1. معرفی
حجم عظیمی از دادههای مکانی با سرعتهای فزایندهای سریعتر و وضوحهای مکانی-زمانی بالاتر با پیشرفت سنسورهای رصد زمین جمعآوری میشوند [ 1 ]. پردازش کارآمد داده های بزرگ جغرافیایی برای مقابله با چالش های جهانی و منطقه ای مانند تغییرات آب و هوا و بلایای طبیعی ضروری است [ 2 ، 3 ]. برای مثال، پشتیبانی تصمیمگیری برای واکنش اضطراری، تنها زمانی میتواند به بهترین شکل انجام شود که یکپارچهسازی و پردازش مقدار زیادی از دادههای مکانی به موقع انجام شود، زیرا یک ثانیه هشدار اولیه یا هشدار ممکن است به نجات جان افراد بیشتری کمک کند [4 ، 5 ] .
با این حال، پردازش کارآمد دادههای بزرگ مکانی چالش برانگیز است نه تنها به دلیل حجم عظیم دادهها، بلکه به دلیل پیچیدگی ذاتی و ابعاد بالای مجموعه دادههای مکانی [ 6 ]. به عنوان مثال، تجزیه و تحلیل روندهای اقلیمی اغلب نیاز به تجمیع اطلاعات (صدها متغیر اقلیمی) از ترابایت داده های آب و هوایی چهار بعدی صدها سال دارد [7 ] . اگر چنین تحلیلی با استفاده از یک کامپیوتر انجام شود، معمولاً ساعت ها یا حتی روزها طول می کشد. درون یابی DEM (مدل ارتفاعی دیجیتال) نمونه خوبی دیگر از تجزیه و تحلیل جغرافیایی محاسباتی فشرده و زمان بر است که با زیرساخت های محاسباتی سنتی مقیاس خوبی ندارد [ 8 ].
برای سرعت بخشیدن به پردازش داده های مکانی، زیرساخت های محاسباتی توزیع شده به طور گسترده استفاده می شود. Hadoop، یک پلت فرم محاسباتی توزیعشده که از رایانههای کالایی استفاده میکند، همانطور که در بخش 2 بررسی شد، در جوامع علوم زمین محبوبیت فزایندهای به دست میآورد . در حالی که تلاش زیادی برای بررسی چگونگی تطبیق Hadoop برای پردازش دادههای بزرگ مکانی انجام شد (به عنوان مثال، [ 9 ، 10 ، 11 ، 12 ، 13])، چگونگی مدیریت کارآمد بار کاری پردازش جغرافیایی مختلف با تنظیم پویا مقدار منابع محاسباتی (تعداد گرههای یک خوشه Hadoop) به سختی مورد بررسی قرار گرفت. توانایی تنظیم پویا منابع محاسباتی مهم است زیرا حجم کار پردازش برنامههای مکانی عملیاتی نسبتاً پویا است تا ایستا [ 14 ]. به عنوان مثال، حجم کار پردازش داده برای یک سیستم واکنش اضطراری (مانند آتشسوزیها، سونامی و زلزلهها) در طول رویداد اضطراری به اوج خود میرسد، که نیاز به قدرت محاسباتی کافی برای واکنش سریع دارد [14 ، 15 ]]. مثال دیگر این است که برنامههای کاربردی/سرویسهای وب جغرافیایی (مانند یک سیستم تحلیلی آنلاین برای تجزیه و تحلیل دادههای آب و هوایی تعاملی) اغلب به دلیل الگوهای دسترسی کاربر پویا به پردازشهای مختلف نیاز دارند [16 ، 17 ] .
یکی از راهحلهای سنتی برای مدیریت حجم کاری پردازش پویا این است که سیستم را با منابع محاسباتی «کافی» برای مدیریت اوج بار کاری پیکربندی کنید. با این حال، این مشکل ساز است، زیرا اولاً، تخمین تعداد منابع محاسباتی «کافی» دشوار است. ثانیاً، حتی اگر میتوانیم منابع محاسباتی کافی برای مدیریت اوج بار کاری فراهم کنیم، این یک اتلاف منابع بزرگ خواهد بود، زیرا سطوح استفاده از منابع محاسباتی اغلب به طور متوسط بسیار پایین است و تنها در یک دوره محدود به اوج خود میرسد. بنابراین، یک سوال مهم باز باقی می ماند: چگونه می توان به طور خودکار منابع محاسباتی را بر اساس بار کاری پویا تنظیم کرد تا پردازش و تجزیه و تحلیل جغرافیایی به موقع به پایان برسد و در عین حال مصرف منابع (هزینه) به حداقل برسد؟
برای مقابله با این موضوع، ما یک چارچوب مبتنی بر عملکرد و آگاهی از هزینه را پیشنهاد میکنیم تا به طور خودکار منابع محاسباتی یک خوشه Hadoop را بر اساس حجم کاری پردازش جغرافیایی پویا در یک محیط ابری مقیاسبندی کند. مشارکتهای این تحقیق عبارت بودند از: (1) یک ساختار ذخیرهسازی جدید برای فعال کردن حذف به موقع منابع محاسباتی بدون تحمیل انتقال داده اضافی، و (2) یک الگوریتم مقیاسبندی خودکار پیشبینیکننده برای محاسبه دقیقتر مقدار منابع محاسباتی برای افزودن ایجاد شد. . چارچوب امکان سنجی و کارایی با یک سیستم نمونه اولیه با استفاده از درونیابی DEM به عنوان مثال مورد ارزیابی قرار گرفت. نتایج تجربی نشان میدهد که سیستم نمونه اولیه قادر است با اضافه کردن و حذف خودکار منابع محاسباتی در صورت نیاز، به طور مؤثری حجم کاری پردازش پویا را مدیریت کند.
این مقاله تحقیق را به روش زیر گزارش میکند: بخش 2 کار مرتبط را مرور میکند. بخش 3 روش های مورد استفاده در چارچوب مقیاس بندی خودکار پیشنهادی را شرح می دهد. بخش 4 امکان سنجی و کارایی چارچوب مقیاس خودکار را با استفاده از درون یابی DEM به عنوان مثال آزمایش می کند و بخش 5 مقاله را به پایان می رساند.
2. کارهای مرتبط
2.1. Hadoop برای پردازش داده های مکانی
استفاده از تعداد زیادی کامپیوتر و تجمیع منابع محاسباتی برای ذخیره سازی داده ها به طور گسترده ای مورد استفاده قرار گرفته است تا اطمینان حاصل شود که داده ها در یک بازه زمانی سریع پردازش می شوند [ 18 ]. به عنوان یک پیادهسازی منبع باز چارچوب MapReduce [ 19 ]، Hadoop در طول سالهای گذشته در عصر Big Data محبوبیت فزایندهای پیدا کرده است [ 20 ]. در همین حال، مطالعات زیادی برای استفاده از Hadoop برای پردازش دادههای مکانی انجام شده است. به عنوان مثال، گائو و همکاران. Hadoop را برای ساختن روزنامهها از دادههای بزرگ زمینفضایی داوطلبانه تطبیق داد [ 12 ]. لین و همکاران از Hadoop برای ذخیره و پردازش تصاویر سنجش از راه دور عظیم برای پشتیبانی از درخواستهای همزمان بزرگ کاربران استفاده کرد [ 21]. کریشنان و همکاران استفاده از MapReduce برای تولید DEM با شبکه بندی داده های LIDAR [ 22 ] را بررسی کرد. لی و همکاران از Hadoop MapReduce برای فعال کردن جریمه پردازش داده های آب و هوایی بزرگ استفاده کرد [ 11 ، 13 ]. علاوه بر این رویکردهای مشکل خاص که بر حل مشکلات خاص با Hadoop تمرکز می کنند، ابزارهایی نیز برای رسیدگی به وظایف پردازش داده های جغرافیایی عمومی توسعه یافته اند و در جوامع GIScience پذیرفته می شوند. به عنوان مثال، SpatialHadoop، یک افزونه منبع باز Hadoop، برای پردازش مجموعه داده های جغرافیایی عظیم [ 10 ] طراحی شده است. به طور مشابه، HadoopGIS یک سیستم جستجوی فضایی مقیاسپذیر و با کارایی بالا را بر روی MapReduce برای تسریع تجزیه و تحلیل دادههای مکانی ارائه میکند [ 23]]. در حالی که این مطالعات یک تجربه و دستورالعمل ارزشمند در مورد چگونگی انطباق Hadoop برای پردازش دادههای مکانی بزرگ ارائه میکنند، نحوه تنظیم اندازه خوشه محاسباتی برای مدیریت کارآمد بارهای کاری مختلف ژئوپردازش کاوش نشده است.
یک خوشه محاسباتی با اندازه ثابت دارای اشکالات آشکاری با توجه به حجم کاری پویا برای کاربردهای مکانی عملی است. اولاً، نه انرژی است و نه مقرون به صرفه، زیرا منابع محاسباتی به طور کامل زمانی که حجم کار کم است استفاده نمی شود. دوم، زمانی که حجم کار از ظرفیت محاسباتی بیشتر شود، عملکرد کاهش می یابد. برای مقابله با این مسائل، به عنوان مثال، لوریچ و همکاران، راهبردی را پیشنهاد کردند که به خوشه اجازه میدهد تا زمانی که حجم کار کم است، کاهش یابد تا کارایی انرژی بهبود یابد [ 24 ]. روش دیگر برای کوچک کردن خوشه Hadoop GreenHDFS [ 25] است]، که دارای طرح چند منطقه ای مناطق سرد و گرم است. رویکردهای فوق بر حذف گره های خوشه ای تمرکز دارند، اما اتوماسیون برای عملیات مقیاس بندی به سختی مورد توجه قرار می گیرد. ماهشواری و همکاران با هدف دستیابی به اتوماسیون. یک الگوریتم قرار دادن داده های پویا و پیکربندی مجدد خوشه را برای خاموش یا روشن کردن گره های خوشه ای بر اساس میانگین نرخ استفاده از خوشه پیشنهاد کرد [ 26]]. با این حال، لازم است بلوک های داده ذخیره شده در یک گره قبل از حذف گره به گره های دیگر منتقل شوند. چنین فرآیندی نه تنها وقت گیر است، بلکه مقدار قابل توجهی از منابع شبکه را نیز مصرف می کند، به خصوص زمانی که داده هایی که قرار است انتقال داده شوند، زیاد باشد. علاوه بر این، موضوع دوم به دلیل محدودیت منابع فیزیکی تا حدی حل نشده است (خرید و اضافه کردن یک کامپیوتر فیزیکی به خوشه معمولاً به روزها و هفته ها نیاز دارد).
2.2. مقیاس خودکار Hadoop در ابر
رایانش ابری یک الگوی محاسباتی جدید با ویژگی های سلف سرویس، در دسترس بودن، مقیاس پذیری و هزینه اندازه گیری شده است [ 27 ]. رایانش ابری یک راه حل بالقوه برای رسیدگی به چالشهای خوشهای با اندازه ثابت ارائه میکند، زیرا میتوان یک خوشه مجازی Hadoop را در چند دقیقه تهیه کرد. ارائه دهندگان ابر عمومی معمولاً خوشههای Hadoop را به عنوان خدمات وب ارائه میکنند که به کاربران اجازه میدهند تا خوشه را از طریق یک رابط مبتنی بر وب پیکربندی، تهیه و خاتمه دهند. به عنوان مثال، Amazon Elastic MapReduce (EMR) [ 28 ] و Window Azure HDInsight [ 29]] سرویس های Hadoop مبتنی بر ابر محبوب هستند که کاربران را قادر می سازد تا به سرعت یک خوشه Hadoop را برای پردازش حجم زیادی از داده ها فراهم کنند. پس از اتمام کار، کاربران می توانند خوشه را خاتمه دهند و خوشه دیگری را برای کار دیگری راه اندازی کنند. با این حال، یک مشکل حیاتی در این سرویس های Hadoop وجود دارد: اندازه خوشه را نمی توان به طور خودکار بر اساس حجم کاری پویا تنظیم کرد (به عنوان مثال، بسیاری از مشاغل در مدت زمان کوتاهی به همان خوشه ارسال می شوند). حتی اگر برخی از سرویسها مانند آمازون EMR مکانیسمهایی را ارائه میدهند که به کاربران اجازه میدهد اندازه خوشه را تغییر دهند، که باید به صورت دستی انجام شود، و بار تصمیمگیری درباره تعداد ماشینهایی که باید حذف یا اضافه شوند بر عهده کاربران غیرمتخصص اداری گذاشته میشود. 30 ].
از آنجایی که محاسبات ابری و Hadoop به طور فزاینده ای در پرداختن به داده های بزرگ و مشکلات محاسباتی در حوزه های مکانی (به عنوان مثال، [ 31 ، 32 ، 33 ، 34 ]) پذیرفته می شوند، چگونگی بهینه سازی منابع محاسباتی اختصاص داده شده با در نظر گرفتن حجم کاری ژئوپردازش پویا مستحق بررسی است. با این حال، تحقیقات کمی برای مطالعه مقیاس بندی پویا یک خوشه Hadoop در محیط های ابری وجود دارد. رومر یک مقیاس بندی مبتنی بر آستانه را پیشنهاد کرد تا به طور خودکار گره های بیشتری را بر اساس معیارهای عملکرد جعبه سیاه (CPU و RAM) و مقادیر آستانه از پیش تعریف شده به خوشه اضافه کند [ 35] .]. این مقیاسبندی ماشینهای مجازی جدیدی را زمانی که میانگین بار کلاستر از یک آستانه فراتر رود، فراهم میکند و سپس به طور خودکار این ماشینها را در خوشه پیکربندی میکند. با این حال، افزایش مقیاس بر اساس حجم کاری فعلی آغاز می شود. این مشکل ساز است زیرا افزایش مقیاس برای تهیه ماشین های مجازی جدید و پیکربندی آنها در خوشه زمان می برد (بسته به پلت فرم ابری از چند دقیقه تا ساعت). برای مثال، ممکن است 10 دقیقه طول بکشد تا یک ماشین مجازی (VM) در Elastic Compute Cloud آمازون (Amazon EC2) فراهم شود و این VM به یک خوشه اضافه شود. این احتمال وجود دارد که حجم کار در این دوره زمانی تغییر کرده باشد (مثلاً ماشین های مجازی اضافه شده جدید دیگر مورد نیاز نیستند یا ماشین های مجازی بیشتری مورد نیاز هستند). علاوه بر این، برای کاهش مقیاس، رومر پیشنهاد کرد که گره ها را به صورت دستی خاتمه دهید. برای مقابله با این موضوع،بخش 3.3 ). اخیراً، گاندی و همکاران. یک راهحل مقیاسپذیری خودکار مبتنی بر مدل برای خوشههای Hadoop با برآورد منابع دینامیک مورد نیاز یک کار Hadoop برای زمان اجرای معین SLA (توافق سطح سرویس) [ 36 ] ارائه کرد. با این حال، برای حذف پویا یک گره برده، داده های ذخیره شده در این گره باید قبل از حذف به گره های دیگر منتقل شوند. چنین فرآیند انتقال داده بسته به حجم داده ها ممکن است ده ها دقیقه یا ساعت طول بکشد، که گرفتن به موقع و پاسخ به حجم کاری پویا را دشوار می کند. برای پرداختن به این موضوع، ما مکانیزم CoveringHDFS را همانطور که در بخش 3.2 توضیح داده شده است، پیشنهاد می کنیم .
3. روش ها
3.1. چارچوب مقیاس بندی خودکار
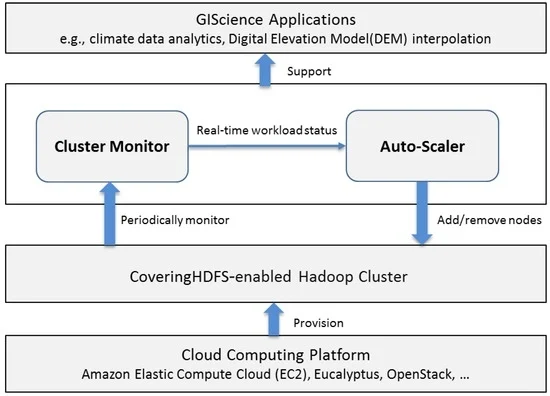
هدف این چارچوب تنظیم پویا منابع محاسباتی (اندازه خوشه) بر اساس حجم کار پردازشی برای رسیدگی به نیاز به افزایش قدرت محاسباتی (مثلاً برای پشتیبانی از پاسخ به فاجعه) و در عین حال به حداقل رساندن مصرف منابع (در طول دوره زمانی کم بار کاری) است. شکل 1 معماری چارچوب را نشان می دهد که شامل اجزای زیر است: پلت فرم محاسبات ابری، خوشه Hadoop دارای قابلیت CoveringHDFS، مقیاس خودکار و مانیتور کلاستر.
پلت فرم محاسبات ابری منابع محاسباتی بر اساس تقاضا (ماشین های مجازی) را برای چارچوب فراهم می کند. پلت فرم ابری می تواند یک ابر عمومی (به عنوان مثال، آمازون EC2 و مایکروسافت آزور) یا پلت فرم ابر خصوصی (به عنوان مثال، ابر اکالیپتوس و OpenStack) باشد.
CoveringHDFS-enabled Hadoop cluster یک خوشه محاسباتی مجازی متشکل از تعدادی ماشین مجازی است که توسط پلتفرم ابری ارائه شده است. این خوشه وظیفه ذخیره و پردازش داده های مکانی را بر عهده دارد. CoveringHDFS (به تفصیل در بخش 3.2 ) خوشه را قادر میسازد تا به سرعت در صورت نیاز، بزرگتر و پایینتر شود.
Cluster Monitor راهبر چارچوب مقیاس خودکار است و به طور مداوم اطلاعات بار کاری بلادرنگ را از خوشه Hadoop با استفاده از Hadoop API (رابط برنامه نویسی برنامه)، از جمله کارهای در حال اجرا/در انتظار، اجرای نقشه/کاهش وظایف و در انتظار جمع آوری می کند. نقشه/کاهش وظایف
Auto-Scaler به صورت پویا منابع محاسباتی را با استفاده از API پلتفرم ابری (مثلاً Amazon EC2 API) بر اساس حجم کاری بلادرنگ ارائه شده توسط Cluster Monitor اضافه یا حذف می کند . اگر حجم کار فعلی از توان پردازشی خوشه بیشتر شود، منابع محاسباتی (ماشین های مجازی) بیشتری به خوشه اضافه می شود. وقتی حجم کار نسبتاً کم است، ماشینهای مجازی بیکار خاتمه مییابند. هسته مقیاس خودکار یک الگوریتم مقیاسبندی خودکار پیشبینیکننده (به تفصیل در بخش 3.3 ) است که تعیین میکند چه زمانی عملیات مقیاسگذاری را آغاز کند و تخمین میزند که چه تعداد از منابع محاسباتی باید مقیاس شوند.
3.2. پوشش HDFS
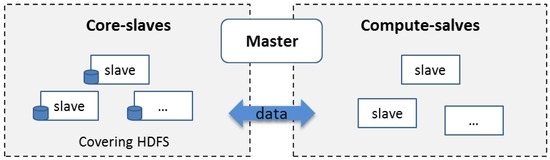
به طور پیش فرض، یک خوشه Hadoop از سیستم فایل توزیع شده Hadoop (HDFS, [ 37) استفاده می کند.]) برای ذخیره داده ها. دادههای روی HDFS در تمام گرههای داده (گرههایی که هم ظرفیت ذخیرهسازی و هم محاسبات را فراهم میکنند) توزیع میشوند تا محاسبات محلی داده را فعال کنند. در حالی که این استراتژی ذخیرهسازی انتقال دادهها را در میان گرههای خوشه به حداقل میرساند، کوچکسازی خوشهها دشوار است زیرا خاموش کردن یک گره خطر از دست دادن دادهها را به همراه دارد. Hadoop یک عملکرد داخلی به نام “decommission” برای حذف ایمن یک گره از HDFS با انتقال تمام بلوک های داده از این گره به گره های دیگر قبل از حذف آن از خوشه ارائه می دهد. زمان صرف شده در از کار انداختن به اندازه داده ای که باید منتقل شود (یعنی دقیقه، ساعت، روز) بستگی دارد، که برای یک چارچوب مقیاس خودکار کارآمد طراحی شده برای ضبط به موقع و پاسخ به حجم کاری پویا غیرقابل تحمل است.
برای مقابله با این مشکل، مکانیسم CoveringHDFS را معرفی میکنیم تا خوشه را بهطور ایمن و به موقع بدون از دست دادن دادهها با الهام از مفهوم زیر مجموعه پوششی پیشنهاد شده در [ 24 ] کاهش دهیم. بر خلاف [ 24 ]، به جای اصلاح نرمافزار زیربنایی Hadoop، دادهها را مستقیماً در زیرمجموعهای از گرههای برده ذخیره میکنیم که HDFS روی آنها مستقر شده است. گره های متشکل از CoveringHDFS را core-slave می نامند و سایر گره ها را compute-slave می نامند . Core-slave ها هم قدرت ذخیره سازی و هم قدرت محاسباتی را فراهم می کنند، در حالی که compute-slave فقط قدرت محاسباتی را ارائه می دهند. بنابراین، چنین خوشه محاسباتی مبتنی بر ابر از سه جزء تشکیل شده است: گره اصلی، بردهای هسته، و بردهای محاسباتی ( شکل 2).) و می تواند سه حالت داشته باشد: FullMode ، شامل core-slaves، compute-slaves و master. CoreMode ، شامل core-slave و master. و TerminateMode ، کل خوشه خاتمه می یابد.
با ادغام CoveringHDFS در یک خوشه، وقتی حجم کار کم است، میتوان با راهاندازی یک عملیات کاهش مقیاس، بردهای محاسباتی غیرفعال را حذف کرد. در این طراحی، Compute-Slave مزیت محلی بودن داده را هنگام پردازش داده ها از دست می دهند، اما منابع محاسباتی درخواستی را ارائه می دهند. مبادله بین محلی بودن داده و توان محاسباتی در بخش 4 با نتیجه آزمایش مورد بحث قرار گرفته است.
3.3. الگوریتم مقیاس بندی خودکار
الگوریتم مقیاس خودکار زمانی که بار کاری از توان محاسباتی یک خوشه فراتر رود (مثلاً کارها در انتظار اجرا هستند) بردهای محاسباتی را اضافه می کند و زمانی که بار کاری کم است، بردهای محاسباتی بیکار را آزاد می کند.
3.3.1. افزایش مقیاس
یک کار MapReduce معمولاً شامل بسیاری از وظایف نقشه و یک یا چند کار کاهش است. هر گره برده در خوشه Hadoop دارای حداکثر ظرفیت پردازش نقشه/کاهش وظایف به صورت موازی است که به طور معمول با تعداد هسته های پردازنده و اندازه حافظه Slave تعیین می شود. فرض کنید هر برده می تواند n وظیفه نقشه همزمان و m را کاهش دهد، می توانیم فکر کنیم که هر برده دارای n اسلات نقشه و m اسلات کاهش است. اگر مقدار وظایف نقشه (بار کاری) از اسلات های نقشه (ظرفیت خوشه) بیشتر باشد، وظایف نقشه بیش از حد باید منتظر بمانند تا شکاف های نقشه رایگان در دسترس باشند که عملکرد را مختل می کند. کلید افزایش مقیاس مکانیزم این است که تخمین بزنیم زمانی که حجم کار از ظرفیت خوشه فراتر رود، به چه تعداد منبع محاسباتی اضافی (بردهای محاسباتی) نیاز است.
فرض کنید در هر لحظه ده کار نقشه معلق وجود دارد [ خطای پردازش ریاضی ]تی�، و اینکه هر برده جدید اضافه شده دو اسلات نقشه را افزایش می دهد. یک راه حل ساده این است که پنج برده اضافه کنید تا هر کار معلق توسط یک اسلات نقشه انجام شود. با این حال، افزودن پنج برده را نمی توان فوراً انجام داد. برای مثال، تهیه یک نمونه متوسط آمازون EC2 با سیستم عامل لینوکس تقریباً پنج دقیقه طول می کشد (تا زمانی که نمونه برای اتصال آماده شود). در این حالت، زمانی که پنج برده اضافه میشوند، ممکن است نقشههای معلقی وجود نداشته باشد، بنابراین اگر کار دیگری ارسال نشود، بردههای تازه اضافهشده هیچ عملکردی ندارند. بنابراین، زمان صرف شده برای فرآیند مقیاسپذیری ( [ خطای پردازش ریاضی ]تین، زمان مورد نیاز است به اضافه کردن ن بردگان) باید در نظر گرفته شود تا تعداد صحیحی از بردها برای اضافه کردن تخمین زده شود. برای این منظور، ما یک الگوریتم مقیاسبندی پیشبینیکننده برای تخمین حجم کار در آن زمان معرفی میکنیم. [ خطای پردازش ریاضی ]تی�+ [ خطای پردازش ریاضی ]تینزمانی که فرآیند بزرگسازی به پایان رسید. تعداد بردهایی که باید اضافه شوند (با N نشان داده می شوند ) با استفاده از رابطه (1) به صورت محاسبه می شود.
جایی که [ خطای پردازش ریاضی ]نپه�دمن��تعداد کارهای معلق در است [ خطای پردازش ریاضی ]تی�، [ خطای پردازش ریاضی ]ن�من�منسساعتهدتعداد وظایف نقشه معلقی است که پس از انجام فرآیند بزرگسازی به پایان میرسند یا اجرا میشوند، و n تعداد شکافهای نقشه برای هر برده اضافهشده است.
فرض کنید افزایش مقیاس N گره به خوشه طول می کشد [ خطای پردازش ریاضی ]تیندقایق. این [ خطای پردازش ریاضی ]ن�من�منسساعتهدبه صورت زیر تخمین زده می شود: برای لیستی از اسلات های پردازش ( [ خطای پردازش ریاضی ]نسل�تی) و صف وظایف با N وظایف نقشه، هر شکاف قدرت پردازش یکسانی دارد، اما هر کار ممکن است به زمان متفاوتی نیاز داشته باشد (مثلاً انواع کار). درحال حاضر [ خطای پردازش ریاضی ]تی�، هر شکاف وظیفه ای را با پیشرفت p پردازش می کند . وظایف انتظار بر اساس اصل اولین خدمت اولیه پردازش می شوند. هنگامی که یک اسلات وظیفه فعلی خود را به پایان رساند، یک کار جدید از لیست انتظار کار واکشی می شود. این روند تا زمانی تکرار می شود که زمان صرف شده برای هر شکاف تمام شود [ خطای پردازش ریاضی ]تین.
بر اساس این مدل، تعداد کارهای معلقی که در طول بازه زمانی تمام شده یا در حال اجرا هستند [ خطای پردازش ریاضی ]تینبرابر است با تعداد کارهای نقشه که در هر شکاف به پایان رسیده است [ خطای پردازش ریاضی ]تینکه به صورت زیر قابل محاسبه است:
جایی که [ خطای پردازش ریاضی ]نسل�تیتعداد اسلات های نقشه برای خوشه فعلی است، [ خطای پردازش ریاضی ]تی�همترآمن�� زمان باقی مانده در بازه زمانی است [ خطای پردازش ریاضی ]تین هنگامی که یک گره وظایف j را به پایان رساند (از لحظه شمارش می شود [ خطای پردازش ریاضی ]تی�) [ خطای پردازش ریاضی ]تیمن�زمان مورد نیاز برای اتمام کار j امین نقشه در شکاف i است ( [ خطای پردازش ریاضی ]تیمن�برای انواع مشاغل متفاوت است) [ خطای پردازش ریاضی ]پمنپیشرفت کار نقشه در حال اجرا در شکاف i در است[ خطای پردازش ریاضی ]تی�( [ خطای پردازش ریاضی ]0≤پمن≤1) و [ خطای پردازش ریاضی ]تینزمان صرف شده برای افزایش مقیاس N گره است که به پلت فرم ابر و تعداد گره هایی که باید مقیاس شوند بستگی دارد.
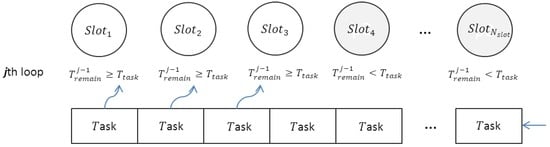
شکل 3 نمونه ای از یک نقطه زمانی خاص (یعنی حلقه j ام) از معادله (1) است. در حلقه j ، سه اسلات اول هنوز قابلیت پذیرش وظایف نقشه جدید در طول دوره زمانی را دارند. [ خطای پردازش ریاضی ]تین، در حالی که اسلات های باقی مانده نمی توانند وظایف جدید را بپذیرند. بعد از هر حلقه، اسلات ها بر اساس مرتب سازی می شوند [ خطای پردازش ریاضی ]تی�همترآمن�به ترتیب نزولی
در معادلات (1) و (2) [ خطای پردازش ریاضی ]نسل�تی، [ خطای پردازش ریاضی ]نپه�دمن��،و [ خطای پردازش ریاضی ]پمناز خوشه Hadoop توسط Cluster Monitor در زمان واقعی جمع آوری می شوند. [ خطای پردازش ریاضی ]تی�همترآمن��به صورت پویا محاسبه می شود. [ خطای پردازش ریاضی ]تینبه عنوان تابعی از N نشان داده می شود : [ خطای پردازش ریاضی ]تین=�(ن). تعریف از [ خطای پردازش ریاضی ]�(ن)بستگی به پلتفرم ابری دارد که خوشه در آن مستقر شده است. به عنوان مثال، برای پلتفرم ابری اکالیپتوس ما، تابع این است [ خطای پردازش ریاضی ]�(ن)=0.2*ن+1.67(واحد: دقیقه). بنابراین، معادله (3) به عنوان تابعی از N ، به عنوان نشان داده می شود[ خطای پردازش ریاضی ]ن�من�منسساعتهد=�(�(ن)). در نهایت، تعداد بردهایی که باید مقیاس شوند به صورت زیر بدست میآیند:
جایی که [ خطای پردازش ریاضی ]نمترآایکسحداکثر تعداد بردهای مجاز در خوشه است، و [ خطای پردازش ریاضی ]نجتو��ه�تیتعداد بردهای خوشه فعلی است. متفاوت از تئوریهای صف سنتی، مانند صف M/M/c، که عموماً مبتنی بر نظریههای احتمال هستند، الگوریتم مقیاسبندی خودکار پیشنهادی، حجم کار را زمانی که فرآیند مقیاسسازی به پایان میرسد با در نظر گرفتن وضعیت پردازش کار در زمان واقعی پیشبینی میکند. زمان مورد نیاز برای افزودن گره های برده
3.3.2. کاهش مقیاس
حذف بخشهای محاسباتی ساده است. هنگامی که زمان بیکاری (بدون اجرای وظایف نقشه یا کاهش وظایف) برای یک برد محاسباتی از آستانه تعیین شده توسط کاربر (مثلاً پنج دقیقه) فراتر رود، این برده خاتمه می یابد. به این ترتیب، زمانی که حجم کار به اندازهای کم باشد که بتوان آن را تنها بردگان اصلی مدیریت کرد، خوشه از حالت FullMode به CoreMode تنزل پیدا میکند . اگر خوشه تحت CoreMode برای یک دوره زمانی مشخص بیکار باشد (بدون کار در حال اجرا یا معلق)، خوشه می تواند بسته شود یا بر اساس پیکربندی کاربر بیکار بماند. با CoveringHDFS، compute-slave داده ها را ذخیره نمی کند، حذف برد در چند ثانیه کامل می شود، که از مصرف منابع اضافی در طول فرآیند کاهش مقیاس جلوگیری می کند.
4. مقیاس خودکار نمونه اولیه و نتیجه تجربی
4.1. پیاده سازی نمونه اولیه
بر اساس چارچوب مقیاسبندی خودکار پیشنهادی، یک نمونه اولیه مقیاسپذیری خودکار با دو عملکرد اصلی زیر توسعه داده شد: (1) خوشههای Hadoop بهطور خودکار با تعداد مشخصی از هسته/بردهای محاسباتی و سایر پیکربندیهای مشخصشده توسط کاربر در محیط ابری ارائه میشود. (2) نظارت بر حجم کار بلادرنگ خوشهای و انجام اقدامات مقیاسبندی بر اساس اطلاعات بار کاری و آستانههای مشخص شده توسط کاربر. و (3) داده های DEM را به صورت موازی با استفاده از خوشه مقیاس پذیر خودکار Hadoop درون یابی کنید.
چارچوب مقیاسبندی خودکار پیشنهادی میتواند با پلتفرمهای ابری کار کند که به کاربران اجازه میدهد ماشینهای مجازی را با استفاده از API (از طریق IaaS) تهیه کنند. در اینجا ما از یک پلتفرم ابر خصوصی روی اکالیپتوس به عنوان محیط ابری برای این نمونه اولیه استفاده کردیم. دلیل استفاده از اکالیپتوس، سازگاری API آن با Amazon EC2، یک سرویس ابر عمومی شناخته شده است. سختافزار ابری زیرین متشکل از شش ماشین فیزیکی متصل به اترنت 1 گیگابیتی (Gbps) است که هر دستگاه با CPU 8 هستهای با فرکانس 2.35 گیگاهرتز و 16 گیگابایت رم پیکربندی شده است. یک تصویر ماشین مجازی Hadoop (ساخته شده بر اساس CentOS 6.0) برای ارائه خوشه های Hadoop استفاده می شود. در این نمونه اولیه، زمان صرف شده برای افزایش مقیاس N گره با تابع محاسبه شد [ خطای پردازش ریاضی ]تین=0.2*ن+1.67 (دقیقه). این تابع با آزمایش زمان ارائه تعداد متفاوتی از ماشین های مجازی در پلتفرم ابری اکالیپتوس ما به دست آمد.
4.2. طراحی تجربی
4.2.1. درون یابی DEM و شبیه سازی بار کاری پویا
درونیابی DEM، یک عملیات معمولی فشرده داده و محاسباتی در ژئوپردازش، برای نشان دادن کارایی چارچوب مقیاس خودکار برای پشتیبانی از پردازش دادههای مکانی استفاده شد. وزن دهی معکوس فاصله (IDW) به عنوان الگوریتم درون یابی DEM انتخاب شد و یک برنامه MapReduce درون یابی DEM با زبان برنامه نویسی JAVA توسعه یافت. داده های DEM برای کل ایالت کانزاس، ایالات متحده، دانلود شده از سرور ملی نقشه بدون درز (NMSS)، به عنوان مجموعه داده آزمایشی (1 قوس در ثانیه، فاصله 30 متر در 30 متر، ~ 900 مگابایت) استفاده شد. برای فعال کردن درونیابی موازی با MapReduce، دادههای DEM به صورت مکانی به کاشیهایی با اندازه مساوی تجزیه شدند. سپس کاشیها در Hadoop SequenceFile سازماندهی شدند ( https://wiki.apache.org/hadoop/SequenceFile) فرمت کرده و برای پردازش در CoveringHDFS بارگذاری می شود.
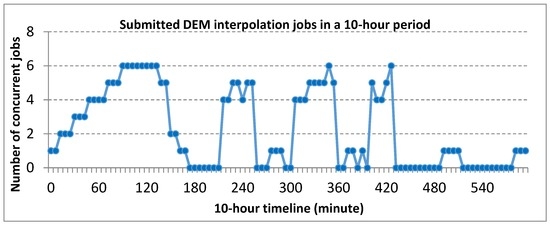
به منظور شبیه سازی حجم کاری ژئوپردازش پویا، تعداد متفاوتی از درخواست های درون یابی DEM همزمان (کارهای MapReduce) را هر شش دقیقه در یک دوره 10 ساعته با هر درخواست پردازش زیرمجموعه ای از مجموعه داده DEM (200 مگابایت) به خوشه ارسال کردیم. . هر درخواست را می توان به عنوان یک حجم کاری برای خوشه محاسباتی در نظر گرفت و در مجموع 100 بار کاری شامل 224 کار درونیابی DEM ارسال شد. شکل 4 الگوهای حجم کاری پردازش ارسالی را در این دوره نشان می دهد. منطق استفاده از این طرح الگو این است که نشاندهنده دینامیک حجم کار معمولی افزایش (از 0 تا 100 دقیقه)، کاهش (130 تا 180 دقیقه)، خاموش کردن و شکست دورهای (200 تا 420 دقیقه) و حجم کاری سبک یا بیکار است. الگوهای (420 تا 600 دقیقه).
4.2.2. راه اندازی خوشه Hadoop
سه خوشه Hadoop در محیط ابری خصوصی ما برای مقایسه مورد استفاده قرار گرفت: (1) یک خوشه مقیاسبندی خودکار بر اساس چارچوب پیشنهادی. (2) یک خوشه استاتیک با هفت گره برده. (3) یک خوشه استاتیک دیگر با 14 گره برده. پیکربندی دقیق برای سه خوشه در جدول 1 نشان داده شده است. هر سه خوشه از یک نمونه متوسط به عنوان گره اصلی استفاده کردند. خوشه مقیاسبندی خودکار با سه بخش اصلی شروع شد، که به عنوان پوشش HDFS عمل میکردند و میتوانستند 12 برد محاسباتی را در طول اوج بار کاری مقیاسبندی کنند. دو خوشه استاتیک به عنوان خطوط پایه برای مقایسه با خوشه مقیاس خودکار استفاده شد. در مقایسه با بارهای کاری که قبلاً مورد بحث قرار گرفت، خوشه ایستا با هفت برد به عنوان یک خوشه با قابلیت کمتر عمل کرد، در حالی که خوشه ایستا با 14 برد به عنوان یک خوشه تمام توان عمل کرد (بهترین عملکرد با استفاده از 14 برد برای فشرده ترین بار کاری در آرشیو شد. محیط آزمایش ما).
4.3. نتیجه و بحث
برای سه خوشه، زمان صرف شده برای اتمام هر کار ثبت شد، و زمان مصرف شده توسط هر بار کار با تجمیع زمان کار فردی به دست آمد. نتیجه در شکل 5 نشان داده شده است .
4.3.1. کارایی
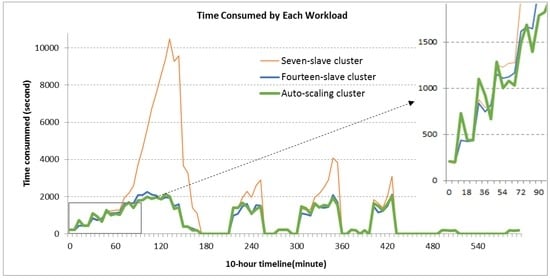
به طور کلی، زمان پایان بار کاری برای هر خوشه دارای الگوی مشابهی با الگوی بار کاری است ( شکل 5 ). با این حال، خوشه هفت برده با حساسیت بیشتری به بارهای کاری افزایش یافته، به ویژه هنگامی که بارهای کاری در یک زمان نسبتاً طولانی در سطح بالایی حفظ می شدند، همانطور که در دوره 90 تا 150 دقیقه نشان داده شده است. بنابراین، زمانی که حجم کار از ظرفیت خوشه فراتر رفت، درخواستهای پردازش در صف قرار میگرفتند و تنها زمانی میتوانستند کارهای قبلی تکمیل شوند. صف با افزایش حجم کار طولانی تر شد که به نوبه خود زمان اتمام را طولانی تر کرد. بنابراین، خوشه با تعداد ثابتی از بردها ظرفیت بسیار محدودی برای مدیریت بار کاری پویا داشت مگر اینکه برای اوج بار کاری تدارک دیده شود.
برای خوشه مقیاسبندی خودکار، زمان مصرف شده توسط هر بار کاری، الگوی مشابهی با خوشه چهارده بردی پرقدرت نشان داد. همانطور که در نمای بزرگنمایی شده شکل 5 نشان داده شده است، خوشه مقیاس خودکار نوسانات شدیدتری نسبت به خوشه چهارده بردی برای 1.5 ساعت اول داشت. این جهشهای شدید در حین افزایش مقیاس زمانی که خوشه با حالت کمتوان در حال اجرا بود، رخ داد. پس از اتمام مقیاسبندی، خوشه در حالت تمام توان برای حجم کاری فعلی قرار داشت که افت شدید زمان اتمام حجم کار را توضیح میدهد. این فرآیند در ادامه نشان داده شده است شکل 6 بیشتر نشان داده شده استA، که در آن تغییر اندازه خوشه مقیاس خودکار که توسط بارهای کاری پویا در دوره 10 ساعته هدایت می شود مشهود است. خوشه مقیاس خودکار به طور موثری با افزایش قدرت محاسباتی (اغلب محاسباتی) برای اطمینان از اتمام کارها در مدت زمان قابل قبول، الگوهای بار کاری فزاینده و انفجاری را مدیریت کرد. به طور کلی، کلاستر مقیاس خودکار عملکردی مشابه با خوشه تمام قدرت نشان می دهد.
4.3.2. مصرف منابع
برای ارزیابی مصرف منابع و میزان استفاده از خوشه مقیاسبندی خودکار، تعداد بردهها ( شکل 6 الف) و بردهای بیکار ( شکل 6 ب) از سه خوشه در طول دوره 10 ساعته برای نظارت بر وضعیت برده ثبت شد. شکل 6 B الگوی کلی بردهای بیکار را نشان می دهد که از الگوی بار کاری پیروی می کنند اما با جهت مخالف. وقتی حجم کار به اوج خود رسید، هر سه خوشه هیچ برده بیکار ندارند. هنگامی که حجم کار کاهش یافت، خوشه چهارده بردی بیشترین تعداد بردهای بیکار را داشت، در حالی که خوشه مقیاس پذیر خودکار کمترین بردهای بیکار را داشت، و خوشه هفت بردی بین این دو حالت افراطی قرار دارد.
برای ارزیابی بهتر عملکرد و استفاده از منابع از خوشه مقیاس خودکار به روش کمی، زمان پردازش 224 کار درونیابی DEM برای هر خوشه خلاصه شد ( شکل 7 الف). علاوه بر این، زمان بیکاری کلاستر (CIST) برای هر خوشه محاسبه شد ( شکل 7 ب). CIST به عنوان مجموع زمان بیکاری برای هر بخش از یک خوشه در یک دوره زمانی معین تعریف می شود. خوشه مقیاس خودکار 18.59 ساعت را برای تکمیل همه کارها صرف کرد، که تنها 12 دقیقه بیشتر از 18.38 ساعت خوشه چهارده بردی است ( شکل 7).آ). در مقایسه با خوشه هفت بردی، خوشه مقیاس پذیر خودکار 23 ساعت کمتر (افزایش 2.2 برابری در عملکرد) برای تکمیل همه کارها صرف کرد. برای استفاده از منابع، خوشه مقیاس خودکار کمترین زمان بیکاری (16.2 ساعت) را داشت، 80٪ کمتر از زمان بیکاری برای خوشه چهارده بردی (78.2 ساعت)، که باعث صرفه جویی در 62 ساعت نمونه در دوره 10 ساعته شد. ( شکل 7 ب). اگر خوشه به مدت یک ماه با الگوهای بار کاری مکرر اجرا شود، خوشه مقیاسبندی خودکار 4464 ساعت نمونه را ذخیره میکند. اگر این خوشه در آمازون EC2 با استفاده از فرمت نمونه مشابه استفاده شود، معادل 232 دلار در ماه صرفه جویی است (قیمت نوع نمونه t2.medium EC2 0.052 دلار در ساعت بدون احتساب هزینه های ذخیره سازی، شبکه و سایر هزینه ها [38] ) .
4.3.3. محلی بودن داده
در CoveringHDFS، core-slave نه تنها منابع محاسباتی را فراهم می کند، بلکه به عنوان ذخیره داده و کانال های ورودی/خروجی (I/O) کل خوشه محاسباتی نیز عمل می کند. وظایف پردازش بر روی بردهای اصلی که میتوانستند از موقعیت داده استفاده کنند، انجام میشود. برای یک خوشه فیزیکی، بخشهای اصلی بیشتر ظرفیت ورودی/خروجی بیشتری را برای خوشه فراهم میکنند و از محل دادهها بهتر استفاده میکنند و در عین حال انعطافپذیری مقیاسبندی خودکار را کاهش میدهند (زیرا بردهای اصلی حتی نمیتوانند برای جلوگیری از از دست رفتن دادهها بیکار هستند) خاتمه داده شوند. برعکس با این حال، در یک محیط ابری با ذخیره سازی مجازی و منابع شبکه، چنین تاثیری بیشتر به مکانیزم مجازی سازی و ذخیره سازی ابر مربوط می شود. در محیط آزمایش ابر خصوصی ما، خوشه مقیاسپذیر خودکار دارای سه بخش اصلی است در حالی که دو خوشه دیگر با اندازه ثابت از HDFS سنتی استفاده میکنند.شکل 5 )، CoveringHDFS باعث کاهش عملکرد آشکار در کل خوشه نمی شود، زیرا عملکردی مشابه خوشه چهارده برده با HDFS سنتی نشان می دهد.
از جنبه ای دیگر، این چارچوب کنترل و انعطاف بیشتری را برای متعادل کردن عملکرد و هزینه ارائه می دهد. در یک برنامه کاربردی عملکرد محور، همیشه میتوان از تعداد زیادی از core-slave برای اطمینان از عملکرد استفاده کرد. اگر هزینه عامل مهم تری باشد، می توان از تعداد کمی از core-slave استفاده کرد تا زمانی که حجم کار کم است، خوشه سبک شود. در هر دو مورد، زمانی که حجم کار از ظرفیت خوشهای فراتر رود، همیشه میتوان محاسبات بیشتری را در عرض چند دقیقه اضافه کرد (با فرض اینکه از ظرفیت ابر تجاوز نکند) تا عملکرد را کاهش دهد.
به طور کلی، خوشه چهارده بردی عملکرد عالی را در زمانی که حجم کار زیاد بود حفظ کرد، اما منابع محاسباتی بیشتری را هدر داد (برده های بیکار بیشتر، شکل 7 ب) زمانی که حجم کار کم بود. خوشه هفت بردی در مقایسه با خوشه چهارده بردی استفاده بهتر از منابع را نشان داد اما زمانی که حجم کار زیاد بود عملکرد را قربانی کرد ( شکل 5 ). با تنظیم پویا اندازه خوشه بر اساس حجم کار، خوشه مقیاسبندی خودکار به طور کلی بهترین استفاده از منابع را نشان داد (کمترین زمان بیکاری، شکل 7 B) و در عین حال عملکرد بهتری را ارائه داد (تقریباً برابر با خوشه چهارده بردی، شکل) . 7). این مکانیسم مقیاس خودکار که مانند “گیربکس اتوماتیک” خودرو عمل می کند، اطمینان می دهد که مقدار مناسبی از قدرت برای حجم کاری مناسب تحویل داده می شود، بنابراین “بازده انرژی” را بهبود می بخشد.
5. نتیجه گیری ها
یک چارچوب مقیاسبندی خودکار برای مقیاسبندی خودکار منابع محاسبات ابری برای خوشه Hadoop بر اساس حجم کاری پردازش پویا، با هدف بهبود کارایی و عملکرد پردازش دادههای مکانی بزرگ، پیشنهاد شده است. مهمترین اجزای این چارچوب به شرح زیر است: یک الگوریتم مقیاسپذیری پیشبینیکننده با در نظر گرفتن زمان افزایش مقیاس پیشنهادی برای تعیین دقیق تعداد بردههایی که باید با نظارت بر معیارهای مبتنی بر جعبه سفید اضافه شوند. مکانیزم CoveringHDFS برای کاهش سریع خوشه به طوری که از مصرف منابع غیر ضروری جلوگیری شود.
امکان سنجی و کارایی چارچوب مقیاس بندی با استفاده از یک نمونه اولیه بر اساس یک ابر اکالیپتوس نشان داده شده است. آزمایشها خوشه مقیاسبندی خودکار را از دیدگاه عملکرد و استفاده از منابع با شبیهسازی الگوهای بار کاری معمولی در یک دوره 10 ساعته با استفاده از درون یابی DEM به عنوان مثال ارزیابی کردند. نتایج نشان میدهد که این چارچوب مقیاسبندی خودکار میتواند (1) به طور قابلتوجهی استفاده از منابع محاسباتی را کاهش دهد (در آزمایش ما تا 80٪) در حالی که عملکردی مشابه یک خوشه تمام قدرت را با تنظیم پویا اندازه خوشه بر اساس بار کاری در حال تغییر ارائه میدهد. و (2) با افزایش منابع محاسباتی (محاسبات-برده ها) به طور موثری حجم کار پردازش افزایشی را مدیریت کند تا اطمینان حاصل شود که پردازش در مدت زمان قابل قبولی به پایان می رسد.
اگرچه نتایج امیدوارکنندهای مشاهده شد، اما در مطالعه فعلی ما محدودیتهایی وجود دارد. تحقیقات آتی برای ارزیابی بیشتر و بهبود چارچوب به شرح زیر مورد نیاز است:
-
در آزمایش ما، خوشه مقیاسبندی خودکار فقط مجاز بود 12 برد را افزایش دهد. در صورتی که بتوانیم با یک ابر بزرگتر مقیاس را بیشتر کنیم، قابلیت مقیاس بندی خودکار بهتر ارزیابی می شود. علاوه بر این، ما قصد داریم این چارچوب را بر روی پلتفرمهای مختلف ابری عمومی مانند Amazon EC2 آزمایش کنیم.
-
هنگام پیادهسازی چارچوب در یک ابر عمومی، بررسی نحوه ادغام مدل هزینه سرویس ابری در الگوریتم مقیاسبندی خودکار برای افزایش بیشتر استفاده از منابع، مطلوب است. به عنوان مثال، حداقل چرخه صورتحساب آمازون EC2 یک ساعت است. اگر در پایان چرخه صورتحساب نباشد، نیازی به خاتمه دادن به یک برده بیکار نیست.
-
پلتفرم های پردازش داده های بزرگ مرتبط با Hadoop مانند Spark [ 39 ] در حال افزایش محبوبیت هستند. در حالی که مکانیسم CoveringHDFS تا زمانی که از HDFS برای ذخیره سازی داده ها استفاده می کنند، می تواند با آن پلتفرم ها کار کند، نحوه تنظیم الگوریتم مقیاس بندی مبتنی بر MapReduce برای مدل های برنامه نویسی نیازمند بررسی بیشتر است.
با این وجود، چارچوب مقیاسبندی خودکار پیشنهادی یک رویکرد جدید برای تخصیص کارآمد مقدار مناسب منابع محاسباتی به درخواستهای ژئوپردازش پویا به شیوهای خودکار ارائه میدهد. چنین خوشه محاسباتی با قابلیت مقیاسپذیری خودکار با قابلیت ابر، ابزار قدرتمندی برای پردازش دادههای بزرگ علوم زمین با عملکرد بهینه و کاهش مصرف منابع ارائه میدهد. در حالی که از درونیابی DEM به عنوان مثال استفاده می شود، چارچوب پیشنهادی می تواند برای رسیدگی به سایر برنامه های ژئوپردازش جغرافیایی که بر روی Hadoop اجرا می شوند، مانند سرویس های تحلیلی داده های آب و هوایی که توسط Hadoop و رایانش ابری ارائه می شوند، گسترش یابد [7، 11 ] .]. علاوه بر این، الگوریتم مقیاسبندی پیشبینیکننده، مقیاس خودکار منابع رایانش ابری را برای سایر پلتفرمهای پردازش داده فراتر از Hadoop روشن میکند. در نهایت، ما معتقدیم که رویکرد پیشنهادی یک مرجع ارزشمند در برنامهریزی برنامههای کاربردی فضایی با عملکرد بهتر در یک محیط زیرساخت سایبری برای پرداختن به چالشهای دادهها و شدت محاسباتی در حوزههای جغرافیایی به صورت مقرونبهصرفه ارائه میکند [40 ، 41 ] .






بدون نظر