

خلاصه
نظارت، پاسخ، کاهش و ارزیابی آسیب بلایا، تقاضاهای متنوعی را بر روی وضوح مکانی و زمانی تصاویر سنجش از دور ایجاد می کند. تصاویر بر اساس منابع داده یا وضوح تصویر به اهرام کاشی تقسیم می شوند و به عنوان خدمات تصویر مستقل برای تجسم منتشر می شوند. یک منطقه متاثر از فاجعه معمولاً توسط چندین لایه تصویر پوشانده می شود تا اطلاعات سطح سلسله مراتبی را بیان کند، که مقدار زیادی کاشی همنام از لایه های مختلف ایجاد می کند که یک مکان را پوشش می دهند. روش سنتی بازیابی کاشی برای تجسم نمی تواند بین لایه های متمایز تمایز قائل شود و تمام مجموعه داده های تصویر را برای هر پرس و جو کاشی طی می کند. این فرآیند پرس و جوهای اضافی و دسترسی نامعتبر ایجاد می کند که می تواند به طور جدی بر عملکرد تجسم کلاینت ها، سرورها و انتقال شبکه تأثیر بگذارد. این مقاله یک روش بازیابی بر اساس تقاضا برای تصاویر چند لایه پیشنهاد میکند و حاشیهنویسی معنایی را برای غنیسازی توصیف هر مجموعه داده تعریف میکند. این روش با تطبیق خواسته های تجسم با اطلاعات معنایی مجموعه داده ها، به طور خودکار لایه های نامناسب را فیلتر کرده و مناسب ترین لایه را برای پرس و جوی کاشی نهایی پیدا می کند. طراحی و پیاده سازی بر اساس معماری پایگاه داده دو لایه NoSQL است که بهینه سازی زمان بندی و قابلیت پردازش همزمان را فراهم می کند. نتایج تجربی نشان دهنده اثربخشی و پایداری رویکرد برای بازیابی چند لایه در تجسم کاهش فاجعه است. این روش با تطبیق خواسته های تجسم با اطلاعات معنایی مجموعه داده ها، به طور خودکار لایه های نامناسب را فیلتر کرده و مناسب ترین لایه را برای پرس و جوی کاشی نهایی پیدا می کند. طراحی و پیاده سازی بر اساس معماری پایگاه داده دو لایه NoSQL است که بهینه سازی زمان بندی و قابلیت پردازش همزمان را فراهم می کند. نتایج تجربی نشان دهنده اثربخشی و پایداری رویکرد برای بازیابی چند لایه در تجسم کاهش فاجعه است. این روش با تطبیق خواسته های تجسم با اطلاعات معنایی مجموعه داده ها، به طور خودکار لایه های نامناسب را فیلتر می کند و مناسب ترین لایه را برای پرس و جو نهایی کاشی پیدا می کند. طراحی و پیاده سازی بر اساس معماری پایگاه داده دو لایه NoSQL است که بهینه سازی زمان بندی و قابلیت پردازش همزمان را فراهم می کند. نتایج تجربی نشان دهنده اثربخشی و پایداری رویکرد برای بازیابی چند لایه در تجسم کاهش فاجعه است.
کلید واژه ها:
بر حسب تقاضا ؛ چند لایه ؛ توصیف معنایی ; NoSQL ; تجسم کاهش فاجعه
1. معرفی
پیشرفتهای سریع در سیستمهای رصد زمین منجر به حجم زیادی از دادههای سنجش از راه دور شده است که میتوانند در پایش بلایا، واکنش، کاهش و بازیابی استفاده شوند [ 1 ، 2 ، 3 ]. این داده ها در کاربرد فناوری اطلاعات جغرافیایی برای کاهش بلایا قابل توجه هستند. علاوه بر این، چنین سیستم هایی می توانند برای بازیابی تصاویر با وضوح مکانی بالا و ایجاد پوشش جهانی زمین دیجیتال از طریق فناوری سنجش از دور هوافضا استفاده شوند [ 4 ، 5 ، 6 ، 7 ].
تصاویر سنجش از راه دور نقش مهمی در فرآیند کاهش بلایا دارند زیرا اطلاعات مربوط به فضایی را به شیوه ای مستقیم و شهودی ارائه می دهند [ 8 ]. بر اساس سیستم شبکه جهانی گسسته [ 9 ]، تصاویر مشاهده شده معمولاً به صورت کاشی بریده می شوند و در مدل های هرمی گنجانده می شوند تا خدمات داده گسترده ای را برای هر مرحله از مدیریت بلایا ارائه دهند. به عنوان مثال، لایههای تصویر با وضوح بالا بهطور گسترده به عنوان نقشههای پایه برای ترسیم مشترک [ 10 ] و استخراج ویژگی [ 1 ] در فرآیندهای کاهش بلایا [ 11 ] استفاده میشوند.
لایه تصویر یک هرم کاشی کامل یا جزئی پیوسته است که از مجموعه ای از تصاویر ساخته شده است. کاشی های سطوح یا نواحی مختلف هرم را می توان از منابع تصویری مختلف برش داد. با استفاده از نقشه های گوگل به عنوان مثال، کاشی های آن از QUICKBIRD، LANDSAT، IKONOS و سایر حسگرهای ماهواره ای سرچشمه می گیرند [ 12 ، 13 ]. هر کاشی در یک لایه خاص منحصر به فرد است و کدگذاری آن نشان دهنده یک مکان فضایی سه بعدی در سطح زمین است.
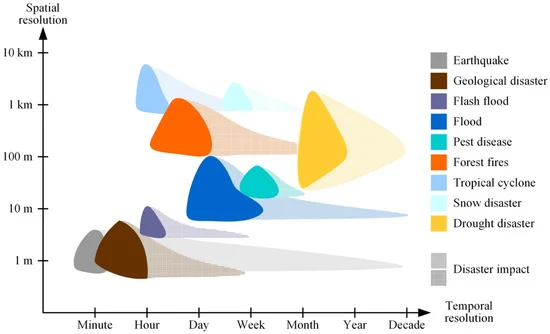
در فرآیند کاهش بلایا، تقاضا برای لایههای تصویر متنوع است و همیشه در حال تغییر است. با استفاده از هشدار بلایا به عنوان مثال، نظارت بر بلایای مختلف با الزامات متمایز در رابطه با وضوح مکانی و زمانی تصاویر سنجش از راه دور مشاهده شده همراه است ( شکل 1 را ببینید ). علاوه بر این، وظایف مختلف در یک فرآیند کاهش فاجعه نیازهای متفاوتی را در مورد مقیاسهای زمانی و وضوح تصویر ایجاد میکند [ 14]]. در یک تجسم کامل کاهش فاجعه، صحنه فاجعه همچنان به کاشیهای تصویر مختلفی دسترسی پیدا میکند که با توجه به وضوح زمانی و مکانی متفاوت هستند تا درجات مختلفی از تشخیص ویژگیهای زمین را برآورده کنند. به عنوان مثال، در فرآیند کاهش سیل، تجسم محیطی فاجعه اساسی به وضوح فضایی 1 کیلومتری برای نظارت روزانه نیاز دارد [ 15 ]. علاوه بر این، تفکیک فضایی 5 متر تا 10 متر برای استخراج آب در فاز پاسخ [ 1 ] و وضوح زیر متر برای استخراج ساختمان های متاثر از سیل در مرحله ارزیابی تلفات مورد نیاز است [ 16] .]. این تصاویر معمولاً در طول هر مرحله از کاهش بلایا به طور مداوم قابل دسترسی هستند. بنابراین، سازماندهی آنها در یک مجموعه داده مبتنی بر هرم دشوار است. بنابراین، بسیاری از مجموعه داده ها به طور مستقل برای وظایف مختلف کاهش بلایا ذخیره می شوند. هنگامی که یک فاجعه رخ می دهد، تصاویر مشاهده شده در زمان واقعی به دست می آیند و برای ساختن اهرام جدید استفاده می شوند. سپس لایههای تصویری جدیدی منتشر میشوند که علاوه بر لایههای تصویر تاریخی، مناطق تخریبشده را با وضوحهای مکانی و زمانی متفاوت نشان میدهند.
با پیشرفت در مطالعات کاهش بلایا، تعداد فزایندهای از خدمات تصویر سنجش از دور در مناطق آسیبدیده از بلایا همپوشانی دارند. بنابراین، کاشیهایی که نام یکسانی دارند اما از مجموعه دادههای متفاوتی هستند، در فرآیند بازیابی، انتقال و تجسم کاشی اضافی ایجاد میکنند. این مقاله یک روش بازیابی بر اساس تقاضای ترکیبی مبتنی بر NoSQL را برای رسیدگی به این ناکارآمدی در خدمات کاشی تصویر چند لایه پیشنهاد میکند. این روش دوگانه است. اول، یک مدل توصیف لایه بر اساس معناشناسی ارائه میکند، که برای نمایش اطلاعات دادههای بیشتر و ایجاد همبستگی بر اساس خواستههای وظیفه استفاده میشود. در فرآیند بازیابی، این روش به طور خودکار لایههای نامربوط را فیلتر میکند و با تطبیق اطلاعات معنایی مجموعه دادهها با تقاضای تجسم در زمان واقعی، مناسبترین لایهها را برای بازیابی کاشی انتخاب میکند. هدف دوم اجرای مدل توصیف و فرآیند انتخاب کاشی بر اساس معماری پایگاه داده دو لایه NoSQL است. یک پایگاه داده توزیع شده در حافظه به عنوان اولین لایه برای کش کاشی و یک پایگاه داده سند به عنوان لایه دوم برای ذخیره سازی موثر و پرس و جوی بسیاری از کاشی ها استفاده می شود. علاوه بر این، در سطح انتقال، پروتکل HTTP/2.0 برای ارتقای کارایی زمانبندی کاشی به کار گرفته شده است. یک پایگاه داده توزیع شده در حافظه به عنوان اولین لایه برای کش کاشی و یک پایگاه داده سند به عنوان لایه دوم برای ذخیره سازی موثر و پرس و جوی بسیاری از کاشی ها استفاده می شود. علاوه بر این، در سطح انتقال، پروتکل HTTP/2.0 برای ارتقای کارایی زمانبندی کاشی به کار گرفته شده است. یک پایگاه داده توزیع شده در حافظه به عنوان اولین لایه برای کش کاشی و یک پایگاه داده سند به عنوان لایه دوم برای ذخیره سازی موثر و پرس و جوی بسیاری از کاشی ها استفاده می شود. علاوه بر این، در سطح انتقال، پروتکل HTTP/2.0 برای ارتقای کارایی زمانبندی کاشی به کار گرفته شده است.
ادامه این مقاله به شرح زیر سازماندهی شده است. بخش 2 مفهوم همپوشانی هرم چند لایه و الزامات تجسم را معرفی می کند. در بخش 3 ، مدل معنایی و جریان تطبیق کاشی بر اساس تقاضا ارائه شده است، در حالی که بخش 4 طراحی پایگاه داده دو لایه و اجرای آن را معرفی می کند. بخش 5 آزمایش را ارائه می کند. ارزیابی عملکرد و بحث مرتبط در بخش 6 ارائه شده است . در نهایت، بخش 7 نتیجه گیری را ارائه می دهد.
2. زمینه و انگیزه
هرم جهانی با وضوح چندگانه یک مدل شبکه جهانی گسسته است که یک تقسیم سلسله مراتبی از سطح زمین را تعریف می کند [ 17 ، 18 ]. بسیاری از روشهای تقسیمبندی در ادبیات ارائه شدهاند، مانند چهار درخت کروی [ 19 ]، مدل ISEA، QTM و مدل طول و عرض جغرافیایی. مدل طول و عرض جغرافیایی کاربردی ترین مدل تقسیم در کاربردهای واقعی است زیرا ساختار به راحتی قابل درک و قابل اجرا برای کاربران برای مدیریت تصاویر در مقیاس بزرگ و با وضوح چندگانه و مکان یابی هر فضای شبکه ثابت با اعمال قوانین تقسیم زیر است [ 20 ] :
-
سطح زمین به یک مستطیل منظم تبدیل می شود که از 180- تا 180 درجه در طول جغرافیایی و 90- تا 90 درجه در عرض جغرافیایی متغیر است. مقادیر خارج از این منطقه نامعتبر است.
-
دهانه کاشی در سطح هرم k دو برابر سطح K + 1 است. هرم جهانی از سطح 0 شروع می شود که دارای دو کاشی است که دهانه های هر کدام 180 درجه است.
-
نسبت تعداد کاشی های هرمی بین جهت عرضی و عمودی 2:1 در هر سطح هرم است.
-
ترتیب کدگذاری کاشی های هرمی از غرب به شرق و از جنوب به شمال در هر سطح هرمی شروع می شود.
-
ترتیب کدگذاری برای سطوح هرمی از بالا به پایین شروع می شود.
-
هنگامی که موقعیت جغرافیایی و ارتفاع به صورت جهانی مشخص می شود، کاشی به دست آمده منحصر به فرد است.
بر اساس قوانین، هر تصویری با یک مرجع جغرافیایی می تواند در مدل شبکه جهانی نگاشت شود. علاوه بر این، تصویر را می توان به یک هرم محلی مستقل برش داد ( شکل 2 را ببینید ). حداکثر سطح هرم محلی بر اساس وضوح فضایی تصویر تعیین می شود. فرض کنید اندازه پیکسل تصویر s × t باشد . سپس، قدرت تفکیک مکانی کاشیها ( f ( l )) در سطح l را میتوان به صورت زیر محاسبه کرد (برای مثال جهت طول جغرافیایی).
fایکس( l ) = 180.0 / (2ل× s )�ایکس(ل)=180.0/(2ل×س)
فرض کنید ناحیه فضایی تصویر A و ماتریس پیکسل آن m × n باشد . سپس، وضوح فضایی تصویر ( r ( x )) را می توان (برای مثال جهت طولی) به صورت زیر تعریف کرد:
r ( x ) = ( A .ایکسساعت– A. _ایکستی) / m ; r ( y) = ( الف .yساعت– A. _yتی) / م�(ایکس)=(آ.ایکسساعت–آ.ایکستی)/متر;�(�)=(آ.�ساعت–آ.�تی)/متر
جایی که ( ایکستیایکستی، yتی�تی) و ( ایکسساعتایکسساعت، yساعت�ساعت) به ترتیب حداقل و حداکثر مختصات ناحیه A هستند . بنابراین، حداکثر سطح هرم محلی ( لm a xلمترآایکس) را می توان بر اساس معادلات (1) و (2) محاسبه کرد.
لm a x= m a x {∣∣∣l og2180.0r ( x ) × s∣∣∣، ∣∣∣l og2180.0r ( y) × t∣∣∣}لمترآایکس=مترآایکس{|ل��2180.0�(ایکس)×س|، |ل��2180.0�(�)×تی|}
بنابراین، یک کاشی منحصر به فرد را می توان بر اساس سطح، ستون و شماره ردیف محاسبه کرد. علاوه بر این، اگر طول و عرض جغرافیایی ( x ، y ) داده شود، کدگذاری کاشی مرتبط ( X ، Y ) در هر سطح از هرم قابل بازیابی است.
ایکس=∣∣∣x + 180fایکس( ل )∣∣∣، ی =∣∣∣y+ 180fy( ل )∣∣∣ایکس=|ایکس+180�ایکس(ل)|، �=|�+180��(ل)|
واضح است که وقتی لایه هرم تک است، تجسم کاشی ساده است زیرا نتیجه بازیابی بر اساس فرمول های فوق منحصر به فرد است. با این حال، در برنامههای کاهش بلایا، هرمهای متعددی در همان منطقه آسیبدیده از بلایا تولید و روی هم قرار میگیرند. هر لایه جدید یک زیرهرم مستقل از یک منبع داده مربوطه است. همانطور که در شکل 3 نشان داده شده استلایههای A، B و C در هرمهای سطح k، k + 1 و k + 2 در یک منطقه همپوشانی دارند، که کاشیهای همنام را تولید میکند که متعلق به لایههای مربوطه در این سطوح است. هنگامی که بازیابی دیدگاه برای کاشی در این منطقه استفاده می شود، نمی تواند کاشی های همنام را از این لایه ها تشخیص دهد. دسترسی مکرر به کاشی و بارگذاری منجر به سردرگمی بصری و ناپیوستگی در صحنه های تازه شده می شود و منابع بیشتری در سرورها و انتقال هدر می رود.
روش سنتی بازیابی کاشی به سمت یک لایه جهتگیری میکند و یک کد کاشی منحصربهفرد را بر اساس مکان فضایی دیدگاه فعلی محاسبه میکند [ 21 ، 22 ]. هنگامی که چندین لایه تصویر در یک منطقه فضایی روی هم قرار میگیرند، کاشیهای اضافی میتوانند با همان نام اما از لایههای مختلف در مناطق خاصی وجود داشته باشند که با تقاطع فضایی مجموعههای داده تصویری متعدد مطابقت دارند [23 ] . از آنجایی که روش بازیابی کاشی مبتنی بر دیدگاه نمیتواند کاشی مورد نظر را از کاشیهای همنام متمایز کند زیرا چندین لایه روی هم قرار میگیرند، کاربران عموماً برای اطمینان از اینکه لایه قابل مشاهده در هر زمان خاص منحصر به فرد است، تعویض لایه انجام میدهند [24] .]. در چنین شرایطی، قبل از هر جستجوی کاشی، لایه هدف مشخص است.
با این حال، در یک فرآیند کاهش فاجعه، دادههای تصویر بلادرنگ به طور مداوم برای ساختن لایههای جدید، که هر یک از آنها با توجه به وضوحها و گسترههای زمانی و مکانی متفاوت هستند، به طور مداوم در دسترس هستند [25 ] . بارگذاری تنها یک لایه در یک زمان نه میتواند نمایانگر ویژگیهای کامل بلایای یک منطقه آسیبدیده از فاجعه باشد و نه میتواند انواع نیازهای تفکیک مکانی-زمانی را در فرآیند تجسم کاهش فاجعه برآورده کند. علاوه بر این، ادغام مجموعههای داده مختلف با وضوحهای فضایی مختلف و مقیاسبندی آنها در یک هرم پیچیده و زمانبر است، که در صورت عدم تطابق وضوح زمانی مجموعه دادههای یکپارچه، ممکن است منجر به هرج و مرج زمانی شود.
روش بازیابی کاشی مبتنی بر دیدگاه نمیتواند کاشیهای همنام را از چندین لایه فیلتر کند. باید هر مجموعه داده ذخیره شده در پایگاه داده را بر اساس کدهای سطح کاشی، ردیف و ستون طی کند [ 26]. سپس، تمام کاشی های جستجو شده بارها و بارها از سرور به مشتری بارگذاری می شوند. واضح است که افزونگی کاشی قابل توجهی رخ می دهد و منابع خدمات را در فرآیند بازیابی هدر می دهد. در سرورها، هر درخواست کاشی، پایگاه داده را مجبور میکند تا همه مجموعههای داده تصویر را جستجو کند و گروهی از نتایج مشابه را برگرداند، که باعث بازیابی مکرر و غیر ضروری در مجموعههای داده نامربوط و همچنین کاهش سرعت پرس و جو میشود. در کلاینتها، کاشیهای همنام به صورت جداگانه دریافت، تجزیه و برای تجسم ترسیم میشوند. این فرآیند به طور قابل توجهی سرعت تازه سازی صحنه بصری را کاهش می دهد و فشار حافظه مشتریان را تا حد زیادی افزایش می دهد. در لایه انتقال، تعداد زیادی کاشی نامعتبر اکثر منابع پهنای باند را اشغال میکنند که به طور جدی بر نرخ انتقال کاشیهای موجود تأثیر میگذارد. علاوه بر این،
یک روش بازیابی بر اساس تقاضا برای کاشی های تصویر چند لایه در این مقاله پیشنهاد شده است. این سرورها را وادار می کند تا به طور خودکار تقاضای تجسم را بر اساس مکان دیدگاه و اطلاعات وظیفه کاهش تجزیه و تحلیل کنند. سپس، کاشی بهجای گذر از تمام مجموعههای داده یا تکیه بر سوئیچ کنترل لایه مرد-ماشین، به طور فعال از لایههای مناسب برای پاسخگویی به مشتریان انتخاب میشود. همانطور که در شکل 4 نشان داده شده استهنگامی که دیدگاه از سطح زمین دور است، سرورها کاشی هایی را از هرم A با وضوح پایین برای تجسم اولیه ارائه می کنند. همانطور که دیدگاه به سمت منطقه متاثر از سیل حرکت می کند، سرورها هرم B با وضوح متوسط را برای وظایف استخراج سیل انتخاب می کنند. هنگامی که دیدگاه نزدیک به سطح شهر سیلزده است، سرورها به طور فعال کاشیهای با وضوح بالا را فقط از هرم C برای وظایف ارزیابی تلفات انتخاب میکنند. این خودمختاری از انعطاف پذیری و تنوع سرویس تصویر چند لایه برای برآورده کردن خواسته های مختلف تجسم کاهش فاجعه و تضمین درخواست کاشی کارآمد برای تازه کردن صحنه سه بعدی توسط مشتریان، بهره کامل می برد.
3. روش شناسی
روش مبتنی بر دیدگاه میتواند به راحتی کاشیهای منحصر به فرد را از یک لایه بازیابی کند، اما با افزایش تعداد لایههای روکششده، این روش نمیتواند مناسبترین کاشیها را از مجموعه دادههای متعدد تشخیص دهد. برای غلبه بر این مشکل، ما یک مدل توصیف معنایی لایههای تصویر را پیشنهاد میکنیم. معناشناسی چند بعدی در مدل تعریف شده است، و یک رویکرد حاشیه نویسی بر اساس چارچوب توصیف منابع (RDF) برای توصیف لایه ها استفاده می شود. انتخاب لایه و فیلتر کاشی در یک فرآیند تطبیق انجام می شود.
3.1. توصیف معنایی یک لایه تصویر
حاشیه نویسی معنایی به طور گسترده در پردازش جغرافیایی، به ویژه در ترکیب سرویس های وب معنایی استفاده شده است [ 27 ، 28 ]. این رویکرد دارای یکپارچگی معنایی بالا است و نمایش ابرداده را رسمی می کند تا ماشین فراداده قابل خواندن باشد [ 29 ]، که درک متقابل و عملکرد متقابل بین مجموعه داده ها را بهبود می بخشد [ 30 ، 31 ].
مدل توصیف معنایی شامل پنج عنصر است: معناشناسی فضایی محدوده منطقه فضایی یک مجموعه داده را توصیف می کند. معناشناسی زمانی زمان جمع آوری تصاویر سنجش از دور را ثبت می کند. معناشناسی وضوح، محدوده عمودی هرم محلی را تعریف می کند. معناشناسی اولویت ترتیب برنامه ریزی مجموعه داده ها را کنترل می کند. و معناشناسی مضمون مجموعه ای از برچسب های فرعی هستند که اطلاعات مربوط به بلایای طبیعی مانند مناطق فاجعه، انواع فاجعه و سایر عوامل را ثبت می کنند. شرح تفصیلی و کارکردهای معناشناسی به شرح زیر است.
3.1.1. معناشناسی فضایی
محدوده دو بعدی یک مجموعه داده در سطح زمین توسط معناشناسی فضایی توصیف می شود. در فرآیند کاهش فاجعه، مجموعه جدیدی از تصاویر معمولاً برش داده میشوند و به یک تصویر متصل میشوند که شکل آن به طور یکپارچه با منطقه اداری منطقه فاجعه مطابقت دارد. معناشناسی فضایی یک شکل چند ضلعی پیچیده را نشان می دهد که به دقت میزان واقعی تصویر ترکیبی را توصیف می کند. معناشناسی فضایی برای فیلتر کردن دقیق مجموعه داده های نامربوط که خارج از viewport هستند استفاده می شود.
3.1.2. معناشناسی زمانی
معناشناسی زمانی ترتیب و چرخه عمر مجموعه داده را در بعد زمانی توصیف می کند. محدوده زمانی هر مجموعه داده در قالب یک مهر زمانی تعریف میشود که از تجزیه و تحلیل توالی و ارائه چند زمانی لایههای متعدد پشتیبانی میکند. اینها برنامه های معمولی هستند که در آن کاشی های چند لایه به طور همزمان درخواست و برنامه ریزی می شوند. بنابراین، مهر شاخص کلیدی است که توالی انتخاب کاشی های همنام را کنترل می کند.
3.1.3. معناشناسی رزولوشن
وضوح فضایی یک تصویر نشان دهنده حداکثر سطح هرم آن است. در فرآیند ساخت هرم، حداکثر سطح هرم فعلی بیانگر معناشناسی وضوح است. وسعت قابل مشاهده لایه های تصویر را در محدوده عمودی فضای سه بعدی مشخص می کند که نشان دهنده اطلاعات عملکردی هرم فعلی است. به عنوان مثال، هنگامی که دیدگاه به مکانی نزدیک به سطح می رسد، به این معنی است که کاربر بیشتر نگران جزئیات ویژگی مجموعه داده تصویر با وضوح بالا است تا بافت با وضوح پایین مجموعه داده پس زمینه جهانی. در چنین شرایطی، اطلاعات سطح برای حذف بیشتر لایههایی که خارج از میدان دید مورد نظر هستند، اعمال میشود.
3.1.4. معناشناسی اولویت
اولویت، شاخص ثانویه است که ترتیب بارگذاری لایه ها را تعیین می کند. در مراحل پاسخ اضطراری و ارزیابی تلفات کاهش بلایا، بسیاری از لایههای جدید وجود دارد که با توجه به وسعت فضایی، عمق قابل مشاهده و چرخه حیات همپوشانی دارند. اولویت برای تشخیص لایه های با همپوشانی زیاد استفاده می شود. اولویت با تجربه مصنوعی اولیه می شود زیرا هرم در پایگاه داده ذخیره می شود. به عنوان مثال، اگر تصاویر کنونی برای استخراج آب در یک فاجعه سیلابی مناسبتر باشند، اولویت هرم مربوطه بیشتر از هرمهای دیگر حسگرها است. یک تنظیم پیشفرض پشتیبانی میشود، زیرا آخرین هرم ذخیرهشده دارای اولویت بالاتری است که سایر شاخصها یکسان هستند.
3.1.5. معناشناسی تم
محدودیت معنایی موضوع برای تشخیص تفاوتهای تصویر از نظر انواع حسگر، منابع داده، رویدادهای فاجعه مرتبط و سایر اطلاعات ایجاد شده است. در کار تجسم منطقه فاجعه، بلایای مختلف دارای اولویت های مختلفی در رابطه با وضوح تصویر و انواع حسگرهای مربوطه هستند. در معناشناسی تم، گروهی از تگهای فرعی برای توصیف ویژگیهای موضوع لایه تصویر ساخته میشوند. همچنین به طور موثر محدودیتهای ارتباطی وظایف و مجموعه دادههای مختلف تجسم را افزایش میدهد، که بیشتر از کاربران در انتخاب و دور انداختن لایهها در دستهها پشتیبانی میکند.
RDF برای نشان دادن حاشیه نویسی معنایی اتخاذ شده است. یک فایل RDF به طور موثر معنایی هر مجموعه داده را سازماندهی می کند و آنها را به اطلاعات منابعی تبدیل می کند که پایگاه داده به راحتی می تواند شناسایی و تجزیه و تحلیل کند. یک فایل RDF، همانطور که در طرح 1 نشان داده شده است ، زمانی تولید می شود که یک هرم جدید ساخته شود. سپس، اطلاعات حاشیه نویسی تفسیر شده و برای فرآیند تطبیق در پایگاه داده ذخیره می شود.
3.2. فرآیند تطبیق
روش سنتی بازیابی کاشی مبتنی بر دیدگاه نمی تواند تفاوت بین کاشی های همنام متعلق به لایه های مختلف را تعیین کند. در عوض، باید تمام مجموعه داده ها را طی کند تا کاشی های موجود را پیدا کند. بهبود ارائه شده در این مقاله در توصیف ویژگی های چند بعدی مجموعه داده مبتنی بر اطلاعات معنایی و کاشی های تطبیق تطبیقی همراه با اطلاعات موقعیت دیدگاه فعلی در فرآیند بازیابی نهفته است. شکل 5 روند تطبیق و فیلتر کردن خودکار کاشی ها را نشان می دهد.
مراحل دقیق فرآیند فوق به شرح زیر است:
- مرحله 1
-
یک درخواست کاشی به دست میآید و ابتدا به معنای نیازمندیهای وظایف تجسم، از جمله گستره جغرافیایی نمای، سطح هرم کاشی، اطلاعات موضوع، نیاز اولویت و محدودیتهای زمانی تجزیه میشود.
- مرحله 2
-
فراداده همه مجموعه داده ها برای انجام عملیات تقاطع بر اساس محدوده viewport و چند ضلعی مرزی هر مجموعه داده برای یافتن مجموعه داده لیست 1 که در آن هر عضو درگاه دید را قطع می کند، پیمایش می شود.
- مرحله 3
-
برای انتخاب مجموعههای دادهای که محدوده سطح هرمی آنها سطح درخواستی فعلی را در بر میگیرد، فهرست را پیمایش کنید . نتایج جستجو لیست2 را ایجاد می کند .
- مرحله 4
-
اطلاعات موضوع را با برگه های تم هر مجموعه داده در list2 مطابقت دهید . مجموعه دادههای منطبق فهرست ۳ را تشکیل میدهند . مجموعه داده ها در list3 ترجیحات وظیفه را برای سرویس های لایه نشان می دهند.
- مرحله 5
-
در list3 ، مجموعه دادهها را بر اساس اولویت مرتب کنید و مجموعه دادهای را با بالاترین اولویت برای تولید list4 انتخاب کنید .
- مرحله 6
-
یک محدودیت زمانی برای انتخاب مناسب ترین مجموعه داده از list4 اعمال می شود . تنظیم پیش فرض این است که آخرین مجموعه داده را انتخاب کنید. یک مجموعه داده منحصر به فرد نیز می تواند با تنظیم یک دوره زمانی خاص در شرایط درخواست کاشی جستجو شود.
علاوه بر این، همانطور که در شکل 5 نشان داده شده است، هر الماس نشان دهنده یک قضاوت است، به طوری که اگر لیست فعلی فقط یک عضو داشته باشد، مجموعه داده ایده آل انتخاب شده است، و فرآیند مستقیماً به گره پایانی می رود. اگر لیست فعلی هیچ عضوی نداشته باشد، فرآیند باید با مکان یابی مجدد لیست قبلی و پرش از آخرین گره فیلترینگ به گره بعدی، شرایط فیلتر را کاهش دهد. به طور خاص، اگر اولین گره قضاوت null را برگرداند، به این معنی که هیچ مجموعه داده مناسبی وجود ندارد که محدوده viewport فعلی را قطع کند، فرآیند باید متوقف شود و null را به سرور برنامه برگرداند.
فرآیند تطبیق و فیلتر کردن لایه ها می تواند به طور موثر مناسب ترین لایه تصویر را انتخاب کند که وظیفه تجسم فعلی را برآورده می کند. برای استفاده کامل از کارایی سرور برای جستجوی داده ها و انتشار اطلاعات، اجرای فرآیند تطبیق و فیلتر در سمت سرور ترتیب داده شده است. یک معماری پایگاه داده دو لایه NoSQL برای برآورده کردن موثر نیازهای ذخیره سازی و دسترسی مجموعه داده های انبوه طراحی شده است.
4. اجرا
یک معماری ترکیبی دو لایه مبتنی بر پایگاههای داده NoSQL کلید-مقدار و سند برای ذخیرهسازی لایه کارآمد و بازیابی کاشی طراحی شده است. پایگاه های داده NoSQL به طور گسترده ای برای ذخیره و مدیریت مقادیر زیادی از داده های تصویری بازیابی شده از طریق تکنیک های هرمی و نمایه سازی هش در سمت سرور استفاده شده است [ 32 ]. هرم قوانین برش تصویر را ارائه می دهد و نمایه سازی هش راه حلی برای ذخیره و جستجوی این کاشی ها به شیوه ای بسیار موثر می دهد. NoSQL یکی از فناوریهای کلیدی برای ذخیرهسازی با ظرفیت زیاد و بازیابی سریع است که به سمت رشد مستمر مجموعههای داده است [ 33 ، 34 ، 35 ، 36 ]. ویژگی های اصلی پایگاه های داده NoSQL به شرح زیر است [ 7 ، 37]:
-
پشتیبانی از عملیات خواندن و نوشتن انبوه همزمان و سازگاری نهایی؛
-
پشتیبانی از ذخیره سازی انبوه؛
-
آسان برای گسترش؛
-
کم هزینه؛
-
مدل داده های انعطاف پذیر که غیرساختار یا نیمه ساختار یافته است. و
-
مقیاس پذیری افقی
محبوب ترین دسته های پایگاه های داده NoSQL شامل پایگاه های داده کلید-مقدار و پایگاه های داده اسناد است. پایگاههای داده کلید-مقدار برای عملیات سریع و ساده استفاده میشوند، زیرا نقشهبرداری سادهای از کلید به مقدار مربوطه ارائه میدهند که جستجوی سریع شی را به همراه دارد. پایگاههای اطلاعاتی اسناد، مدلهای داده انعطافپذیر را با امکان پرس و جو ارائه میدهند. آنها را تکامل یافته پایگاه داده های کلید-مقدار در نظر می گیرند، زیرا در عین پشتیبانی از قابلیت های جستجوی قوی و غنی، تمام مزایای پایگاه های داده با ارزش کلیدی را در بر می گیرند.
4.1. طراحی ذخیره سازی
معماری پایگاه داده دو لایه شامل لایه ذخیره سازی و لایه کش است. لایه ذخیره سازی از MongoDB برای مدیریت مقادیر زیادی از لایه های تصویر و ابرداده استفاده می کند. MongoDB یک ساختار داده غنی برای ذخیره اطلاعات معنایی مجموعه داده ها فراهم می کند. در MongoDB، ساختار GridFS از ذخیرهسازی کارآمد دادههای کاشی انبوه پشتیبانی میکند و ساختار مجموعه، مدیریت ابرداده مؤثری را فراهم میکند [ 38 ]. هر هرم کاشی در GridFS ذخیره می شود و فایل RDF ابرداده آن به عنوان یک سند در مجموعه ابرداده ذخیره می شود.
لایه کش یک مخزن کش قابل گسترش بر اساس Redis، یک پایگاه داده NoSQL با ارزش کلیدی ارائه می دهد. Redis به عنوان یک پایگاه داده در حافظه، توانایی بالایی در انجام وظایف خواندن، نوشتن و پرس و جو دارد. علاوه بر این، مقیاس پذیری افقی و طراحی توزیع آن از ذخیره سازی سریع و الزامات دسترسی ثانویه داده های عظیم کاشی پشتیبانی می کند. کاشی های ذخیره شده به طور مساوی بین گره های حافظه توزیع می شوند. کلید هر کاشی به عنوان “نام مجموعه داده: مکان کاشی” طراحی شده است. نام مجموعه داده بر اساس نام GridFS مجموعه داده هایی است که شامل کاشی در MongoDB است و مکان کاشی شامل ردیف، ستون و شماره سطح سیستم شبکه جهانی گسسته است. این طراحی شاخص های کاشی سازگار را در دو پایگاه داده تضمین می کند.
در بالای پایگاه داده های دو لایه، یک سرور برنامه برای اجرای فرآیند تطبیق لایه ها ساخته شده است. هنگامی که درخواست کاشی در سرور برنامه دریافت می شود، سرور درخواست را تجزیه می کند و مراحل 2 و 3 را انجام می دهد ( شکل 2 را ببینید) از فرآیند از طریق پرس و جوی اتحاد فضایی در MongoDB. نتایج پرس و جو، از جمله موضوع، زمان و معنایی اولویت، به سرور برنامه باز می گردند. مراحل باقی مانده از فرآیند به سرعت در حافظه سرور پیاده سازی می شوند. لایه مناسب در پایان فرآیند تطبیق انتخاب می شود. سپس، سرور کلید کاشی را برای جستجو در Redis جمع آوری می کند. اگر کاشی در حافظه پنهان یافت نشد، سرور دوباره در MongoDB جستجو میکند. نتیجه ابتدا به سرور برگردانده می شود و متعاقباً برای ذخیره سازی به Redis ارسال می شود. کل فرآیند پرس و جو در شکل 6 نشان داده شده است .
4.2. بهینه سازی زمان بندی
برای افزایش کارایی پاسخ و ثبات انتقال بین کلاینتها و سرورها، بهینهسازی زمانبندی کاشی، از جمله روش جایگزینی چند صفی که اخیراً استفاده شده است (LRU) و انتقال کاشی مالتی پلکس مبتنی بر HTTP/2.0 اجرا شده است.
4.2.1. تعویض چند صفی LRU
تکنیک ذخیره سازی داده های مکانی به طور گسترده در محیط های مبتنی بر ابر استفاده می شود [ 39 ، 40 ]. یک مدل هرمی از کاشیها یک روش مدیریت و ذخیرهسازی خوب برای دادههای مکانی در یک محیط مبتنی بر ابر فراهم میکند [ 41 ]. روشهای واکشی اولیه که دسترسی به دادهها را پیشبینی میکنند [ 42 ، 43 ] برای بهبود ذخیرهسازی کاشی زمانی که اندازه ذخیرهسازی حافظه پنهان محدود است، پیشنهاد شدهاند. همانطور که اندازه حافظه بزرگ در تکنیکهای کش در دسترس میشود، بهرهگیری از تواناییهای پایگاه داده حافظه (اندازه ذخیرهسازی بزرگ و بازیابی دادهها و بهروزرسانی حافظه با کارایی بالا) میتواند نرخ ضربه کاشی و کارایی دسترسی ثانویه را در فرآیند تجسم افزایش دهد.
الگوریتم LRU داده ها را با توجه به سوابق تاریخی دسترسی به داده حذف می کند. ایده اصلی آن این است که اگر داده ها اخیراً بازدید شده باشند، احتمال بازدیدهای آینده نیز بیشتر است [ 44 ] که به طور گسترده در مدیریت داده های کش استفاده می شود. الگوریتم جایگزینی LRU چند صفی، صف LRU را به چند صف تقسیم میکند که هر کدام دارای اولویتهای دسترسی متفاوتی هستند. LRU چند صفی نرخ ضربه بالاتری نسبت به الگوریتم LRU سنتی دارد اما با پیچیدگی و هزینههای محاسباتی بالاتری همراه است. از آنجایی که پایگاه داده درون حافظه خوشه ای دارای ظرفیت حافظه کافی و کارایی پرس و جو است، الگوریتم جایگزینی LRU چند صفی برای مدیریت کاشی های ذخیره شده در حافظه به کار گرفته شده است.
همانطور که در شکل 7 نشان داده شده است ، چندین صف در کش وجود دارد، از Q 0 تا Qk ، و اولویت های دسترسی به نوبه خود مورد بررسی قرار می گیرند. یک کاشی جدید در Q ذخیره می شود0 زمانی که برای اولین بار توسط مشتری درخواست می شود. با افزایش تعداد دسترسی ها از آستانه، کاشی از صف فعلی حذف می شود و به سر یک صف سطح بالا اضافه می شود. اگر کاشی برای مدت معینی دسترسی نداشته باشد، باید از صف فعلی حذف شود و به سر یک صف سطح پایین ارسال شود. کاشیهای انتهای هر صف برداشته میشوند و در صورتی که صف آن پر شده باشد به سر صف تاریخی فشار داده میشوند. ترتیب بازیابی کاشی در حافظه پنهان به اولویت دسترسی صف ها بستگی دارد و صف تاریخچه کمترین اولویت را دارد. اگر به یک کاشی در صف تاریخ دوباره دسترسی پیدا کرد، اولویت آن بازیابی میشود و به سر آخرین صف برمیگردد. در نهایت، صف تاریخ کاشی های “بی فایده” را طبق قانون LRU پاک می کند.
4.2.2. انتقال کاشی چندپلکسی مبتنی بر HTTP/2.0
درخواستهای کاشی از کلاینتهای توزیعشده به درخواستهای HTTP تبدیل شده و به سرور ارسال میشوند. سپس سرور URL را تجزیه می کند و پایگاه داده را جستجو می کند. پس از بازیابی کاشی ها، از طریق شبکه به مشتریان بازگردانده می شوند. HTTP یک پروتکل کاربردی است که بیشتر در اینترنت استفاده می شود. همچنین زبان مشترک بین کلاینت ها و سرورها است.
اگرچه بیشتر پروتکلهای انتقال ابرمتن مبتنی بر HTTP/1.x هستند، اما زمانبندی سنتی مبتنی بر پروتکل انتقال HTTP/1.x از کارایی و تداوم زمانی ضعیف رنج میبرد. استقرار و قطع مکرر ارتباط بین کلاینت ها و سرورها منجر به مصرف زمان قابل توجهی می شود و انتقال مکرر هدر HTTP منجر به هدر رفتن مقدار زیادی از منابع شبکه می شود.
در یک برنامه تجسم کاشی در زمان واقعی، سرور برنامه باید به بسیاری از درخواستهای داده کاشی در یک دوره نسبتاً کوتاه پاسخ دهد تا از تجسم مداوم توسط مشتریان اطمینان حاصل کند. در HTTP/1.x، یک اتصال برای یک فرآیند درخواست-پاسخ ایجاد میشود و با دریافت پاسخ، اتصال بسته میشود. فرآیند استقرار و قطع ارتباط مستلزم مقدار زیادی زمان انتقال اضافی است. علاوه بر این، HTTP/1.x از رویکرد فرآیند خط لوله استفاده میکند که چندین درخواست را در یک فرآیند تک رشتهای سریال در صف قرار میدهد. درخواست در پشت صف باید منتظر بماند تا درخواست قبلی رسیدگی شود. زمانی که تعداد کاشی های درخواستی به سرعت افزایش می یابد، روش تک رشته ای مستعد بلوک های کاشی و وقفه زمانی پاسخ است که به راحتی باعث مسدود شدن تجسم در مشتریان می شود.
پروتکل حمل و نقل مبتنی بر HTTP/2.0 می تواند به اتصال ناهمزمان مالتی پلکسی دست یابد که می تواند کارایی انتقال کاشی را تا حد زیادی افزایش دهد. بر خلاف HTTP/1.x که برای هر درخواست پاسخی اتصال ایجاد می کند، HTTP/2.0 یک اتصال پیوسته برای تمام درخواست های داده برقرار می کند. این یک پیام درخواست را به فریم های متعدد برای انتقال تجزیه می کند. فریم ها در انتهای گیرنده مجدداً مونتاژ می شوند تا تعدادی از درخواست ها به صورت موازی بدون تأثیر بر یکدیگر ارسال و دریافت شوند. پاسخ ها نیز به همین روش ارسال و دریافت می شوند ( شکل 8 را ببینید ). انتقال کاشی چندگانه HTTP/2.0 به طور کامل از شبکه برای به حداقل رساندن مسدود شدن کاشی در موقعیت دسترسی همزمان استفاده می کند.
5. آزمایش کنید
5.1. محیط تجربی
چهار سرور Dell Edge Power R710 در دوازده ماشین مجازی (VM) مجازی سازی شدند تا یک منبع سرویس مشترک خوشه ای ایجاد کنند. در میان آنها، شش ماشین مجازی (1 CPU هسته ای که با فرکانس 1.2 گیگاهرتز و 8 گیگابایت رم کار می کند) برای ساخت کلاسترهای ذخیره سازی کاشی و استقرار پایگاه داده NoSQL سند توزیع شده استفاده شد. هر VM با بیش از 1.5 ترابایت فضای ذخیره سازی دیسک بارگذاری شده بود (در مجموع تقریباً 10 ترابایت). شش ماشین مجازی باقیمانده (1 هسته پردازنده با فرکانس 1.2 گیگاهرتز و 40 گیگابایت رم) برای ساخت کلاسترهای کش با استقرار کلاستر پایگاه داده حافظه کلید-مقدار استفاده شد. به هر VM علاوه بر این، 40 گیگابایت حافظه (مجموع 240 گیگابایت) اختصاص داده شد.
5.2. مجموعه داده های تجربی
این پایگاه داده بیش از 30 مجموعه داده کاشی تصویر سنجش از دور مربوط به دو فاجعه بزرگ زلزله را که در سالهای اخیر در چین خسارات قابلتوجهی ایجاد کردهاند، ذخیره میکند: زلزله لوشان (30.3 درجه شمالی، 103.0 درجه شرقی)، که در 20 آوریل 2014 رخ داد، و لودیان. زمین لرزه (27.2 درجه شمالی، 103.4 درجه شرقی)، که در 3 اوت 2014 رخ داد. مجموعه داده ها شامل تمام تصاویر استانی با وضوح 5 متر از چین و تصاویر ماهواره ای، هوایی و پهپاد با وضوح بالاتر از شهرها، شهرستان ها و روستاهای درگیر فاجعه است. استان های تحت تاثیر چین حجم کل مجموعه داده بیش از 5 ترابایت است. جدول 1 جزئیات داده های تجربی را نشان می دهد.
5.3. طراحی آزمایش و نتایج
این آزمایش وظایف تجسم مبتنی بر صحنه سهبعدی را شبیهسازی میکند، از جمله مروری بر مناطق فاجعهبار بر اساس تصاویر با وضوح پایین، تشخیص ویژگی بر اساس تصاویر با وضوح متوسط و ارزیابی آسیب بر اساس تصاویر با وضوح بالا. در این فرآیند، تجسم باید اطمینان حاصل کند که کاشیها در مکانهای مختلف و سطوح هرم بهآرامی تازهسازی میشوند، حتی در سناریوی دسترسی همزمان چند مشتری. آزمایشها در این مقاله برای نشان دادن اعتبار روش بازیابی بر اساس تقاضا هنگام دسترسی به کاشیهای تصویر چند لایه طراحی و مورد بحث قرار گرفتهاند.
5.3.1. مقایسه کارایی درخواست کاشی
همانطور که در شکل 9 نشان داده شده است، یک مسیر پرواز خودکار روی سطح یک مدل زمین مجازی سه بعدی برنامه ریزی شد . ابتدا، نقطه نظر بر فراز چین در ارتفاع 5 کیلومتری پرواز کرد. سپس به ارتفاع 500 متری در منطقه زلزله زده شهرستان لودیان در استان یوننان فرود آمد. در نهایت، دیدگاه به ناحیه نزدیک به زمین در شهرستانهای استان سیچوان که بهطور جدی تحت تأثیر زلزله لوشان قرار گرفته بودند، منتقل شد. در طول فرآیند پرواز، مشتری باید به طور مداوم کاشی ها را در مکان ها و وضوح های مختلف درخواست کند. ما برای مقایسه کارایی درخواست کاشی با یا بدون بهینهسازی جستجوی کاشی، تفاوتها را در مورد تعداد درخواستها و برگرداندن کاشیها و تکرارپذیری کاشیهای همنام بهشمار آوردیم.
همانطور که در شکل 10 نشان داده شده است، با افزایش تعداد مجموعه داده ها، تعداد کل درخواست های کاشی عمومی افزایش یافت، در حالی که میزان و نرخ درخواست های موجود همچنان رو به کاهش بود. در مقابل، تعداد درخواستهای کاشی بهینه شده ثابت باقی ماند و درصد دسترسی موجود در بیش از 97.8 درصد حفظ شد ( شکل 11 و شکل 12 را ببینید.) صرف نظر از تعداد مجموعه داده هایی که در پایگاه داده ذخیره شده اند. به دلیل عدم شناسایی و فیلتر خودکار کاشیهای غیرقابل دسترس، روشهای سنتی باعث شد که اکثریت شبکه توسط درخواستهای غیرقابل دسترس و کاشیهای همنام اشغال شود که دسترسی بلادرنگ کلاینتها به کاشیهای هدف را بهشدت تحت تأثیر قرار داد. در چنین سناریویی، با افزایش تعداد لایه های داده، نرخ تجدید صحنه به طور قابل توجهی کاهش می یابد. روش پیشنهادی به طور موثر این مشکلات را با استفاده از حاشیه نویسی معنایی و فرآیند فیلتر کاشی حل می کند. بر اساس فرآیند تطبیق بر اساس تقاضا ( شکل 5 را ببینید، سرور برنامه می تواند با موفقیت لایه های در دسترس را که به نمای فعلی بی ربط هستند حذف کند، به طوری که تعداد پرس و جوهای پایگاه داده و برگرداندن کاشی های نامعتبر تا حد زیادی کاهش می یابد. بنابراین، بهینهسازی اشغال پهنای باند کاشیهای موجود را از 600 کیلوبایت بر ثانیه به 20 مگابایت بر ثانیه بهبود میبخشد تا از تازهسازی یکنواخت صحنه سهبعدی در کلاینتها اطمینان حاصل شود.
5.3.2. مقایسه بازده دسترسی به حافظه پنهان
بیست مشتری برای مرور بصری سه بعدی همزمان مناطق فاجعه زلزله لودیان، از جمله ترجمه دیدگاه، زوم، رومینگ و مسیرهای پرواز، در حالی که به طور همزمان به سرورها دسترسی دارند، ایجاد شده است. ما تفاوت پاسخ سرور را قبل و بعد از افزودن حافظه پنهان با روش جایگزینی LRU چند صفی آزمایش کردیم. همانطور که در شکل 13نشان می دهد، نرخ درخواست-پاسخ کاشی هایی که مستقیماً از پایگاه داده دیسک واکشی می شوند، هیچ تغییر آشکاری را نشان نمی دهند، در حالی که زمان پاسخ بر اساس طراحی کش حافظه به تدریج کاهش می یابد. علاوه بر این، با افزایش ظرفیت حافظه نهان، سرعت پاسخ سرور افزایش مییابد، که نشان میدهد طراحی کلید-مقدار موضوع محور از توانایی بازیابی پایگاه داده حافظه توزیع شده استفاده کامل میکند. این رویکرد میتواند الزامات عملکرد تجسم عظیم تصویر را در شرایط مشتریان متعدد برآورده کند.
5.3.3. مقایسه عملکرد چندگانه
کارایی انتقال بر اساس HTTP/1.1 و HTTP/2.0 با تنظیم مسیر پروازی یکسان تحت روش بازیابی کاشی بهینه شده مقایسه میشود تا اطمینان حاصل شود که تعداد درخواستهای کاشی موجود تحت پروتکلهای مختلف HTTP یکسان است. زمانی که دیدگاه به انتهای مسیر پرواز کرد و ویوپورت باقی ماند، شروع به ثبت تعداد کاشیهای تازهسازی کردیم. در این مدت 235 کاشی درخواست شده است. میانگین زمان مصرف بارگذاری کاشی ها بر اساس HTTP/2.0 2.73 ثانیه است، اما بارگذاری همان کاشی ها با استفاده از HTTP/1.1 10.05 ثانیه طول می کشد. مالتی پلکس شدن در HTTP/2.0 باعث کاهش زمان مصرف مورد نیاز برای ایجاد یک اتصال و پشتیبانی از درخواست های موازی به شکل جریان می شود.
آزمایشها نشان میدهند که روش پیشنهادی میتواند کارایی دسترسی به دادههای کاشی تصویر چندلایه را در سه زمینه بهبود بخشد: (1) فرآیند تطبیق کاشی و فیلتر بر اساس تقاضا از حاشیه نویسی و تجزیه و تحلیل معنایی برای انتخاب مجموعه داده مناسب برای بازیابی کاشی استفاده میکند که به طور قابل توجهی محدود میشود. دامنه جستجوی پایگاه داده؛ (2) معماری پایگاه داده دو لایه NoSQL سرعت پاسخ سرورها به دسترسی همزمان را با بهبود بازیابی و حذف کاشی در حافظه نهان افزایش می دهد. و (3) HTTP/2.0 راندمان انتقال را بیشتر بهبود می بخشد تا از نیازهای به روز رسانی در زمان واقعی وظایف تجسم سمت مشتری اطمینان حاصل شود. شکل 14 تفاوت بارگذاری کاشی را در 2.0 ثانیه بر اساس دو روش نشان می دهد.
6. بحث
این آزمایش نشان میدهد که روش بازیابی بر اساس تقاضا میتواند تا حد زیادی کارایی خدمات تصویر چندلایه را در تجسم کاهش فاجعه بر اساس یافتههای زیر بهبود بخشد: (1) برای پرس و جو کاشی چند مجموعه داده، سرور میتواند با موفقیت مناسبترین مجموعه داده را انتخاب کند. با توجه به روند تطبیق؛ (2) در مقایسه با برنامه های سنتی بازیابی کاشی، نرخ ضربه موثر کاشی های معتبر بدون توجه به تأثیر تعداد مجموعه داده ها در سطح بالایی حفظ می شود. و (3) طراحی مدیریت داده مبتنی بر NoSQL، ذخیره کاشی و جستجو در سمت سرور را بهبود می بخشد، که از دسترسی همزمان توسط چندین مشتری پشتیبانی می کند. از آنجایی که دسترسی مشتری به سرویس تصویر چند لایه تحت تأثیر تعداد مجموعه داده ها قرار نمی گیرد، پایگاه داده می تواند شامل مجموعه داده های بیشتری برای کارهای مختلف مرتبط با تجسم کاهش فاجعه باشد. مجموعه دادهها را میتوان با موارد و انواع فاجعه با استفاده از معناشناسی مضمون بر اساس دانش ادبیات برچسبگذاری کرد. به عنوان مثال، به هر فاجعه میتوان منابع داده ترجیحی با وضوح تصویر بهینه اختصاص داد و این منابع داده ترجیحی در درجه اول در طول فرآیند تطبیق انتخاب میشوند. بنابراین، زمانی که پایگاه داده تعداد کافی مجموعه داده را برای بلایای مختلف ذخیره کرده است، روش پیشنهادی می تواند برای تجزیه و تحلیل درخواست های تصویر فاجعه بر اساس توصیفات معنایی و انتخاب خودکار کاشی ها از مناسب ترین مجموعه داده برای تجسم توسط مشتری استفاده شود. به عنوان مثال، به هر فاجعه میتوان منابع داده ترجیحی با وضوح تصویر بهینه اختصاص داد و این منابع داده ترجیحی در درجه اول در طول فرآیند تطبیق انتخاب میشوند. بنابراین، زمانی که پایگاه داده تعداد کافی مجموعه داده را برای بلایای مختلف ذخیره کرده است، روش پیشنهادی می تواند برای تجزیه و تحلیل درخواست های تصویر فاجعه بر اساس توصیفات معنایی و انتخاب خودکار کاشی ها از مناسب ترین مجموعه داده برای تجسم توسط مشتری استفاده شود. به عنوان مثال، به هر فاجعه میتوان منابع داده ترجیحی با وضوح تصویر بهینه اختصاص داد و این منابع داده ترجیحی در درجه اول در طول فرآیند تطبیق انتخاب میشوند. بنابراین، زمانی که پایگاه داده تعداد کافی مجموعه داده را برای بلایای مختلف ذخیره کرده است، روش پیشنهادی می تواند برای تجزیه و تحلیل درخواست های تصویر فاجعه بر اساس توصیفات معنایی و انتخاب خودکار کاشی ها از مناسب ترین مجموعه داده برای تجسم توسط مشتری استفاده شود.
7. نتیجه گیری
این مقاله یک روش بازیابی کاشی بر اساس یک معماری هیبریدی NoSQL را برای انتخاب دقیق کاشیهای مناسب از لایههای متعدد برای تجسم متنوع در کاهش بلایا پیشنهاد میکند. با ایجاد حاشیهنویسی معنایی برای مجموعه دادههای تصویر، این روش میتواند لایههای نامعتبر را فیلتر کرده و بیشترین کاشیها را با توجه به موضوع، جنبههای مکانی-زمانی و وضوح وظایف تجسم پیدا کند. بهینه سازی می تواند به طور موثر تعداد درخواست های کاشی از مشتریان و تعداد بازیابی داده های سمت سرور را کاهش دهد تا انتقال پایدار کاشی های معتبر از تعداد مجموعه داده های ذخیره شده را حفظ کند. علاوه بر این، حافظه پنهان کلاستر مبتنی بر NoSQL از طراحی ارزش کلید برای بازیابی سریع کاشی بهره میبرد و بهینهسازی زمانبندی، توانایی خدمات را برای مشتریان همزمان افزایش میدهد.
منابع
- Serpico، SB; دلپیان، اس. بونی، جی. موزر، جی. آنگیاتی، ای. رودری، ر. استخراج اطلاعات از تصاویر سنجش از دور برای پایش سیل و ارزیابی خسارت. Proc. IEEE 2012 ، 100 ، 2946-2970. [ Google Scholar ] [ CrossRef ]
- Sweta، LO; Bijker, W. روششناسی برای ارزیابی قابلیت استفاده دادههای مبتنی بر رصد زمین برای مدیریت بلایا. نات. خطرات 2012 ، 65 ، 167-199. [ Google Scholar ] [ CrossRef ]
- ژای، ایکس. یو، پی. Zhang، M. رویکرد مبتنی بر وب و سرویس وب حسگر برای پایش فعال بلایای هیدرولوژیکی. ISPRS Int. J. Geo-Inf. 2016 ، 5 ، 171. [ Google Scholar ] [ CrossRef ]
- فکته، ا. تزاولا، ک. آرماس، آی. بینر، جی. گارشاگن، ام. گیوپونی، سی. مجتهدی، و. پتیتا، م. اشنایدرباوئر، اس. Serre, D. منبع داده بحرانی; ابزار یا حتی زیرساخت؟ چالش های سیستم های اطلاعات جغرافیایی و سنجش از راه دور برای حاکمیت خطر بلایا ISPRS Int. J. Geo-Inf. 2015 ، 4 ، 1848-1869. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- گروسنر، KE; Goodchild، MF; Clarke، KC تعریف سیستم زمین دیجیتال. ترانس. GIS 2008 ، 12 ، 145-160. [ Google Scholar ] [ CrossRef ]
- گوا، اچ. ماهواره های رصد زمین در چین برای ساخت زمین دیجیتال. بین المللی جی دیجیت. زمین 2012 ، 5 ، 185-188. [ Google Scholar ] [ CrossRef ]
- ناتیوی، س. مازتی، پی. سانتورو، ام. پاپسچی، ف. کراگلیا، ام. Ochiai, O. چالشهای کلان داده در ساخت سیستمهای جهانی رصد زمین. محیط زیست مدل. نرم افزار 2015 ، 68 ، 1-26. [ Google Scholar ] [ CrossRef ]
- داومن، آی. رویتر، HI; داومن، آی. رویتر، HI داده های جغرافیایی جهانی از رصد زمین: وضعیت و مسائل. بین المللی جی دیجیت. زمین 2016 . [ Google Scholar ] [ CrossRef ]
- لو، ن. چنگ، سی. ما، اچ. یانگ، ی. تحلیل و مقایسه سیستم های شبکه گسسته جهانی. در مجموعه مقالات سمپوزیوم بین المللی زمین شناسی و سنجش از دور IEEE 2012 (IGARSS 2012)، مونیخ، آلمان، 22 تا 27 ژوئیه 2012. صص 2771-2774.
- فرنقی، م. منصوریان، ع. برنامه ریزی بلایا با استفاده از ترکیب خودکار خدمات وب OGC معنایی: مطالعه موردی در پناهگاه. محاسبه کنید. محیط زیست سیستم شهری 2013 ، 41 ، 204-218. [ Google Scholar ] [ CrossRef ]
- میازاکی، اچ. ناگای، م. Shibasaki, R. بررسی فناوری اطلاعات مکانی و تحویل داده های مشترک برای مدیریت خطر بلایا. ISPRS Int. J. Geo-Inf. 2015 ، 4 ، 1936-1964. [ Google Scholar ] [ CrossRef ]
- Potere, D. دقت موقعیت افقی آرشیو تصاویر با وضوح بالا google earth. Sensors 2008 , 8 , 7973-7981. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- بیلی، جی. چن، ای. نقش گلوب های مجازی در علم زمین. محاسبه کنید. Geosci. 2011 ، 37 ، 1-2. [ Google Scholar ] [ CrossRef ]
- دینگ، ی. فن، ی. دو، ز. زو، س. وانگ، دبلیو. لیو، اس. Lin, H. یک سیستم خدمات اطلاعات مکانی یکپارچه برای مدیریت بلایا در چین. بین المللی جی دیجیت. زمین. 2014 ، 8 ، 918-945. [ Google Scholar ] [ CrossRef ]
- جونگمن، بی. Wagemaker، J.; رومرو، بی. د پرز، ای. تشخیص زودهنگام سیل برای واکنش سریع بشردوستانه: مهار سیگنالهای ماهوارهای و توییتر در زمان واقعی. ISPRS Int. J. Geo-Inf. 2015 ، 4 ، 2246-2266. [ Google Scholar ] [ CrossRef ]
- کیو، ال. دو، ز. زی، جی. کیو، ز. خو، دبلیو. Zhang, Y. یک روش تجسم در زمان واقعی فایلهای بزرگ تصویر سنجش از دور با وضوح بالا. Geomat. آگاه کردن. علمی دانشگاه ووهان 2016 ، 41 ، 1021-1026. [ Google Scholar ]
- کیستر، آر. Sahr, K. مقدمه ای بر شبکه های جهانی گسسته. محاسبه کنید. محیط زیست سیستم شهری 2008 ، 32 ، 173. [ Google Scholar ] [ CrossRef ]
- سحر، ک. سفید، دی. سیستم های شبکه جهانی گسسته Kimerling، AJ Geodesic. کارتوگر. Geogr. Inf. علمی 2003 ، 30 ، 121-134. [ Google Scholar ] [ CrossRef ]
- فکته، جی. Treinish، چهار درخت LA Sphere: یک ساختار داده جدید برای پشتیبانی از تجسم داده های کروی توزیع شده. در SC—DL Tentative ; فارل، ای جی، اد. SPIE: Bellingham, WA, USA, 1990; ص 242-253. [ Google Scholar ]
- شیانگ، ال. چن، جی. گونگ، جی. Zeng, Z. ساخت سریع اهرام جهانی برای تصاویر ماهواره ای بسیار بزرگ. ترانس. GIS 2013 ، 17 ، 282-297. [ Google Scholar ] [ CrossRef ]
- وو، اچ. او، ز. گونگ، جی. تجسم سه بعدی و چارچوب تعاملی مبتنی بر کره مجازی برای مشارکت عمومی در فرآیندهای برنامه ریزی شهری. محاسبه کنید. محیط زیست سیستم شهری 2010 ، 34 ، 291-298. [ Google Scholar ] [ CrossRef ]
- یو، ال. Gong, P. Google Earth به عنوان یک ابزار کره مجازی برای کاربردهای علوم زمین در مقیاس جهانی: پیشرفت و چشم اندازها. بین المللی J. Remote Sens. 2012 ، 33 ، 3966-3986. [ Google Scholar ] [ CrossRef ]
- کیو، ال. وانگ، ام. زو، س. Du، Z. یک روش بازیابی بهینه کاشیهای تصویر چند مضمونی با در نظر گرفتن معناشناسی مکانی-زمانی. J. Natl. دانشگاه Def. تکنولوژی 2015 ، 37 ، 15-20. [ Google Scholar ]
- گی، ز. کائو، جی. لیو، ایکس. چنگ، ایکس. Wu, H. بررسی منابع در مقیاس جهانی و نظارت بر عملکرد خدمات نقشه وب OGC عمومی. ISPRS Int. J. Geo-Inf. 2016 ، 5 ، 88. [ Google Scholar ] [ CrossRef ]
- لی، دی. زنگ، ال. چن، ن. شان، جی. لیو، ال. فن، ی. لی، دبلیو. طراحی چارچوبی برای سیستمهای کاهش بلایای ملی چین (CNDRSS). بین المللی جی دیجیت. زمین 2014 ، 7 ، 68-87. [ Google Scholar ] [ CrossRef ]
- شیائو، ز. Liu, Y. پایگاه داده تصویر سنجش از دور بر اساس پایگاه داده NOSQL. در مجموعه مقالات 2011 نوزدهمین کنفرانس بین المللی IEEE در زمینه ژئوانفورماتیک، شانگهای، چین، 24-26 ژوئن 2011. صص 1-5.
- فیتزنر، دی. هافمن، جی. کلین، ای. توصیف عملکردی خدمات ژئوپردازش به عنوان پرس و جوهای دیتالوگ پیوندی. Geoinformatica 2011 ، 15 ، 191-221. [ Google Scholar ] [ CrossRef ]
- یو، پی. ژانگ، ام. Tan, Z. یک سیستم گردش کار ژئوپردازش برای نظارت بر محیط زیست و مدل سازی یکپارچه. محیط زیست مدل. نرم افزار 2015 ، 69 ، 128-140. [ Google Scholar ] [ CrossRef ]
- کلین، ای. لوتز، ام. کوهن، دبلیو. کشف خدمات اطلاعات جغرافیایی مبتنی بر هستی شناسی – کاربرد در مدیریت بلایا. محاسبه کنید. محیط زیست سیستم شهری 2006 ، 30 ، 102-123. [ Google Scholar ] [ CrossRef ]
- کیو، ال. دو، ز. زو، Q. روش همبستگی اطلاعات فاجعه محور. ISPRS Ann. فتوگرام حسگر از راه دور اسپات. Inf. علمی 2015 ، 1 ، 169-176. [ Google Scholar ]
- سان، اس. وانگ، ال. رنجان، ر. Wu, A. تحلیل معنایی و بازیابی دادههای فضایی بر اساس مدل هستیشناسی نامشخص در زمین دیجیتال. بین المللی جی دیجیت. زمین 2015 ، 8 ، 3-16. [ Google Scholar ] [ CrossRef ]
- یانگ، رایانه شخصی؛ وانگ، DW; یانگ، آر. کافاتوس، م. لی، کیو. تکنیک های بهبود عملکرد در GIS مبتنی بر وب. بین المللی جی. جئوگر. Inf. علمی 2005 ، 19 ، 319-342. [ Google Scholar ] [ CrossRef ]
- گودیوادا، وی. رائو، دی. Raghavan, VV NoSQL Systems for Big Data Management. در مجموعه مقالات کنگره جهانی خدمات IEEE 2014 (SERVICES)، انکوریج، AK، ایالات متحده آمریکا، 27 ژوئن تا 2 ژوئیه 2014. صص 190-197.
- هان، جی. E، H. پا.؛ Du, J. Survey on NoSQL Database. در مجموعه مقالات ششمین کنفرانس بین المللی IEEE در سال 2011 در مورد محاسبات فراگیر و کاربردها (ICPCA)، پورت الیزابت، آفریقای جنوبی، 26-28 اکتبر 2011. صص 363-366.
- کائور، ک. Rani, R. مدل سازی و پرس و جو داده ها در پایگاه های داده NoSQL. در مجموعه مقالات کنفرانس بین المللی IEEE در سال 2013 در مورد داده های بزرگ، دره سیلیکون، کالیفرنیا، ایالات متحده، 6 تا 9 اکتبر 2013.
- ناهمان، دبلیو. وی، جی. بررسی پایگاه های داده NoSQL و تست عملکرد در HBase. در مجموعه مقالات کنفرانس بین المللی IEEE 2013 در علوم مکاترونیک، مهندسی برق و کامپیوتر (MEC)، شنگ یانگ، چین، 20 تا 22 دسامبر 2013.
- گرولینگر، ک. کاپرتز، مام؛ مزغانی، ا. Exposito، E. دانش به عنوان یک چارچوب خدماتی برای مدیریت داده های بلایا. در مجموعه مقالات بیست و دومین کارگاه بین المللی IEEE 2013 در زمینه فن آوری های توانمند: زیرساخت برای شرکت های مشارکتی (WETICE)، Hammamet، تونس، 17-20 ژوئن 2013.
- گو، ی. وانگ، ایکس. شن، اس. وانگ، جی. کیم، JU تجزیه و تحلیل مکانیسم ذخیره سازی داده در پایگاه داده NoSQL MongoDB. در مجموعه مقالات کنفرانس بین المللی IEEE 2015 در مورد لوازم الکترونیکی مصرفی-تایوان (ICCE-TW)، شهر تایپه، تایوان، 6 تا 8 ژوئن 2015.
- لی، آر. فنگ، دبلیو. وو، اچ. Huang, Q. یک استراتژی تکرار برای یک سیستم ذخیره سازی پرسرعت توزیع شده بر اساس الگوهای دسترسی مکانی-زمانی داده های مکانی. محاسبه کنید. محیط زیست سیستم شهری 2017 ، 61 ، 163-171. [ Google Scholar ] [ CrossRef ]
- Qin، X. ژانگ، دبلیو. وانگ، دبلیو. وی، جی. ژونگ، اچ. Huang, T. پیکربندی مجدد استراتژی کش آنلاین برای پلت فرم کش کش کشسان: یک رویکرد یادگیری ماشین. در مجموعه مقالات سی و پنجمین کنفرانس سالانه نرم افزار و برنامه های کامپیوتری IEEE 2011 – COMPSAC، مونیخ، آلمان، 18 تا 22 ژوئیه 2011.
- لی، آر. ژانگ، ی. خو، ز. Wu, H. یک روش متعادل کننده بار برای GIS های شبکه در یک سیستم مبتنی بر خوشه ناهمگن با استفاده از چگالی دسترسی. ژنرال آینده. محاسبه کنید. سیستم 2013 ، 29 ، 528-535. [ Google Scholar ] [ CrossRef ]
- لی، آر. گوا، آر. خو، ز. Feng, W. یک مدل پیش واکشی مبتنی بر محبوبیت دسترسی برای دادههای مکانی در یک سیستم ذخیرهسازی مبتنی بر خوشه. بین المللی جی. جئوگر. Inf. علمی 2012 ، 26 ، 1831-1844. [ Google Scholar ] [ CrossRef ]
- پارک، دی.-جی. کیم، اچ.-جی. سیاستهای واکشی اولیه برای اشیاء بزرگ در یک برنامه GIS با قابلیت وب. دانستن داده ها مهندس 2001 ، 37 ، 65-84. [ Google Scholar ] [ CrossRef ]
- جلیل، ع. تئوبالد، KB; استیلی، SC; Emer, J. جایگزینی حافظه نهان با کارایی بالا با استفاده از پیش بینی بازه مرجع مجدد (RRIP). کامپیوتر ACM SIGARCH. آرشیت. News 2010 , 38 , 60. [ Google Scholar ] [ CrossRef ]
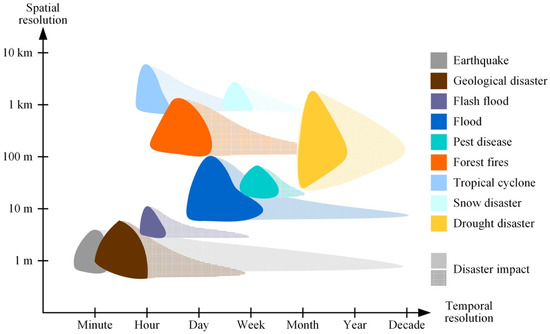
شکل 1. الزامات وضوح مکانی و زمانی تصاویر سنجش از دور در کاهش بلایا (برگرفته از “گزارش تحلیل امکان سنجی سیستم برنامه کاهش بلایا از صورت فلکی ماهواره ای کوچک برای نظارت و پیش بینی محیط زیست و بلایا، 2006، کمیته ملی کاهش بلایای چین”).
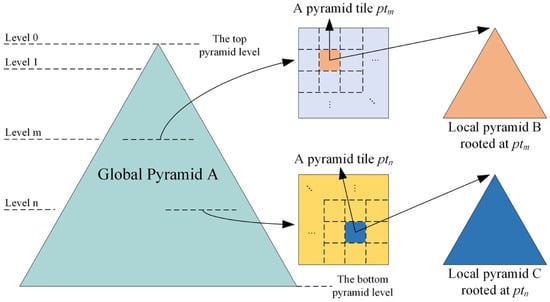
شکل 2. رابطه بین هرم جهانی و اهرام محلی.

شکل 3. همپوشانی چند لایه تصویر.
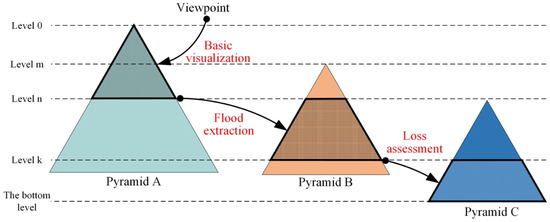
شکل 4. الزامات کاشی متنوع در تجسم سه بعدی یک منطقه فاجعه.

طرح 1. بخش های انتخاب شده از توضیحات مجموعه داده در یک فایل RDF.
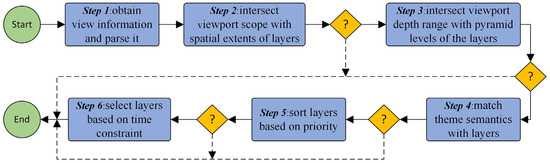
شکل 5. فرآیند تطبیق کاشی و فیلتر بر اساس تقاضا.

طرح 2. پرس و جو مشترک با ترکیب محدوده فضایی و محدودیت سطح در MongoDB.
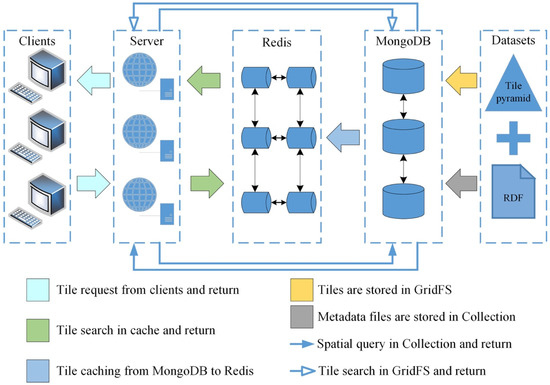
شکل 6. کل فرآیند درخواست کاشی از مشتریان و پاسخ در سرورها.

شکل 7. فرآیند جایگزینی LRU چند صفی.

شکل 8. فرآیند انتقال کاشی چندگانه HTTP/2.0.
شکل 9. نمودار مسیر پرواز نقطه دید.
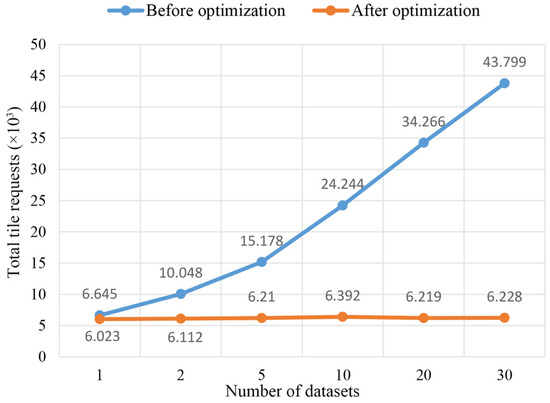
شکل 10. مقایسه کل درخواست های کاشی.

شکل 11. مقایسه درخواست های کاشی معتبر.
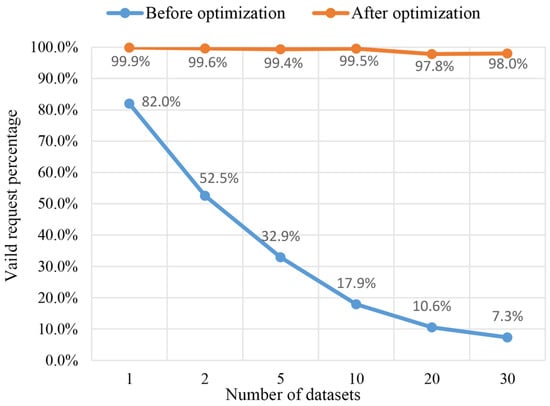
شکل 12. مقایسه نرخ درخواست کاشی معتبر.
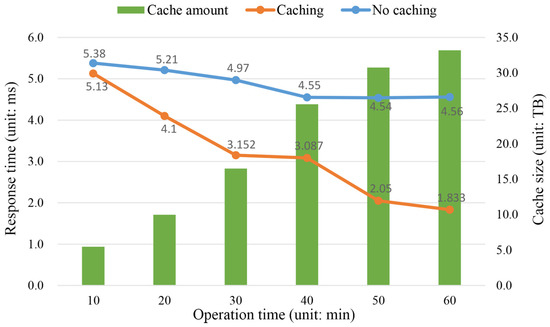
شکل 13. مقایسه بازده پاسخ همزمان با و بدون ذخیره سازی.

شکل 14. مقایسه بارگذاری کاشی با استفاده از دو روش مختلف.

جدول 1. جزئیات داده های تجربی.
© 2017 توسط نویسندگان؛ دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (CC-BY) (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر