپس مسیر غیر قابل اعتماد در نظر گرفته می شود. پس از اجرای الگوریتم در 35 بازدید مجزا از سایت، مسیرهای عبور از رکوردهای 33 (به رنگ آبی روشن)، 17 (نارنجی رنگ) و 38 (آبی روشن) از جدول 4 غیرقابل اعتماد بودند . در این مرحله، یک مداخله دستی برای بررسی عدم اطمینان ضروری بود. از این پس، برای سادگی، اجازه دهید رکوردهای 33 (آبی روشن) نقطه A، 17 (به رنگ نارنجی) نقطه B و 38 (آبی روشن) نقطه C باشد.
فاصله اندازه گیری شده هنگام پرواز کلاغ از نقطه A به B حدود 535 کیلومتر است در حالی که فاصله از نقطه B تا C 531 کیلومتر دیگر است. اعزامی از این نقاط به شرح زیر بازدید کرد: نقطه A (1923/01/23–1923/02/26)، نقطه B (1923/01/25) و نقطه C (1923/02/27–1923/03/16) ( شکل 13 را ببینید). با فرض مسافتی که می توان طی کرد 30 کیلومتر در روز باشد، اکسپدیشنر باید 18 روز از نقطه A به B و 18 روز دیگر از نقطه B تا C را طی کرده باشد. اما داستانی که در اطلاعات استخراج شده می بینیم این است که اکسپدیشنر از طریق این نقاط در یک روز سفر کرد، که بسیار بعید است در سال 1923 اتفاق افتاده باشد، با این فرض که اکسپدیشن های آن روزها با اسب سفر می کردند. چنین تناقضی ممکن است مربوط به برچسب زدن اشتباه یا استخراج اطلاعات اشتباه باشد. با در نظر گرفتن این موارد، موارد زیر سناریوهای احتمالی هستند.
سناریوی اول: اطلاعات استخراج شده ممکن است در واقع مربوط به اکسپدیشن مناسب باشد، اما شرح می تواند مربوط به اکسپدیشن دیگری باشد، به عنوان مثال به جای 1923/01/25، تاریخ بازدید ممکن است 1921/01/25 باشد.
سناریوی دوم: اطلاعات استخراج شده ممکن است مربوط به زمان و اکسپدیشن مناسب باشد، اما مشکل می تواند مکان استخراج شده باشد. در این صورت، اگر نقطه B نزدیک نقاط A و C بود، میتوانستیم باور کنیم که مسیر عبور از این نقاط قابل اطمینان است.
اگر غیرقابل اعتماد بودن مسیر مورد ارزیابی دلیل سناریوی یک را داشته باشد، به نظر می رسد راه حل مناسب بررسی می کند که آیا مسیر اکسپدیشن دیگر یک تقاطع اسنادی، زمانی و مکانی در نقطه بیرونی (نقطه B) اکسپدیشن ارزیابی شده دارد یا خیر. شکل 13سه مسیر اکسپدیشن کرستوفسکی را نشان می دهد. همین شکل تقاطع فضایی بین Expedition III (خط قرمز) و Expedition II (خط آبی) را نشان می دهد. با نگاهی به نقاط تقاطع، می توان نتیجه گرفت که این دو نقطه را می توان از یک توصیف مکان یکسان استخراج کرد و آنها یک مکان مشابه دارند. از این رو، دلیل اینکه نقطه B از مسیر اکسپدیشن ارزیابیشده، پرت است، باید یا به دلیل استخراج سهقلوها از توصیف مکان اشتباه باشد یا به دلیل اشتباه نوشته شدن توصیف باشد. برای تایید این ادعا، باید به توضیحاتی که سه قلوها از آن استخراج شده اند نگاه کنیم. پاراگراف زیر همان توضیحات بازدید است که اطلاعات از آن استخراج شده است. با توجه به این توصیف، نقطه پرت به درستی استخراج می شود. 25 ژانویه 1923” البته وجود دارد. در همین توصیف عبارتی وجود دارد که می گوید: « هرچند کرستوفسکی به آن اشاره نکرده است ». در اینجا باید به اعتبار « 25 ژانویه 1923 » مشکوک باشیم. بنابراین، نویسنده این توصیف ممکن است یک گزارش نادرست نسبت داده باشد. با فرض اینکه نقطه B کاملاً پرت بود و ممکن است به اکسپدیشن دیگری تعلق داشته باشد (در این مورد اکسپدیشن دوم کروستوفسکی)، آن را از مسیر اکسپدیشن ارزیابی شده حذف کردیم، و مسیر اکسپدیشن را با اتصال نقاط A و C تغییر دادیم. شکل 14 این اکسپدیشن اصلاح شده را نشان می دهد . مسیر
« حدود 900 متر، در سمت جنوبی ریو ایگواسو [ریو ایگواسو، 2536/5436 (USBGN)]، حدود. 12 کیلومتری جنوب شرقی کوریتیبا [2525/4915 (USBGN)]، کریستوفسکی، 22، 31 ژانویه، 11، 14، 19–20، 22 فوریه، 15 مارس 1914، 10 فوریه 1915[?]، 25 ژانویه 1919، 25 ژانویه 1919، Chro :31–34، به عنوان «افونسو پنا»؛ 1922، آن. زوول. موس. پولونیچی تاریخ، نات.، 1:400، به عنوان «افونسو پنا»؛ شتولکمن، 1926: 119). توضیحات این را در نزدیکی سائو خوزه دوس پینهیس [2531/4913 (USBGN)] قرار میدهد، اگرچه کرستوفسکی به آن اشاره نکرده است. ”
شکل 14دو مسیر اکسپدیشن را نشان می دهد. خط قرمز مسیر متصل شده توسط خطوط مستقیم را نشان می دهد که از هر نقطه می گذرند، و خط آبی همان مسیر متصل شده توسط شبکه جاده را نشان می دهد (برای راحتی، ما از ابزار راه یاب امروزی Google Earth استفاده کردیم) که از هر نقطه عبور می کند. نقطه. مسیر اعزامی که توسط خط آبی به تصویر کشیده شده است، به عنوان بازنمایی معقول از سومین اکسپدیشن انجام شده توسط کرستوفسکی در دوره 1921-1923 در نظر گرفته می شود. ما این نقشه مسیر را به صورت بصری مقایسه کردیم – مداخله دستی در این مرحله ضروری بود – با یک نقشه مرجع از همان اکسپدیشن که به صورت دستی توسط یکی از دوستان کروستوفسکی، Jaczewski، در سال 1925 تهیه شده بود. هدف از این مقایسه بصری تایید این است که آیا چارچوب قابل اعتماد است و اطلاعات مکانی – زمانی به درستی استخراج شده است.شکل 15 مسیر مرجع را نشان می دهد. ما مسیر مرجع اصلی را آبی رنگ کردیم تا دید آن را افزایش دهیم و بازرسی بصری را آسان کنیم، و شکل 14 مسیر اکسپدیشن را که از متن روزنامه اکسپدیشن استخراج کردیم نشان می دهد. شکل ها نشان می دهد که مسیرهای اعزامی در هر دو مورد از نظر هندسی و مکانی مشابه هستند. شباهت این مسیرها دلیل قانعکنندهای به ما داد تا باور کنیم چارچوب ما قابل اعتماد است و میتوان از آن برای استخراج اطلاعات مکانی-زمانی از متون مشابه اکسپدیشن استفاده کرد. توجه: در حین بررسی بیوگرافی اکسپدیشن (کرستوفسکی) به یک واقعیت شگفت انگیز پی بردیم. با توجه به [ 27]، کرستوفسکی در 4 آوریل 1923 درگذشت. با این حال، اطلاعات مکانی-زمانی که ما از متن روزنامه اعزامی او استخراج کردیم نشان می دهد که آخرین بازدید او از 5 مه 1923 تا 4 ژوئیه 1923 انجام شده است (به جدول 4 ، رکورد 4 مراجعه کنید)، که با این واقعیت که در تضاد است . او قبل از این ملاقات درگذشت. تنها توضیح ممکن برای این تناقض، گزارش نادرست بازدید از سایت است، که ممکن است در زمان نگارش روزنامه رخ داده باشد.
5.2. اعزامی: امیل هاینریش اسنتلیج و ماریا امیلی اسنتلیج
ماریا امیلی اسنتلیج (۱۸۶۸–۱۹۲۹) پرندهشناس بود که از سال ۱۹۰۵ تا زمان مرگش سفرهای بسیاری را انجام داد. امیل هاینریش اسنتلیج (۱۸۹۷–۱۹۳۹) جانورشناس و قوم شناس بود. او برادرزاده ماریا بود که تحت تأثیر کار عمه اش قرار گرفت و او را تشویق کرد تا با او سفر کند. طبق [ 28 ]، امیل اولین سفر خود را در سالهای 1923-1926 در همراهی با عمه خود انجام داد. او سفر خود را در ایالت مارانهائو در شمال شرقی برزیل آغاز کرد. با این حال، دو اسنتلاژ کل دوره را با هم سفر نکردند. از مارس 1924 تا 1926 امیل به تنهایی سفر کرد [ 28]. این فرض جالبی را به ارمغان می آورد که امیل و ماریا باید مسیرهای اعزامی داشته باشند که در سال های 1923/1924 در جایی قطع شده است. از آنجایی که امیل پس از مارس 1924 تا 1926 به تنهایی سفر کرد، مکان احتمالی ملاقات با عمه اش باید یکی از مکان هایی باشد که او در سال های 1923/1924 بازدید کرده است. بر اساس اطلاعات استخراج شده از توضیحات مکان مربوطه خود، ماریا از ایالت های ریودوژانیرو، باهیا، میناس گرایس و اسپیریتو سانتو در سال های 1923-1926 بازدید کرد در حالی که امیل به مکان هایی در ایالت های Maranhão، Ceara و Piaui سفر کرد.
یکی از توصیفهای بازدید از مکان (نگاه کنید به شکل 16 ) اشاره کرد که ماریا و امیل در سالهای 1923/1924 از مکانی در اطراف ” ساحل شمال غربی مارانیو ” بازدید کردند. همین توصیف سرنخی در مورد مکان احتمالی که ممکن است نقطه تقاطع بین مسیرهای اعزامی این اکسپدیشنرها باشد به دست می دهد. یکی دیگر از توضیحات مکان (نگاه کنید به شکل 17 ) اشاره کرد که امیل در سال های 1923/1924 از ” شمال غربی Maranhão ” بازدید کرد. تقاطع اسنادی بین این دو توصیف به ما یک مدرک اولیه می دهد که ” شمال غربی Maranhão” مکانی است که این افراد اعزامی می توانستند با هم سفر کنند. با این فرض، مسیرهای اعزامی این اکسپدیشنرها را تولید کردیم.
مسیرهای اعزامی تولید شده به صورت بصری تجزیه و تحلیل می شوند تا از فرض ما در مورد تلاقی اسنادی، زمانی و مکانی اکسپدیشن ها حمایت کنند. شکل 18 مسیرهای اعزامی امیل و ماریا و همچنین نقطه تقاطع احتمالی این مسیرهای اعزامی را نشان می دهد. مسیر اعزامی ماریا از جنوب شرقی برزیل ( ریودوژانیرو) به شمال شرقی برزیل (مارانیو) کشیده شده و با مسیر اعزامی امیل تلاقی می کند و به جنوب شرقی برزیل (اسپیریتو سانتو) بازمی گردد . در اینجا، میتوانیم به دو سناریو در مورد تلاقی دو مسیر اکسپدیشن در محل شروع بازدید از اکسپدیشن امیل فکر کنیم:
سناریوی اول: این دو اعزامی از نقطه تقاطع در زمانهای مختلف بازدید کردند، و شکل 18 فقط یک تقاطع در فضا را بدون اثبات زمانی نشان میدهد که اعزامکنندگان در آن نقطه تقاطع ملاقات کردهاند.
سناریوی دوم: ماموران اعزامی در واقع در نقطه تقاطع یکدیگر را ملاقات کردند. بنابراین، برای ارزیابی اعتبار این دو سناریو، باید بررسی کنیم که آیا بازدیدهای آنها در محل متقاطع یک بازه زمانی مشابه دارند یا خیر. با توجه به این واقعیت که این اعزامی ها در سال 1923/1924 ملاقات کردند و امیل پس از مارس 1924 به تنهایی سفر کرد [ 28 ]، حداقل به دو سه قلو در نقطه تقاطع، یکی از هر مسیر اعزامی، با علائم زمانی یکسان یا نزدیک نیاز داریم.
تاریخهای بازدید نشاندادهشده در شکل 16 و شکل 17 از نظر زمانی به هم نزدیک هستند، که دلیل محکمی است برای این باور که ماریا و امیل واقعاً در « شمال غربی مارانیو » با هم ملاقات کردهاند. از آنجایی که تقاطع مسیرهای اکسپدیشن در مکان و زمان است، داستان ما درباره ملاقات دو اکسپدیشن در «شمال غربی مارانهائو » در سالهای 1923/1924 درست است و با یک واقعیت تأیید میشود.
6. نتیجه گیری
در این مقاله، ما یک چارچوب نیمه خودکار برای استخراج اطلاعات مکانی-زمانی از یک روزنامه اکتشافی تاریخی ارائه کردیم. این رویکرد بر روی یک مجموعه داده نمونه بهدستآمده از روزنامه Ornithological Gazetteer برزیل اجرا و آزمایش شد. به طور عمده، ما از قوانین JAPE مبتنی بر الگو و فرآیندهای تطبیق فهرست روزنامه برای کارهای حاشیه نویسی و استخراج اطلاعات استفاده کردیم. اگر الگوهای موجودات در یک متن (به عنوان مثال، الگوهای تاریخ و مختصات) یا فهرست موارد مرجع (مانند ماه ها، نام مکان ها و نام افراد) برای مطابقت با موجودیت های موجود در متن به صراحت آماده نشده باشد، فرآیند استخراج اطلاعات ممکن است موفق نباشد با این حال، تعریف الگوها و فهرست کردن آیتمهای مرجع برای همه موجودیتهایی که میتوانیم در متون روزنامه اکسپدیشن پیدا کنیم ایدهآل نیست. چارچوب ما کاملاً به قوانین JAPE مبتنی بر الگو و تطبیق فهرست روزنامه وابسته است. در نتیجه، اگر الگوها تعریف نشده باشند و فهرست موارد برای مرجع از قبل تهیه نشده باشد، ممکن است برخی موارد حاشیه نویسی و استخراج نشوند. ما همچنین یک ابزار استنتاج زمانی را در چارچوب گنجاندهایم تا مرزهای زمانی نسبی را برای سهقلوهای مبهم استخراجشده از متون روزنامه اعزامی پیشنهاد کنیم. با این حال، این ابزار وابسته به در دسترس بودن سه قلوهای واضح است که می توانند به عنوان مرجع برای محاسبه مرزهای زمانی نسبی استفاده شوند. این چارچوب روی سه مجموعه داده از روزنامه Ornithological Brazilian Gazetteer آزمایش شد. نقشه های مسیر سفر با استفاده از اطلاعات مکانی-زمانی استخراج شده از این مجموعه داده ها تولید شد. مداخله دستی در طول فرآیندهای تولید نقشه مسیر و وظایف ارزیابی قابلیت اطمینان ضروری بود. یکی از نقشه های مسیر اعزامی تولید شده به صورت دستی با نقشه ای که قبلا تهیه شده بود مقایسه شد – این نقشه مرجع در سال 1925 توسط Jaczewski ترسیم شد.26 ] – برای ارزیابی قابلیت اطمینان چارچوب. برای بهبود کیفیت استخراج اطلاعات چارچوب ما، پیشنهاد می کنیم یک ماژول حاشیه نویسی مکانی معنایی، یک ماژول استنتاج فضایی، ماژول بررسی سازگاری مکانی-زمانی و هستی شناسی فضایی را در چارچوب بگنجانیم.
هستی شناسی فضایی دانش فضایی را به عنوان سلسله مراتبی از مفاهیم در یک زمینه فضایی تعریف شده نشان می دهد که از واژگان مشترک و نام مکان ها برای نشان دادن انواع، ویژگی ها و روابط متقابل فضایی آن مفاهیم استفاده می کند. رویکرد حاشیه نویسی فضایی معنایی از پایگاه دانش مکانی و پایگاه داده نموداری به جای پایگاه داده یا مجموعه داده ها استفاده می کند، زیرا ورودی اصلی برای حاشیه نویسی معنایی، نمایش تداعی های فضایی بین موارد است و پایگاه های داده قادر به نمایش این دانش نیستند. حاشیه نویسی های مکانی معنایی را می توان با ماژول استنتاج فضایی ادغام کرد تا روابط فضایی مانند ” 40 کیلومتری جنوب Maranhão” را تفسیر کند.“. بخشهایی از متن روزنامه اکسپدیشن (ما موجودیتها را در این مقاله دیدهایم) که مکان را نشان میدهند همیشه قطعی نیستند. مواردی وجود دارد که این موجودات مبهم، معنایی و نسبی هستند، به عنوان مثال عبارت فضایی ” در ساحل شمال غربی مارانیو”.” مبهم است و حاشیه نویسی این مکان مستلزم دانستن متن عبارت است. از این رو، رویکرد حاشیه نویسی فضایی معنایی شامل یادگیری ماشین فضایی، هستی شناسی فضایی، پایگاه داده نمودار فضایی و نمایه سازی فضایی به عنوان ویژگی های اساسی خواهد بود. ما طراحی یادگیری ماشین فضایی، ابزار استنتاج فضایی و پایگاه داده نمودار فضایی و ترکیب آنها با چارچوب مبتنی بر الگو و روزنامه (رویکرد ما) را پیشنهاد میکنیم که کیفیت استخراج اطلاعات و وظایف ابهامزدایی مکانی-زمانی را بهبود میبخشد.
اگر حاشیه نویسی مکانی معنایی، همراه با هستی شناسی فضایی، در چارچوب گنجانده شود، ابهام زدایی مکانی-زمانی، استنتاج زمانی و وظایف استخراج اطلاعات آسان خواهد بود و چارچوب می تواند برای استخراج اطلاعات مکانی-زمانی از هر متون روزنامه اعزامی بدون تغییر زیاد چارچوب استفاده شود. . بنابراین، ما تحقیقات بیشتری را برای تمرکز بر حاشیه نویسی فضایی معنایی و هستی شناسی های فضایی توصیه می کنیم.
منابع
- Bekele، MK ردیابی فضایی سفرهای تاریخی: از متن تا مسیر. پایان نامه کارشناسی ارشد، دانشگاه Twente، Enschede، هلند، 2014. [ Google Scholar ]
- پینتر، RA; Traylor, MA V.1- Ornithological Gazetteer of Brazil ; دانشگاه هاروارد: کمبریج، MA، ایالات متحده آمریکا، 1991. [ Google Scholar ]
- پینتر، RA; Traylor, MA V.2— Ornithological Gazetteer of Brazil ; دانشگاه هاروارد: کمبریج، MA، ایالات متحده آمریکا، 1991. [ Google Scholar ]
- سابوده، وی. کریستوفر، بی جی; هیدئو، جی. Mark, S. نمایه سازی فضایی- متنی برای جستجوی جغرافیایی در وب. در پیشرفت در پایگاه داده های مکانی و زمانی ; Springer: هایدلبرگ، آلمان، 2005. [ Google Scholar ]
- McCurley، KS نقشه برداری جغرافیایی و ناوبری وب. در مجموعه مقالات دهمین کنفرانس بین المللی وب جهانی، هنگ کنگ، چین، 1 تا 5 مه 2001.
- چن، YY; سوئل، تی. Markowetz، A. پردازش پرس و جو کارآمد در موتورهای جستجوی وب جغرافیایی. در مجموعه مقالات کنفرانس بین المللی ACM SIGMOD 2006 در مدیریت داده ها، شیکاگو، IL، ایالات متحده آمریکا، 27-29 ژوئن 2006.
- وو، دی. کنگ، جی. Jensen, CS چارچوبی برای بازیابی کارآمد شیء وب فضایی. بین المللی J. پایگاه داده بسیار بزرگ 2012 ، 21 ، 797-822. [ Google Scholar ] [ CrossRef ]
- فریره، ن. جوس، ی. بوربینها، ز. کالادو، وی. مارتینز، بی. یک سیستم تجزیه و تحلیل جغرافیایی فراداده برای تشخیص و تفکیک نام مکان در سوابق فراداده. در مجموعه مقالات یازدهمین کنفرانس مشترک بینالمللی سالانه ACM/IEEE در کتابخانههای دیجیتال، اتاوا، ON، کانادا، 13 تا 17 ژوئن 2011.
- گلرنتر، جی. بالاجی، س. الگوریتمی برای تجزیه جغرافیایی محلی ریزمتن. Geoinformatica 2013 ، 17 ، 1-33. [ Google Scholar ] [ CrossRef ]
- Guillén, R. Geoparsing پرس و جوهای وب. در پیشرفت در بازیابی اطلاعات چند زبانه و چندوجهی ; Peters, C., Jijkoun, V., Mandl, T., Müller, H., Oard, D., Peñas, A., Petras, V., Santos, D., Eds.; Springer: برلین، آلمان، 2008; جلد 5152، ص 781–785. [ Google Scholar ]
- ویتمر، جی. کالیتا، جی. استخراج موجودات جغرافیایی از ویکی پدیا. در مجموعه مقالات کنفرانس بین المللی IEEE محاسبات معنایی، برکلی، کالیفرنیا، ایالات متحده آمریکا، 14-16 سپتامبر 2009.
- Zubizarreta، Á. فوئنته، پی. کانترا، جی. آریاس، م. کابررو، جی. گارسیا، جی. لاماس، سی. وگاس، جی. استخراج بافت جغرافیایی از وب: ارجاع جغرافیایی در MyMoSe. در پیشرفت در بازیابی اطلاعات ; Boughanem, M., Berrut, C., Mothe, J., Soule-Dupuy, C., Eds.; Springer: برلین، آلمان، 2009; جلد 5478، ص 554–561. [ Google Scholar ]
- بوگورایف، بی. آندو، تجزیه و تحلیل متن سازگار با RK TimeML برای استدلال زمانی. در مجموعه مقالات نوزدهمین کنفرانس بین المللی مشترک هوش مصنوعی، مادرید، اسپانیا، 30 ژوئیه تا 5 اوت 2005. ص 997-1003.
- ژانگ، سی. ژانگ، ایکس. جیانگ، دبلیو. شن، Q. ژانگ، اس. استخراج روابط فضایی مبتنی بر قانون در متن زبان طبیعی. در مجموعه مقالات کنفرانس بین المللی هوش محاسباتی و مهندسی نرم افزار، ووهان، چین، 11-13 دسامبر 2009.
- برکت، ع. Schütze, H. خود حاشیه نویسی برای استخراج رابطه جغرافیایی ریز دانه. در مجموعه مقالات بیست و سومین کنفرانس بین المللی زبانشناسی محاسباتی، پکن، چین، 23 تا 27 اوت 2010.
- استروتگن، جی. گرتز، ام. Popov, P. استخراج و کاوش اطلاعات مکانی-زمانی در اسناد. در مجموعه مقالات ششمین کارگاه در مورد بازیابی اطلاعات جغرافیایی، تورنتو، ON، کانادا، 30 اکتبر 2010.
- بریسابوآ، ن. لواسس، ام. مکان ها، Á. Seco, D. بهره برداری از مراجع جغرافیایی اسناد در یک سیستم بازیابی اطلاعات جغرافیایی با استفاده از یک شاخص مبتنی بر هستی شناسی. Geoinformatica 2010 ، 14 ، 307-331. [ Google Scholar ] [ CrossRef ]
- دریموناس، ای. Pfoser, D. استخراج مسیر جغرافیایی از متون. در مجموعه مقالات اولین کارگاه بین المللی ACM SIGSPATIAL در مورد داده کاوی برای ژئوانفورماتیک، سن خوزه، کالیفرنیا، ایالات متحده آمریکا، 3 تا 5 نوامبر 2010.
- هال، MM; هوشمند، PD; جونز، CB تفسیر زبان فضایی در شرح تصاویر. شناخت. روند. 2011 ، 12 ، 67-94. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- هوراک، جی. بلاج، پ. ایوان، آی. نمک، پ. آردیلی، جی. Růžička، J. Geoparsing اخبار RSS چک و ارزیابی توزیع فضایی آن. در روشهای معنایی برای مدیریت دانش و ارتباطات ; Katarzyniak, R., Chiu, T.-F., Hong, CF, Nguyen, N., Eds.; Springer: برلین، آلمان، 2011; جلد 381، صص 353–367. [ Google Scholar ]
- آباسکال منا، ر. López-Ornelas، E. استخراج و پردازش اطلاعات جغرافیایی از روایات سفر. در مجموعه مقالات چهاردهمین کنفرانس بین المللی انتشارات الکترونیکی، هلسینکی، فنلاند، 16-18 ژوئن 2010.
- گودو، ال. ویلا، L. استدلال زمانی احتمالی مبتنی بر محدودیتهای زمانی فازی. در مجموعه مقالات چهاردهمین کنفرانس مشترک بین المللی در زمینه هوش مصنوعی، مونترال، QC، کانادا، 20-25 اوت 1995.
- فرکسا، سی. استدلال زمانی بر اساس نیمه فواصل. آرتیف. هوشمند 1992 ، 54 ، 199-227. [ Google Scholar ] [ CrossRef ]
- ناگیپال، جی. Motik، B. مدلی فازی برای نمایش دانش زمانی نامشخص، ذهنی و مبهم در هستی شناسی ها. در حرکت به سوی سیستمهای اینترنتی معنادار 2003: Coopis، Doa و Odbase . Springer: برلین، آلمان، 2003; ص 906-923. [ Google Scholar ]
- کانینگهام، اچ. مینارد، دی. بونتچوا، ک. تابلان، وی. اورسو، سی. دیمیتروف، م. داومن، ام. اسوانی، ن. رابرتز، آی. Li, Y. توسعه اجزای پردازش زبان با گیت نسخه 5: (راهنمای کاربر) ; دانشگاه شفیلد: یورکشایر جنوبی، انگلستان، 2009. [ Google Scholar ]
- Dicionário Geográfico das Expedições Zoológicas Polonesas ao Paraná. در دسترس آنلاین: http://www.ao.com.br/download/polonesa.pdf (در 25 مارس 2016 قابل دسترسی است).
- استراوب، اف. Urben-Filho, A. Tadeusz Chrostowski (1878-1923): Biografia e perfil do patrono da ornitologia paranaense. بول. Inst. تاریخچه Geogr. پارانا 2002 ، 52 ، 35-52. [ Google Scholar ]
- زندگی، سفرها، مجموعه ها و یادداشت های میدانی منتشر نشده دکتر امیل هاینریش اسنتلیج. در دسترس آنلاین: http://www.snethlage.info/ (دسترسی در 20 سپتامبر 2015).
- Singh, G. From Location To Map: Understanding VGI from the Past. دکتری پایان نامه، دانشگاه Twente، Enschede، هلند، 2014. [ Google Scholar ]
شکل 1. مدخل روزنامه اکسپدیشن معمولی که یک مکان و تاریخچه بازدیدهای آن را توصیف می کند (منبع: [ 2 ، 3 ]). توجه: این منابع تحت مجوز Creative Commons Attribution-NonCommercial-ShareAlike 3.0 به اشتراک گذاشته شده اند.

شکل 2. Tadeusz Chrostowski: 1878–1923 (منبع: ویکی پدیا).

شکل 3. مثالی از قانون دستور زبان JAPE، هدف این قانون نشان دادن چگونگی تعریف قوانین JAPE است. قوانین صریح JAPE چارچوب نیمه خودکار ما به عنوان یک مجموعه داده جداگانه ارائه شده است.
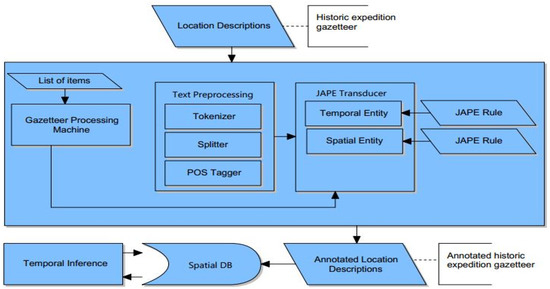
شکل 4. چارچوبی برای استخراج اطلاعات مکانی و زمانی از یک روزنامه اکتشافی تاریخی.

شکل 5. ورود با یک اکسپدیشنر. این ورودی از مجموعه داده های مورد استفاده برای این تحقیق (پایگاه داده paynter) استخراج شده است. شناسه ورودی 251 است (منبع: [ 2 ، 3 ]).

شکل 6. ورود با چندین اعزامی ذکر شده. این ورودی از مجموعه داده های مورد استفاده برای این تحقیق (پایگاه داده paynter) استخراج شده است. شناسه ورودی 3130 است (منبع: [ 2 ، 3 ]).
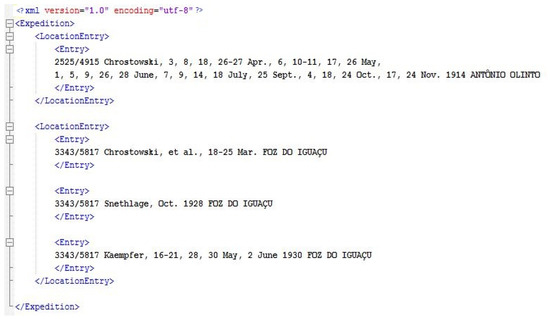
شکل 7. داده های خام استخراج شده.
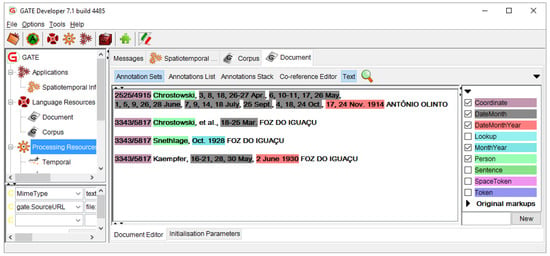
شکل 8. خط لوله حاشیه نویسی موجودیت های مکانی-زمانی.

شکل 9. مدل داده برای اکتشافات استخراج شده.

شکل 10. فرآیند استنتاج زمانی.

شکل 11. الگوریتم استنتاج زمانی.

شکل 12. محدودیت های الگوریتم استنتاج زمانی.
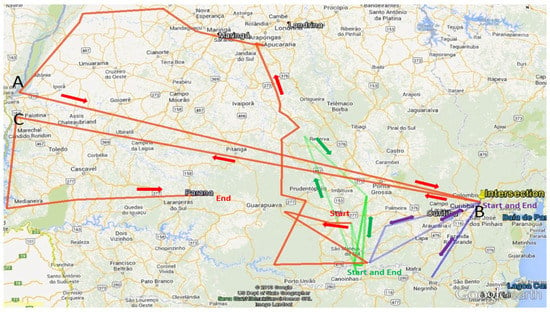
شکل 13. اکسپدیشن های Chrostowski که توسط چارچوب ما تولید شده است: Expedition I (خط سبز)، Expedition II (خط آبی) و Expedition III (خط قرمز). برای ارجاع جزئیات اکتشافات به مجموعه داده خارجی مراجعه کنید (به فایل های KML در پوشه های “تجزیه و تحلیل” و “Chrostowski” فایل تکمیلی مراجعه کنید ).
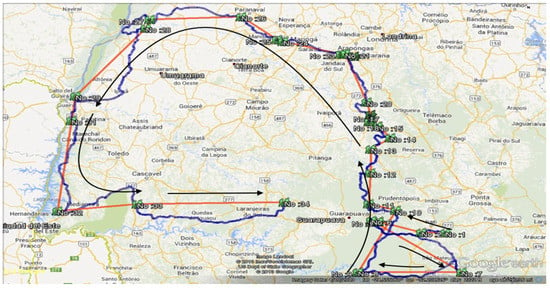
شکل 14. مسیرهای اعزامی استخراج شده از خط مستقیم (خط قرمز) و شبکه جاده (خط آبی). مسیر قرمز با اتصال نقطه از طریق یک خط مستقیم ایجاد می شود و مسیر آبی با اتصال همان نقاط از طریق شبکه جاده ای ایجاد می شود که ما از Google Earth به دست آوردیم. برای ارجاع جزئیات اکتشافات به مجموعه داده خارجی مراجعه کنید (به فایل های KML در پوشه های “تجزیه و تحلیل” و “Chrostowski” فایل تکمیلی مراجعه کنید ).
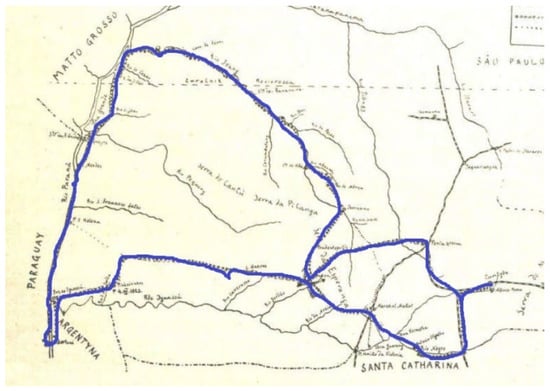
شکل 15. مسیر اعزامی مرجع (Jaczewski، 1925 [ 26 ]). برای ارجاع جزئیات اکسپدیشن به مجموعه داده خارجی مراجعه کنید (به فایلهای KML در پوشههای «تحلیلشده» و «کرستوفسکی» فایل تکمیلی مراجعه کنید ).

شکل 16. شرح بازدید EH Snethlage.

شکل 17. شرح بازدید ME Snethlage.

شکل 18. سفرهای EH Snethlage (خط بنفش). و ME Snethlage (خط قرمز)، 1923-1926. برای ارجاع جزئیات اکتشافات به مجموعه داده خارجی مراجعه کنید (به فایلهای KML در پوشههای «تحلیلشده» و «Snethlage» فایل تکمیلی مراجعه کنید ) .

جدول 1. نهادهای حاشیه نویسی شده توسط دستگاه پردازش روزنامه.
جدول 2. نهادهای حاشیه نویسی شده توسط مبدل JAPE.
جدول 3. اکسپدیشن های کروستوفسکی که توسط چارچوب ما تولید شده است.
جدول 4. اطلاعات مکانی – زمانی استخراج شده (سومین اکسپدیشن کرستوفسکی، 1921-1923).
© 2016 توسط نویسندگان؛ دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (CC-BY) (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر