

خلاصه
با افزایش روزافزون حجم تصاویر سنجش از دور جمعآوریشده توسط صورتهای فلکی ماهوارهای و سکوهای هوایی، استفاده از تکنیکهای خودکار برای تشخیص تغییرات اهمیت پیدا کرده است، به طوری که تغییرات در ویژگیها را میتوان به سرعت شناسایی کرد. با این حال، مقدار داده های جمع آوری شده از ظرفیت تحلیلگران تصویر فراتر می رود. به منظور بهبود اثربخشی و کارایی تحلیلگران تصویری که فعالیتهای نگهداری دادهها را انجام میدهند، ما روشی را برای پیشبینی تغییرات مرتبط در تصاویر ماهوارهای با وضوح بالا بر اساس حاشیهنویسیهای انسانی در مناطق انتخابشده یک تصویر پیشنهاد میکنیم. ما انواع طبقه بندی کننده ها را مطالعه می کنیم تا مشخص کنیم کدام دقیق تر است. علاوه بر این، ما روشهای مختلفی را آزمایش میکنیم که در آن مجموعهای از دادههای آموزشی میتوان برای بهبود کیفیت پیشبینیها ایجاد کرد. روش پیشنهادی به تجزیه و تحلیل نتایج تشخیص تغییر با استفاده از طبقهبندیکنندههای مختلف برای توسعه یک مدل تغییر مرتبط کمک میکند که میتواند برای پیشبینی احتمال سایر حوزههای تجزیهوتحلیلشده حاوی تغییرات مرتبط یا غیر مرتبط مورد استفاده قرار گیرد. این پیشبینیهای تغییرات مربوطه برای تحلیلگران مفید است، زیرا با اعمال نفوذ مشاهدات آنها از مناطقی که قبلاً تجزیه و تحلیل شدهاند، بازجویی از نتایج تشخیص خودکار تغییر را سرعت میبخشند. مقایسه چهار طبقه بندی کننده نشان می دهد که تکنیک جنگل تصادفی کمی بهتر از سایر رویکردها عمل می کند. زیرا آنها با استفاده از مشاهدات خود از مناطقی که قبلاً تجزیه و تحلیل شده اند، بازجویی از نتایج تشخیص تغییر خودکار را سرعت می بخشند. مقایسه چهار طبقه بندی کننده نشان می دهد که تکنیک جنگل تصادفی کمی بهتر از سایر رویکردها عمل می کند. زیرا آنها با استفاده از مشاهدات خود از مناطقی که قبلاً تجزیه و تحلیل شده اند، بازجویی از نتایج تشخیص تغییر خودکار را سرعت می بخشند. مقایسه چهار طبقه بندی کننده نشان می دهد که تکنیک جنگل تصادفی کمی بهتر از سایر رویکردها عمل می کند.
تشخیص تغییر ؛ طبقه بندی ; سنجش از دور
1. معرفی
با گسترش تصاویر ماهواره ای با وضوح بالا و به آسانی در دسترس، بسیاری از محققان تلاش خود را بر روی تجزیه و تحلیل تصاویر چند زمانی متمرکز کرده اند. بات و والگرون زیرکانه مشاهده می کنند که جنبه زمانی داده های مکانی به یک جزء مهم فزاینده برای کاربردهای تحلیل [ 1 ]، از جمله تشخیص تغییر تصویر به تصویر تبدیل شده است. یکی از نمونههای چنین سیستمی، سیستم تشخیص و بهرهبرداری تغییرات مکانی (GeoCDX)، یک سیستم کاملاً خودکار برای تشخیص تغییرات در مقیاس بزرگ در تصاویر با وضوح بالا [ 2 ] است که اخیراً در یک شماره ویژه در مورد تجزیه و تحلیل چند زمانی منتشر شده است. داده های سنجش از دور [ 3 ]. روش های دیگر برای تشخیص تغییر با وضوح بالا شامل استفاده از شبکه های عصبی [ 4]، خوشه بندی سلسله مراتبی [ 5 ، 6 ]، مجموعه های سطح حداکثر سازی انتظار [ 7 ]، پروفایل های ویژگی های مورفولوژیکی [ 8 ] و تقسیم بندی [ 9 ]. با این حال، در بسیاری از موارد، به سادگی شناسایی تغییرات رخ داده کافی نیست.
چندین رویکرد تشخیص تغییر، شناسایی تغییر را برای اهداف بسیار خاص متمرکز می کنند. نمونه برداری از این موارد شامل نقشه برداری از الگوهای پوشش زمین برای مدل سازی رشد شهری [ 10 ]، شناسایی مناطق نیازمند احیای پوشش گیاهی [ 11 ] و برآورد خطر لرزه ای [ 12 ] است. در این دست نوشته، ما به تغییرات دائمی و انسانی علاقه مندیم. توضیحات بیشتر در بخش 3.1 ارائه شده است.
ما رویکردی را برای شناسایی خودکار تغییرات مرتبط با استفاده از طبقهبندیکنندهای پیشنهاد میکنیم که با نمونههای شناسایی شده توسط کاربر از تغییرات مرتبط آموزش داده شده است. اگر کاربر مناطق نمونه ای از یک جفت تصویر چند زمانی را مشاهده کند و ارزیابی کند که آیا تغییر مربوطه رخ داده است یا نه، ما باید بتوانیم یک سیستم را آموزش دهیم تا سپس مناطق دیگر را در تصویر طبقه بندی کنیم.
در کار قبلی، ما یک سیستم پرس و جو به مثال (QBE) برای بازیابی تصویر مبتنی بر محتوا (CBIR) [13-15] توسعه دادیم که میتوانست تصاویر را در یک پایگاه داده شناسایی کند که با یک تصویر پرسوجو مطابقت دارد. در [ 16 ]، Barb و Kilicay-Ergin مدل های معنایی را با استفاده از بهینه سازی ژنتیکی ویژگی های تصویر سطح پایین توسعه دادند. نمونه های دیگر استفاده از الگوریتم های داده کاوی برای تصاویر سنجش از دور شامل استخراج اطلاعات زمانی-مکانی [ 17 ] و استفاده از قوانین تداعی برای استخراج اطلاعات از الگوهای نگاه افراد در حال مشاهده تصاویر ماهواره ای است [ 18 ].
در این نسخه خطی، بخش 2 یک نمای کلی در سطح بالا از سیستم تشخیص تغییر GeoCDX ارائه میکند، زیرا این سیستم به عنوان منبع ویژگیهای تصویری و حاشیهنویسیهای تغییر مورد استفاده در پیشبینی تغییرات مربوطه عمل میکند. تعریف ما از تغییر مربوطه در بخش 3 همراه با شرحی از الگوریتم های طبقه بندی استفاده شده ارائه شده است. بخش 4 آزمایش های انجام شده برای ارزیابی الگوریتم های پیش بینی تغییر را تشریح می کند و معنای نتایج را مورد بحث قرار می دهد. در نهایت، بخش 5 یک نتیجهگیری و شرح مختصری از جهتگیریهای آینده تحقیقات را ارائه میکند.
2. تشخیص تغییر با GeoCDX
سیستم تشخیص و بهره برداری تغییرات جغرافیایی (GeoCDX) یک سیستم تشخیص تغییر حسگر سنسور برای تصاویر سنجش از دور با وضوح بالا است [ 2 ]]. GeoCDX به طور خودکار تصاویر را از انواع حسگرها، از جمله IKONOS، QuickBird، GeoEye-1 و WorldView-2 دریافت می کند. پس از ورود به کاتالوگ سیستم، یک برنامه پردازش ویژه داده بر اساس ویژگی های تصویر ایجاد می شود. مرحله اول این پردازش ممکن است شامل مراحلی مانند تصحیح هندسی و تبدیل به بازتاب بالای جو (TOA) باشد، اگر برای تصویر مناسب باشد. این سیستم به طور خودکار تعیین می کند که چه جفت زمانی تصاویر را می توان در هنگام دریافت تصاویر جدید ایجاد کرد. این همچنین یک برنامه پردازش برای هر جفت ایجاد می کند. این طرح کاملاً خودکار شامل ثبت همزمان تصویر به تصویر، تعادل رادیومتری، استخراج ویژگی های سطح بالا، تفاوت ویژگی های استخراج شده و ادغام تصاویر تفاوت در یک تصویر اطمینان تغییر واحد است.شکل 1 .
سپس نتایج تشخیص تغییر توسط سیستم GeoCDX به کاشی های 256×256 متری تقسیم می شود. سپس امتیاز تغییر در هر کاشی برای هر کاشی بر اساس میزان و شدت تغییر محاسبه میشود. همانطور که در [ 2 ] تعریف شده است، این امتیاز تغییر در هر کاشی عبارت است از:
که در آن T مجموعه پیکسل هایی است که یک کاشی را تشکیل می دهند و s ij یک امتیاز تغییر در هر پیکسل است که با استفاده از یک الگوریتم فیلتر پشته غیر خطی محاسبه می شود که شدت و ویژگی های مورفولوژیکی تغییر موجود در هر پیکسل را محاسبه می کند. این امتیاز تغییر هر پیکسل به طور مفصل در بخش IV.B توضیح داده شده است. از [ 2 ].
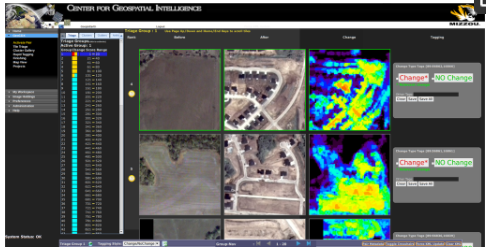
سپس کاشیها با استفاده از این امتیاز تغییر از بیشترین تغییر به کمترین تغییر رتبهبندی میشوند و به ترتیب رتبهبندی در یک رابط وب ارائه میشوند. سپس کاربران میتوانند از کاشیهایی استفاده کنند که مشخص شده است بیشترین تغییر را دارند و زمانی که دیگر تغییر مرتبطی در نتایج پیدا نکردند، تحلیل خود را متوقف کنند. نمونه ای از نتایج تغییرات با رتبه بالا در رابط وب GeoCDX را می توان در شکل 2 مشاهده کرد.
علاوه بر این، سیستم GeoCDX همچنین از امضای ویژگی هر کاشی و امضای تغییر در هر کاشی برای خوشهبندی کاشیها بر اساس میزان تغییر و محتوا استفاده میکند. جزئیات کامل در مورد الگوریتم خوشه بندی تجمعی رقابتی مورد استفاده برای این کار را می توان در [ 19 ] یافت. این الگوریتم بر اساس درجه واریانس در انواع تغییرات موجود در یک جفت معین، تعداد خوشههای پویا (اما محدود) تولید میکند. هر خوشه تولید شده نشان دهنده نوع متمایز انتقال بین پوشش زمین و انواع کاربری زمین است. برای مثال، یک خوشه ممکن است علفزاری را نشان دهد که به مسکن مسکونی تغییر کرده است، در حالی که خوشه دیگر ممکن است شامل نمونه هایی از ساختمان های جدید باشد که در مناطق شهری ظاهر می شوند. شکل 3 چندین نمونه از اعضای خوشه های تولید شده توسط سیستم GeoCDX را نشان می دهد.
برای کار ارائه شده در اینجا، سیستم GeoCDX برای انجام تشخیص تغییر در تصاویر از مناطق مختلف جغرافیایی استفاده شد. یکی از نتایج (و تنها مورد در نظر گرفته شده در این کار) پردازش خودکار تشخیص تغییر GeoCDX، فهرست اولویتبندیشده کاشیهایی با ابعاد 256×256 متر است که از نظر بیشترین تغییر به کمترین تغییر مرتب شدهاند. در استفاده معمولی، یک تحلیلگر این نتایج را به ترتیب رتبه بندی مورد بازجویی قرار می دهد و برای هر کاشی تغییری در مقابل ارزیابی عدم تغییر ایجاد می کند. همانطور که کاربر در فهرست کاشیها پیش میرود، ما به دنبال استفاده از دانش کاشیهایی هستیم که قبلاً ارزیابی شدهاند تا در مورد کاشیهای باقیمانده در فهرست که حاوی تغییرات هستند یا خیر، پیشبینی کنیم.
3. استفاده از طبقه بندی کننده ها برای پیش بینی تغییرات مرتبط
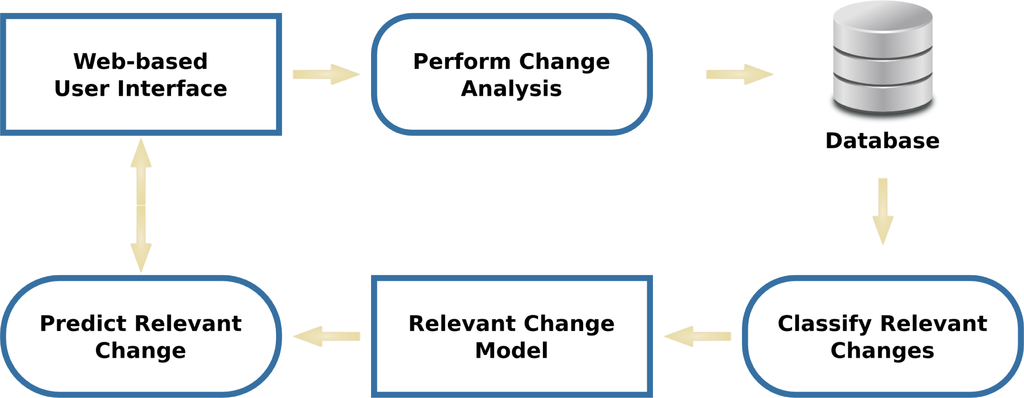
با استفاده از همان امضاهای ویژگی در هر کاشی که سیستم GeoCDX برای سازماندهی کاشیهای تصویر در خوشهها استفاده میکند [ 19 ]، ما روشهایی را برای پیشبینی نواحی تغییرات مربوطه بر اساس طبقهبندی دستی قبلی یک زیرمجموعه از یک جفت پیشنهاد میکنیم. نمودار جریان سطح بالا از روش پیشنهادی پیش بینی تغییر را می توان در شکل 4 مشاهده کرد.
کاربر با بازرسی کاشیها در رابط کاربری GeoCDX و انجام تجزیه و تحلیل تغییرات شروع میکند تا مشخص کند آیا تغییر مربوطه در کاشی رخ داده است یا خیر. این حاشیه نویسی های تغییر/بدون تغییر بر اساس هر کاشی در پایگاه داده سیستم ثبت می شوند. اگر تغییر رخ دهد، اما مرتبط نباشد، باید توسط تحلیلگر به عنوان بدون تغییر علامت گذاری شود. سپس میتوان این اطلاعات را همراه با ویژگیهای هر کاشی مورد استفاده برای خوشهبندی تغییر که در بخش 2 توضیح داده شد و به تفصیل در بخش III.A توضیح داده شد، استفاده کرد. از [ 19 ]. این ویژگی ها هیستوگرام های 16 بین هستند که اطلاعات مربوط به ویژگی های سطح 14 پیکسلی مورد استفاده توسط سیستم GeoCDX را رمزگذاری می کنند. همانطور که در [ 19]، این هیستوگرام ها را به یکدیگر الحاق می کنیم تا یک بردار ویژگی واحد بسازیم که نشان دهنده امضای هر کاشی است. ما از این امضاها همراه با دادههای حاشیهنویسی انباشته تغییر/بدون تغییر برای یک جفت استفاده میکنیم تا یک طبقهبندی کننده (یعنی مدل تغییر مربوطه) تولید کنیم که میتواند برای پیشبینی تغییرات مربوطه برای کاشیهای باقیمانده در یک جفت استفاده شود.
3.1. تعریف تغییر مرتبط
برنامه های بسیاری وجود دارند که به استفاده از تشخیص خودکار تغییرات با استفاده از تصاویر سنجش از راه دور نیاز دارند. هر برنامه دارای مجموعه ای از معیارهای خاص خود است که انواع تغییرات مرتبط و غیر مرتبط را تعریف می کند. به عنوان مثال، پس از یک بلای طبیعی، مقامات مدیریت اضطراری احتمالا فقط به شناسایی مناطق آسیب دیده یا تخریب شده علاقه مند هستند. علاوه بر این، شرکت های بیمه علاقه مند به دانستن تغییرات در املاکی هستند که برای آنها بیمه نامه می نویسند (به عنوان مثال، توسعه سازه های موجود، ساختمان های جدید در حال ساخت و غیره).
Bruzzone و Bovolo یک طبقه بندی از علل تغییرات در [ 20]. در این مقاله، ما سناریویی را پیشنهاد میکنیم که در آن به زیرمجموعهای از تغییرات انسانی علاقهمندیم که ممکن است نیاز به بهروزرسانی ویژگیهایی روی نقشه داشته باشند که تغییرات مرتبط در نظر گرفته میشوند. همه ویژگی های دیگر تغییر مرتبط در نظر گرفته نمی شوند. در این تعریف از تغییرات مربوطه، ما هر ساختمان جدید یا الحاقی به یک ساختمان موجود را که حداقل 200 متر مربع مساحت داشته باشد (یعنی تقریباً به اندازه یک خانه مسکونی کوچک) شامل میشود. علاوه بر این، ما هر جاده جدید، پارکینگ یا سایر سطوح غیرقابل نفوذ را تغییر مرتبط می دانیم. تخریب هر ساختمان یا جاده موجود نیز به عنوان یک تغییر مرتبط در نظر گرفته می شود. در نهایت، زمین آشفته ای که برای اهداف غیر کشاورزی پاکسازی شده است (مثلاً ساخت و ساز، جنگل زدایی و غیره) به عنوان تغییر مرتبط در نظر گرفته می شود.
در مقابل، تغییرات فصلی یا گذرا به عنوان تغییرات مرتبط برای این آزمایش خاص در نظر گرفته نمی شود. به عنوان مثال، وسایل نقلیه در پارکینگ ها یا در جاده ها، اگرچه یک منظره رایج است، اما تغییر مربوطه در نظر گرفته نمی شود. تغییرات در سطوح جاده، مانند بازسازی، تغییر مرتبطی را ایجاد نمی کند، زیرا تغییری نیست که نیاز به به روز رسانی ویژگی ها در نقشه داشته باشد. تغییرات کشاورزی (از جمله کاشت محصولات زراعی، شخم زدن مزارع، و غیره) و نوسانات فصلی بدنه آب مربوط به این آزمایش نیست. در نهایت، تغییرات زودگذر، مانند سایه ها یا درخشش ساختمان (به دلیل اشباع بیش از حد سنسور)، که منجر به رگه شدن می شود، تغییر مرتبطی نیست.
3.2. الگوریتم های طبقه بندی
در این مقاله، ما نتایج طبقهبندی تغییرات را از چهار الگوریتم مختلف ارائه میکنیم تا کارایی نسبی هر کدام را تعیین کنیم. ورودی هر مدل طبقهبندی یک بردار ویژگی با ارزش واقعی به همراه یک طبقهبندی باینری (تغییر/بدون تغییر) برای هر نقطه داده آموزشی است. برای اهداف طبقهبندی، از همان بردارهای ویژگی استفاده میکنیم که برای خوشهبندی کاشیهایی که در بخش 2 توضیح داده شد، استفاده میکنیم. از این مجموعه داده آموزشی، یک مدل طبقهبندی برای نزدیکترین همسایه، SVM، درخت تصمیم (CART) و طبقهبندی تصادفی جنگل ساخته شده است.
3.2.1. k-نزدیکترین همسایه ها
ساده ترین الگوریتم به کار رفته در این دست نوشته، الگوریتم طبقه بندی k نزدیکترین همسایه ها است [ 21 ]. برای طبقهبندی یک کاشی معین، بردار ویژگی آن، x، با تمام کاشیهای آموزشی در مجموعه مقایسه میشود و کلاس نزدیکترین کاشی در فضای ویژگی اختصاص داده میشود.
3.2.2. ماشین های بردار پشتیبانی
استفاده از ماشین های بردار پشتیبان (SVM) به طور گسترده ای به عنوان وسیله ای برای انجام طبقه بندی غیرخطی دو کلاسه مورد بحث قرار گرفته است. در ابتدا توسط Cortes و Vapnik [ 22 ] توسعه داده شد، SVMها قادر به انجام طبقه بندی کارآمد داده ها هستند که در غیر این صورت به صورت خطی قابل تفکیک نیستند، با استفاده از “ترفند هسته” برای نمایش داده ها در یک فضای ویژگی با ابعاد بالا.
برای هر کاشی در مجموعه آموزشی، میتوانیم بردار ویژگی x i ∈ R d را تعریف کنیم و عضویت را بر اساس اینکه به عنوان تغییر مرتبط علامتگذاری شده است ( یعنی اجازه دهید y i = 1) یا تغییر نامربوط یا خیر مشخص شده است را به آن اختصاص دهیم. تغییر دهید ( به عنوان مثال ، اجازه دهید y i = -1). اگر اجازه دهیم w بردار نرمال را برای ابر صفحه ای که دو مجموعه را تقسیم می کند نشان دهد، می توانیم با استفاده از برنامه نویسی درجه دوم مسئله طبقه بندی را حل کنیم. ما باید بهینه سازی کنیم:
موضوع:
برای تمام مقادیر i . طبقهبندی بهدستآمده طبقهبندی است که حاشیه یا جدایی بین دو کلاس را در فضای ابعادی بالا مورد استفاده توسط هسته انتخابی به حداکثر میرساند.
سپس طبقهبندی با پرتاب کردن هر نقطه داده جدید به همان فضای با ابعاد بالا و تعیین اینکه در کدام سمت ابر صفحه قرار میگیرد، انجام میشود.
3.2.3. طبقه بندی درخت تصمیم
علاوه بر این، ما از الگوریتم طبقهبندی درخت تصمیم CART که در اصل توسط Breiman و همکاران پیشنهاد شده بود، استفاده میکنیم. [ 23 ]. درختهای تصمیم یک تکنیک ناپارامتریک هستند که با انتخابهایی در هر گره درخت در مورد نحوه تقسیم مجموعه داده به گونهای که نقاط داده را متعادل کرده و بیشترین دقت پیشبینی را به دست میآورد، ساخته میشوند. این تقسیمها به صورت بازگشتی ادامه مییابد تا زمانی که هر گره حاوی نقاط داده متعلق به یک کلاس واحد باشد یا اندازه گره از پیش تعیینشده به دست آید.
طبقه بندی را می توان با شروع از گره ریشه و راه رفتن در درخت تصمیم تا رسیدن به یک گره انجام داد. سپس یک برچسب کلاس بر اساس برچسب نقاط داده در گره اختصاص داده می شود.
3.2.4. جنگل تصادفی
مفهوم درخت تصمیم توسط بریمن برای ایجاد روش طبقهبندی گروهی جنگلهای تصادفی گسترش یافت [ 24 ]. این تکنیک از “کیسه بندی” برای نمونه برداری از مجموعه داده آموزشی برای تولید درخت های تصمیم گیری چندگانه استفاده می کند. در مرحله طبقه بندی، این درختان به طور هماهنگ برای تولید چندین نتیجه طبقه بندی استفاده می شوند. هر درخت برای طبقهبندی نقطه داده رأی میدهد و نقطه داده اجماع (یعنی یکی با تعداد آرا) اختصاص داده میشود.
4. نتایج
در این بخش، آزمایشهای انجامشده برای آزمایش پیشبینیهای تغییر مربوطه توسط الگوریتمهای مختلف را شرح میدهیم. این آزمایش ها شامل داده هایی از سه ناحیه نشان داده شده در جدول 1 بود. مناطق مورد استفاده از نظر چشم انداز متفاوت بودند. کلمبیا، میسوری، ایالات متحده، شامل ترکیبی از مناطق شهری و زمین های کشاورزی روستایی است که هر دو تغییرات متوسطی را نشان دادند. تصاویر لاس وگاس، نوادا، ایالات متحده، به شدت شهری شده بود و حاوی مقادیر قابل توجهی از تغییرات بود. در نهایت، یک منطقه کوهستانی و کم جمعیت در نزدیکی نطنز ایران مورد استفاده قرار گرفت که در فاصله زمانی بین دو تصویر، تغییر بسیار کمی داشته است.
به منظور تعمیم خوب، یک طبقه بندی باید با مجموعه داده آموزشی ساخته شود که با توزیع طبیعی کل مجموعه داده مطابقت داشته باشد [ 25 ]. این امر به ویژه در مورد مجموعه داده های نامتعادل که در آنها نمونه های نسبتا کمی از یک کلاس وجود دارد چالش برانگیز است. روشهای مقابله با چالش مجموعه دادههای نامتعادل را میتوان در سه دسته [ 26 ] دستهبندی کرد: تطبیق الگوریتمهای موجود، پیش پردازش مجموعههای داده از طریق تکنیکهای نمونهگیری یا پس پردازش مدل طبقهبندی. در حالی که مجموعه دادههای کلمبیا و لاس وگاس تقریباً 3:1 بین کاشیهای بدون تغییر و تغییر تقسیم میشوند، مجموعه دادههای نطنز 50:1 بین کاشیهای بدون تغییر و تغییر تقسیم میشوند. با توجه به چالشهای بالقوه مجموعه داده ما، تکنیکهای نمونهگیری از دادهها را بررسی خواهیم کرد، مانند آنهایی که در [27 ]، برای بهبود نتایج طبقه بندی ما. بخشهای زیر روشهای نمونهگیری را توصیف میکنند که از دانش مجموعه داده استفاده میکنند تا اطمینان حاصل شود که انواع مختلفی از نقاط داده در مجموعه آموزشی گنجانده شدهاند. جدول 2 تعداد نمونه های آموزشی و آزمایشی استفاده شده برای هر مجموعه داده و همچنین درصد تغییرات و کاشی های بدون تغییر موجود در هر مجموعه داده آزمایشی را نشان می دهد.
4.1. پیشبینیها با استفاده از کاشیهای با تغییر زیاد
اولین آزمایش شامل استفاده از کاشیهایی است که سیستم GeoCDX آنها را به عنوان کاشیهایی با تغییرات بالا شناسایی کرده است. با استفاده از این کاشیهای تغییر بالا، هر یک از چهار طبقهبندی کننده با دادههای مربوط به درصد ثابتی از کاشیها آموزش داده میشوند. در حالی که کاشیهای انتخابشده همگی کاشیهایی با تغییرات زیاد هستند، همه تغییرات ثبت شده توسط آنها لزوماً تغییر مرتبط نیستند. ما سه مجموعه داده مختلف با کاشیهای تغییر بالا تولید کردیم. آنها شامل بالاترین رتبه 5، 15 درصد و 25 درصد از مجموعه داده ها هستند. جدول 3 درصد انتخاب شده و تعداد مربوط به کاشی های استفاده شده از هر جفت را نشان می دهد.
4.3. پیش بینی ها با استفاده از اعضای خوشه
به یاد بیاورید که بخش 2 خوشه بندی نتایج تشخیص تغییر را تشریح کرد. در تلاش برای آموزش طبقه بندی کننده با مجموعه داده های آموزشی متنوع تر، می توانیم از این خوشه ها برای تولید نمونه های آموزشی خود استفاده کنیم. همانطور که در بالا ذکر شد، تعداد خوشه ها براساس جفت متفاوت است، همانطور که تعداد اعضا در هر خوشه متفاوت است. ما با تولید یک مجموعه داده آموزشی برای هر جفت شروع کردیم که حاوی نماینده ترین عضو هر خوشه در جفت بود. سپس، مجموعه دادههای آموزشی گستردهای را برای هر جفت با گنجاندن دومین و سپس سومین عضو نماینده در هر خوشه تولید کردیم. جدول 5 خلاصه ای از تعداد کاشی های استفاده شده برای هر مجموعه داده را نشان می دهد.
4.4. پیشبینیها با استفاده از اعضای خوشه علاوه بر کاشیهای با تغییر زیاد و کم
در نهایت، ما همچنین مجموعههای دادهای تولید میکنیم که کاشیهایی را ترکیب میکنند که امتیازات تغییر GeoCDX بسیار بالا، امتیازات تغییر GeoCDX بسیار پایین و نمونههایی نماینده از هر خوشه تغییر GeoCDX دارند. جداول 6 و 7 خلاصه ای از ترکیب این مجموعه داده های آموزشی را نشان می دهد. در حالت ایدهآل، این کاشیها طیف گستردهای از پوشش زمین و انواع کاربری اراضی موجود در هر جفت را به تصویر میکشند تا به نگرانیهای نمونهبرداری شرح دادهشده در مقدمه بخش 4 بپردازند.
4.5. نتایج پیش بینی
با استفاده از تمام مجموعه دادههای آموزشی که در بخشهای فرعی قبلی توضیح داده شد، نزدیکترین همسایه، ماشین بردار پشتیبان، درخت تصمیم و طبقهبندیکننده جنگل تصادفی را برای هر مجموعه میسازیم. ما از هر طبقهبندیکننده برای برچسبگذاری تمام دادههای باقیمانده (یعنی دادههای آزمایشی) استفاده میکنیم و نتایج را با برچسبهای تغییر حقیقت/بدون تغییر اعمال شده توسط یک تحلیلگر تصویر با تجربه مقایسه میکنیم. بر اساس این نتایج طبقه بندی، ما موارد زیر را فهرست بندی می کنیم:
- نتایج مثبت واقعی: تغییر مربوطه رخ داد و به این ترتیب طبقه بندی شد.
- نتایج مثبت کاذب: هیچ تغییری رخ نداده یا تغییری رخ نداده است که مرتبط نیست، اما توسط الگوریتم به عنوان تغییر طبقهبندی شده است.
- نتایج منفی کاذب: یک تغییر مرتبط رخ داده است، اما به درستی طبقه بندی نشده است.
- نتایج منفی واقعی: هیچ تغییری رخ نداده یا تغییری رخ نداده است که مرتبط نبوده و طبقهبندی کننده به درستی این شرایط را نشان داده است.
بر اساس این چهار عامل، می توانیم معیارهای ارزیابی سنتی دقت و یادآوری را به صورت زیر محاسبه کنیم:
همانطور که در رابطه (6) نشان داده شده است، می توان یک متریک دقت را نیز برای اندازه گیری عملکرد کلی هر الگوریتم محاسبه کرد .
ما چهار جدول را ارائه می کنیم که مقادیر دقت، یادآوری و دقت را برای هر یک از انواع طبقه بندی کننده شرح داده شده در بخش 3 نشان می دهد. جدول 8 نتایج را برای طبقه بندی کننده نزدیکترین همسایه، جدول 9 برای ماشین بردار پشتیبان، جدول 10 برای درخت تصمیم و جدول ارائه می دهد. 11 برای طبقه بندی جنگل تصادفی. هر ردیف در جدول مربوط به یکی از مجموعه داده های آموزشی است که در جداول 3 تا 5 ، 6 و 7 توضیح داده شده است.
جدول 8 نتایج پیش بینی تغییر را با استفاده از طبقه بندی کننده نزدیکترین همسایه نشان می دهد. نرخ فراخوان زمانی بالاتر است که فقط از کاشی های تغییر بالا به عنوان داده های آموزشی استفاده می شود (مجموعه داده A1–A3). این برای هر سه سایت تست صادق است. با این حال، هنگام استفاده از این داده های آموزشی، دقت کلی به وضوح آسیب می بیند. به طور کلی، بالاترین ترکیب مقادیر دقت، یادآوری و دقت از مجموعه دادههای آموزشی حاصل میشود که کاشیهای با تغییرات بالا و اعضای هر یک از خوشههای تغییر (مجموعههای داده سری F و G) را ترکیب میکنند. با این حال، به طور کلی، نتایج استفاده از طبقهبندیکننده نزدیکترین همسایه (NN) قانعکننده نیست.
نتایجی که عملکرد طبقه بندی ماشین بردار پشتیبان (SVM) را کمی می کند در جدول 9 آمده است.. به طور کلی، این نتایج بهبود قابل توجهی را نسبت به دستهبندیکننده NN نشان میدهد. باز هم، استفاده از مجموعههای آموزشی که کاشیهای با تغییرات زیاد را با اعضای خوشهای نماینده ترکیب میکنند، همچنان بهترین نتایج طبقهبندی را تولید میکنند. مقادیر دقت و دقت در اطراف علامت 50٪ قرار دارند، در حالی که دقت کلی بین 70 تا 80٪ برای مجموعه داده های کلمبیا و لاس وگاس است. مجموعه داده نطنز نشان دهنده یک ناهنجاری است، زیرا مقدار نسبتاً کمی تغییر واقعی در مجموعه داده است. مقادیر دقت و فراخوان معمولاً بالاتر از 30٪ نیستند، اما دقت کلی در محدوده متوسط 90٪ است. این به این دلیل رخ می دهد که طبقه بندی کننده قادر است تعداد زیادی از کاشی های منفی واقعی را در این جفت به دقت پیش بینی کند.
به طور کلی، نتایج طبقه بندی درخت تصمیم CART نشان داده شده در جدول 10 نشان دهنده کاهش جزئی در دقت، یادآوری و دقت در مقایسه با SVM است. استثنا قابل توجه این بود که مجموعه داده های سری D و E با استفاده از درخت تصمیم CART در مقایسه با SVM بهبود جزئی را نشان دادند.
در نهایت، نتایج پیشبینی تغییر با استفاده از طبقهبندیکننده جنگل تصادفی نشاندادهشده در جدول 11 بهترین در بین چهار الگوریتم ارائهشده است.
4.6. تجزیه و تحلیل نتایج با استفاده از یک امتیاز F تعمیم یافته
امتیاز F یک ارزیابی معمولی است که برای تعیین دقت الگوریتم طبقه بندی به روشی که هم دقت و هم دقت را در نظر می گیرد، استفاده می شود. امتیاز سنتی F 1 به عنوان میانگین هارمونیک مقادیر دقت و یادآوری محاسبه می شود و بین صفر و یک محدود می شود. F 1 را می توان به صورت زیر محاسبه کرد:
که در آن TP تعداد پیامدهای مثبت واقعی، FP تعداد پیامدهای مثبت کاذب و FN تعداد پیامدهای منفی کاذب را نشان می دهد.
یک نسخه تعمیمیافتهتر از امتیاز F را میتوان با معرفی یک متغیر β محاسبه کرد که اجازه میدهد تاکید بیشتری بر دقت یا مولفه یادآوری شود. این امتیاز F تعمیم یافته، Fβ ، به صورت زیر محاسبه می شود:
که در آن مقدار بیشتر وزنهای β بیشتر از دقت به یاد میآورند و مقدار کمتری از β بر دقت در هزینه یادآوری تأکید میکند.
جدول 12 مقادیر F 0.1 , F 1 و F 10 را نشان می دهد که با استفاده از مقادیر دقت و فراخوان جدول 8 محاسبه شده اند. F 0.1 نشان دهنده معیاری است که در آن دقت 10 برابر مهمتر از یادآوری است. F 10 دقت وزنه ها و فراخوانی را به گونه ای اندازه گیری می کند که یادآوری را 10 برابر دقت می کند. در نهایت F 1وزن متعادل مقادیر دقت و یادآوری است. بر اساس این سه معیار در میان مجموعه دادههای مختلف، میتوانیم ببینیم که، به طور کلی، طبقهبندیکننده نزدیکترین همسایه میتواند نتایج رضایتبخشی را در صورتی که فراخوانی بر دقت ترجیح داده شود، تولید کند، اما این کار را به طور مداوم انجام نمیدهد. به طور خاص، مجموعه داده های لاس وگاس و نطنز به ندرت دارای مقادیر بیشتر از 0.5 هستند.
مقادیر سه امتیاز F با استفاده از طبقه بندی کننده SVM در جدول 13 نشان داده شده است. در این جدول به دلیل بهبود کیفیت نتایج طبقه بندی در مقایسه با طبقه بندی کننده NN شروع به مشاهده امتیازات بالاتر می کنیم. امتیازات مجموعه داده کلمبیا معمولاً برای هر سه معیار بیشتر از 0.5 است. بسیاری از مقادیر F-score برای لاس وگاس از این آستانه نیز عبور می کنند. با این حال، نتایج برای نطنز با استفاده از طبقهبندی کننده SVM بهبود کمی را نشان میدهد.
همانطور که در بخش 4.5 اشاره کردیم، نتایج برای طبقهبندی کننده CART عموماً کمی بدتر از نتایج SVM است. ما همین روند را هنگام بررسی مقادیر مختلف F-score برای طبقهبندی کننده CART نشان داده شده در جدول 14 مشاهده میکنیم.
در نهایت، پیشرفت زمانی حاصل می شود که مقادیر امتیاز F را برای طبقه بندی جنگل تصادفی نشان داده شده در جدول 15 بررسی کنیم. به طور کلی، همه مجموعه دادههای آموزشی برای کاشیهای کلمبیا نتایج متعادلی را ارائه میدهند که نه دقت و نه به یاد آوردن را نشان میدهند. مجموعه دادههای آموزشی لاسوگاس نتایجی را به دست میدهد که دقت را به یادآوری ترجیح میدهد، همانطور که میتوان از امتیازات نسبتاً بالای F 0.1 و امتیازات نسبتاً پایین F 10 آنها مشاهده کرد. جالب است بدانید که مجموعه داده های سری G برای لاس وگاس (یعنی G1، G2 و G3) امتیاز پایین F 0.1 را ایجاد می کنند. با مراجعه به جدول 7، می بینیم که آن مجموعه داده ها درصد بسیار زیادی از کاشی های جفت را به کار می گیرند. ما معتقدیم که برازش بیش از حد اتفاق می افتد، که مانع از تعمیم خوب طبقه بندی کننده می شود. مقادیر F-score برای مجموعه داده های نطنز روند جالبی را نشان می دهد. سری داده های A، C، D و E همگی مقادیر پایینی را برای سه امتیاز F گزارش شده تولید می کنند. در همین حال، سری دادههای B، F و G امتیاز بالایی را برای F 0.1 گزارش میکنند که به این معنی است که دقت نسبتاً بالا است. به یاد بیاورید که جدول 2 نشان می دهد که جفت نطنز با تعداد زیادی کاشی بدون تغییر پر شده است. فقط سری دادههای B، F و G شامل تعداد قابلتوجهی کاشیهای بدون تغییر هستند که به طبقهبندیکننده جنگل تصادفی اجازه میدهد یک مدل مؤثر از دادههای آموزشی تولید کند که به دادههای آزمایش تعمیم مییابد.
5. بحث و نتیجه گیری
این دستنوشته روشی را برای پیشبینی نواحی تغییرات مربوطه، در سیستم GeoCDX [ 2 ] ارائه میکند. این سیستم پردازش تشخیص تغییر خودکار را با تریاژ سریع نتایج تشخیص تغییر انسان در حلقه ترکیب می کند. در حالی که سیستم GeoCDX نسبت به نوع تغییر شناسایی شده ناشناس است، قضاوت انسان برای این نتیجه گیری استفاده می شود که آیا یک کاشی باید بسته به وظیفه تحلیلگر به عنوان حاوی تغییرات “مرتبط” برچسب گذاری شود یا خیر. همانطور که یک کاربر نتایج تشخیص تغییر ارائه شده توسط GeoCDX را بازجویی می کند، ما نشان دادیم که می توانیم از حاشیه نویسی تغییر/بدون تغییر تحلیلگر تصویر برای کمک به پیش بینی اینکه آیا کاشی های بعدی دارای تغییرات مرتبط هستند یا خیر استفاده کنیم. این پیش بینی ها در نهایت منجر به کاهش زمان تحلیل برای کاربر می شود.
چهار الگوریتم طبقه بندی مختلف برای انجام پیش بینی استفاده شد. به طور کلی الگوریتم طبقه بندی تصادفی جنگل بهترین عملکرد را داشت. ما همچنین طرحهای مختلفی را برای ایجاد یک مجموعه داده آموزشی با تنوع خوب که شامل مناطق تغییر و مناطق بدون تغییر است بررسی کردیم تا اطمینان حاصل کنیم که ترکیب مجموعه داده آموزشی منعکس کننده کل مجموعه داده است [ 25 ]]. به طور کلی، مجموعه دادههای آموزشی که شامل نمونههایی از همه خوشههای تغییر GeoCDX بودند، بهترین طبقهبندیکنندهها را تولید کردند. ما نشان دادیم که با یک مجموعه داده آموزشی مناسب، میتوانیم یک طبقهبندی جنگل تصادفی تولید کنیم که معمولاً میتواند تغییرات مربوطه را با دقت بیش از ۷۰٪ و حتی تا ۹۷٪ پیشبینی کند. طبقهبندیکنندههایی که تولید میشوند عموماً دقت را به یادآوری ترجیح میدهند، به این معنی که نشانههای تغییر مثبت کاذب نسبتاً کمی وجود خواهد داشت.
در کار آینده، ما قصد داریم با استفاده از ویژگی های دانه ای بیشتر استخراج شده از تصاویر برای پیش بینی تغییرات در مقیاس دقیق تر، بررسی کنیم. ما محدودیت های استفاده از ویژگی های استخراج شده از کاشی های 256 در 256 متری مورد استفاده توسط GeoCDX را می شناسیم، اما به طور کلی از نتایجی که می توان با آن ویژگی ها به دست آورد راضی بودیم. علاوه بر این، ما قصد داریم اطلاعات ردیابی نگاه جمعآوریشده از کاربران سیستم را ترکیب کنیم [ 18] برای تشخیص دقیق اینکه کدام بخش از تصویر برای تصمیم گیری در مورد تغییر مرتبط در مقابل تغییر نامربوط در مقابل عدم تغییر مهم است. استفاده از این اطلاعات ردیابی چشم همراه با ویژگی های تصویری دقیق تر، پیش بینی تغییرات آینده را بهبود می بخشد. در نهایت، آزمایشهای اضافی باید برای سنجش بهبود عملکرد ارائه شده با استفاده از حاشیهنویسی تغییر/بدون تغییر از یک تحلیلگر تصویر برای پیشبینی وجود تغییر مرتبط در سایر بخشهای دیده نشده از تصویر انجام شود. ما با استفاده از رویکرد نیمه خودکار خود برای نشان دادن اینکه آیا تغییر مربوطه رخ داده است یا خیر، بهبودهای کارایی قابل توجهی را پیش بینی می کنیم. با این حال، این باید به صورت تجربی تایید شود.
منابع
- بهات، ام. والگرون، JO روایات جغرافیایی و پویایی مکانی-زمانی آنها: استدلال متعارف برای تحلیل های سطح بالا در سیستم های اطلاعات جغرافیایی. ISPRS Int. J. Geo-Inf. 2014 ، 3 ، 166-205. [ Google Scholar ]
- کلاریچ، م. کلایول، بی. اسکات، جی. هادسون، ن. Sjahputera، O. لی، ی. بارت، اس. کلر، جی. Davis, C. GeoCDX: یک سیستم تشخیص و بهره برداری خودکار تغییرات برای تصاویر ماهواره ای با وضوح بالا. IEEE Trans. Geosci. Remote Sens 2013 , 51 , 2067–2086. [ Google Scholar ]
- بوولو، اف. بروزون، ال. کینگ، آر. مقدمه ای بر موضوع ویژه در تجزیه و تحلیل داده های سنجش از راه دور چند زمانی. IEEE Trans. Geosci. Remote Sens. 2013 ، 51 ، 1867-1869. [ Google Scholar ]
- ژونگ، ی. لیو، دبلیو. ژائو، جی. Zhang, L. تشخیص تغییر براساس شبکههای عصبی جفتشده با پالس و ویژگی NMI برای تصاویر سنجش از دور با وضوح فضایی بالا. IEEE Geosci. سنسور از راه دور Lett. 2015 ، 12 ، 537-541. [ Google Scholar ]
- دینگ، ک. هوو، سی. خو، ی. ژونگ، ز. Pan, C. خوشه بندی سلسله مراتبی پراکنده برای تشخیص تغییر تصویر VHR. IEEE Geosci. سنسور از راه دور Lett. 2015 ، 12 ، 577-581. [ Google Scholar ]
- لیو، اس. بروزون، ال. بوولو، اف. Du، P. تشخیص تغییر بدون نظارت سلسله مراتبی در تصاویر فراطیفی چند زمانی. IEEE Trans. Geosci. Remote Sens. 2015 ، 53 ، 244-260. [ Google Scholar ]
- هائو، ام. شی، دبلیو. ژانگ، اچ. لی، سی. تشخیص تغییر بدون نظارت با مجموعه سطح مبتنی بر حداکثرسازی انتظار. IEEE Geosci. سنسور از راه دور Lett. 2014 ، 11 ، 210-214. [ Google Scholar ]
- فالکو، ن. مورا، م. بوولو، اف. بندیکتسون، جی. Bruzzone، L. تشخیص تغییر در تصاویر VHR بر اساس پروفایل های ویژگی مورفولوژیکی. IEEE Geosci. سنسور از راه دور Lett. 2013 ، 10 ، 636-640. [ Google Scholar ]
- هیچری، ح. بازی، ی. آلاجلان، ن. Malek, S. تقسیم بندی تعاملی برای تشخیص تغییر در تصاویر سنجش از دور چند طیفی. IEEE Geosci. سنسور از راه دور Lett. 2013 ، 10 ، 298-302. [ Google Scholar ]
- احمد، بی. احمد، آر. مدلسازی پویایی رشد پوشش زمین شهری با استفاده از تصاویر ماهواره ای چند زمانی: مطالعه موردی داکا، بنگلادش. ISPRS Int. J. Geo-Inf. 2012 ، 1 ، 3-31. [ Google Scholar ]
- Estoque، RC; Estoque، RS; مورایاما، ی. اولویت بندی مناطق برای توانبخشی با نظارت بر تغییر در پوشش گیاهی مبتنی بر بارنگی. ISPRS Int. J. Geo-Inf. 2012 ، 1 ، 46-68. [ Google Scholar ]
- ویلند، ام. پیتور، ام. پارولای، س. Zschau، J. برآورد قرار گرفتن در معرض از تصاویر ماهواره ای نوری با وضوح چندگانه برای ارزیابی خطر لرزه ای. ISPRS Int. J. Geo-Inf. 2012 ، 1 ، 69-88. [ Google Scholar ]
- Shyu، CR; کلاریچ، م. اسکات، جی. بارب، ا. دیویس، سی. Palaniappan، K. GeoIRIS: سیستم بازیابی اطلاعات مکانی و نمایه سازی mdash؛ محتوی کاوی، مدل سازی معناشناسی، و پرس و جوهای پیچیده. IEEE Trans. Geosci. Remote Sens. 2007 , 45 , 839-852. [ Google Scholar ]
- کلاریچ، م. اسکات، جی. Shyu, CR بازیابی مبتنی بر محتوای چند شیء چند شاخصه. IEEE Trans. Geosci. Remote Sens. 2012 , 50 , 4036–4049. [ Google Scholar ]
- اسکات، جی. کلاریچ، م. دیویس، سی. Shyu، CR درخت بیت مپ متعادل با آنتروپی برای بازیابی اشیاء مبتنی بر شکل از پایگاه داده های تصاویر ماهواره ای در مقیاس بزرگ. IEEE Trans. Geosci. Remote Sens. 2011 ، 49 ، 1603-1616. [ Google Scholar ]
- بارب، ا. Kilicay-Ergin، N. بهینه سازی ژنتیکی برای مدل های رتبه بندی معنایی انجمنی تصاویر ماهواره ای بر اساس پوشش زمین. ISPRS Int. J. Geo-Inf. 2013 ، 2 ، 531-552. [ Google Scholar ]
- Shyu، CR; کلاریچ، م. اسکات، جی. Mahamaneerat, W. کشف دانش توسط قوانین انجمن معدن و اطلاعات زمانی-مکانی از پایگاههای اطلاعاتی تصاویر جغرافیایی در مقیاس بزرگ، مجموعه مقالات IGARSS 2006، کنفرانس بینالمللی IEEE در زمینه علوم زمین و سمپوزیوم سنجش از دور، 2006، دنور، CO، ایالات متحده آمریکا، 31 ژوئیه-34 آگوست 2006; ص 17-20.
- Klaric، MN; اندرسون، بی. Shyu، CR اطلاعات کاوی از استدلال بصری انسان در مورد تصاویر ماهواره ای چند زمانی و با وضوح بالا. بین المللی J. Image Data Fusion 2012 ، 3 ، 243-256. [ Google Scholar ]
- Sjahputera، O. اسکات، جی. کلایول، بی. کلاریچ، م. هادسون، ن. کلر، جی. دیویس، سی. خوشه بندی تغییرات شناسایی شده در تصاویر ماهواره ای با وضوح بالا با استفاده از یک الگوریتم تراکم رقابتی تثبیت شده. IEEE Trans. Geosci. Remote Sens. 2011 , 49 , 4687–4703. [ Google Scholar ]
- بروزون، ال. Bovolo, F. چارچوبی جدید برای طراحی سیستمهای تشخیص تغییر برای تصاویر سنجش از دور با وضوح بسیار بالا. Proc. IEEE 2013 ، 101 ، 609-630. [ Google Scholar ]
- جلد، تی. هارت، P. طبقه بندی الگوی نزدیکترین همسایه. IEEE Trans. Inf. نظریه 1967 ، 13 ، 21-27. [ Google Scholar ]
- کورتس، سی. Vapnik، V. پشتیبانی-بردار شبکه. ماخ فرا گرفتن. 1995 ، 20 ، 273-297. [ Google Scholar ]
- بریمن، ال. فریدمن، جی اچ. اولشن، RA; Stone, C. طبقه بندی و رگرسیون درختان ; چپمن و هال: نیویورک، نیویورک، ایالات متحده آمریکا، 1984. [ Google Scholar ]
- بریمن، L. جنگل های تصادفی. ماخ فرا گرفتن. 2001 ، 45 ، 5-32. [ Google Scholar ]
- Provost، F. یادگیری ماشینی از مجموعه داده های نامتعادل 101، مجموعه مقالات کارگاه آموزشی AAAI-2000 در مورد مجموعه داده های نامتعادل، آستین، TX، ایالات متحده، 31 ژوئیه 2000.
- Abe, N. روش های نمونه گیری برای یادگیری از مجموعه داده های نامتعادل: یادگیری فعال، یادگیری حساس به هزینه و فراتر از آن، مجموعه مقالات کارگاه آموزشی ICML-KDD’2003: یادگیری از مجموعه داده های نامتعادل، واشنگتن، دی سی، ایالات متحده آمریکا، 21 اوت 2003.
- تانگ، ی. ژانگ، YQ; چاولا، ن. Krasser، S. SVMs مدل سازی برای طبقه بندی بسیار نامتعادل. IEEE Trans. سیستم مرد سایبرن. قسمت B: Cybern 2009 ، 39 ، 281-288. [ Google Scholar ]




© 2014 توسط نویسندگان; دارنده مجوز MDPI، بازل، سوئیس این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر