1. معرفی
درک تحرک انسان از اهمیت بسیار مهمی برخوردار است [ 1 ، 2 ]، با مزایای بالقوه برای زمینه های مختلف مانند پیش بینی تحرک [ 3 ، 4 ]، برنامه ریزی شهری [ 5 ، 6 ، 7 ]، تحقیقات حمل و نقل [ 8 ، 9 ] و سلامت انسان. تحقیق [ 10 ]. با توسعه سریع فناوری اطلاعات و ارتباطات [ 11] در دو دهه گذشته، انواع مختلفی از ردپای عظیم دیجیتالی ایجاد شده توسط انسان مانند دادههای کارت هوشمند، سوابق جزئیات تماس (CDR)، دادههای رسانههای اجتماعی با برچسب جغرافیایی، دادههای ردیابی GPS، دادههای WiFi، دادههای سوابق کارت اعتباری، و تجزیه و تحلیل همزمان آنها برای تحقیقات تحرک انسان استفاده می شود [ 2 ، 12 ، 13 ، 14 ، 15 ، 16 ، 17 ، 18 ]. با این حال، بحث در مورد نمایندگی یا سوگیری های ذاتی داده ها وجود دارد. به عنوان مثال، مطالعات قبلی نشان می دهد که کاربران تلفن همراه در سن، جنسیت و جغرافیا به طور نابرابر توزیع شده اند [ 19 ، 20]]. این نوع سوگیری در داده های رسانه های اجتماعی نیز وجود دارد [ 21 و 22 ].
برخلاف دادههای ردیابی GPS که میتوانند چندین رکورد در دقیقه داشته باشند [ 23 ]، یک نقطه ضعف اصلی دادههای مورد استفاده در تحقیقات قبلی، مانند مکان تلفن همراه و دادههای ورود به شبکههای اجتماعی، این است که نمونهبرداری بسیار « پراکنده » در یک مقیاس زمانی بنابراین، سوابق یک فرد می تواند در چند ساعت در روز یا هفته یا فقط چند ساعت در ماه، به دلیل توزیع نابرابر فعالیت های تلفنی افراد در مکان و زمان توزیع شود، که موضوعی است که نیاز به توجه دارد. داده ها [ 24 ]. محققان قبلی در مورد اینکه چگونه CDR ها می توانند سوگیری ها را در تحقیقات تحرک انسانی معرفی کنند بحث کرده اند [ 25 , 26]و اینکه چگونه سطح انحراف ارتباط نزدیکی با نسبت سوابق ارتباط تلفنی نمونه برداری شده در مسیر حرکت یک فرد دارد [ 26 ]. علاوه بر این، ساگارا و همکاران. [ 27 ] یک مدل ابرنمونهای برای ارزیابی سوگیریهای نمونهگیری دادههای کاهشیافته پیشنهاد کرد. بازنمایی بخش های زمانی مختلف به دلیل عدم وجود حقیقت زمینی برای مسیرها به طور جامع بررسی نشده است. میزان نمایندگی داده های مکان تلفن همراه پراکنده در برآورد تحرک انسان چیست؟ این سوال باید قبل از استفاده از داده ها برای مطالعه الگوهای تحرک انسان و استخراج نتایج مورد بررسی قرار گیرد.
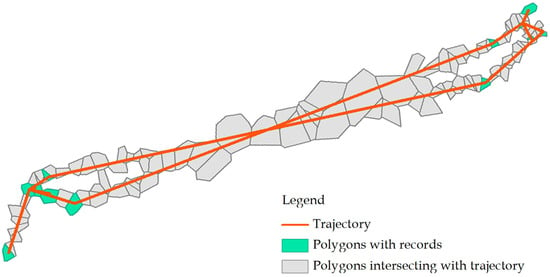
در این مقاله، ما به طور کمی نماینده دادههای مکان تلفن همراه را بر روی تخمین الگوهای حرکتی فردی تجزیه و تحلیل میکنیم. CDR ها معمولاً ردپای فردی را در طول ارتباط تلفنی می گیرند، در حالی که داده های موقعیت مکانی تلفن همراه که به طور فعال ردیابی می شوند حاوی سوابق ارتباط تلفنی و سوابق موقعیت مکانی هستند که توسط استراتژی های به روز رسانی مکان مانند به روز رسانی های دوره ای و منظم و تحویل تلفن همراه ایجاد می شوند. این مطالعه از داده های ردیابی فعال برای انجام تحقیقات استفاده می کند. شکل 1مسیر کامل یک فرد را از مجموعه داده های موقعیت مکانی تلفن همراه ما در طول یک روز کامل نشان می دهد. Tessellations Voronoi برای نشان دادن مناطق خدماتی برج های تلفن همراه استفاده شد. تعیین یک مسیر واقعی دشوار است زیرا اکثر دکل های تلفن همراه حتی تحت استراتژی های به روز رسانی فعال ضبط نشده بودند. بنابراین، سوال اصلی تحقیق این مطالعه تعیین تأثیر دادههای مکان تلفن همراه نمونهبرداری پراکنده بر ارزیابی شاخصهای تحرک انسانی است.
این مقاله به بررسی این سوال می پردازد و چندین پیشنهاد برای انتخاب مجموعه داده مناسب برای تجزیه و تحلیل تحرک انسان ارائه می دهد. یافتههای این تحقیق همچنین میتواند برای ارزیابی بازنمایی انواع دیگر دادههای نمونهگیری پراکنده، مانند دادههای رسانههای اجتماعی با برچسب جغرافیایی، مورد استفاده قرار گیرد.
این مقاله به شرح زیر تنظیم شده است: در بخش دوم به بررسی مطالعات مرتبط با این تحقیق می پردازیم. بخش 3 مجموعه داده های موقعیت مکانی تلفن همراه ردیابی فعال و منطقه مورد مطالعه را معرفی می کند. بخش 4 روشی را برای ارزیابی نمایندگی داده های پراکنده تلفن همراه برای اندازه گیری شاخص های تحرک انسانی توضیح می دهد. بخش 5 نتایج تجزیه و تحلیل را مورد بحث قرار می دهد. بخش آخر یافتههای ما را خلاصه میکند و جهتهای تحقیقات آینده را مورد بحث قرار میدهد.
2. بررسی ادبیات
این بخش تحقیقات مرتبط را در دو حوزه زیر ارائه میکند. داده های بزرگ برای تحقیقات تحرک انسانی و مسائل نماینده داده های بزرگ.
2.1. داده های مکان تلفن همراه برای تحقیقات تحرک انسانی
بسیاری از یافته های ارزشمند مربوط به تحرک انسان و تعامل با محیط های شهری در سال های اخیر با ظهور داده های بزرگ گزارش شده است. این مطالعات تحقیقاتی عمیق را می توان برای پیش بینی تحرک [ 3 ، 4 ]، برنامه ریزی شهری [ 5 ، 6 ، 7 ]، تحقیقات حمل و نقل [ 8 ، 9 ، 28 ] و سایر زمینه ها [ 10 ، 29] استفاده کرد.]. در میان مجموعه دادهها، دادههای موقعیت مکانی تلفن همراه، دادههای بسیار ویژهای هستند، زیرا تلفنهای همراه ضریب نفوذ بسیار بالایی دارند و مردم معمولاً تلفنهای همراه خود را بهخصوص در کشورهای آسیایی مانند چین با خود میبرند. برخی از محققان این نوع داده ها را به عنوان یک منبع معقول برای توصیف تحرک انسان می بینند [ 30 ].
کونگ و همکاران با استفاده از داده های مکان تلفن همراه نمونه برداری پراکنده. [ 31 ] الگوهای رفت و آمد خانه-کار در چندین شهر در کشورهای مختلف را بررسی کرد و کشف کرد که زمان رفت و آمد و توزیع ارزش متوسط مستقل از مسافت رفت و آمد یا کشور است. دیائو و همکاران [ 32 ] قوانین رایج حاکم بر مشارکت یک فرد در فعالیت را کشف کرد و اطلاعات جاسازی شده را با ارائه یک مدل تشخیص فعالیت با بررسی های خاطرات سفر استخراج کرد. رد پای انسان همچنین می تواند برای تجزیه و تحلیل الگوهای مکانی- زمانی همگرایی و واگرایی در مناطق شهری مورد استفاده قرار گیرد [ 33]. برای تحقیقات حمل و نقل، بخش های زنجیره سفر به دست آمده از داده های مکان تلفن همراه را می توان برای برآورد تقاضای بالقوه پویا سفرهای دوچرخه در برنامه ریزی حمل و نقل عمومی استفاده کرد [ 34 ]. با تخمین ماتریس های پویا مبدا-مقصد، الگوهای سفر در روزهای هفته و آخر هفته برای تجزیه و تحلیل تفاوت در تقاضای سفر در طول زمان به تصویر کشیده شده است [ 35 ]. با این حال، مجموعه دادههای نمونه فرعی در ارائه تخمین خوب از الگوهای تحرک چقدر خوب هستند؟ پاسخ به این سؤال صرفاً بله یا خیر نیست، اما تحقیقات در مورد بازنمایی دادههای مکان نمونهبرداری شده پراکنده ممکن است به یافتن برخی پاسخها کمک کند.
علاوه بر این، فضای فعالیت انسانی و ناهمگونی تحرک در این فضا نیز موضوعات بسیاری از مطالعات در مورد تحقیقات تحرک انسانی است [ 2 ، 36 ، 37 ، 38 ، 39 ]. به عنوان مثال، گونزالس و همکاران. [ 2 ] دریافت که شعاع چرخش برای همه افراد را می توان با یک قانون قدرت کوتاه تقریب زد. یوان و همکاران [ 37 ] روابط بین استفاده از تلفن و شاخصهای رفتار سفر که با آنتروپی حرکت و شعاع مشخص میشود را بررسی کرد. فقدان برخی نقاط دور از مکان در سوابق پراکنده تلفن همراه ممکن است بر محاسبه شعاع حرکت در صحنه واقعی تأثیر بگذارد. کالابرس و همکاران [ 30] کل طول سفر بین داده های تلفن همراه و وسیله نقلیه را مقایسه کرد و نشان داد که استفاده از فاصله اقلیدسی بین دکل های تلفن همراه برای اندازه گیری تحرک فردی می تواند باعث تعصب به سمت پایین شود، اما اینکه آیا توزیع پراکنده سوابق موقعیت مکانی نیز یکی از دلایل این سوگیری است. نیاز به تایید دارد. سونگ و باراباسی [ 39 ] و گالوتی [ 40 ] از آنتروپی برای پیشبینی الگوهای تحرک فردی استفاده کردند. علاوه بر این، کاتتون و همکاران. [ 41] متوجه شد که بین وضوح مکانی و زمانی دادههای تلفن همراه و دقت پیشبینی تحرک انسان نیز روابطی وجود دارد. اثربخشی داده های مکان پراکنده در توصیف تحرک فردی انسان باید بیشتر مورد توجه قرار گیرد.
علاوه بر این، از ادبیات بررسی شده در بالا، شاخص های زیادی برای توصیف الگوهای تحرک انسان استفاده می شود، مانند شعاع چرخش [ 2 ، 38 ]، آنتروپی حرکت [ 37 ، 39 ، 40 ]، و مسافت سفر [ 26 ، 30 ]. این شاخص ها معمولاً برای مشخص کردن فاصله سفر، محدوده فضای فعالیت و ناهمگونی الگوهای بازدید استفاده می شوند که سه شاخص اساسی در تحرک انسان هستند. با این حال، مطالعات کمی گزارش کردهاند که چگونه دادههای مکان پراکنده در توصیف تحرک فردی انسان نماینده است.
2.2. مسائل نماینده داده های بزرگ
علیرغم مطالعه مشتاقانه داده های بزرگ، بحث هایی نیز در مورد حریم خصوصی [ 42 ، 43 ، 44 ]، کیفیت داده ها [ 45 ، 46 ، 47 ، 48 ]، و مسائل نماینده [ 25 ، 26 ] وجود دارد. مطالعات قبلی نشان می دهد که کاربران تلفن همراه در جنسیت و جغرافیا [ 19 ، 20 ] و مولفه جمعیت [ 49 ] به طور نابرابر توزیع شده اند. این نوع سوگیری در داده های رسانه های اجتماعی نیز وجود دارد [ 21 و 22 ]. اثرات نمونهگیری مکانی و دانهبندی دادههای مکان پراکنده نیز مورد مطالعه قرار گرفته است.24 ، 50 ].
مسائل نمونه گیری زمانی در استفاده از داده ها برای بررسی الگوهای تحرک انسان از اهمیت حیاتی برخوردار است. داده های ردیابی GPS می توانند از نظر زمانی و مکانی دارای دانه بندی نسبتاً خوبی باشند [ 23 ، 51 ]. با این حال، دادههای موقعیت مکانی تلفن همراه و دادههای رسانههای اجتماعی برچسبگذاریشده جغرافیایی مورد استفاده در مطالعات قبلی بهدلیل توزیع نابرابر فعالیتهای تلفن افراد در مکان و زمان، به طور موقت نمونهبرداری میشوند، که این مسئله اصلی است که نیاز به توجه دارد [24 ] . سوابق تلفن همراه یا داده های ورود به شبکه های اجتماعی یک فرد را می توان در چند ساعت در روز یا یک هفته یا فقط چند ساعت در ماه توزیع کرد. Goodchild [ 52] نشان داد که تلفات در کنترل کیفیت و نمونه گیری دقیق از ویژگی های کلان داده است که می تواند آن را از داده های کوچک متمایز کند. اگرچه مطالعات قبلی نشان داده اند که CDR های نمونه پراکنده برخی سوگیری ها را به تحقیقات تحرک انسانی وارد می کند [ 25 ، 26 ] و سطح انحراف ارتباط نزدیکی با نسبت CDR ها در مسیر کامل یک فرد دارد [ 26 ]، آنها توضیح نمی دهند که چگونه اگر مسیر کامل برای مقایسه در دسترس نباشد، یک مجموعه داده معرف بیشتری به دست آورید.
ناقص بودن داده های مکان نمونه برداری شده به صورت زمانی یا مکانی نیز عامل قابل توجهی است که منجر به مسائل عدم قطعیت در GIScience می شود [ 53 ، 54 ]، و نگرانی هایی را در مورد اینکه چگونه عدم قطعیت ها می توانند بر یافته ها تأثیر بگذارند [ 55 ، 56 ] ایجاد می کند. برخی از محققان فکر می کنند که دوره های زمانی طولانی به افزایش حجم نمونه کمک می کند. جیکوبز [ 57] خاطرنشان می کند که این داده ها تعداد زیادی مشاهدات مکرر در طول زمان و/یا مکان هستند و ممکن است از شر مشکل پراکنده خلاص نشوند. سوال مهم این است که “داده های مکان تلفن همراه چقدر در ارائه یک برآورد دقیق از شاخص های تحرک فردی خوب هستند؟” قبل از استفاده از داده ها برای بررسی الگوهای تحرک انسان و به دست آوردن نتایج معقول باید مورد توجه قرار گیرد.
بنابراین، این مقاله به طور کمی نماینده داده های مکان تلفن همراه پراکنده را در برآورد شاخص های تحرک فردی افراد ارزیابی می کند. ما نه تنها بر تعیین اثرات بخشهای زمانی مختلف بر خصوصیات تحرک انسان تمرکز میکنیم، بلکه بر ارائه یک شناخت کمی روشن از بازنمایی دادهها نیز تمرکز میکنیم.
3. منطقه مطالعه و مجموعه داده
منطقه مورد مطالعه این تحقیق شنژن یکی از بزرگترین شهرهای چین است. این بخش اطلاعات پسزمینه شنژن و مجموعه دادههای موقعیت مکانی تلفن همراه ردیابی فعال جمعآوری شده در آنجا را ارائه میکند.
3.1. منطقه مطالعه
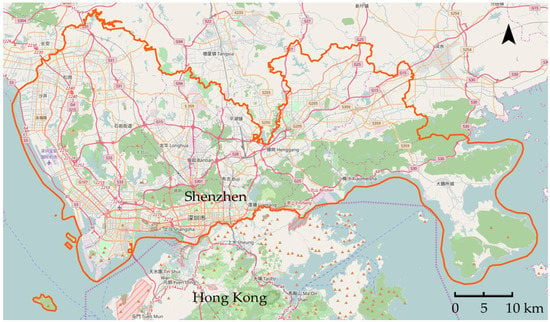
جمعیت شنژن بیش از 15 میلیون نفر در مساحتی حدود 2000 کیلومتر مربع است که نشان دهنده بالاترین تراکم جمعیت در میان شهرهای چین است. تولید ناخالص داخلی سالانه آن (GDP) پس از شانگهای، پکن و گوانگژو در میان تمام شهرهای چین در رتبه چهارم قرار گرفت [ 58 ]. شنژن در سواحل جنوبی چین واقع شده و در آن سوی مرز هنگ کنگ قرار دارد ( شکل 2 ). شنژن به یک شهر بین المللی با نفوذ تبدیل شده است. وضعیت اجتماعی-اقتصادی مرفه شنژن آن را به انتخاب خوبی برای تحرک انسانی و تحلیل های حوزه تجاری تبدیل می کند.
3.2. داده ها
دادههای موقعیت مکانی تلفن همراه مورد استفاده در تحقیق ما توسط یک شرکت تلفن همراه بسیار بزرگ جمعآوری شده است که تقریباً 60٪ از کل بازار تلفن همراه در شنژن را شامل میشود. تقریباً 16 میلیون رکورد موقعیت مکانی مشترک در طول یک روز کاری جمع آوری شد. جدول 1 ویژگی های داده های مکان تلفن همراه را نشان می دهد. برای نگرانی های حفظ حریم خصوصی، شناسه کاربر رمزگذاری شده است. اپراتورهای مخابراتی سیار هر بار که مشترک از تلفن خود استفاده می کند نزدیکترین دکل تلفن همراه را ضبط می کند. برخلاف دادههای سوابق جزئیات تماس، سوابق اطلاعات مکان تلفن همراه در این مقاله شامل انواع اتصال زیر است:
- (1)
-
برقراری و دریافت تماس؛
- (2)
-
ارسال و دریافت پیامک؛
- (3)
-
به روز رسانی منظم موقعیت مکانی (با حرکت از یک دکل تلفن همراه به دکل دیگر ایجاد می شود) و
- (4)
-
بهروزرسانی دورهای مکان (اگر مشترکی برای مدت زمان مشخصی فعالیت تلفنی نداشته باشد، با پینگ برج شروع میشود).
(3) و (4) دو استراتژی به روز رسانی فعال برای این مجموعه داده هستند. انواع اتصال در این مجموعه داده نشده است. حتی تحت استراتژیهای بهروزرسانی فعال، ما نمیتوانیم مسیر واقعی را تعیین کنیم زیرا اکثر دکلهای تلفن همراه ضبط نشده بودند ( شکل 1 ).
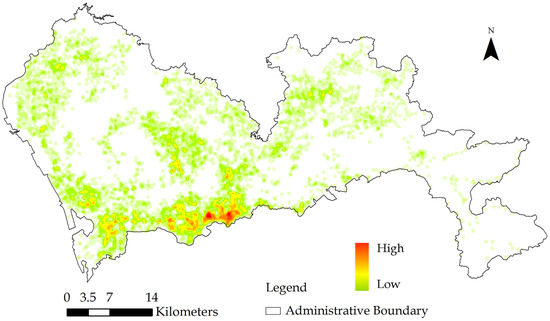
5940 دکل تلفن همراه منحصر به فرد در این مجموعه داده وجود دارد. شکل 3 چگالی هسته فضایی دکل های تلفن همراه را نشان می دهد. دکل های تلفن همراه در فضای شهری به طور ناموزون توزیع شده اند. به طور کلی دکل های تلفن همراه در مرکز شهر و در مناطق پرجمعیت پراکنده هستند، در حالی که دکل های تلفن همراه در مناطق حومه شهر به صورت پراکنده توزیع شده اند و در نتیجه دقت موقعیت یابی کمتری دارند. میانگین فاصله و حداکثر فاصله بین دکل های تلفن همراه مجاور به ترتیب حدود 0.21 و 2.6 کیلومتر است.
از آنجایی که تمرکز این مقاله بررسی بازنمایی دادههای مکان یدکی تلفن همراه در توصیف الگوهای حرکتی انسان است، توزیع نابرابر فعالیتهای تلفنی افراد در مکان و زمان نگرانی اصلی در رابطه با هدف تحقیق ما است [24]، در حالی که توزیع متراکم دکل های تلفن همراه در سراسر منطقه شهری نشان داد که دانه بندی فضایی در سطح دکل تلفن همراه ممکن است یک اشکال عمده در این منطقه مورد مطالعه نباشد.
4. روش شناسی
این مقاله به معرفی شاخصهای متداول حرکت انسان پرداخته است. پس از آن، روش ارزیابی نمایندگی داده های مکان تلفن همراه شامل سه مرحله اصلی بود. ابتدا، روز را به بخشهای 24 ساعته تقسیم کردیم، مشترکانی را که سوابق آنها تمام بخشهای 24 ساعته را پوشش میداد در یک مجموعه داده جدید استخراج کردیم و شاخصهای کامل تحرک انسانی آنها را به عنوان معیارهای این مطالعه محاسبه کردیم. سپس، شاخصهای تحرک انسانی نمونهبرداری شده را با انتخاب تعداد مختلف بخشهای زمانی از مجموعه داده جدید تحت قوانین تصادفی محاسبه کردیم. در نهایت، یک مدل رگرسیون خطی برای تعیین کمیت سطح زیر برآورد جمعآوری شده بین شاخصهای تحرک انسانی نمونهبرداری شده و کامل در هر زمان تصادفی پیشنهاد شد.
4.1. شاخص های متداول حرکتی انسان
شاخص های زیادی برای اندازه گیری فضای فعالیت استفاده می شود، مانند حداکثر فاصله سفر، شعاع چرخش، شعاع حرکت، مسافت کل سفر، آنتروپی حرکت، فراوانی بازدید و غیره. به طور عمده، این شاخص ها را می توان به سه دسته طبقه بندی کرد که عبارتند از محدوده فضای فعالیت، مسافت سفر و ناهمگونی الگوهای بازدید در فضای فعالیت. به عنوان مثال، هر دو آنتروپی حرکت و فرکانس بازدید برای مشخص کردن ناهمگونی الگوهای بازدید استفاده میشوند. بنابراین، این مقاله از سه مورد از آنها برای توصیف رفتار فعالیت انسانی استفاده کرد. آنها بر اساس یک روز کاری محاسبه می شوند و به شرح زیر تعریف می شوند:
مسافت کل سفر : مجموع مسافت سفر مجموع فاصله اقلیدسی بین هر جفت رکورد متوالی [ 26 ] است که معیاری اساسی برای تحرک فردی است.
آنتروپی حرکت : توصیف ناهمگونی الگوهای بازدید [ 37 ، 38 ]، محاسبه شده به صورت
که در آن n تعداد دکل های تلفن همراه متمایز بازدید شده توسط یک مشترک و p i احتمال بازدید از مکان i است.
شعاع چرخش : توصیف می کند که مشترک چقدر سفر کرده است. یکی از متداول ترین معیارهای مورد استفاده برای توصیف محدوده فضای فعالیت [ 2 , 38 ]، محاسبه شده به صورت
که در آن N تعداد دکل های تلفن همراه با توالی زمانی بازدید شده توسط مشترک است، p j j امین برجی است که مشترک از آن بازدید کرده است، و pcm مرکز تمام مکان های توالی زمانی است.
4.2. استخراج مشترکین معتبر
پس از معرفی شاخصهای متداول حرکتی انسان، روش مورد استفاده برای ارزیابی نمایندگی دادههای مکان تلفن همراه در توصیف این شاخصها شامل سه مرحله اصلی است که در زیر توضیح داده شده است.
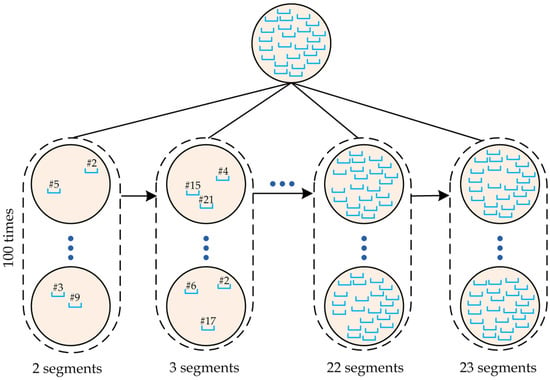
ابتدا مشترکینی را که سوابق آنها برای این تحقیق کافی بود استخراج کردیم. ما روز را به 24 بخش زمانی یک ساعته تقسیم کردیم. 00:00:00 تا 00:59:59 (#0)، 01:00:00 تا 01:59:59 (#1)، …، 23:00:00 تا 23:59:59 (#23). در این مقاله از تعداد بخش های زمانی برای توصیف واژه رکوردهای نمونه برداری پراکنده از منظر زمانی استفاده شد. سپس، مشترکانی را استخراج کردیم که سوابق آنها تمام 24 بخش زمانی را پوشش می داد.
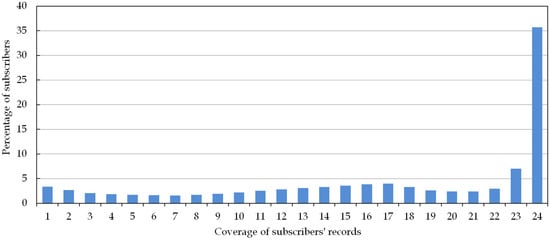
بدیهی است که سوابق موقعیت مکانی تلفن همراه مشترکین مختلف به صورت پراکنده در بخشهای زمانی مختلف توزیع شده است. هرچه بخشهای زمانی کمتری در رکوردهای مشترک باشد، رکوردها از منظر زمانی کمتر میشوند. به عنوان مثال، حدود 3.37 درصد از رکوردهای مشترکان فقط در یک ساعت در روز بوده است و درصد کاربرانی که در 24 بخش موقت رکورد دارند، 35.70 درصد بوده است که به این معنی است که رکوردهای تقریباً 65 درصد از کاربران در کمتر از زمان توزیع شده است. 24 بخش، همانطور که در شکل 4 نشان داده شده است . همچنین سوابق تقریباً 13.18 درصد از کاربران در 6 بخش یا کمتر بوده است. از این رو، این که آیا الگوهای تحرک کاربران را می توان به درستی بدون پوشش فواصل زمانی کافی مشخص کرد، جای سوال دارد.
دادههای 5.8 میلیون مشترک در این تحقیق گنجانده شد، بنابراین میتوان از آن برای بررسی اثرات بخشهای زمانی مختلف در توصیف الگوهای حرکتی انسان استفاده کرد. شاید این مشترکین معمولاً بیشتر از دیگران از تلفن همراه خود استفاده کنند. علاوه بر این، مطالعات قبلی نشان داده اند که کاربران تلفن همراه به طور ناهمگنی در سن، جنسیت و فضا توزیع شده اند [ 19 ، 20 ]. بنابراین، کاربران تلفن همراه در مجموعه دادههای نمونه فرعی ما ممکن است سوگیریهای متفاوتی در این جنبهها داشته باشند، که باید در کارهای آینده بیشتر مورد بررسی قرار گیرد.
4.3. قوانین تصادفی
پس از استخراج 5.8 میلیون مشترک، رکوردهای هر مشترک را به 24 بخش زمانی تقسیم کردیم، همانطور که در شکل 5 نشان داده شده است .
برای بررسی نمایندهگی دادههای مکان تلفن همراه پراکنده در برآورد شاخصهای تحرک فردی، این مطالعه تعداد بخشهای زمانی انتخاب شده را از 2 تا 23 تغییر داد. برای هر تعداد بخش زمانی، انتخاب 100 بار تصادفی شد تا از هر بخش زمانی اطمینان حاصل شود. می تواند انتخاب شود. برای مثال، زمانی که تعداد بخشهای زمانی انتخاب شده دو بود، بخشهای زمانی (#2، #5) یا بخشهای (#3، #9) را میتوان انتخاب کرد. هنگامی که تعداد بخش های زمانی انتخاب شده سه بود، بخش های (#4، #5، #21) یا بخش های (#2، #6، #17) می توانند انتخاب شوند، همانطور که در شکل 6 نشان داده شده است .. علاوه بر این، بخشهای زمانی انتخابشده تکرار نشدند، حتی اگر تعداد بخشهای زمانی یکسان بود. به عنوان مثال، زمانی که تعداد بخشهای زمانی انتخاب شده سه بود، ترکیب بخش (#4، #9، #22) تنها یک بار از بین 100 زمان تصادفی انتخاب شد.
علاوه بر این، برای همان تعداد بخش زمانی، هر بخش باید حداقل پنج بار از هر 100 بار انتخاب شود. به عنوان مثال، در انتخاب دو بخش زمانی، اگر بخش های (#2، #5)، (#2، #7)، (#2، #16)، (#2، #19)، و (#2، #) 23) انتخاب شدند، شماره 2 پنج بار ظاهر شد، اما #5، #7، #16، #19، #23 فقط یک بار ظاهر شد و 18 بخش دیگر ظاهر نشدند. بنابراین، در 95 زمان تصادفی بعدی، توجه بیشتری به 23 بخش دیگر در انتخاب های تصادفی معطوف خواهد شد. این قانون برای کاهش نابرابری در انتخاب هر بخش زمانی طراحی شده است.
هنگامی که 23 بخش زمانی وجود دارد، تنها 24 انتخاب وجود دارد که از میان آنها می توان 23 بخش را انتخاب کرد. هر یک از 5.8 میلیون مشترک که بهطور تصادفی شاخصهای تحرک نمونهگیری شده بودند، با استفاده از تمام سوابق تلفن همراه در بخشهای زمانی انتخاب شده در هر زمان تصادفی محاسبه شد.
4.4. ارزیابی ضریب کم برآوردی کل
برای هر زمان تصادفی، مجموعهای از مقادیر شاخص نمونهگیری شده، مسافت کل سفر نمونهبرداری شده، آنتروپی حرکت نمونهبرداری شده و شعاع چرخش نمونهبرداری شده را با استفاده از رکوردهای نمونهگیری در بخشهای زمانی بهطور تصادفی انتخاب شده برای همه 5.8 میلیون مشترک محاسبه کردیم.
برای تعیین کمیت سطح کم برآورد جمعآوری شده برای بخشهای زمانی نمونهگیری شده در توصیف شاخصهای تحرک انسانی، از مدل رگرسیون خطی استفاده شد [ 26 ].
در اینجا، برای هر زمان تصادفی، هر یک از شاخصهای تحرک محاسبه شده با استفاده از رکوردهای کامل در کل بخشهای زمانی، به عنوان متغیر مستقل x و شاخص تحرک نمونهگیری شده مربوطه به عنوان متغیر وابسته y با استفاده از رکوردها به صورت تصادفی تعریف میشوند. بخش های زمانی انتخاب شده ضریب a رابطه بین شاخص های نمونه برداری شده و کامل همه 5.8 میلیون مشترک را اندازه گیری می کند. در اینجا، b در مدل رگرسیون خطی روی 0 تنظیم شد، زیرا زمانی که شاخص تحرک در یک مجموعه داده معیار کامل 0 باشد، شاخص تحرک در مجموعه داده انتخابی نیز باید 0 باشد. ضریب aبا روش رگرسیون حداقل مربع [ 60 ] کالیبره شده است.
بنابراین، ضریب کم برآورد جمع شده ( uc ) به صورت زیر تعریف می شود:
واضح است که هرچه uc پایین تر باشد، سطح دست کم گرفتن پایین تر است و بخش های زمانی انتخاب شده به طور تصادفی برای مشخص کردن شاخص های تحرک انسانی نماینده تر است. برای مثال، وقتی بخشهای زمانی انتخابشده (#3، #6، #7، #13، #19، و #21) هستند و ضریب بین مسافت کل سفر نمونهبرداری شده و مسافت کامل سفر 0.25 باشد، ضریب کمتخمین جمعآوری شده است. 0.75 است. uc نسبتا زیاد است، به این معنی که بازنمایی این شش بخش زمانی کم است، زیرا کل مسافت سفر محاسبه شده با استفاده از رکوردها در این شش بخش زمانی ممکن است حدود 75٪ کوتاهتر از کل ردپای آنها در منطقه مورد مطالعه باشد .
5. نتایج
5.1. اندازه گیری شاخص های تحرک با انتخاب تصادفی بخش های زمانی
این بخش تفاوتهای مختلف بین شاخصهای تحرک نمونهگیری شده و شاخصهای تحرک کامل را از دیدگاه فردی تحلیل میکند. سپس اثرات کم برآورد کمّی از دیدگاه متوسط مورد بررسی قرار گرفت.
5.1.1. دیدگاه فردی
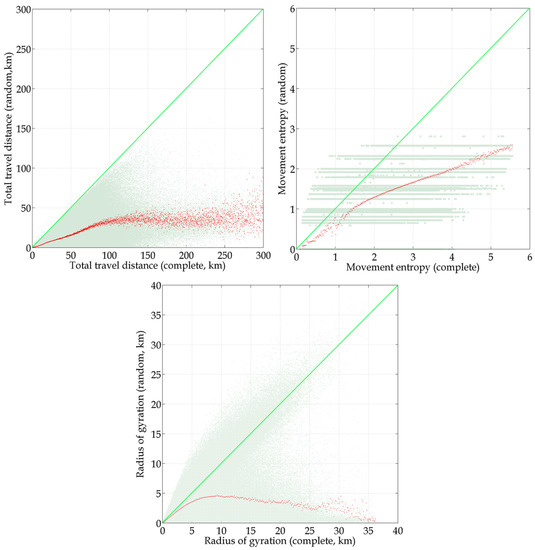
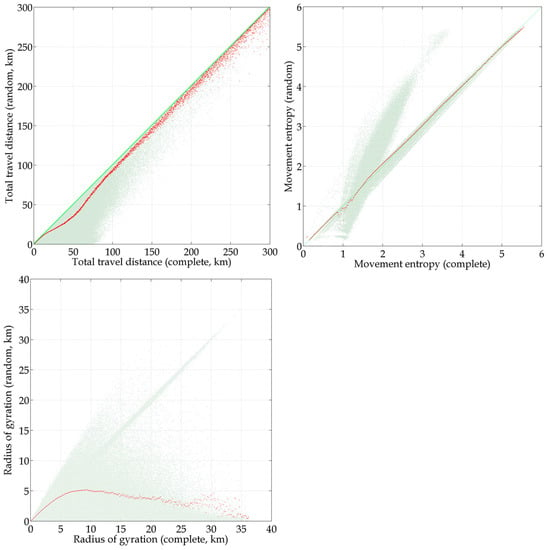
این بخش بر ارزیابی نمایندگی داده های مکان تلفن همراه پراکنده در تجزیه و تحلیل الگوی تحرک روزانه فردی متمرکز است. نمونه هایی از شاخص های تحرک تصادفی و شاخص های تحرک کامل در جدول 2 و شکل 7 ، شکل 8 و شکل 9 نشان داده شده است .
محورهای افقی و عمودی به ترتیب نشاندهندههای تحرک از بخشهای زمانی کامل و تصادفی هستند. اگر پاره های زمانی تصادفی نماینده بخش های زمانی کامل باشند، نقاط شکل 7 ، شکل 8 و شکل 9 باید نزدیک به خط مورب آبی روشن از سمت چپ پایین به سمت راست بالا باشد. همانطور که نقاط خاکستری نشان می دهد، نمایندگی بخش های زمانی مختلف برای تخمین شاخص های تحرک فردی کاملاً متفاوت است. به عنوان مثال، هنگامی که از 10 بخش زمانی استفاده می شود، آنتروپی حرکت فردی برای 32.79٪ از مشترکان بیش از حد تخمین زده می شود و شعاع چرخش فردی برای 19.42٪ از مشترکان بیش از حد برآورد می شود.
مسافت تصادفی کل سفر را نمی توان بیش از حد تخمین زد زیرا رکوردهای کمتر به دلیل اصل مثلث منجر به مسافت کل سفر کوتاه تر می شود. با این حال، آنتروپی حرکت و شعاع چرخش میتواند برای افراد مختلف به دلیل استفاده از رکوردهای بخشهای زمانی مختلف در محاسبه، دستکم یا بیشازحد برآورد شود. سطح متوسط اغلب برای توصیف توزیع پهنای باند مربوطه استفاده می شود [ 4 ، 26 ، 37 ، 38 ]. سطح متوسط برآورد به شرح زیر مورد مطالعه قرار گرفت.
5.1.2. دیدگاه متوسط
در شکل 7 ، شکل 8 و شکل 9 ، انحرافاتی بین نقاط قرمز و خط مورب آبی وجود دارد که نشان میدهد استفاده از بخشهای زمانی داده مکان تلفن همراه کمتر باعث دست کم گرفتن مسافت کل سفر، آنتروپی حرکت و شعاع چرخش میشود. یک دیدگاه متوسط که از جدول 2 نیز قابل مشاهده است .
از منظر متوسط، ضریب دست کم برآورد کل مسافت سفر 0.86 است ( R2 = 0.291، خوبی تناسب [ 61 ]) زمانی که 3 بخش زمانی وجود دارد . هنگامی که از 10 بخش زمانی استفاده می شود، ضریب کم برآورد 0.52 است ( R2= 0.894). مسافت کل سفر نمونه برداری شده معمولاً بیش از حد تخمین زده نمی شود زیرا رکوردهای کمتر منجر به مسافت کل سفر کوتاه تر می شود. با افزایش تعداد بخش های زمانی، انحرافات کمتری از خط مورب آبی برای کل مسافت سفر وجود دارد. برعکس، تغییر در میانگین مسافت کل سفر زمانی افزایش مییابد که مسافت کامل سفر افزایش مییابد. به عنوان مثال، زمانی که مسافت کل کامل سفر برای 10 بخش زمانی 100 کیلومتر باشد، مسافت سفر تصادفی تقریباً 65 کیلومتر است اما زمانی که مسافت کامل سفر 200 کیلومتر باشد، مسافت تصادفی کل سفر بین 70 کیلومتر تا 140 کیلومتر است. این احتمالاً به این دلیل است که با افزایش مسافت کل سفر، تعداد مشترکین به سرعت کاهش مییابد و به این دلیل که رکوردهای مکان در برخی بخشهای زمانی از سایر بخشهای زمانی دور هستند.
مسافت کل سفر می تواند بیشتر از 70 کیلومتر باشد که توسط مشترکانی مانند رانندگان تاکسی یا اتوبوس، تحویل دهنده بسته و گردشگران ایجاد شده است. این مشترکین کمتر از 2.0 درصد از 5.8 میلیون مشترک را تشکیل می دهند. الگوی جالب دیگر این است که محدوده میانگین مسافت کل سفر در هنگام استفاده از 23 بخش زمانی باریک تر باشد. این عمدتاً به این دلیل است که زمان های تصادفی کمتری وجود دارد و رکوردهای انتخاب شده بسیار نزدیک به کل رکوردهای هر فرد است.
آنتروپی حرکت را می توان برای افراد مختلف به دلیل محاسبه با استفاده از رکوردهای بخش های زمانی مختلف، دست کم تخمین زد یا دست کم گرفت. با این حال، از دیدگاه متوسط، روند کاهشی ضریب کم برآوردی در تخمین آنتروپی حرکت را می توان از شکل 7 ، شکل 8 و شکل 9 مشاهده کرد . هنگامی که از 3 بخش زمانی استفاده می شود، ضریب دست کم برآورد آنتروپی حرکت 0.49 است ( R2 = 0.943)، اما زمانی که از 10 بخش زمانی استفاده می شود، ضریب کم برآورد 0.18 است ( R2 ) .= 0.986)، که بسیار نزدیک به 0 است. علاوه بر این، هنگامی که از 23 بخش زمانی استفاده می شود، نقاط به خط مورب آبی نزدیک می شوند و ضریب دست کم گرفتن فقط 0.01 است، به این معنی که رکوردهای این 23 بخش زمانی می توانند کامل را نشان دهند. آنتروپی حرکت به طور کامل
برخلاف مسافت کل سفر و آنتروپی حرکت، توزیع میانگین تصادفی شعاع چرخش همیشه با شعاع کامل چرخش افزایش نمییابد. همانطور که در شکل 7 ، شکل 8 و شکل 9 نشان داده شده است، میانگین تصادفی شعاع چرخش افزایش می یابد تا زمانی که شعاع کامل چرخش تقریباً 9 کیلومتر باشد. سپس، اگرچه شعاع چرخش کامل افزایش مییابد، اما میانگین شعاع تصادفی چرخش کاهش مییابد. بنابراین از مدل رگرسیون خطی در فاصله 9 کیلومتری استفاده می شود. برای تخمین شعاع چرخش، سوابق ناقص مکان تلفن همراه احتمالاً در بیشتر موارد برای تجزیه و تحلیل سفر مشترک در محدوده فعالیت روزانه معمولی، یعنی کمتر از 9 کیلومتر کافی است.
علاوه بر این، برای مشترکینی که شعاع چرخش کامل آنها بیشتر از 9 کیلومتر است، به دلیل از دست دادن برخی از مکان های مسافت طولانی، میانگین شعاع چرخش تصادفی اغلب صفر یا بسیار نزدیک به صفر است. این مشترکین کمتر از 7.0 درصد از کل مشترکین معتبر را تشکیل می دهند، معمولاً در جهات مختلف سفر می کنند و احتمالاً در محدوده وسیعی سفر می کنند. بنابراین، فقدان هر بخش زمانی بین 8 صبح تا 8 بعد از ظهر ممکن است به طور قابل توجهی بر شعاع چرخش تأثیر بگذارد. هویت اجتماعی این مشترکین ممکن است رانندگان تاکسی یا Uber/Didi، تحویلدهنده بستهها یا گردشگران باشد. بنابراین، دادههای موقعیت مکانی تلفن همراه ممکن است شعاع چرخش مشترکینی را که محدوده فعالیت آنها بسیار وسیع است (یعنی بیش از 9 کیلومتر) به طور قابل توجهی دست کم بگیرد. علاوه بر این،
مهمتر از همه، حتی استفاده از بخشهای زمانی زیاد میتواند شعاع چرخشی بسیار کوچکتری ایجاد کند، که نشان میدهد یک مسیر ناقص برای استخراج محدوده فضای فعالیت روزانه مورد سوال باقی میماند.
استفاده از رکوردهای مکان تلفن همراه از تعداد مختلف بخش های زمانی می تواند نتایج بسیار متفاوتی در توزیع کل مسافت سفر، آنتروپی حرکت و شعاع چرخش ایجاد کند که به ترتیب نشان دهنده فاصله، برد و ناهمگونی الگوهای تحرک فردی است. بنابراین، معرف بودن داده های مکان تلفن همراه باید قبل از استفاده از آن برای پاسخ به سوالات مختلف تحقیق مورد بررسی قرار گیرد. در مرحله بعد، ما با استفاده از ضریب کمتر برآوردی از دیدگاه متوسط، مقایسه جامعی از نمایندگی تعداد مختلف بخشهای زمانی و تعداد مشابه بخشهای زمانی با شکافهای زمانی متفاوت ارائه میکنیم.
5.2. تحلیل کمی ضریب دست کم برآورد مسافت کل سفر
برای ارزیابی بازنمایی تعداد بخشهای زمانی مختلف و تعداد یکسان بخشهای زمانی با اسلاتهای مختلف، تعداد بخشهای زمانی انتخابی را از 2 تا 23 تغییر دادیم. برای هر تعداد بخش زمانی، انتخاب را 100 بار تصادفی کردیم، به جز برای زمانی که از 23 بخش زمانی استفاده شد. برای هر زمان تصادفی، میتوانیم مجموع ضریب کم برآورد مسافت سفر را محاسبه کنیم. توزیع ضرایب کم برآورد برای تخمین مسافت کل سفر در شکل 10 نشان داده شده است .
اولاً، واضح است که حتی با تعداد یکسانی از بخش های زمانی، ضریب دست کم گرفتن می تواند کاملاً متفاوت باشد. به عنوان مثال، زمانی که از 4 بخش زمانی استفاده می شود، ضریب کم برآورد از 0.77 تا 0.90 متغیر است و زمانی که از 18 بخش زمانی استفاده می شود، ضریب کم برآورد بین 0.19 و 0.26 است. این الگوها نشان میدهند که سوابق مکان در بخشهای زمانی مختلف، نمایندگی متفاوتی برای توصیف مسافت کل سفر در تحقیقات تحرک انسانی دارند. درک این موضوع در زمینه فعالیتهای انسانی نسبتاً آسان است: اگر بخشهای زمانی انتخابشده عمدتاً به فعالیت خانه مربوط باشد، مسافت کل سفر کوتاهتر و ضریب دستکمبینی بیشتر میشود، اما اگر بخشهای زمانی انتخابشده خانه را پوشش دهد. و فعالیت کاری،
دوم، الگوی جالب دیگر این است که، با افزایش تعداد بخش های زمانی انتخاب شده، ضریب دست کم گرفتن به طور قابل توجهی کاهش می یابد. متوسط ضریب دست کم گرفتن زمانی که از 2 بخش زمانی استفاده می شود 0.93 است و در صورت استفاده از 23 بخش زمانی به 0.04 کاهش می یابد. با برازش یک مدل رگرسیون خطی دیگر با یک فاصله، روند نزولی تقریباً خطی است ( R2 = 0.99) و n تعداد بخش های زمانی را نشان می دهد .
تعیین اینکه دادههای مکان تلفن همراه برای تخمین مسافت کل سفر با استفاده از این مدل چقدر است، آسان است. به عنوان مثال، اگر سوابق هر فرد فقط هشت بخش زمانی را پوشش دهد، مسافت کل سفر ممکن است تقریباً 60٪ کمتر از کل ردپای آنها در منطقه مورد مطالعه باشد.
5.3. تحلیل کمی ضریب کم برآورد آنتروپی حرکت
به طور مشابه، ما می توانیم یک ضریب کم برآورد آنتروپی حرکت را برای هر زمان تصادفی محاسبه کنیم. توزیع ضرایب کم برآوردی تجمعی برای تخمین آنتروپی حرکت در شکل 11 نشان داده شده است .
همانطور که در توزیع ضریب کمتر برآوردی برای تخمین مسافت کل سفر، بدیهی است که حتی با تعداد واحدهای زمانی یکسان، ضریب کم برآورد می تواند کاملاً متفاوت باشد. به عنوان مثال، زمانی که از 7 بخش زمانی استفاده می شود، ضریب کم برآورد از 0.24 تا 0.39 متغیر است. درک این الگو آسان است زیرا ممکن است مکانهای جدیدی وجود داشته باشد یا تعداد بازدید از برخی مکانها ممکن است در بخشهای زمانی مختلف تغییر کند. علاوه بر این، با افزایش تعداد بخشهای زمانی، دامنه ضریب کم برآوردی باریکتر خواهد بود. به عنوان مثال، زمانی که از 4 بخش زمانی استفاده می شود، ضریب کم برآورد از 0.39 تا 0.68 متغیر است و زمانی که از 18 بخش زمانی استفاده می شود، ضریب کم برآورد بین 0.02 و 0.10 است.
الگوی جالب دیگر این است که با افزایش تعداد بخش های زمانی انتخاب شده، ضریب دست کم گرفتن تمایل به کاهش دارد. روند را می توان با یک مدل رگرسیون لگاریتمی با یک برازش برازش داد ( R2 = 0.99، n تعداد بخش های زمانی است).
با استفاده از این مدل میتوانیم به راحتی نمایندگی دادههای مکان تلفن همراه را برای تخمین آنتروپی حرکت تعیین کنیم. به عنوان مثال، اگر رکوردهای هر فرد فقط هشت بخش زمانی را پوشش دهد، ضریب کم برآورد تقریباً 0.25 است، بنابراین میانگین آنتروپی حرکت ممکن است تقریباً 25٪ کمتر از کل ردپای آنها در منطقه مورد مطالعه باشد.
5.4. تحلیل کمی ضریب کم برآورد شعاع چرخش
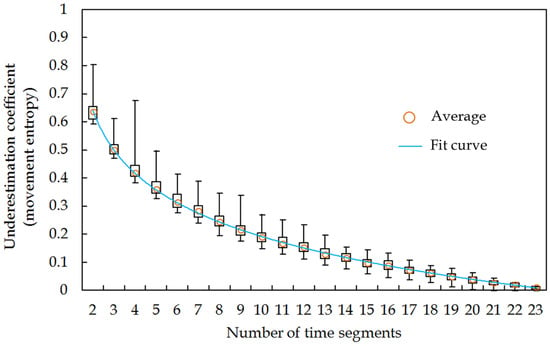
به طور مشابه، میتوانیم برای هر زمان تصادفی یک ضریب کمتخمین شعاع چرخش را محاسبه کنیم. توزیع ضرایب کم برآوردی تجمعی برای تخمین شعاع چرخش در شکل 12 نشان داده شده است .
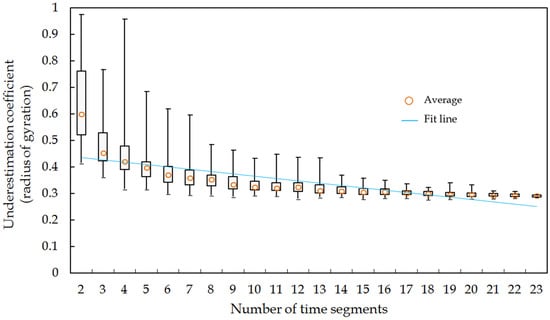
همانطور که در بخش 5.1.2 تفسیر شد، برای تخمین شعاع چرخش، سوابق ناقص مکان تلفن همراه احتمالاً در اکثر موارد به اندازه کافی خوب است تا مشترکین را در محدوده فعالیت روزانه عادی، مانند کمتر از 9 کیلومتر، تجزیه و تحلیل کند. بنابراین در این بخش عمدتاً بر شعاع چرخش کمتر از 9 کیلومتر تمرکز می کنیم.
بدیهی است، حتی با تعداد واحدهای زمانی یکسان، ضریب کم برآوردی می تواند کاملاً متفاوت باشد. به عنوان مثال، هنگامی که از 4 بخش زمانی استفاده می شود، ضریب کم برآورد از 0.31 تا 0.97 متغیر است. درک این الگو آسان است، زیرا ممکن است مکانهای جدیدی به دلیل بخشهای زمانی مختلف وجود داشته باشد. علاوه بر این، با افزایش تعداد بخشهای زمانی، دامنه ضریب کم برآوردی باریکتر خواهد بود. به عنوان مثال، زمانی که از 3 بخش زمانی استفاده می شود، ضریب کم برآورد از 0.36 تا 0.77 متغیر است و زمانی که بیش از 15 بخش زمانی استفاده می شود، ضریب کم برآورد بین 0.28 تا 0.35 است.
روند نزولی را می توان با یک مدل رگرسیون خطی با یک برش برازش داد ( R2 = 0.63، n تعداد بخش های زمانی است)، ما به راحتی می توانیم تعیین کنیم که داده های مکان تلفن همراه برای تخمین شعاع چرخش در 9 کیلومتر چقدر نماینده است . با استفاده از این مدل بر خلاف مسافت کل سفر و آنتروپی حرکت ، خوبی تناسب ( R2 ) تنها 0.63 است.
شعاع چرخش احتمالاً با بخشهای زمانی انتخابشده کمتر نامشخصتر است. همانطور که از شکل 12 مشاهده می شود ، ضریب متوسط دست کم گرفتن بیشتر از 0.29 است حتی زمانی که از 23 بخش زمانی استفاده می شود، به این معنی که هر تعداد بخش زمانی نمونه برداری شده می تواند محدوده سفر روزانه را حداقل 29٪ کوتاهتر از کل ردپای آنها نشان دهد. در منطقه مورد مطالعه علاوه بر این، همانطور که در بخش 5.1.2 تفسیر شده است، برای مشترکینی که محدوده فعالیت آنها بیشتر از 9 کیلومتر است، شعاع چرخش نمونه برداری شده اغلب می تواند به دلیل عدم وجود نقطه مکانی دورتر بسیار کمتر باشد. این همچنین نشان میدهد که شعاع چرخش ممکن است مناسبترین اندازهگیری برای مشخص کردن محدوده تحرک انسان با استفاده از دادههای مکان نمونهبرداری شده پراکنده، مانند دادههای مکان تلفن همراه نباشد. بنابراین، ما به محققان پیشنهاد میکنیم از شاخصها با احتیاط برای تفسیر نتایج به دست آمده از دادههای مکان نمونهبرداری شده استفاده کنند.
در نهایت، بر اساس نتایج و توزیع مشترکین در شکل 4 ، اگر یک نمونه واقعی از افراد ردیابی شده توسط تلفن همراه داده شود و فرض کنیم که uc برای 24 بخش زمانی 0 است، سطوح کم برآورد وزنی کل مسافت سفر، آنتروپی حرکت، و شعاع چرخش در این منطقه به ترتیب حدود 23، 11 و 21 درصد است.
6. نتیجه گیری
در این مقاله، ما نمایندگی دادههای مکان تلفن همراه پراکنده را در توصیف شاخصهای تحرک، که برای اندازهگیری محدوده فضای فعالیت، فاصله سفر و ناهمگونی الگوهای بازدید در فضای فعالیت استفاده میشوند، بررسی کردیم. سهم این مطالعه سه مورد است:
اولاً، مطالعه موردی نشان میدهد که بازنمایی تخمینهای شاخصهای تحرک انسانی برای هر فرد میتواند منجر به دستکم یا تخمینزدایی شود. با این حال، از دیدگاه متوسط [ 4 ، 26 ، 37 ، 38 ]، زمانی که با تمام رکوردها مقایسه می شود، داده های ناقص موقعیت مکانی تلفن همراه تمایل به دست کم گرفتن شاخص های تحرک، مانند میانگین مسافت کل سفر و آنتروپی حرکت دارند. علاوه بر این، دست کم گرفتن میانگین شعاع چرخش قابل توجه تر می شود. بازنمایی داده های تلفن همراه نیز به رکوردها در بخش های زمانی مختلف بستگی دارد.
ثانیا، این مطالعه به طور کمی نماینده بخش های زمانی انتخاب شده به طور تصادفی از مجموعه داده های معیار را در توصیف شاخص های تحرک انسانی ارزیابی می کند. ضریب کم برآورد جمعی برای تخمین مسافت کل سفر به صورت خطی با افزایش تعداد بخشهای زمانی کاهش مییابد. برای مثال، اگر سوابق هر فرد تنها 33 درصد از مسیر را پوشش دهد، مسافت کل سفر ممکن است به طور متوسط تقریباً 60 درصد کمتر از کل ردپای آنها در منطقه مورد مطالعه باشد. نتایج ضریب کم برآوردی جمعآوری شده برای تخمین آنتروپی حرکت به صورت لگاریتمی با افزایش تعداد بخشهای زمانی کاهش مییابد. به عنوان مثال، اگر رکوردهای هر فرد فقط 33٪ از مسیر را پوشش دهد، ضریب کم برآوردی کل تقریباً 0.25 است.
در نهایت، اثرات دست کمگرفتن میتواند برای شعاع چرخش بسیار قابلتوجه باشد، و میانگین ضریب کمتر برآوردی حتی زمانی که از 23 بخش زمانی استفاده میشود، بیشتر از 0.29 است، که به این معنی است که دادههای موقعیت مکانی تلفن همراه ناقص میتواند میانگین سفر روزانه را تقریباً 29 درصد کوتاهتر نشان دهد. از مجموع ردپای آنها در منطقه مورد مطالعه. این ممکن است نشان دهد که شعاع چرخش باید با احتیاط استفاده شود، زیرا با استفاده از داده های مکان نمونه برداری شده پراکنده، مانند داده های موقعیت مکانی تلفن همراه، به راحتی آن را دست کم گرفته می شود. با این حال، یافتههای ما ممکن است به دلیل محیطهای شهری متفاوت و عادات استفاده از تلفن همراه در شهرهای دیگر قابل اجرا باشد یا نباشد.
این مطالعه یک روش جایگزین برای ارزیابی نمایندگی داده های مکان تلفن همراه برای تحقیقات تحرک انسانی ارائه می دهد. روش پیشنهادی در این مقاله همچنین میتواند برای دادههای درشت مانند دادههای ورود به شبکههای اجتماعی با برچسب جغرافیایی استفاده شود. با استفاده از رویکرد تحقیقی در اینجا، محققان می توانند نقاط قوت و محدودیت های داده های خود را برای کمک به استخراج نتایج معقول درک کنند. با این حال، ما چندین محدودیت و چالش خاص برای دادههای مکان نمونهبرداری پراکنده، مانند:
- (1)
-
عادات استفاده از تلفن همراه؛ شکل 4 نشان می دهد که پوشش زمانی سوابق مشترکین عمدتاً نسبتاً کم است که ممکن است به عادات استفاده از تلفن همراه مشترکان مربوط باشد. بنابراین اگر مشترکین زیاد سفر می کنند اما به ندرت تلفن همراه خود را می گیرند، ضریب دست کم گرفتن ممکن است در داده های موقعیت مکانی تلفن همراه نمونه غیرتصادفی بالاتر باشد.
- (2)
-
سوگیری استفاده از نمونه های فرعی به جای مجموعه داده های کامل. کاربران تلفن همراه در مجموعه دادههای نمونه فرعی ممکن است سوگیریهای متفاوتی در جنسیت، سن یا جغرافیا داشته باشند [ 19 ، 20 ]. ما اثرات این سوگیری را در توصیف الگوهای تحرک انسانی در مطالعه آینده بیشتر بررسی خواهیم کرد.







بدون نظر