1. معرفی
فنآوریهای رصد بصری زمین برای جوامع معاصر اهمیت حیاتی دارند، زیرا مقیاس تأثیر ما بر محیط اطراف ما اکنون بیشتر از همیشه است. علاوه بر این، بهبود سریع تفکیکپذیریهای فضایی و طیفی دستگاههای جمعآوری تصویر، تصاویر ماهوارهای و هوایی را به منبعی ارزشمند از اطلاعات با طیف گستردهای از کاربردهای اجتماعی، محیطی و نظامی تبدیل کرده است. در نتیجه، این تکثیر مداوم و پیچیدگی روزافزون تصاویر سنجش از دور نیاز مبرمی به روشهای به همان اندازه مؤثر و کارآمد برای بهرهبرداری از آنها ایجاد کرده است.
به طور خاص، انباشت سریع دادههای هوایی و ماهوارهای به ارزش گیگابایت به صورت روزانه، ابزارهای مقیاسپذیر، قوی و خودکار را که برای مدیریت، جستجو و بازیابی آنها طراحی شدهاند، برای بهرهبرداری مؤثر از آنها ضروری کرده است. این به ما انگیزه می دهد تا روی بازیابی چنین تصاویر هوایی تمرکز کنیم و یک رویکرد جدید برای توصیف و بازیابی مبتنی بر محتوای آنها پیشنهاد کنیم.
بازیابی تصویر مبتنی بر محتوا (CBIR) معمولاً با استفاده از توصیفگرهای محاسباتی [ 1 ، 2 ، 3 ، 4 ]، یا به صورت سراسری برای کل تصویر [ 5 ، 6 ] یا بر روی [ 1 ، 7 ، 8 ] انتخاب شده یا بخش های از پیش تعیین شده از تصویر [ 9 ، 10 ]. در صورتی که توصیفگرها به صورت محلی بر روی وصلهها محاسبه شوند، که توصیفگرهای متعدد در هر تصویر تولید میکنند، ابتدا آنها را جمعآوری میکنند تا یک ورودی توصیفگر منفرد برای هر تصویر تولید شود [ 11 ، 12 ]. در نهایت، توصیفگرهای تصویر بیشتر در طرحهای نمایهسازی اختصاصی استفاده میشوند [9 ، 13 ، 14 ، 15 ] برای دستیابی به هدف نهایی بازیابی موفق.
مورفولوژی ریاضی برای مدت طولانی مورد توجه جامعه تجزیه و تحلیل تصویر سنجش از دور قرار گرفته است، به ویژه از نظر طبقه بندی پیکسل با پروفایل های ریخت شناسی [ 16 ] و اخیراً مشخصات پروفایل ها [ 17 ، 18 ، 19 ، 20 ]، زیرا دارای ابزارهای منحصر به فردی است که قادر به فضایی هستند. -تحلیل محتوای طیفی با این حال، کاربرد آن برای بازیابی مبتنی بر محتوا در این زمینه با استفاده از توصیفگرهای بافت [ 21 ، 22 ] به طرز شگفتآوری محدود شده است، با توجه به اینکه جایگزینهای بسیار قویتری دارد.
یکی از این جایگزینها، طیفهای الگوی شناخته شده [ 23 ] است، ابزاری چند مقیاسی که به صورت جهانی بر روی اجزای تصویر متصل عمل میکند و توزیع هیستوگراممانند یک یا چند ویژگی فضایی و/یا طیفی دلخواه آنها را تولید میکند. اگرچه طیفهای الگو توصیفگر محتوا قدرتمندی هستند، تا همین اواخر تنها میتوان آنها را به صورت جهانی از روی یک تصویر مشخص محاسبه کرد. این از طریق گسترش ما به نظریه اساسی آنها تغییر کرده است که محاسبات آنها را در سطح محلی فعال کرده است [ 24 ]. کارهای اولیه ما با طیف های الگوی محلی بر محاسبه موفقیت آمیز آنها از مناطق برجسته محلی متمرکز شده است [ 25 ، 26 ].
با انگیزه این نتایج، در این مقاله، ما یک استراتژی توصیف محتوای جدید را ارائه میکنیم که برای اولین بار بر محاسبه متراکم طیفهای الگوی محلی از یک شبکه منظم تکیه میکند، و بیشتر آنها را با بردارهای توصیفگرهای محلی (VLAD) ترکیب میکنیم. راهحل توصیف محتوای حاصل در برابر طیفهای الگوی جهانی، و استراتژیهای محلی جایگزین با استفاده از بزرگترین مجموعه داده هوایی CBIR که در دسترس عموم است، یعنی مجموعه داده UC Merced Landuse/Landcover، که در آن به عملکردهای امیدوارکنندهای دست مییابد، آزمایش میشود.
مقاله بصورت زیر مرتب شده است. بخش 2 کار قبلی را در مورد بازیابی تصاویر هوایی و ماهواره ای مبتنی بر محتوا مرور می کند و مشارکت های ما را شرح می دهد. در مرحله بعد، بخش 3 تعریف طیف های الگو را به عنوان توصیفگرهای جهانی و محلی یادآوری می کند و همچنین ویژگی های مختلف درگیر در مطالعه ما را شرح می دهد. ما پروتکل ارزیابی مورد استفاده در آزمایشهای خود را در بخش 4 توصیف میکنیم ، در حالی که نتایج در بخش 5 قبل از نتیجهگیری و ارائه دستورالعملهای تحقیقاتی آینده مورد بحث قرار میگیرند.
2. کار قبلی
بازیابی تصویر مبتنی بر محتوا در 20 سال گذشته مسیر طولانی را طی کرده است. پس از آزمایشهای امکانسنجی موفقیتآمیز اولیه، تلاش زیادی برای پر کردن «شکاف معنایی»، یعنی شکاف بین توصیفگرهای محتوای سطح پایینتر و معنایی یک تصویر، و اجرای روشهای بازیابی بیشتر (به عنوان مثال، عمل) انجام شده است. بازیابی مبتنی بر ویدئو و غیره). برای مطالعه عمیق مسائل مربوط به CBIR و بررسی جامع این زمینه، خواننده به [ 27 ] مراجعه می کند.
ظهور نسبتاً اخیر پایگاههای داده تجاری بسیار بزرگ از تصاویر سنجش از دور، جامعه تحقیقاتی را به انطباق و توسعه بیشتر راهحلهای CBIR موجود برای این زمینه جدید سوق داده است که عمدتاً با دیدگاه بالا، وضوح فضایی بالا و محتوای ناهمگن مشخص میشود. در نتیجه، مجموعه وسیعی از استراتژیهای جدید پدیدار شدهاند که مروری بر آنها در ادامه میآید.
2.1. کار مرتبط
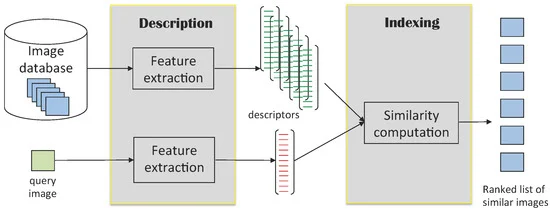
یک سیستم استاندارد CBIR از حداقل دو جزء تشکیل شده است: شرح محتوای آن یا ماژول استخراج ویژگی، که دادههای بصری را به نمایشهای فشرده کاهش میدهد، و معیار تشابه که در ویژگیهای استخراجشده به منظور تعیین تصاویر مشابه استفاده میشود. پرس و جو (ر.ک. شکل 1 ).
تا آنجا که به توضیحات محتوایی تصاویر هوایی و ماهواره ای با هدف نهایی بازیابی مربوط می شود، با طیف گسترده ای از راه حل های استخراج ویژگی مواجه می شوید. تلاشهای اولیه با ویژگیهای آماری پایه کلاسهای تصویر طیفی [ 28 ] آغاز شد و به سرعت به انطباق روشهای قبلاً آزمایششده CBIR رنگی با این زمینه، با استفاده از شکل [ 29 ] و توصیفکنندههای بافت بهویژه شناخته شده مانند فیلترهای گابور [ 30 ] پیش رفت. کوواریانس مورفولوژیکی [ 21 ]، الگوهای باینری محلی [ 31 ] و ماتریس های هم رخدادی در مقیاس خاکستری [ 32 ].
با این حال، رویکردهای جدیدتر، به موازات تحولات در زمینه بینایی رایانه، خود را به سمت استراتژیهای توصیف محلی و واژگان بصری سوق دادهاند. در این راستا، GIST [ 33 ]، SIFT [ 9 ، 34 ] و MSER [ 35 ] به طور کامل مورد مطالعه قرار گرفته اند و SIFT به عنوان بهترین عملکرد در بین آنها نتیجه گیری شده است. علاوه بر این، مجموعه دادههای جدید و چالش برانگیزی نیز با در نظر گرفتن CBIR تصاویر جغرافیایی پیشنهاد شدهاند که مجموعه داده Landcover/Landuse UC Merced بزرگترین تا به امروز در میان آنها بوده و دارای 21 کلاس و 2100 نمونه است. به این ترتیب، به سرعت توسط جامعه علمی بازیابی مبتنی بر محتوا و طبقه بندی صحنه برای سنجش از راه دور پذیرفته شده است [ 9], 21 , 22 , 36 , 37 , 38 , 39 , 40 , 41 , 42 , 43 , 44 ].
اخیراً، کارهای بیشتر منتشر شده در این زمینه بر ترکیب توصیفگرهای جهانی و محلی [ 45 ] متمرکز شدهاند، در حالی که دیگران بر بهرهبرداری از بازخورد کاربر از طریق یادگیری فعال [ 46 ] تمرکز کردهاند. در نهایت، تکنیکهای یادگیری عمیق نیز برای مسئله مورد بررسی، عمدتاً به شکل شبکههای عصبی کانولوشنال [ 44 ] اعمال شدهاند.
2.2. مشارکت های ما
در این مقاله، ما پتانسیل طیفهای الگوی محلی را که با یک استراتژی متراکم محاسبه شدهاند، برای توصیف محتوای تصاویر هوایی بررسی میکنیم که هدف نهایی آن CBIR است. ما آنها را بیشتر با بردار توصیفگرهای محلی (VLAD) ترکیب می کنیم تا یک واژگان بصری را تشکیل دهیم.
با جزئیات بیشتر، طیف های الگو یکی از قدیمی ترین و قوی ترین توصیف کننده های محتوا هستند که توسط مورفولوژی ریاضی ارائه می شوند [ 23 ]. آنها در ابتدا برای توصیف توزیع اندازه اشیاء درون تصاویر از طریق نمایش های هیستوگرام مانند معرفی شدند. با گذشت زمان، آنها تمدید شدند [ 6 ، 47] برای توصیف نه تنها اندازه، بلکه توزیع شکل و بافت و همچنین توزیع هر صفت انتخاب شده دلخواه در بین اجزای تصویر متصل شده. علاوه بر این، اجرای کارآمد آنها از طریق نمایشهای تصویری مبتنی بر درخت، آنها را به ابزارهای توصیف محتوا مؤثر، کارآمد و چند مقیاسی، هدف کلی، جامع (یعنی جهانی) تبدیل کرده است. از این رو، اولین کمک ما به پیشرفته ترین، استفاده از طیف های الگو برای اولین بار در CBIR تصاویر هوایی است.
علاوه بر این، پیشینه نظری مورد نیاز برای محاسبه آنها به صورت محلی به تازگی معرفی شده است [ 24 ]. اولین پیادهسازی گزارششده از طیفهای الگوی محلی در زمینه طبقهبندی تصویر با هدف عمومی بوده است، جایی که آنها از مناطق برجسته که با استفاده از MSER شناسایی شدهاند محاسبه شدهاند [ 25 ، 26 ]. به دنبال عملکردهای امیدوارکننده ای که در آن زمینه به دست آمده است، در این مقاله، برای اولین بار، محاسبه طیف های الگوی محلی را نه از مناطق برجسته، بلکه از کل تصویر ورودی، با استفاده از نه یک رویکرد جهانی، بلکه یک شبکه متراکم بررسی می کنیم. با مراحل ثابت این دومین جنبه جدید رویکرد ما را تشکیل می دهد.
علاوه بر این، به دنبال کار اوزکان و همکاران. [ 9 ]، در جایی که SIFT همراه با VLAD مورد بررسی قرار گرفته است، ما نتایج ترکیب طیف های الگوی محاسبه شده محلی را همراه با واژگان بصری به دست آمده از طریق VLAD بررسی و گزارش می کنیم. در این راستا، کار ما برای دومین بار در پیشرفته ترین زمان است که از هر رویکرد صرفی برای تشکیل یک واژگان بصری استفاده می شود (با اولین مورد [22])، و اولین بار با طیف های الگوی محلی ، که سومین سهم اصلی کار ما در پیشرفت هنر است.
رویکرد پیشنهادی با بزرگترین مجموعه دادههای عمومی موجود در نوع خود آزمایش و تأیید میشود، و نشان داده شده است که از نظر عملکرد بازیابی با توصیفگرهای SIFT پرکاربرد در طول بردار ویژگی بسیار کوتاهتر قابل مقایسه است.
3. طیف الگو
این بخش ابتدا اصول پشت طیف های الگو را یادآور می شود و سپس به جزئیات و تفاوت های بین اجرای جهانی و محلی آنها می پردازد.
طیف الگو ساختارهای هیستوگرام مانندی هستند که از ریخت شناسی ریاضی سرچشمه می گیرند و معمولاً برای تجزیه و تحلیل محتوا [ 23 ] استفاده می شوند و اطلاعات مربوط به توزیع اندازه و شکل اجزای تصویر را به دست می آورند. آنها را می توان به عنوان تخمینی از توابع چگالی احتمال، با هیستوگرام به عنوان پایه و قدیمی ترین شکل آنها مشاهده کرد [ 48 ]. آنها را می توان به طور موثر با استفاده از تکنیکی به نام گرانولومتری (اندازه یا شکل) محاسبه کرد [ 49 ، 50 ] در یک سلسله مراتب درخت حداکثر و منتخب [ 51 ، 52 ].
3.1. Min- و Max-Trees
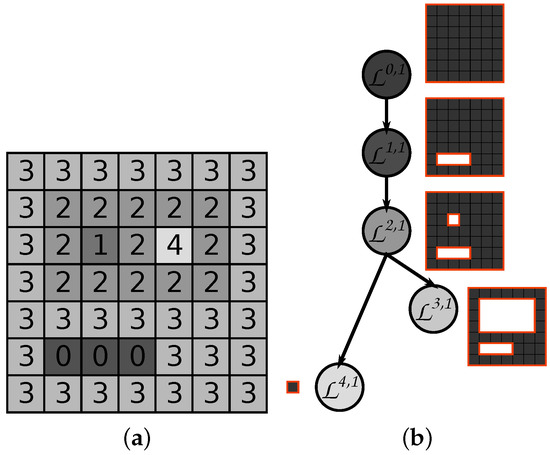
درختان min- و max [ 51 ، 52 ] تجزیه های سلسله مراتبی یک تصویر هستند که با مجموعه های سطح آن کار می کنند. با جزئیات بیشتر، مجموعههای سطح بالایی برای هر سطح خاکستری k از یک تصویر I تعریف شدهاند . سطح بالایی که در سطح k تنظیم شده است شامل تمام پیکسل های p با مقدار سطح خاکستری استf( ص )�(�)بالاتر از آستانه k ، Lک= { p ∈ I| f( p ) ≥ k }��={�∈�|�(�)≥�}. هر مجموعه سطح می تواند شامل چندین مؤلفه متصل باشد که به آنها مؤلفه های پیک نیز گفته می شود. اجزای اوج سطح بالایی مجموعه Lک��با نشان داده می شوند Lk ، i��,�(جایی که i از یک مجموعه شاخص است) و برای مقادیر کاهنده k تودرتو هستند . هنگامی که در یک سلسله مراتب سازماندهی می شوند، این اجزای تو در تو سلسله مراتبی به نام max-tree را تشکیل می دهند ( شکل 2 ). Lk ، i��,�.
سلسله مراتب درخت حداکثر شامل جزئیات تصویر روشن و مناطق (ماکسیما سطح خاکستری محلی) در برگ های آن است. در مقابل، برای عملکرد با مناطق تصویر تاریک، مجموعههای سطح پایینتر با نشان داده میشوند Lک= { p ∈ I| f( p ) ≤ k }��={�∈�|�(�)≤�}استفاده می شوند و در سلسله مراتبی به نام min-tree سازماندهی می شوند. سلسله مراتب min-tree همچنین می تواند به عنوان درخت حداکثر از تصویر معکوس ساخته شود. من�، به دلیل رابطه دوگانگی بین دو سلسله مراتب. از آنجایی که سلسله مراتب خود سطوح خاکستری همه اجزا را ذخیره می کنند، می توان یک تصویر کامل را مستقیماً از درختان min و max آن بازسازی کرد.
3.2. فیلترینگ و گرانولومتری
برای مشخص کردن مناطق این سلسله مراتب، میتوانیم به هر گره ویژگیهای مربوط به ویژگیهای آن گره را اختصاص دهیم. یک صفت ک( ⋅ )�(·)اگر برای دو منطقه تودرتو افزایش می یابد Lk ، i⊆Ll ، j��,�⊆��,�، مقدار آن همیشه برای منطقه بزرگتر بیشتر است: ک(Ll ، j) ≥K(Lk ، i)�(��,�)≥�(��,�). در نتیجه، مقدار ویژگی یک گره، ک(Lk ، i)�(��,�)، کوچکتر از هر یک از ارزش های اجداد خود خواهد بود. این نوع ویژگی ها معمولاً اندازه گره را توصیف می کنند.
اگر این ویژگی برقرار نباشد، ویژگی غیرافزاینده است. از میان تمام ویژگیهای غیرافزاینده، در اینجا ما به ویژگیهای شکل دقیق علاقهمندیم که فقط به شکل ناحیه پاسخ میدهند و بنابراین نسبت به مقیاسبندی، چرخش و ترجمه ثابت هستند [49 ] .
ما به روش استاندارد اندازه گیری تعداد پیکسل های یک منطقه برای توصیف اندازه آن تکیه می کنیم، که بنابراین با ناحیه مربوطه نشان داده می شود. الف (Lk ، i)�(��,�). ما اطلاعات شکل را از طریق دو ویژگی مختلف بررسی می کنیم. اولین ویژگی مورد استفاده، اندازه گیری ازدیاد طول منطقه است که به آن عدم تراکم اصلاح شده (CNC) می گویند:
جایی که من(Lk ، i)�(��,�)لحظه اینرسی منطقه در اینجا است. این ویژگی در واقع مطابق با اولین لحظه تغییر ناپذیر هو [ 53 ] است که برای کاربرد آن در فضای تصویر گسسته، برخلاف فضای پیوسته [ 54 ] تصحیح شده است. این یک ویژگی شکل است که معمولاً در سنجش از دور استفاده می شود [ 20 ]. بنابراین، اولین ترم من(Lk ، i)آ(Lk ، i)2�(��,�)�(��,�)2لحظه اول ثابت هو را محاسبه می کند، در حالی که اصطلاح 16 A (Lk ، i)16�(��,�)مربوط به ضریب تصحیح است. این ویژگی برای یک جسم کاملا دایره ای (فشرده) مقدار 1 را می گیرد، که با نزدیک شدن شکل جسم به خط نازک طولانی، رشد می کند. با این حال، در عمل، مقادیر بالاتر از آستانه حدود 50-60 هنگام کار با این ویژگی [ 6 ، 24 ] کنار گذاشته میشوند، زیرا مناطقی که به چنین مقادیر غیرفشردگی بالایی دست مییابند بسیار نادر هستند. 1 %1%یا کمتر از تمام مناطق در دقیقه و حداکثر درختان مربوط به مجموعه داده استفاده شده در این مقاله). معیارهای دیگری مانند قطر ژئودزیکی [ 55 ] وجود دارد که با ازدیاد طول جسم مطابقت دارد . با این حال، در حالی که چنین ویژگی هایی زمانی مورد نیاز است که فرآیند انتخاب منطقه صرفاً به یک (یا چند) ویژگی مانند استخراج ساختارهای اثر انگشت ارائه شده در [ 56 ] بستگی دارد، رویکرد طیف الگوی ارائه شده بعداً به دلیل تکیه بر معیارهای ویژگی های متعدد از قوی تر است. یک منطقه واحد برای مشخص کردن آن با یک توصیفگر منطقه. علاوه بر این، حتی تقریب کارآمد قطر ژئودزیکی به نام قطر باریسنتریک [ 56] همچنان به اصلاح الگوریتم max-tree نیاز دارد زیرا درخت max فقط برای محاسبه ویژگیهایی مناسب است که میتوانند به طور موثر به روز شوند زیرا درخت از حداکثرهای محلی توسط یک فرآیند تجمیع ساخته میشود. بنابراین، در اجرای کارآمد فیلتر با استفاده از قطر باریسنتریک، ترتیب پیمایش بیشینه درخت برای مطابقت بهتر با ماهیت ویژگی اصلاح میشود و تنها اطلاعات جزئی مربوط به ویژگی در طول پیمایش درخت بهروزرسانی میشود، در حالی که مقادیر ویژگی نهایی هنوز باید با بررسی مجدد پیکسل های هر گره در پیمایش محاسبه شود.
دومین ویژگی غیرافزاینده ای که ما استفاده می کنیم، آنتروپی شانون است که با استفاده از فرکانسی که یک پیکسل از سطح خاکستری i در منطقه رخ می دهد، تعریف می شود.Lk ، i��,�، با احتمال بیان می شود p ( من ،Lk ، i)پ(من،�ک،من):
مقادیر کم ویژگی از اچ( ⋅ )اچ(·)زمانی مشاهده خواهد شد که محتوای ناحیه از نظر توزیع سطح خاکستری همگن باشد، در حالی که مناطق ناهمگن حاوی سطوح خاکستری مختلف مقادیر بالاتری از این ویژگی خواهند داشت. با این حال، دامنه این ویژگی بسیار کوچکتر از محدوده است C N CCNCویژگی، به طوری که مقادیر ویژگی مورد علاقه بین 0 تا 8 باشد [ 6 ]. ویژگی های تخصیص داده شده به گره ها همچنین می تواند بر اساس مفاهیم پیچیده تر، مانند بافت، حرکت، یا حتی شباهت به اشکال از پیش تعریف شده [ 57 ] باشد. بسیاری از نمونه های ویژگی دیگر را می توان در [ 49 ، 51 ، 58 ] یافت .
پس از مرحله ساخت درخت و انتساب ویژگی گره های آنها، تنها در صورتی می توانیم گره ها را برای پردازش بیشتر در نظر بگیریم که مقدار ویژگی آنها باشد. ک(Lk ، i)ک(�ک،من)بالاتر از یک آستانه معین t است . سپس درختان با حذف تمام اجزای متصل زیر این آستانه هرس می شوند. پردازش سلسله مراتب ها به این صورت (که در آن تصمیم برای حفظ یا رد گره های سلسله مراتب بر اساس مقادیر ویژگی آنها است) فیلترینگ نامیده می شود. برای یک ویژگی کلی ک( ⋅ )ک(·)و آستانه t را نشان می دهیم ΨتیΨتیفیلتری که فقط گره ها را با آن نگه می دارد ک(Lk ، i) > tک(�ک،من)>تی، و Ψتی( من)Ψتی(من)تصویر به دست آمده از بازسازی درخت فیلتر شده.
هنگام انجام فیلتر کردن یک ویژگی با یک ویژگی افزایشی مانند اندازه، عملیات حاصل می شود ΓتیΓتیویژگی های باز شدن صفت (یعنی ضد گسترش، افزایش و ناتوانی) را خواهد داشت. گرانولومتری اندازه [ 49 ] مجموعه ای از چنین دهانه هایی است {Γتیمن}{Γتیمن}با افزایش سایز تیمن + 1>تیمنتیمن+1>تیمن، که در هر مرحله اجزای بیشتری را از تصویر حذف می کند و به عنوان مجموعه ای از غربال های درجه های افزایشی دیده می شود. پس از هر باز شدن متوالی، گرانولومتری میزان جزئیات موجود در تصویر را یادداشت می کند. هنگام استفاده از یک ویژگی غیر افزایشی و متغیر مقیاس ΦتیΦتی، فیلتر کردن صفت یا نازک شدن صفت به دست آمده همچنان ضد گسترده و بی قدرت است، اما دیگر افزایش نمی یابد. اگر تصویر Φتی( من)Φتی(من)از درختی که با اعمال قانون تفریق [ 50 ] هرس شده بازسازی می شود، گسترش تکنیک برای شکل دادن به گرانولومتری ها [ 50 ] اجازه می دهد تا میزان جزئیات تصویر را در بین کلاس ها بر اساس شکل یا سایر معیارهای مشخصه مستقل از مقیاس مناطق ذکر کنید. قانون تفریق مورد استفاده برای هرس درخت تنها با حذف اجزایی انجام می شود که ویژگی را برآورده نمی کنند، اما کنتراست محلی اجزای نگه داشته شده را حفظ می کند. وقتی از چنین قاعده ای استفاده می شود، Φتی( من)Φتی(من)فقط شامل اجزای با ک(Lk ، i) > tک(�ک،من)>تیو مهمتر از همه، تصویر تفاوت من–Φتی( من)من–Φتی(من)فقط شامل اجزای با ک(Lk ، i) ≤ tک(�ک،من)≤تی.
3.3. طیف الگوی جهانی
بر خلاف گرانولومتری، طیف الگو بر روی مقدار جزئیات حذف شده بین دهانه های متوالی تمرکز می کند. طیف الگوی اندازه [ 23 ] بر اساس دهانه های ناحیه و گرانولومتری های اندازه است و با یک هیستوگرام در تمام کلاس های اندازه مختلف نشان داده می شود. به طور مشابه، یک طیف الگوی شکل [ 50] بر اساس گرانولومتری شکل مربوط به هیستوگرام توزیع صفت مؤلفه در طیف وسیعی از طبقات شکل است. هر کلاس اندازه (مطابق با کلاس شکل) در طیف الگوی اندازه (طیف الگوی شکل وجه) با اندازه گیری Lebesgue مربوط به مقدار جزئیات در آن کلاس توصیف می شود. طیف الگو را می توان به عنوان تخمین های تابع چگالی احتمال در ساده ترین شکل هیستوگرام خود تفسیر کرد که احتمال وجود یک جزء با اندازه یا شکل معین در تصویر را توصیف می کند. به منظور قرار دادن تعریف طیف الگوی اندازه از [ 23 ] به شکلی مناسب تر برای تصاویر در مقیاس خاکستری I ، حجم یک تصویر مقیاس خاکستری I را به صورت زیر تعریف می کنیم:
سپس برای گرانولومتری اندازه {Γتیمن}{Γتیمن}، می توانیم طیف الگوی اندازه را تعریف کنیم {سΓ ,تیمن}{سΓ،تیمن}مانند:
به طور مشابه، با توجه به [ 50 ]، برای یک گرانولومتری شکل {Φتیمن}{Φتیمن}، طیف الگوی شکل {سΦ ,تیمن}{سΦ،تیمن}را می توان به صورت زیر تعریف کرد:
ترکیب طیفهای الگوی شکل و اندازه در یک هیستوگرام دو بعدی منحصر به فرد که میزان جزئیات تصویر را در سطلهای اندازه شکل اختصاصی نشان میدهد، یک طیف الگوی اندازه شکل تولید میکند [ 47 ]. برای اندازه گرانولومتری {Γتیمن}{Γ��}و گرانولومتری شکل {Φتوj}{Φ��}، ما طیف الگوی اندازه شکل ترکیبی را تعریف می کنیم {سΓ , Φ ,تیمن،توj}{�Γ,Φ,��,��}مانند:
هنگامی که برای یک تصویر کامل محاسبه میشوند، میتوانند بهعنوان توصیفگر تصویر ثابت ترجمه، مقیاس و چرخش استفاده شوند و با موفقیت در طبقهبندی تصویر [ 47 ] و بازیابی [ 6 ] اعمال شوند. استفاده از ترکیبی از ویژگیهایی که ویژگیهای شیء مختلف را توصیف میکنند، مانند جهتگیری، رنگ و شدت، همانطور که در [ 59] بررسی شد، ممکن است.]. از آنجایی که هدف ما توصیفگر کدگذاری تفاوت بین تصاویر با محتوای زیاد و کم است، توصیفگرهای تولید شده را عادی نمیکنیم، بلکه صرفاً مقدار جزئیات تصویر (معیار Lebesgue از مؤلفههای کمککننده) را به عنوان نسبت اندازه کل تصویر ذخیره میکنیم. طیف های الگو با انتخاب تعداد bin هایی که برای هر ویژگی استفاده می شود و همچنین حداکثر مقدار هر ویژگی که در هیستوگرام در نظر گرفته می شود، پارامتری می شوند. توزیع bin بر روی کلاسهای شکل و اندازه مختلف معمولاً لگاریتمی در محدوده انتخاب شده از مقادیر ویژگی است. هنگامی که به این روش استفاده می شود، ما به توصیفگرهای تصویر جهانی تولید شده به عنوان طیف الگوی جهانی (GPS) اشاره خواهیم کرد.
3.4. طیف الگوی محلی
اخیراً، یک گسترش محلی از طیف های الگو پیشنهاد شده است [ 24 ، 25 ]، که برای مشخص کردن تکه ها به جای کل تصویر طراحی شده است، به عنوان مثال، مناطق مورد نظر به طور خاص انتخاب شده یا تکه هایی با شکل و اندازه از پیش تعیین شده. یک طیف الگوی اندازه شکل محلی با اعمال سری عملگرها به دست می آید {سΓ , Φ ,تیمن،توj}{�Γ,Φ,��,��}به یک جزء متصل خاص Lk ، i��,من، یا به طور کلی یک منطقه آرآربه جای کل تصویر من . آنها در ابتدا در مناطق بیرونی با حداکثر پایداری (MSER) [ 7 ] به دلایل کارایی محاسباتی معرفی شدند ، زیرا MSERها را می توان از سلسله مراتب درخت حداکثر و min-tree به روشی ساده استخراج کرد. نتایج تجربی اولیه نشان داد که این توصیفگرها میتوانند عملکردهای رقابتی را در زمینه بازیابی تصویر در مقیاس خاکستری [ 24 ] به دست آورند، و ما را برانگیخت تا طیفهای الگوی محلی (LPS) را در زمینه سنجش از دور در کنار استراتژیهای متنوعتر بررسی کنیم.
مقیاس ناگزیر کوچکتر اشیاء موجود در تصاویر هوایی، با توجه به عکسهای رنگی معمولی، نیاز به استخراج مناطق مورد علاقه با استفاده از مراحل تشخیص مانند MSER را کاهش می دهد. به همین دلیل است که ما در عوض از یک استراتژی شبکه منظم متراکم برای محاسبه LPS استفاده کرده ایم. به طور خاص، LPS بر روی تکه های مستطیلی محلی که بر روی یک شبکه منظم نمونه برداری متراکم روی تصویر تعریف شده اند محاسبه می شود ( برای جزئیات به بخش 4 مراجعه کنید). اگر همه وصلههای محلی از پیش انتخابشده اندازه یکسان (یا بسیار مشابه) داشته باشند، ویژگی عدم تغییر مقیاس در گسترش GPS به LPS وجود دارد [ 25]]. با این حال، برای دستیابی به توصیف تصویر در مقیاسهای چندگانه، میتوان اندازههای مختلف وصلههای محلی را متناسب با هر مقیاس مورد استفاده انتخاب کرد. با توجه به باینینگ لگاریتمی، از یک مقیاس مرجع مشترک M استفاده میشود تا امکان مقایسه توصیفگر را به شیوهای غیرمتغیر مقیاس فراهم کند. طیف الگوی محلی {سΓ , Φ ,تیمن،توj، م} ( ر){سΓ،Φ،تیمن،تو�،م}(آر)سپس به صورت زیر تعریف می شود:
جایی که یک Rآآربه طور کلی مقیاس پذیری منطقه را نشان می دهد آرآرتوسط یک . این تکنیک، که در [ 24 ] معرفی شد، پیچیدگی رویکرد را افزایش نمیدهد، زیرا این امر با مقیاس کردن مقیاس Lebesgue از مشارکتهای فردی در طول محاسبه توصیفگر به دست میآید.
4. تنظیم آزمایشی
4.1. مجموعه داده ها و معیارهای ارزیابی
همه آزمایشهای ما روی مجموعه دادههای UC Merced در دسترس عموم [ 34 ] انجام شده است. دارای 2100 رنگ است R G Bآرجیبتصاویر در 21 کلاس (100 تصویر در هر کلاس) سازماندهی شده اند که نمونه هایی از آنها در شکل 3 نشان داده شده است . همه تصاویر در اندازه هستند 256 × 256256×256پیکسل ها با وضوح فضایی 30 سانتی متر. ما توصیفگرهای خود را ابتدا بر روی نسخه های خاکستری تصاویر محاسبه کرده ایم، با تبدیل G r a y= 0.299 × R + 0.587 × G + 0.114 × Bجی�آ�=0.299×آر+0.587×جی+0.114×ب.
برای افزایش عملکرد توصیفگرهای LPS، تکنیکهای تقویت دادهها را در تصاویر ورودی مجموعه داده اعتبارسنجی اعمال کردیم. بهترین عملکرد زمانی حاصل شد که تمام تصاویر مجموعه داده های Merced به مدت 45 درجه چرخانده شدند، که نمونه ای از آن در شکل 4 نشان داده شده است. نشان داده شده است . سپس محاسبه LPS بر روی تصاویر تقویت شده تکرار می شود و به توصیفگرهای به دست آمده برای داده های غیرافزوده اضافه می شود. توجه به این نکته حائز اهمیت است که مزیت این رویکرد از این واقعیت ناشی میشود که از قسمتهای مختلف تصویر برای محاسبه توصیفگر استفاده میشود، زیرا خود توصیفکنندهها تغییرناپذیر مقیاس هستند. به همین دلیل، توصیفگرهای GPS بر روی داده های تقویت شده محاسبه نمی شوند، زیرا چرخش یک تصویر محتوای آن را تغییر نمی دهد (همانطور که توسط GPS اندازه گیری می شود).
معیار ارزیابی انتخاب شده متوسط رتبه بازیابی اصلاح شده نرمال شده (ANMRR) است، زیرا این معیار رایج ترین مورد استفاده در این مجموعه داده است، بنابراین امکان مقایسه مستقیم با سایر نتایج منتشر شده را فراهم می کند [9 ، 21 ، 22 ، 34 ] . معمولاً برای اندازه گیری اثربخشی بازیابی استفاده می شود [ 60 ]. با دادن یک پرس و جو q یا تمام پرس و جوهای یک کلاس، یک عدد ک ( ق)ک(�)تعریف شده است، که نشان می دهد که فقط اولی ک( ق)ک(�)تصاویر برگشتی از نظر ارزیابی بازیابی امکان پذیر در نظر گرفته می شوند. اغلب به اندازه دو برابر مجموعه حقیقت زمین تنظیم می شود NG ( q)NG(�). با فرض اینکه کتی ساعتکتیساعتتصویر حقیقت زمین در بازیابی می شود رتبه ( k )رتبه(ک)، یک تابع پنالتی رتبه * ( k )رتبه*(ک)برای هر آیتم بازیابی شده تعریف شده است:
از تمام پنالتی ها رتبه * ( k )رتبه*(ک)برای هر query q ، میانگین رتبه (AVR) برای آن q به صورت زیر تعریف می شود:
پس از مرحله میانی، ANMRR مستقیماً به صورت زیر تعریف می شود:
که در آن NQ تعداد پرس و جوها است. بنابراین، ANMRR مقادیری در محدوده 0 برای بهترین نتایج و 1 برای بدترین نتایج به دست می آورد.
به منظور کامل بودن، ما همچنین نتایج خود را بر حسب معیار بازیابی دیگری، یعنی میانگین دقت (mAP) بیان می کنیم. این اندازه گیری به طور خاص برای ارزیابی نتایج بازیابی رتبه بندی شده [ 61 ] و ارائه یک معیار کیفیت واحد در تمام سطوح فراخوانی یک سیستم برای مجموعه ای از پرس و جوهای متعدد طراحی شده است. برای یک تصویر پرس و جوی منفرد q ، اگر یک سیستم بازیابی برگردد ک( ق)ک(�)نتایج، ما میتوانیم دقت را محاسبه کرده و تنها با در نظر گرفتن اولین m تصاویر بازگشتی به صورت نامرتب، آن را به یاد آوریم. دقت در m به عنوان نسبت بین تعداد تصاویر صحیح (مرتبط) در مجموعه نتایج و تعداد کل تصاویر بازیابی شده در آن نقطه، m محاسبه می شود :
در حالی که فراخوانی در m به عنوان نسبت بین تعداد تصاویر مرتبط در مجموعه نتایج و تعداد کل تصاویر مرتبط برای آن پرس و جو تعریف می شود:
محاسبه و ترسیم مقادیر دقت و یادآوری برای یک پرس و جو در یک زمینه بازیابی رتبه بندی شده، یک منحنی فراخوان دقیق را تولید می کند. مساحت زیر این منحنی بر روی همه نتایج K مطابق با AP، میانگین دقت یک پرس و جو، و معادل میانگین مقادیر دقت به دست آمده برای مجموعه نتایج بازیابی K برتر، پس از بازیابی هر نتیجه مرتبط جدید است:
جایی که مرتبط ( m )مربوط(متر)اگر m- امین تصویر بازیابی شده مرتبط باشد ، یک متغیر نشانگر با مقدار 1 است . در نهایت، mAP به عنوان مقدار میانگین میانگین دقت برای همه پرس و جوها محاسبه می شود. این روش پیشبینیهای نادرست را جریمه نمیکند، و امکان بررسی تعداد زیادی از نتایج بازیابی را فراهم میکند، در حالی که ترتیب پیشبینیها را با جریمه کردن پیشبینیهای نادرست قبل از پیشبینیهای صحیح ارزشگذاری میکند.
4.2. تنظیمات رویکردهای طیف الگو
4.2.1. طیف الگوی جهانی
ما استفاده از توصیفگرهای GPS دو بعدی را برای به دست آوردن عملکرد پایه برای خانواده توصیفگرهای طیف الگو استفاده کردیم. در این رویکرد پایه، ما توصیفگرهای GPS را از کل تصاویر محاسبه میکنیم. اندازههای سطل به صورت تجربی تعیین شدهاند، جایی که اندازههای سطل مورد استفاده در آثار منتشر شده قبلی به عنوان نقطه شروع استفاده میشوند [ 6 ]. این منجر به انتخاب استفاده از 10 bin برای ویژگی اندازه (مساحت) و شش برای ویژگی شکل شد. حداکثر مساحت مجاز در هیستوگرام برابر با اندازه تصویر است. حداکثر برای ویژگی های شکل به طور تجربی 56 برای ویژگی CNC و هشت برای ویژگی تعیین شد. اچاچصفت. همانطور که ما GPS را از هر دو درخت کوچک و حداکثر درخت هر تصویر محاسبه می کنیم، این منجر به توصیف کننده های جهانی طول می شود. 6 × 10 + 6 × 10 = 1206×10+6×10=120.
ما در جدول 1 نتایج را با استفاده از Area+CNC و Area+ گزارش می کنیماچاچبه عنوان ویژگی های شکل، و هنگام ترکیب آنها در یک توصیفگر واحد به طول 240، بهبود بیشتری را مشاهده کنید. محاسبه GPS از هر کانال در مقیاس خاکستری R G Bآرجیبتصاویر به طور جداگانه (یعنی به صورت حاشیه ای) نیز مورد بررسی قرار گرفته است، اما نتایج به دلیل پیشرفت های ناچیز و به دلیل اینکه این رویکرد نمی تواند عملاً با تصاویر چند کاناله دارای تعداد دلخواه کانال اجرا شود، گزارش نشده است.
4.2.2. طیف الگوی محلی
به منظور بهبود رویکرد GPS خط پایه، ابتدا روی یک رویکرد محلی و تک مقیاس تمرکز کردهایم. در اینجا، تصویر به صورت متراکم نمونه برداری می شود و LPS بر روی تکه های تصویر مستطیلی معمولی بر روی یک شبکه روی تصویر محاسبه می شود، همانطور که در شکل 5 الف نشان داده شده است. ابعاد پچ به صورت تجربی بین تعیین شده است د= 32د=32و د= 128د=128پیکسل ها و ابعاد 80 × 8080×80پیکسل ها بهینه تعیین شدند. به همین ترتیب، فاصله 16 پیکسلی بین مراکز وصله برای بهترین عملکرد در بین موارد آزمایش شده انتخاب شده است. s = 8 ، 16 ، 32س=8،16،32پیکسل ها استفاده از هشت سطل برای مشخصه اندازه و شش عدد برای شکل، که در نتیجه یک هیستوگرام اندازه ایجاد می شود 8 × 68×6، مشخص شد که بهترین عملکرد را با توجه به اندازه LPS نشان می دهد. این نیز با آزمایشات قبلی ما از LPS در مناطق برجسته [ 24 ] مطابقت دارد. از آنجایی که ما هنوز دو هیستوگرام در هر پچ تصویر (یکی برای هر درخت) محاسبه می کنیم، اندازه توصیفگر نهایی LPS برابر است با 8 × 6 + 8 × 6 = 968×6+8×6=96( جدول 1 – LPS متراکم). از آنجایی که همه وصله ها دارای اندازه یکسانی هستند (برخلاف مناطق برجسته)، نیازی به هیچ مرحله اضافی برای اطمینان از عدم تغییر مقیاس توصیفگرها وجود ندارد.
ما با محاسبه LPS در مقیاس های چندگانه، با استفاده از یک هرم چند مقیاسی از تکه ها، آزمایش بیشتری با LPS انجام داده ایم ( جدول 1 – هرم LPS). اندازه وصله در پایین ترین مقیاس به تنظیم شد 32 × 3232×32پیکسل ها و اندازه پچ برای هر سطح از هرم افزایش می یابد ( 2 ×2×در امتداد هر بعد)، همانطور که در شکل 5 نشان داده شده است . از آنجایی که اندازه وصله های مورد استفاده برای LPS دیگر سازگار نیست، ما از استراتژی معرفی شده در کار قبلی خود [ 24 ] پیروی می کنیم تا با استفاده از یک مقیاس مرجع مشترک برای همه وصله ها، از عدم تغییر مقیاس اطمینان حاصل کنیم (تنظیم به اندازه پچ در مقیاس دوم، 64 × 6464×64). فاصله بین مراکز وصله بر روی 16 پیکسل در تمام مقیاس ها تنظیم شده است، بنابراین طول توصیفگر یکسان 96 است، اما با سه برابر بیشتر توصیفگرهای محاسبه شده در هر تصویر.
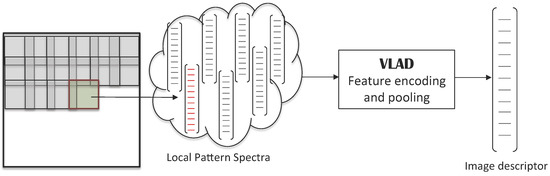
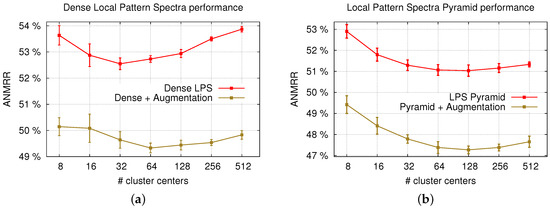
ما هم LPS متراکم و هم LPS هرمی را با و بدون افزایش داده آزمایش کردهایم. علاوه بر این، برای هر دو رویکرد مبتنی بر LPS، از طرح نمایه سازی VLAD برای تولید توصیفگرهای تصویر نهایی [ 11 ] استفاده شده است ( شکل 6 ). از آنجایی که پارامتر مهم VLAD تعداد مراکز خوشه است، ما بهترین عملکرد را برای هر رویکرد LPS با فرض تعداد متفاوتی از مراکز خوشه گزارش میکنیم. k = 8ک=8به k = 512ک=512( شکل 7 ب). برای ساختن واژگان برای VLAD، ما به مجموعه دادهای در دسترس عمومی دیگر، یعنی مجموعه داده اعتبارسنجی چالش تشخیص تصویری در مقیاس بزرگ ImageNet 2010 (ILSVRC2010) تکیه میکنیم [ 62 ]. اجازه دهید تأکید کنیم که این مجموعه داده حاوی هیچ داده سنجش از راه دور نیست. توصیفگرها برای 500 تصویر اول این مجموعه داده ImageNet محاسبه میشوند (با پارامترهای یکسان برای نمونههای متراکم و رویکرد هرمی، جایی که اندازه وصله هرم در آن متوقف شده است. 256 × 256256×256پیکسل)، و یک زیر مجموعه تصادفی از این توصیف کننده ها برای هر آزمایش استفاده می شود. هیچ افزایش داده ای روی این مجموعه داده انجام نشد، زیرا فقط برای ارائه کلمات بصری برای محاسبه مرکز خوشه VLAD استفاده شده است.
5. نتایج و بحث
یافته های کلی ما در جدول 1 نشان داده شده است . از نتایج بهدستآمده، گزارش میدهیم که خط پایه GPS، علیرغم اینکه یک رویکرد کلنگر است، هماکنون هم از رویکردهای مورفولوژیکی جهانی و محلی گزارششده قبلی بر اساس توصیف بافت [ 21 ، 22 ] و همچنین رویکرد SIFT منی بر اساس نقاط کلیدی برجسته بهتر عمل میکند. [ 34 ].
به طور خاص، GPS ابتدا در امتداد Area+CNC محاسبه شده است، زیرا این ویژگی شکل است که بیشتر برای محاسبه طیف الگو استفاده می شود. سپس، ما علاوه بر این با Area+ آزمایش کردهایم اچاچترکیبی برای GPS (پیشنهاد شده توسط [ 6 ] به عنوان دومین ویژگی مؤثر شکل). مجموعه دوم از طیف های الگو، بر اساس اچاچ، به خودی خود عملکرد بدتری دارد که می تواند با قدرت تبعیض کمتری توضیح داده شود اچاچویژگی، زیرا این ویژگی مقادیر را از محدوده کوچکتری نسبت به CNC بدست می آورد. با این وجود، ترکیب این دو ویژگی منجر به بهبود عملکرد می شود، بنابراین ماهیت مکمل آنها را نشان می دهد. بهترین نتایج به دست آمده با GPS به ANMRR رسیده است 55.7 %55.7%(یا mAP معادل 32.5 %32.5%).
تا آنجا که به رویکرد مبتنی بر LPS متراکم و VLAD پیشنهادی مربوط می شود، ما پیشرفت های قابل توجه تری را در آنجا به دست آورده ایم. اولین رویکرد LPS (LPS متراکم)، که در آن توصیفگرها از تکههای اندازهگیری متراکم و منظم محاسبه میشوند. 80 × 8080×80پیکسل با 16 پیکسل بین مراکز خوشه، 144 توصیفگر در هر تصویر تولید می کند و ANMRR از 52.5 %52.5%(یا نقشه از 38 درصد38%).
با این حال، نتایج LPS تنها با استفاده از ویژگی CNC گزارش میشوند، زیرا برخلاف GPS، ترکیب آنها با ویژگی شکل دیگر منجر به بهبودی نشده است. این را می توان با این واقعیت توضیح داد که مقدار جزئیات موجود در تکه های نمونه متراکم بسیار کوچکتر از کل تصویر است که در مورد GPS وجود دارد، از این رو نمونه ها (مناطق) کمتری در طول محاسبه هیستوگرام به کار می روند. علاوه بر این، طیف وسیعی از اچاچویژگی معمولاً کوچکتر از ویژگی CNC است. در نتیجه، هیستوگرام ها دیگر نماینده توزیع این ویژگی در LPS نیستند، به دلیل عدم وجود مناطق نمونه کافی. از سوی دیگر، افزایش داده ها منجر به بهبود سه درصدی برای هر دو ANMRR و mAP می شود ( شکل 7 a). این شکل همچنین تأثیر تعداد مراکز خوشه VLAD را بر عملکرد نشان می دهد، جایی که می توان مشاهده کرد که بهترین عملکرد برای تعداد نسبتاً کمی از مراکز خوشه به دست می آید. همچنین میتوان مشاهده کرد که تعداد بهینه مراکز خوشهای بهدلیل تنوع بیشتر بیانشده در توصیفگرها، هنگام اعمال تقویت دادهها به سمت مقادیر بیشتر تغییر میکند.
آخرین پیشرفت در رویکرد پیشنهادی از طریق محاسبه LPS چند مقیاسی (LPS هرمی) به دست آمده است. این استراتژی منجر به افزایش تقریباً سه برابری در تعداد توصیفگرها میشود و به طور خاص 476 توصیفگر در هر تصویر به دلیل مقیاسهای چندگانه تولید میکند. در حالی که عملکرد خود را با استفاده از افزایش داده ها همانطور که در شکل 7 نشان داده شده است، بهبود می بخشد ب نشان داده شده است، بهبود می بخشد.
علاوه بر این، روند مشابهی در تعداد مراکز خوشهای نیز بین نسخههای تقویتشده و غیرافزودهشده LPS هرمی مشاهده میشود، زیرا هر دو به سطح بهینه خود برای همان تعداد مراکز خوشهای دست مییابند. در مقایسه با رویکرد متراکم مقیاس تک، تفاوت را می توان با افزایش پیچیدگی توصیفگر و همچنین تعداد آنها توضیح داد. توجه داریم که این استراتژی شامل رویکرد GPS است، زیرا مقیاس نهایی هرم LPS خود تصاویر است.
به طور کلی، بهترین نتایج مبتنی بر LPS که به دست آمده اند، هستند 47.2 %47.2%ANMRR (مربوط به 43.7 %43.7%mAP)، و بهبودی را نسبت به تمام رویکردهای مبتنی بر مورفولوژی قبلی، و همچنین رویکرد SIFT مبتنی بر نقطه کلیدی در این مجموعه داده نشان میدهد [ 34 ]. علاوه بر این، نتایج ما با رویکرد متراکم SIFT+VLAD [ 9 ] تنها با یک 1.2 ٪1.2%تفاوت در عملکرد ANMRR با این حال، اجازه دهید به این نکته اشاره کنیم که با استفاده از توصیفگرهای کوتاهتر (به طول 96 برای LPS و 128 برای SIFT)، و همچنین با استفاده از توصیفگرهای کمتر ([9] یک افست 10 پیکسل و پنج سطح هرمی را گزارش میکند . در حالی که ما از یک افست 16 پیکسلی در چهار مقیاس مختلف استفاده می کنیم).
6. نتیجه گیری
در این مقاله، ما از هر دو طیف الگوی جهانی و محلی در زمینه بازیابی تصویر جغرافیایی استفاده کردهایم و طیفهای الگو را برای اولین بار با یک استراتژی متراکم در ترکیب با طرح نمایهسازی VLAD پیادهسازی کردهایم. ما عملکرد بازیابی طیف الگوی جهانی و همتای محلی جدید آن را ارزیابی کردهایم و آنها را با عملکرد سایر رویکردهای پیشرفته مقایسه کردهایم. ما همچنین نتایج خود را بر حسب mAP بیان کردهایم، یکی دیگر از معیارهای رایج در بازیابی، که امکان مقایسه آسانتر با عملکرد توصیفگرها در مجموعههای داده مختلف را فراهم میکند. توصیفگر ما از رویکرد SIFT مبتنی بر نقطه کلیدی [ 34] بهتر عمل می کند] و بهترین نتایج مبتنی بر مورفولوژی را تا کنون تولید می کند، که از تمام رویکردهای مورفولوژیکی قبلی بهتر عمل می کند.
در مقایسه با رویکرد SIFT متراکم [ 9 ]، نتایج مشابهی را با استفاده از طرح نمایه سازی VLAD به دست می آوریم، با عملکرد ما کمی کمتر از 1.2 ٪1.2%ANMRR. با این حال، مزیت توصیفگر ما این است که، علیرغم نمونهگیری کمتر، بر بردارهای ویژگی بسیار کوتاهتر متکی است ( 75 درصد75%طول توصیفگرهای SIFT متراکم)، که منجر به سرعت بازیابی بالاتر می شود.
با ایجاد یک راه حل توصیفی مبتنی بر محتوای LPS چند مقیاسی و موثر، کار آینده بر بهره برداری از ساختار چند متغیره تصاویر سنجش از راه دور متمرکز خواهد شد، که امروزه به طور معمول به سطح صدها باند در مورد تصاویر فراطیفی می رسد.






بدون نظر