

خلاصه
مدیریت فراداده یک عامل توانمند کننده ضروری برای دارایی های مکانی است زیرا کشف، بازیابی و استفاده واقعی از دومی به شدت به کیفیت این توصیفات وابسته است. متأسفانه، چشم انداز چندوجهی فرمت ها، الزامات و قراردادهای فراداده، شناسایی ابزار ویرایشی را که می توان به راحتی با ویژگی های یک پروژه، گروه کاری و جامعه عملی خاص تنظیم کرد، دشوار می کند. راه حل ما یک ابزار ویرایش ابرداده مبتنی بر الگو است که می تواند برای هر طرحواره مبتنی بر XML سفارشی شود. خروجی آن توسط سوابق فراداده مطابق با استانداردها تشکیل میشود که همتای معنایی آگاهانهای دارند که تکنیکهای بهرهبرداری جدید را استخراج میکند. علاوه بر این، منابع داده های خارجی را می توان به راحتی وصل کرد تا عملکردهای تکمیل خودکار را بر اساس ساختارهای داده ای که در Web of Data موجود است، ارائه دهند. علاوه بر ارائه ملزومات سفارشی سازی ویرایشگر با استفاده از دو مورد استفاده، ما روش شناسی را به کل چرخه حیات ابرداده های مکانی گسترش می دهیم. ما قابلیتهای جدیدی را که توسط نمایش ابرداده مبتنی بر RDF با توجه به مدیریت متاداده سنتی در حوزه جغرافیایی فعال میشود، نشان میدهیم.
کلید واژه ها:
زیرساخت های داده های مکانی ; فراداده های جغرافیایی ; RDF _ معناشناسی ; سفارشی سازی ویرایشگر
1. معرفی
بازیابی دارایی ها در وب در درجه اول به فراداده ای که آنها را توصیف می کند متکی است. پورتالهای داده میتوانند مکانیسمهای جستجو را بر اساس این توصیفات، با درجاتی از بیان که به جزئیات طرحواره ابرداده حاکم بر ساختار آنها وابسته است، بیان کنند. در میان داراییها، داراییهای مربوط به اطلاعات مکانی تقریباً به طور کامل برای بازیابی به ابردادهها متکی هستند که اغلب به عنوان کشف نامیده میشوند، زیرا داراییها معمولاً در قالب غیر متنی هستند و سپس شیوههای نمایهسازی موتورهای جستجوی عمومی در بهترین حالت ناکارآمد هستند. علاوه بر این، این دسته از دادهها با ویژگیهایی مشخص میشوند (به عنوان مثال، گستره جغرافیایی، با نام مستعار جعبه مرزی) که به ابرداده استاندارد نیاز دارند تا توسط ابزارهای هدف خاص در این دامنه رمزگذاری و پردازش شوند [ 1 ، 2 ، 3 ]. این یکی از محرکهای تلاش استانداردسازی است که توسط دستورالعمل INSPIRE، [ 4 ، 5 ، 6 ]، مجموعهای از دستور العملها برای قابلیت همکاری که پایه و اساس درستی بر روی استانداردها دارند، ارائه شده است. INSPIRE امکان هماهنگی داراییهای مکانی را در میان کشورهای اروپایی فراهم میکند، زیرا علیرغم جابجاییهای متفاوت دستورالعمل در کشورهای متمایز، خط پایه تعیینشده توسط ابردادههای اصلی INSPIRE به جامعه مکانی اجازه میدهد تا داراییهای ناهمگن را به صورت یکپارچه کشف و به آن دسترسی داشته باشد.
با این حال، چشم انداز مدیریت داده ها به ناچار از زمان تدوین دستورالعمل و اجرای اولیه و اولیه آن تغییر کرده است. با توجه به ابرداده ها، مقدمه ای که زمانی پیشرفته بود که توسط استانداردهای مرجع برای اطلاعات جغرافیایی تعیین شده بود [ 7 ، 8 ، 9] اساساً به دلیل تغییر دیدگاه از نمایش داده ها (یعنی جستجو برای مکانیسم های رمزگذاری مناسب برای داده ها و ابرداده ها در یک حوزه خاص) به دسترسی و پردازش داده ها ناکافی شده است. به عنوان مثال، عباراتی مانند Open Data، Linked Data، RDF و SPARQL به طور فزاینده ای با قابلیت همکاری و باز بودن داده مرتبط هستند. همچنین، الزامات جدیدی که در چارچوب اصلی INSPIRE پیش بینی نشده است، در چند سال اخیر پدیدار شده اند، برخی از این موارد توسط گروه های کاری موضوعی INSPIRE (مانند [ 10 ، 11) رسیدگی می شود.]). به عنوان مثال، کاتالوگ های داده – به معنای گسترده – توسط دسته جدیدی از منابع داده که توسط داده های زمان واقعی/تقریباً واقعی استخراج شده از حسگرها تشکیل شده اند، غنی شده اند. در نتیجه، این منابع داده جدید برای مدیریت و تصویب به دادههای موقت و نمایشهای فراداده نیاز داشتند. در نهایت، همانطور که قالبها و شیوهها در زمینه جغرافیایی توسعه مییابند، وب به طور کلی در پیدایش حجم وسیعی از اطلاعات قابل پردازش ماشینی که عموماً تحت عنوان وب دادهها نامیده میشوند، مشارکت میکند [12 ، 13 ] . به طور کلی، فناوریهای وب معنایی پتانسیل زیادی برای کشف دقیق داراییها دارند، همانطور که توسط کاربردهای معناشناسی در بسیاری از حوزههای متمایز، مانند [14، 15 ، 16 گواهی میشود .].
در مهندسی زیرساخت اشتراک داده برای RITMARE ( http://www.ritmare.it/ ) (یک پروژه شاخص توسط وزیر ایتالیایی dell’Istruzione، dell’Università e della Ricerca ) ما تصمیم گرفتیم بهترین شیوه ها را اتخاذ کنیم که با هم با انطباق با دستورالعمل INSPIRE، همچنین می تواند مهاجرت به پارادایم های جدید فوق الذکر را برای نمایش داده ها و دسترسی آسان کند. در واقع، از یک سو، ما باید ابردادهها را مطابق با خط پایه تنظیمشده توسط INSPIRE (به طور خاص، با انتقال ایتالیایی دستورالعمل، RNDT [17] ) و همچنین طبق SensorML، قالب ابردادهای که برای اطلاعات حسگر استفاده میکنیم، هماهنگ کنیم. 18 ، 19]. از سوی دیگر، ما میخواهیم ایجاد ابرداده را بر روی واژگان کنترلشده و بهطور کلی، اطلاعات زمینهای که از وب دادهها گرفته شده است، پایهگذاری کنیم. با اشاره به طبقهبندی ناهمگونیها در [ 20 ]، تحقیق ما به سطح معنایی میپردازد، دو مورد دیگر ( نحوی و ساختاری) توسط نهادهای استاندارد استاندارد (به عنوان مثال، جوامع ISO، INSPIRE و OGC) مورد توجه قرار میگیرند. همچنین، باید توجه داشت که در میان تلاشهای مختلف برای پرداختن به عدم تطابق معنایی توصیفهای فراداده، ما بر افزایش معنایی (یعنی ارتباط مقادیر ویژگی مبتنی بر متن با شناسههای منحصربهفرد مبتنی بر URI، همانطور که در بخش 3 توضیح داده شده است، تمرکز میکنیم .). سایر رشتههای تحقیقاتی، مانند فعالیتهای تکمیلی اختصاص داده شده به هماهنگسازی مشارکتهای مستقل در وب مکانی دادهها در شبکهای ثابت از ساختارهای دادهای به هم پیوسته، باید خارج از موضوع در نظر گرفته شوند.
به عبارت دیگر، ما راه حل خود را برای پل زدن شکاف بین انطباق قانونی و شیوه های جدید وب 3.0 فوق الذکر ارائه می دهیم [ 21 ]. به طور خاص، ما بر ادغام منابع داده های خارجی تمرکز می کنیم تا توصیفات ابرداده یکپارچه و یکپارچه را به اسناد زنده تبدیل کنیم . در واقع، توصیفهای فراداده مبتنی بر RDF ما میتوانند به راحتی با تغییرات (محققان در حال تغییر محل کار، شرکتها به آدرسی متفاوت، تغییر اصطلاحات، و غیره) تطبیق داده شوند و به عنوان مثال در بخش، مکانیسمهای کشف نوآورانه را استخراج کنند . 4. لازم به ذکر است که در حالی که شیوه های توصیف شده در این کار از الزامات مطرح شده توسط پروژه RITMARE ناشی می شود، استفاده از روش شناسی به هیچ دانش قبلی در مورد پروژه نیاز ندارد. در واقع، چارچوب مدیریت ابرداده ما توسط تعدادی از پروژه ها، یعنی پروژه های FP7 ERMES ( http://www.ermes-fp7space.eu/it/homepage/ ) و EuroFleets2 ( http://www.eurofleets) پذیرفته شده است. eu/np4/home.html )، پروژه H2020 eLTER ( http://www.lter-europe.net/lter-europe/projects/eLTER )، و پروژه پرچمدار ایتالیایی NextData ( http://www.nextdataproject. آن/ ). علاوه بر این، نمایههای فرادادهای که خارج از جعبه در دسترس هستند، برای جوامع INSPIRE و SWE مورد توجه عموم هستند [ 22]] و سپس روش ما برای پذیرش توسط ارائه دهندگان داده مناسب است.
روشی که ما برای مدیریت ابرداده پیشنهاد می کنیم بر روی الگوها استوار است . یعنی تعاریف طرحوارههای فراداده ایجاد شده بر اساس یک فرازبان (در اینجا، برای جلوگیری از ابهام با تعاریف بخش 3.2 ، به جای «زبان الگو» از «فرازبان» استفاده میکنیم . الگوها ساختار یک طرحواره فراداده XML هدف را بیان می کنند، مانند طرحواره های INSPIRE و RNDT که قبلا ذکر شد، اما همچنین SensorML (نسخه های 1.0.1 و 2.0.0) [ 18 ، 19 ]]. آنها همچنین حاوی اطلاعات لازم برای اعمال افزایش معنایی به ابرداده تولید شده هستند. به طور خاص، الگو باعث ایجاد یک واسط ویرایش ابرداده، پیشانی برنامه، می شود که به طرح و منابع داده مورد نظر متصل است. سپس، فعالیت تألیف ابرداده، اطلاعات اضافی را ارائه میکند که برای خروجی XML خاص نیست، بلکه برای تشکیل همتای معنایی توصیف ابرداده است که به صورت RDF بیان میشود [23] .]. هر زمان که ابرداده اصلی درخواست شود، به عنوان مثال پس از کشف دارایی توسط کاربر نهایی، الگو دوباره جستجو می شود، توضیحات RDF مربوط به دارایی از کاتالوگ استخراج می شود و توضیحات XML بازسازی می شود. مزایای این روش با توجه به سازگاری فراداده آشکار است: در واقع، هر بار که توضیحات فراداده XML تولید میشود، بر اساس اطلاعات بهروز شدهای که از وب دادهها بر اساس الگو و توضیحات RDF ایجاد میشود، ساخته میشود. مشخص كردن.
این مقاله به شرح زیر سازماندهی شده است. بخش 2 زمینه این کار را ترسیم می کند که شامل موارد ضروری در مورد فناوری های وب معنایی است که در ادامه مفید خواهند بود، یک نمای کلی از پروژه RITMARE ارائه می دهد و کارهای مرتبط را معرفی می کند. در میان راه حل های پیشنهادی، ما بر روی EDI تمرکز می کنیم، برنامه مدیریت ابرداده که از XML و RDF برای توصیف ابرداده استفاده می کند. بخش 3 دو مورد استفاده را ارائه می کند و آنها را به عنوان ساختارهای الگو پیاده سازی می کند. این بخش همچنین یکپارچه سازی ساختارهای داده خارجی و تولید فرمت های خروجی مجزا را پوشش می دهد. بخش 4 مزایای رویکرد ما را مورد بحث قرار می دهد. در نهایت، بخش 5نتیجهگیری میکند، به «تصویر بزرگ» مدیریت غیرمتمرکز ابرداده اشاره میکند، و کارهای آینده در مورد این موضوع را تشریح میکند.
2. زمینه
2.1. ضروریات وب معنایی
از جمله جنبه های نوآورانه رویکرد ما، توسل به اطلاعاتی است که از وب داده ها برای ارائه ابرداده استخراج می شود. ما به سختی سطح تنوع فناوریها، مشخصات و شیوههایی را که این حوزه را مشخص میکنند بررسی میکنیم، اما پس از خواندن این پاراگراف، خواننده باید از نمایش دادهها و فرمالیسمهای پرس و جو که در سراسر مقاله استفاده میشود آگاه شود. اطلاعات بیشتر در مورد این موضوع را می توان در [ 24 ] یافت . دانش اولیه مدل داده XML ( https://www.w3.org/standards/xml/l ) نیز برای درک کامل ساختار فرازبانی که ما توسعه دادیم مفید است. هنوز معرفی این فناوری پایه خارج از حوزه این کار است.
مدل داده مرجع برای وب داده ها RDF [ 23 ] است، فرمالیسمی که اطلاعات را به صورت نمودارهای برچسب دار جهت دار بیان می کند که جزء اتمی آن سه گانه (یا ادعا ) است، مانند موارد زیر:
<http://some/subject> <http://some/predicate> <http://some/object>.
سه گانه ها از یک موضوع ، یک محمول و یک شی تشکیل شده اند که معمولاً از طریق URI ها شناسایی می شوند [ 25 ] (URI ها را به عنوان URL های قدیمی خوب در نظر بگیرید که لزوماً به محتوای وب منتهی نمی شوند). اشیاء همچنین می توانند تحت اللفظی ساده باشند، اگرچه این دسته از موجودیت های “برگ” به شکل دادن به نمودار کلی داده کمکی نمی کنند:
<http://some/subject> <http://some/predicate> "some object"@en .
فضاهای نام [ 26 ] که مانع خوانایی URI ها می شوند، اغلب با پیشوندها جایگزین می شوند، همانطور که در فرمالیسم لاک پشت ما از بین قالب های سریال سازی مختلف برای این مدل داده [ 27 ] انتخاب کردیم. Turtle همچنین اجازه می دهد تا از مشخص کردن اطلاعات ثابت (یعنی همان ویژگی و/یا موضوع مشابه) هنگام ارائه چندین سه با استفاده از علائم نگارشی اجتناب شود:
@prefix ex: <http://some/> . ex:subject ex:predicate_1 ex:object_1 ; ex:predicate_2 ex:object_2 . ex:subject ex:predicate_3 ex:object_3 , ex:object_4 .
سبک مشخصات هر چه باشد، سه گانه RDF یک گراف (غیرمتمرکز) را القا می کند که ساختار و محتوای اطلاعات آن نیاز به پرس و جوی موقت و به طور کلی فرمالیسم های دستکاری دارد. در یک سناریوی داده پیوندی ایدهآل (یعنی زمانی که URIها در توضیحات RDF قابل حل با ساختارهای داده واقعی هستند)، عاملها میتوانند با دنبال کردن ویژگیهای RDF، نمودار را از یک سر به سر دیگر عبور دهند. به عبارت واقع بینانه، مرور وب داده ها مستلزم تجمیع تعدادی از نقاط پایانی مجزا است که از طریق SPARQL، یک زبان پرس و جوی SQL مانند، مورد بازجویی قرار می گیرند.
SPARQL [ 28 ]، به بلوغ رسیده است و انعطافپذیری و بیانی بسیار بیشتری نسبت به SQL سنتی [ 29 ] ارائه میکند (البته عملکردی که پایگاههای اطلاعاتی رابطهای هنگام مدیریت حجم عظیمی از دادهها اجازه میدهند، هنوز بینظیر است). ما فقط از پرسوجوهای SPARQL استفاده میکنیم که مطابق با شیوههای SQL، عبارتهای SELECT و INSERT را شامل میشود، حتی اگر زبان برای سایر فرمهای پرس و جو (ساخت، توصیف، پرسش) اجازه دهد. بازیابی داده ها با عبارات SELECT برابر با تطبیق داده ها (یعنی سه گانه ها، ادعاها) در پایگاه داده با نمودار تعریف شده توسط سه گانه در پرس و جو است. به عنوان مثال، یک پرس و جو که کلمات کلیدی مرتبط با مجموعه داده منبع_1 را انتخاب می کند، و بازیابی از یک نقطه پایانی راه دور بازنمایی های قابل خواندن توسط انسان به زبان انگلیسی به شرح زیر است:
1 PREFIX dcat: <http://www.w3.org/ns/dcat#> 2 SELECT ?keyw ?label 3 WHERE { 4 <http://.../dataset_1> dcat:keyword ?keyw . 5 6 SERVICE <http://some/endpoint> { 7 ?keyw skos:prefLabel ?label . 8 FILTER( LANG(?label) = "en") 9 } 10 }
به طور خاص، در ادامه این مقاله، ما قصد داریم از فدراسیون پرس و جو برای بازسازی نمایش XML هنجاری ابرداده INSPIRE از توضیحات RDF مربوطه استفاده کنیم.
2.2. پروژه شاخص RITMARE
همانطور که قبلاً در مقدمه بحث شد، پذیرش تکنیک های مدیریت ابرداده ما نیازی به دانش قبلی در مورد پروژه RITMARE ندارد. با این حال، این بخش زیرساخت اشتراک داده این پروژه خاص را به عنوان نمونه ای از کاربرد روش در یک معماری جامع برای مدیریت داده های مکانی تشریح می کند. RITMARE مستلزم ادغام تمام مشارکتهای پیشرفته در تحقیقات دریایی ایتالیا در یک SDI منسجم است [ 30]]، چارچوبی برای جمعآوری و ارائه دادههای مکانی، فراداده، خدمات شبکهای و فناوریها. طبقه بندی درشت دانه SDI ها بین زیرساخت های متمرکز و غیرمتمرکز تمایز قائل می شود، با توجه به اینکه داده ها و ابرداده ها در یک مخزن ذخیره می شوند یا بین ارائه دهندگان داده مجزا توزیع می شوند. زیرساخت RITMARE متعلق به نوع دوم است که شامل:
-
مجموعهای از گرههای جانبی که ابردادهها و خدمات مطابق با استانداردها را در معرض دید قرار میدهند.
-
یک سرویس کاتالوگ متمرکز که دسترسی به منابع در دسترس پروژه را به عنوان یک کل فراهم می کند.
این پروژه با مجموعه ای ناهمگون از ارائه دهندگان داده ها (هیئت های تحقیقاتی عمومی و کنسرسیوم های بین دانشگاهی) و نیز طیفی از سهامداران (اداره دولتی، شرکت های خصوصی و شهروندان) مشخص می شود. در نتیجه، این نهادها مجموعه متنوعی از دادهها، ابردادهها، گردش کار و الزامات ناهمگن را در نظر میگیرند. علاوه بر این، ارائه دهندگان داده درجات مختلف بلوغ را با توجه به تأمین دارایی ها مطابق با استانداردهای الزامی نشان می دهند: این بدان معنی است که در توسعه زیرساخت، تلاش زیادی برای ظرفیت سازی در سمت ارائه دهنده داده انجام شده است. علاوه بر این، به عنوان یک پروژه ملی، RITMARE SDI به قوانین تعیین شده توسط INSPIRE و همچنین توسط RNDT ملزم است: بنابراین مدیریت ابرداده نقش کلیدی در معماری مورد نیاز دارد [ 31 ,32 ]. این امر با ارائه یک ابزار مجازی، مجموعه نرم افزار Geoinformation Enabling ToolkIT ( http://www.get-it.it/ )، به اختصار GET-IT، محصول FOSS که قادر به راه اندازی یک گره مستقل در SDI برای جمع آوری، حاشیه نویسی و استقرار داده های مکانی. از جمله دستاوردهای مجموعه GET-IT، ادغام اطلاعات جغرافیایی سنتی (به عنوان مثال، لایهها) با دادههای حسگر است و طبق دانش ما، GET-IT اولین برنامهای است که به این امر دست مییابد. به طور خاص، توزیع GeoNode ( http://geonode.org/ ) با مؤلفههای ad-hoc تکمیل شده است و از جمله آنها، امکاناتی برای مدیریت توصیفات حسگر و مشاهدات مرتبط در سرویس مشاهده سنسور (SOS) است.http://www.opengeospatial.org/standards/sos ) پیاده سازی توسط 52North ( http://52north.org/ ). سپس لایههای جغرافیایی را میتوان با دادههای زمان واقعی حسگرها ترکیب و تطبیق داد [ 33 ، 34 ].
2.3. کارهای مرتبط
در میان بسیاری از محصولات موجود در حالت پیشرفته برای ارائه ابرداده های مکانی، محصولی که توسط GeoNetwork نسخه 2.8 و پیش از آن ( http://geonetwork-opensource.org/ ) ارائه شده است، تا آنجا که می دانیم تنها ابزاری است که به راحتی امکان پذیر است. طرحواره های ابرداده قابل اتصال. بنابراین شناسایی ویرایشگرهایی که میتوان با راهحل ما مقایسه کرد دشوار است: ما فقط میتوانیم ابزارهایی را در نظر بگیریم که بهطور جداگانه به طرحوارههای ابردادهای که بهطور گستردهتر در RITMARE پیادهسازی شدهاند، یعنی پروفایلهای ISO 191** و توضیحات SensorML رسیدگی میکنند. مورد استفاده ارائه شده در این کار بر روی اولین دسته از طرحواره های ابرداده تمرکز دارد، که همچنین بیشترین پشتیبانی را توسط ابزارهای ویرایش دارد. بررسی خوبی از این موارد توسط صفحه نگهداری شده توسط FGDC آمریکایی (بررسی ویرایشگر فراداده ISO) ارائه شده است:https://www.fgdc.gov/metadata/iso-metadata-editor-review ). این منبع آشکار میسازد که اگرچه ویرایشگرهای بالغتر ممکن است ویژگیهایی را ارائه دهند که در حال حاضر توسط ابزار ما پشتیبانی نمیشوند، ابزاری که هنوز در مراحل ابتدایی خود است، ویرایشگرهای فراداده ISO موجود فقط از سفارشیسازی طرح متاداده حاکم پشتیبانی میکنند و اصلاً پشتیبانی نمیکنند. برای منابع داده شخص ثالث همین امر در مورد دسته دوم ابزارهای ویرایش ابرداده، یعنی ابزارهای اختصاص داده شده به SensorML صدق می کند. بررسی مشابهی را می توان در وب سایت OGC (نرم افزار فعال سازی حسگر وب: http://www.ogcnetwork.net/SWESoftware ) یافت. دو ابزار ویرایشی مورد اشاره در این بررسی عبارتند از Pines SensorML Editor ( http://lxspine.googlepages.com/pine’ssensormleditor )، و ویرایشگر فرآیند SensorML (http://code.google.com/p/sensorml-data-processing/ ). هر دو نسخه قدیمی SensorML را پیادهسازی میکنند و هیچکدام از عملکردهای مورد نیاز ما را پیادهسازی نمیکنند. همچنین با در نظر گرفتن ابزارهای ویرایش جدیدتر که در این لیست گنجانده نشده اند، مانند ویرایشگر OpenSensorHub SensorML ( https://github.com/opensensorhub/sensorml-editor ) و ویرایشگر SensorNanny – DrawMyObservatory ( https://github.com/ifremer/snanny -drawmyobservatory )، هیچ یک از آنها چنین انعطافپذیری را با توجه به طرح ابردادهای که پیادهسازی میشود، ارائه نمیکنند. مهمتر از آن، وصل کردن ساختارهای داده ارائه شده توسط اشخاص ثالث، یکی دیگر از عملکردهایی است که در ویرایشگرهای موجود پیاده سازی نشده است.
2.4. EDI، یک ویرایشگر فراداده مبتنی بر الگو
در توسعه GET-IT، ما باید از ایجاد ابرداده مطابق با RNDT و SensorML پشتیبانی میکردیم. ما همچنین می خواستیم از نمایه اصلی INSPIRE ISO 19115/19119 و همچنین انتقال آن توسط کشورهای مختلف پشتیبانی کنیم. علاوه بر این، ناهمگونی جامعه کاربر در RITMARE مستلزم درجه بالایی از سفارشی سازی، به ویژه با توجه به اطلاعات زمینه خاص پروژه است. از این رو، به منظور مدیریت چنین تنوعی، ما تصمیم گرفتیم از قالب خروجی خاص انتزاع کنیم و یک ابزار همه منظوره ایجاد کنیم که به طور مناسب با تعریف طرحواره ابرداده سفارشی، می تواند یک ابزار تألیف مبتنی بر وب را در مرورگر ارائه کند و به آن کمک کند. کاربر در ارائه ابرداده EDI ( http://edidemo.get-it.it ) [ 35]، ابزار ویرایش شرح داده شده در این مقاله، توسط یک برنامه جاوا اسکریپت سمت سرویس گیرنده تشکیل شده است که می تواند به طور مستقل رابط ایجاد کند و به منابع داده ای که در قالب مشخص شده است متصل شود. یک جزء سمت سرور، که به زبان جاوا نوشته شده است، ترجمه واقعی ورودی کاربر را در هر دو نمایش XML و RDF که توسط معماری ما پشتیبانی میشوند، اجرا میکند. با توجه به دانش ما، هیچ ابزار موجود عملکردهای یکسانی را با توجه به ناهمگونی پروفایل های ابرداده قابل پشتیبانی و قابلیت اتصال به منابع داده خارجی ارائه نمی دهد. حاشیه نویسی آگاه به معنایی فیلدهای فراداده یکی دیگر از ویژگی هایی است که در ابزارهای پیشرفته ویرایش ابرداده یافت نمی شود.
فرازبان EDI اجازه می دهد تا رفتار برنامه را برای یک پروژه یا دامنه خاص تنظیم کنید. از یک طرف، توسل به یک فرازبان برای بیان طرحواره فراداده هدف، امکان تطبیق کامل دومی را با زمینه برنامه کاربردی در دست فراهم می کند. از سوی دیگر، ادغام ساختارهای داده خارجی باعث سفارشیسازی مقادیر ویژگی ابرداده میشود که این طرحواره را پر میکند. در RITMARE، چنین سفارشی سازی با ایجاد الگوهایی شروع می شود که طرحواره های ابرداده مورد نیاز را بیان می کنند (در مورد ما، RNDT و SensorML). ثانیا، اطلاعات زمینه مرتبط با پروژه (به عنوان مثال، ساختار پروژه به عنوان مجموعه ای از مؤسسات و افراد و همچنین واژگان کنترل شده انتخاب شده) رسمی شده و به عنوان ساختارهای داده RDF در دسترس قرار گرفته است تا در قالب ها به آنها اشاره شود. به همین ترتیب، منابع داده خارجی قابل اجرا شناسایی شده اند و به ابزار ویرایش متصل شده اند. ادغام EDI با مجموعه GET-IT همچنین امکان محدود کردن تعداد فیلدهای فراداده مورد نیاز را با اعمال قراردادهای نامگذاری بر روی شناسههای منبع و استخراج اطلاعات در زمان آپلود داده فراهم میکند.
3. سناریوی مدیریت فراداده
اگرچه ما در ضمائم به برخی نکات فنی افراط میکنیم، این مقاله به این منظور نیست که یک نمای کلی از عملکردهایی که توسط EDI پیادهسازی شدهاند ارائه دهد (لطفاً به مستندات ارائه شده در GitHub برای مشاهده برنامهنویس در مورد ابزار مراجعه کنید). با این حال، سفارشی سازی طرحواره ابرداده هدف نیازی به اصلاح یک خط کد در برنامه ندارد. در واقع، EDI یک ویرایشگر ابرداده مبتنی بر الگو است که در اصل، هر طرح ابرداده مبتنی بر XML (یا مبتنی بر متن) را ایجاد میکند: مدیران سیستم میتوانند یک الگو را از ابتدا ایجاد کنند یا یکی از آنهایی را که با برنامه ارائه شده است سفارشی کنند. نمایه اصلی INSPIRE، RNDT، و SensorML نسخه های 1.0.1 و 2.0.0 را که بر اساس نمایه سبک وزن OGC SOS نمایه شده اند، پیاده سازی کنید [ 36]. در ادامه این بخش، ما بر روی ویژگیهایی تمرکز میکنیم که در راستای مشکلات تحقیقی که در مقدمه به آن اشاره شده است، امکان باز کردن مدیریت ابرداده به وب دادهها را فراهم میکند.
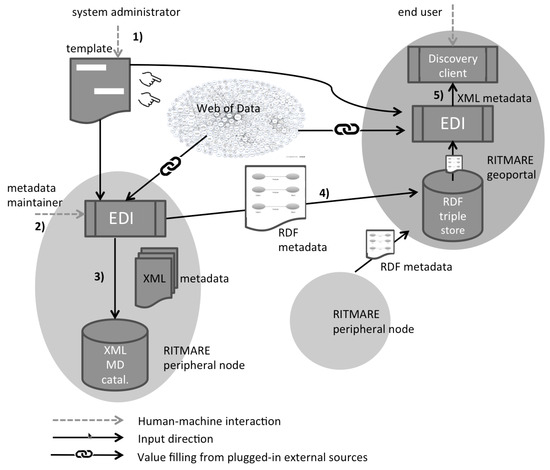
شکل 1 جریان اطلاعات تنظیم شده توسط ساختار قالب ما را نشان می دهد که شامل مراحل زیر است:
-
مدیر سیستم یکبار ایجاد یا سفارشی سازی الگو را به منظور تنظیم طرحواره ابرداده برای مورد استفاده خاص اجرا می کند. در این مرحله، منابع داده خارجی از Web of Data را میتوان وصل کرد: این به ویژگیهای ابرداده اجازه میدهد به منابع (افراد، نامهای نامگذاری، مقادیر کد و غیره) که توسط اشخاص ثالث مدیریت میشوند اشاره کنند. این الگو به عنوان ورودی EDI در گره های محیطی و مرکزی RITMARE عمل می کند.
-
نگهدارنده ابرداده یک گره جانبی RITMARE از رابط ویرایشی استفاده می کند که توسط EDI بر اساس تعاریف الگو ایجاد می شود و ابرداده (خروجی EDI) را ایجاد/ویرایش می کند. منابع دادهای که در فاز قبلی وصل شدهاند، قابلیتهای تکمیل خودکار را فعال میکنند که تلاش لازم برای ارائه ابرداده را تا حد ممکن کاهش میدهد.
-
رکوردهای فراداده در قالب XML توسط EDI برای درج در کاتالوگ ها و برنامه هایی که فرمالیسم خاص را درک می کنند، مانند گره های جانبی زیرساخت RITMARE، تولید می شوند. به طور معمول، موجودیت های اشاره شده در مرحله قبل اکنون به عنوان مقادیر ویژگی متن آزاد ارائه می شوند.
-
همتای معنایی آگاه توصیف ابرداده نیز توسط EDI تولید شده و به عنوان داده RDF در فروشگاه سه گانه پروژه (یعنی پایگاه داده برای داده های RDF) ذخیره می شود. رکورد همچنین میتواند در Web of Data منتشر شود و طبق همان فرمتها و پروتکلهایی که امکان اتصال به منابع داده خارجی در فاز اول را فراهم میکرد، قابل دسترسی است.
-
کاربر نهایی می تواند ژئوپورتال مرکزی RITMARE را از طریق مشتری کشف جستجو کند. هنگامی که رکوردهای فراداده طبق طرحواره فراداده XML درخواست می شوند، مجدداً توسط EDI بر اساس تعاریف الگو تولید می شوند. به طور خاص، مقادیر مشخصهای که از منابع دادهای که در الگو به آنها اشاره شده است، در زمان درخواست کاربر دوباره قابل دسترسی هستند. این اجازه می دهد تا یک توضیح XML حاوی مقادیر به روز ویژگی، همانطور که در ادامه این بخش توضیح داده شده است، ایجاد کنید.
3.1. موارد استفاده و الزامات
در این بخش، دو مورد استفاده را معرفی میکنیم که ممکن است اجرای آنها در صورتی سادهتر به نظر برسد، اما به محض اینکه الزامات جدید – کاملاً منطقی – ظاهر شوند، ممکن است بسیار چالشبرانگیزتر شوند. در هر دو مورد استفاده، نکته کلیدی انتخاب منابع داده ای است که از طریق ویرایشگر ابرداده قابل دسترسی هستند. لازم به ذکر است که اگرچه این موارد استفاده از الزامات مطرح شده توسط پروژه RITMARE سرچشمه میگیرند، اما در حوزه وسیعتر مدیریت ابردادههای مکانی قابل توجه هستند.
3.1.1. مشخص کردن نقاط تماس
شکل 2A قطعه فرم وب را نشان می دهد که به نگهدارنده ابرداده اجازه می دهد تا یک نقطه تماس را برای یک مجموعه داده بر اساس نمایه INSPIRE ISO 19115/19119 مشخص کند. به محض اینکه کاربر شروع به تایپ آدرس ایمیل می کند، رابط گزینه هایی را برای تکمیل قسمت فوق داده (b) پیشنهاد می کند. پس از انتخاب یکی از این موارد، فیلد زیر که نقطه تماس را توصیف می کند (یعنی فیلد حاوی نام سازمانی که فرد در آن کار می کند) به طور خودکار پر می شود (ج). همچنین، این فرم یک لیست کشویی برای انتخاب نقش خاصی که نقطه تماس ایفا می کند ارائه می دهد (در مثال، “ارائه دهنده منبع”). ممکن است کسی استدلال کند که با یک پایگاه داده رابطه ای پشتیبان در پشت صحنه، پیاده سازی دقیقاً همان عملکرد ساده است. اما اگر ساختارهای دادهای که برای تکمیل خودکار استفاده میشوند توسط شخص ثالث مدیریت شوند چه؟ اگرچه در این مورد استفاده آشکار نیست، اما این الزام (یعنی ادغام ساختارهای داده شخص ثالث در برنامه ویرایش ابرداده) بیشترین اهمیت را برای موارد استفاده زیر دارد. همچنین، در نظر بگیرید که وقتی برخی از فیلدهای فراداده درگیر در این مورد استفاده (مثلاً آدرس ایمیل مرتبط با فرد) تغییر می کند، چه اتفاقی می افتد. آیا باید به ابرداده های ناسازگاری که دارای مقادیر دارایی قدیمی هستند تکیه کنیم یا سعی کنیم آنها را به روز نگه داریم؟ در نظر بگیرید که چه اتفاقی می افتد زمانی که برخی از زمینه های فراداده درگیر در این مورد استفاده (مثلاً آدرس ایمیل مرتبط با فرد) تغییر می کند. آیا باید به ابرداده های ناسازگاری که دارای مقادیر دارایی قدیمی هستند تکیه کنیم یا سعی کنیم آنها را به روز نگه داریم؟ در نظر بگیرید که چه اتفاقی می افتد زمانی که برخی از زمینه های فراداده درگیر در این مورد استفاده (مثلاً آدرس ایمیل مرتبط با فرد) تغییر می کند. آیا باید به ابرداده های ناسازگاری که دارای مقادیر دارایی قدیمی هستند تکیه کنیم یا سعی کنیم آنها را به روز نگه داریم؟
3.1.2. کلمات کلیدی از واژگان کنترل شده
قطعه فرم وب در شکل 2 B به نگهدارنده ابرداده اجازه می دهد تا کلمات کلیدی را برای توصیف یک مجموعه داده ارائه دهد که، همانطور که اغلب در ابرداده های مکانی اتفاق می افتد، به یک واژگان کنترل شده خاص (یا مجموعه ای از آنها) محدود می شوند. به عنوان مثال، در فراداده مبتنی بر INSPIRE، فهرست کدهای ارائه شده توسط استانداردهای مرجع ISO با مواردی که توسط دستورالعمل تعریف شده است تکمیل شده است (به عنوان مثال، فهرست کد حاوی موضوعات INSPIRE). همچنین، دامنههای کاربردی متمایز ممکن است به واژگان کنترلشده بیشتری که مخصوص یک CoP معین هستند تکیه کنند. در مورد استفاده، فهرست کد نامهای استاندارد آب و هوا و پیشبینی در مجموعه جامع اصطلاحنامههای تعریف شده توسط پروژه SeaDataNet ( http://www.seadatanet.org/ ) انتخاب شده است.) و از طریق سرور واژگان NERC ( http://vocab.nerc.ac.uk/ ) [ 37 ، 38 ] ارائه می شود و برای یافتن پیشنهاداتی که به نگهدارنده ابرداده (b) پیشنهاد می شود، استفاده می شود. بسته به انتخاب او، فیلدهای جانبی که کلمه کلیدی را توصیف می کنند به طور خودکار در (c) پر می شوند.
همچنین در اینجا، یک پایگاهداده رابطهای پشتیبانی میتواند تکمیل خودکار کلمات کلیدی را پایهگذاری کند. اما در مورد تکامل اجتناب ناپذیر چنین اصطلاحاتی چطور؟ برای مدیران سیستم ناخوشایند است که این منبع داده را کپی کنند و سعی کنند آن را به نسخه معتبر به روز نگه دارند. در عوض، بهتر است رفتار برنامه را مستقیماً به منبع داده فوق الذکر پیوند دهید. اگر در مقطعی، عملکرد «یافتن داراییهای مشابه» یا «ترجمه این رکورد ابرداده» درخواست شود، چه؟ در اکتشاف سنتی مبتنی بر فراداده ISO 19136، پیادهسازی بسط پرس و جو و قابلیتهای چند زبانه یک کار دلهرهآور است. در عوض، انجام این کار با ابرداده مبتنی بر URI که توسط برنامه ما تولید میشود، ساده است.
در بخش بعدی، مؤلفههای قالب را بررسی میکنیم که امکان تحقق این موارد استفاده را فراهم میکنند و همچنین مؤلفههایی را که ترجمه ورودی کاربر را در هر یک از قالبهای دادهای که ما استفاده میکنیم، تنظیم میکنند، به ترتیب برای نمایش ابرداده و برای رمزگذاری XML دومی معرفی میکنیم.
3.2. ساختار قالب
تمام فعالیتهای مربوط به مدیریت ابرداده، مانند ویرایش فیلدها و ایجاد نمایشهای RDF و XML از توضیحات فراداده، توسط الگوی EDI، در قالب XML نیز هدایت میشوند، که وابسته به طرح خاصی است که توسط یک معین مورد نیاز است. پروژه (به عنوان مثال، RNDT، SensorML، و غیره). این الگو ویژگیهای فرادادههایی را مشخص میکند که باید به ویجتها در رابط ویرایش تبدیل شوند: برخی از این ویژگیها مستقیماً از مقررات ناشی میشوند (به عنوان مثال، اجباری بودن یا نبودن یک فیلد مشخص، تعدد مرتبط و غیره)، در حالی که ویژگیهای دیگر به زمینه بستگی دارد. اطلاعات مرتبط با پروژه خاص (مانند واژگان کنترل شده مورد استفاده، پرس و جوهایی که به رابط اجازه می دهد مقادیر پیش فرض را برای فیلدها پیشنهاد کند و غیره). البته، این الگو همچنین اطلاعات مورد نیاز برای ترجمه به یک سند XML معتبر را مشخص می کند. لازم به ذکر است که طرحواره های XML که در قالب فرمت فوق داده خاص قرار دارند، قبلاً حاوی برخی از این اطلاعات هستند. با این حال، به دلایل مختلف، استفاده از این مشخصات برای بیان ترکیب رابط کاربری دشوار است. اولاً، بسیاری از محدودیتها مستقیماً از طرحواره پایه ناشی نمیشوند، بلکه بیشتر از نمایه خاص دومی ناشی میشوند: به عنوان مثال، هر دو INSPIRE و RNDT برای رمزگذاری به ISO 19136 متکی هستند، اما هر کدام دارای فیلدهای اجباری، مقادیر تجویز شده و غیره هستند. ثانیاً، جالبترین جنبهها در این تمرین یکپارچهسازی، مانند توسل فراگیر به ساختارهای داده آگاه از معناشناسی و تولید قالبهای خروجی متعدد، در طرحوارههای مبدأ (و نه هدف) کدگذاری شدهاند.
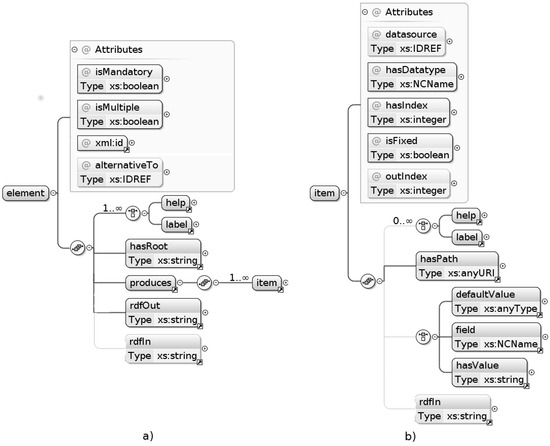
در نتیجه، یک فرازبان برای بیان این ویژگی ها ایجاد و به عنوان طرحواره XML کدگذاری شده است. شکل 3 مؤلفه های کلیدی را نشان می دهد که در قالب ها برای تعریف یک فیلد ابرداده استفاده می شود. به طور خاص، تگ عنصر (توجه داشته باشید که برای جلوگیری از ابهام با اجزای عنصر الگوها ، عبارت «برچسب» را به «عنصر» ترجیح میدهیم ) در شکل 3 a، فیلدهای متادیتا را تعریف میکند: ویژگیهای تعریفشده یک xml:id منحصربهفرد برای آن ارائه میکنند، مشخص میکند که آیا اجباری یا اختیاری است و تعدد مرتبط را اعلام کنید. همچنین، فیلد را می توان به عنوان جایگزین دیگری اعلام کرد. محتوای عنصربرچسبها شامل نشانههای بصری چندزبانهای هستند که میتوان در رابط ( برچسب و تگهای راهنما ) و مکان XPath که در آن چندین نمونه از فیلد ابرداده روت میشوند ( تگ hasRoot ) دیده میشوند. تولید برچسب شامل مجموعه ای از موارد است که نشان دهنده گره های XML منفرد است که باید برای فیلد فوق داده خاص ایجاد شود. در نهایت، تگ rdfOut باعث ایجاد نمایش ابرداده واقعی می شود تا در فروشگاه سه گانه RDF ذخیره شود. برعکس، rdfIn را تگ کنیددرایوهای استخراج مقادیر فیلد ابرداده در هنگام ایجاد مجدد توضیحات ابرداده مطابق طرحی که الگو قرار است پیاده سازی کند. این تگ حاوی یک پرس و جو SPARQL است که مقادیر ویژگی های لازم را از فروشگاه سه گانه محلی بازیابی می کند. از آنجایی که چندین منبع داده ممکن است در ایجاد فراداده نهایی کمک کنند، این تعریف پرس و جو فقط جزئی است زیرا فاقد الگوهای سه گانه (یعنی محدودیت های پرس و جو) است که باید با منابع داده از راه دور تعریف شده مطابقت داشته باشند. در ادامه این جنبه روشن خواهد شد.
در واقع، همانطور که در بالا پیشبینی شد، تعاریف عناصر میتوانند باعث ایجاد چندین گره XML (عناصر و ویژگیهای XML) در فایل فراداده هدف شوند، که هدف تگ موردی است که میخواهیم توضیح دهیم. این تمایز برای قالب هدف موارد استفاده ما بسیار ضروری است زیرا در فراداده ISO (شکل مرجع که ساختار الگو بر اساس آن است) کم نیست که مقادیر واقعی انتخاب شده توسط نگهدارنده ابرداده در چندین مکان به همراه موارد ثابت درج شود. مقادیر در موقعیت های دیگر در درخت فرعی XML خاص. در میان سایر موارد، این رفتار برای کلمات کلیدی گرفته شده از واژگان کنترل شده آشکار است، جایی که انتخاب یک عبارت واحد توسط نگهدارنده ابرداده، شش گره XML مختلف را در سند نهایی ایجاد می کند (نگاه کنید بهضمیمه D برای مثالی از آن). معنای تگ آیتم به شرح زیر است: ویژگیهای hasIndex و outIndex به ترتیب ترتیب فیلدها را در رابط و در سند خروجی مشخص میکنند. مشخصه isFixed تعیین می کند که آیا یک ویجت باید در رابط ویرایش ایجاد شود (در صورت تنظیم روی “نادرست”) یا اینکه آیا می توان فیلد ابرداده را برای کاربر نهایی شفاف نگه داشت زیرا مقدار آن از قبل مشخص است. سایر ویژگیهای کلیدی hasDatatype است که محدوده مقادیر معتبر مورد را مشخص میکند و منبع داده ، انعطافپذیری فوقالذکر را در تعریف منابع داده خارجی فراهم میکند. برچسب های موجود در آیتم های فردیعلاوه بر نشانههای بصری که قبلاً در تعریف تگ عنصر پیدا کردهایم ، مقدار خاص (زمانی که مشخصه isFixed روی “true” تنظیم شود)، یک پیشفرض یا متغیر مربوطه (برچسب فیلد ) که توسط تگ مربوطه نشان داده شده است، تعریف میشود. منبع داده . تگ hasPath که XPath گره XML را که باید ایجاد شود را مشخص می کند، جزء ضروری تعاریف آیتم است. در نهایت، یک تگ اختیاری rdfIn تکمیل کننده پرس و جو SPARQL در تگ rdfIn است که برای عنصر به عنوان یک کل تعریف شده است. در واقع هر عنصرتعریف موجود در الگو، پرس و جوی SPARQL را برای بازیابی مقادیر ویژگی متادیتا که مورد نیاز آیتم مجزا s است، تعریف می کند. توجه داشته باشید که از آنجایی که هر یک از اینها ممکن است به نقطه پایانی متفاوتی متکی باشد، پرس و جوهای SPARQL که از الگوهای EDI کامپایل شده اند، طبق تعریف، فدرال هستند. پیوست A شامل تعاریف الگو است که دو مورد استفاده معرفی شده در این بخش را اجرا می کند.
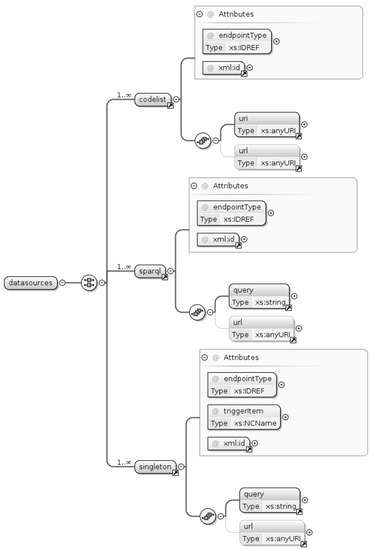
اکنون ما بر تعریف منابع داده تمرکز می کنیم، ویژگی اصلی برای استخراج مدیریت غیرمتمرکز ابرداده. در واقع، هر دو مورد استفاده تعریف شده در بخش 3.1 شامل منابع داده است: مورد اول توسط فروشگاه سه گانه ای که ما برای مدیریت اطلاعات زمینه در پروژه RITMARE راه اندازی کردیم، تشکیل شده است، در حالی که مورد دوم توسط پروژه SeaDataNet ارائه شده است. اگر چه توسط طرف های مختلف مدیریت می شود، این منابع داده را می توان به صورت یکپارچه، از طریق یک نقطه پایانی HTTP، دسترسی داشت، زیرا پروتکل دسترسی یکسان (SPARQL) و فرمت داده یکسان (RDF) را به اشتراک می گذارد. البته، محتوای هر یک از اینها ممکن است مربوط به طرحواره هایی باشد که با فرمالیسم های مختلف ایجاد شده اند (مانند RDFS یا OWL [ 39 ، 40]]) و با اهداف مختلف، اما اشتراک فرمت پایه امکان مکانیزم های پرس و جوی تک صدایی را فراهم می کند. در واقع، هر دو منبع داده به طور یکسان توسط EDI مدیریت می شوند و هر کدام می توانند هدف تعاریف منبع داده در قالب باشند. شکل 4 سه دسته مختلف از منابع داده را نشان می دهد که توسط الگوها پشتیبانی می شوند. همه آنها یک ویژگی xml:id برای شناسایی منحصر به فرد و یک ویژگی endpointType به اشتراک می گذارند که به مدیران اجازه می دهد تا با مرتبط کردن پارامترهای درخواست صحیح، فروشگاه های سه گانه مختلف را وصل کنند. آنها همچنین آدرس اینترنتی را به اشتراک می گذارندبرچسبی که امکان تعریف نقاط پایانی را برای هر منبع داده فراهم می کند (یعنی پرس و جوهای آدرس های وب باید به آنها ارسال شوند). این سه دسته نیز در زیر توضیح داده شده است:
-
Codelist: این دسته از منابع داده فرض میکنند که تگ uri تودرتو به یک اصطلاحنامه SKOS (یک واژگان کنترلشده که بر اساس این هستیشناسی خاص کدگذاری شده است) اشاره میکند و یک پرس و جو استاندارد را برای تطبیق مقادیر کد اجرا میکند. این نوع منبع داده است که امکان ایجاد لیست کشویی برای انتخاب نقش یک نقطه تماس در شکل 2 a را فراهم می کند.
-
Sparql: این دسته امکان اجرای پرس و جوهای عمومی SPARQL را فراهم می کند. این در موارد استفاده مثال مفید است زیرا نقطه پایانی SeaDataNet اصطلاحنامههای سازگار با SKOS را ارائه میدهد که ساختار آن کمی با آنچه در نوع منبع داده قبلی مورد انتظار بود متفاوت است. هر دو مورد استفاده شامل یک منبع داده از این نوع هستند.
-
Singleton: پرس و جوهایی را اجرا می کند که برای بازگرداندن یک رکورد مورد نیاز هستند (معمولاً در نتیجه تماس قبلی با منبع داده از نوع قبلی برای ارائه عملکردهای تکمیل خودکار). هر دو مورد استفاده شامل یک منبع داده از این نوع هستند.
به طور خاص ، موارد استفاده در بالا برای ساختارهای داده به ترتیب نشان دهنده جامعه کاربر و واژگان کنترل شده است. در صورت دسترسی، این آدرس ها یک فرم وب برای ارسال پرس و جو به نقطه پایانی ارائه می دهند. با ارائه پرس و جو به عنوان پارامتر درخواست GET یا POST، امکان صدور پرس و جو به صورت خودکار وجود دارد. به عنوان مثال، پرس و جوی استفاده شده در مورد استفاده «تعیین نقاط تماس» (تطابق با آدرس ایمیل نقاط تماس احتمالی) در فهرست 1 نشان داده شده است.
فهرست 1: جستجوی SPARQL برای موارد استفاده “مشخص کردن نقاط تماس”
1 PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> 2 PREFIX vcard: <http://www.w3.org/2006/vcard/ns#> 3 PREFIX foaf: <http://xmlns.com/foaf/0.1/> 4 SELECT ?contact ?label 5 FROM <http://ritmare.it/rdfdata/lotrx> 6 WHERE { 7 ?contact rdf:type foaf: شخص . 8 ?تماس کارت مجازی: ایمیل ?برچسب . 9 FILTER( REGEX( STR(?label)، "$search_param"، "i") ) 10 ) 11 } 12 ORDER BY ASC(?label)
ساختارهای داده ای که ویژگی های ویژگی را از طرحواره FOAF ( http://xmlns.com/foaf/spec/ ) و کارت مجازی ( https://www.w3.org/TR/vcard-rdf/ ) جستجو می کنند: اولین برای مدلسازی محققان و مؤسسات شرکتکننده در RITMARE استفاده میشود، دومی ویژگیهای ریزدانهای را برای جزئیات اولی ارائه میدهد. به منظور ارائه دادههای غیر حساس به کاربران سایت آزمایشی EDI برای بازی، ساختارهای داده FOAF نمونهای را برای شخصیتهای ارباب حلقهها و هابیت ایجاد کردیم.. با درج پرس و جو در فرم وب ارائه شده توسط اولین نقطه پایانی، می توان پرس و جو را قبل از استقرار الگو آزمایش کرد: برای انجام این کار، جای جای “$search_param” باید با الگوی جستجوی واقعی جایگزین شود، درست مانند شکل 2 . ب سپس، پرس و جو URI ها و آدرس های ایمیل افراد مطابق با الگو را برمی گرداند.
یک پرس و جو دوم، نشان داده شده در فهرست 2، به برنامه اجازه می دهد تا فیلد “Institute” را در قطعه رابط نشان داده شده در شکل 2 به صورت خودکار تکمیل کند:
فهرست 2: جستجوی SPARQL برای موارد استفاده “مشخص کردن نقاط تماس”
1 کارت مجازی PREFIX: <http://www.w3.org/2006/vcard/ns#> 2 PREFIX foaf: <http://xmlns.com/foaf/0.1/> 3 SELECT ?inst 4 FROM <http:// /ritmare.it/rdfdata/lotrx> 5 WHERE { 6 <$search_param> vcard:org ?org. 7 ?org foaf:name ?inst . 8 FILTER(LANG(?inst) = "en") 9 }
با جایگزینی هر یک از URI های بازگردانده شده توسط اولین پرس و جو به جای جای “$search_param”، نام سازمان مربوطه برگردانده می شود.
به طور مشابه، مورد دوم استفاده، «کلمات کلیدی از واژگان کنترلشده»، به پرسشهای نشاندادهشده در فهرستهای زیر متکی است. فهرست 3 برای تطبیق ورودی کاربر با واژگان نامهای استاندارد آب و هوا و پیشبینی P07 ارائه شده توسط SeaDataNet استفاده میشود و این محدودیت در خط 6 قابل مشاهده است. این را کنار بگذاریم، پرس و جو بسیار شبیه به فهرست 1 است.
فهرست 3: پرس و جو SPARQL برای موارد استفاده “کلمات کلیدی از واژگان کنترل شده”
1 PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> 2 PREFIX skos: <http://www.w3.org/2004/02/skos/core #> 3 SELECT ?concept ?label 4 WHERE { 5 ?concept rdf:type skos:Concept. 6 <http://vocab.nerc.ac.uk/collection/P07/current/> 7 skos:member ?concept. 8 ?concept skos:prefLabel ?label . 9 FILTER(LANG(?label) = "en" && 10 REGEX( STR(?label), "$search_param", "i") ) 11 }
پرس و جو در فهرست 4 نام اصطلاحنامه مورد بررسی و تاریخ انتشار مرتبط را استخراج می کند. از آنجایی که قالب مقدار داده اخیر یک مهر زمانی کامل است، بند BIND در خط 8 قطعه ای را استخراج می کند که با فرمت تعیین شده yyyy-mm-dd مطابقت دارد و این مقدار را به متغیر ?date مرتبط می کند :
فهرست 4: پرس و جو SPARQL برای موارد استفاده “کلمات کلیدی از واژگان کنترل شده”
1 PREFIX skos: <http://www.w3.org/2004/02/skos/core#> 2 PREFIX dct: <http://purl.org/dc/terms/> 3 SELECT ?label ?date 4 WHERE { 5 ?voc skos:member <$search_param> . 6 ?voc skos:prefLabel ?label . 7 ?voc dct:date ?ts . 8 BIND( STRBEFORE(?ts, " ") AS ?تاریخ) 9 }
تعاریف الگو برای همه منابع داده را می توان در ضمیمه B و ضمیمه C یافت .
3.3. تولید و ذخیره متادیتا
هنگامی که ابرداده به مؤلفه سمت سرور EDI ارسال می شود، خروجی XML تجویز شده با ایجاد گره های XML به دنبال عبارات XPath تعریف شده توسط تگ های hasRoot و hasPath در الگو ایجاد می شود. علاوه بر این، تگ rdfOut تعریف شده توسط هر عنصر اجازه می دهد تا مشخص شود کدام سه RDF باید تولید و در فروشگاه سه گانه درج شوند. در واقع، در طول ویرایش ابرداده، EDI مقادیر متن آزاد را که برای تولید گرههای خاص XML مورد نیاز است (برای فیلدهایی که بهعنوان ثابت تعریف نشدهاند) نمایش میدهد، اما در زیر سرپوش، URIهای انتخاب شده را ردیابی میکند. توسط کاربر به منظور ایجاد یک قطعه داده RDF که همان معنایی را منتقل می کند. به عنوان مثال، rdfOutبرچسب در اولین عنصر تعریف شده در ضمیمه A (اجرای اولین مورد استفاده، “مشخص کردن نقاط تماس”) در فهرست 5 نشان داده شده است.
فهرست 5: محتوای تگ rdfOut مرتبط با استفاده از «مشخص کردن نقاط تماس»
1 PREFIX dcat: <http://www.w3.org/ns/dcat#> 2 PREFIX vcard: <http://www.w3.org/2006/vcard/ns#> 3 INSERT 4 { 5 <$id_1_uri > dcat:contactPoint [ 6 rdf:type vcard:Individual ; 7 کارت مجازی:hasUID <$resp_1_uri> ; 8 کارت مجازی:hasRole <$resp_3_uri> 9 ] . 10 } 11 WHERE {}
این شناسه (URI) مجموعه داده توصیف شده (با عنوان “$id_1_uri” نشان داده شده است) را به یک کارت مجازی: ساختار داده فردی از طریق ویژگی contactPoint از فضای نام DCAT مرتبط می کند: این ساختار داده از شناسه نقطه تماس و آن تشکیل شده است. نقش خاصی که او پوشش می دهد (هر دو، دوباره به عنوان URI بیان می شوند). همه درخواستهای این بخش حاوی متغیرهایی هستند که از قانون تولید <element_id>_<item_index>[_uri] پیروی میکنند. آنها زمان اجرا را با مقادیر واقعی وارد شده توسط نگهدارنده ابرداده جایگزین می کنند. به عنوان مثال، مکان نگهدار <$resp_1_uri> با URI مرتبط با اولین مورد در عنصری که xml:id آن است، جایگزین میشود.“resp” است (یعنی URI فرد انتخاب شده).
لازم به ذکر است که این سهگانهها با گرههای XML که در فراداده ISO ایجاد میشوند، مطابقت یک به یک ندارند، ویژگیای که در تگ rdfOut عنصر دوم ( پیادهسازی مورد استفاده، «کلمات کلیدی از واژگان کنترل شده»)، در فهرست 6 نشان داده شده است.
فهرست 6: محتوای برچسب rdfOut مرتبط با موارد استفاده “کلمات کلیدی از واژگان کنترل شده”
1 PREFIX dcat: <http://www.w3.org/ns/dcat#> 2 INSERT 3 { 4 <$id_1_uri> dcat:keyword <$contr_voc_1_uri> . 5 } 6 WHERE {}
در این مورد، یک سه گانه منفرد برای ارائه معنای شش موردی که در عنصر مربوطه در الگو تعریف شده اند، کافی است. در سطح نحوی صرف، این تفاوت عمده بین رویکرد ما و هر یک از ترجمههای ممکن یک به یک فراداده INSPIRE به RDF است، مانند آنچه در [ 41 ، 42 ] است. بخش 4 به تشریح مفاهیم عمیق رویکرد ما در مدیریت ابرداده میپردازد. در حال حاضر، توجه به این نکته کافی است که این عمل عاملی است که برای عملکردهای جدیدی که در بخش بعدی ترسیم میکنیم، میباشد.
در واقع، هر زمان که نمایش XML یک رکورد ابرداده درخواست شود، الگو دوباره تجزیه می شود تا مقادیر ویژگی را در زمان درخواست ابرداده جستجو کند. نقش تگهای rdfIn در الگو این است: به عنوان مثال، use case «مشخص کردن نقاط تماس» سه مورد از این تگها را تعریف میکند ( پیوست A را ببینید ) زیرا بازیابی مقادیر دادههای لازم ممکن است شامل حداکثر سه منبع داده متمایز باشد. ، نقطه پایانی محلی که ما برای ذخیره ابرداده استفاده می کنیم، نقطه پایانی که اطلاعات مربوط به نقاط تماس (و سازمان ها) را میزبانی می کند، و در نهایت نقطه پایانی که لیست کدهایی را ذخیره می کند که نقش های موجود برای نقطه تماس را تعریف می کند (فقط دو نقطه پایانی در مثال کار شده ما ). فهرست 7 پرس و جوی را نشان می دهد که از این اطلاعات کامپایل شده است:
فهرست 7: پرس و جوی SPARQL از تعاریف برچسب rdfIn در مورد استفاده “مشخص کردن نقاط تماس” نشات می گیرد.
1 PREFIX dcat: <http://www.w3.org/ns/dcat#> 2 PREFIX vcard: <http://www.w3.org/2006/vcard/ns#> 3 PREFIX foaf: <http:/ /xmlns.com/foaf/0.1/> 4 PREFIX skos: <http://www.w3.org/2004/02/skos/core#> 5 SELECT ?1 ?2 ?3 6 WHERE { 7 <$id_1_uri> dcat:contactPoint ?struct . 8 ?struct vcard:hasUID ?contact . 9 ?struct vcard:hasRole ?role . 10 SERVICE <http://sparql.get-it.it/> { 11 ?contact vcard:email ?1 . 12 ?contact vcard:org ?org . 13 ?org foaf:name ?2 . 14 } 15 SERVICE <http://sparql.get-it.it/> { 16 ?role skos:prefLabel ?3 . 17 } 18 FILTER( LANG(?2) = "en" && LANG(?3) = "en" ) 19 }
نام متغیرها در عبارت طرح ریزی، مقادیر عددی هستند که آیتم های متمایز عنصر خاص را مشخص می کنند . پرس و جو قرار است همه کارت های مجازی مربوط به دارایی خاص را در ابرداده های ذخیره شده محلی بازیابی کند. سپس URI هایی که شخص و نقش او را به عنوان یک نقطه تماس شناسایی می کنند، در جستارهای فدرال که توسط بندهای SERVICE نشان داده شده است، استفاده می شود. هر تاپل در مجموعه نتیجه، تکه های داده XML مربوطه را همانطور که در الگو مشخص شده است، تولید می کند.
به طور مشابه، استفاده از «کلمات کلیدی از واژگان کنترلشده» مستلزم تشکیل سرور واژگان NERC به منظور بازیابی جزئیات ضروری کلمه کلیدی است:
فهرست 8: محتوای تگ rdfIn مرتبط با موارد استفاده “کلمات کلیدی از واژگان کنترل شده”
1 PREFIX dcat: <http://www.w3.org/ns/dcat#> 2 PREFIX skos: <http://www.w3.org/2004/02/skos/core#> 3 PREFIX dct: <http ://purl.org/dc/terms/> 4 SELECT ?1 ?2 ?3 5 WHERE { 6 <$id_1_uri> dcat:keyword ?keyw . 7 SERVICE <http://vocab.nerc.ac.uk/sparql/> { 8 ?keyw skos:prefLabel ?1 . 9 ?thes skos:member ?keyw . 10 ?thes skos:prefLabel ?2 . 11 ?thes dct:date ?timestamp . 12 } 13 BIND( STRBEFORE(?timestamp, " ") AS ?3) 14 }
پرس و جوهایی که ما با ترکیب محتوای تگ های rdfIn گردآوری می کنیم تا حدی با مواردی که برای تعریف منبع داده ارائه شده اند اضافی هستند ، اما در حال حاضر، ما ابزار مناسبی برای بیان این پرسش ها به صورت یکپارچه پیدا نکردیم.
4. بحث
در این بخش، بررسی میکنیم که آیا شیوههای مدیریت ابرداده که در بخشهای قبلی پیشنهاد شدهاند، به درستی به مسائل و خواستههای ارائهشده در بخش 3.1 میپردازند یا خیر . علاوه بر این، ما ایده های بیشتری در مورد چگونگی گسترش قابلیت های ژئوپورتال های پیشرفته ارائه می دهیم.
4.1. اطمینان از سازگاری فراداده
اولین مورد استفاده، مشکلات احتمالی ناهماهنگی را مطرح می کند که ممکن است به محض تغییر یکی از مقادیر فیلد موجود در ابرداده ایجاد شود. هیچ روش تایید شده ای برای انعکاس (به طور خودکار) چنین تغییراتی در توضیحات فراداده که دارایی ها را حاشیه نویسی می کند وجود ندارد: به طور معمول، مداخله انسانی برای بازگرداندن توضیحات فراداده به یکپارچگی لازم است. در عوض، تولید XML به تعویق افتاده ذاتی شرح داده شده در بخش 3.3قرار است مقادیر به روز دارایی را برگرداند (البته تا حدی که منبع داده خاص به روز نگه داشته شود). توجه داشته باشید که این قابلیت با متادیتای استاندارد INSPIRE مبتنی بر ISO و همچنین با ترجمه یک به یک آنها به RDF قابل دستیابی نیست. طبق دانش ما، هیچ تکنیک مدیریت ابرداده موجود نمی تواند به به روز رسانی خودکار فیلدهای ابرداده، به ویژه آنهایی که شامل داده های ارائه شده توسط اشخاص ثالث است، دست یابد.
4.2. دارایی های پیشنهادی
اطلاعات جانبی که می تواند از منابع داده های ناهمگن استخراج شود می تواند برای گسترش دامنه کاربرد یک فرد ارزشمند باشد. به عنوان مثال، URI یک نقطه تماس در توضیحات فراداده ممکن است به افرادی در شبکه اجتماعی او منجر شود (مثلاً با foaf:knows نشان داده شده استارزشهای دارایی) و اینها ممکن است به داراییهای مربوطه اشاره کنند که با معیارهای کشف مطابقت ندارند (مثلاً به دلیل مسائل ناهمگونی معنایی). علاوه بر این، هنگامی که کاربر دسترسی به ژئوپورتال احراز هویت شد، نتایج کشفی که توسط افراد در شبکه اجتماعی خودش مرتبط تلقی شده است (به دلیل مشاهده، دانلود، نشانک گذاری و غیره دارایی های مربوطه) را می توان بر اساس جستجو پیشنهاد کرد. تجزیه و تحلیل لاگ هر دوی این شبکههای اجتماعی (محل تماس و کاربر که جستوجو را انجام میدهد) میتوانند با تطبیق موضوعات تحقیقاتی ترجیحی افراد درگیر (که بهعنوان مقادیر ویژگی foaf:topic_interest بیان میشوند) در فهرست نهایی قرار گیرند .
4.3. گسترش کوئری ها
مزایای تکیه بر اطلاعات به دست آمده از وب داده زمانی که منابعی را در نظر می گیریم که از نظر معنایی غنی تر هستند و با منابع دیگر از همان نوع مرتبط هستند، مانند اصطلاحات در واژگان کنترل شده، آشکارتر می شود. در هنگام حدس و گمان در مورد عملکردهای «یافتن دارایی های مشابه» یا «ترجمه این رکورد ابرداده»، از مواردی استفاده کنید که «کلمات کلیدی از واژگان کنترل شده» به این موضوع اشاره دارد. اولین مورد را می توان بر اساس ساختار (چند) سلسله مراتبی اصطلاحنامه های SKOS پیاده سازی کرد زیرا URI یک اصطلاح را می توان برای استخراج عبارات کلی تر، خاص تر، معادل تر یا ساده تر مرتبط استفاده کرد. اینها به نوبه خود می توانند مجموعه نتایج یک کشف را با تطبیق URIهای این اصطلاحات (یا نمایش متن آنها در کشف سنتی) با ابرداده های فهرست افزایش دهند. هنگامی که ابرداده به صورت XML یا متن کدگذاری می شود، قابلیت دوم فقط می تواند از ابزارهای ترجمه خودکار استفاده کند. در عوض، URI اصطلاحات در واژگان کنترل شده اصولاً از نظر زبانی خنثی هستند، اما خود اصطلاحات می توانند ترجمه به چندین زبان را در خود جای دهند. از این رو، یک کلمه کلیدی از یک واژگان کنترل شده را می توان به سادگی به هر یک از زبان های پشتیبانی شده ترجمه کرد.
4.4. بهره برداری از اطلاعات روزنامه
خدمات Gazetteer ابزار اصلی برای پر کردن شکاف بین جستجوهای وب مکانی و سنتی (به عنوان مثال، مبتنی بر متن) است. حتی اگر موارد استفاده ارائه شده در این مقاله به ابرداده هایی اشاره دارد که مفهوم جغرافیایی ندارند، توضیحات فراداده ما مجموعه کامل فراداده INSPIRE را شامل می شود که شامل گستره جغرافیایی و زمانی است (به عنوان ساختارهای داده مطابق با طرحواره ها در [41] بیان می شود ) . با تشریح ویژگی های قبلی، خدمات روزنامه روزنامه مبتنی بر RDF، مانند GeoNames ( http://www.geonames.org/) را می توان برای “ترجمه” پرس و جوهای مبتنی بر متن مانند “ستون شوری آب در 100 کیلومتری غرب ناپل” به جستجوی مکانی مربوطه استفاده کرد. در عوض، ژئوپورتالها معمولاً از کاربر میخواهند مختصات را ارائه کند یا یک مستطیل (“جعبه مرزی”) روی نقشه بکشد. علاوه بر این، نامها معمولاً به عنوان یک سلسله مراتب با توجه به ویژگیهای مهار سازماندهی میشوند، بنابراین معیارهای بسط پرس و جو را بیشتر میکنند.
4.5. پیشنهادات بیشتر برای غنی سازی معنایی
موارد استفاده در بخش 3.1 مستلزم ساختارهای داده ای است که افراد را نشان می دهد، کدگذاری شده بر اساس طرحواره های FOAF و کارت مجازی، و توصیف اصطلاحات در واژگان کنترل شده، که به عنوان ساختارهای داده SKOS بیان می شود. با این حال، حتی نگاهی گذرا به نمودار ابر دادههای باز پیوندی ( http://lod-cloud.net/) می تواند تعدادی از منابع داده قابل اجرا را برای غنی سازی ابرداده با اطلاعات معنایی پیشنهاد کند. ما تصدیق می کنیم که تکیه بر قابلیت اطمینان منابع داده ای که در وب از داده ها وجود دارد، بنابراین تحت کنترل مستقیم مدیر سیستم نیست که EDI را برای یک پروژه خاص سفارشی می کند، یک جهش ایمانی بزرگ است. با این حال، به نظر ما، در درازمدت بهتر است به منابع داده تثبیت شده مراجعه کنیم تا اینکه به ساختارهای داده اختصاصی که مستعد نادیده گرفته شدن به محض توقف پروژه یا ابتکار خاصی هستند، تکیه کنیم. لطفاً برای یک نمای کلی در مورد ساختارهای داده RDF که ما در پروژه RITMARE به منظور زمینی کردن مدیریت ابرداده ادغام کردیم، به [ 43 ] مراجعه کنید.
5. نتیجه گیری و کار آینده
در این مقاله، ما سناریویی را ارائه کردیم که روششناسی مدیریت ابرداده را که برای پروژه RITMARE تنظیم شده است، نشان میدهد. این وابسته به یک برنامه مشتری-سرور است که رابط ویرایش را برای یک طرح ابرداده معین ارائه می کند و از تولید توضیحات XML و RDF بر اساس داده های درج شده توسط نگهدارنده ابرداده مراقبت می کند. این ابزار، EDI، یک بسته FOSS است (تیم RITMARE SP7 بخشی از شبکه GEOforALL است: http://www.geoforall.org/) که می تواند به راحتی با نیازهای پروژه های دیگر سفارشی شود. اگر انطباق با یکی از نمایه های پشتیبانی شده برای یک زمینه کاربردی خاص کافی باشد، می توان از نرم افزار خارج از جعبه استفاده کرد. مرحله دوم در سفارشیسازی ابزار، شخصیسازی الگو است که رفتار آن را تنظیم میکند: این توسط طرحواره XML مرتبط با زبان الگو، که ملزومات آن در این کار ارائه شده است، کمک میکند. در آینده، ممکن است الگوهای بیشتری به توزیع GitHub اضافه شود ( https://github.com/SP7-Ritmare) به عنوان خروجی تلاش جامعه. در نهایت، منابع داده خارجی را میتوان به راحتی برای سفارشیسازی کامل تجربه ویرایش ابرداده وصل کرد: ما نمونهای از توسل به منابع داده اختصاصی برای توصیف یک پروژه (به عنوان مثال، توصیف کاربران، مؤسسات، نقشها و غیره) و ادغام شخص ثالث بودیم. ساختارهای داده به عنوان نقاط پایانی SPARQL ارائه شده است (به عنوان مثال، برای استفاده از واژگان کنترل شده در استفاده توسط CoP خاص).
این ویژگی با هدف تقویت یک پارادایم غیرمتمرکز برای مدیریت ابرداده است: در چارچوب ما، مقادیر مشخصه از ساختارهای داده (احتمالاً راه دور) که با اصلی خاص مرتبط هستند، بازیابی میشوند. به عنوان مثال، آدرس ایمیل یک نقطه تماس مستقیماً از توضیحات FOAF او گرفته شده است، بنابراین از اضافه کاری و ناسازگاری جلوگیری می شود. روششناسی ما مزیت کلیدی این را دارد که بهروزرسانی خودکار ویژگیهای فراداده را که URI (مستقیم یا غیرمستقیم) با آنها مرتبط میکنند، دارد: به نظر ما، این کافی است تا پارادایم مدیریت ابرداده ما را با توجه به استراتژیهای متمرکز سنتی قویتر بدانیم. در واقع، استراتژیهای متمرکز نمیتوانند همان مقادیر ویژگی را تکرار کنند (دوباره آدرس ایمیل یک نقطه تماس را در نظر بگیرید) در سوابق ابردادهها،
همچنین تعدادی تکنیک جدید بسط پرس و جو وجود دارد که می تواند بر اساس ساختارهای داده RDF که فراداده را بیان می کند، باشد: این تکنیک ها می توانند افراد، کلمات کلیدی، نام های نامی و همه دسته های توصیفی را که می توان در وب داده پیدا کرد شناسایی کرد. این که تا چه حد می تواند بر دقت و یادآوری در کشف دارایی های جغرافیایی تأثیر بگذارد (ارزیابی خارج از حیطه این کار) هنوز مشخص نشده است و با سایر راهبردها برای اکتشافات آگاه از معناشناسی، مانند راهبردهای [ 44 , 45 ]. با این حال، مزیت آشکار روش ما با توجه به رویکرد اول این است که هیچ پردازش پیشگیرانه ای از توضیحات فراداده مورد نیاز نیست، زیرا ارتقای معنایی در ویرایش ابرداده به طور ضمنی وجود دارد. در عوض، در [ 44] فراداده سنتی مبتنی بر ISO ابتدا به منظور مرتبط کردن (به صورت اکتشافی) مقادیر دارایی با URIها پردازش می شود. افزایش معنایی هنوز برای پارامترهای پرس و جو وارد شده توسط کاربر نهایی در زمان کشف، مانند [ 45 ] منطقی است، و این یکی از جنبه هایی است که ما می خواهیم در رابط ژئوپورتال RITMARE پیاده سازی کنیم.
به عنوان یک خط پایانی، اشاره می کنیم که تصمیماتی که منجر به توسعه روش توصیف شده در این مقاله شد، ریشه های خود را در دیدگاه ما از ابرداده های مکانی به عنوان توصیف های چند مستاجر پیدا می کند. متأسفانه، ابرداده ها معمولاً نادیده گرفته می شوند، جامع نیستند، یا ناسازگار نیستند. پس منطقی است که ساختارهای داده شخص ثالث را در بر گیرد، اگر این به معنای طولانی شدن فاصله زمانی است که در آن می توان به توضیحات فراداده تکیه کرد. منبعیابی این ساختارهای داده خارجی بهعنوان دادههای باز هیچ شرطی در مورد استفاده یا باز بودن داراییهای اشارهشده در توضیحات فراداده ایجاد نمیکند. با این حال، اشتراکگذاری دادهها و ابردادهها به روش باز یک روش توصیهشده است که ما عموماً آن را پذیرفتهایم: بهویژه، در زمینه RITMARE، ما یک خطمشی دادههای باز را ترویج کردیم [ 46]] که به راحتی می تواند با آنهایی که ابتکارات علوم باز را مشخص می کنند مطابقت داشته باشد [ 47 ، 48 ، 49 ].
فعالیتهای آتی در این موضوع تحقیقاتی بر تعمیم رویکرد متمرکز خواهد بود. به طور خاص، ما میخواهیم توصیفهای مبتنی بر RDF را از فرادادههای ISO تولید کنیم که توسط ابزارهایی غیر از EDI تولید شدهاند، یعنی فاقد هرگونه مرجع معنایی. در ابتدا، زبان الگوی معرفیشده در این مقاله اهمیت خود را حفظ میکند، زیرا افزایش معنایی نیازمند تعریف منابع داده و پرسوجوهای SPARQL است، مانند مواردی که در اجرای موارد استفاده ارائه شده در این کار ارائه شده است. سپس، کاهش این الزام گام نهایی به سمت یک چارچوب کلی قابل اجرا برای مدیریت فراداده غیرمتمرکز و آگاه به معنایی خواهد بود.
اختصارات
در این نسخه از اختصارات زیر استفاده شده است:
| CoP | جامعه تمرین |
| FGDC | کمیته داده های جغرافیایی فدرال |
| FOAF | دوست یک دوست |
| FOSS | نرم افزار رایگان و متن باز |
| الهام بخشیدن | زیرساخت اطلاعات فضایی در اروپا |
| RDF | چارچوب شرح منابع |
| RITMARE | Ricerca ITaliana per il MARE – تحقیق ایتالیایی برای دریا |
| RNDT | Repertorio Nazionale dei Dati Territoriali – مخزن ملی داده های سرزمینی |
| SDI | زیرساخت داده های مکانی |
| SPARQL | پروتکل SPARQL و زبان پرس و جو RDF |
| SWE | فعال سازی وب سنسور |
| لاک پشت | زبان سه گانه کوتاه RDF |
| URI | شناسه های یکنواخت منابع |
| XML | زبان نشانه گذاری توسعه پذیر |
ضمیمه A. تعاریف الگو برای موارد استفاده در بخش 3
10 <RDFin><![CDATA[ 11 ?contact vcard:email ?1 . 12 ?contact vcard:org ?org . 13 ?org foaf:name ?2 . 14 ]]></RDFin> 15 </item> 16 <item hasIndex="2" outIndex="1" isFixed="false" 17 hasDatatype="select" datasource="personS"> 18 <label xml:lang= "en">موسسه</label> 19 <hasPath>/.../gmd:organisationName/...</hasPath> 20 </item> 21 <item hasIndex="4" isFixed="false" 22 hasDatatype= "codelist" datasource="roleCodes"><hasPath>/.../gmd:CI_RoleCode/@codeListValue</hasPath> 25 <defaultValue>http://.../resourceProvider</defaultValue> 26 <RDFin><![CDATA[ 27 ?role skos:prefLabel ?3. 28 ]]></RDFin> 29 </item> 30 </produces> 31 <RDFout><![CDATA[ 32 PREFIX dcat: <http://www.w3.org/ns/dcat#> 33 کارت مجازی PREFIX : <http://www.w3.org/2006/vcard/ns#> 34 INSERT 35 { 36 <$id_1_uri> dcat:contactPoint [ 37 rdf: 38 کارت مجازی:hasUID <$resp_1_uri> ; 39 vcard:hasRole <$resp_3_uri> 40 ] . 41 } 42 WHERE {} 43 ]]></RDFout> 44 <RDFin><![CDATA[ 45 PREFIX dcat: <http://www.w3.org/ns/dcat#> 46 کارت مجازی PREFIX: <http: //www.w3.org/2006/vcard/ns#> 47 پیشوند foaf: <http://xmlns.com/foaf/0.1/> 48 PREFIX skos: <http://.../skos/core# > 49 SELECT ?1 ?2 ?3 50 WHERE { 51 <$id_1_uri> dcat:contactPoint ?struct .?struct vcard:hasUID ?contact . 53 ?struct vcard:hasRole ?role . 54 FILTER( LANG(?2) = "en" && LANG(?3) = "en" ) 55 } 56 ]]></RDFin> 57 </element> 58 68 <RDFin><![CDATA[ 69 ?keyw skos:prefLabel ?1 . 70 ?thes skos:member ?keyw . 71 ?thes skos:prefLabel ?2 . 72 ?thes dct:date ?timestamp . 73 BIND( STRBEFORE(?timestamp, " ") AS ?3) 74 ]]></RDFin> 75 </item> 76 <item hasIndex="2" isFixed="false" 77 hasDatatype="select" datasource=" keyw_SDN_S"> 78 <label xml:lang="en">منشا واژگان کنترل شده</label> 79 <hasPath>/.../gmd:title/...</hasPath> 80 <field>برچسب</field>$contr_voc_1_uri> . 95 } 96 WHERE {} 97 ]]></RDFout> 98 <RDFin><![CDATA[ 99 PREFIX dcat: <http://www.w3.org/ns/dcat#> 100 PREFIX skos: <http://www .w3.org/2004/02/skos/core#> 101 PREFIX dct: <http://purl.org/dc/terms/> 102 SELECT ?1 ?2 ?3 103 WHERE { 104 <$id_1_uri> dcat: کلید واژه ?keyw . 105 } 106 ]]></RDFin> 107 </element>
ضمیمه B. منابع داده برای استفاده «تعیین نقاط تماس»
1 <sparql xml:id="person" endpointType="virtuoso"> 2 <query><![CDATA[ 3 PREFIX vcard: <http://www.w3.org/2006/vcard/ns#> 4 SELECT ? تماس با ?label 5 FROM <http://ritmare.it/rdfdata/lotrx> 6 WHERE { 7 ?contact rdf:type foaf:Person . 8 ?تماس کارت مجازی: ایمیل ?برچسب . 9 FILTER( REGEX( STR(?label), "$search_param", "i") ) 10 } 11 ORDER BY ASC(?label) 12 ]]></query> 13 </sparql> 14 15 <singleton xml:id="personS" endpointType="virtuoso" 16 triggerItem="resp_1_uri"> 17 <query><![CDATA[ 18 PREFIX vcard: <http://www.w3.org/2006/vcard/ ns#> 19 SELECT ?inst 20 FROM <http://ritmare.it/rdfdata/lotrx> 21 WHERE { 22 <$search_param> vcard:org ?org. 23 ?org foaf:name ?inst . 24 FILTER(LANG(?inst)='en') 25 } 26 ]]></query> 27 </singleton> 28 29 <codelist xml:id="roleCodes" endpointType="virtuoso"> 30 <uri>http://.../ResponsiblePartyRole</uri> 31 </codelist>
ضمیمه ج. منابع داده برای مورد استفاده «کلید واژهها از واژگان کنترلشده»
1 <sparql xml:id="keyw_SDN" endpointType="fuseki"> 2 <query><![CDATA[ 3 PREFIX skos: <http://www.w3.org/2004/02/skos/core#> 4 PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> 5 SELECT ?concept ?label 6 WHERE { 7 ?concept rdf:type skos:Concept. 8 <http://vocab.nerc.ac.uk/collection/P07/current/> 9 skos:member ?concept . 10 ?concept skos:prefLabel ?label . 11 FILTER( 12 LANG(?label)="en" && REGEX(STR(?label)") 14 } 15 ]]></query> 16 <url>http://vocab.nerc.ac.uk/sparql/sparql</url> 17 </sparql> 18 19 <singleton xml:id="keyw_SDN_S" endpointType="fuseki" 20 triggerItem="contr_voc_1_uri"> 21 <query><![CDATA[ 22 PREFIX skos: <http://www.w3.org/2004/02/ skos/core#> 23 PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> 24 PREFIX dct: <http://purl.org/dc/terms/ > 25 SELECT ?label ?date 26 WHERE { 27 ?voc skos:member <$search_param> . 28 ?voc skos:prefLabel ?label . 29 ?voc dct:date ?ts . 30 BIND( STRBEFORE(?ts, " " 32 ]]></query> 33 <url>http://vocab. 34 .ac.uk/sparql/sparql</url> 35 </singleton>
ضمیمه D. قطعات فراداده ISO تولید شده توسط دو مورد استفاده
1 <?xml version="1.0" encoding="UTF-8" encoding="UTF-8"?> 2 < gmd :MD_Metadata 3 xmlns:gmd="http://www.isotc211.org/2005/gmd" 4 xmlns:gco="http://www.isotc211.org/2005/gco" 5 xmlns:xlink="http://www.w3.org/1999/xlink" 6 xmlns:gml="http:// www.opengis.net/gml/3.2" 7 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" 8 xsi:schemaLocation="http://www.isotc211.org/2005/ gmd 9 http://schemas.opengis.net/iso/19139/20060504/gmd/gmd.xsd"> 10 ... 11 <gmd:contact> 12 <gmd:CI_ResponsibleParty> 13 <gmd:organisationName> 14 <gco:CharacterString> 15 یاران حلقه 16 </gco:CharacterString> 17 </gmd:organisationName> 18 <gmd:contactInfo> 19 < gmd:CI_Contact> 19 <gmd: CI_Contact > gmd:CI_Address> 22 <gmd:electronicMailAddress> 23 <gco:CharacterString> 24 mailto: boromir.son-denethor@lotr.org 25 </gco:CharacterString> 26 </gmd:electronicMailAddress> 27 </gmd:CI_Address> 28 </gmd:address> 29 </gmd:CI_Contact> 30 < /gmd:contactInfo> 31 <gmd:role> 32 <gmd:CI_Role > ://.../gmxCodelists.xml#CI_RoleCode" 34 codeListValue="pointOfContact"> 35 pointOfContact 36 </gmd:CI_RoleCode> 37 < /gmd:role> 38 </gmd:CI_ResponsibleParty </gmd:CI_ResponsibleParty </gmd> 40 <gmd:descriptiveKeywords> 41 <gmd:MD_Keywords> 42 <gmd:keyword> 43 <gco:CharacterString> 44 19'-butanoyloxyfucoxanthin 45 </gco:CharacterString> 46 </gmd:keyword> 47 <gmd:CharacterString> 47 <gmd:CharacterString> 44 <gmd:title> 50 <gco:CharacterString> 51 اصطلاحنامه Marisaurus 52 </gco:CharacterString> 53 </gmd:title> 54 <gmd:date> 55 <gmd:CI_Date> 56 <gmd:date> 57 <gco:Date>22-09-2010</gco:Date> 58 </gmd:date> 59 <gmd:dateType> 60 <gmd:CI_DateTypeCode 61 codeList="http://. ... _ _ _ _ _ _ _ _ _ _ _ _ _ _ 69 </gmd:thesaurusName> 70 </gmd:MD_Keywords> 71 </gmd:descriptiveKeywords> 72 ... 73 </gmd:MD_Metadata>
منابع
- دی اسمیت، ام جی; Goodchild، MF; Longley، P. تجزیه و تحلیل جغرافیایی: راهنمای جامع اصول، تکنیک ها و ابزارهای نرم افزاری . Troubador Publishing Ltd.: Leicester, UK, 2007. [ Google Scholar ]
- خاره، ر. Rifkin، A. XML: مدل سازی داده ها و فراداده. در مجموعه مقالات کنفرانس ACM CSCW98 در مورد کار تعاونی با پشتیبانی رایانه، سیاتل، WA، ایالات متحده آمریکا، 14-18 نوامبر 1998. پ. 430.
- گروه کاری RDM. اطلاعات مرجع و مقاله موقعیت فراداده ; 2002; پ. 45. در دسترس آنلاین: http://inspire.jrc.ec.europa.eu/reports/positionpapers/inspiredmppv43en.pdf (در 30 نوامبر 2016 قابل دسترسی است).
- کمیسیون اروپایی. دستورالعمل 2007/2/EC پارلمان اروپا و شورای 14 مارس 2007 برای ایجاد زیرساخت برای اطلاعات فضایی در جامعه اروپایی (INSPIRE) . گزارش فنی. 2007. در دسترس آنلاین: http://eur-lex.europa.eu/legal-content/EN/ALL/?uri=CELEX:32007L0002 (دسترسی در 30 نوامبر 2016).
- کمیسیون اروپایی. مقررات کمیسیون (EC) شماره 1205/2008 مورخ 3 دسامبر 2008 دستورالعمل اجرایی 2007/2/EC پارلمان اروپا و شورا در خصوص فراداده ها . گزارش فنی. 2008. موجود به صورت آنلاین: http://eur-lex.europa.eu/legal-content/EN/ALL/?uri=CELEX:32008R1205 (دسترسی در 30 نوامبر 2016).
- کمیسیون اروپایی. تصحیح مقررات کمیسیون (EC) شماره 1205/2008 مورخ 3 دسامبر 2008 دستورالعمل اجرایی 2007/2/EC پارلمان اروپا و شورا در مورد فراداده (OJ L 326, 4.12.2008) . گزارش فنی. 2008. موجود به صورت آنلاین: http://eur-lex.europa.eu/legal-content/EN/ALL/?uri=CELEX:32008R1205R%2802%29 (در 30 نوامبر 2016 قابل دسترسی است).
- ISO ISO 19115:2014 اطلاعات جغرافیایی — فراداده . استاندارد، سازمان بین المللی استانداردسازی (TC 211)، 2014. موجود به صورت آنلاین: http://www.iso.org/iso/isocatalogue/catalogueics/cataloguedetailics.htm?csnumber=53798 (در 30 نوامبر 2016 قابل دسترسی است).
- ISO ISO 19119:2005 اطلاعات جغرافیایی — خدمات . استاندارد، سازمان بین المللی استانداردسازی (TC 211)، 2005. موجود به صورت آنلاین: http://www.iso.org/iso/cataloguedetail.htm?csnumber=39890 (دسترسی در 30 نوامبر 2016).
- ISO ISO 19136:2007 اطلاعات جغرافیایی – زبان نشانه گذاری جغرافیایی (GML) . استاندارد، سازمان بین المللی استانداردسازی (TC 211)، 2007. موجود به صورت آنلاین: http://www.iso.org/iso/isocatalogue/cataloguetc/cataloguedetail.htm?csnumber=32554 (دسترسی در 30 نوامبر 2016).
- کارگروه موضوعی پایش محیطی INSPIRE. D2.8.III.7 مشخصات دادههای INSPIRE در مورد تأسیسات پایش محیطی-پیشنویس دستورالعملها . مرکز تحقیقات مشترک کمیسیون اروپا: پتن، هلند، 2011; پ. 22. [ Google Scholar ]
- گروه کاری موضوعی INSPIRE در مورد توزیع گونه ها. D2.8.III.19 مشخصات دادههای INSPIRE در مورد توزیع گونهها – دستورالعملهای فنی . مرکز تحقیقات مشترک کمیسیون اروپا: پتن، هلند، 2013; پ. 22. [ Google Scholar ]
- برنرز لی، تی. هندلر، جی. Lassila، O. وب معنایی . علمی آمریکایی: نیویورک، نیویورک، ایالات متحده آمریکا، 2001; جلد 284، ص 34-43. [ Google Scholar ]
- بیزر، سی. هیث، تی. Berners-Lee, T. داده های مرتبط – داستان تاکنون. در خدمات معنایی، قابلیت همکاری و برنامه های کاربردی وب: مفاهیم نوظهور ; IGI Global: Hershey، PA، USA، 2009; ص 205-227. [ Google Scholar ]
- گارسیا، آر. سلما، او. ادغام معنایی و بازیابی ابرداده های چند رسانه ای. در مجموعه مقالات پنجمین کارگاه بین المللی در مورد نشانه گذاری دانش و حاشیه نویسی معنایی، بورنموث، انگلستان، 9 تا 11 اکتبر 2006. صص 69-80.
- کورکی، تی. جوکلا، اس. سولونن، آر. Turpeinen، M. Agents در ارائه محتوای شخصی شده بر اساس فراداده معنایی. در مجموعه مقالات کارگاه سمپوزیوم بهار AAAI 1999 در مورد عوامل هوشمند در فضای مجازی، استانفورد، کالیفرنیا، ایالات متحده آمریکا، 22 تا 24 مارس 1999. صص 84-93.
- هس، آ. کوشمریک، ن. آموزش پیوست کردن ابرداده معنایی به خدمات وب. در The Semantic Web-ISWC 2003 ; Springer: برلین، آلمان، 2003; صص 258-273. [ Google Scholar ]
- AgID. Repertorio Nazionale dei Dati Territoriali—RNDT ; گزارش فنی، Agenzia per l’Italia Digitale (AgID)؛ 2012. در دسترس آنلاین: http://archivio.digitpa.gov.it/repertorio-nazionale-dei-dati-territoriali-rndt (در 30 نوامبر 2016 قابل دسترسی است).
- کنسرسیوم فضایی باز کنسرسیوم فضایی باز مشخصات پیاده سازی زبان مدل سنسور OpenGIS (SensorML). در طراحی ؛ کنسرسیوم فضایی باز: Wayland، MA، ایالات متحده آمریکا، 2007; پ. 180. [ Google Scholar ]
- OGC. OGC® SensorML: مدل و XML کدگذاری استاندارد ؛ کدگذاری استاندارد OGC-12-000. کنسرسیوم فضایی باز: Wayland، MA، ایالات متحده آمریکا، 2014. [ Google Scholar ]
- بیشر، YA غلبه بر موانع معنایی و دیگر موانع قابلیت همکاری GIS. بین المللی جی. جئوگر. Inf. علمی 1998 ، 12 ، 229-314. [ Google Scholar ] [ CrossRef ]
- لاسیلا، او. هندلر، جی. Embracing Web 3.0 ; IEEE Internet Computing: Baltimore, MD, USA, 2007; جلد 11، ص 90–93. [ Google Scholar ]
- رید، سی. بوتس، ام. Davidson, J. OGC® Sensor Web Enablement: Overview and High Level Architecture . 2007 IEEE Autotestcon: Baltimore, MD, USA, 2007; صص 372-380. [ Google Scholar ] [ CrossRef ]
- سیگانیاک، ر. وود، دی. Lanthaler, M. RDF 1.1 Concepts and Abstract Syntax—W3C Recommendation 25 فوریه 2014 . گزارش فنی. 2014. در دسترس آنلاین: http://www.w3.org/TR/2014/REC-rdf11-concepts-20140225/ (در 30 نوامبر 2016 قابل دسترسی است).
- هیتزلر، پی. کرتزش، ام. رودولف، اس. مبانی فن آوری های وب معنایی ، ویرایش اول. Chapman & Hall/CRC: Boca Raton، FL، USA، 2009. [ Google Scholar ]
- برنرز لی، تی. فیلدینگ، آر. Masinter, L. Uniform Resource Identifier (URI): Generic Syntax . گزارش فنی. 2005. در دسترس آنلاین: https://tools.ietf.org/html/rfc3986 (در 30 نوامبر 2016 قابل دسترسی است).
- کنسرسیوم وب جهانی فضاهای نام در XML 1.0 (نسخه سوم) . گزارش فنی. 2009. در دسترس آنلاین: https://www.w3.org/TR/REC-xml-names/ (در 30 نوامبر 2016 قابل دسترسی است).
- بکت، دی. برنرز لی، تی. Prud’hommeaux, E.; Carothers، G. RDF 1.1 Turtle—Terse RDF Triple Language . گزارش فنی. 2014. در دسترس آنلاین: https://www.w3.org/TR/turtle/ (در 30 نوامبر 2016 قابل دسترسی است).
- هریس، اس. Seaborne, A. SPARQL 1.1 Query Language—W3C توصیه 21 مارس 2013 . گزارش فنی. 2013. در دسترس آنلاین: http://www.w3.org/TR/sparql11-query/ (در 30 نوامبر 2016 قابل دسترسی است).
- معناشناسی کمبریج. SPARQL در مقابل SQL . گزارش فنی. در دسترس آنلاین: http://www.cambridgesemantics.com/semantic-university/sparql-vs-sql-intro (در 30 نوامبر 2016 قابل دسترسی است).
- هجلماگر، ج. مولرینگ، اچ. کوپر، AK; دلگادو، تی. رجبی فرد، ع. راپنت، پی. دانکو، دی.م. هوئت، ام. لوران، دی. آلدرز، اچ. و همکاران یک مدل رسمی اولیه برای زیرساخت های داده های مکانی بین المللی جی. جئوگر. Inf. علمی 2008 ، 22 ، 1295-1309. [ Google Scholar ] [ CrossRef ]
- تاگلیولاتو، پ. اوجیونی، ا. فوگازا، سی. پپه، م. Carrara، P. Sensor طرحهای فراداده و ویرایش به کمک رایانه برای SensorML منظم. IOP Conf. سر. محیط زمین. علمی 2016 , 34 , 012036. [ Google Scholar ] [ CrossRef ]
- فوگازا، سی. پپه، م. اوجیونی، ا. تاگلیولاتو، پ. کاررارا، ص. سادهسازی ابردادههای مکانی در وب معنایی. IOP Conf. سر. محیط زمین. علمی 2016 , 34 , 012009. [ Google Scholar ] [ CrossRef ]
- فوگازا، سی. منگن، اس. پپه، م. اوجیونی، ا. Carrara, P. کیت شروع RITMARE: ظرفیت سازی از پایین به بالا برای ارائه دهندگان داده های جغرافیایی. در مجموعه مقالات نهمین کنفرانس بین المللی گرایش های پارادایم نرم افزار (ICSOFT-PT)، وین، اتریش، 29 تا 31 اوت 2014. صص 169-176.
- اوجیونی، ا. تاگلیولاتو، پ. فوگازا، سی. پپه، م. منگن، اس. پاوسی، ف. Carrara، P. مدیریت دادههای بین دامنهای اقیانوسشناسی و دریایی برای توسعه پایدار . Diviacco, P., Leadbetter, A., Glaves, H., Eds. IGI Global: Hershey, PA, USA, 2017; ص 200-223. [ Google Scholar ]
- پاوسی، ف. باسونی، ا. فوگازا، سی. منگن، اس. اوجیونی، ا. پپه، م. تاگلیولاتو، پ. Carrara, P. EDI – یک ویرایشگر ابرداده مبتنی بر الگو برای داده های تحقیق. J. Open Res. نرم افزار 2016 . [ Google Scholar ] [ CrossRef ]
- کنسرسیوم فضایی باز OGC بهترین تمرین برای فعال کردن وب حسگر نمایه SOS سبک برای سنسورهای ثابت درجا—OGC 11-169r1 ; گزارش فنی؛ کنسرسیوم فضایی باز: Wayland، MA، ایالات متحده آمریکا، 2014. [ Google Scholar ]
- لیدبیتر، ا. لوری، آر. Clements, D. The NERC Vocabulary Server: نسخه 2.0 ; چکیده تحقیقات ژئوفیزیک; EGU–European Geosciences Union GmbH: مونیخ، آلمان، 2012; جلد 14. [ Google Scholar ]
- Leadbetter، A. داده های اقیانوسی مرتبط. در وب معنایی در علوم زمین و فضا. وضعیت فعلی و مسیرهای آینده AKA GmbH: برلین، آلمان، 2015; صص 11-31. [ Google Scholar ]
- کارگروه RDF طرحواره RDF 1.1 . گزارش فنی. 2014. در دسترس آنلاین: https://www.w3.org/TR/rdf-schema/ (در 30 نوامبر 2016 قابل دسترسی است).
- کارگروه OWL. زبان هستی شناسی وب (OWL) . گزارش فنی. 2012. در دسترس آنلاین: https://www.w3.org/2001/sw/wiki/OWL (در 30 نوامبر 2016 قابل دسترسی است).
- سایمون کاکس. OWL نمایش مدل هماهنگ شده UML ISO/TC 211 برای اطلاعات جغرافیایی. گزارش فنی، 2013. در دسترس آنلاین: http://def.seegrid.csiro.au/static/isotc211/iso19115/2003/ (در 30 نوامبر 2016 قابل دسترسی است).
- کمیسیون اروپایی. GeoDCAT-AP نسخه 1.0 . گزارش فنی. 2015. در دسترس آنلاین: https://joinup.ec.europa.eu/asset/dcatapplicationprofile/assetrelease/geodcat-ap-v10 (در 30 نوامبر 2016 قابل دسترسی است).
- فوگازا، سی. پپه، م. اوجیونی، ا. پاوسی، ف. Carrara, P. رویکردی جامع و آگاه از معنای شناسی به زیرساخت های داده های مکانی. در مجموعه مقالات سومین کنفرانس بینالمللی فناوریها و کاربردهای مدیریت داده (DATA)، وین، اتریش، 29 تا 31 اوت 2014. صص 349-356.
- فوگازا، سی. لوراشی، گ. نمایه سازی آگاهانه از معنایی منابع جغرافیایی بر اساس اصطلاحنامه چند زبانه: روش شناسی و نتایج اولیه. بین المللی جی. اسپات. زیرساخت داده Res. 2012 ، 7 ، 16-37. [ Google Scholar ]
- سانتورو، ام. مازتی، پی. ناتیوی، س. فوگازا، سی. گرانل، سی. دیاز، ال. روششناسی برای کشف افزوده شده منابع جغرافیایی. در کشف منابع جغرافیایی: روشها، فناوریها و کاربردهای اضطراری ؛ Díaz, L., Granell, C., Huerta, J., Eds. IGI Global: Hershey, PA, USA, 2012; صص 172-203. [ Google Scholar ]
- Documento Per La Definizione Di Una Politica Nella Gestione E Utilizzo Dei Dati E Dei Prodotti Resi Disponibili Nell’ambito Del Progetto RITMARE. در دسترس آنلاین: http://www.ritmare.it/area-download?download=187:data-policy-new (در 30 نوامبر 2016 قابل دسترسی است).
- رایشمن، او. جونز، مگابایت؛ Schildhauer، MP چالش ها و فرصت های داده های باز در محیط زیست. Science 2011 ، 331 ، 703-705. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- دیوید، PA منطق اقتصادی علم باز و تعادل بین حقوق مالکیت خصوصی و مالکیت عمومی در داده ها و اطلاعات علمی: یک آغازگر. در نقش داده ها و اطلاعات علمی و فنی در حوزه عمومی: مجموعه مقالات یک سمپوزیوم ; انتشارات آکادمی ملی: واشنگتن، دی سی، ایالات متحده آمریکا، 2003; صص 19-34. [ Google Scholar ]
- Uhlir، PF; شرودر، پی. داده های باز برای علم جهانی. اطلاعات علمی J. CODATA 2007 ، 6 ، 36-53. [ Google Scholar ] [ CrossRef ]
شکل 1. مدیریت فراداده در RITMARE SDI.

شکل 2. از موارد “مشخص کردن نقاط تماس” ( A ) استفاده کنید. “کلمات کلیدی از واژگان کنترل شده” ( B ).
شکل 3. اجزای عنصر و مورد XML Schema .
شکل 4. جزء طرحواره منبع داده .
© 2016 توسط نویسندگان؛ دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (CC-BY) (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر