1. معرفی
یک الگوی آبشاری به این معنی است که وقوع و توسعه یک پارامتر همیشه بر پارامتر دوم و به دنبال آن سوم و غیره تأثیر می گذارد [ 1 ]. در ژئوانفورماتیک، چنین الگوهایی رایج هستند. به عنوان مثال، در علم اقیانوس، نوسان جنوبی ال نینو (ENSO) ممکن است با تغییرات غیرعادی دمای سطح دریا (SST)، به دنبال آن یک ناهنجاری سطح دریا (SLA)، و در نهایت با بارش سطح دریا (SSP) دنبال شود. 2 ]. این پدیده را می توان به شکل “ENSO → SST → SLA → SSP” نشان داد، که در آن “→” به معنای پس از آن است. به طور مشابه، به عنوان مثالی که شامل مخاطرات طبیعی است، طوفان ها همیشه با طوفان باران و سپس سیل دنبال می شوند، به شکل «طوفان → طوفان باران → سیل» [ 3] .]. چنین واکنشی یک نوع خاص از الگوی ترتیبی است که برای اولین بار توسط Agrawal و Srikant [ 4 ] معرفی شد.
در دهههای اخیر، روشهای مختلفی برای ثبت الگوهای متوالی توسعه یافته است که میتوان آنها را به دو دسته سازماندهی کرد. دسته اول بر طراحی روش ها و بهبود عملکرد آنها تمرکز دارد که شامل الگوریتم های مبتنی بر Apriori و الگوریتم های رشد می باشد [ 5 ]. دسته دوم با بازنگری الگوریتم های رایج (به عنوان مثال، الگوهای تلفن همراه [ 6 ، 7 ، 8 ]، رویدادهای جغرافیایی [ 9 ، 10 ]، و الگوهای آبشاری [ 11 ]) بر برنامه های مشخص شده تمرکز می کند.
Apriori اولین الگوریتم پیشنهاد شده توسط Agrawal و Srikantto بود که با تحلیل داده های سبد بازار [ 4 ] سروکار داشت. سپس الگوریتم الگوی متوالی تعمیم یافته (GSP) به عنوان یک بهبود توسعه یافت [ 12 ]. چنین الگوریتمهایی از ایده اصلی Apriori استفاده میکنند و تابع پیوند و هرس بازگشتی را اتخاذ میکنند، که به تکرار اسکن پایگاه داده برای تولید الگوهای متوالی نیاز دارد. برای غلبه بر این مشکل با استفاده از قالبهای داده از پیش تعریفشده، انواع دادههای جدیدی برای جایگزینی آیتمها در تولید الگوهای متوالی معرفی شدهاند (مانند SPADE با شناسه رویداد [13] و SpaMi-FTS با بردارهای بیت [ 14]]). در اصل، الگوریتمهای مبتنی بر Apriori از جستجوی پهنای اول و هرس Apriori استفاده میکنند که مجموعههای بزرگی از نامزدها را برای رشد توالیهای طولانیتر ایجاد میکنند [ 15 ]. برای کاهش مجموعههای بزرگ نامزدها، الگوریتمهای الگوی رشد با ایده اصلی تقسیم و غلبه توسعه داده شدهاند [ 16 ، 17 ، 18 ، 19.]. از آنجایی که مجموعه کامل الگوهای متوالی را می توان به زیرمجموعه های مختلف با توجه به پیشوندهای مختلف تقسیم کرد، تعداد نامزدها به طور قابل توجهی کاهش می یابد اما به قیمت افزایش پایگاه داده های پیش بینی شده مربوطه. با چندین توالی مکرر، هر دو دسته الگوریتم به طور موثر اجرا نمی شوند زیرا تعداد بیشتری از دنباله های نامزد به تعداد بیشتری اسکن پایگاه داده یا ساخت پایگاه داده پیش بینی شده نیاز دارند.
برای کاربردهای واقعی، برخی از الگوریتمهای معمولی برای برآورده کردن الزامات مشخص بازنگری شدهاند. به عنوان مثال، با تعریف یک شاخص توالی فضایی، Huang et al. [ 9 ] یک الگوریتم مبتنی بر برش زمانی را برای یافتن رویدادهای مکانی-زمانی متوالی، که شامل پیوند و هرس مبتنی بر Apriori است، پیشنهاد کرد. الگوریتم استخراج مبتنی بر نمودار، ایده اصلی تقسیم و غلبه را با جایگزین کردن آیتمها با فهرستهای اطلاعات مسیر برای تولید همه الگوهای مسیر مکرر با پیوند دادن و هرس کردن [ 6 ] اتخاذ کرد. QPrefixSpan – گسترش مستقیم PrefixSpan – برای کشف الگوهای متوالی مکرر رویدادهای زمانی کمی پیشنهاد شد [ 10]. برای الگوهای آبشاری، استخراجکننده الگوی مکانی-زمانی آبشاری (CSTPM) استراتژیهای فیلترینگ را برای کاهش تعداد تکرارهای اسکن پایگاهداده اتخاذ کرد، اما ایده اصلی، جستجوی وسعت و به دنبال آن هرس Apriori [11] بود . به طور کلی، این روشها برنامههای واقعی را در چندین حوزه حل میکنند و توانایی کمی برای بهبود عملکرد الگوریتم استخراج دارند.
در مواجهه با تعداد زیادی از تکرارهای اسکن پایگاه داده برای تولید الگوهای مکرر معنیدار و محاسبات فشرده برای تولید نامزدهای الگوهای مکرر، هر دو دسته از روشها چالشهای بزرگی برای کشف الگوهای آبشاری پیشنهادی ما دارند. الگوی آبشاری یک سطحی ما به شکل ” X 1 → X 2 ” معنایی شبیه به یک مورد مرتبط جفتی به دست آمده از اطلاعات متقابل عادی دارد. اطلاعات متقابل نرمال شده میزان اطلاعاتی را که یک مورد در مورد دیگری ارائه می دهد را نشان می دهد [ 20]. به عنوان یک عدم تقارن، اطلاعات متقابل نرمالشده میتواند رابطه علّی بین اقلام را ایجاد کند، که به طور گسترده برای یافتن الگوهای مرتبط یا همبسته در دادهکاوی استفاده شده است [21 ، 22 ، 23 ، 24 ]. با این حال، در کاربردهای واقعی، الگوی آبشاری، به شکل « X 1 → X 2 → … → X n »، کاملاً متفاوت از الگوی مرتبط است، به شکل « X 1 X 2… X k → X k + 1 X k + 2… X n ”. به عنوان مثال، “La Niña → SST → SLA” به این معنی است که یک رویداد La Niña باعث وقوع SST می شود، و سپس SLA به دنبال آن می آید، در حالی که “La Niña → SST, SLA” به این معنی است که یک رویداد La Niña باعث وقوع همزمان می شود. SST و SLA.
بنابراین، انگیزه پشت این مقاله طراحی روشی برای استخراج الگوهای آبشاری به طور موثر با جاسازی اطلاعات متقابل نرمال شده، در نتیجه کاهش تعداد اسکن های پایگاه داده مورد نیاز و بهبود عملکرد است. هدف مطالعه ما موارد زیر است.
-
ما یک الگوریتم – روش کاوی مبتنی بر اطلاعات متقابل نرمال شده برای الگوهای آبشاری (M3 Cap) – برای استخراج الگوهای آبشاری با جاسازی اطلاعات متقابل نرمال شده پیشنهاد می کنیم . M 3 Cap از اطلاعات متقارن نامتقارن از آیتم ها برای به دست آوردن موارد مرتبط جفتی در ابتدا استفاده می کند، که به طور قابل ملاحظه ای تعداد اسکن های پایگاه داده مورد نیاز برای تولید الگوهای آبشاری را کاهش می دهد.
-
ما پیچیدگی محاسباتی M 3 Cap را تجزیه و تحلیل می کنیم و آن را به دو دسته – اسکن پایگاه داده و محاسبات فشرده طبقه بندی می کنیم. دسته اول الگوهای آبشاری معنیداری را از طریق شاخصهای ارزیابی به دست میآورد و دسته دوم همه نامزدهای یک الگوی آبشاری را با استفاده از پیوند بازگشتی و هرس به دست میآورد.
-
مجموعه داده های واقعی با تصاویر سنجش از دور بلند مدت که اقیانوس آرام را پوشش می دهند برای ارزیابی عملکرد M 3 Cap استفاده می شود. اطلاعات متقابل، پشتیبانی و آستانه های شاخص آبشاری در درجه اول بر تکرارهای اسکن پایگاه داده تأثیر می گذارد و تعداد رکوردهای پایگاه داده بر زمان یک اسکن پایگاه داده تأثیر می گذارد. تعداد آیتم های مشتق شده و آستانه اطلاعات متقابل، محاسبات فشرده را تعیین می کند.
ادامه این مقاله به شرح زیر سازماندهی شده است. در بخش 2 ، ما برخی از مفاهیم و ویژگی هایی را که به استفاده از اطلاعات متقابل در الگوریتم الگوریتم کاوی آبشاری مربوط می شود، مورد بحث قرار می دهیم. در بخش 3 ، گردش کار M 3 Cap را شرح می دهیم و به چهار موضوع کلیدی می پردازیم. در بخش 4 ، آزمایشها با مجموعه دادههای تصویر سنجش از دور برای بحث در مورد پیچیدگی محاسباتی M 3 Cap توضیح داده میشوند و عوامل اصلی مؤثر بر عملکرد آن تحلیل میشوند. ما مطالعه خود را در بخش 5 بررسی و خلاصه می کنیم .
2. مفاهیم و ویژگی های اساسی
این مطالعه از اصطلاحات زیر استفاده می کند.
یک آیتم نوعی پارامتر یا پدیده محیطی جغرافیایی است (به عنوان مثال، دما، بارش، بهرهوری اولیه، شاخص گیاهی تفاوت نرمال شده، یا یک رویداد ENSO).
اطلاعات متقابل نرمال شده مقدار اطلاعاتی است که یک مورد ( X ) در مورد دیگری ( Y ) [ 21 ] ارائه می کند، همانطور که در معادلات (1)-(3) نشان داده شده است.
که در آن X و Y موارد هستند، N تعداد کل رکوردهای تراکنش است، و v x و v y به ترتیب سطوح کمی در دامنه dom( x ) و domaindom( y ) هستند. n ( v x ) و n ( v x ، v y ) به ترتیب تعداد وقوع v x و تعداد همزمان v x و v y هستند . p ( v x) چگالی احتمال مورد X است و p ( v x , v y ) چگالی احتمال مشترک بین موارد X و Y است .
حمایت و اطمینان، شاخص های رایج ارزیابی قوانین انجمن هستند [ 25 ]. در این مقاله، ما از این مفاهیم برای تعریف دو شاخص ارزیابی جدید برای الگوهای آبشاری – پشتیبانی و شاخص آبشاری – استفاده میکنیم.
پشتیبانی احتمال وقوع همزمان موارد X 1 , X 2 , …, X m , در مجموعه داده است که به صورت تعریف می شود
که در آن N تعداد کل مجموعه داده است، و n ( X 1 ، X 2 ، …، X m ) تعداد همزمان موارد X 1 ، X 2 ، …، X m ، در مجموعه داده است.
شاخص آبشاری احتمال وقوع مورد X m را با فرض اینکه آیتم X m − 1 , X m − 2 , …, X 1 به ترتیب رخ می دهد را توصیف می کند که به این صورت تعریف می شود:
که در آن k یک سطح آبشاری و m تعداد آیتم ها است.
یک الگوی آبشاری یک رابطه مرتب با موارد متوالی است که در شکل زیر نشان داده شده است، که در آن S و CI شاخص های ارزیابی هستند.
الگوی آبشاری سطح m یک الگوی آبشاری متشکل از ( m + 1) آیتم است.
زیر مجموعه های سطح ( m – 1) یک الگوی آبشاری سطح m زیر مجموعه های یک الگوی آبشاری سطح m در سطح ( m – 1) هستند. ( m + 1) الگوهای آبشاری زیر مجموعه های سطح ( m – 1) یک الگوی آبشاری سطح m وجود دارد .
مثال 1.
هنگامی که رویدادهای لانینا در اقیانوس آرام غربی رخ می دهد، که توسط جریان های استوایی شمالی و جنوبی و جریان مخالف استوایی تقویت می شود، دمای سطح دریا (SST) به طور غیرعادی افزایش می یابد، افزایش SST جرم آب را جمع می کند که به سمت غرب حرکت می کند، و SLA به طور غیر طبیعی افزایش می یابد. بنابراین، الگوی آبشاری در بین La Niña، SST و SLA به شکل “La Niña → SST → SLA” است. این الگو یک الگوی آبشاری دو سطحی با سه زیرالگوی یک سطحی، “La Niña → SST”، “La Niña → SLA” و “SST → SLA” است.
مثال 2.
با فرض اینکه الگوی آبشاری دو سطحی “La Niña → SST → SLA” در مثال 1 معنادار است، و رکوردهای موجود در پایگاه داده در جدول 1 نشان داده شده است، جایی که 1 به این معنی است که یک رویداد La Niña رخ می دهد، SST افزایش می یابد، یا SLA افزایش می یابد، در حالی که 0 به این معنی است که ندارد، و ID یک شناسه یکنواخت است که یک رکورد خاص را نشان می دهد – یک فیلد منظم در یک جدول پایگاه داده. بنابراین، پشتیبانی از “La Niña → SST → SLA” n(La Niña, SST, SLA)/N×100% (یعنی 30%) است و شاخص Cascading حداقل است{n(La Niña, SST) /n(La Niña) × 100٪، 66.7٪، n (La Niña، SST، SLA)/n (La Niña، SST) × 100٪، 75.0٪، (یعنی 66.7٪).
از آنجایی که اطلاعات متقابل نرمال شده نامتقارن است، آیتم های مرتبط دارای جهتی به شکل ” X 1 → X 2 ” هستند و ماتریس اطلاعات متقابل نرمال شده اقلام فقط الگوهای آبشاری یک سطحی را شناسایی می کند. به دست آوردن مجموعه کامل الگوهای آبشاری نیاز به پیوند و هرس دارد که به ویژگی های اطلاعات متقابل نرمال شده بستگی دارد.
ویژگی 1. عدم تقارن اطلاعات.
عدم تقارن خاصیتی است که به موجب آن اطلاعاتی که مورد X 1 به مورد X 2 ارائه می دهد با اطلاعات ارائه شده توسط مورد X 2 به مورد X 1 متفاوت است . این ویژگی موارد مرتبط جفتی را با جهت گیری ارائه می دهد (به عنوان مثال، “X 1 → X 2 ” ممکن است در شرایط خاص صادق باشد، به این معنی که یک تغییر در X 1 باعث ایجاد تغییرات در X 2 می شود ، در حالی که “X 2 → X 1 ” ممکن است درست نباشد). این ویژگی توسط Ref. [ 21 ].
اموال 2. اطلاعات غیر افزودنی.
غیرافزایش خاصیتی است که به موجب آن هنگام برخورد با فرآیندهای چند سطحی، اطلاعات پس از هر سطح کاهش می یابد. به این معنا که پردازش اطلاعات به سادگی سیگنال، داده یا پیام را به شکل مفیدی تبدیل می کند و هیچ اطلاعات جدیدی ایجاد نمی کند. این ویژگی به صورت نابرابری های زیر نشان داده می شود.
اثبات مالکیت 2.
با توجه به یک الگوی آبشاری دو سطحی به شکل “X 1 → X 2 → X 3 ” که با I(X 1 ; X 2 ; X 3 ) مشخص می شود، به این معنی که X 1 مقدار اطلاعات را نشان می دهد که X 3 بعد از X رخ می دهد. 2 رخ می دهد. با توجه به مفاهیم و تعاریف مرتبط مرجع [ 20 ]، معادلات (8) و (9) زیر صحیح است.
که در آن، I ( X 1 ؛ X 2 X 3 ) نشان دهنده یک اطلاعات متقابل مشترک بین X 1 ، X 2 و X 3 است ، به این معنی که X 1 در مورد مقدار اطلاعات زمانی که X 2 و X 3 همزمان رخ می دهند می گوید، در حالی که من ( X 1 ; X 3 | X 2 ) نشان دهنده یک اطلاعات متقابل مشروط است، به این معنی که با توجه به X 2 ، مقدار اطلاعات X 1در مورد X 3 می گوید . همانطور که X 2 ، X 1 و X 3 داده شده مستقل هستند، یعنی I ( X 1 ; X 2 | X 3 ) = 0، معادله (10) درست است.
همانطور که I ( X 1 ; X 3 | X 2 ) ≥ 0، فرمول (11) درست است.
فرمول های (12) و (13) نیز از استدلال مشابه نتیجه می گیرند.
خاصیت 3. ضد یکنواختی.
تمام زیر مجموعه های غیر خالی یک الگوی آبشاری نیز باید الگوهای آبشاری باشند.
اثبات مالکیت 3.
شاخص پشتیبانی و آبشاری یک الگوی آبشاری به شکل « X 1 → X 2 → … → X m » معادله (14) را برآورده می کند. با توجه به زیرالگوهای سطح ( m − 1) آن، مطابق با معادلات (5) و (6)، معادلات (15) و (16) درست هستند. بنابراین، تمام زیر مجموعه های سطح ( m – 1) الگوهای آبشاری هستند. الگوهای فرعی ( m – 2) تا یک سطح نیز می توانند با استفاده از یک گردش کار مشابه ثابت شوند.
3. روش استخراج مبتنی بر اطلاعات متقابل برای الگوهای آبشاری (M 3 Cap)
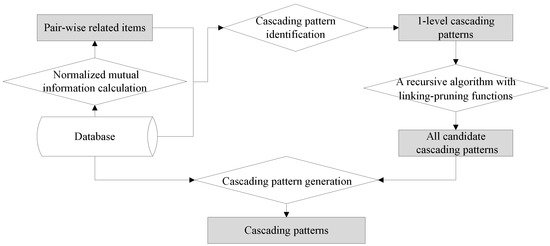
با استفاده از مفاهیم و ویژگی های اساسی که در بالا توضیح داده شد، گردش کار M 3 Cap، که شامل چهار مرحله کلیدی است، در شکل 1 نشان داده شده است . مرحله اول اطلاعات متقابل نرمال شده را در بین اقلام محاسبه می کند و اقلام مرتبط جفتی را به دست می دهد. مرحله دوم الگوهای آبشاری یک سطحی را از آیتم های مرتبط جفت تولید می کند. سومی توابع پیوند-هرس بازگشتی را برای تولید همه الگوهای آبشاری نامزد طراحی میکند. مرحله چهارم با حذف الگوهای شبه از نامزدها، الگوهای آبشاری معنادار را حفظ می کند.
3.1. الگوریتمی برای تولید اقلام مرتبط با جفت
بر اساس مجموعه داده های گسسته سازی (یعنی جدول تراکنش های استخراج)، پایگاه داده یک بار اسکن شد تا اطلاعات متقابل نرمال شده بین همه جفت آیتم ها مطابق با معادلات (1) – (3) محاسبه شود، و جدول اقتضایی اطلاعات متقابل نرمال شده آنها محاسبه شد. ساخته شده است. جدول 2 ساختار آن را نشان می دهد. هر عنصر در این جدول، I ( X i ، X j )، نشان می دهد که مورد X i اطلاعاتی را در مورد مورد X j ارائه می دهد که به شکل ” X i → X j ” نشان داده شده است.
به طور کلی، میانگین و انحراف معیار اطلاعات متقابل اقلام برای نشان دادن موارد بسیار مرتبط استفاده می شود [ 23 ]. در اینجا، فقط عناصر داخل جدول که نابرابری زیر را برآورده میکنند، بهعنوان موارد مرتبط زوجی در نظر گرفته میشوند.
که در آن μ و σ به ترتیب میانگین و انحراف معیار اطلاعات متقابل هستند که i برابر با j نیست و λ یک عامل اسکالر است. به دلیل عدم تقارن آیتم مربوط به زوج، ” X i → X j “، X i را به عنوان مقدم و X j را به عنوان نتیجه تعریف می کنیم .
3.2. الگوهای آبشاری یک سطحی با رتبه های کمی
این مرحله تمام الگوهای آبشاری یک سطحی را با رتبههای کمی از آیتمهای مرتبط جفتی تولید میکند. رتبه های کمی نشان دهنده تغییرات یک آیتم است. به طور کلی، همه اقلام مرتبط زوجی با رتبه های کمی معنادار نیستند. یعنی فقط رتبه های کمی آیتم با فراوانی کمتر از آستانه ارزیابی حفظ می شود. بنابراین، این موضوع نیاز به سه مرحله دارد. مرحله اول با یک بار اسکن پایگاه داده، آیتم های مرتبط معنی دار را با رتبه های کمی استخراج می کند. مرحله دوم الگوهای آبشاری کمی یک سطحی نامزد را از طریق جایگشت و ترکیب موارد معنی دار با رتبه های کمی ایجاد می کند. مرحله سوم با اسکن پایگاه داده با استفاده از معیار زیر، الگوهای آبشاری یک سطحی را از نامزدها به دست میآورد. فرکانس کمتر از پشتیبانی مشخص شده توسط کاربر و یک شاخص آبشاری کمتر از آستانه تعیین شده توسط کاربر نیست. پایگاه داده یک بار برای هر کاندید الگوی آبشاری کمی یک سطحی اسکن می شود. بنابراین، تمام الگوهای آبشاری یک سطح به دست می آیند. الگوریتم 1 شبه کد این تابع را نشان می دهد.
| الگوریتم 1. الگوریتم برای شناسایی الگوهای آبشاری یک سطحی از موارد مرتبط جفت. |
| نام الگوریتم: OneLevelCascadingPatternIdentification. |
| شرح الگوریتم : شناسایی تمام الگوهای آبشاری یک سطحی با رتبه های کمی از آیتم های مرتبط جفت. |
| پارامترهای ورودی: اقلام مرتبط جفتی، که با PI نشان داده می شوند ، و یک رتبه کمی، با R نشان داده می شوند . |
| پارامترهای خروجی: الگوهای آبشاری یک سطحی که با 1-CP نشان داده می شوند. |
| 1 |
OneLevelCascadingPatternIdentification ( PI , R , 1-CP) |
| 2 |
برای i امین مورد مرتبط جفتی در PI که با i − pi نشان داده می شود. |
| 3 |
مقدم و نتیجه آن را استخراج کنید که به ترتیب با X i و X j مشخص می شود. |
4
5
6 |
جایگشت و ترکیب Xi و Xj با رتبههای کمی، یعنی r و l به ترتیب، جایی که r ، l∈ R ، سپس نامزدهای الگوی آبشاری را به شکل Xi [ r ] → Xj [ l ] ایجاد کنید . |
| 7 |
برای هر X i [ r ] → X j [ l ] |
8
9 |
پایگاه داده را یک بار اسکن کنید و پشتیبان های X i و X j را با رتبه های کمی از طریق معادله (4) محاسبه کنید. |
10
11 |
اگر نابرابری های زیر درست باشند، که τ S آستانه حمایت است. |
| 12 |
S(Xi[r])≥τSS(Xj[l])≥τS}�(��[�])≥���(��[�])≥��} |
13
14 |
X i و X j با رتبه کمی r و l حفظ می شوند ، یعنی X i [ r ] و X i [ l ] . |
| 15 |
END IF |
16
17 |
با استفاده از معادلات (4) و (5)، حمایت و شاخص آبشاری آن را محاسبه کنید. |
18
19 |
اگر نابرابری های زیر درست باشند، که τ CI آستانه شاخص آبشاری است. |
| 20 |
S(Xi[r]Xj[l])≥τSCI(Xi[r]Xj[l])≥τCI}�(��[�]��[�])≥����(��[�]��[�])≥���} |
21
22
23 |
X i [ r ] و X j [ l ] را به شکلی با X i [ r ] → X j [ l ] پیوند دهید ، آن را به عنوان الگوی آبشاری یک سطحی، یعنی 1- cp نشان دهید و آن را در 1- CP ذخیره کنید. |
| 24 |
END IF |
| 25 |
پایان برای |
| 26 |
i = i + 1 |
| 27 |
پایان برای |
خط 10 تا خط 12 معیارهای متمایز هستند که برای یافتن اقلام معنی دار با رتبه کمی مشخص (خط 13 تا خط 14) استفاده می شود، به طور مشابه، خط 18 تا خط 20 برای ایجاد یک الگوی آبشاری یک سطحی جدید انجام می شود. از خط 7 تا خط 25، یک آیتم مرتبط با جفت با تمام رتبههای کمی برای تولید الگوهای آبشاری یک سطحی از صفر تا چند سطح انجام میشود، و خط 2 تا خط 27 تکرار میشود تا با تمام موارد مرتبط جفتی سروکار داشته باشد.
مثال 3 .
با توجه به موارد مرتبط جفتی X و Y، X و Z، و Y و Z از فرم های “X → Y”، “X → Z” و “Y → Z” معنی دار هستند و رتبه های کمی آنها از 5 تعیین می شود. −2 تا 2 با فاصله ممتد. مجموعه داده های کمی در جدول 3 نشان داده شده است . آستانه شاخص حمایتی و آبشاری به ترتیب 30 درصد و 60 درصد تعیین شده است.
طبق جدول 3 ، فرکانس های X [2]، X [1]، X [0]، X [-1] و X [-2] 50٪، 0٪، 10٪، 30٪ و 10 است. به ترتیب، و فرکانسهای Y [2]، Y [1]، Y [0]، Y [–1] و Y [–2] 40٪، 30٪، 20٪، 0٪ و 10 است. به ترتیب، در حالی که موارد Z [2]، Z [1]، Z [0]، Z [-1]، و Z [-2] 0٪، 0٪، 20٪، 30٪ و 50٪ هستند. ، به ترتیب. با توجه به آستانه پشتیبانی، فقط X [2]، X[–1]، Y [2]، Y [1]، Z [–1] و Z [–2] معنیدار هستند. با موارد مرتبط جفت، ” X → Y ” و از طریق جایگشت و ترکیب آنها، الگوهای آبشاری یک سطح نامزد عبارتند از ” X [2] → Y [2]”، ” X [2] → Y [1] ]»، « X [–1] → Y [2]»، و « X [–1] → Y [1]». پس از اعمال پشتیبانی مشخص شده توسط کاربر و آستانه های شاخص آبشاری، فقط الگوی آبشاری یک سطحی، ” X [2] → Y[2]، که دارای حمایت 30٪ و شاخص آبشاری 60٪ است، حفظ می شود. ” X [2] → Z [-2] (40٪، 80٪) و ” Y [2] → Z [-2] (40٪، 100٪)” به طور مشابه به دست می آیند.
3.3. الگوریتم بازگشتی برای تولید نامزدهای همه الگوهای آبشاری
این الگوریتم بازگشتی همه الگوهای آبشاری سطح نامزد ( m + 1) را از الگوهای سطح m مطابق توابع پیوند و هرس تولید می کند، جایی که m کمتر از یک نباشد. در این مرحله، توابع پیوند و هرس به صورت بازگشتی بدون اسکن پایگاه داده اجرا می شوند تا زمانی که الگوهای آبشاری نامزد دیگری تولید نشوند.
تابع پیوند، الگوهای آبشاری سطح نامزد ( m + 1) را از الگوهای یک سطح و m- سطح تولید می کند. شبه کد برای تابع پیوند در الگوریتم 2 نشان داده شده است.
| الگوریتم 2. الگوریتم پیوند الگوهای آبشاری سطح m برای تولید ( m + 1) آنهایی که در سطح هستند. |
| نام الگوریتم : الگوریتم پیوند. |
| شرح الگوریتم : الگوهای آبشاری سطح m (یعنی m -CP) را برای تولید الگوهای آبشاری سطح ( m + 1) (یعنی ( m + 1)-CP) با توجه به عدم تقارن اطلاعاتی ویژگی 1 پیوند دهید. |
| پارامترهای ورودی : الگوهای آبشاری یک سطحی، الگوهای آبشاری 1-CP و m -level، m -CP. |
| پارامترهای خروجی : ( m + 1) -الگوهای آبشاری سطح، ( m + 1) -CP. |
| 1 |
الگوریتم پیوند (1-CP، m -CP، ( m + 1) – CP) |
| 2 |
برای الگوی آبشاری سطح m در m -CP ، که با i ام -cp نشان داده می شود . |
3
4 |
آخرین مورد آن، یعنی X i m + 1 [ r i m + 1 ] را استخراج کنید و آن را به عنوان PostItem نشان دهید و بقیه به ترتیب به شکلی با X i 1 [ r i 1 ] X i 2 [ r سازماندهی می شوند. i 2 ]… X i m [ r i m ] که به عنوان PreItems نشان داده می شود . |
| 5 |
برای j ام الگوی آبشاری سطح 1 در 1-CP، که با i 1-cp نشان داده می شود. |
6
7 |
مقدمه آن را استخراج کنید، یعنی X j 1 [ r j 1 ] را که به صورت Pre نشان داده می شود، و در نتیجه X j 2 [ r j 2 ] را که به عنوان Post نشان داده می شود، استخراج کنید . |
8
9 |
IF Pre با PostItem یکسان است ، یعنی موارد X j 1 و X i m + 1 یکسان هستند و سطوح r j 1 و r i m + 1 برابر هستند. و X j 2 را در X i 1 [ r i 1 ] X i 2 [ r i 2 ] … X i m [ r i m ] پیدا نکنید. |
10
11
12 |
پیوند m -cp با اضافه کردن مورد X j 2 [ r j 2 ] به شکل X i 1 [ r i 1 ] → X i 2 [ r i 2 ] → … → X i m [ r i m ] → X i m + 1 [ r i m + 1 ] → X j 2 [ rj 2 ]، آن را به صورت ( m + 1) -cp نشان دهید و آن را در ( m + 1) -CP |
| 13 |
END IF |
| 14 |
j = j + 1 |
| 15 |
پایان برای |
| 16 |
I = I + 1 |
| 17 |
پایان برای |
خطوط 8 و 9 معیارهای تبعیض پیوند را ارائه می دهند. پیوند در صورتی انجام میشود که آخرین مورد از الگوی آبشاری سطح m با اولین مورد از الگوی آبشاری یکسطحی یکسان باشد (یعنی یک آیتم واحد و یک سطح کمی داشته باشند). الگوی آبشاری سطح m آخرین مورد از الگوی آبشاری یک سطحی را شامل نمی شود (خط 10 تا خط 12). از خط 8 تا خط 13 پیوند صفر (معیار تشخیص نادرست است) به یک (معیار تشخیص درست است) انجام می شود. از خط 5 تا خط 15، یک حلقه بین یک الگوی آبشاری سطح متر با تمام الگوهای یک سطح اجرا می شود و خط 2 تا خط 17 برای تولید همه (m) تکرار می شود .+ 1)-سطح الگوهای آبشاری. مسئله کلیدی در این تابع، تبعیض پیوند است.
مثال 4.
الگوهای آبشاری یک سطحی “X[2] → Y[2]”، “X[2] → Z[-2]”، و “Y[2] → Z[-2]” وجود دارد (نتایج مثال 3) . از آنجایی که الگوهای آبشاری یک سطحی هستند، m-CP ورودی نیز یک CP است (یعنی الگوهای آبشاری یکسانی دارند). برای اولین الگوی آبشاری در m-CP، “X[2] → Y[2]”، تابع به صورت متوالی از یک CP عبور می کند. از آنجایی که اولین الگوی آبشاری در one-CP همان “X[2] → Y[2] است، هیچ پیوندی انجام نمی شود. با توجه به الگوی دوم در one-CP، “X[2] → Z[-2]”، زیرا آخرین مورد Y[2] با مورد اول X[2] یکسان نیست، هیچ پیوندی انجام نمیشود. با توجه به سومین مورد در one-CP، «Y[2] → Z[−2]»، زیرا آخرین مورد Y[2] مانند مورد اول Y[2] است، یک پیوند انجام میشود و یک فرم جدید تولید شده، “X[2] → Y[2] → Z[-2]”. به طور مشابه، سایر الگوهای آبشاری در m-CP تجزیه و تحلیل میشوند و هیچ پیوندی وجود ندارد. بدین ترتیب،
تابع هرس، الگوهای آبشاری کاذب در سطح m را از الگوهای کاندید در سطح m مطابق با ویژگیهای 2 و 3 حذف میکند. مسئله کلیدی این مرحله یافتن همه زیرالگوهای سطح ( m – 1) الگوهای آبشاری یک m – است. الگوی سطح تا زمانی که یک الگوی فرعی یک الگوی آبشاری سطح ( m – 1) نباشد ، الگوی آبشاری نامزد سطح m حذف میشود. در غیر این صورت، الگوی آبشاری نامزد حفظ می شود. شبه کد تابع هرس به صورت الگوریتم 3 نشان داده شده است.
| الگوریتم 3. الگوریتم هرس برای حذف الگوهای شبه آبشاری. |
| نام الگوریتم: PruningAlgorithm. |
| شرح الگوریتم : الگوهای شبه آبشاری را از نامزدهای سطح m الگوهای آبشاری، که با m -CCP نشان داده میشوند، حذف کنید تا الگوهای آبشاری سطح m ، که با m -CP نشان داده میشوند، مطابق با ویژگی 2. اطلاعات غیرافزودنی و ویژگیها 3. ضد یکنواختی. |
| پارامترهای ورودی: نامزدهای سطح m از الگوهای آبشاری (یعنی m -CCP) و الگوهای آبشاری سطح ( m – 1) که با ( m – 1) -CP مشخص میشوند. |
| پارامترهای خروجی : الگوهای آبشاری سطح m (یعنی m -CP) . |
| 1 |
الگوریتم هرس ( m -CCP، ( m – 1) -CP، m -CP) |
| 2 |
برای i امین سطح m کاندید الگوی آبشاری در m -CCP، که با i ام-ccp نشان داده می شود . |
| 3 |
زیرمجموعه های سطح ( m – 1) آن را استخراج کنید که با ( m – 1) -S مشخص می شود. |
| 4 |
الگوی آبشاری سطح j th ( m – 1) در ( m – 1)-S که با j th ( m – 1) -s |
| 5 |
اگر j th( m- 1)-s در ( m- 1)-CPیافت نمی شود |
| 6 |
به خط 11 بروید |
| 7 |
END IF |
| 8 |
J = j + 1 |
| 9 |
پایان برای |
| 10 |
m – ccp من به عنوان یک الگوی آبشاری سطح m حفظ می شود و در m -CP ذخیره می شود. |
| 11 |
i th m -ccp حذف می شود |
| 12 |
I = I + 1 |
| 13 |
پایان برای |
خط 5 معیار تبعیض حذف است. تا زمانی که یک زیرالگوی سطح ( m – 1) از الگوی سطح m کاندید در بین الگوهای آبشاری سطح ( m – 1) یافت نشود ، الگوی آبشاری سطح m کاندید حذف می شود (خط 11) و بعدی الگوی آبشاری سطح m کاندید پردازش می شود (خط 12). اگر همه زیر مجموعههای سطح ( m – 1) الگوی آبشاری سطح m کاندید، الگوهای آبشاری سطح ( m – 1) باشند، الگوی آبشاری سطح m کاندید به عنوان m سطح یک در نظر گرفته میشود (خط 10). از خط 4 تا خط 9، یک حلقه از طریق تمام (m – 1) زیر مجموعه های سطح به ترتیب برای تعیین الگوهای آبشاری. خط 3 همه زیرالگوهای سطح ( m – 1) یک الگوی آبشاری سطح m را استخراج می کند و خط 2 تا خط 13 تکرار می شود تا همه الگوهای آبشاری سطح m نامزد را متمایز کند .
3.4. ایجاد الگوهای آبشاری با شاخص های ارزیابی
این مرحله با توجه به حداقل آستانه شاخصهای ارزیابی، الگوهای آبشاری معنیداری را از داوطلبان ایجاد میکند. به طور کلی، آستانه های مشخص شده توسط کاربران با توجه به حوزه های تحقیقاتی آنها تعریف می شود. شاخص های ارزیابی هر الگوی آبشاری، شامل پشتیبانی و شاخص آبشاری، با یک بار اسکن پایگاه داده محاسبه می شود. اگر شاخص های ارزیابی آستانه های مشخص شده توسط کاربر را که در معادله (18) نشان داده شده است، برآورده کنند، یک الگوی آبشاری معنادار است. آستانه پشتیبانی، σ s ، به معنای حداقل احتمال همزمانی الگو در پایگاه داده است، در حالی که شاخص آبشاری، σ CI ، به معنای حداقل احتمال وقوع هر یک از الگوهای فرعی در پایگاه داده در برابروقوع الگو در این مرحله موضوع کلیدی اسکن پایگاه داده و محاسبه شاخص های ارزیابی است.
4. آزمایشات
این بخش به سه مطالعه موردی برای M 3 Cap با استفاده از سری های زمانی طولانی تصاویر سنجش از دور می پردازد. آزمایش اول پیچیدگی محاسباتی M 3 Cap را از دیدگاه اسکن پایگاه داده و محاسبات فشرده تجزیه و تحلیل می کند، آزمایش دوم امکان سنجی و اثربخشی M 3 Cap را در مقایسه با الگوریتم Apriori مشتق شده نشان می دهد، و سوم الگوهای آبشاری عناصر محیطی دریایی را بررسی می کند. اقیانوس آرام.
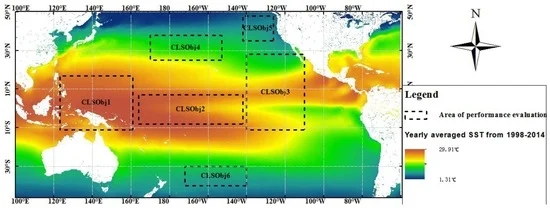
این موارد بر روی تصاویر سنجش از راه دور دریایی طولانیمدت انجام شد که ناهنجاریهای ماهانه دمای سطح دریا به نام SSTA، ناهنجاریهای ماهانه کلروفیل a سطح دریا، CHLA ، ناهنجاریهای ماهانه بارش سطح دریا، SSPA و ناهنجاریهای ماهانه سطح دریا را نشان داد. ناهنجاری، SLAA. برای شناسایی رویدادهای ENSO از شاخص چند متغیره ENSO (MEI) استفاده شد. جدول 4 مجموعه داده های مورد استفاده را خلاصه می کند. پارامترهای محیطی دریایی در پنج سطح برای فواصل پیوسته (2-، -1، 0، 1 و 2) رتبه بندی می شوند که به ترتیب نشان دهنده تغییر منفی شدید، تغییر منفی خفیف، بدون تغییر، تغییر مثبت خفیف و تغییر مثبت شدید است. در مورد شاخص MEI، 2- نشان دهنده رویدادهای قوی لانینا است، در حالی که +2 نشان دهنده رویدادهای قوی ال نینو است [ 26]]. مجموعه داده های تصویری ماهانه با وضوح فضایی 1 درجه در طول و عرض جغرافیایی از ژانویه 1998 تا دسامبر 2014 برای شش منطقه مختلف در اقیانوس آرام، که به صورت CLSObj1، CLSObj2، CLSObj3، CLSObj4، CLSObj26، و CLSObj5، و CLSObj6 و Figure هستند . برای آزمایش الگوریتم ها استفاده می شود. هر ناحیه از یک سری شبکه های شطرنجی تشکیل شده است که هر کدام شامل چهار پارامتر SSTA، SSPA، SLAA و CHLA با شاخص ENSO می باشد. محیط سخت افزاری آزمایشی شامل یک پردازنده مرکزی Intel core i7 با فرکانس 2.80 گیگاهرتز، یک هارد دیسک 500 گیگابایتی و 4.0 گیگابایت حافظه است.
4.1. پیچیدگی محاسباتی
پیچیدگی محاسباتی M 3 Cap به دو دسته طبقه بندی می شود: تعداد اسکن های پایگاه داده و محاسبات فشرده.
در فرآیند M 3 Cap، اسکن پایگاه داده شامل سه مرحله است. مرحله اول با یک بار اسکن پایگاه داده، جدول احتمالی اطلاعات متقابل را می سازد. مرحله دوم الگوهای آبشاری یک سطحی را از آیتمهای مرتبط زوجی با رتبههای کمی شناسایی میکند. برای هر مورد مرتبط جفت با هر رتبه کمی، یک اسکن پایگاه داده وجود دارد. برای رتبه کمی داده شده، R و تعداد کل موارد، M ، با توجه به تابع OneLevelCascadingPatternIdentification، تعداد اسکن های پایگاه داده ( R × M ) × ( R × ( M − 1)) است (یعنی R 2 × پ2مپم2) و پیچیدگی محاسباتی شناسایی الگوهای آبشاری یک سطحی O ( R2 ×M2 ) است . برای مرحله سوم، M 3 Cap از معادله (15) استفاده می کند تا با یک بار اسکن پایگاه داده، یک الگوی آبشاری معنادار برای هر الگوی کاندید پیدا کند. از نظر تئوری، R 2 × وجود دارد پ2مپم2 + R 3 × پ3مپم3 + … + R M × M ! (یعنی O ( R 2 × پ2مپم2 + R 3 × پ3مپم3 + … + R M × M!)) الگوهای آبشاری نامزد. از این رو، پیچیدگی محاسباتی یافتن یک الگوی آبشاری معنادار o(R 2 × M 2 ) + o (R 3 × M 3 ) + … + o (R M × M M ) است . با این حال، در واقعیت، الگوهای آبشاری نامزد به طور قابل توجهی مطابق با آستانه اطلاعات و ویژگیهای 2 و 3 کاهش مییابد که به طور قابلتوجهی کمتر از R2 × هستند. پ2مپم2 + R 3 × پ3مپم3 + … + R M × M !.
M 3 Cap شامل دو مرحله محاسبات فشرده است. یک مرحله اقلام مرتبط جفتی را از جدول احتمالی اطلاعات متقابل بدست می آورد. M × ( M – 1) تبعیض برای تعیین موارد مرتبط با توجه به آستانه اطلاعات وجود دارد . از این رو، پیچیدگی محاسباتی O ( M2 ) است. مرحله دیگر الگوهای آبشاری نامزد را با استفاده از یک الگوریتم پیوند بازگشتی و هرس ایجاد می کند. در مرحله پیوند، طبق الگوریتم پیوند، الگوهای آبشاری سطح ( m + 1) با پیوند دادن الگوهای m سطح و یک سطح تولید می شوند و تعداد پیوندها R 2 × M است. 2 × R m × پمترمپممتر; بنابراین، پیچیدگی پیوند o ( R 2 × M 2 × R m × است پمترمپممتر) = o ( R 2 + m × M 2 + m ). در مرحله هرس، برای هر الگوی آبشاری سطح نامزد ( m + 1)، زیرالگوهای ( m + 2) از یک الگوی آبشاری سطح m وجود دارد . هر زیر مجموعه به یک محاسبه نیاز دارد تا مشخص کند که آیا الگوی آبشاری سطح ( m + 1) باید حذف شود یا خیر. تعداد تبعیض ها R 2 × M 2 × R m × است پمترمپممتر × ( m + 2)؛ بنابراین، پیچیدگی هرس o ( m × R 2 + m × M 2 + m ) است.
4.2. عوامل موثر بر عملکرد M 3 Cap
با توجه به یک رتبه کمی، سه عامل بر عملکرد M 3 Cap تأثیر می گذارد. آنها آستانه اطلاعات، آستانه ارزیابی و اندازه پایگاه داده (یعنی تعداد فیلدهای پایگاه داده (موارد مشتق شده)) و رکوردها هستند. آستانه اطلاعات تعیین می کند که چند آیتم به صورت جفتی مرتبط هستند و بر زمان اسکن پایگاه پایگاه داده تأثیر می گذارد. آستانه ارزیابی با اسکن پایگاه داده تعداد الگوهای آبشاری معنادار از میان نامزدها تعیین می شود. فیلدهای پایگاه داده زمان اسکن پایگاه داده را تعیین می کنند و رکوردهای پایگاه داده زمان محاسباتی را برای اسکن پایگاه داده تعیین می کنند.
4.2.1. آستانه اطلاعات
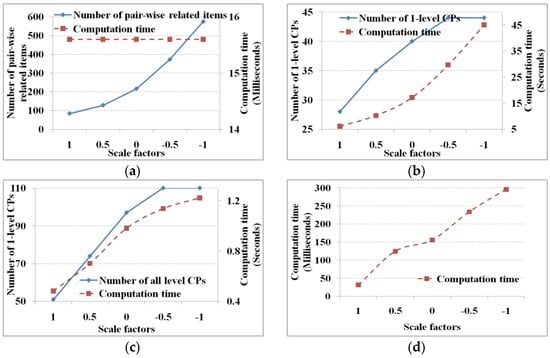
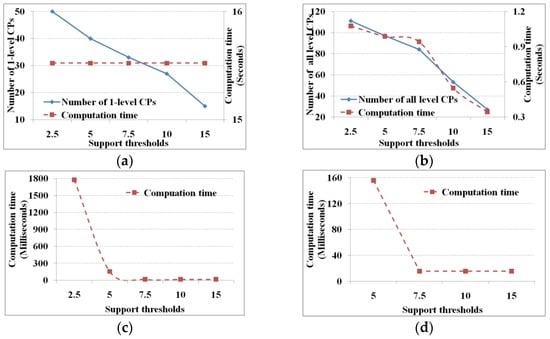
آستانه اطلاعات متقابل، آیتم های مرتبط اولیه را به صورت جفت تعیین می کند و سپس الگوهای آبشاری را به دست می آورد. طبق رابطه (14)، آستانه از طریق میانگین 1.0 به اضافه انحراف استاندارد λ اطلاعات متقابل اقلام محاسبه می شود. در این آزمایش، آستانه شاخص پشتیبانی و آبشاری به ترتیب روی 5% و 75% تنظیم شده است و λ 1.0، 0.5، 0.0، -0.5 و -1.0 است. شکل 3 عملکرد را تحت آستانه های اطلاعاتی متقابل با مقادیر λ متفاوت نشان می دهد.
با توجه به آستانههای شاخص پشتیبان و آبشاری، هرچه آستانه اطلاعات متقابل کوچکتر باشد، آیتمهای مرتبط زوجی بیشتر، و سپس الگوهای آبشاری یک سطحی و کل بیشتر میشوند. با توجه به زمان محاسبه، برای تعیین اینکه کدام آیتم ها از جدول اقتضایی اطلاعات متقابل مرتبط هستند، تعداد تبعیض ها برای به دست آوردن موارد مرتبط ثابت است (مثلاً 25×24). بنابراین زمان محاسبه ثابت است (یعنی 15.6 میلی ثانیه) چه λ بزرگ یا کوچک باشد ( شکل 3)آ). زمان محاسبه برای یافتن الگوهای آبشاری یک سطحی و کل با تعداد اسکن های پایگاه داده (به عنوان مثال، تعداد موارد مرتبط جفت و الگوهای آبشاری نامزد) تعیین می شود. بنابراین، هرچه آستانه اطلاعات متقابل کوچکتر باشد، زمان محاسبه برای یافتن الگوهای آبشاری یک سطحی و کل بیشتر است ( شکل 3 b,c) و بالعکس. به طور مشابه، تعداد الگوهای آبشاری نامزد تعداد پیوندها و هرس ها را تعیین می کند. از این رو، هرچه آستانه اطلاعات متقابل کوچکتر باشد، زمان محاسبه پیوند و هرس بیشتر است ( شکل 3 د). اگر پایگاه داده اسکن نشود، این زمان محاسبه به میزان قابل توجهی کاهش می یابد.
4.2.2. آستانه های ارزیابی
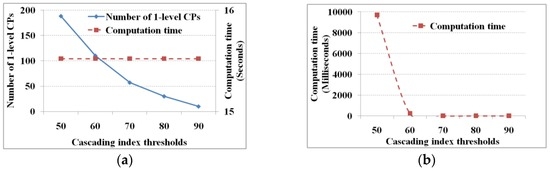
آستانه های ارزیابی شامل یک پشتیبان و یک آستانه شاخص آبشاری است که تا حد زیادی با توجه به نیازهای کاربر و دامنه تعریف می شوند. M 3 Cap شامل دو مرحله است که در آن از آستانه های ارزیابی برای یافتن الگوهای آبشاری استفاده می کند. یک مرحله الگوهای آبشاری یک سطحی را از آیتمهای مرتبط جفتی شناسایی میکند، در حالی که مرحله دیگر الگوهای آبشاری معنیداری را از همه نامزدها تولید میکند. در این آزمایش از 25 مورد در شش منطقه با 204 رکورد برای آزمایش الگوریتم استفاده شده است. ضریب مقیاس آستانه اطلاعات متقابل روی مقدار میانگین تنظیم شده است (یعنی λ = 0�=0) و آستانه شاخص حمایت و آبشاری به ترتیب 5 و 75 درصد تعیین شده است. شکل 4 و شکل 5 به ترتیب عملکرد تحت آستانه های مختلف حمایتی و شاخص آبشاری را نشان می دهند.
از شکل 4 و شکل 5، می دانیم که هرچه آستانه های ارزیابی کمتر باشد، تعداد الگوهای آبشاری بیشتر است و بالعکس، و زمان محاسبه یافتن همه الگوهای آبشاری با افزایش آستانه ها کاهش می یابد. با این حال، زمان محاسبه برای یافتن الگوهای آبشاری یک سطح ثابت است (یعنی 15.6 ثانیه) چه آستانه ها بالا یا پایین باشند. با توجه به آستانه اطلاعات متقابل، تعداد ثابتی از موارد مرتبط جفتی و زمان اسکن پایگاه داده را دریافت خواهیم کرد. از این رو، زمان محاسبه یافتن الگوهای آبشاری یک سطحی ثابت است. در مورد زمان محاسبه تابع پیوند و هرس، از نظر تئوری انتظار میرود که همراه با افزایش آستانه ارزیابی کاهش یابد. با این حال، زمانی که آستانه های ارزیابی به یک مقدار خاص می رسند (آستانه های حمایتی و شاخص آبشاری 7.5٪ و 70٪). به ترتیب) زمان محاسبه تغییر نمی کند. هنگامی که آستانه به مقدار خاص می رسد، زمان پیوند و هرس برای نشان دادن تغییرات در زمان محاسبه بسیار کوچک است. به این معنا که وقتی آستانه به مقدار مشخص شده رسید، زمان محاسبه به عنوان یک واحد محاسباتی نشان داده می شود (یعنی 15.6 میلی ثانیه در رایانه آزمایشی ما).
4.2.3. اندازه پایگاه داده
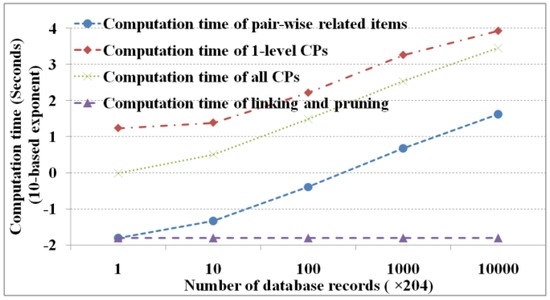
اندازه پایگاه داده شامل رکورد و شماره فیلد است. اولی تعداد نمونه ها و دومی نشان دهنده اقلام مشتق شده است. در این آزمایش آستانه شاخص پشتیبان و آبشاری به ترتیب 5 و 60 درصد تعیین شده است. λ�روی صفر تنظیم شده است. با توجه به رکوردهای پایگاه داده، 1، 10، 100، 1000 و 10000 نسخه از 204 رکورد (ژانویه 1998 تا دسامبر 2014) با 25 مورد (شش منطقه با چهار پارامتر و شاخص ENSO) از تصاویر سنجش از دور تولید شده است. همانطور که ما در حال استخراج با تکرارها هستیم، نتایج مشابهی را با 216 مورد مرتبط زوجی، 40 الگوی آبشاری یک سطحی و 97 الگوی آبشاری کل به دست میآوریم. شکل 6 عملکرد M 3 Cap را تحت اعداد رکوردهای مختلف نشان می دهد (به ترتیب، 204 × 10 0 ، 204 × 10 1 ، 204 × 10 2 ، 204 × 10 3 ، و 204 × 10 4 ، به ترتیب).
شکل 6نشان میدهد که حداکثر زمان محاسبه در یافتن الگوهای آبشاری یک سطحی، سپس در یافتن تمام الگوهای آبشاری و موارد مرتبط جفتی به ترتیب و در نهایت در پیوند و هرس رخ میدهد. زمان محاسبات عمدتاً تحت تأثیر تعداد اسکن های پایگاه داده است که با تعداد رکوردهای پایگاه داده تعیین می شود. در این آزمایش، 216 × 25 اسکن پایگاه داده برای یافتن الگوهای آبشاری یک سطحی، 105 اسکن برای یافتن همه الگوهای آبشاری، و یک اسکن برای ساخت جدول احتمالی اطلاعات متقابل و به دست آوردن موارد مرتبط زوجی وجود دارد. جدا از اثرات سوابق پایگاه داده، زمان محاسبه پیوند و هرس بدون توجه به اندازه رکورد پایگاه داده ثابت است. علاوه بر این، می دانیم که به جز پیوند و هرس، زمان محاسبه به صورت تصاعدی با افزایش تعداد رکوردهای پایگاه داده افزایش می یابد.
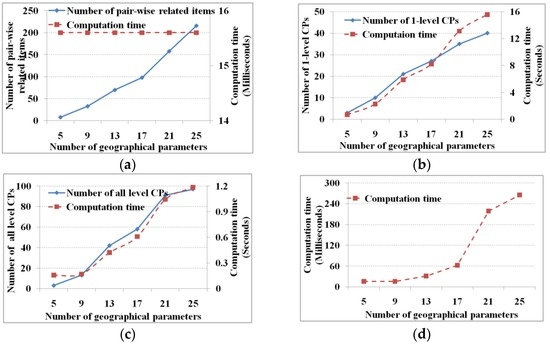
برای آزمایش عدد فیلد روی عملکرد M 3 Cap، ما چهار پارامتر دریایی را در هر منطقه (یعنی CLSObj1 تا ClSObj6 با شاخص ENSO، همانطور که در شکل 2 نشان داده شده است ) ترکیب می کنیم. بنابراین از فیلدهای 5، 9، 13، 17، 21 و 25 استفاده می شود (به عنوان مثال، پنج فیلد چهار پارامتر دریایی در منطقه CLSObj1 با شاخص ENSO هستند، نه فیلد چهار پارامتر دریایی در CLSObj1 و CLSObj2 هستند. مناطق، به ترتیب، با شاخص ENSO، و غیره). در این آزمایش آستانه شاخص پشتیبان و آبشاری به ترتیب 5 و 75 درصد تعیین شده است. λ�روی صفر تنظیم شده است. نتایج در شکل 7 نشان داده شده است .
همراه با افزایش تعداد آیتم ها، زمان بیشتری را صرف به دست آوردن تعداد بیشتر الگوهای آبشاری یک سطحی و تمام سطحی ( شکل 7 b,c) و پیوند بیشتر الگوهای آبشاری نامزد و حذف الگوهای کاذب می کنیم ( شکل 7) د). اگرچه ما آیتم های مرتبط جفت بیشتری را بدست می آوریم، زمان محاسبه تقریباً ثابت است ( شکل 7 a). دلیل آن در این است که زمان محاسبه بر زمانهای تشخیص تمرکز دارد که از 5×4، 9×8، 13×12، 17×16، 21×20 به 25×24 تغییر میکند. در مقایسه با تواناییهای محاسباتی، زمان محاسبه برای تمایز اقلام مرتبط جفتی تغییر قابل توجهی ایجاد نمی کند.
4.3. مقایسه با GSP کمی
ما از الگوی توالی تعمیم یافته، GSP [ 12 ]، به عنوان خط پایه برای مقایسه بازده الگوریتم M 3 Cap استفاده می کنیم. سه مرحله اصلی GSP عبارتند از (1) یافتن موارد 1 مکرر برای تولید الگوهای توالی یک سطحی. (2) پیوند و هرس برای تولید الگوهای نامزد. و (3) شمارش نامزدها برای یافتن الگوهای توالی معنی دار. برای برخورد با الگوهای کمی، GSP کمی از ایده اصلی GSP مشتق شده است، و به منظور مقایسه منصفانه، GSP کمی از همان استراتژی گسسته سازی، آستانه های شاخص پشتیبانی و آبشاری مانند M 3 Cap استفاده می کند .
در این آزمایش، از 25 آیتم در شش منطقه با 204 رکورد برای آزمایش الگوریتم ها استفاده شده است، ضریب مقیاس آستانه اطلاعات متقابل بر روی مقدار میانگین (یعنی، λ = 0�=0) و آستانه شاخص حمایت و آبشاری به ترتیب 5 و 75 درصد تعیین شده است. برای مقایسه واضح، هر دو GSP و M 3 Cap به سه مرحله استخراج تقسیم می شوند (یعنی محاسبه الگوهای آبشاری یک سطحی، بازگشتی پیوند و هرس، و یافتن الگوهای آبشاری معنادار). شکل 8 زمان محاسبه و نتایج آنها را نشان می دهد و جدول 5 مقایسه ای از بخش هایی از الگوهای آبشاری معنی دار استخراج شده را نشان می دهد (فقط الگوهای آبشاری با پشتیبانی نه کمتر از 00/15%).
در الگوریتم کمی GSP، محاسبه CPهای یک سطحی شامل مراحل یافتن موارد 1 مکرر و ایجاد الگوهای تداعی دو بعدی (یعنی الگوهای آبشاری یک سطحی) است، در حالی که در M 3 Cap، این شامل مراحل شناسایی است . موارد مرتبط جفتی و ایجاد الگوهای آبشاری یک سطحی. در این مرحله، M 3 Cap دو برابر سریعتر از GSP است، یعنی اولی 11.6 ثانیه طول می کشد، در حالی که دومی 22.9 ثانیه ( شکل 8 a). دلیل آن در M 3 نهفته استCap یک بار پایگاه داده را اسکن می کند تا اطلاعات متقابل اقلام را محاسبه کند، و سپس آیتم های مرتبط جفتی را تولید می کند، در حالی که GSP پایگاه داده را یک بار برای هر آیتم اسکن می کند تا مکرر یا غیرمنتظره آن را شناسایی کند، و سپس موارد مرتبط جفتی را تولید می کند. از آیتمهای مرتبط جفتی گرفته تا الگوهای آبشاری یک سطحی، هم GSP و هم M 3 Cap پایگاه داده را یکبار برای هر مورد مرتبط جفتی اسکن میکنند، با این حال، اولی با 2352 قطعه از آیتمهای مرتبط جفت سروکار دارد، در حالی که دومی این کار را انجام میدهد. 216 قطعه. در مرحله بازگشتی مرحله پیوند و هرس، هر دو GSP و M 3 Cap همه نامزدهای الگوهای آبشاری را تولید می کنند. اولی یکبار پایگاه داده را برای هر الگوی آبشاری کاندید اسکن می کند، در حالی که M 3 Cap نمی کند، بنابراین M 3Cap همه نامزدهای الگوهای آبشاری را تا دو مرتبه سریعتر از GSP محاسبه می کند. در مرحله آخر، M 3 Cap و GSP روش پردازش مشابهی برای یافتن الگوهای آبشاری معنادار با اسکن پایگاه داده یک بار برای هر نامزد دارند، بنابراین، بازده محاسباتی آنها تفاوت معنی داری ندارد.
جدول 5 نشان می دهد که نتایج استخراج شده از M 3 Cap و GSP یکسان است، با این تفاوت که GSP یک الگوی اضافی پیدا می کند، “CHLA-CLSObj1[-1] → SSTA-CLSObj1[2]، 15.00٪، 93.10٪”. دلیل آن در انتخاب آستانه اطلاعات متقابل نهفته است. اطلاعات متقابل استاندارد از CHLA-CLSObj1 تا SSTA-CLSObj1 0.100 است، در حالی که میانگین اطلاعات متقابل استاندارد برای همه موارد، آستانه اطلاعات، 0.104 است. به این معنا که نامزد “CHLA-CLSObj1 → SSTA-CLSObj1” زمانی که موارد مرتبط جفتی در مرحله اول یافت می شوند از دست می رود، بنابراین الگوریتم M 3 Cap پیدا نمی شود.
4.4. الگوهای آبشاری دریایی در اقیانوس آرام
فرض بر این است که الگوهای آبشاری در جدول 5 معنادار هستند (مناسب با حداقل حمایت و آستانه های شاخص آبشاری)، برخی از روابط متقابل شناخته شده در اقیانوس آرام به دست آمده اند: تغییرات SSTA، SLAA، یا تغییرات مشترک بین SSTA و SLAA عمدتاً عبارتند از تحت سلطه ENSO، نوسان دهگانه اقیانوس آرام، و الگوهای اقیانوس آرام-آمریکای شمالی، بنابراین، SSTA و SLAA بیشتر از سایر پارامترهای محیطی دریایی (شماره 2 تا شماره 12) مرتبط هستند [33 ]]. هنگامی که رویدادهای لانینا رخ می دهد، راسبی به سمت غرب به اقیانوس آرام مرکزی می رسد، که حوضچه گرم در سطح را به سمت غرب می راند. در همان زمان، جریان شمالی اقیانوس آرام به سمت شرق از وسط اقیانوس آرام نیمه گرمسیری شمالی می گذرد و در نتیجه میانگین SST افزایش می یابد. بنابراین، SSTA در مناطق CLSObj2، CLSObj3 و CLSObj4 پاسخی به یک رویداد La Niña (شماره 13 تا شماره 15) است [ 2]]. علاوه بر این، ما همچنین میتوانیم اطلاعات کمی بیشتر را در بین پارامترهای محیطی دریایی تشخیص دهیم و الگوهای کمتر شناخته شده را از پارامترهای محیطی دریایی متعدد، مانند شماره 16 شناسایی کنیم، به این معنی که کاهش غیرعادی SSTA در منطقه CLSObj4 ممکن است پاسخی به یک رویداد لا نینا از الگوهای آبشاری دو سطحی به سطح بیشتر (شماره 17 تا شماره 30) روابطی به ترتیب در مناطق مختلف پیدا می کنیم. چنین الگوهایی ممکن است برای دانشمندان زمین جدید باشد.
5. بحث و نتیجه گیری
این مقاله یک الگوریتم جدید – M 3 Cap – برای استخراج الگوهای آبشاری پیشنهاد میکند و الگوریتم را با استفاده از مجموعه دادههای تصویر سنجش از دور آزمایش میکند. M 3 Cap با جستجو در اطلاعات متقابل برای استخراج موارد مرتبط اولیه به صورت جفت و با استفاده از یک پیوند بازگشتی و عملکرد هرس بدون اسکن پایگاه داده، تعداد اسکن های پایگاه داده را به میزان قابل توجهی کاهش می دهد و کارایی محاسباتی را بهبود می بخشد.
اگرچه M 3 Cap پیشنهادی ما دارای یک گردش کاری مشابه با MIQarma [ 24 ] پیشنهادی قبلی است، اما این دو رویکرد اساسا متفاوت هستند. M 3 Cap بر روی ویژگی های آبشاری تمرکز می کند، در حالی که MIQarma با ویژگی های ارتباطی سر و کار دارد. از این رو، آنها در موضوع کلیدی پیوند و هرس متفاوت هستند. بدون اسکن پایگاه داده در طول پیوند و هرس، کارایی M 3 Cap افزایش می یابد. علاوه بر این، ایده اصلی M 3 Cap بر اساس GSP کمی [ 12 ] است، اما این دو الگوریتم در استخراج، پیوند و هرس، و شاخصهای ارزیابی اولیه به صورت جفتی (دو موردی مکرر) متفاوت هستند.
تجزیه و تحلیل پیچیدگی محاسباتی نشان می دهد که M 3 Cap شامل چهار مرحله است – استخراج موارد مرتبط به صورت جفتی، پیوندهای بازگشتی و هرس برای به دست آوردن همه الگوهای آبشاری نامزد، استخراج الگوهای آبشاری یک سطحی، و تولید الگوهای آبشاری معنادار. دو مرحله اول شامل محاسبات فشرده است و به تعداد موارد مشتق شده و به پیوند و هرس بستگی دارد. دو مورد دیگر به تعداد اسکن پایگاه داده و زمان اسکن یکبار پایگاه داده بستگی دارد. از نظر تئوری، مرحله دوم شامل پیچیده ترین محاسبات فشرده است. با این حال، بدون اسکن پایگاه داده، پیچیدگی محاسباتی آن ساده ترین است.
با توجه به زمان اسکن پایگاه داده، آستانه اطلاعات متقابل یکی از مهمترین عوامل است. با توجه به تعداد آیتمهای مشتقشده، آستانه اطلاعات متقابل کوچکتر منجر به موارد مرتبط اولیهتر زوجی و اسکنهای بیشتر پایگاه داده میشود و بالعکس. بنابراین، مسئله کلیدی تعیین آستانه اطلاعات متقابل است. M 3 Cap میانگین و انحراف استاندارد اطلاعات متقابل اقلام را ترکیب می کند که معمولاً برای آشکار کردن موارد بسیار مرتبط استفاده می شود [ 21]]. علاوه بر این، بسیاری از آزمایشها نشان میدهند که وقتی یک آستانه اطلاعات متقابل بین مقدار میانگین با تفریق یک انحراف استاندارد و مقدار میانگین با افزودن یک انحراف استاندارد باشد (یعنی یک ضریب اسکالر بین 1- و 1 باشد)، ما تقریبی به دست خواهیم آورد. الگوهای آبشاری به عنوان الگوریتم های استخراج معمولی. علاوه بر این، آستانه های ارزیابی، یک آستانه پشتیبانی و یک شاخص آبشاری، بر تعداد اسکن های پایگاه داده تأثیر می گذارد. هرچه شاخص های ارزیابی کوچکتر باشد، الگوهای آبشاری یک سطحی بیشتر، سپس الگوهای سطح دیگر بیشتر، سپس زمان اسکن پایگاه داده بیشتر می شود و بالعکس. در این مقاله آستانه های ارزیابی با توجه به نیاز و دامنه کاربران تعریف شده است. آزمایشها با مجموعه دادههای تصویر سنجش از دور نشان داد که زمان محاسبات اسکن پایگاهداده یک بار عمدتاً تحت سلطه تعداد رکوردهای پایگاه داده است. تعداد بیشتری از رکوردهای پایگاه داده منجر به زمان محاسباتی بیشتر برای اسکن پایگاه داده می شود. با این حال، زمان محاسبه پیوند و هرس با آستانه های مختلف، نشان داده شده استشکل 4 ج و شکل 5 ب، با تحلیل نظری تناقض دارند. از نظر تئوری، با افزایش آستانه ارزیابی، الگوهای آبشاری نامزد کاهش مییابد و زمان پیوند و هرس همراه با زمان محاسبه کاهش مییابد. با این حال، زمانی که آستانه حمایت و شاخص آبشاری به ترتیب به 7.5% و 70% میرسند، زمانهای محاسبه آنها کاهش نمییابد زیرا زمان پیوند و هرس برای نشان دادن تغییرات در زمان محاسبه بسیار کوتاه است. به طور مشابه، با توجه به آستانه اطلاعات متقابل، هرچه اقلام مشتق شده بیشتر باشد، معیار تمایز بیشتر برای به دست آوردن موارد مرتبط زوجی اعمال می شود و زمان محاسبات بیشتری مورد نیاز است. با این حال، مانند شکل 7 ، زمان محاسبه تغییر نمی کندیک نشان می دهد. تعداد اقلام مشتق شده از 5 به 25 تغییر می کند و تعداد کاربردهای معیار تبعیض به ترتیب از 5 × 4 به 25 × 24 تغییر می کند. زمان معیار تبعیض محدود برای نشان دادن تغییرات در زمان محاسبه کافی نیست.
به طور خلاصه، در مواجهه با چالش یافتن ویژگیهای آبشاری، روش M 3 Cap را پیشنهاد کردیم و آن را با استفاده از مجموعه دادههای تصویر سنجش از دور واقعی آزمایش کردیم. نتایج اصلی مطالعه ما به شرح زیر است:
-
ما گردش کار M 3 Cap را طراحی کردیم و پیچیدگی های محاسباتی M 3 Cap را با جذب اطلاعات متقابل مورد بحث قرار دادیم. با توجه به دو دسته پیچیدگی – محاسبات فشرده و اسکن پایگاه داده – چهار مرحله کلیدی ارائه شد.
-
دو مرحله بر محاسبات فشرده مسلط هستند، به دست آوردن موارد مرتبط زوجی از یک جدول احتمالی اطلاعات متقابل با توجه به معیار تمایز، که بر تعداد موارد مشتق شده غالب است، و تولید همه الگوهای آبشاری نامزد از الگوهای یک سطحی با پیوند بازگشتی. و هرس بدون اسکن پایگاه داده پیچیدگی محاسباتی را به میزان قابل توجهی کاهش می دهد.
-
آستانه های اطلاعات و ارزیابی متقابل و اندازه پایگاه داده عوامل اصلی تأثیرگذار بر تعداد اسکن پایگاه داده هستند. آستانه اطلاعات متقابل عمدتاً بر اقلام مرتبط با جفت اولیه تسلط دارد و به طور غیرمستقیم بر تعداد الگوهای آبشاری نامزد تأثیر می گذارد. آستانه ارزیابی بر زمان یافتن الگوهای آبشاری معنادار غالب است. تعداد فیلدهای پایگاه داده (یعنی تعداد آیتم های مشتق شده) نیز بر آیتم های اولیه مرتبط با جفت، سپس الگوهای یک سطحی و تمام آبشاری تأثیر می گذارد و تعداد رکوردهای پایگاه داده بر زمان اسکن پایگاه داده یک بار غالب است.
-
آزمایشهایی با مجموعه دادههای تصویر سنجش از دور واقعی که اقیانوس آرام را پوشش میدهند برای نشان دادن امکانسنجی و کارایی M 3 Cap انجام شد.





بدون نظر